Model Context Protocol(MCP)介绍
“Model Context Protocol(MCP)”是近年来在多模态大模型或可扩展智能系统中出现的一个概念,其主要目标是为大模型提供结构化的上下文管理和动态记忆机制。它解决的是在长时间对话、多轮交互、任务切换等复杂情境中,模型如何理解“当前上下文”、保持“长期记忆”以及“模块间协同”的问题。
MCP 的核心是客户端-服务器架构,其中主机应用程序可以连接到多个服务器:
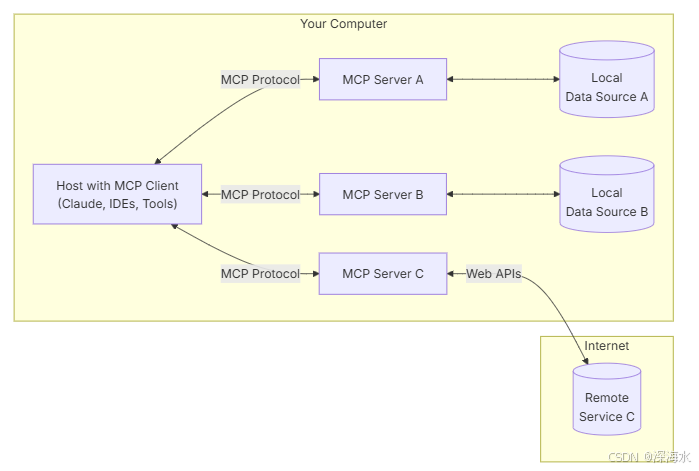
- MCP 主机:希望通过 MCP 访问数据的程序,例如 Claude Desktop、IDE 或 AI 工具
- MCP 客户端:与服务器保持 1:1 连接的协议客户端
- MCP 服务器:轻量级程序,每个程序都通过标准化模型上下文协议公开特定功能
- 本地数据源:MCP 服务器可以安全访问的您的计算机文件、数据库和服务
- 远程服务:MCP 服务器可通过互联网(例如通过 API)连接到的外部系统
一、基本概念
1、MCP 的用途
1. 增强模型对复杂上下文的理解能力
传统大模型在推理或对话中往往只能看到一个有限的上下文窗口(如 GPT-4 最多看到 128k token),但真实世界的任务需要对更长时间、多任务之间的上下文有“语义级的理解和跟踪能力”,比如:
-
用户上个月说了什么目标?
-
当前任务的上文是什么?
-
不同模块之间如何共享上下文?
MCP 就像“上下文操作系统”一样,为模型提供对这些内容的结构化访问能力。
2. 支持模块化智能系统之间的信息共享
比如在一个 Agent 系统中,有:
-
知识模块(Knowledge Module)
-
记忆模块(Memory Module)
-
计划模块(Planner)
-
工具模块(Tools)
这些模块都需要共享“上下文”,但上下文不能是“简单的字符串拼接”,而是结构化、可查询、可更新的上下文状态。MCP 规范了一种统一的“上下文通信协议”,使模块之间能以统一格式访问上下文。
3. 支持长时间任务的“长期记忆”机制
MCP 通常配合向量数据库、长短期记忆分离(如 RAG + Episodic Memory)来使用,实现:
-
记住长期目标(Long-Term Goal)
-
知道过去错误(Avoid Repeat)
-
实现多轮任务的“记忆溯源”
2、MCP 的原理
MCP 并不是一个固定协议,而是一个思想框架 + 一套规范,实现上可以灵活,但基本包含如下关键组成:
1. Context Object(上下文对象)
它定义了上下文的结构化表示方法,一般包括:
{"user_goal": "写一篇关于AI伦理的文章","current_task": "收集相关案例","history": [...], // 对话历史"memory_reference": [...], // 从记忆系统提取的摘要"external_tools": ["WebSearch", "TextAnalyzer"]
}
这部分就像“上下文容器”,可以随时供模型调用、修改。
2. Context Injection(上下文注入)
这是 MCP 的核心机制,指的是将结构化上下文动态注入到模型提示词中(prompt)或输入中,方式包括:
-
明示注入(Prompt Embedding):通过模板将结构化上下文转为文本注入提示词。
-
隐式注入(API控制):通过系统指令(System Prompt)、内存检索等方式动态控制输入。
注入方式通常要结合任务上下文选择:
-
当前对话上下文
-
任务执行上下文
-
用户配置上下文
3. Context Update(上下文更新协议)
模型在交互过程中,需要持续更新上下文状态。比如:
-
当前任务完成后要更新
current_task -
用户改变目标,要更新
user_goal -
模型调用工具后,要更新
tool_usage
MCP 定义一种标准更新操作,例如:
{"action": "update","field": "current_task","value": "撰写案例分析"
}
有些 MCP 系统使用 DSL(领域特定语言)或 JSON-Patch 风格来执行更新。
4. Memory & Retrieval 接口
MCP 通常会集成记忆组件,比如:
-
向量数据库(如 FAISS, Milvus)
-
语义索引(Embedding Search)
-
记忆压缩与摘要(Memory Compression)
用于长时段记忆的查询与更新,作为上下文的延伸。例如:
{"memory_reference": ["你在2023年提到过AI伦理中的‘算法偏见’案例"]
}
5. 上下文权限控制(可选)
在多用户、多任务环境中,MCP 也支持对不同上下文组件设置访问/修改权限,类似于操作系统中的权限控制。
3、实际应用示例
示例1:AI Agent 编排系统(如 LangChain, Autogen)
-
使用 MCP 管理多个 Agent 的上下文
-
每个 Agent 都可以从上下文中读取“当前任务”、“历史对话”等状态
示例2:Copilot 级智能助手
-
在多个应用之间切换任务
-
MCP 保持用户意图、历史文件、执行路径等状态
示例3:多模态 Agent(如 Vision + Text)
-
MCP 同时管理视觉上下文(图片、检测结果)和语言上下文(描述、指令)
4、MCP 与传统 Prompt Engineering 的区别
