MySQL窗口函数学习
视频链接
基本语法
窗口限定一个范围,它可以理解为满足某些条件的记录集合,窗口函数也就是在窗口范围内执行的函数。
基本语法
窗口函数有over关键字,指定函数执行的范围,可分为三部分:分组子句(partition by),排序子句(order by),窗口子句(rows)
<函数名>over(partition by<分组的列>order by<排序的列>rows between <起始行>and <终止行>)
窗口函数适用于在不破坏原有表结构的基础上,新增一列
窗口的确定
分组子句(partition by)
根据分组设定静态窗口的范围。
不分组可以写成partition by null或者直接不写后面可以跟多个列,如 partition by cid,sname
注意 partition by与group by的区别
1)partition by不会压缩行数但是group by会
2)后者只能选取分组的列和聚合的列
也就是说group by 后生成的结果集与原表的行数和列数都不同
排序子句(order by)
不排序可以写成order by nul 或者直接不写asc或不写表示升序,desc表示降序
后面可以跟多个列,如 order by cid,sname
窗口子句(rows)
窗口子句的描述
1)起始行:N preceding/unbounded preceding
2)当前行:current row
3)终止行:N following/unbounded following
举例:
rows between unbounded preceding and current row 从之前所有的行到当前行
rows between 2 precedingand current row 从前面两行到当前行
rows between current row and unbounded following 从当前行到之后所有的行
rows between current row and 1following 从当前行到后面一行
注意:
排序子句后面缺少窗口子句,窗口规范默认是rows between unbounded preceding and current row
排序子句和窗口子句都缺失,窗口规范默认是 rows between unbounded preceding and unbounded following
总体流程
1)通过partition by和 order by 子句确定大窗口(定义出上界unbounded preceding和下界unbounded following)
2) 通过row 子句针对每一行数据确定小窗口(滑动窗口)
3)对每行的小窗口内的数据执行函数并生成新的列
函数的分类
排序类
rank,dense rank,row number
--【排序类】
-- 按班级分组后打上序号不考虑并列
SELECT *, ROW_NUMBER() OVER (PARTITION BY cid ORDER BY score DESC) AS '不可并列排名' FROM SQL_5;-- 按班级分组后作跳跃排名考虑并列
SELECT *, RANK() OVER (PARTITION BY cid ORDER BY score DESC) AS '跳跃可并列排名' FROM SQL_5;-- 按班级分组后作连续排名考虑并列
SELECT *, DENSE_RANK() OVER (PARTITION BY cid ORDER BY score DESC) AS '连续可并列排名' FROM SQL_5;-- 合并起来对比
SELECT *,ROW_NUMBER() OVER (PARTITION BY cid ORDER BY score DESC) AS '不可并列排名',RANK() OVER (PARTITION BY cid ORDER BY score DESC) AS '跳跃可并列排名',DENSE_RANK() OVER (PARTITION BY cid ORDER BY score DESC) AS '连续可并列排名'
FROM SQL_5;
