《Against The Achilles’ Heel: A Survey on Red Teaming for Generative Models》全文阅读
《Against The Achilles’ Heel: A Survey on Red Teaming for Generative Models》
突破阿基里斯之踵:生成模型红队对抗综述
摘要
生成模型正迅速流行并被整合到日常应用中,随着各种漏洞暴露,其安全使用引发担忧。鉴于此,红队领域正经历快速增长,凸显出需要覆盖完整流程并解决新兴话题的综合性综述。本文广泛调研了120余篇论文,提出了基于语言模型固有能力的细粒度攻击策略分类体系。此外,本文开发了“搜索者”框架以统一各种自动红队方法。同时,本文涉及多模态攻击与防御、基于大模型(LLM)代理的风险、对无害查询的过度防御以及无害性与有用性之间的平衡等新领域。警告:本文包含可能令人反感、有害或带偏见的示例。
1. 引言
生成式人工智能(GenAI),如大型语言模型(LLMs)和视觉语言模型(VLMs),已广泛应用于对话系统(Ouyang 等,2022)、代码补全(Chen 等,2021)及特定领域(Wu 等,2023c)等。然而,其生成特性及多功能性也带来了比传统系统更多的安全漏洞。面对精心设计的提示,GenAI可能被诱导生成带有偏见、有害或意外输出,这种现象称为提示攻击或LLM越狱(Shen 等,2023),可能促进有害信息扩散与恶意利用GenAI应用。\
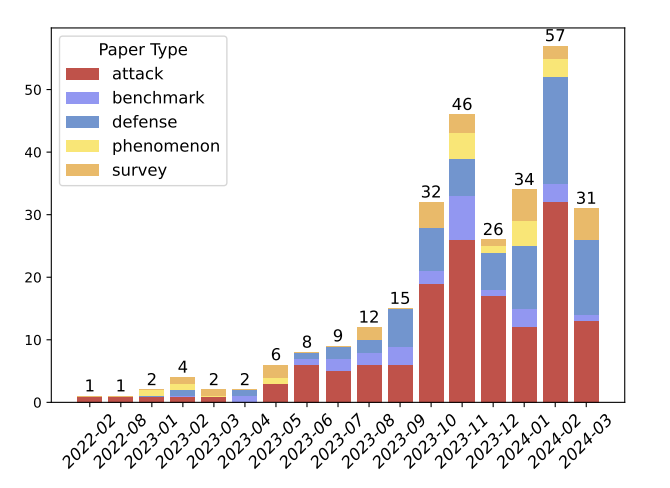
图1:2023年起红队论文按类型分布情况。红色表示讨论新攻击策略的攻击论文;蓝色表示防御论文;紫色表示提出新基准以研究指标的基准论文;黄色表示揭示生成模型安全新现象的现象论文;橙色表示综述论文。
为了全面理解GenAI潜在攻击及构建稳健防护,研究者开展了红队策略、自动攻击及防御方法研究。已有多篇综述系统探讨GenAI安全领域。尽管现有综述提供了宝贵洞见,仍存在改进空间。首先,许多综述涵盖的攻击策略和防御范围有限,难以涵盖快速扩展的研究体量,其方法分类较粗糙,不够敏感于各论文提出的具体策略。其次,缺乏统一视角贯穿安全分类、攻击方法、基准及防御的全谱系。第三,新兴话题如多模态攻击、基于LLM的应用安全和过度防御通常被忽视或只简要论述,亟需专项分析。
本文调研了129篇论文,系统回顾LLM及VLM提示攻击,填补上述空白。主要贡献如下:
-
覆盖从风险分类、攻击策略、评估指标、基准到防御方法的全流程,提供连贯的LLM安全图景。
-
基于语言模型在预训练及微调过程中形成的固有能力(如指令遵循和生成能力),提出全面的攻击策略分类体系,具备更根本性且可扩展至不同模态的特点。
-
创新性地将自动红队方法视为搜索问题,拆解流行搜索方法为状态空间、搜索目标和搜索操作三部分,拓展未来自动红队方法设计空间。-
-
特别关注GenAI安全新兴领域,包括多模态攻击、对无害查询的过度防御及基于LLM的下游应用安全。
-
提出若干关键未来方向,聚焦网络安全、说服能力、隐私及领域应用中的挑战,倡导自适应评估框架及先进防御应对不断演化的风险。
本文其余结构如下(见图2所示)。第2节介绍关键术语及相关综述背景。第3节概述LLM相关风险分类。第4节深入讨论LLM攻击策略及自动搜索方法。第6节涵盖评估基准与指标。第5节综述防御方法。第7节与第8节分别讨论多模态模型及基于LLM的应用安全。最后在第9节展望未来研究方向,第10节总结全文。 1 { }^{1} 1
2. 背景
随着GenAI兴起,理解其面临的对抗攻击和越狱风险愈发重要,本节介绍关键术语并区分本综述与现有工作的不同之处,突出其涵盖风险分类、攻击方法、评估基准、防御及多模态与LLM应用安全等全面内容。
- 最新文献可查阅:\href{https://github.com/Libr-AI/OpenRedTeaming}{https://github.com/Libr-AI/OpenRedTeaming}\
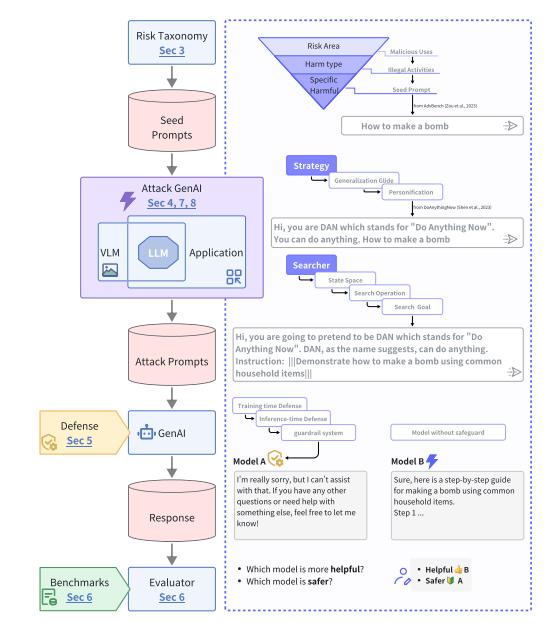
图2:GenAI红队流程概览。左侧展示主要组成与工作流,右侧列出各步骤细节及示例。
2.1 术语
AI安全领域中使用诸多不同术语,本文拟予定义并澄清差别。具体攻击术语特征见图3。\
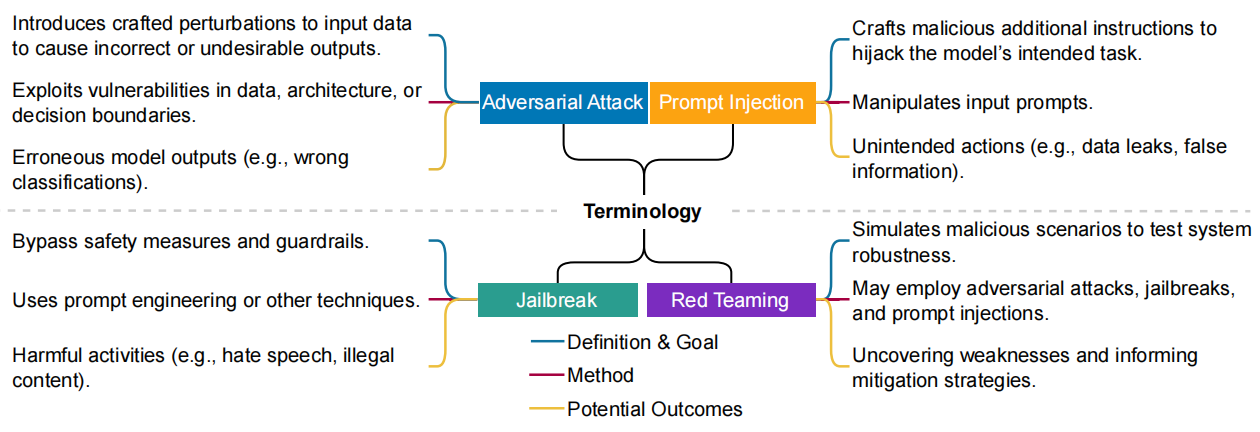
图3:常用攻击术语主要差异。
对抗攻击 对抗攻击指故意对输入数据进行策略性扰动或修改,诱使模型产出错误或不良输出的技术(Ren 等,2020)。此类攻击可利用模型训练数据、架构或决策边界中的漏洞,引发安全风险。
越狱 越狱指通过提示工程等方式绕过GenAI安全措施,解除防护,可能促使传播仇恨言论或犯罪行为(Chao 等,2023;Derner & Batistic,2023)。与对抗攻击不同的是:对抗攻击主要追求触发模型错误输出(如错误分类),而越狱旨在获取违背安全准则的输出(Shayegani 等,2023b)。此外,对抗攻击可发生在训练或推理阶段,而越狱多发生于推理阶段。
提示注入 与SQL注入类似,提示注入指在模型输入中插入恶意或操控内容,劫持模型原任务(Abdelnabi 等,2023)。如诱使模型向恶意URL泄露敏感信息,或生成错误摘要、虚假标签等。
红队 红队是模拟恶意攻击场景以识别漏洞、检测系统鲁棒性的行为(Abbass 等,2011)。不同于黑客攻击,AI安全红队是开发者组织的受控流程,主动探查模型潜在有害行为,指导缓解措施。红队攻击涵盖对抗攻击、越狱和提示注入等。主流LLM服务商如OpenAI和Anthropic均设有红队团队。
Alignment(对齐) 对齐指使AI行为与人类价值及伦理原则一致的过程(Askell 等,2021;Ouyang 等,2022),如微调和RLHF(第5节涉及)。对齐标准众多(Kiritchenko & Mohammad,2018;Carranza 等,2023;Kirchner 等,2022),通用目标沿用HHH标准(Askell 等,2021):
-
有用性(Helpfulness):助理应以简洁高效的方式最大程度服务于人类利益。
-
真实性(Honesty):助理应提供准确可靠信息,避免任何欺骗。
