【视频时刻检索】Text-Video Retrieval via Multi-Modal Hypergraph Networks 论文阅读
Text-Video Retrieval via Multi-Modal Hypergraph Networks 论文阅读
- ABSTRACT
- 1 INTRODUCTION
- 2 PRELIMINARIES
- 3 OUR FRAMEWORK
- 3.1 Multi-Modal Hypergraph Networks
- 3.2 Variational Inference
- 4 EXPERIMENT
- 6 CONCLUSION
文章信息:
发表于:WSDM '24
原文链接:https://dl.acm.org/doi/10.1145/3616855.3635757
ABSTRACT
文本-视频检索是一项旨在根据文本查询识别相关视频的挑战性任务。与传统文本检索相比,文本-视频检索的主要难点在于文本查询与视频内容之间的语义鸿沟。先前的研究主要侧重于通过精细聚合词-帧匹配信号来对齐查询和视频。受人类模块化判断文本与视频相关性的认知过程启发,由于视频内容的连续性和复杂性,这种判断需要高阶匹配信号。 本文提出了一种块级文本-视频匹配方法,其中查询被分解为描述特定检索单元的语义块,而视频被分割为独立的片段。我们将块级匹配建模为查询词与视频帧之间的多元关联,并引入多模态超图进行多元关系建模。通过将文本单元和视频帧表示为节点,并用超边刻画它们之间的关系,构建了一个多模态超图。这样,查询和视频可以在高阶语义空间中对齐。 此外,为了增强模型的泛化能力,提取的特征被输入变分推断组件进行计算,得到高斯分布下的变分表示。超图和变分推断的结合使我们的模型能够捕捉文本和视觉内容之间复杂的多元交互。实验结果表明,所提出的方法在文本-视频检索任务上达到了最先进的性能。
1 INTRODUCTION
文本-视频检索(TVR)是一项多模态任务,旨在根据文本查询找出最相关的视频。TVR使人类能够以简单自然的方式搜索视频,因而吸引了多个研究领域的广泛关注[35,37]。与传统的单模态检索(如特定检索)不同,文本-视频检索需要在不同模态间进行操作。因此,该任务极具挑战性,因为它不仅需要理解视频和文本的内容,还需要理解它们之间的跨模态关联。
跨模态语义表征与对齐是文本-视频检索任务的核心[17,36]。现有研究主要分为两类:一类聚焦跨模态语义表征,另一类侧重跨模态语义对齐。基于预训练表征的优势,CLIP[28]和CLIP4CLIP[24]将文本查询与视频嵌入共享语义空间计算相似度。然而这类方法生成的查询表征较为粗糙,难以捕捉细粒度交互。为此,另一系列研究[1,25,32]采用注意力机制捕获文本词汇与视频帧的交互关系,实现了显著性能提升。这些方法通过不同粒度学习对齐策略,推动了该任务的进展。但跨模态语义对齐仍存在系统性探索空间。
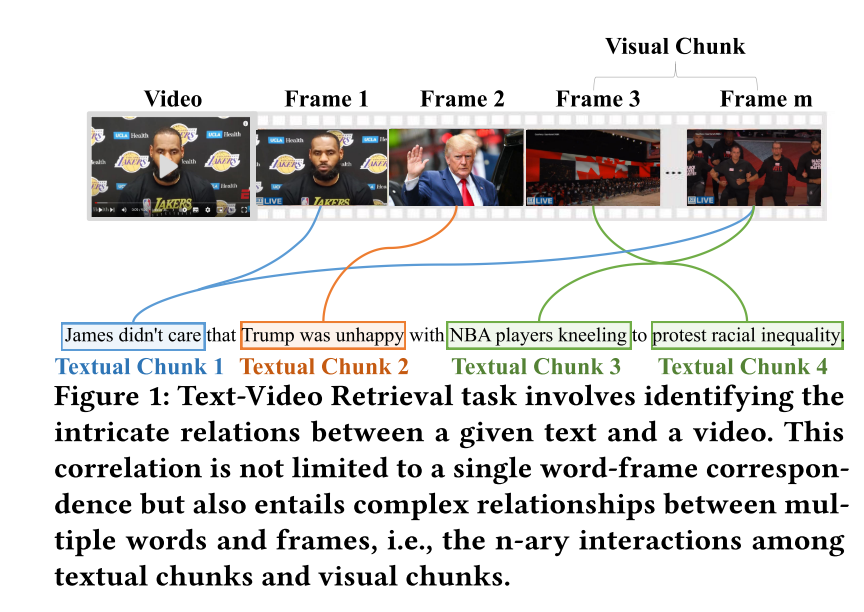