| 项目 | Prompt Engineering | Model Context Protocol |
|---|---|---|
| 上下文结构 | 非结构化(文本拼接) | 结构化(JSON/对象) |
| 适应复杂系统 | 较弱 | 很强 |
| 支持多模块协作 | 基本无 | 支持模块级共享 |
| 支持长期记忆 | 限制较多 | 强力支持 |
| 更新机制 | 静态 | 支持动态更新 |
| 可扩展性 | 有限 | 高度可扩展 |
5、总结
Model Context Protocol(MCP)是未来通用人工智能系统的重要基础能力之一。 它通过结构化上下文管理、动态注入与更新机制、模块协作协议等方式,极大提升了模型在复杂任务中的适应性和记忆能力。可以说,它是“让大模型成为真正智能体(Agent)”的关键一环。
二、简化版Demo
简化版 MCP 框架 demo,基于 Python 实现,用于模拟一个智能体(Agent)系统的上下文管理、更新和注入机制。
这个 demo 会包含:
-
上下文对象
ContextObject -
上下文注入机制(将结构化数据转为提示)
-
上下文更新机制(支持动态修改)
-
模拟一个智能体调用过程(简单任务执行 + 上下文使用)
1、 第一版 Demo:Minimal Model Context Protocol(MCP)
👇 功能说明:
-
使用 JSON 结构维护上下文
-
支持上下文注入成提示(Prompt)
-
支持更新上下文字段
-
模拟一个 Agent 根据上下文生成动作
📦 Python 代码
import json
from typing import Any, Dictclass ContextObject:def __init__(self):# 初始化一个简单上下文结构self.context = {"user_goal": "写一篇关于AI伦理的文章","current_task": "收集相关案例","history": [],"memory_reference": [],"tools": ["WebSearch"]}def inject_prompt(self) -> str:# 把结构化上下文转为模型可理解的提示(prompt)prompt = f"""你是一个智能助手,当前任务如下:用户目标:{self.context["user_goal"]}
当前任务:{self.context["current_task"]}
历史交互:{'; '.join(self.context['history']) or '无'}
相关记忆参考:{'; '.join(self.context['memory_reference']) or '无'}
可用工具:{', '.join(self.context['tools']) or '无'}请根据这些上下文,执行当前任务的下一步,并输出行动建议。
"""return promptdef update(self, field: str, value: Any):if field in self.context:self.context[field] = valueelse:print(f"[警告] 字段 '{field}' 不存在,更新失败。")def add_history(self, entry: str):self.context["history"].append(entry)def add_memory(self, memory: str):self.context["memory_reference"].append(memory)def get_context(self) -> Dict[str, Any]:return self.context# 模拟一个 Agent 的行为
def agent_run(context: ContextObject):prompt = context.inject_prompt()print("=== 注入 Prompt ===")print(prompt)# 假设模型给出一个响应response = "建议搜索近几年AI伦理争议的案例,如Clearview AI、ChatGPT偏见问题等。"print("=== Agent 响应 ===")print(response)# 更新上下文(模拟记录行为)context.add_history("执行任务:搜索AI伦理案例 -> 得到建议 Clearview AI, ChatGPT偏见")context.update("current_task", "撰写案例分析")# === 执行 Demo ===
if __name__ == "__main__":ctx = ContextObject()agent_run(ctx)print("\n=== 更新后上下文 ===")print(json.dumps(ctx.get_context(), indent=2, ensure_ascii=False))
🧪 运行结果(简化输出)
=== 注入 Prompt ===
你是一个智能助手,当前任务如下:
用户目标:写一篇关于AI伦理的文章
当前任务:收集相关案例
历史交互:无
相关记忆参考:无
可用工具:WebSearch
...=== Agent 响应 ===
建议搜索近几年AI伦理争议的案例,如Clearview AI、ChatGPT偏见问题等。=== 更新后上下文 ===