聚合类
sum, avg, count, max, min
--【聚合类】
-- 让同一班级每个学生都知道班级总分是多少
SELECT *, SUM(score) OVER (PARTITION BY cid) AS '班级总分' FROM SQL_5;
-- 或者可以写成
SELECT *, SUM(score) OVER (PARTITION BY cid ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS '班级总分' FROM SQL_5;-- 计算同一班级,每个同学和比他分数低的同学的累计总分是多少
SELECT *, SUM(score) OVER (PARTITION BY cid ORDER BY score) AS '累加分数' FROM SQL_5;
-- 或者可以写成其中rows between ... and 是规定窗口大小
SELECT *, SUM(score) OVER (PARTITION BY cid ORDER BY score ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS '班级总分' FROM SQL_5;
跨行类
lag, lead
-- lag/lead 函数参数说明:
参数1:比较的列
参数2:偏移量
参数3:找不到的默认值-- 同一班级内,成绩比自己低一名的分数是多少
select *, lag(score, 1) over (partition by cid order by score) as '低一名的分数' from SQL_5;
-- 或者写成
select *, lag(score, 1, 0) over(partition by cid order by score) as '低一名的分数' from SQL_5;
-- 向后查询:班级内,成绩比自己高2名的分数是多少
select *, lead(score, 2) over(partition by cid order by score) as '高两名的分数' from SQL_5;
具体问题
分组内TopN查询解决方案
问题1:求出每个学生成绩最高的三条记录
(基于 groupby + order by 实现)
SELECT * FROM (SELECT *,ROW_NUMBER() OVER (PARTITION BY sname ORDER BY score DESC) AS rn FROM SQL_6
) AS temp
WHERE rn <= 3;
问题2:找出每门课程成绩都高于班级课程平均分的学生
- 先求出每个班级、每门课程的平均分
- 筛选出所有课程成绩均高于对应班级课程平均分的学生
WITH
-- 1) 计算每个班级每门课程的平均分(t1)
t1 AS (SELECT *,AVG(score) OVER (PARTITION BY cid, course) AS avgFROM SQL_6
),
-- 2) 计算学生成绩与班级平均分的差值(t2)
t2 AS (SELECT *,score - avg AS 'del'FROM t1
)-- 3) 筛选每门课都高于平均分的学生
SELECT sname
FROM t2
GROUP BY sname
HAVING MIN(del) > 0;
问题3:求每个部门工资最高的前三名员工
-- 1. 首先对每个部门的员工工资进行排序,然后给出1 2 3 的序号
with t1 as (SELECT *, row_number() OVER(partition by dept_no ORDER BY salary DESC) as rn FROM SQL_7
)--2. 找每个部门的序号rn <= 3的
SELECT * FROM t1
WHERE rn <= 3-- 合并起来:
select* from (select *, row_number() over (partition by dept_no order by salary desc) as rn from SQL_7) as tmp
where rn<= 3;