然而,基于给定文本查询检索最相关视频仍面临严峻挑战。如图1所示,该任务要求模型精准理解文本描述与视频中各语义块的关键细节(如实体"詹姆斯"、“特朗普”、"NBA球员"及动作"跪地"等关系),即对构成内容的基础概念进行模块化解析。更重要的是,捕捉视频与文本间的复杂关联不仅需要细粒度的词-帧对应(如现有方法所示),还需建模多元交互关系(如图1所示,文本块3+4与视觉块[帧3+帧m]存在语义关联)。当文本块3与4组合表达"NBA球员抗议种族不平等"事件时,对应的视觉块[帧3+帧m]也呈现相同语义。通过同步解析文本块与视觉块,二者关联性可被清晰辨识。这一现象揭示了多模态语义块在文本-视频检索中的关键作用,而现有研究对此尚未充分探索。
在基于文本查询检索最相关视频时,尽管语义特征分散在多个词/帧中,人类仍能识别并聚类文本/视频中的关键概念块[4],进而通过精细聚合这些特征块间的语义关系来判断文本-视频相关性。受此启发,本文提出多模态超图变分推理网络(LEAN),通过为每个文本查询及对应视频构建多模态超图来模拟这一机制,有效捕捉不同模态间的多元关联。具体而言,我们首先为每个训练样本构建多模态超图,将文本单元和视频帧表示为超图结构;随后模型自动学习超图边与节点的权重,以捕获词与帧间的潜在关联;为增强泛化能力,我们将超图输入变分推理模块,将节点和超边表征转化为高斯分布。通过这种分布化表征,模型能更好地捕捉检索任务中语义关系的潜在分布规律。超图与变分推理的结合使我们的模型能够捕捉文本与视频间复杂的多元交互,并融合多类型关联,为实际应用提供了理想解决方案。实验表明,该模型在文本-视频检索任务上达到了最先进的性能。我们的主要贡献如下:
- 技术创新:我们设计了一种新颖的文本-视频检索框架,用于捕捉文本与视频间复杂的多元交互关系。据我们所知,这是首次将超图网络引入文本-视频检索任务的研究工作。
- 方法创新:构建了包含三类超边的多模态超图结构,同时融合模态内与模态间关联,并设计多模态超图网络来捕捉词与帧的潜在联系。此外,创新性地引入基于变分推理的图表示学习方法以增强模型泛化能力。
- 实验验证:在基准数据集上的大量实验结果表明,我们的方法显著优于现有最优模型,充分验证了其有效性。
2 PRELIMINARIES
文本-视频检索(TVR)是一种跨模态信息检索任务,旨在根据给定的文本查询检索相关视频或根据视频检索相关文本。该任务需要对文本和视觉内容进行匹配对齐以检索最相关视频。对于文本查询,输入为词序列 q t q_t qt,输出为最相关视频集合 V t V_t Vt,其中每个视频 v i ∈ V t v_i\in V_t vi∈Vt都与文本查询 q t q_t qt相关联。TVR的孪生任务是视频-文本检索,其输入 q v q_v qv表示视频表征,输出为最相关文本集合 T v T_v Tv,其中每个文本 t i ∈ T v t_i\in T_v ti∈Tv都与视频查询 q v q_v qv相关联。本任务使用的符号包括: q t q_t qt表示文本查询, q v q_v qv表示视频查询, V t V_t Vt表示与 q t q_t qt相关的视频集合, T v T_v Tv表示与 q v q_v qv相关的文本集合。
