IO 端口与 IO 内存

文章目录
- 一、IO 端口和 IO 内存的区分及联系
- IO 端口和 IO 内存的定义
- 二、Linux 下访问 IO
- 1、Linux 下访问 IO 端口
- I/O 映射方式
- 内存映射方式
- 2、Linux 下访问 IO 内存
- 3、request_region
- (1)、资源管理的数据结构
- (2)、申请流程与冲突检测
- 1. 创建资源节点
- 2. 资源树插入与冲突检测
- 3. 资源树示例
- (3)、锁机制与并发控制
- (4)、资源释放与合并
- (5)、实际应用场景
- 4、request_mem_region
- (1)、核心功能
- (2)、函数参数与返回值
- (3)、实现机制与关键技术
- 1. **资源树结构**
- (4)、与`ioremap()`的关系
- (5)、`request_region()`与`request_mem_region()`的区别
- 5、ioport_map
- (1)、功能定义与核心作用
- 1. **I/O端口到虚拟地址的映射**
- 2. **统一访问接口**
- (2)、函数原型与参数解析
- 1. **函数原型**
- 2. **实现逻辑**
- (3)、`ioport_map` 的映射本质
- 1. **无实际页表映射**
- 2. **硬件访问机制**
- (4)、直接访问的后果
- 1. **非法内存访问**
- 2. **硬件无响应**
- (5)、合法访问流程
- 1. **内核驱动访问**
- 2. **用户空间访问**
- 6、ioremap
- (1)、功能定义与核心作用
- 1. **物理地址到虚拟地址的映射**
- 2. **屏蔽硬件差异**
- (2)、函数原型与参数解析
- 1. **函数原型**
- 2. **标志位(flags)**
- (3)、实现机制与关键技术
- 1. **地址合法性检查**
- 2. **虚拟地址分配**
- 3. **缓存策略控制**
- (4)、典型使用场景
- 1. **外设寄存器访问**
- 2. **内存映射设备驱动**
- 3. **总线协议实现**
- (5)、与相关函数的协作
- 1. **`iounmap`**
- 2. **`readl`/`writel`**
- 3. **`devm_ioremap`**
- (6)、底层实现示例(ARM架构)
- (7)、 `ioport_map` 与 `ioremap` 的对比
- (8)、设计意图
- 7、ioread8
- (1)、功能定义与核心作用
- 1. **统一访问接口**
- 2. **硬件交互的抽象层**
- (2)、函数原型与参数解析
- 1. **函数原型**
- 2. **实现逻辑**
- (3)、与 `readb` 的核心区别
- (4)、典型使用场景
- 1. **传统 x86 设备驱动**
- 2. **嵌入式设备控制**
- 3. **总线协议解析**
- (5)、底层访问流程
- (6)、与 `readb` 的对比示例
- 场景:访问 UART 寄存器
- (7)、设计意图与演进
- 8、MMIO
- (1)、MMIO的核心原理与架构
- 1. **地址映射机制**
- 2. **访问模型**
- 3. **硬件支持**
- (2)、CPU端的指令执行流程
- 1. **指令译码与总线请求**
- 2. **总线事务处理**
- (3)、关键硬件模块支持
- 1. **内存管理单元(MMU)**
- 2. **总线控制器**
- 3. **中断控制器**
- (4)、缓存一致性管理
- 1. **非缓存(Non-Cacheable)区域**
- 2. **强序内存屏障(Memory Barrier)**
- (5)、典型硬件交互示例
- (6)、固定分配的MMIO区间
- 1. **实现原理**
- 2. **典型场景**
- 3. **优缺点**
- (7)、动态分配的MMIO区间
- 1. **实现原理**
- 2. **典型场景**
- 3. **优缺点**
- (8)、混合分配模式
- 参考
一、IO 端口和 IO 内存的区分及联系
这两者如何区分就涉及到硬件知识,X86 体系中,具有两个地址空间:IO 空间和内存空间,而 RISC 指令系统的 CPU(如 ARM、PowerPC 等)通常只实现一个物理地址空间,即内存空间。
- 内存空间:内存地址寻址范围,32 位操作系统内存空间为 232 ,即 4G 。
- IO 空间:X86 特有的一个空间,与内存空间彼此独立的地址空间,32 位 X86 有 64K 的 IO 空间。
IO 端口和 IO 内存的定义
-
IO 端口:当寄存器或内存位于 IO 空间时,称为 IO 端口。一般寄存器也俗称 I/O 端口,或者说 I/O ports ,这个 I/O 端口可以被映射在 Memory Space , 也可以被映射在 I/O Space 。
-
IO 内存:当寄存器或内存位于内存空间时,称为 IO 内存。
二、Linux 下访问 IO
