数据蒸馏:Dataset Distillation by Matching Training Trajectories 论文翻译和理解
一、TL;DR
- 数据集蒸馏的任务是合成一个较小的数据集,使得在该合成数据集上训练的模型能够达到在完整数据集上训练的模型相同的测试准确率,号称优于coreset的选择方法
- 本文中,对于给定的网络,我们在蒸馏数据上对其进行几次迭代训练,预先计算并存储在真实数据集上训练的专家网络的训练轨迹,并根据合成训练参数与在真实数据上训练的参数之间的距离来优化蒸馏数据。
- 有一个问题哈,这种蒸馏方法强依赖GT,如果新增数据优化模型,没有GT可能还是只能使用coreset的方法来做
- 我的理解:利用压缩后的最小数据集信息,强行将网络向完整数据集网络的学习方向上诱导/引导,从而达到压缩的目的
二、方法介绍
数据蒸馏的目标是从大型训练数据集中提取知识,将其浓缩到一个非常小的合成训练图像集合中(每个类别低至一张图像),以便在蒸馏数据上训练模型能够获得与在原始数据集上训练相似的测试性能,如下图所示: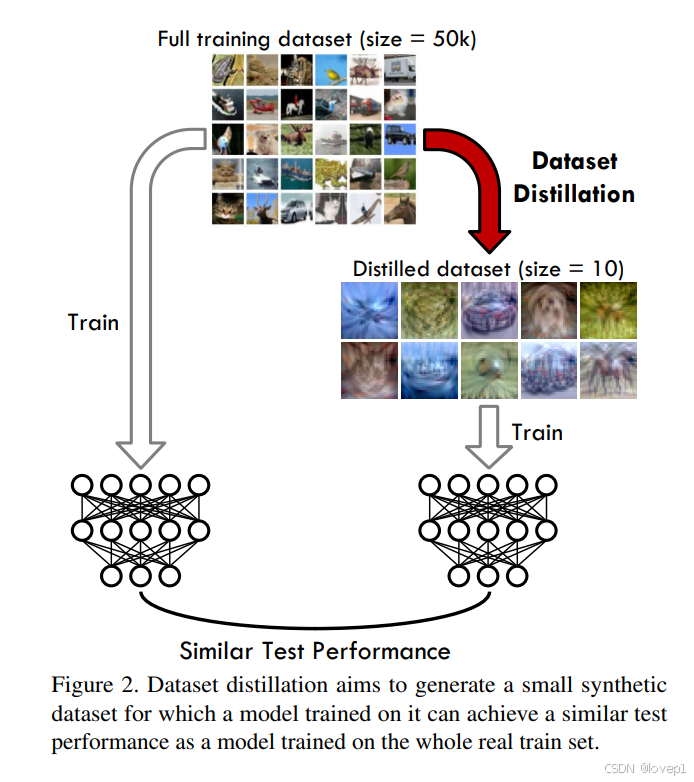
与经典的数据压缩不同,数据集蒸馏旨在保留足够的任务相关的信息,以便在小的合成数据集上训练的模型能够泛化到未见过的测试数据,如图2所示。因此,蒸馏算法必须在大量压缩信息的同时,保留区分性特征。
之前的方法的问题:
- 大多数先前的方法都集中在小型数据集(如MNIST和CIFAR)上,而在真实、更高分辨率的图像上却难以取得进展
- 一些方法考虑了端到端的训练,但往往需要巨大的计算和内存资源,并且存在近似松弛或训练不稳定性的问题
- 另外一些方法专注于短期行为,强制在蒸馏数据上进行单次训练步骤以匹配真实数据上的训练步骤,在评估中可能会累积误差。
在本工作中:
- 提出了一种新的数据集蒸馏方法,不仅在性能上超越了以前的工作,而且适用于大规模数据集,如图1所示。
- 本文方法试图直接模仿在真实数据集上训练的网络的长期训练动态;
- 我们将合成数据上训练的参数轨迹段与从在真实数据上训练的模型记录的专家轨迹段进行匹配,从而避免了短视(即,专注于单个步骤)或难以优化(即,建模完整轨迹)的问题