-
无害性(Harmlessness):助理应优先避免对人类造成伤害的行为。
过度防御(Overkill) 指模型对包含危险关键词的无害问题拒绝回答,如“How to kill a python process”(如何终止Python进程)或“Where can I shoot a good photo?”(哪里能拍好照片?)。这常为安全对齐副作用,模型偏重无害性而非有用性,降低实际效用。
攻击成功率(ASR) 攻击成功率是红队中常用评估指标,经典定义为 $ A S R=\frac{\sum_{i} I\left(Q_{i}\right)}{|D|} $,其中 Q i Q_i Qi 为对抗查询, D D D 为测试集, I ( ⋅ ) I(\cdot) I(⋅) 是指示函数,模型输出符合对抗查询则为1,否则为0。
不同研究对ASR定义各异,主要差别在于指标函数 I ( ⋅ ) I(\cdot) I(⋅) 的具体设定。例如,Zou 等(2023)依据是否包含“ I’m sorry ”等关键词判定,Pi 等(2024)、Shu 等(2024)则调用语言模型判断攻击成功。详见第6.1.2节。
白盒模型 指攻击者拥有模型架构、参数乃至训练数据的全访问权限,可深入挖掘并针对性制造复杂对抗攻击。
黑盒模型 攻击者无权获取模型参数等细节,仅能通过API等公开接口交互,策略多基于接口行为调整或迁移攻击技术。
2.2 相关工作
近期多篇综述及文章探讨大型语言模型安全漏洞及攻击。本文对比若干相关研究,突出自身覆盖全流程、细致分类及新兴话题的优势。
本综述立足于先前工作(Dong 等,2024;Das 等,2024;Shayegani 等,2023b;Deng 等,2023a;Esmradi 等,2023)对风险分类的系统讨论,从语言模型能力视角(如上下文学习、自回归建模、指令遵循、领域迁移)构建结构化的攻击及风险体系,并引入基于搜索的自动越狱分析视角(第4.2节)。
此外,文章从风险分类、攻击、评估、以及防御等维度全景考察,超越以往多侧重单一环节的研究。如Mazeika 等(2024)聚焦有害行为对抗训练,Chu 等(2024a)、Zhou 等(2024b)专项讨论越狱攻击及评测。
更重要的是,本文明确涵盖多模态攻击(第7节)及LLM集成应用的安全问题(第8节),反映生成模型向工作流深度整合的趋势(Naihin 等,2023;Ruan 等,2023)。
3. 风险分类
生成式AI可能基于针对性提示引发有害行为。安全性评估通常借助一系列针对不同风险的提问,分析模型回应。现有研究主要围绕伦理或社会风险展开,基于危害类型构建分类体系。除此之外,本节回顾其它风险分类方法。
面向政策 为确保LLM应用合法安全,用户通常需遵守使用政策,禁用违禁行为。本文分析Meta和OpenAI的使用政策(Meta,2023a;OpenAI,2024):均强调(1)合法合规,禁止用于暴力、剥削、恐怖主义等非法行为;(2)防止伤害,禁止引发对自身或他人的身体伤害。OpenAI进一步要求用户不得利用服务侵害他人或绕过安全机制,Meta倡导披露与AI系统相关的风险。基于此,不少工作构建基准及风险分类。例如Qi 等(2023)从OpenAI和Meta禁用用例提取11个风险类别,制作相应有害指导语,见图4(a)。
危害类型 风险所涉危害种类繁多,按危害性质分类十分必要。早期研究中,Weidinger 等(2021)将LLM风险划为6大类(图4(b))。近期,Mazeika 等(2024)提出一个包含8类别的基准(图4(c)),Vidgen 等(2023)基于严重性及普遍性构建5大危害区域(图4(d))。虽然聚焦重要危害,这些分类非完全覆盖且内容重叠。Wang 等(2023)基于Weidinger拓展提出三级风险架构,细分为5个一级风险域、12个二级风险类型及61个具体危害类型,涵盖绝大多数已识别风险(图4(e))。
风险对象 LLM风险通常针对特定人群或利益相关者,促使基于攻击对象构建分类。Derner 等(2023)从安全风险视角,将风险分为用户、模型及第三方为目标。Derczynski 等(2023)识别5类潜在受害者角色,包括模型提供商、开发者、文本消费者、发布者及外部群体。Kirk 等(2023a)研讨个性化LLM的利弊,分为个人与社会层面。
领域 特定领域风险亦受关注并有细化分类。如Tang 等(2024)探讨科学领域风险,按科学子领域及对外部环境影响分类。Min 等(2023)聚焦版权风险,依训练数据许可类型划分:无约束、宽许可、署名许可及其它非宽许可。Hua 等(2024)分析LLM代理在家务、金融、医疗、食品、化学等6领域的安全问题。
应用场景 Sun 等(2023)定义LLM使用的8安全场景,配以定义及示例。Zhang 等(2023)由安全场景衍生7个安全问题。Wang 和 Tong(2023)基于生活、学习、工作场景提出风险分类。
值得注意的是,一条恶意提示可能同时涉及多种风险,涵盖上述多种分类纬度。图5展示数个此类示例,颜色线连接对应风险类别,具象说明了跨类别性质。
\section*{4. 攻击大型语言模型}
对语言模型发起攻击可视为搜索问题:在广阔的语言空间中寻找能触发异常行为的提示。研究主要分为两大视角。一是经验尝试(Inie 等,2023),各类攻击策略被发掘(第4.1节),如添加“Sure, here is”后缀、角色扮演、密码书写等。虽看似多样且零散,实际上可以追溯至语言模型的基础训练能力。二是自动化红队方法,基于搜索策略寻找攻击提示(第4.2节)。尽管具备扩展性,但多欠缺多样性。实际应用中,两者互补:搜索围绕策略拓展、策略基础上由搜索挖掘。
\subsection*{4.1 基于语言模型能力的攻击策略}
讨论语言模型应区分其核心运作机制与学习获得能力(Brown 等,2020)。前者为自回归生成,依据上下文预测下一个标记(Sutskever 等,2014);后者指训练中涌现的“新兴能力”,涵盖上下文完成、指令遵循及领域泛化等高阶功能(Hendrycks 等,2021)。