对于某一既定的系统,它要么是独立编址、要么是统一编址,具体采用哪一种则取决于 CPU 的体系结构。 如,PowerPC、m68k 等采用统一编址,而 X86 等则采用独立编址,存在 IO 空间的概念。目前,大多数嵌入式微控制器如 ARM、PowerPC 等并不提供 I/O 空间,仅有内存空间,可直接用地址、指针访问。但对于 Linux 内核而言,它可能用于不同的 CPU ,所以它必须都要考虑这两种方式,于是它采用一种新的方法,将基于 I/O 映射方式的或内存映射方式的 I/O 端口通称为 “I/O 区域” (I/O region),不论你采用哪种方式,都要先申请 IO 区域:request_resource() ,结束时释放它:release_resource()。
IO region 是一种 IO 资源,因此它可以用 resource 结构类型来描述。
访问 IO 端口有 2 种途径:I/O 映射方式(I/O-mapped)、内存映射方式(Memory-mapped)。前一种途径不映射到内存空间,直接使用 intb()/outb() 之类的函数来读写 IO 端口;后一种 MMIO(Memory-Mapped I/O) 是先把 IO 端口映射到 IO 内存(“内存空间”),再使用访问 IO 内存的函数来访问 IO 端口。
1、Linux 下访问 IO 端口
I/O 映射方式
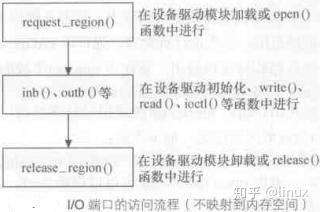
内存映射方式

2、Linux 下访问 IO 内存

3、request_region
Linux中的request_region()函数用于申请并占用一段I/O端口资源,其核心实现依赖于内核的资源管理框架和树形结构组织。以下是其占用实现原理的详细分析:
(1)、资源管理的数据结构
Linux通过struct resource描述I/O资源,关键字段如下:
struct resource {const char *name; // 资源名称resource_size_t start; // 资源起始地址resource_size_t end; // 资源结束地址unsigned long flags; // 资源标志(如IORESOURCE_BUSY)struct resource *parent; // 父资源节点struct resource *child; // 子资源节点struct resource *sibling;// 兄弟资源节点
};
- 树形结构:资源以树状组织,
ioport_resource(I/O端口根节点)和iomem_resource(内存映射根节点)为顶级父节点,子节点按地址范围从小到大链接。 - 标志位:
IORESOURCE_BUSY表示资源已被占用,IORESOURCE_FIXED表示不可移动。
(2)、申请流程与冲突检测
1. 创建资源节点
调用request_region(start, num, name)时,内核会:
- 分配
struct resource结构体,设置start、end(start + num - 1)、name和flags(默认IORESOURCE_BUSY)。 - 通过
__request_region()函数将资源插入资源树。
2. 资源树插入与冲突检测
__request_region()的核心逻辑如下:
struct resource *__request_region(struct resource *parent, resource_size_t start, resource_size_t n, const char *name, int flags) {struct resource *res = kzalloc(...);write_lock(&resource_lock);conflict = __request_resource(parent, res);if (!conflict) {// 插入资源到树中write_unlock(&resource_lock);return res;}// 冲突处理...write_unlock(&resource_lock);kfree(res);return NULL;
}
- 关键函数
__request_resource():- 范围检查:确保新资源在父节点范围内(
start >= parent->start且end <= parent->end)。 - 遍历兄弟节点:从父节点的
child开始,按地址顺序检查是否存在重叠:- 无冲突:将新资源插入到合适位置(保持地址有序)。
- 有冲突:
- 若冲突资源非父节点,递归检查该冲突资源是否为可抢占的子树。
- 若冲突资源不可抢占(如已被标记为
IORESOURCE_BUSY),则申请失败。
- 范围检查:确保新资源在父节点范围内(
3. 资源树示例
假设已有资源树:
ioport_resource (0-0xFFFF)
├── child1 (0x1000-0x1FFF)
│ └── grandchild1 (0x1200-0x1300)
└── child2 (0x2000-0x2FFF)
申请0x1100-0x11FF时:
- 检测到与
child1的0x1000-0x1FFF重叠。 - 递归检查