超图(Hypergraph)是一种扩展了传统图结构的数学模型,其核心特征在于超边(hyperedge)可以同时连接任意数量的节点,突破了普通图中边只能连接两个节点的限制。具体而言,一个超图可以形式化表示为三元组G=(X,E,P),其中X={x₁,x₂,…,xₙ}表示节点集合,E={e₁,e₂,…,eₘ}是由多个超边组成的集合,而P∈ℝ{m×m}是一个可选的对角矩阵,用于表示各超边的权重。这种结构通过关联矩阵H∈{0,1}{n×m}来精确描述节点与超边的隶属关系,其中矩阵元素H_{i,j}取值为1当且仅当节点x_i属于超边e_j。超图的这种高阶表达能力使其特别适合建模复杂的多元关联关系,在文本-视频检索等需要处理多模态关联的任务中展现出独特优势。
超图是一种特殊的图结构,其核心特征在于能够通过超边(hyperedges)连接两个或多个节点,常用于表示多元关联[10]。形式上,超图定义为 G = ( X , E , P ) G=(X,\mathcal{E},\mathcal{P}) G=(X,E,P),包含三个组成部分:节点集 X = { x 1 , x 2 , … , x n } X=\{x_1,x_2,\ldots,x_n\} X={x1,x2,…,xn}、超边集 E = { e 1 , … , e m } \mathcal{E}=\{e_1,\ldots,e_m\} E={e1,…,em},以及可选的超边权重对角矩阵 P ∈ R m × m \boldsymbol{P}\in\mathbb{R}^{m\times m} P∈Rm×m。该结构可通过关联矩阵 H ∈ { 0 , 1 } n × m H\in\{0,1\}^{n\times m} H∈{0,1}n×m表示,其中每个元素 H i , j H_{i,j} Hi,j定义为:当节点 x i x_i xi属于超边 e j e_j ej时取值为1,否则为0。这种表示方法能有效捕捉复杂的高阶关联关系。
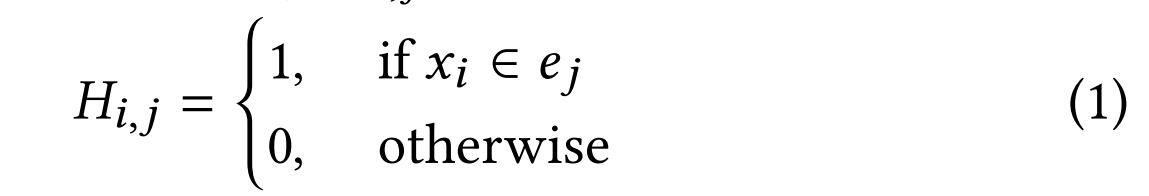
通过这种方式,每条超边 e j e_j ej连接所有相关节点 x i x_i xi,从而揭示它们之间的关联性。本文采用超图概念来表征文本内容与视觉内容之间的多元关联,为建立语义块之间的复杂关联关系提供了强有力的建模工具。
3 OUR FRAMEWORK
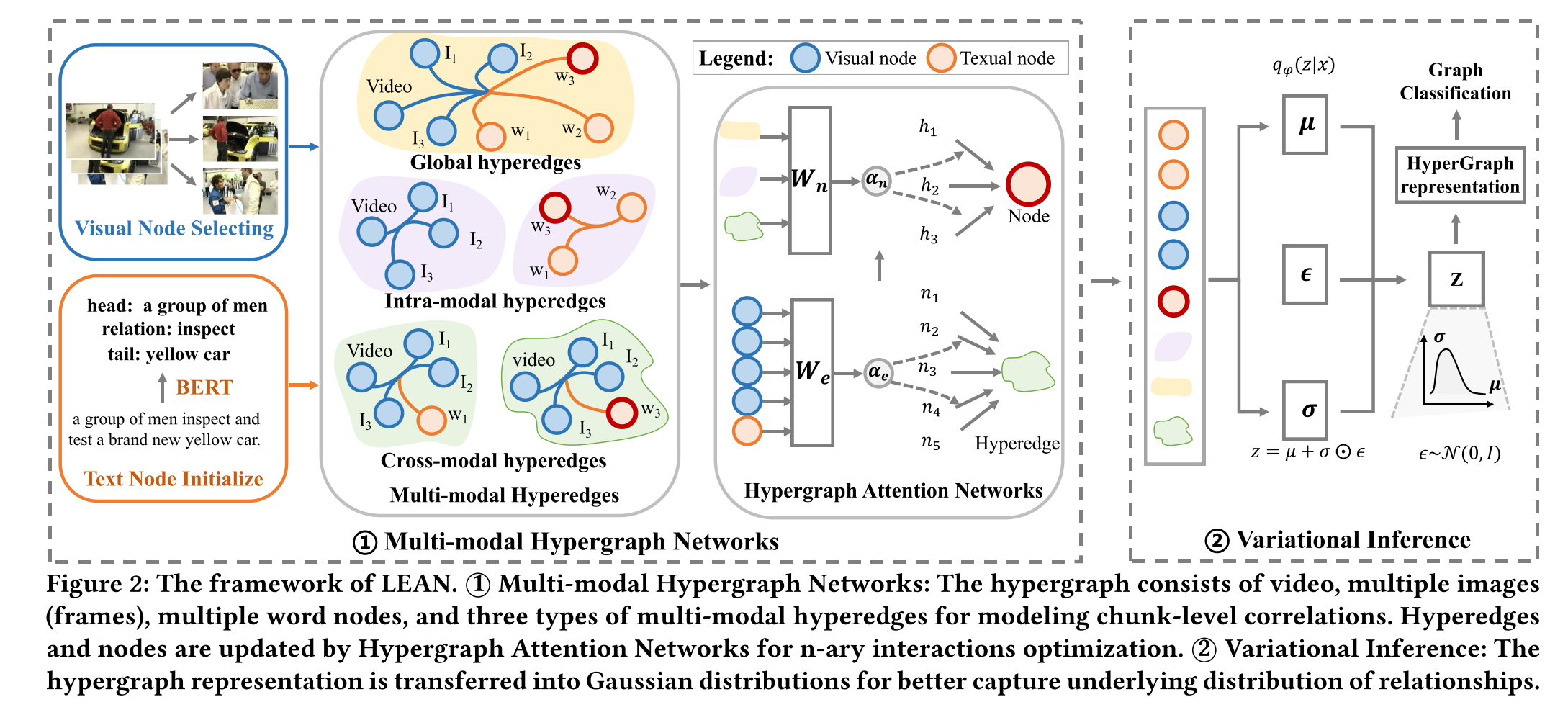
本节介绍我们提出的多模态超图变分推理网络(LEAN)框架,用于解决文本-视频检索任务。如图2所示,LEAN包含两大核心模块:多模态超图网络和变分推理模块。在多模态超图网络模块中,我们为每个文本查询和视频构建多模态超图,通过将文本单元和视频帧表示为节点、利用超边刻画其关联关系,有效捕捉不同模态间的多元关联,从而缓解多模态数据匹配的挑战。为了获得最优超图结构,模型自动学习超图权重,以捕获文本与视觉模态间的潜在关联。变分推理模块将超图表征转化为高斯分布,这一设计显著增强了模型在跨模态场景下的泛化能力,从而获得更精准的检索预测结果。
3.1 Multi-Modal Hypergraph Networks
文本-视频检索需要从文本和视觉双模态中提取关联关系。为有效捕捉不同模态间复杂的高阶关联,我们提出多模态超图网络模块,该模块通过利用多元关键关联来促进高阶关系的理解。具体而言,该模块包含三个核心组件:节点选择与初始化、多模态超边构建以及超图注意力网络。