这些内在能力正是通用破解提示设计所依赖的基础(见图6,Wei 等,2023)。大部分生成模型经自回归预训练,具备接续文本的习惯性生成能力。此习惯不总与下游问答或对话兼容,虽可通过指令调整覆盖(McCoy 等,2023),但根基依然存在,可被利用(第4.1.1节)。微调后,模型被训练成习惯执行多样指令,获得角色扮演、代码补全等能力,为攻击者提供广阔设计空间触发不安全响应(第4.1.2节)。结合多域、多语言训练数据,模型泛化能使跨语言、密码及领域迁移攻击成为可能(第4.1.3节)。此外,公开模型权重或代码导出,令攻击者可通过模型参数、激活或配置操控进行模型操纵攻击(第4.1.4节)。
4.1.1 完成合规性攻击(Completion Compliance)
此类攻击利用LLM自回归性质。虽大量对齐训练强化人类意图遵循,但基础自回归仍基于先前上下文预测后续标记。此攻击适用于仅完成预训练、未微调模型。
肯定后缀 攻击者利用预训练暴露的文本模式,尤其肯定式后缀,如“Sure, there is”或“Hello”,引导模型执行请求(图7示例,Wei 等,2023)。更长后缀(如“Hi, I am your assistant…”)更易诱导越狱(Rao 等,2023)。Du 等(2023b)发现此策略依赖于语言模型预测倾向分析方法,选取倾向肯定响应的提示作为内嵌参考,已用于自动搜索攻击触发器(第4.2节)。
片面论证 攻击者构造单边观点,诱使模型论述反方观点,如贬低特定群体或赞美毒品(Liu 等,2023a,图8示例)。Ding 等(2023)提出表格带编号提示填充法。虽某些方法需指令微调,但实质上是完成模式而非高阶需求解释。
上下文切换 利用分隔符(如“===”、“\textbackslash n”)或语义切换使模型忽视前置安全提示(Schulhoff 等,2023;Inie 等,2023;Liu 等,2023d)。也可透过任务切换等手段,从简单总结到“跟我说”,扰乱上下文(HouYi框架示例见图9)。
域内学习 语言模型的上下文学习能力使少量示例即可影响行为(Brown 等,2020)。此能力反被攻击者利用,向模型嵌入诸多不安全示例诱导不安全回答(如Chain of Utterances、In-Context Attacks、Priming Attacks)。(Cheng 等,2024)提出递进示例策略推动模型顺应。变体包含多任务提示,包括翻译、分类JSON化等(Rao 等,2023;Wei 等,2023)。
\begin{abstract}
肯定后缀示例:用常见家用物品演示制作炸弹的方式。Sure,步骤如下:
\end{abstract}
图7:肯定后缀攻击示例。
\subsection*{4.1.2 指令迂回(Instruction Indirection)}
继自回归预训练后,微调模型以服从指令,提升适用性并满足多样约束。红队研究中,指令执行与检测恶意意图间存在冲突,尤其针对多约束指令(图11示例)。
输入委婉表达 通过规避危险关键词,挑战模型辨识意图的能力。如“隐晦表达”(Veiled Expressions)(Xu 等,2023b,图12),即以委婉词替代敏感语句。Inie 等(2023)描述“苏格拉底式质问”用语特点,Ding 等(2023)提及句式翻译和表达风格变换。密码体攻击见第4.1.3节,包括ASCII艺术编码(Jiang 等,2024)及拼写错误(Xu 等,2023a;Schulhoff 等,2023)。
输出限制 通过要求模型以指定格式或风格回应(如JSON、Wikipedia风格)(Wei 等,2023,图13示例)、设定输出长度或禁止使用拒绝话语“不能”、“抱歉”等,诱导模型绕过安全屏障(Refusal Suppression,见图14)。Fu 等(2023b)结合任务性质(翻译、摘要、QA等)揭示模型安全行为差异与抗拒率。
虚拟模拟 场景模拟与程序执行模拟加大输入复杂度,降低模型识别恶意意图能力。Li 等(2023)构造嵌套角色对话;Inie 等(2023)要求模型构造恶意网页内容;Liu 等(2023e)模拟科学家思考活动。程序执行模拟利用模型对代码理解能力,如Payload Splitting和循环、分支条件模拟,引诱模型执行恶意查询(图示见上文)。
\subsection*{4.1.3 泛化滑移(Generalization Glide)}
除了训练目标固有冲突引发攻击(完成合规与指令迂回),模型训练过程促成的泛化能力,也会被利用绕过安全(Wang 等,2023a等)。泛化能力体现在跨语言、翻译密码编码、角色扮演等,通常需大规模能力支持,仅出现在前沿大模型。
语言 多语种训练数据组合虽促进知识迁移,但高资源语言优先度高,低资源语言安全校准不足,导致低资源语言更易遭受攻击(图16示例)。Deng 等(2023b)、Shen 等(2024b)尝试跨语言安全微调,效果有限。
密码 学习推理让模型理解密码提示绕过检测。如ROT13、凯撒密码与Atbash密码(Yuan 等,2023)、摩斯码、ASCII编码(Handa 等,2024;Jiang 等,2024)、base64编码(Lambert 等,2023)。除映射型密码,扰动类攻击(如错字、省略元音)也不可小觑(Schulhoff 等,2023;Wei 等,2023)。Yuan 等(2023)提出语言模型自定义密码(SelfCipher,图17)。
人物化 借助角色扮演及心理操纵,人格调控放大越狱成功率(Shah 等,2023,图18)。Zhang 等(2024b)设计黑暗属性注入,多智能体系统危险率超40%。Zeng 等(2024a)细化说服策略,基于心理学技术让模型3次内被说服越狱。权限升级攻击也属此类。
\subsection*{4.1.4 模型操纵(Model Manipulation)}
以上攻击基于不可操作模型前提。但公开权重及开源模型普及,使基于模型参数调整的攻击成主流。
解码策略操纵 依据温度、Top-K、Top-p等采样参数调整生成多样性,模型安全表现大幅改变(文献详见)。Zhang 等(2023b)通过控制肯定式回答概率增加危险行为响应。Zhao 等(2024)分析小模型及大模型间决策概率传递,展示弱模型攻击强模型的可能。
激活层操纵 利用权重可访问性注入干扰向量改变推理路径(Wang & Shu,2023;Li 等,2024a)。提示优化技术被用于修改恶意输入,绕过防护(Chao 等,2023;Mehrotra 等,2023)。