child1的子节点grandchild1(0x1200-0x1300),发现无重叠。 - 将新资源插入到
child1和grandchild1之间。
(3)、锁机制与并发控制
- 写锁保护:通过
write_lock(&resource_lock)保证资源树操作的原子性,防止并发申请导致的数据竞争。 - 读锁优化:查询资源时使用读锁(
read_lock),允许多个线程同时读取资源树。
(4)、资源释放与合并
调用release_region(start, num)时:
- 查找匹配的
struct resource节点。 - 从父节点的
child或兄弟链表中移除该节点。 - 合并相邻空闲区域:若释放的节点前后存在空闲兄弟节点,合并为连续区域。
(5)、实际应用场景
- 驱动开发:
驱动通过request_region()独占I/O端口,避免其他驱动或进程误操作。例如:if (!request_region(0x3F8, 8, "serial")) return -EBUSY; // 串口资源占用 - 设备树匹配:
设备树中定义的I/O端口范围需通过request_region()验证可用性,防止资源冲突。
4、request_mem_region
Linux中的request_mem_region()函数用于申请并占用一段I/O内存资源(即内存映射的I/O区域),其核心功能是确保驱动程序对特定物理内存地址的独占访问权,避免资源冲突。以下是其实现功能、技术细节及典型应用场景的详细分析:
(1)、核心功能
-
资源独占性声明
- 通过向内核资源管理框架注册一段物理内存地址范围(如外设寄存器地址),标记该区域为“已占用”(
IORESOURCE_BUSY标志),防止其他驱动或进程误操作。 - 例如,驱动访问GPIO控制器的寄存器时,需先调用
request_mem_region()声明对该区域的占用。
- 通过向内核资源管理框架注册一段物理内存地址范围(如外设寄存器地址),标记该区域为“已占用”(
-
资源树管理
- 将申请的资源插入内核全局资源树(
iomem_resource为根节点),按地址范围组织为树形结构,便于快速查询冲突和释放。
- 将申请的资源插入内核全局资源树(
-
与硬件编址的适配
- 针对 内存映射I/O(MMIO) 设备(如ARM、PowerPC平台的外设),将物理地址映射到内核虚拟地址空间前,必须通过该函数声明资源所有权。
(2)、函数参数与返回值
struct resource *request_mem_region(resource_size_t start, resource_size_t n, const char *name);
- 参数:
start:物理内存起始地址(如0xE0200240)。n:申请长度(字节数)。name:资源名称(用于调试和/proc/iomem显示)。
- 返回值:
- 成功:返回指向
struct resource的指针,包含分配的地址范围信息。 - 失败:返回
NULL,表示资源冲突或分配失败。
- 成功:返回指向
(3)、实现机制与关键技术
1. 资源树结构
- 树形组织:资源以树状结构管理,根节点为
iomem_resource(覆盖整个物理地址空间),子节点按地址范围从小到大链接。例如:iomem_resource (0x00000000-0xFFFFFFFF) ├── child1 (0xE0000000-0xE000FFFF) // GPIO寄存器 └── child2 (0xF0000000-0xF000FFFF) // UART寄存器 - 冲突检测:通过遍历树结构,检查新申请的地址范围是否与已有资源重叠。若重叠且标记为
IORESOURCE_BUSY,则申请失败。
(4)、与ioremap()的关系
-
分工协作
request_mem_region():仅声明资源所有权,不涉及地址映射。ioremap():将已申请的物理地址映射到内核虚拟地址,提供访问接口(如readl()/writel())。
-
典型代码流程
// 申请资源 struct resource *res = request_mem_region(0xE0200240, 0x1000, "gpio"); if (!res) return -EBUSY;// 映射到虚拟地址 void __iomem *regs = ioremap(res->start, resource_size(res)); if (!regs) {release_mem_region(res->start, resource_size(res));return -ENOMEM; }// 访问寄存器 writel(0x1, regs + GPIO_CON_OFFSET);// 清理资源 iounmap(regs); release_mem_region(res->start, resource_size(res));
(5)、request_region()与request_mem_region()的区别
| 特性 | request_region() | request_mem_region() |
|---|---|---|