3.1.1 Node Selecting and Initialization.
为增强文本与视频信息的融合,我们选择性地将关键内容指定为超图节点。设输入视频为 V \mathcal{V} V,对应文本查询为 S \mathcal{S} S,该多模态超图包含视觉节点和文本节点两类基础节点。
对于视觉节点的处理,我们采用多种关键帧检测方法,选取视频内容差异显著的帧作为补充视觉信息。设 I = I 1 , I 2 , . . . , I m I={I_1,I_2,...,I_m} I=I1,I2,...,Im表示视频 V V V中检测到的帧集合,这些帧通过VGG16网络进行初始化,具体方式如下:
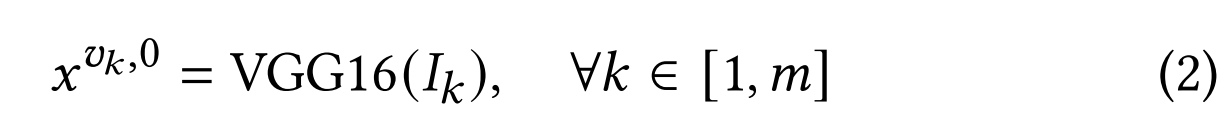
在文本节点处理方面,我们选取三元组(文本块)作为构建超图的节点。具体而言,首先利用Stanford CoreNLP工具 1 ^1 1识别句子中的三元组,随后采用BERT模型[6]学习这些三元组的上下文表征,并依下式对文本节点进行初始化:
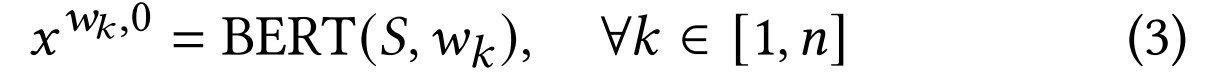 其中 x w k , 0 x^{w_k,0} xwk,0表示句子 S S S中单词 w k w_k wk的文本特征向量, w k w_k wk代表输入句子 S S S所选三元组中的第 k k k个单词, n n n为文本节点总数。
其中 x w k , 0 x^{w_k,0} xwk,0表示句子 S S S中单词 w k w_k wk的文本特征向量, w k w_k wk代表输入句子 S S S所选三元组中的第 k k k个单词, n n n为文本节点总数。
3.1.2 Multi-modal Hyperedges.
该多模态超图包含三类节点:视频节点、帧节点和文本节点。这些节点通过超边连接以建立多元关键关联。为捕捉文本与视频间的高阶相关性,我们设计了三种超边类型:全局超边(连接所有模态节点)、模态内超边(连接同模态节点)和跨模态超边(连接不同模态节点)。
Global hyperedges.
为推断节点间潜在的关联性与相似性,我们设计了全局超边。这类超边连接超图中所有节点,用于捕捉全模态间的全局关联。具体而言,我们将全局超边的输入定义为:
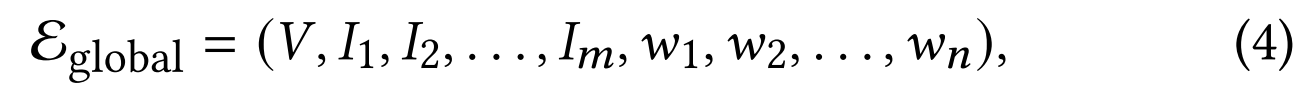
其中每条超边连接𝑚个视觉节点与𝑛个文本节点。
Intra-modal hyperedges.
为深化对文本和视觉内容的理解,我们设计了模态内超边。这类超边连接同一模态内的节点,用于捕捉各模态内部的关联性。具体而言,我们构建了两种模态内超边:一种连接文本节点,另一种连接视频节点与帧节点。模态内超边的定义如下:
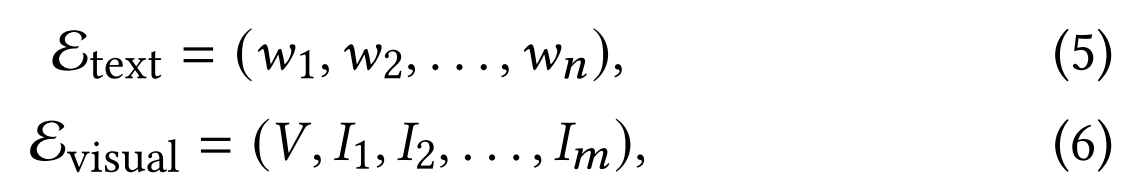
其中 E t e x t \mathcal{E}_\mathrm{text} Etext表示连接文本节点的模态内超边, E v i s u a l \mathcal{E}_\mathrm{visual} Evisual表示连接视频节点与前三关键帧的模态内超边。 w n w_{n} wn代表第 n n n个文本节点, I m I_m Im表示第 m m m个视觉节点。
Cross-modal hyperedges.
为揭示不同数据类型间的交互关系,我们设计了跨模态超边。这类超边连接不同模态的节点,用于捕捉跨模态关联。我们构建了𝑛类跨模态超边,其中文本节点与视频及𝑚个关键帧相连接。跨模态超边的定义如下:
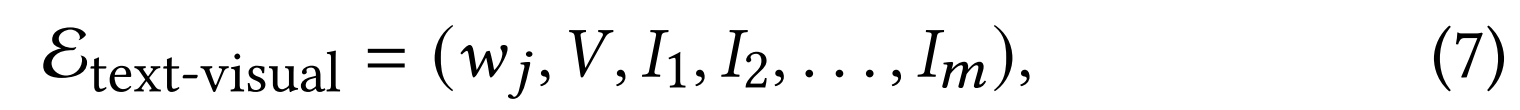
其中 E text-visual \mathcal{E}_\text{text-visual} Etext-visual表示连接文本节点 w j w_j wj与视频节点 V V V及帧节点 I i I_i Ii( i ∈ [ 1 , m ] i\in[1,m] i∈[1,m])的跨模态超边。
我们提出的多模态超图构建方法具有双重优势:其一,通过显式建模不同模态间的高阶关联,该模块能捕捉现有方法可能忽略的复杂关系;其二,由多词多帧构成的语义块能提供更具判别力的检索信号。
3.1.3 Hypergraph Attention Networks.
为增强超图结构的表征能力,我们提出超图注意力网络,该网络通过学习节点表征来实现节点与超边的协同更新。该网络包含两个核心组件:Hypergraph Encoder负责对超图中的节点进行编码,而Hypergraph Attention.模块则通过超边传播节点信息并更新节点表征。
Hypergraph Encoder.