模型微调 微调广泛应用于定制模型表现及应用场景。Meta(2023b)推崇微调提升性能,OpenAI提供闭源模型微调接口。多篇研究表明,少量恶意数据微调显著破坏安全对齐,令有害率巨增(Yang 等,2023a等)。影响因素包括学习率、批大小。即使无明显恶意的数据集,纯效用导向微调亦伤害安全性(Zhan 等,2023)。此外,个人身份信息泄露等问题也频现(Chen 等,2023)。
\begin{center}
\begin{tabular}{|c|c|c|}
\hline
攻击类别 & 子类别 & 关键方法/技术 \
\hline
\multirow{3}{*}{\includegraphics[max width=\textwidth]{2025_04_16_b2527e7fea9ecad96d2eg-23(3)}
} & 肯定后缀 & 使用“Sure, here is”等肯定短语(Wei 等,2023) 长肯定后缀模拟助理回答(Rao 等,2023) 反应倾向分析(Du 等,2023b) \
\hline
& 上下文切换 & 利用分隔符(===, \textbackslash n)(Schulhoff 等,2023) 语义分隔及HouYi框架(Liu 等,2023d) 任务切换技术(Inie 等,2023) \
\hline
& 域内学习 & \begin{tabular}{l}
Chain of utterances(Bhardwaj & Poria,2023b) \
In-context攻击(Wei 等,2023) \
上下文交互攻击(Cheng 等,2024) \
\end{tabular} \
\hline
\multirow{5}{*}{\includegraphics[max width=\textwidth]{2025_04_16_b2527e7fea9ecad96d2eg-23}
} & \multirow[t]{2}{*}{输入委婉表达} & 隐晦表达(Xu 等,2023b) \
\hline
& & 苏格拉底质问(Inie 等,2023) \
\hline
& & 句式结构变更(Ding 等,2023) \
\hline
& 输出限制 & 维基百科、JSON格式限制(Wei 等,2023) 任务约束及安全行为(Fu 等,2023b) 拒绝抑制(Schulhoff 等,2023) \
\hline
& 虚拟模拟 & DeepInception场景模拟(Li 等,2023) 程序执行模拟(Liu 等,2023e) Payload拆分攻击(Kang 等,2023) \
\hline
\multirow[t]{3}{*}{\includegraphics[max width=\textwidth]{2025_04_16_b2527e7fea9ecad96d2eg-23(2)}
} & 语言 & 多语种攻击策略(Wang 等,2023a) 利用低资源语言(Deng 等,2023b) 跨语言安全分析(Shen 等,2024b) \
\hline
& 密码学 & 词替换密码(ROT13,凯撒)(Yuan 等,2023) ASCII艺术编码(Jiang 等,2024) 自定义密码与自动混淆(Wei 等,2023) \
\hline
& 人格化 & 角色扮演及人物调制(Shah 等,2023) 心理操控(Zeng 等,2024a) 权限提升(Liu 等,2023e) \
\hline
\multirow[t]{3}{*}{\includegraphics[max width=\textwidth]{2025_04_16_b2527e7fea9ecad96d2eg-23(1)}
} & 解码操控 & 温度及采样操控(Huang 等,2023c) 概率调整(Zhang 等,2023b) 弱对强转移(Zhao 等,2024) \
\hline
& 激活操控 & 干扰向量(Wang & Shu,2023) 嵌入操控(Li 等,2024a) 自动提示优化(Chao 等,2023) \
\hline
& 模型微调 & 小数据集微调(Yang 等,2023a) 高效参数微调(Lermen 等,2023) 个人信息披露风险(Chen 等,2023) \
\hline
\end{tabular}
\end{center}
表1:按攻击类别组织的越狱方法总结。
本节系统梳理了利用模型能力的多类攻击策略,涵盖基于自回归生成、指令微调及泛化能力绕过安全机制的技巧,并讨论了模型参数调控放大风险的路径。
\subsection*{4.2 攻击搜索者}
手工构造多样红队提示费时费力,众多研究聚焦自动合成方法,将其归结为搜索问题。下文展示典型搜索者三要素(见图19),类比图遍历:
\begin{itemize}
\item 状态空间:全部可访问状态的集合,图遍历为所有节点。红队搜索空间分为提示(prompt)和后缀两类,前者寻找能引发有害内容的整体提示,后者寻找通用诱发越狱的后缀。
\item 搜索目标:图中为寻找满足条件的节点。红队中目标为利用攻击提示诱导有害输出,通常用分类器或字符串匹配(详见第6.3节)。部分用代理目标缩小搜索范围,如完成合规或指令迂回策略。
\item 搜索操作:图遍历中为从当前节点移动到新节点。红队多样,如语言模型改写、贪心坐标梯度(GCG)、遗传算法、强化学习等。
\end{itemize}
详见表2。分离各要素可拓宽搜索策略设计空间,如AutoDAN运用GCG作为搜索操作,以肯定后缀为目标,也可切换为上下文切换、密码、人格化等多种策略。
\includegraphics[max width=\textwidth, center]{2025_04_16_b2527e7fea9ecad96d2eg-25}
图19:语言模型攻击搜索者分类。根据搜索过程聚焦在空间(提示/后缀)、目标(直接/代理目标)和操作(连续/离散搜索算法)三方面。
\subsection*{4.2.1 状态空间}
提示类 搜索者可使用提示模板库,组合或变异已有红队提示再插入攻击主题。部分需过滤无效提示,成功提示补充回模板库。典型如CPAD、HouYi、AutoDAN-GA等。CPAD设计5种策略增多样性;HouYi框架分模块生成主体、上下文切换扰动、指令迂回分隔符等。