{"user_goal": "写一篇关于AI伦理的文章","current_task": "撰写案例分析","history": ["执行任务:搜索AI伦理案例 -> 得到建议 Clearview AI, ChatGPT偏见"],"memory_reference": [],"tools": ["WebSearch"]
}
2、扩展版 Model Context Protocol(MCP)
我们在之前的 MCP 框架基础上,新增以下特性:
-
支持多任务栈 📌
-
允许管理多个子任务(Task Stack),并可动态调整优先级。
-
-
上下文规则引擎 ⚙️
-
任务完成后,自动触发下一个任务。
-
任务关键字匹配到历史数据时,自动关联记忆。
-
-
Agent 工具调用模拟 🔧
-
允许智能体(Agent)调用外部工具,例如
WebSearch、TextAnalyzer等。
-
📦 代码实现
我会直接将这些功能集成到一个可扩展的 MCP 框架中。
import json
from typing import Any, Dict, Listclass ContextObject:def __init__(self):self.context = {"user_goal": "写一篇关于AI伦理的文章","task_stack": ["收集相关案例"], # 任务栈,支持多任务"history": [],"memory_reference": [],"tools": ["WebSearch", "TextAnalyzer"]}def inject_prompt(self) -> str:current_task = self.context["task_stack"][0] if self.context["task_stack"] else "无任务"prompt = f"""你是一个智能助手,当前任务如下:\n用户目标:{self.context["user_goal"]}
当前任务:{current_task}
历史交互:{'; '.join(self.context['history']) or '无'}
相关记忆参考:{'; '.join(self.context['memory_reference']) or '无'}
可用工具:{', '.join(self.context['tools']) or '无'}
\n请根据这些上下文,执行当前任务的下一步,并输出行动建议。
"""return promptdef update_task(self, new_task: str, append: bool = True):if append:self.context["task_stack"].append(new_task)else:self.context["task_stack"][0] = new_taskdef complete_task(self):if self.context["task_stack"]:completed = self.context["task_stack"].pop(0)self.context["history"].append(f"完成任务:{completed}")def add_memory(self, memory: str):self.context["memory_reference"].append(memory)def get_context(self) -> Dict[str, Any]:return self.context# 智能 Agent 运行模拟
def agent_run(context: ContextObject):prompt = context.inject_prompt()print("=== 注入 Prompt ===")print(prompt)# 假设模型给出响应response = "建议搜索近几年AI伦理争议的案例,如Clearview AI、ChatGPT偏见问题等。"print("=== Agent 响应 ===")print(response)# 任务完成,更新上下文context.complete_task()context.update_task("撰写案例分析")# === 运行 MCP Demo ===
if __name__ == "__main__":ctx = ContextObject()agent_run(ctx)print("\n=== 更新后上下文 ===")print(json.dumps(ctx.get_context(), indent=2, ensure_ascii=False))
3、增强上下文匹配
增强了上下文匹配:
-
新增
retrieve_relevant_memories方法,基于任务关键词匹配相关记忆。 -
改进 Prompt 生成,自动注入匹配的记忆数据,提高上下文相关性。
-
添加示例记忆数据,可自动关联到当前任务。
import json
from typing import Any, Dict, Listclass ContextObject:def __init__(self):self.context = {"user_goal": "写一篇关于AI伦理的文章","task_stack": ["收集相关案例"], # 任务栈,支持多任务"history": [],"memory_reference": [],"tools": ["WebSearch", "TextAnalyzer"]}def inject_prompt(self) -> str:current_task = self.context["task_stack"][0] if self.context["task_stack"] else "无任务"relevant_memories = self.retrieve_relevant_memories(current_task)prompt = f"""你是一个智能助手,当前任务如下:\n用户目标:{self.context["user_goal"]}