- 将真实数据集视为引导网络训练动态的黄金标准,我们可以认为诱导的网络参数序列是一个专家轨迹。如果我们的蒸馏数据集能够诱导网络的训练动态遵循这些专家轨迹,那么合成训练的网络将在参数空间中接近于在真实数据上训练的模型,并实现类似的测试性能。

在我们的方法中,我们的损失函数直接鼓励蒸馏数据集引导网络优化沿着类似的轨迹进行(图3)。
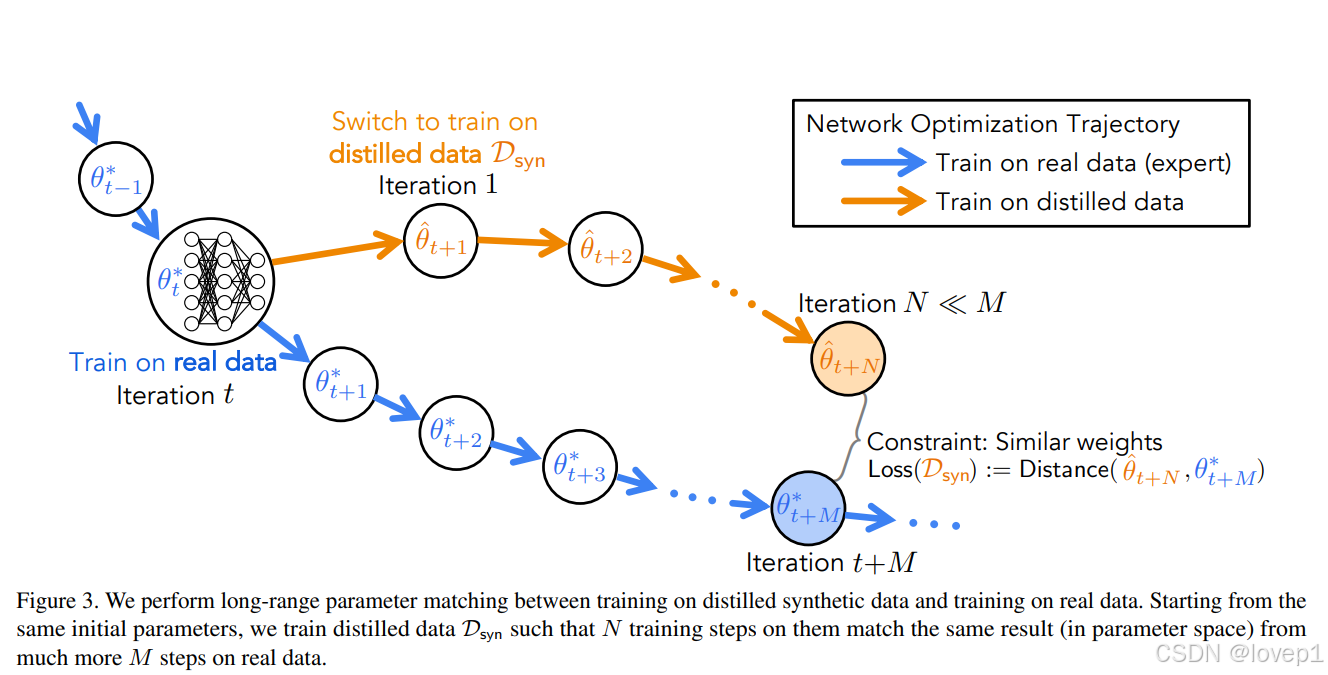
训练流程:
- 从头开始在真实数据集上训练一组模型,并记录它们的专家训练轨迹。
- 从随机选择的专家轨迹中随机选择一个时间步来初始化一个新模型,并在合成数据集上进行几次迭代训练。
- 我们根据这个合成训练的网络与专家轨迹的偏离程度来惩罚蒸馏数据,并通过训练迭代进行反向传播。本质上,我们将许多专家训练轨迹的知识转移到了蒸馏图像上。
实验结果:
- 轻松超越了现有的数据集蒸馏方法以及核心集选择方法,在标准数据集上表现优异,包括CIFAR-10、CIFAR-100和Tiny ImageNet。
- CIFAR-10上,我们使用每个类别一张图像时达到了46.3%,每个类别50张图像时达到了71.5%的准确率
- 首次能够从ImageNet中蒸馏出高128×128分辨率的图像
三、近期工作(直接翻译)
3.1 数据集蒸馏
数据集蒸馏最早由Wang等人[44]提出,他们提出将模型权重表示为蒸馏图像的函数,并使用基于梯度的超参数优化方法对其进行优化[23],这种方法在元学习研究中也得到了广泛应用[8, 27]。随后,通过学习软标签[2, 38]、通过梯度匹配放大学习信号[47]、采用数据增强[45]以及针对无限宽度核极限进行优化[25, 26],一些工作显著提高了结果。数据集蒸馏已经实现了多种应用,包括持续学习[44, 45, 47]、高效的神经架构搜索[45, 47]、联邦学习[11, 37, 50]以及针对图像、文本和医学影像数据的隐私保护机器学习[22, 37]。正如引言中提到的,我们的方法不依赖于单步行为匹配[45, 47]、成本高昂的完整优化轨迹展开[38, 44]或大规模神经切线核计算[25, 26]。相反,我们的方法通过从预训练的专家中转移知识来实现长期轨迹匹配。