超图编码器的设计旨在通过超边促进信息传播,使节点能够获取相邻节点的集体知识与特征。具体而言,节点更新的计算公式如下:
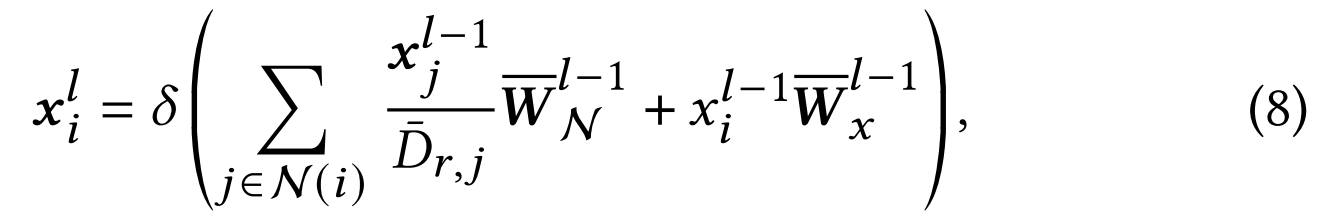
其中 x i l − 1 x_i^{l-1} xil−1表示第 l − 1 l-1 l−1层中节点 i i i的当前表征, W ‾ N l − 1 \overline{\boldsymbol{W}}_{\mathcal{N}}^{l-1} WNl−1和 W ‾ X l − 1 \overline{\boldsymbol{W}}_{\mathcal{X}}^{l-1} WXl−1为可学习参数, N ( i ) N(i) N(i)表示节点 i i i的邻域节点集合, D ˉ r , j \bar{D}_{r,j} Dˉr,j为节点 j j j的归一化因子。通过整合邻域节点信息来更新节点嵌入,这种考虑邻近节点集体知识与特征的方法,使得更新后的节点嵌入能包含更丰富的语义信息,从而有效捕捉超图结构的本质特征。
为深入理解超边在超图中的功能,我们通过整合连接节点的信息来更新超边嵌入。这一更新过程能够捕捉互连节点的集体知识与特征,从而更全面地理解超边的重要性。超边更新的计算公式如下:
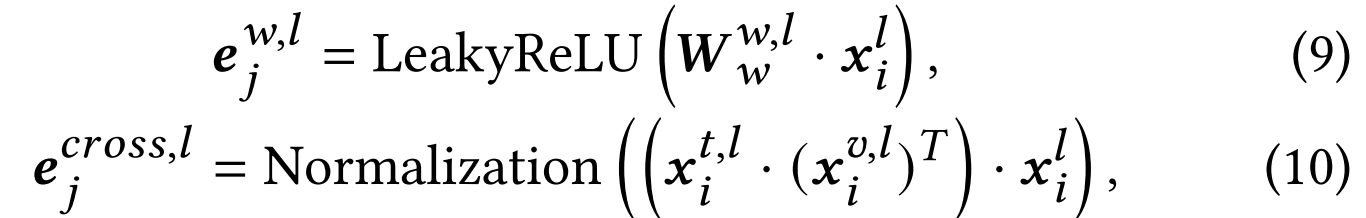
其中 w ∈ [ g , v , t ] w\in[g,v,t] w∈[g,v,t], x i g , l = x i l x_i^{g,l}=x_i^l xig,l=xil表示超边连接的所有节点表征的拼接, x i t , l \boldsymbol{x}_i^{t,l} xit,l为所有文本节点的拼接, x i υ , l \boldsymbol{x}_i^{\upsilon , l} xiυ,l为所有视觉节点的拼接。 e j g , l \boldsymbol{e}_j^{g,l} ejg,l、 e j v , l \boldsymbol{e}_j^{v,l} ejv,l、 e j t , l \boldsymbol{e}_j^{t,l} ejt,l和 e j c r o s s , l \boldsymbol{e}_j^{cross,l} ejcross,l分别表示全局超边、模态内超边和跨模态超边。 W w w , l \boldsymbol{W}_{w}^{w, l} Www,l为可学习参数。通过超边信息传播、嵌入更新和超边聚合等步骤,超图编码器能有效捕捉超图的内在结构与依赖关系,从而实现节点表征的精准更新,这有助于更全面地理解超图及其底层关联。
Hypergraph Attention.
