Pascal VOC 2012 数据集格式与文件结构
Pascal VOC 2012
- 1 Pascal VOC 2012 数据集
- 1.1 数据集概述
- 1.2 文件结构
- 1.3 关键文件和内容格式
- (1) Annotations/ 目录
- (2) ImageSets/ 目录
- (3) JPEGImages/ 目录
- (4) SegmentationClass/ 和 SegmentationObject/ 目录
- 1.4 标注格式说明
- (1) 目标检测标注
- (2) 语义分割标注
- (3)实例分割标注说明
- 1.5 数据集的任务支持
- (1) 目标检测
- (2) 语义分割
- (3) 实例分割
- (4) 图像分类
- 1.6 总结
- 2 读取查看VOC 2012语义分割数据集
1 Pascal VOC 2012 数据集
Pascal VOC 2012 是计算机视觉领域中一个非常经典的数据集,广泛用于目标检测、语义分割、图像分类等任务。以下是 Pascal VOC 2012 数据集的格式和文件结构的详细介绍:
1.1 数据集概述
- 任务类型:支持目标检测、语义分割、动作识别、图像分类等。
- 类别数量:包含 20 个物体类别(如
aeroplane,bicycle,car等)以及一个背景类别。 - 图像数量:
- 训练集 + 验证集:共 11,530 张图像。
- 测试集:未公开标注,需提交结果到官方服务器进行评估。
1.2 文件结构
Pascal VOC 2012 的文件组织非常清晰,通常解压后会看到以下目录结构:
VOCdevkit/
└── VOC2012/├── Annotations/ # 存储目标检测的 XML 标注文件├── ImageSets/ # 存储不同任务的图像索引文件│ ├── Action/ # 动作识别任务的图像列表│ ├── Layout/ # 布局任务的图像列表│ ├── Main/ # 目标检测任务的图像列表│ └── Segmentation/ # 语义分割任务的图像列表├── JPEGImages/ # 存储原始图像文件(JPEG 格式)├── SegmentationClass/ # 存储语义分割的类别标签图(PNG 格式)└── SegmentationObject/ # 存储实例分割的对象标签图(PNG 格式)
1.3 关键文件和内容格式
(1) Annotations/ 目录
目录下包含了很多 XML 文件,如下图所示:
- 每张图像对应一个 XML 文件,存储目标检测的标注信息。
- XML 文件的内容包括:
- 图像的基本信息(文件名、尺寸等)。
- 每个目标的类别和边界框坐标(
xmin,ymin,xmax,ymax)。
示例 XML 文件内容:
<annotation><folder>VOC2012</folder><filename>2007_000032.jpg</filename><size><width>500</width><height>333</height><depth>3</depth></size><object><name>aeroplane</name><bndbox><xmin>104</xmin><ymin>78</ymin><xmax>375</xmax><ymax>183</ymax></bndbox></object>
</annotation>
(2) ImageSets/ 目录
- 包含不同任务的图像索引文件,用于划分训练集、验证集和测试集。
- 文件格式为纯文本,每行是一个图像的 ID(不带扩展名)。
常用子目录:
-
Segmentation/:语义分割任务的图像列表。
- 示例文件名:
train.txt,val.txt,trainval.txt。 - train.txt 文件图中的图片编号,表示已经被收入到训练集的图片,
val.txt,trainval.txt情况也是类似。
- 示例文件名:
-
Main/:目标检测任务的图像列表,分为训练集、验证集等。
- 示例文件名:
train.txt,val.txt,trainval.txt,以及物体名称_train/val/train_val.txt。 
- 示例内容(假设为aeroplane_train.txt文件):
- 示例文件名:
2008_000032 1
2008_000129 -1
2008_000130 0
...