问题四:计算这些员工的工资占所属部门总工资的百分比
with t1 as(select *, sum(salary) over (partition by dept_no) as 'sum_sal' from SQL_7
),
t2 as (select *,round(salary*100/sum_sal,2)as 'percentage' from t1 select * from t2;
问题五:对各部门员工的工资进行从小到大排序,排名前30%为低层,30%-80%为中层,高于80%为高层,并打上标签
--1)对各部门员工的工资进行从小到大排序并排名select * from SOL_7;
with tl as(select *,row_number() over (partition by dept_no order by salary) as rn,count(empno) over (partition by dept_no) as cnt from SQL_7
),
t2 as(
select *,round(rn/cnt,2)as percent from t1SELECT *, case when percent <= 0.3 then'低层select *when percent <= 0.8 then'中层when percent <= 1 then'高层end as label from t2;
问题四:统计每年入职总数以及截至本年累计入职总人数(本年总入职人数+本年之前所有年的总入职人数之和)
每年入职总数:
select year(hire_date) as hire_year, count(empno) as cnt from SQL_7
group by year(hire_date)
order by hire_year ;累计入职总人数:
with tl as(select year(hire_date) as hire_year, count(empno) as cntfrom SQL_7group by year(hire_date) order by hire_year
)
select *, sum(cnt) over (order by hire_year) as sum from t1;连续类问题
博客:https://blog.csdn.net/qq_26442553/article/details/145658368
连续登录问题是数据开发同学SQL面试中考察的重点,主要涉及对日期字段的处理和逻辑判断连续登录问题的核心在于“日期连续”,一般题目中出现“求XXX连续N天登录“这种字眼时,往往就是一道连续登陆日期的题目
解决这类题目,首先要清楚什么是“连续”?
1.首先,就拿用户登录而言,用户在12.5登录,12.6登录,12.7也登陆,这样才算是连续3天登录。倘若用户在12.5上午登录,12.5下午登录,12.6早上登录,这并不算是连续登录3天。所以我们在处理连续登录问题时,往往要保证用户每天的登录记录只有一条。
2.此外,倘若用户在12.5上午登录,12.5下午登录,12.6早上登录,这并不算是连续登录3天。所以我们在处理连续登录问题时,往往要保证用户每天的登录记录只有一条。
3.最后,一个用户会出现多次连续登录的场景,例如一个用户在12.1、12,2、12.3、12.5、12.6、12.7这六天均有登录记录,那么,这个用户其实并不是连续登录了6天,而是有两次连续登录3天的情况,此时我们要分组处理
连续登录问题的常规解法
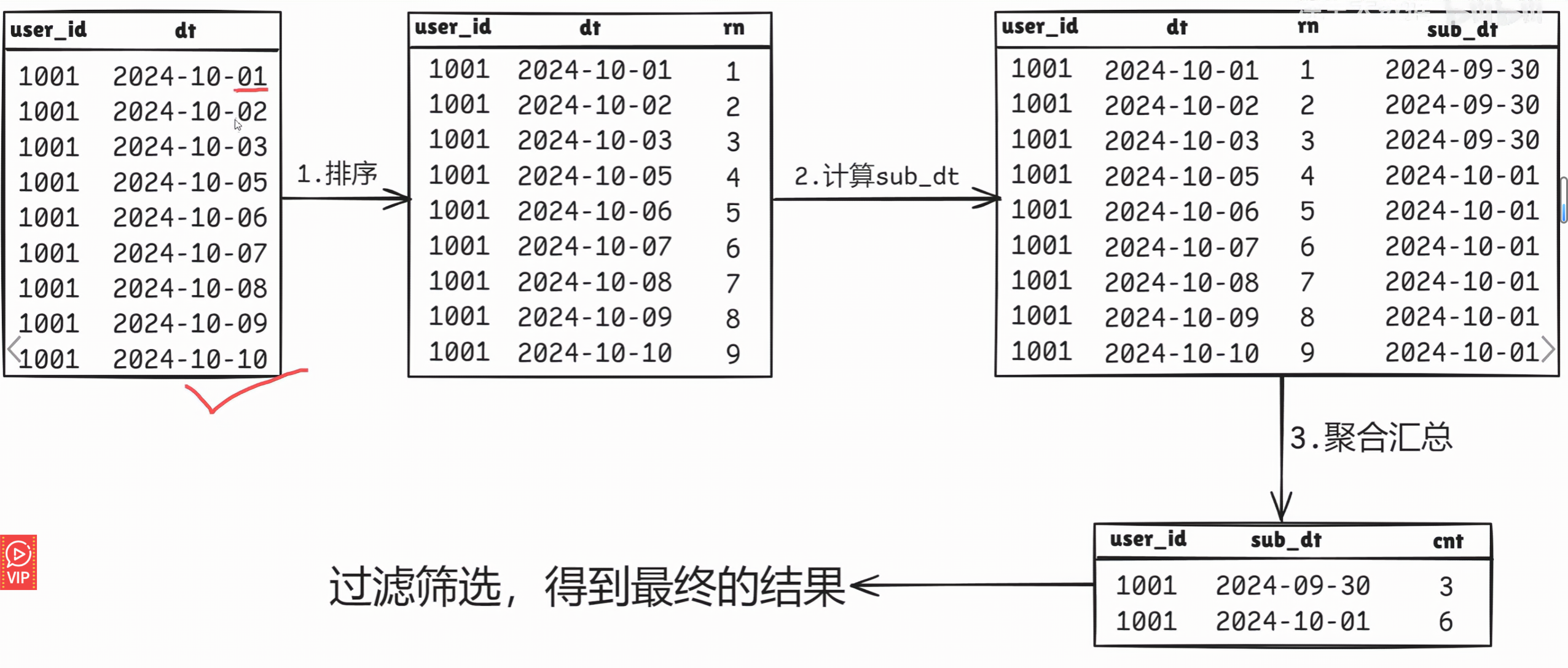
- 首先。在确保每个用户在每天只有我们需要给每个用户的登录日期都进行排序,使用ROW_NUMBER()开窗函数
row number() over (partition by user id order by dt) as rn
- 第二步,也是最里要的一步,我们器要构造日期差标。构造的方法也很简单,就是用登陆日期减去第一步算出来的排序。通过观察可以发现,这个标识符在连续登录的记录里是相同的,因为日期在变化,但是排序也在变化,减去之后的结果是固定的!