| 资源类型 | I/O端口(Port-Mapped I/O) | 内存映射I/O(Memory-Mapped I/O) |
| 标志位 | IORESOURCE_IO | IORESOURCE_MEM |
| 访问方式 | inb()/outb()等端口操作指令 | 直接内存访问(readl()等) |
| 典型设备 | 串口、并口、老式ISA设备 | GPIO、UART、DMA控制器 |
5、ioport_map
Linux 内核中的ioport_map函数是用于将I/O端口地址映射到内核虚拟地址空间的关键接口,其核心目标是统一I/O端口和内存的访问接口,使驱动开发者能够通过内存操作函数(如readb/writeb)间接访问I/O端口设备。以下从功能定义、实现机制、使用场景等角度展开详细分析:
(1)、功能定义与核心作用
1. I/O端口到虚拟地址的映射
- 硬件背景:在x86架构中,I/O端口(如GPIO、UART)通过独立的I/O地址空间(0x0000-0xFFFF)访问,需使用
inb/outb等专用指令。ioport_map通过地址转换,将物理端口地址(如0x3F8)映射到内核虚拟地址空间(通常位于0x000060000000-0x000070000000),使开发者可使用readb/writeb等通用函数操作端口。 - 示例:
void __iomem *port = ioport_map(0x3F8, 8); // 映射串口寄存器 writeb(0x01, port + UART_LCR); // 通过虚拟地址配置波特率
2. 统一访问接口
- 屏蔽硬件差异:通过映射后的虚拟地址,驱动开发者无需区分端口和内存访问方式,直接使用
ioread8/iowrite8等统一接口。例如:u8 val = ioread8(port); // 自动判断地址类型(端口或内存)
(2)、函数原型与参数解析
1. 函数原型
void __iomem *ioport_map(unsigned long port, unsigned int nr);
void ioport_unmap(void __iomem *addr);
- 参数:
port:I/O端口的物理地址(如0x3F8)。nr:映射的端口数量(通常为1-4,表示连续端口)。
- 返回值:
成功返回虚拟地址指针(void __iomem *类型),失败返回NULL。
2. 实现逻辑
- 地址转换:
ioport_map仅将端口地址加上固定偏移量PIO_OFFSET(通常为0x000060000000),生成虚拟地址:return (void __iomem *)((port) + PIO_OFFSET); // 示例代码 - 无实际页表映射:
该函数不修改页表,仅通过地址偏移模拟映射,实际访问仍依赖inb/outb指令。
(3)、ioport_map 的映射本质
1. 无实际页表映射
- 地址转换逻辑:
ioport_map仅将 I/O 端口号(如0x3F8)加上固定偏移量PIO_OFFSET(通常为0x60000000),生成虚拟地址(如0x60000000 + 0x3F8),但不会修改页表建立物理页映射。 - 地址空间归属:
生成的虚拟地址位于内核保留的0x60000000-0x70000000区间,该区域通常被标记为保留内存(VM_RESERVED),禁止常规内存访问。
2. 硬件访问机制
- 指令分发:
当驱动通过readb/writeb访问该虚拟地址时,内核会通过IO_COND宏判断地址类型(I/O 端口或 MMIO),并生成对应的inb/outb指令(而非内存访问指令)。 - 绕过 MMU:
直接操作 I/O 端口时,CPU 会绕过页表,通过专用总线事务(如 x86 的IN/OUT指令)与设备交互。
(4)、直接访问的后果
1. 非法内存访问
- 页错误(Page Fault):
若用户空间程序尝试直接访问ioport_map返回的地址,由于页表未映射,会触发SIGSEGV信号。 - 总线错误(Bus Error):
内核态直接访问未映射的虚拟地址可能导致总线错误(如 x86 的#GP异常)。
2. 硬件无响应
- 指令格式错误:
I/O 端口操作需使用IN/OUT指令,若通过MOV等内存指令访问,硬件会忽略或报错。
(5)、合法访问流程
1. 内核驱动访问
void __iomem *port = ioport_map(0x3F8, 1); // 虚拟地址 0x60000000+0x3F8
writeb(0x01, port); // 内核调用 writeb,生成 outb $0x01, $0x3F8 指令
- 关键机制:
writeb宏会根据地址范围调用IO_COND,触发outb指令生成,直接操作 I/O 端口。
2. 用户空间访问
- 授权限制:
用户态需通过ioperm/iopl系统调用获取 I/O 端口操作权限,但仍需通过inb/outb指令(无法直接使用mov)。
6、ioremap
Linux 内核中的ioremap函数是设备驱动开发的核心接口,其核心功能是为硬件设备的外设寄存器或内存区域建立虚拟地址映射,使内核代码能够像访问普通内存一样操作物理地址空间。以下从功能定义、实现机制、使用场景等角度展开详细分析:
(1)、功能定义与核心作用