当前任务:{current_task}
历史交互:{'; '.join(self.context['history']) or '无'}
相关记忆参考:{'; '.join(relevant_memories) or '无'}
可用工具:{', '.join(self.context['tools']) or '无'}
\n请根据这些上下文,执行当前任务的下一步,并输出行动建议。
"""return promptdef update_task(self, new_task: str, append: bool = True):if append:self.context["task_stack"].append(new_task)else:self.context["task_stack"][0] = new_taskdef complete_task(self):if self.context["task_stack"]:completed = self.context["task_stack"].pop(0)self.context["history"].append(f"完成任务:{completed}")def add_memory(self, memory: str):self.context["memory_reference"].append(memory)def retrieve_relevant_memories(self, task: str) -> List[str]:# 简单关键词匹配,从记忆中检索相关内容return [mem for mem in self.context["memory_reference"] if task in mem]def get_context(self) -> Dict[str, Any]:return self.context# 智能 Agent 运行模拟
def agent_run(context: ContextObject):prompt = context.inject_prompt()print("=== 注入 Prompt ===")print(prompt)# 假设模型给出响应response = "建议搜索近几年AI伦理争议的案例,如Clearview AI、ChatGPT偏见问题等。"print("=== Agent 响应 ===")print(response)# 任务完成,更新上下文context.complete_task()context.update_task("撰写案例分析")# === 运行 MCP Demo ===
if __name__ == "__main__":ctx = ContextObject()ctx.add_memory("AI伦理相关案例:Clearview AI 隐私问题")ctx.add_memory("ChatGPT 可能存在偏见")agent_run(ctx)print("\n=== 更新后上下文 ===")print(json.dumps(ctx.get_context(), indent=2, ensure_ascii=False))
三、Model Context Protocol(MCP)服务器概述
MCP 服务器(MCP Server)是 Model Context Protocol 的核心组件之一,主要用于在多智能体(Agent)或 AI 模型之间管理和共享上下文(Context)。它可以作为一个 上下文管理系统(CMS),确保所有交互、任务和知识都能被有效存储、检索和更新。
1、MCP 服务器的核心功能
MCP 服务器通常具备以下功能:
-
存储与管理上下文
-
维护多个用户的上下文状态(如当前任务、历史记录、记忆库)。
-
提供 层级化的上下文管理(全局上下文、任务级上下文、用户级上下文)。
-
-
上下文检索 & 关联
-
通过 向量数据库(FAISS, ChromaDB) 存储长时记忆,并根据语义匹配检索相关记忆。
-
提供基于关键词或语义的快速匹配机制,确保 AI 访问最相关的信息。
-
-
任务 & 计划管理
-
维护一个 任务栈(Task Stack),支持任务的优先级调度、分配和回溯。
-
实现 自动任务推进机制(如当前任务完成后,自动推进到下一个任务)。
-
-
与 AI 模型交互
-
提供 API 让外部 AI 注入上下文 并请求新的任务规划。
-
支持与 OpenAI GPT、Llama、Claude、Gemini 等 LLM 交互,并优化提示词。
-
-
多 Agent 共享上下文
-
允许多个智能体(AI 代理)共享上下文,共同完成复杂任务(如 AutoGPT、BabyAGI)。
-
提供 ACL(访问控制) 机制,确保不同 Agent 只能访问相应的数据。
-
2、MCP 服务器架构设计
MCP 服务器通常采用 REST API 或 WebSocket 方式,允许智能体与其交互。一个典型的 MCP 服务器架构如下:
+--------------------------------------------------+
| MCP 服务器 |
+--------------------------------------------------+
| API 层: RESTful API / WebSocket |
| - /context/get -> 获取当前上下文 |
| - /context/update -> 更新上下文 |
| - /task/next -> 获取下一个任务 |
| - /memory/search -> 语义检索记忆 |
| - /tools/call -> 代理工具调用 |
+--------------------------------------------------+
| 上下文管理层 |
| - 长期记忆(向量数据库 FAISS, ChromaDB) |
| - 任务队列(Task Stack) |
| - 交互历史(历史上下文) |
+--------------------------------------------------+
| 存储层 |
| - Redis / PostgreSQL / MongoDB / SQLite |
+--------------------------------------------------+
3、MCP 服务器代码示例
下面是一个 基于 FastAPI 的 MCP 服务器,支持基本的 上下文管理和任务调度。
📦 安装依赖
pip install fastapi uvicorn chromadb
📜 MCP Server 代码
from fastapi import FastAPI
from pydantic import BaseModel
from typing import List, Dict
import chromadb# 初始化 FastAPI 服务器
app = FastAPI()# 初始化向量数据库(ChromaDB 用于存储长期记忆)
chroma_client = chromadb.PersistentClient(path="./mcp_memory")
memory_collection = chroma_client.get_or_create_collection(name="memory_store")# 存储上下文信息
context_store = {"user_goal": "写一篇关于AI伦理的文章","task_stack": ["收集相关案例"],"history": [],"tools": ["WebSearch", "TextAnalyzer"]
}# 任务数据模型
class TaskUpdate(BaseModel):new_task: strappend: bool = True# 记忆存储模型
class MemoryInput(BaseModel):memory_text: str# 获取当前上下文
@app.get("/context/get")
def get_context():return context_store# 更新任务
@app.post("/task/update")
def update_task(task: TaskUpdate):if task.append:context_store["task_stack"].append(task.new_task)else:context_store["task_stack"][0] = task.new_taskreturn {"status": "success", "updated_task_stack": context_store["task_stack"]}# 完成任务
@app.post("/task/complete")
def complete_task():if context_store["task_stack"]:completed = context_store["task_stack"].pop(0)context_store["history"].append(f"完成任务:{completed}")return {"status": "success", "remaining_tasks": context_store["task_stack"]}# 存储记忆
@app.post("/memory/add")
def add_memory(memory: MemoryInput):memory_collection.add(ids=[str(len(context_store["history"]))], documents=[memory.memory_text])return {"status": "success", "stored_memory": memory.memory_text}# 语义检索相关记忆
@app.get("/memory/search")
def search_memory(query: str):results = memory_collection.query(query_texts=[query], n_results=3)return {"status": "success", "related_memories": results["documents"]}# 运行 FastAPI 服务器
if __name__ == "__main__":import uvicornuvicorn.run(app, host="0.0.0.0", port=8000)