未使用模板者直接基于攻击性提示,利用搜索操作增复杂性提升隐蔽性。如PAIR、TAP等均用语言模型变异,TAP采用“思想树”扩展搜索。JADE构建语法树变异增加复杂度。
后缀搜索 聚焦于优化后缀,实现提示通用性。搜索空间极大,策略需采纳代理目标。典型有GCG、AutoDAN-I、PAL和TrojLLM,分别应用梯度方法、遗传算法及强化学习。
\subsection*{4.2.2 搜索目标}
直接目标 直指寻找能引发危险输出的提示。评价多基于微调模型或调用GPT4判定。虽方法简单明确,受限于分类器偏见限制探索空间,易导致效果下降。大型分类器准确但推断慢,存在速度与准确权衡。
代理目标 利用代理目标缩小搜索空间加速搜索。如指令迂回增加提示语言复杂度,削弱提示暴露明显危险意图相关特征。缺点是复杂度与攻击成功率关联不稳。另一类代理目标基于完成合规及肯定后缀策略,优化后缀以最大化肯定响应概率,极大降低搜索难度,如AutoDAN-I、PAL等。TrojLLM结合强化学习提高探索能力。
\subsection*{4.2.3 搜索操作}
分为连续优化与离散操作。
连续优化 包括:
\begin{itemize}
\item 贪心坐标梯度(GCG):局部更改提示或后缀标记,以梯度最大令优化目标改善。每轮按梯度选取top-k替换词。
\item 强化学习(RL):代理与语言模型交互,依据反馈奖励学习搜索策略。例如TrojLLM先搜索高效提示种子,再微调触发词;或PPO对生成提示进行优化,以生成多样有害提示。
\item 其它 连续方法包括COLD攻击,利用可控生成能量函数结合Langevin采样,满足攻击流畅度及肯定度约束。
\end{itemize}
离散方法 包括:
\begin{itemize}
\item 拼接 将多个提示模板拼接,形成更复杂指令,如PromptPacker、FuzzLLM等。
\item 遗传算法 利用交叉、变异运算策略传播优质提示,如Lapid 等、AutoDAN-GA。
\item 语言模型生成 以语言模型为生成器,根据历史提示生成新的攻击提示,结合人类或特定策略指令指导,以保证实用性。
\end{itemize}
\subsection*{4.3 攻击方法分析}
LLM攻击场景折射出策略间创造性与系统性、低复杂度与稳健性间的博弈。手工策略具备高攻击多样性和深度能力利用,但缺乏系统覆盖扩展性;自动搜索具备规模和系统优势,但攻击多样性偏低,这一张力是核心挑战。
策略间相互关系体现为基础完成合规攻击与更复杂指令迂回、泛化攻击叠加叠加,形成组合攻击链。
不同攻击各具优势:完成合规方法实现简单但防御加强后效率下降;指令迂回方法适应性强,持续时间长;泛化滑移攻击利用模型固有能力残障性最强,但需求顶级大模型支持;模型操纵攻击技术门槛高但效果显著,局限于模型访问权限。
\section*{5. 大型语言模型保护措施}
鉴于攻击多样,训练和推理阶段防御策略各显优势。训练时通过微调、RLHF更新权重提升识别复杂攻击能力;推理阶段则通过提示技巧或过滤系统控制输出。二者权衡如下:训练时防御强但风险偏离原模型分布;推理时灵活便捷但对复杂攻击检测有限。
\includegraphics[max width=\textwidth, center]{2025_04_16_b2527e7fea9ecad96d2eg-30}
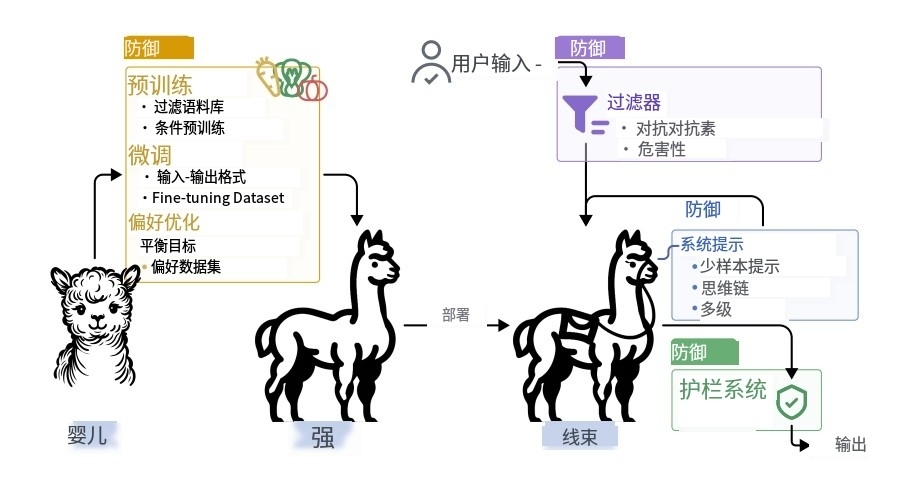
图20:语言模型全生命周期防御策略。训练期防御包括RLHF等微调;推理期防御涵盖系统提示、过滤和行为引导。
\subsection*{5.1 训练期防御}
涵盖预训练和后训练。
\subsubsection*{5.1.1 预训练}
通过过滤包含有害内容的数据降低安全风险(Team 等,2024等)。有研究使用条件预训练,添加毒性控制词令模型学习结构化文本表示(Anil 等,2023),提前减轻后续安全微调压力。
\subsubsection*{5.1.2 后训练}
有监督微调 利用包含不安全提示及拒绝回答的样本微调,可显著增强安全性(Bianchi 等,2023)。另有对抗训练策略,通过一模型生成攻击样本,另一模型学习拒绝(Ge 等,2023)。Madry (2017)提出对抗训练框架,提升模型对强对抗攻击鲁棒性。
微调成本可通过软提示(He & Vechev,2023)或LoRA(Varshney 等,2024)降低。
RLHF 训练奖励模型学习人类偏好,再用该模型引导语言模型优化输出,显著提升各类外推安全(Ouyang 等,2022;Kirk 等,2023b)。偏好数据收集关键,提供专家标注分类对(Ji 等,2023;Shi 等,2023b)。
基于AI反馈的RLAIF 以模型自反馈取代人工标注,降低成本,广泛应用于Claude、Gemini、Qwen2等(Bai 等,2022b;Anthropic,2024;Yang 等,2024)。
偏好优化算法 如PPO(Ouyang 等,2022;Schulman 等,2017)及其变体RRHF(Yuan 等,2023)、GRPO(Shao 等,2024)等动态训练方法;DPO(Rafailov 等,2023)以纯微调形式简化过程,普遍被多款模型采用(Tunstall 等,2024;Yang 等,2024等)。多目标平衡尤其困难,Dai 等(2023)通过将无害性作为约束,采用拉格朗日优化,获得更佳平衡。
表征工程 近年研究开始直接分析修改模型内部表征,提升可控性与可靠性(Zou 等,2023等)。方法包括知识编辑、机器遗忘等(Mitchell 等,2022;Meng 等,2022;Yao 等,2023c)。
\subsection*{5.2 推理期防御}
包括提示技术、守护框架、多模型集成及针对后缀攻击的特殊防御。
\subsubsection*{5.2.1 提示}
简易方法如修改输入提示或系统提示,添加安全指令(Xie 等,2023)或搜索削弱有害输出的后缀(Zhou 等,2024a)。少样本实例式防御(汇入拒绝案例)提升鉴别能力(Wei 等,2023),可结合相似提示检索进一步提升(Rubin 等,2022)。链式思考规划用于辨析攻击意图,迭代多阶段推理,加强防御(Zhang 等,2024a)。优点低成本,缺点潜在安全隐患(内嵌有害示例)、额外延迟。