1. 物理地址到虚拟地址的映射
- 硬件背景:现代CPU通过虚拟地址访问内存,但外设寄存器(如GPIO、UART)的物理地址无法直接被内核代码操作。
ioremap通过修改页表,将物理地址(如0xFE000000)映射到内核虚拟地址空间(通常位于VMALLOC区域)。 - 示例:
void *virt_addr = ioremap(0xFE000000, 0x1000); // 将物理地址0xFE000000映射为虚拟地址 writel(0x1, virt_addr + 0x10); // 通过虚拟地址操作寄存器
2. 屏蔽硬件差异
- 跨平台兼容性:不同架构(x86/ARM)对I/O内存的访问方式不同(如x86使用
in/out指令,ARM直接内存映射)。ioremap统一接口,使驱动开发者无需关注底层硬件差异。 - 缓存控制:自动设置页表属性(如
Non-Cacheable),避免CPU缓存与设备状态不一致。
(2)、函数原型与参数解析
1. 函数原型
void __iomem *ioremap(unsigned long phys_addr, unsigned long size);
void __iomem *__ioremap(unsigned long phys_addr, unsigned long size, unsigned long flags);
- 参数:
phys_addr:要映射的物理地址(如PCI设备BAR空间)。size:映射长度(需与设备寄存器对齐,通常为页大小的整数倍)。flags(仅__ioremap):控制映射属性(如缓存策略、权限)。
- 返回值:
成功返回虚拟地址指针(void __iomem *类型),失败返回NULL。
2. 标志位(flags)
| 标志 | 作用 |
|---|---|
IORESOURCE_READONLY | 标记为只读映射,禁止写操作(部分架构会优化缓存策略) |
IORESOURCE_UNCACHED | 强制非缓存访问(适用于频繁读写的寄存器,如状态寄存器) |
IORESOURCE_WRITE_COMBINE | 启用写合并(Write-Combine),允许多次写操作合并为一次总线传输(提升性能) |
(3)、实现机制与关键技术
1. 地址合法性检查
- 范围验证:确保
phys_addr和size不覆盖已分配的RAM区域(通过memblock_is_reserved()检查)。 - 对齐要求:自动对齐物理地址到页边界(如ARM要求页对齐),若未对齐则内部调整。
2. 虚拟地址分配
- VMALLOC区域分配:从内核虚拟地址的
VMALLOC_START到VMALLOC_END区间分配连续空间。 - 页表配置:通过
remap_area_pages()或remap_pfn_range()修改页表项(PTE),建立虚拟地址到物理地址的映射。
3. 缓存策略控制
- 页属性设置:在页表项中设置
_PAGE_DEVICE标志,告知MMU该区域为设备内存,禁止缓存。 - 架构优化:
- ARM:使用
DC CVAU指令刷新缓存一致性。 - x86:通过
MTRR(Memory Type Range Register)设置内存类型。
- ARM:使用
(4)、典型使用场景
1. 外设寄存器访问
- GPIO控制:映射GPIO控制器的寄存器基地址,通过
readl/writel设置引脚电平。#define GPIO_BASE 0x40021000 void __iomem *gpio = ioremap(GPIO_BASE, 0x1000); writel(0x1, gpio + GPIO_MODER); // 配置GPIO模式寄存器
2. 内存映射设备驱动
- 帧缓冲(Framebuffer):映射GPU显存或LCD控制器内存,实现图形显示。
struct fb_info *info; info->screen_base = ioremap(fb_phys_addr, fb_size);
3. 总线协议实现
- PCI设备驱动:通过BAR(Base Address Register)获取设备MMIO地址并映射。
struct resource *res = &pdev->resource; void __iomem *regs = ioremap(res->start, resource_size(res));
(5)、与相关函数的协作
1. iounmap
- 功能:释放
ioremap分配的虚拟地址空间,恢复页表原状。iounmap(gpio); // 解除映射
2. readl/writel
- 作用:通过映射的虚拟地址安全访问设备寄存器,自动处理字节序和内存屏障。
u32 val = readl(gpio + GPIO_DR); // 读取数据寄存器
3. devm_ioremap
- 资源管理:与设备生命周期绑定,自动释放映射(避免手动调用
iounmap)。void __iomem *virt = devm_ioremap(dev, phys_addr, size);
(6)、底层实现示例(ARM架构)
// 简化版ioremap实现流程