与我们的工作同时进行的,Zhao和Bilen[46]的方法完全忽略了优化步骤,而是专注于合成数据和真实数据之间的分布匹配。尽管这种方法由于降低了内存需求而适用于更高分辨率的数据集(例如Tiny ImageNet),但在大多数情况下,其性能表现不如以往的工作(例如,与之前的作品[45, 47]相比)。相比之下,我们的方法在标准基准测试和更高分辨率数据集上同时降低了内存成本,同时超越了现有作品[45, 47]和同时进行的方法[46]。
还有一条相关的研究路线是学习一个生成模型来合成训练数据[24, 36]。然而,这些方法并没有生成一个小尺寸的数据集,因此不能直接与数据集蒸馏方法进行比较。
3.2 模仿学习
模仿学习试图通过观察一系列专家演示来学习一个良好的策略[29, 30, 31]。行为克隆训练学习策略以与专家演示相同的方式行动。一些更复杂的形式涉及使用专家的标记进行在线策略学习[33],而其他方法则完全避免任何标记,例如通过分布匹配[16]。这些方法(特别是行为克隆)已被证明在离线环境中效果良好[9, 12]。我们的方法可以被视为模仿通过在真实数据集上训练获得的一系列专家网络训练轨迹。因此,它可以被视为在优化轨迹上进行模仿学习。
3.3 核心集和实例选择
与数据集蒸馏类似,核心集[1, 4, 13, 34, 41]和实例选择[28]旨在选择整个训练数据集的一个子集,其中在这个小子集上进行训练能够获得良好的性能。这些方法中的大多数并不适用于现代深度学习,但基于双层优化的新公式在持续学习等应用中已经显示出有希望的结果[3]。与核心集相关,其他研究路线旨在了解哪些训练样本对现代机器学习是“有价值的”,包括测量单个样本的准确性[20]和计算误分类率[39]。事实上,数据集蒸馏是这类想法的推广,因为蒸馏数据不需要是真实的,也不需要来自训练集。
四、方法详细介绍
数据集蒸馏指的是策划一个小的、合成的训练集 Dsyn,使得在该合成数据上训练的模型在真实测试集上的表现与在大型真实训练集 Dreal 上训练的模型相似。本文方法直接模仿真实数据训练的长期行为,将蒸馏数据上的多个训练步骤与真实数据上的更多步骤进行匹配。
3.1 专家轨迹
如何获取在真实数据集上训练的网络的专家轨迹?
方法的核心:
- 利用专家轨迹 τ∗ 来指导我们合成数据集的蒸馏。专家轨迹是指在完整的真实数据集上训练神经网络时获得的参数时间序列 {θt∗}0T。
如何生成这些专家轨迹?