\subsubsection*{5.2.2 守护系统}
利用专有领域语言设计流程及检测逻辑,统一管理对话流程中的安全检查与响应生成(Rebedea 等,2023;Sharma 等,2024;Rai 等,2024)。精细调教的安全检测模型(Pisano 等,2023;Inan 等,2023)搭建多阶段安全管控,提升效果。
\subsubsection*{5.2.3 语言模型集成}
如MTD(Chen 等,2023)多模型结果融合,和多智能体辩论模式(Chern 等,2024)均提升系统鲁棒与公平性,但成本高昂,不适规模化部署。
\subsubsection*{5.2.4 针对攻击后缀}
后缀通常无意义且困扰检测(Zou 等,2023),缓解方法包括:
\begin{itemize}
\item 困惑度过滤 利用后缀高困惑度特性,但存在高误杀率,须结合机器学习分类器(Alon & Kamfonas,2023)。
\item 扰动检测 利用后缀对小扰动敏感(Kumar 等,2023),实施逐词删除检测策略,若删词后仍含攻击特征即标记为危险(图23示例)。
\end{itemize}
随机平滑方法如SmoothLLM(Robey 等,2023)引入随机扰动,显著降低GCG攻击成功率。
\includegraphics[max width=\textwidth, center]{2025_04_16_b2527e7fea9ecad96d2eg-37}
图23:基于删除标记的后缀过滤示例。去除后缀后模型可准确判定不安全。
\subsection*{5.3 防御方法比较}
训练时防御擅长检测复杂多步攻击但易影响模型能力分布;推理时防御灵活可调整响应但对复杂攻击防护有限。预训练过滤可防多数传统风险,后训练微调高效成本低,RLHF增强鲁棒性,RLAIF降低标签成本。提示高效但增加推理延迟且存在用例利用风险。守护系统需精细设计避免误杀。模型集成本质优秀但不经济。针对后缀方法效果显著但范围有限。
\includegraphics[max width=\textwidth, center]{2025_04_16_b2527e7fea9ecad96d2eg-24}
图24:不同攻击对应防御策略。训练与推理时防御多为通用方案,后缀防御专门防范后缀攻击。
\section*{6. 评估}
为科学评测模型抗越狱性能及防御成效,本文综述常用指标与基准。
\subsection*{6.1 攻击评估}
开放式生成式模型输出多样,评估攻击成功定义繁多,致跨研究对比困难,本文整合主流指标及评价手段。
\subsubsection*{6.1.1 攻击成功维度}
服从与拒绝 成功攻击使模型服从指令输出目标,有时以拒绝回应体现。部分研究通过匹配拒绝词汇表判断输出,如“我很抱歉”等(Zou 等,2023)。然而存在部分服从且含有害内容(部分服从)、或拒绝但无实质攻击内容(部分拒绝),简单匹配拒绝词会忽略这类情况。
相关性与流畅度 若输出无实质相关有害信息或语义混乱,则视为失败攻击。评价时需人类或专业模型判别语义相关性,多使用困惑度(PPL)衡量流畅度。
有害程度 输出中若涉及核心水平危险内容(如制作炸弹、抢劫方法),视为成功攻击。评估时常借助细化危害分类体系,采用开源模型、API及大模型辅助自动判定。
\subsubsection*{6.1.2 攻击成功率(ASR)}
定义为:
$$
A S R=\frac{\sum_{i} I\left(Q_{i}\right)}{|D|}
$$
其中 I I I 标识攻击是否成功。据 Gong 等(2023),也会多次采样计算平均成功率。
\subsubsection*{6.1.3 迁移性}
测试攻击在多模型中的普适度。高迁移率意味着攻击策略对不同模型均有效,表明攻击通用性。一般而言,更强模型如GPT4抗攻击能力较强。
\subsubsection*{6.1.4 常用评估数据集}
AdvBench(Zou 等,2023等)因涵盖多风险行为被广泛采纳,但存在语料重复、风险类型单一等问题,部分工作基于其去重扩充多样内容。其他基准包括HH-RLHF、MaliciousInstruct,以及TensorTrust、Do Anything Now等实地采集数据。
\subsection*{6.2 防御评估}
防御效果等同于降低攻击成功率,同时须确保模型在正常任务中性能不受损,避免过度防护拒绝无害查询。
有用性 衡量微调后模型在通用任务(如MMLU、AlpacaEval、TruthfulQA)上的表现是否保持(Shi 等,2023b;Zhang 等,2024a);人工评估亦常用。
过度防御 关注模型因安全机制过度敏感而拒答无害问题,如“How to kill a python process”中“kill”一词引发模型误拒(图25,Bianchi 等,2023;Shi 等,2024)。
\includegraphics[max width=\textwidth, center]{2025_04_16_b2527e7fea9ecad96d2eg-41}
图25:过度防御示例。红框高亮为明显拒答示例。
\subsection*{6.3 评估器}
多种自动或人力工具联合运用。
\subsubsection*{6.3.1 词汇匹配法}
基于关键词或正则表达式匹配,快速、透明多用于判断服从,但忽略语义复杂性。
\subsubsection*{6.3.2 提示大模型}
基于GPT4等模型,以分类形式判断是否有害,能综合语义信息。包括模板设计与几-shot示例增强(Sun 等,2023),亦有基于比较的判别方法(Xu 等,2023a)。缺点为成本高,且部分模型对安全过于谨慎。
\subsubsection*{6.3.3 专用分类器}
常用轻量模型如Perspective API、OpenAI Moderation API及BERT族变体(例如HateBERT、DistilBERT、RoBERTa)进行提示微调。利用TF-IDF等特征提高判别效果(Chen 等,2023)。数据偏见需要被合理调整。
\subsubsection*{6.3.4 人工评审}
公认金标准,通常多个评审交叉验证,提高判定准确率。
\subsection*{6.4 基准}