void __iomem *ioremap(phys_addr_t phys_addr, size_t size) {// 1. 分配虚拟地址空间struct vm_struct *area = get_vm_area(size, VM_IOREMAP);if (!area) return NULL;// 2. 映射物理地址到虚拟地址if (remap_pfn_range(area->addr, phys_addr >> PAGE_SHIFT, size, PAGE_KERNEL_DEVICE)) {vfree(area->addr);return NULL;}return area->addr;
}
(7)、 ioport_map 与 ioremap 的对比
| 维度 | ioport_map | ioremap |
|---|---|---|
| 映射对象 | I/O端口(独立地址空间) | 设备内存(MMIO) |
| 页表映射 | 无(逻辑地址偏移) | 有(修改页表建立物理映射) |
| 访问方式 | 通过 inb/outb 指令 | 通过 readb/writeb 指令 |
| 缓存策略 | 无缓存(直接操作端口) | 需配置缓存策略(如Non-Cacheable) |
| 性能 | 低(单字节指令) | 高(支持总线流水线) |
| 地址空间 | 虚拟地址范围:0x60000000-0x70000000 | 虚拟地址范围:0xFFFF888000000000+ |
| 用户态访问 | 需 ioperm 授权 + 特权指令 | 需 mmap + 普通内存指令 |
(8)、设计意图
- 统一接口:
通过ioport_map和ioremap的虚拟地址映射,驱动开发者可使用readb/writeb统一接口,无需区分端口和内存访问方式。 - 兼容性:
在 x86 架构中,传统设备依赖 I/O 端口访问,而现代设备多采用 MMIO。ioport_map使旧驱动能平滑迁移到新内核框架。
7、ioread8
(1)、功能定义与核心作用
1. 统一访问接口
- 屏蔽硬件差异:
ioread8可同时处理两种硬件访问模式:- I/O 端口访问(x86 架构):通过
inb指令直接读取端口(如0x3F8)。 - MMIO 访问(通用架构):通过内存读取指令(如
readb)访问映射后的虚拟地址。
- I/O 端口访问(x86 架构):通过
- 示例:
u8 val = ioread8(ioport_map(0x3F8, 1)); // 读取串口状态寄存器
2. 硬件交互的抽象层
- 跨架构兼容:在 x86、ARM 等不同架构下,
ioread8自动适配底层指令(如 x86 的inb或 ARM 的内存映射访问)。 - 简化驱动开发:开发者无需关注硬件访问的具体实现细节,只需调用统一接口。
(2)、函数原型与参数解析
1. 函数原型
unsigned int ioread8(const volatile void __iomem *addr);
- 参数:
addr:指向 I/O 端口或 MMIO 的虚拟地址(void __iomem *类型)。
- 返回值:
- 读取的 8 位无符号整数(
u8类型)。
- 读取的 8 位无符号整数(
2. 实现逻辑
- 地址类型判断:
#define IO_COND(addr, is_pio, is_mmio) \do { \unsigned long port = (unsigned long)addr; \if (port < PIO_RESERVED) { \VERIFY_PIO(port); \port &= PIO_MASK; \is_pio; \} else { \is_mmio; \} \} while (0)- I/O 端口(
port < 0x40000UL):调用inb(port)指令。 - MMIO(
port >= 0x40000UL):调用readb(addr)指令。
- I/O 端口(
- 代码展开示例:
unsigned int ioread8(void __iomem *addr) {unsigned long port = (unsigned long)addr;if (port < 0x40000UL) { // 判断是否为 I/O 端口BUG_ON((port & ~PIO_MASK) != PIO_OFFSET); // 地址合法性检查port &= PIO_MASK; // 清除无效位return inb(port); // 执行 inb 指令} else {return readb(addr); // 执行内存读取} }
(3)、与 readb 的核心区别
| 维度 | ioread8 | readb |
|---|---|---|
| 地址类型 | 支持 I/O 端口和 MMIO | 仅支持 MMIO |
| 类型安全 | 使用 void __iomem * 类型指针 | 使用普通指针(如 void *) |
| 兼容性 | 跨架构统一接口 | 依赖架构实现 |
| 使用场景 | 驱动开发(需兼容端口/MMIO) | 内核模块(仅 MMIO) |
(4)、典型使用场景
1. 传统 x86 设备驱动
- 键盘控制器:通过