超图注意力机制通过消息传递机制计算每条超边的注意力权重并更新节点表征。具体而言,超边 k k k的注意力权重 α k \alpha_k αk计算公式如下:
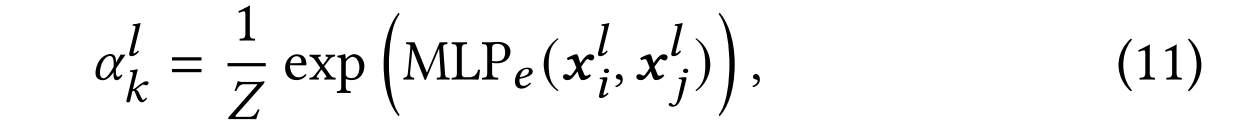
其中MLP e _e e为共享神经网络,用于计算超边 k k k所连接的节点 i i i与 j j j之间的相似度。 x i l x_i^l xil和 x j l x_j^l xjl分别表示第 l l l层中节点 i i i和 j j j的表征, Z Z Z为归一化因子。
通过超图注意力机制,节点i的更新表征通过聚合与其相连的所有超边信息来计算。具体计算公式如下:
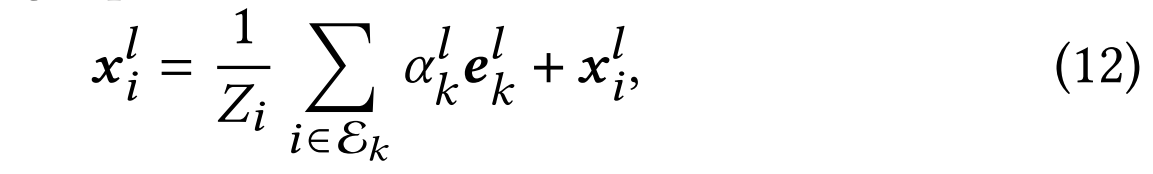
其中 E k \mathcal{E}_k Ek表示与节点 i i i相连的超边集合, e k l \boldsymbol{e}_k^l ekl为第 l l l层超边 k k k的表征, Z i Z_i Zi是归一化因子。该机制通过聚合相关超边信息来更新节点表征,有效捕捉超图内部的依赖关系与结构特征。
基于该注意力机制,超图网络通过整合相关超边与节点的特征来构建。其中超边特征通过注意力权重向量 α ~ k l = exp ( − γ x k l ) \tilde{\boldsymbol{\alpha}}_k^l=\exp(-\gamma x_k^l) α~kl=exp(−γxkl)计算获得,最终通过如下方式聚合超边得到全局表征:
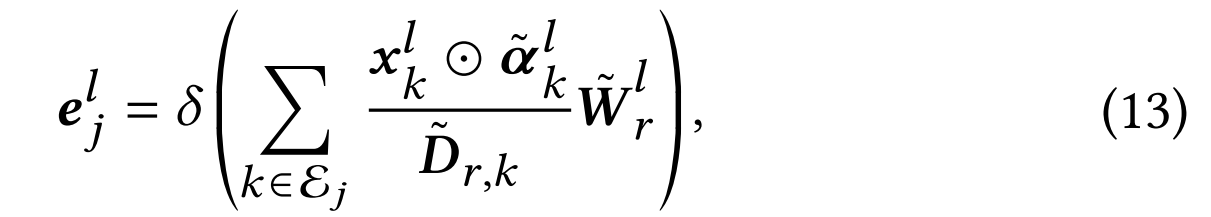
其中 D ~ r , k \tilde{\boldsymbol{D}}_{r,k} D~r,k为归一化因子。生成的节点特征融合了相关超边的特征信息,而生成的超边特征则整合了相关节点的特征信息。最终输出的节点特征记为 x k l \boldsymbol{x}_k^l xkl,该聚合过程充分考虑了连接节点及其关联权重的影响。
3.2 Variational Inference
在超图中构建文本节点和视觉节点后,节点的特征表示不仅受其自身嵌入向量的影响,还会受到邻域特征聚合的作用。这一过程往往伴随噪声干扰,可能损害节点的表征质量。高质量的节点嵌入对于实现查询与视频的对齐至关重要。通过变分推断方法,能够从潜在空间(而非观测空间)有效推断出隐变量的随机分布。
变分推断是提升模型泛化能力、生成高质量嵌入向量的强效方法。具体而言,我们基于图结构变分自编码器框架构建了超图变分自编码器,其模型结构如下:首先设计编码器模块,用于求解如下形式的隐变量𝒁:
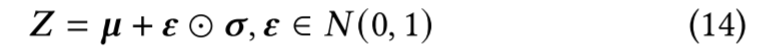
其中,
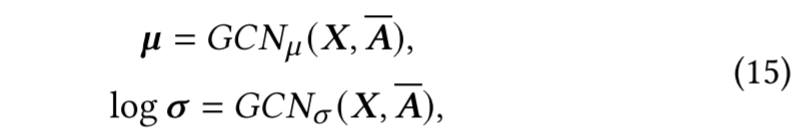
超图卷积网络GCN ( X , A ‾ ) ( X, \overline {A}) (X,A)的计算过程可以表示为 A ‾ ReLU ( A ‾ X W 0 ) \overline {A}\operatorname { ReLU} \left ( \overline {A}\mathbf{X} \boldsymbol{W}_{0}\right ) AReLU(AXW0),其中 A ‾ \overline {A} A是超图的对称归一化拉普拉斯矩阵,其具体形式为 D d − 1 2 H W D e − 1 2 H T D d − 1 2 D_{d}^{- \frac 12}\boldsymbol{HW}D_{e}^{- \frac 12}H^TD_{d}^{- \frac 12} Dd−21HWDe−21HTDd−21。这里 D d D_d Dd和 D e D_e De分别表示超图的节点度矩阵和超边度矩阵, H H H是邻接矩阵, W W W则是一个对角矩阵,其对角线元素为各超边的权重。值得注意的是,均值分支 G C N μ ( X , A ‾ ) GCN_{\mu }( \boldsymbol{X}, \overline {\boldsymbol{A}}) GCNμ(X,A)和方差分支 G C N σ ( X , A ‾ ) GCN_{\sigma }( \boldsymbol{X}, \overline {\boldsymbol{A}}) GCNσ(X,A)共享了第一层的权重参数 W 0 \boldsymbol{W}_0 W0。这种参数共享机制不仅提高了模型的参数效率,更重要的是能够将节点表征有效地映射到一个统一的潜在空间中,从而生成更具表达力的嵌入表示。
在完成上述模型构建后,我们可以基于超图模块中建立的结构进一步实施变分推断,从高斯分布的角度近似后验分布。当超图模块完成更新和学习后,我们将获得的图像与文本节点特征输入变分模块,通过变分推理得到新的特征表示。最终,这些特征被送入多层感知机(MLP)进行最终分类。图分类概率的计算过程如下所述:
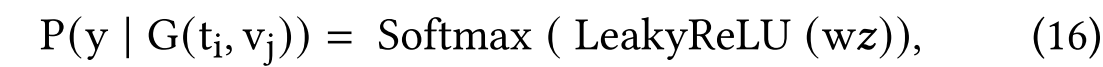
其中,w代表注意力参数, z = σ ( ∑ α i ⋅ h i ) z = \sigma(\sum \alpha_i \cdot h_i) z=σ(∑αi⋅hi)表示整个超图的表征向量, G ( t i , v j ) G(t_i, v_j) G(ti,vj)则是由第i个文本和第j个视频组合构成的超图结构。