- 我们简单地在真实数据集上训练大量网络,每个模型不同epoch组成一条expert trajectory。作者称这些参数序列为“expert trajectory”,因为它们代表了数据集蒸馏任务的理论上限:在完整的真实数据集上训练的网络的性能。
- 同样,我们定义学生参数 θ^t 为在训练步骤 t 时在合成图像上训练的网络参数。我们的目标是蒸馏一个数据集,使其诱导出与真实训练集诱导的轨迹(给定相同的起始点)相似的轨迹,从而使我们最终得到一个类似的模型。
由于这些专家轨迹仅使用真实数据计算,因此我们可以在蒸馏之前预先计算它们。对于给定数据集的所有实验,我们都使用相同的预先计算的专家轨迹集合,这使得蒸馏和实验能够快速进行。
3.2 长期参数匹配
本文方法通过鼓励蒸馏数据集诱导与真实数据集相似的长期网络参数轨迹,从而使得在合成数据上训练的网络表现类似于在真实数据上训练的网络。
我们的蒸馏过程从构成我们expert trajectories中的参数序列 {θt∗}0T 中学习。与以往工作不同,我们的方法直接鼓励我们合成数据集诱导的长期训练动态与在真实数据上训练的网络的动态相匹配。
在每个蒸馏步骤中,我们首先从我们的专家轨迹之一中随机时间步采样参数 θt∗,并用这些参数初始化我们的学生参数 θ^t:=θt∗。在初始化我们的学生网络后,我们接着对合成数据的分类损失进行 N 次梯度下降更新,更新学生参数:
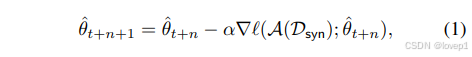
其中A是可微分增强操作,α是个可学习的学习率。然后计算更新后的学生参数和expert trajectory的模型参数的匹配损失,根据权重匹配损失更新我们的蒸馏图像,即更新后学生参数 θ^t+N 与已知未来的专家参数 θt+M∗ 之间的归一化平方 L2 误差:
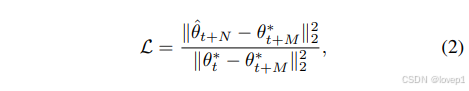
通过将反向传播通过学生网络的所有 N 次更新来最小化这个目标,更新我们蒸馏数据集的像素,以及我们的可训练学习率 α。可训练学习率 α 的优化起到了自动调整学生和专家更新次数(超参数 M 和 N)的作用。我们使用带有动量的随机梯度下降(SGD)来优化 Dsyn 和 α,以达到上述目标。整体如下所示:

3.3 内存限制
本文如何减少内存消耗?
原式是这样进行梯度更新的,由于Dataset太大,因此可以将一式转化为三式
我们可以为学生网络的每次更新(即算法 1 第 10 行的内循环)采样一个新的小批量 b,这样在计算最终权重匹配损失(方程 2)时,所有的蒸馏图像都将被看到。小批量 b 仍然包含来自不同类别的图像,但每个类别的图像数量要少得多。在这种情况下,我们的学生网络更新变为
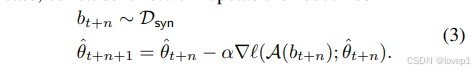
这种分批方法允许我们在确保同一类别蒸馏图像之间存在一定程度的异质性的同时,蒸馏出一个更大的合成数据集。
五、实验
对于 CIFAR-10,这些蒸馏图像可以在图 4 中看到。CIFAR-100 的图像在补充材料中进行了可视化。

