whisper 语音识别的安装与使用
Whisper 是由OpenAI开发的开源自动语音识别(ASR)模型,不仅支持音频转录,还可以用于视频转录。通过调用ffmpeg处理视频,支持主流音视频格式的转录。
安装
安装ffmpeg:下载ffmpeg,Releases · BtbN/FFmpeg-Builds · GitHub,
找到“ffmpeg-master-latest-win64-gpl.zip”版本下载,可解压在D盘,之后将其配置在环境变量中。
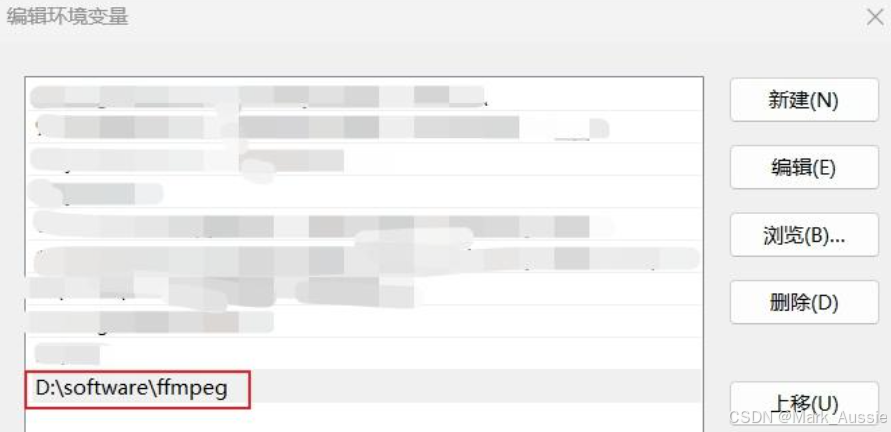
安装Git
使用安装包安装,也需要配置在环境变量中。Git - Downloading Package
安装torch:可在PyTorch中选择对应的环境的安装命令,如:
pip3 install torch torchvision torchaudio
使用如下命令安装 whisper:
pip install git+https://github.com/openai/whisper.git,再执行 pip install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git
安装中遇到问题:

开始创建的虚拟环境用的是3.11的Python,重新创建使用3.9的Python,问题未解决。
替换安装命令:pip install -U openai-whisper -i https://pypi.tuna.tsinghua.edu.cn/simple
安装成功,可使用 whisper --help 验证。
使用
准备一个mp3格式的音频做测试。
命令行调用
cmd命令进入音频文件目录,命令whisper audio.mp3,首次使用会自动下载模型,保存位置:

也可以在命令中增加参数设置:
–model MODEL 选择模型
从小到大依次为:tiny、base、small、medium、large
–output_format srt 可以只生成srt文件,其他的包括:[“txt”, “vtt”, “srt”, “tsv”, “json”, “all”]
选择模型的保存地址 --model_dir MODEL_DIR 默认为:~/.cache/whisper/small.pt
whisper input.mp4 -o outputFile -f srt --language Chinese
-o:指定srt文件生成的路径
-f:指定只生成srt文件,所有:[“txt”, “vtt”, “srt”, “tsv”, “json”]
–language:指定音视频的语言
python调用
import whisper
model = whisper.load_model("./models/large-v3-turbo.pt") # 将模型保存在项目目录,加载模型
result = model.transcribe("./data/audio/audio.mp3")
print(result["text"])
参考:
https://zhuanlan.zhihu.com/p/595691785
https://openai.com/index/whisper/
whisper安装说明_linux whisper pt文件位置-CSDN博客
https://github.com/openai/whisper