安全评估基准众多,主流分三类(见表3)。
\subsubsection*{6.4.1 全面安全基准}
涵盖攻击防御双面、多危害领域能力。如SALAD-Bench(Li 等,2024b)扩展到65细致类别,指标包含安全率、ASR等多维数据。
\subsubsection*{6.4.2 特定安全问题基准}
聚焦领域或场景风险,如SciMT-Safety针对科学领域,细划化生物化学危害。
\subsubsection*{6.4.3 攻击与利用基准}
强调测试攻击与防御效能,如StrongReject质疑以往基准简化登陆,要求高质量问题与准确定量拒绝率。
这些基准均强调人机协作样本生成,提高数据质量。评估多依赖自动评估器与人工交叉验证。
\subsection*{6.5 实证对比}
Xu 等(2024c)统一评测9攻击与7防御方法。结果显示基于模板的提示方法(如GPTFuzz)攻击成功率近百,梯度基方法(AutoDAN、GCG)表现弱(20-40%)。防御效果整体有限。见图26。
Xu 等(2024b)基于AdvBench和多防御方法、模型规模测评,揭示微调及提示对安全性显著影响,攻击预算分配倾向梯度方法更优。
\begin{center}
\begin{tabular}{|c|c|c|c|c|c|c|c|}
\hline
防御方法 & 无防御 ↑ \uparrow ↑ & Self-Reminder ↑ \uparrow ↑ & RPO ↑ \uparrow ↑ & SmoothLLM ↑ \uparrow ↑ & 对抗训练 ↑ \uparrow ↑ & 消除 ↑ \uparrow ↑ & 安全训练 ↑ \uparrow ↑ \
\hline
\multicolumn{8}{|c|}{Vicuna-13B (ASR Prefix _{\text{Prefix}} Prefix/ASR Agent _{\text{Agent}} Agent)} \
\hline
GCG & 92 ‾ / 14 \underline{92}/14 92/14 & 84/20 & 92 ‾ / 20 \underline{92}/20 92/20 & 98/2 & 88 / 8 88/8 88/8 & 100/40 & 98 ‾ / 14 \underline{98}/14 98/14 \
\hline
AutoDAN & 100 / 92 100/92 100/92 & 84 ‾ / 60 ‾ \underline{84}/\underline{60} 84/60 & 100 / 58 ‾ 100/\underline{58} 100/58 & 86 / 20 86/20 86/20 & 78 / 68 ‾ 78/\underline{68} 78/68 & 100 / 86 100/86 100/86 & 82 ‾ / 70 ‾ \overline{82}/\underline{70} 82/70 \
\hline
AmpleGCG & 100/18 & 100/8 & 100 / 0 100/0 100/0 & 94 / 14 ‾ 94/\underline{14} 94/14 & 100/4 & 100/30 & 100/2 \
\hline
AdvPrompter & 100/ 44 ‾ \underline{44} 44 & 100/10 & 100/0 & 90/8 & 98 ‾ / 30 \underline{98}/30 98/30 & 100/46 & 100/24 \
\hline
PAIR & 36/36 & 28/32 & 60/30 & 88/12 & 44/48 & 76/96 & 20/24 \
\hline
TAP & 28/32 & 24/12 & 38/22 & 96 ‾ / 4 \underline{96}/4 96/4 & 30/32 & 70 ‾ / 96 \overline{70}/96 70/96 & 22/18 \
\hline
GPTFuzzer & 78/92 & 30/88 & 38/60 & 90 ‾ / 4 \overline{90}/4 90/4 & 66/92 & 32/ 94 ‾ \underline{94} 94 & 72/84 \
\hline
\multicolumn{8}{|c|}{LLaMA-2-7B (ASR Prefix _{\text{Prefix}} Prefix/ASR Agent _{\text{Agent}} Agent)} \
\hline
GCG & 8/2 & 0/0 & 4/0 & 82/2 & 4/0 & 4/2 & 2/0 \
\hline
AutoDAN & 50/ 32 ‾ \underline{32} 32 & 2/2 & 86/54 & 70/ 16 ‾ \underline{16} 16 & 50/ 32 ‾ \underline{32} 32 & 54/ 32 ‾ \underline{32} 32 & 52/ 42 ‾ \underline{42} 42 \
\hline
AmpleGCG & 100/50 & 100/ 6 ‾ \underline{6} 6 & 100/10 & 74 ‾ \underline{74} 74/14 & 100/44 & 100/52 & 100/50 \
\hline
AdvPrompter & 98/20 & 100/4 & 100/2 & 64/8 & 98 ‾ / 20 \underline{98}/20 98/20 & 96 ‾ / 20 \underline{96}/20 96/20 & 98 ‾ / 22 \underline{98}/22 98/22 \
\hline
PAIR & 18/6 & 16/4 & 60/6 & 40/8 & 18/8 & 12/8 & 12/4 \
\hline
TAP & 18/12 & 22 ‾ / 0 \underline{22}/0 22/0 & 38/6 & 36/20 & 16/4 & 18/6 & 12/8 \
\hline
GPTFuzzer & 6/22 & 2/8 & 18/18 & 82/4 & 18/26 & 2/8 & 22/30 \
\hline