date_sub(dt, row_number() over (partition by user id order by dt)) as sub dt
- 最后,按照题目要求筛选连续登录的记录那可,注意,一个用户可能存在多次连续登录的场景,所以我们需要先按照user_id+sub_dt来进行分组,如果最终要统计的是用户粒度的结果,需要再按照user_id进行二次聚合。
group by user id, sub dt
--找到连续7天登录的用户
having count(1)>= 3
连续登陆问题的第二种解法
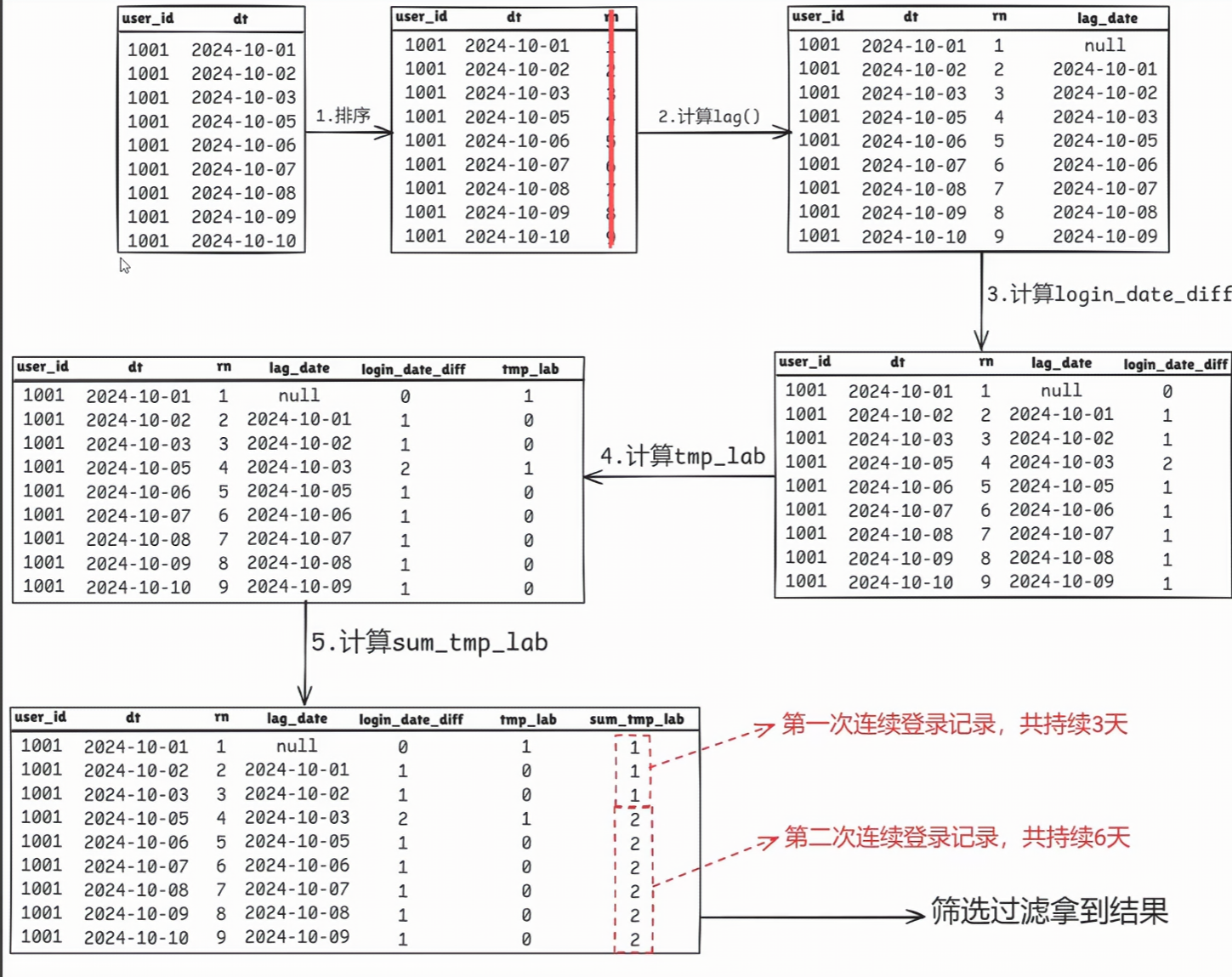
- 相比于第一种解法,第二种解法可能在理解上要稍微复杂一些,计算步骤也更多。核心思想就是:如果用户两次登录的日期之间相差一天,说明这两天是连续登录的。第二种解法的第一步和第一种解法一样,仍然是先计算每个用户的日期排序:
-- 一般的连续登录问题可以直接求datediff(dt,lag(dt,1),不计算row_number()也可以
row_number() over (partition by user id order by dt) as rn
- 第二步,我们需要通过开窗函数lag()拿到每个用户前一次的登陆日期,再用datediff0函数计算当前日期和前一次日期的差值即可。如果差值为1,说明是连续的,否则不连续。
datediff(dt, lag(dt, 1) over (partition by user id order by dt)) as login_date_diff
- 第三步,利用日期差的结果,当datediff为1时,说明整体是连续的,否则不连续。这里可以使用case when end语句来又每一行打标:
case when login_date_diff = 1 then 0 else 1 end as tmp_lab
- 第四步,利用我们的标签,使用开窗函数对计算的标签进行累加,窗口范围限制在[以上所有行,当前行];因为当连续中断时,login_date_diff !=1,此时 tmp_lab=1,对 tmp_lab 累加计算的话,累计值会变化,刚好反映了连续中断的场景。因此,只要累计值不变,用户就是在连续登录!
sum(tmp_lab) over (partition by user_id order by dt rows between unbounded preceding and current row)as sum_tmp_lab
=>
group by user id, sum_tmp_lab
having count(1)>=7
间隔连续登陆