- 标注标志的含义:- 1:表示该图像中存在目标类别(如飞机),并且标注是可靠的。- 0:表示该图像中不存在目标类别(如飞机)。- -1:表示该图像中可能存在目标类别,但标注不可靠或难以判断。
(3) JPEGImages/ 目录
- 存储所有原始图像文件(JPEG 格式)。
- 文件命名规则:
年份_编号.jpg,例如2007_000032.jpg。
(4) SegmentationClass/ 和 SegmentationObject/ 目录
- SegmentationClass/:存储语义分割的类别标签图。
- 每个像素的RGB值用来表示其所属的类别(共21个类别,0 表示背景,1-20 表示物体类别,但图像中并不是直接显示类别索引,而是有一个从RGB到类别的映射,可以通过本文第二章的程序来理解)。
- 文件格式为 PNG,无压缩。
# 图像中的物体类别
VOC_CLASSES = ['background', 'aeroplane', 'bicycle', 'bird', 'boat','bottle', 'bus', 'car', 'cat', 'chair', 'cow','diningtable', 'dog', 'horse', 'motorbike', 'person','potted plant', 'sheep', 'sofa', 'train', 'tv/monitor']# 每个类别对应的RGB值
VOC_COLORMAP = [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0],[0, 0, 128], [128, 0, 128], [0, 128, 128], [128, 128, 128],[64, 0, 0], [192, 0, 0], [64, 128, 0], [192, 128, 0],[64, 0, 128], [192, 0, 128], [64, 128, 128], [192, 128, 128],[0, 64, 0], [128, 64, 0], [0, 192, 0], [128, 192, 0],[0, 64, 128]]
- SegmentationObject/:存储实例分割的对象标签图。
- 每个对象都有唯一的 ID,用于区分不同的实例。
- 背景像素值为 0。
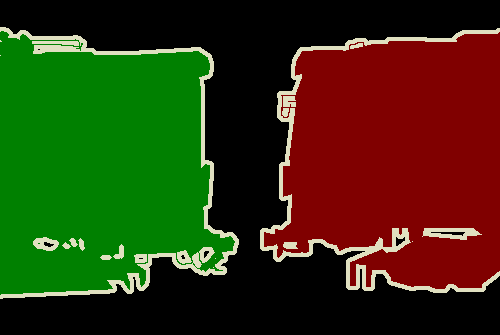
示例:
- 对于一张图像
2007_000042.jpg:- 类别标签图:
SegmentationClass/2007_000042.png - 实例标签图:
SegmentationObject/2007_000042.png
- 类别标签图:
原图 SegmentationClass/2007_000042.jpg:

类别标签图:

实例标签图(两个实例):
1.4 标注格式说明
(1) 目标检测标注
- 使用 XML 文件存储,主要字段包括:
<filename>:图像文件名。<size>:图像尺寸(宽、高、通道数)。<object>:每个目标的类别和边界框信息。<name>:类别名称。<bndbox>:边界框坐标(xmin,ymin,xmax,ymax)。
(2) 语义分割标注
- 使用 PNG 文件存储,不能使用JPEG,因为JPEG会压缩,要保证标注文件和原始文件有相同的分辨率
- 标注文件的相关内容,可以通过本文第二章的程序来理解。
(3)实例分割标注说明
-
假设有一张图像包含以下内容:
- 背景区域。
- 两个“人”(person)对象。
- 一辆“汽车”(car)。
-
对应的标签文件(png文件)中,内容如下:
- 背景区域的像素值为 0。
- 第一个人的像素值为 1。
- 第二个人的像素值为 2。
- 汽车的像素值为 3
实例分割不但要划分不同实例,还需要区分每个实例所属的类别,每个实例具体属于什么类别,需要去Annotations/下面的XML文件中确定,XML文件中的<name> </name>顺序即为 png 文件中的实例类别顺序。(XML三个目标的类别顺序分别是 person、person、car,那么分别对应png文件中的1、2、3的实例类别名)
<object><name>person</name><bndbox><xmin>104</xmin><ymin>78</ymin><xmax>375</xmax><ymax>183</ymax></bndbox>
</object>
<object><name>person</name><bndbox><xmin>400</xmin><ymin>100</ymin><xmax>500</xmax><ymax>250</ymax></bndbox>
</object>
<object><name>car</name><bndbox><xmin>200</xmin><ymin>300</ymin><xmax>400</xmax><ymax>400</ymax></bndbox>
</object>
1.5 数据集的任务支持
(1) 目标检测
- 使用
Annotations/中的 XML 文件和ImageSets/Main/中的图像列表。 - 每个目标的类别和边界框用于训练和评估目标检测模型。
(2) 语义分割
- 使用
SegmentationClass/中的类别标签图和ImageSets/Segmentation/中的图像列表。 - 评估指标通常采用 mIoU(mean Intersection over Union)。
(3) 实例分割
- 使用
SegmentationObject/中的实例标签图。 - 每个实例有唯一 ID,用于区分同一类别的不同对象。
(4) 图像分类
- 使用
ImageSets/Main/中的图像列表和 XML 文件中的类别信息。
1.6 总结
Pascal VOC 2012 数据集的文件结构清晰,格式规范,非常适合初学者和研究者使用。它的多任务支持(目标检测、语义分割、实例分割等)使其成为计算机视觉领域的基准数据集之一。在使用时,可以根据任务需求选择相应的标注文件和图像列表进行训练和评估。
2 读取查看VOC 2012语义分割数据集
以下内容是在notebook中运行得到,然后转化成Markdown并粘贴过来。
import os
import torch
import torchvision
import matplotlib.pyplot as plt