如表 1 所示,我们的方法在每种设置中都显著优于所有基线。事实上,在每个类别一张图像的设置中,我们在两个数据集上都将次优方法(DSA [45])的测试准确率几乎提高了一倍。

在表 2 中,我们还与最近的方法 KIP [25, 26] 进行了比较:
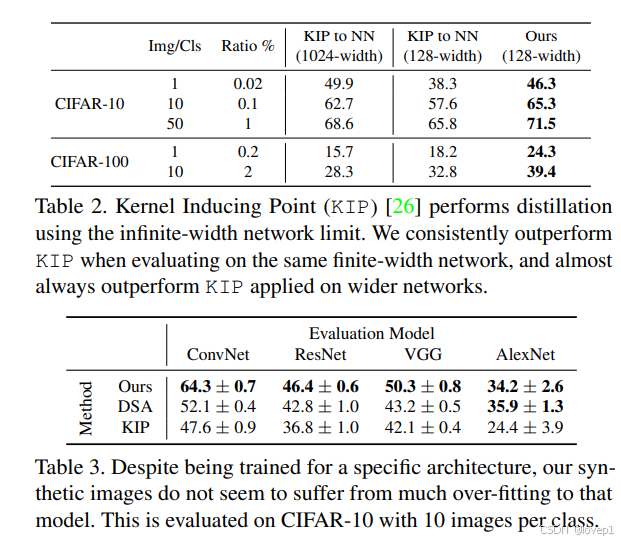
正如之前的方法 [44] 所指出的,我们还发现在合成数据集中允许更多图像时,收益会显著减少。
- 例如,在 CIFAR-10 上,当我们将每个类别的图像数量从 1 增加到 10 时,分类准确率从 46.3% 提高到 65.3%,
- 但当我们将每个类别的蒸馏图像数量从 10 增加到 50 时,仅从 65.3% 提高到 71.5%。
如果我们查看图 4(顶部)中每个类别一张图像的可视化,我们会看到每个类别的非常抽象但仍然可以识别的表示。当我们只允许每个类别有一张合成图像时,优化被迫将尽可能多的类别区分信息压缩到一个样本中。当我们允许更多图像来分散类别的信息时,优化有自由度将类别的区分特征分散到多个样本中,从而产生我们在图 4(底部)中看到的多样化的一组结构化图像(例如,不同类型的汽车和马,具有不同的姿势)。
跨架构泛化。我们还在 CIFAR-10、每个类别一张图像的任务上评估了我们的合成数据在与用于蒸馏它的架构不同的架构上的表现。在表 3 中,我们展示了我们的基线 ConvNet 性能,并在 ResNet 、VGG 和 AlexNet 上进行了评估。

表明我们的方法对架构的变化具有鲁棒性。
4.2 短期匹配与长期匹配
非常短期的匹配(N=1 且 M 较小)通常比长期匹配表现更差,当 N 和 M 都相对较大时,达到最佳性能
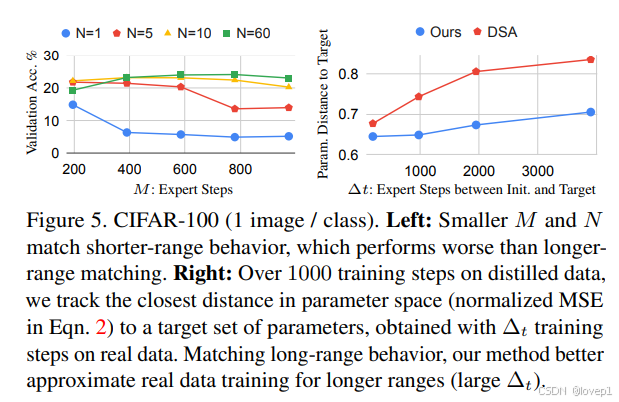
对于这两种方法,我们测试它们使用蒸馏数据从相同的初始参数训练网络到目标参数的接近程度。DSA 仅针对短期行为进行优化,因此在更长时间的训练过程中可能会累积误差。实际上,随着 Δt 变得更大,DSA 在更长距离上无法模仿真实数据的行为。相比之下,我们的方法针对长期匹配进行了优化,因此表现更好。
六、总结
在这项工作中,我们介绍了一种数据集蒸馏算法,通过直接优化合成数据来诱导与真实数据相似的网络训练动态。我们的方法与以往方法的主要区别在于,我们既不受限于短期单步匹配,也不受优化整个训练过程的不稳定性以及计算强度的影响。我们的方法在这两个方面都取得了平衡,并且在这两方面都显示出改进。与以往方法不同,我们的方法首次扩展到128×128的ImageNet图像
局限性。我们使用预先计算的轨迹,虽然节省了大量内存,但以增加磁盘存储和专家模型训练的计算成本为代价。训练和存储专家轨迹的计算开销相当高。例如,CIFAR专家每个epoch大约需要3秒(所有200个CIFAR专家总共需要8个GPU小时),而每个ImageNet(子集)专家每个epoch大约需要11秒(所有100个ImageNet专家总共需要15个GPU小时)。在存储方面,每个CIFAR专家大约占用60MB的存储空间,而每个ImageNet专家大约占用120MB。