ioport_map映射 I/O 端口,使用ioread8读取状态:void __iomem *kbd_port = ioport_map(0x60, 1); u8 kbd_status = ioread8(kbd_port); // 读取键盘状态寄存器
2. 嵌入式设备控制
- GPIO 寄存器:直接访问 MMIO 地址:
void __iomem *gpio_base = ioremap(0x40021000, 0x400); u8 gpio_pin = ioread8(gpio_base + GPIO_INPUT_DATA); // 读取 GPIO 输入状态
3. 总线协议解析
- I2C 控制器:通过
ioread8读取设备寄存器:u8 device_id = ioread8(i2c_dev->base + I2C_REG_DEVICE_ID);
(5)、底层访问流程
以 ioread8 访问 I/O 端口为例:
- 地址映射:
ioport_map(0x3F8, 1)返回虚拟地址0x60000000 + 0x3F8。 - 指令生成:
ioread8调用IO_COND宏,判断地址类型后生成inb $0x3F8指令。 - 硬件交互:
CPU 执行inb指令,通过总线控制器与设备通信,返回数据。
(6)、与 readb 的对比示例
场景:访问 UART 寄存器
- MMIO 实现:
void __iomem *uart_base = ioremap(0xFE200000, 0x1000); u8 lcr = readb(uart_base + UART_LCR); // 直接内存访问 - ioport_map 实现:
void __iomem *uart_port = ioport_map(0x3F8, 1); u8 lcr = ioread8(uart_port); // 实际执行 inb $0x3F8 指令
(7)、设计意图与演进
- 统一抽象层:
在 Linux 2.6 内核后逐步替代readb/writeb,通过void __iomem *类型强制类型检查,提升代码安全性。 - 架构无关性:
使驱动开发者无需关注底层硬件差异(如 x86 的端口访问与 ARM 的 MMIO)。 - 未来扩展:
与ioread8_rep(批量读取)、ioread8_be(大端模式)等函数共同构成完整的 I/O 访问接口体系。
8、MMIO
Linux中的 MMIO(Memory-Mapped I/O,内存映射输入/输出) 是一种通过将硬件设备寄存器或内存区域映射到CPU虚拟地址空间,使CPU能像访问内存一样直接操作设备的技术。其核心目标是简化设备访问逻辑、提升性能,并支持现代硬件的高效交互。以下从原理、实现、应用等角度展开详细分析:
(1)、MMIO的核心原理与架构
1. 地址映射机制
- 物理地址到虚拟地址的转换:
MMIO通过内存管理单元(MMU)将设备的物理地址(如PCI BAR空间)映射到进程的虚拟地址空间。例如,GPU显存可能被映射到0xFFFF888000000000起始的虚拟地址。 - 总线地址与物理地址的关系:
在某些架构(如ARM)中,设备寄存器可能通过总线地址(Bus Address)映射到内核虚拟地址,需通过dma_map_single()等函数处理缓存一致性问题。
2. 访问模型
- 指令级透明性:
CPU使用普通内存访问指令(如mov)操作设备寄存器,无需专用I/O指令(如x86的in/out)。例如,向0x40000000写入数据即触发UART发送字符。 - 缓存一致性:
MMIO区域通常标记为非缓存(UC)或写直通(WT),避免CPU缓存与设备状态不一致。例如,ARM通过ioremap_uc()强制设备内存不可缓存。
3. 硬件支持
- MMU与页表:
MMIO依赖MMU的页表机制实现地址转换。例如,x86-64的4级页表将虚拟地址0xFFFF888000000000映射到物理地址0x40000000。 - 总线协议扩展:
PCIe等现代总线通过配置空间(Configuration Space)管理MMIO区域,支持动态分配(如BAR的BAR0-BAR5)。
(2)、CPU端的指令执行流程
1. 指令译码与总线请求
- mov指令解析:
CPU执行mov eax, [0xFE000000]时,译码器识别为内存加载指令,生成内存访问请求,包含目标地址0xFE000000和操作类型(读)。 - MMU地址转换:
内存管理单元(MMU)将虚拟地址0xFE000000转换为物理地址(假设启用虚拟化),若该物理地址属于MMIO区域,则请求被转发至总线控制器。
2. 总线事务处理
- 总线协议交互:
总线控制器(如PCIe Root Complex)将CPU的请求封装为总线事务(如PCIe Memory Read),通过总线协议(PCIe、AHB等)传输到目标设备。 - 设备响应:
设备完成操作后,通过总线返回数据(写操作无需返回),总线控制器将数据写入CPU的寄存器或缓存。
(3)、关键硬件模块支持
1. 内存管理单元(MMU)
- 页表映射:
MMU的页表项(PTE)中设置Present和Valid标志,并关联物理页框号(PFN)。若物理页映射到MMIO设备,MMU生成总线访问请求而非访问DRAM。 - 缓存策略控制:
通过页属性(如Non-Cacheable或Write-Combining)指定MMIO区域的缓存行为。例如,ARM的MT_NORMAL和MT_DEVICE属性分别控制缓存模式。
2. 总线控制器
- 事务路由:
总线控制器根据地址范围将请求路由到对应设备。例如,x86的PCIe Root Complex根据BAR配置将0xFE000000的请求转发到GPU。 - 错误处理:
若设备未响应或超时,总线控制器触发错误中断(如PCIe Uncorrectable Error)。
3. 中断控制器
- 中断触发:
设备完成操作后,通过中断引脚(如IRQ)通知CPU。中断控制器(如APIC)将物理中断映射到虚拟中断号,触发中断服务例程(ISR)。
(4)、缓存一致性管理
1. 非缓存(Non-Cacheable)区域
- 强制刷新:
对MMIO区域的写操作绕过缓存,直接写入设备寄存器。例如,ARM通过DC CVAU指令刷新缓存一致性。 - 写直通(Write-Through):
数据同时写入缓存和总线,适用于需要实时同步的场景(如DMA缓冲区)。
2. 强序内存屏障(Memory Barrier)
- 指令顺序控制:
CPU在MMIO访问前后插入内存屏障(如x86的mfence),确保指令执行顺序不被乱序执行破坏。例如,写寄存器后必须立即刷新总线流水线。
(5)、典型硬件交互示例
以CPU通过MMIO控制GPIO为例:
- 地址映射:
GPIO控制器的寄存器基地址0x40021000被映射到物理地址空间,并关联到总线控制器。 - 指令执行:
CPU执行mov al, [0x40021000],MMU转换地址后触发总线读事务。 - 总线交互:
总线控制器解析地址,向GPIO控制器发送读请求,控制器返回引脚状态值。 - 数据返回:
数据通过总线返回CPU,写入寄存器EAX,程序根据值判断引脚电平。
MMIO(Memory-Mapped I/O)区间的分配方式既可以是固定的,也可以是动态的,具体取决于系统设计目标、硬件架构和应用场景。以下是两者的对比分析及典型实现:
(6)、固定分配的MMIO区间
1. 实现原理
- 静态预留:在系统初始化阶段(如BIOS/UEFI启动时),预先为特定设备分配固定的MMIO地址范围。例如:
- PCIe配置空间:每个PCIe设备分配4KB的配置空间,固定映射到
0xCF8-0xCFC等地址。 - GPU显存:NVIDIA GPU的显存可能固定映射到
0xFE000000-0xFEFFFFFF。
- PCIe配置空间:每个PCIe设备分配4KB的配置空间,固定映射到
- 硬件解码规则:总线控制器(如Northbridge)根据硬编码的地址映射表,将CPU的MMIO访问请求路由到固定设备。
2. 典型场景
- 传统嵌入式系统:资源有限且设备固定,如工业控制PLC中固定分配GPIO、UART的MMIO区域。
- x86平台的早期设计:如4GB以下内存地址空间(MMIOL)固定分配给PCI设备,剩余空间留给系统内存。
3. 优缺点
- 优点:
- 实现简单,无需复杂的资源管理逻辑。
- 确保关键设备(如中断控制器)的地址稳定性。
- 缺点:
- 资源浪费:若设备未使用预留空间,该区域无法被其他设备复用。
- 扩展性差:新增设备时可能因地址空间不足导致冲突。
(7)、动态分配的MMIO区间
1. 实现原理
- 按需分配:根据设备实际需求动态分配地址空间。例如:
- PCIe设备热插拔:当新设备插入时,系统从空闲地址池中分配所需大小的MMIO区域。
- GPU显存弹性扩展:NVIDIA的Unified Memory技术动态调整显存与系统内存的共享区域。
- 地址空间管理:
- 操作系统维护空闲地址段列表,通过算法(如首次适应、最佳适应)选择合适区域分配。
- 硬件支持动态解码(如PCIe的BAR机制),允许设备在运行时调整MMIO地址。
2. 典型场景
- 现代服务器与桌面系统:支持PCIe设备热插拔(如USB扩展卡、NVMe SSD),需动态分配MMIO资源。
- 云计算与虚拟化:Hypervisor动态为虚拟机分配MMIO区域,避免物理地址冲突。
- 多核处理器:根据CPU核心的负载动态调整MMIO缓存策略(如ARM的Big.LITTLE架构)。
3. 优缺点
- 优点:
- 资源利用率高:避免固定分配导致的碎片化和浪费。
- 灵活性强:支持设备热插拔和动态配置。
- 缺点:
- 实现复杂,需硬件和软件协同管理。
- 可能引入延迟(如动态地址映射的开销)。
(8)、混合分配模式
实际系统中常采用静态预留+动态分配的混合模式:
- 静态预留关键区域:
- 为中断控制器(APIC)、内存控制器(MC)等预留固定地址。
- 动态分配扩展区域:
- 剩余地址空间由操作系统动态分配给PCIe设备等可扩展硬件。
例如,x86系统将4GB以下地址空间(MMIOL)静态分配给传统PCI设备,而4GB以上(MMIOH)动态分配给PCIe设备。
参考
io端口与io内存详解
Linux系统对IO端口和IO内存的管理
【统一编址应用详解】:如何在现代系统中最大化IO端口与IO内存的潜力
☆