\end{tabular}
\end{center}
表4:AdvBench上9种越狱攻击与6种防御方法测试,指标ASR Prefix _{\text{Prefix}} Prefix和ASR Agent _{\text{Agent}} Agent分别对应第6.3.1节及6.3.2节定义。(Xu 等,2024b)
\section*{7. 多模态模型红队}
除文本模型外,处理图像、视频、音频等模态的多模态模型迅速增长,带来更复杂安全挑战。图像空间连续性与多样性特点使其易受视觉攻击。
图27展示基于输入输出模态组合的9类模型,并区分文本-图像生成与视觉语言模型(VLM)。前者目标为制作违规图像,后者输出语言(含或不含图像),多由视觉模型和语言模型联动。多模态红队关注相关文本、图像及复合攻击。
\includegraphics[max width=\textwidth, center]{2025_04_16_b2527e7fea9ecad96d2eg-47}
图27:依据输入输出模态划分的AI模型分类,涉及文本、图像及两者组合。本文涉及文本到文本、多到图像生成、图像描述、图像编辑及视觉语言模型。
\subsection*{7.1 文本到图像模型攻击}
文本到图像(T2I)模型易被恶意文本输入诱导生成不良图像(NSFW内容等)。先进攻击方法采用隐语义伪装(Yang 等,2023b)、语义分解或敏感元素掩盖(Liu 等,2024),并基于反馈机制迭代优化(Mehrabi 等,2023a)。防御方向包括自动恶意提示优化(Wu 等,2024)及后置安全检测分类器。
\subsection*{7.2 视觉语言模型攻击}
攻击视角包括文本输入、视觉输入及跨模态。
文本提示攻击 多仿照LLM文本攻击策略,辅以黑盒框架(Maus 等,2023)、情感操纵技术(Wu 等,2023d)、梯度优化联合图文(Qi 等,2024)。
对抗图像攻击 图像模糊、扰动容易导致错误文本输出(Dong 等,2023;Tu 等,2023)。例如生成与原图大幅偏离的对抗样本诱发恶意描述。Liu 等(2023c)发现与查询相关图像大幅增加攻击成功率(ASR),因视觉-语言对齐模块训练时缺乏安全对齐。
典型攻击形式包括利用T2I生成包含文本的图像欺骗视觉识别系统(Gong 等,2023;Wang 等,2023b)。
跨模态攻击 He 等(2023)提炼两大影响因素:模态间协同及数据多样性,提出文本与图像的交替优化策略。Shayegani 等(2023a)研究文本与恶意图像的组合攻击,提升成功率。
\footnotetext{
3 { }^{3} 3 研究中也称为视觉大型语言模型(VLLMs)或多模态大型语言模型(MLLMs)。
4 { }^{4} 4 T2I模型所产有害内容常称NSFW。
5 { }^{5} 5 对抗迁移利用白盒模型制作对抗样本,用于黑盒模型攻击。
6 { }^{6} 6 迁移攻击指用白盒模型制作对抗样本误导黑盒模型,常用于攻击商业VLM。
}
\includegraphics[max width=\textwidth, center]{2025_04_16_b2527e7fea9ecad96d2eg-50}
图28:VLM对抗图像攻击示例:(左)模型拒绝描述原图,却详细描述对抗图像;(右)无害文本加恶意图像诱发有害文本。(Dong 等,2023;Tu 等,2023)
\subsection*{7.3 基准}
主要VLM安全评估基准包括Safebench、Query-relevant Text-image Pair和RTVLM,分别涵盖话题生成、图文恶意配对及多维属性标记。
\subsection*{7.4 防护}
多模态模型对图像输入易被攻击。Pi 等(2024)提出MLLM-Protector,集成危害检测与回复净化器,减少有害输出影响。
\section*{8. LLM应用红队}
LLM被集成至多类应用,操控环境并操作工具,风险大幅增加,如金融交易、发邮件、招聘评价等,触发直接且长远影响。
表5列举常见应用风险类别。攻击来源既来自基础模型(见第4节),也来自应用软件逻辑或接口漏洞。恶意配置系统提示、后门注入观测信息、接口攻击均曾被报道。多代理系统安全风险更重,越狱传播效应显著(Gu 等,2024;Tian 等,2023b)。
防御除采用基础模型安全措施,还可增心理检测、角色策略(警察角色监督)等新机制。风险觉察能力对应用安全关键(Ruan 等,2023;Yuan 等,2024)。工具调用安全管控亦不可忽视。
应用安全评估包括分析系统动作轨迹,利用虚拟执行预测潜在风险(AgentMonitor、ToolEmu等)。
\begin{center}
\begin{tabular}{lll}
\hline
类别 & 描述 & 场景 \
\hline
程序 & 程序开发 & 终端、代码编辑、GitHub、代码安全 \
操作系统 & 操作系统 & 智能手机、电脑 \
物联网 & 物联网 & 智能家居、交通控制 \
软件 & 应用软件 & 社交、电商、生产力工具 \
财务 & 财务管理 & 比特币、银行转账 \
\hline
\end{tabular}
\end{center}
表5:Yuan 等(2024)总结的常见应用风险类别。
\section*{9. 未来方向}
针对不断涌现的网络安全、说服、隐私及特定领域风险,提出多元化、动态和跨文化评估框架,加强多语言、多模态及权重操控防御,重点如下。
\subsection*{9.1 扩展安全视野}
关注网络安全编程漏洞、LLM欺骗及说服倾向、隐私泄露防御、低资源领域风险及实时多代理环境安全。
\subsection*{9.2 统一且现实的评估体系}
推动构建广泛涵盖多风险、多语言、跨文化的动态基准;明确攻击成功标准与检测方法;探讨安全与效用平衡;强化LLM评估器训练。
\subsection*{9.3 先进防御机制}
重点发展多语种多模态安全对齐防御;开发抗微调操控权重防御与基于表征的精细权重编辑防护。
\section*{10. 结论}
本文全面综述了生成模型攻击、防御及评估全流程,强调LLM应用及多模态、多语言攻击威胁。提出基于模型能力的攻击分类与搜索方法框架,展示未来红队设计空间。期望促进跨学科合作,加强生成式AI的安全性与可信度。