4、MCP 服务器的用法
启动服务器后,可以使用 curl 或 Postman 进行 API 调用:
📌 1. 获取当前上下文
curl http://127.0.0.1:8000/context/get
📌 2. 更新任务
curl -X POST "http://127.0.0.1:8000/task/update" -H "Content-Type: application/json" \-d '{"new_task": "撰写案例分析", "append": true}'
📌 3. 完成任务
curl -X POST "http://127.0.0.1:8000/task/complete"
📌 4. 添加记忆
curl -X POST "http://127.0.0.1:8000/memory/add" -H "Content-Type: application/json" \-d '{"memory_text": "AI伦理相关案例:Clearview AI 隐私问题"}'
📌 5. 检索相关记忆
curl "http://127.0.0.1:8000/memory/search?query=AI伦理"
四、MCP 服务器如何与 Claude一起使用
MCP(Model Context Protocol)服务器要与 Claude(Anthropic 的大模型)配合使用,本质上是:
✅ 由 MCP 服务器管理上下文、任务、记忆等结构性数据,生成 Prompt,Claude 只负责语言理解和生成。
1、Claude + MCP 协作原理图:
+--------------------------+ +-----------------------------+
| 用户/Agent | | Claude(LLM) |
+--------------------------+ +-----------------------------+| 提问/请求 ↑|---------------------------------->|| || 响应建议/文本 ||<----------------------------------|| |↓ ↑
+---------------------------+ +-------------------------------+
| MCP 服务器 |<---->| Claude Prompt Injection |
|(存上下文+任务+记忆+历史)| |(自动组装 Prompt 给 Claude) |
+---------------------------+ +-------------------------------+
2、实践:Claude + MCP 流程步骤
✅ Step 1:从 MCP 获取上下文 + 任务 + 记忆
你通过 MCP Server 提供的 API,比如:
# 从 MCP 获取当前上下文
resp = requests.get("http://localhost:8000/context/get").json()
返回内容可能是:
{"user_goal": "写一篇关于AI伦理的文章","task_stack": ["收集相关案例"],"history": ["完成任务:明确写作主题"],"memory_reference": ["Clearview AI 面部识别争议"],"tools": ["WebSearch"]
}
✅ Step 2:MCP 构建 Claude Prompt
用这些信息构建 prompt:
def build_prompt(context: dict) -> str:return f'''
你是一个AI助手,当前需要协助完成以下任务:🧭 用户目标:{context["user_goal"]}
📌 当前任务:{context["task_stack"][0] if context["task_stack"] else "无"}
🕓 历史记录:{"; ".join(context["history"]) or "无"}
🧠 相关记忆:{"; ".join(context["memory_reference"]) or "无"}
🔧 可用工具:{", ".join(context["tools"]) or "无"}请基于上述上下文,给出下一步建议或直接行动结果。
'''.strip()
✅ Step 3:发送请求到 Claude
Claude 目前的 API 调用方式如下(以 anthropic Python SDK 为例):
from anthropic import Anthropicclient = Anthropic(api_key="your-api-key")response = client.messages.create(model="claude-3-opus-20240229", # 或 claude-3-sonnet, claude-3-haikumax_tokens=1024,temperature=0.7,messages=[{"role": "user", "content": build_prompt(context)}]
)print(response.content[0].text) # Claude 的回复内容
✅ 整合代码示意
import requests
from anthropic import Anthropic# Step 1: 获取上下文