与现有方法不同,我们通过融合文本和视觉数据构建超图结构,这使得传统损失计算方法不再适用。为此,我们采用图分类策略来评估模型性能。其中,文本-视频检索损失用于衡量预测结果与真实结果之间的误差,其具体计算方式如下(视频-文本检索损失的定义与之对称):
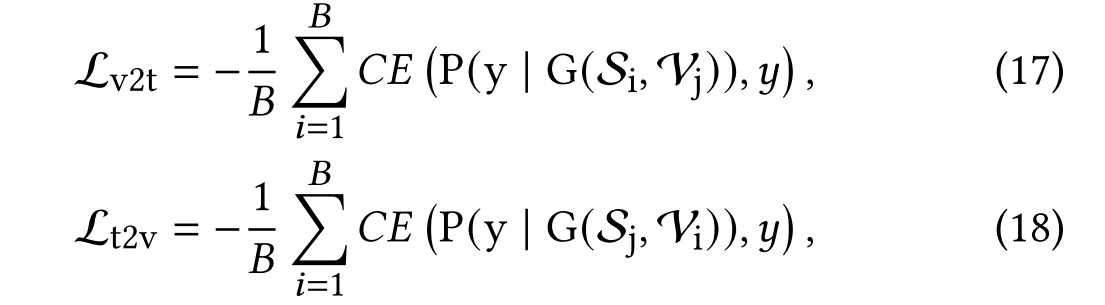
其中 C E CE CE表示交叉熵损失函数, S i S_i Si和 V i \mathcal{V}_i Vi分别代表第 i i i个输入的文本和视频数据, y y y为全局标签。在训练过程中,给定包含 B B B个视频-文本对的批次数据时,模型会生成一个 B × B B\times B B×B的相似度矩阵。
在我们的超图网络中,除了检索损失(retrieval loss)外,我们还引入了变分损失(variational loss):
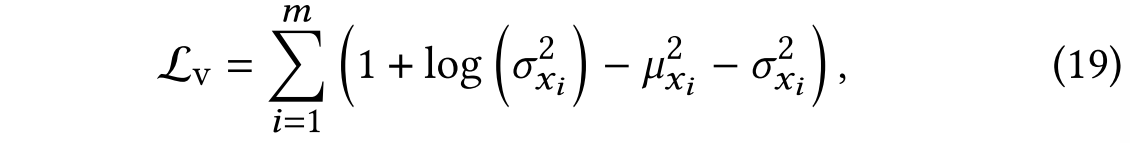
在LEAN模型中, L v \mathcal{L}_\mathrm{v} Lv表示用于衡量变分前后分布差异的KL散度损失(Kullback-Leibler loss)。
整体损失函数由以下三部分损失项加权求和构成:
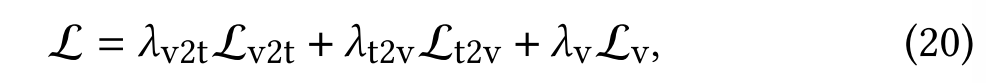
其中, λ v 2 t \lambda_{v2t} λv2t、 λ t 2 v \lambda_{t2v} λt2v和 λ v \lambda_{v} λv是用于控制各损失项相对权重的超参数。
4 EXPERIMENT
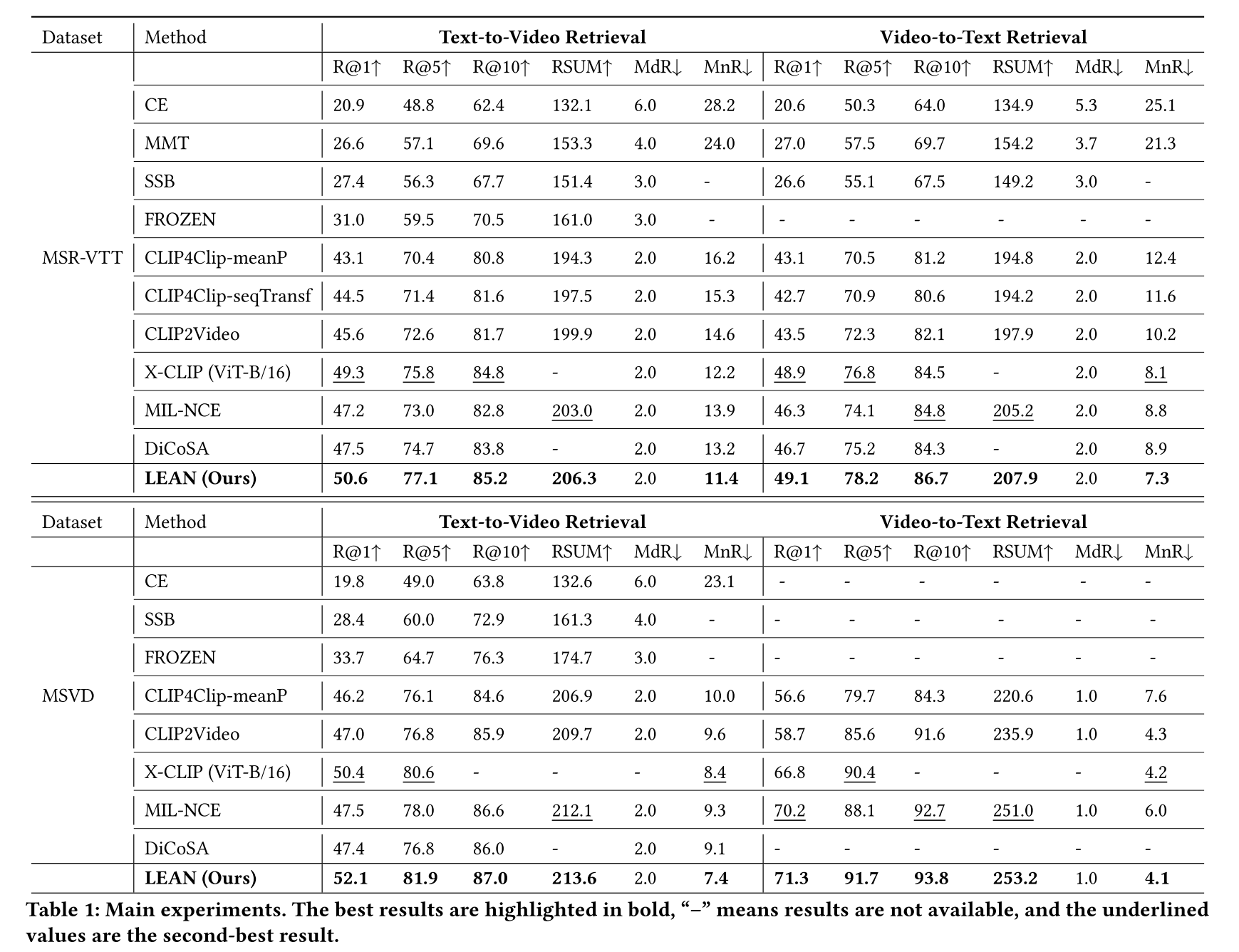

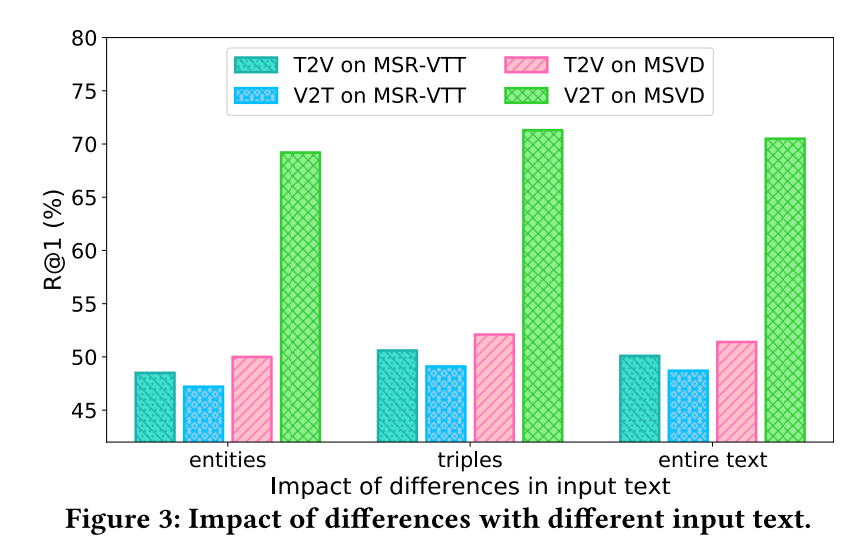
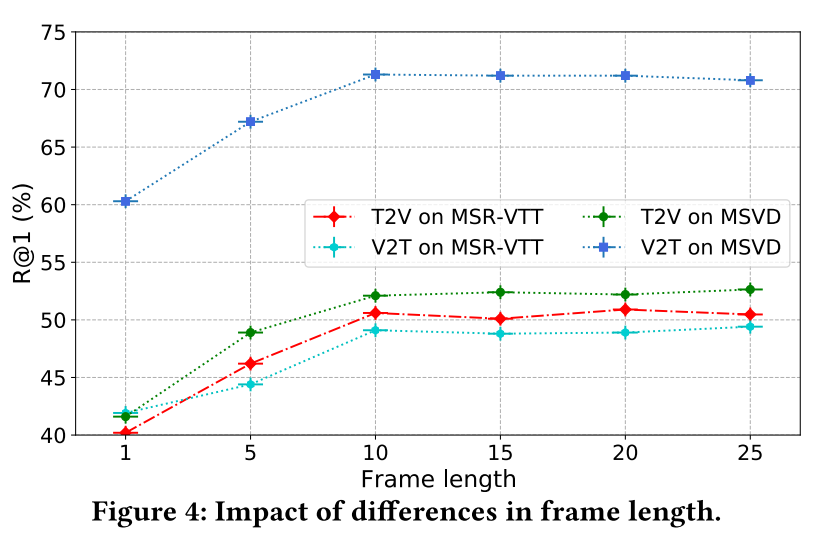
6 CONCLUSION
本文提出了一种新颖的文本-视频检索模型LEAN,该模型通过基于变分推断的多模态超图网络来捕捉片段级相关性。我们的方法通过为每个文本查询和视频构建多模态超图,从而捕获不同模态之间的多元交互关系。此外,为了学习最优的超图结构,我们的模型能够自动学习超图中超边和节点的权重。为了进一步提升模型的泛化能力,我们将提取的特征输入变分推断模块,获得高斯分布下的变分表征。这些技术的结合使我们的模型能够捕捉文本和视频之间的多元交互关系,并整合多种类型的相关性。实证实验表明,我们的方法有效融合了片段级相关性,并实现了最先进的性能表现。