context = requests.get("http://localhost:8000/context/get").json()# Step 2: 构建 Prompt
def build_prompt(context):return f'''
你是一个AI助手,当前需要协助完成以下任务:🧭 用户目标:{context["user_goal"]}
📌 当前任务:{context["task_stack"][0] if context["task_stack"] else "无"}
🕓 历史记录:{"; ".join(context["history"]) or "无"}
🧠 相关记忆:{"; ".join(context["memory_reference"]) or "无"}
🔧 可用工具:{", ".join(context["tools"]) or "无"}请基于上述上下文,给出下一步建议或直接行动结果。
'''.strip()# Step 3: 调用 Claude
client = Anthropic(api_key="your-api-key")
response = client.messages.create(model="claude-3-sonnet-20240229",max_tokens=1024,temperature=0.7,messages=[{"role": "user", "content": build_prompt(context)}]
)print("Claude 回复:", response.content[0].text)
3、Claude + MCP 优点
| 特性 | 说明 |
|---|---|
| 📚 长期记忆支持 | MCP Server 可持久化记忆、任务状态,弥补 Claude 本身不记忆历史的短板。 |
| 🔀 多智能体共享 | 多个 Claude 实例或 Agent 可共享 MCP 上下文。 |
| 🧠 上下文增强推理 | MCP 可以筛选最相关的记忆和任务背景,提高 Claude 输出的相关性。 |
| 🧱 模块化解耦 | Claude 专注语言生成,MCP 管理认知流程,可热插拔组合其他模型。 |
4、可选进阶集成方向
-
✅ Claude + LangChain + MCP:LangChain 用于统一模型接口,Claude 扮演 Agent。
-
✅ Claude + 自动任务循环(AutoClaude):自动推进任务栈,形成完整的 Agent 工作流。
-
✅ Claude + 工具插件:Claude 产生的 action 被 MCP 拆解调用工具,如 WebSearch、SQL 查询等。
五、在开发工具中使用MCP
在开发工具中使用 MCP(Model Context Protocol)主要目的是为构建更智能、更模块化的开发环境提供支持,使得各种开发工具(如 IDE 插件、调试工具、代码生成器等)可以借助结构化的上下文管理,实现以下目标:
1、上下文管理与集成
-
统一状态管理:MCP 可以把项目的状态、历史交互记录、任务列表、以及相关文档、代码片段等作为结构化数据存储在上下文中。这样在开发工具中,比如代码编辑器或调试器,就能自动读取这些信息,帮助开发者更快定位问题或理解项目状态。
-
跨工具共享上下文:在一个大型项目中,开发、测试、调试、部署工具之间共享同一份上下文数据,可以保证各个模块间信息的一致性和连贯性。例如,一个代码生成器可以从 MCP 提取当前任务和历史交互,然后自动生成相应的代码模板。
2、智能提示与任务管理
-
智能补全与提示:利用 MCP 维护的上下文信息(例如最近的代码修改记录、错误日志、任务描述等),开发工具能够在编辑器中为开发者提供更精准的代码补全、错误诊断和调试建议。
-
任务调度与提醒:MCP 服务器管理的任务栈可以被集成到开发环境中,自动提醒开发者当前需要完成的任务或建议下一步行动。比如在 IDE 的侧边栏展示当前任务、历史记录和关联文档,帮助开发者保持专注并有条不紊地推进项目进程。
3、多模块协同开发
-
模块化开发:通过 MCP 协议,各个开发工具可以采用统一的接口来访问和更新上下文数据。这种方式类似于“上下文操作系统”,它将代码、文档、调试信息等拆分为不同模块,便于团队协同工作,减少信息孤岛。
-
自动化工作流:MCP 可以作为一个中央协调者,驱动工具链中的自动化任务。例如,当调试工具检测到某个异常时,可以自动调用文档生成器更新代码文档;或者触发 CI/CD 流程,根据当前上下文信息自动部署最新版本。
4、开发与测试支持
-
快速原型构建:借助 MCP 提供的上下文注入机制,开发者可以快速构建原型工具,例如自动生成测试用例、构建代码片段或执行静态代码分析,所有这些都可以依赖于 MCP 动态构造的上下文数据。
-
历史记录与追踪:在开发工具中集成 MCP 能够记录项目的每一次交互与更新,使得项目演进过程透明化,有助于后续调试、代码审查和团队协作。
5、实际应用场景示例
示例 1:智能 IDE 插件
-
功能:插件利用 MCP 从项目上下文中获取当前开发任务、最近的错误日志和相关代码片段,然后基于这些数据自动生成调试建议或代码补全。
-
工作流程:
-
插件调用 MCP API 获取当前上下文。
-
构建 Prompt 并调用内嵌的 AI 模型(如 Claude 或 GPT)。
-
将生成的建议直接展示在编辑器中。
-
示例 2:自动化测试与部署工具
-
功能:自动收集项目中的测试结果和日志,将这些信息存入 MCP 中,然后根据上下文判断是否触发部署流程。
-
工作流程:
-
测试工具将错误记录和性能指标更新到 MCP 上下文中。
-
部署工具从 MCP 检索相关信息,确定是否满足自动部署的条件。
-
自动化任务引擎根据上下文信息执行下一步操作。
-
5、总结
在开发工具中引入 MCP 能够:
-
提升开发效率:通过结构化的上下文管理和任务调度,开发者可以更快地获取关键信息和提示。
-
实现跨工具协同:统一的上下文数据为不同开发模块和工具之间的信息共享提供了可靠基础。
-
支持智能化功能:依托 AI 模型的上下文增强推理,开发工具能自动生成代码、建议调试方案,并且持续优化开发流程。
这种方式不仅能提高单个开发工具的智能化程度,还能通过 MCP 将整个开发生态系统串联起来,使得团队协作和项目管理更加高效和一致。
六、配置开发工具使用MCP
下面将用一个真实可复现的例子,说明 如何在开发工具(如 VS Code)中配置 MCP(Model Context Protocol)并实际使用它。本例中你将看到:
1、整体目标:
我们将在 VS Code 中构建一个“AI 智能任务辅助插件”,通过 MCP 获取当前开发任务、历史记录、代码片段,并利用 Claude 生成代码建议。
2、MCP 服务端准备
安装并运行 MCP Server
可以选择使用一个轻量级的 Python Flask 实现来快速启动 MCP 服务器:
git clone https://github.com/ContextualComputing/mcp.git
cd mcp
pip install -r requirements.txt
python app.py
此时 MCP 监听在 http://localhost:8000,你可以通过 API 读写:
-
获取当前上下文:
GET /context -
添加任务栈:
POST /task -
添加历史记录:
POST /history -
获取记忆片段:
GET /memory
3、VS Code 中配置 MCP 集成
可以通过以下 2 种方式将 MCP 集成进开发环境:
✅ 方法 1:使用 VS Code 插件 + HTTP 请求(推荐)
安装推荐插件:
-
REST Client 插件:可发送 HTTP 请求到 MCP
-
CodeGPT(或你自制的 Claude 插件):接入 AI 模型,使用 Prompt
示例文件 .vscode/mcp.http:
### 获取当前上下文
GET http://localhost:8000/context### 追加开发任务
POST http://localhost:8000/task
Content-Type: application/json{"task": "实现用户登录功能"
}### 添加历史记录
POST http://localhost:8000/history
Content-Type: application/json{"entry": "已完成数据库连接模块"
}
右键点击 .http 文件里的命令,直接发送请求管理上下文。
✅ 方法 2:通过脚本(Node.js / Python)对接 Claude + MCP
创建脚本 suggest_from_context.py:
import requests
from anthropic import Anthropic# Step 1: 从 MCP 获取上下文
ctx = requests.get("http://localhost:8000/context").json()# Step 2: 构建 Prompt
prompt = f"""
你是开发者助手。当前任务是:{ctx.get('task_stack', [''])[0]}。
历史记录包括:{";".join(ctx.get("history", []))}。
请根据任务,给出代码实现建议。
"""# Step 3: 调用 Claude(或 GPT)
client = Anthropic(api_key="你的API密钥")
resp = client.messages.create(model="claude-3-sonnet-20240229",max_tokens=1024,messages=[{"role": "user", "content": prompt}]
)
print(resp.content[0].text)
然后在 VS Code 里绑定快捷键,或者通过命令面板运行该脚本,即可基于 MCP 上下文获得 AI 建议。
4、使用场景示例
🌟 场景 1:代码智能建议
写到一半的代码不确定函数设计是否合理,点击一个按钮就能让 Claude 基于 MCP 里的“当前任务”和“历史内容”给出建议。
🌟 场景 2:自动任务追踪
当运行调试工具或测试完成时,VS Code 执行脚本将任务进展自动追加进 MCP 的 history,保持任务上下文完整。
🌟 场景 3:多人协作共享上下文
MCP 可以放在局域网服务器上,不同开发者通过插件/脚本共享任务栈、历史记录等,提高团队协同效率。
5、总结
| 步骤 | 内容 |
|---|---|
| ✅ 1 | 启动 MCP 服务器(Python/Flask) |
| ✅ 2 | VS Code 中使用 REST Client 插件或脚本发送请求 |
| ✅ 3 | 调用 Claude / GPT,根据 MCP 上下文生成代码建议 |
| ✅ 4 | 可扩展:自动更新任务、持久化开发记录、团队共享上下文 |