def read_voc_segmentation_images(voc_dir, is_train=True):"""读取VOC中用于语义分割的图像与标签"""# 获取包含图像名的 txt 文件txt_fname = os.path.join(voc_dir, 'ImageSets', 'Segmentation','train.txt' if is_train else 'val.txt')# 从 txt 文件中获取图像名(不含后缀)with open(txt_fname, 'r') as f:images = f.read().split()# 以RGB方式读取标签(标签被保存成了png格式)mode = torchvision.io.image.ImageReadMode.RGB# 获取图像与标签features, labels = [], []for i, fname in enumerate(images):img_path = os.path.join(voc_dir, 'JPEGImages', f'{fname}.jpg')image = torchvision.io.read_image(img_path)features.append(image)mask_path = os.path.join(voc_dir, 'SegmentationClass' ,f'{fname}.png')mask = torchvision.io.read_image(mask_path, mode)labels.append(mask)return features, labelsvoc_dir = r'./VOCdevkit/VOC2012'
train_features, train_labels = read_voc_segmentation_images(voc_dir, True)
n = 5
imgs = [img.permute(1, 2, 0).numpy() for img in train_features[0:n]] # 转换图像维度 (3, H, W) -> (H, W, 3)
labels = [label.permute(1, 2, 0).numpy() if len(label.shape) == 3 else label for label in train_labels[0:n]] # 确保标签形状正确# 创建图像网格
fig, axes = plt.subplots(2, n, figsize=(15, 6)) # 2 行 n 列# 显示图像和标签
for i in range(n):# 第一行:显示原始图像axes[0, i].imshow(imgs[i]) # 假设 imgs[i] 的值范围在 [0, 1] 或 [0, 255]axes[0, i].axis('off') # 关闭坐标轴axes[0, i].set_title(f"Image {i+1}")# 第二行:显示语义分割标签axes[1, i].imshow(labels[i], cmap='viridis') # 使用颜色映射显示标签axes[1, i].axis('off') # 关闭坐标轴axes[1, i].set_title(f"Class {i+1}")# 调整子图间距
plt.tight_layout()# 显示图像
plt.show()

第一张图片是飞机,标签的类别编号是1
"创建 类别-颜色映射"# 图像中的物体类别
VOC_CLASSES = ['background', 'aeroplane', 'bicycle', 'bird', 'boat','bottle', 'bus', 'car', 'cat', 'chair', 'cow','diningtable', 'dog', 'horse', 'motorbike', 'person','potted plant', 'sheep', 'sofa', 'train', 'tv/monitor']# 每个类别对应的RGB值
VOC_COLORMAP = [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0],[0, 0, 128], [128, 0, 128], [0, 128, 128], [128, 128, 128],[64, 0, 0], [192, 0, 0], [64, 128, 0], [192, 128, 0],[64, 0, 128], [192, 0, 128], [64, 128, 128], [192, 128, 128],[0, 64, 0], [128, 64, 0], [0, 192, 0], [128, 192, 0],[0, 64, 128]]标签也是图片,如果把图片中的每个像素拿出来,然后根据它的RGB组合去查该像素的类别,则需要很长的运行时间,因此这里考虑使用矩阵进行并行,所以有了下面两个函数:
def voc_colormap2label():"""构建从RGB值到VOC类别索引的映射"""# 先创建一个长度为 256 ** 3 的向量colormap2label = torch.zeros(256 ** 3, dtype=torch.long)# 将VOC_COLORMAP中的RGB组合转化成坐标轴上的点,实际上是把三位的点降成一维,# 然后在指定点上赋予类别索引for i, colormap in enumerate(VOC_COLORMAP):position_1d = (colormap[0] * 256 + colormap[1]) * 256 + colormap[2]colormap2label[position_1d] = ireturn colormap2labeldef voc_label_indices(label, colormap2label):"""将标签中每个像素点的RGB值映射到它们的类别索引"""label = label.permute(1, 2, 0).numpy().astype('int32')idx = ((label[:, :, 0] * 256 + label[:, :, 1]) * 256 + label[:, :, 2])return colormap2label[idx]
colormap2label = voc_colormap2label()
y = voc_label_indices(train_labels[0], colormap2label) # 查看第一张图片的label
y[105:115, 130:140], VOC_CLASSES[1] # 第一张图片的类别编号是1
(tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 1],[0, 0, 0, 0, 0, 0, 0, 1, 1, 1],[0, 0, 0, 0, 0, 0, 1, 1, 1, 1],[0, 0, 0, 0, 0, 1, 1, 1, 1, 1],[0, 0, 0, 0, 0, 1, 1, 1, 1, 1],[0, 0, 0, 0, 1, 1, 1, 1, 1, 1],[0, 0, 0, 0, 0, 1, 1, 1, 1, 1],[0, 0, 0, 0, 0, 1, 1, 1, 1, 1],[0, 0, 0, 0, 0, 0, 1, 1, 1, 1],[0, 0, 0, 0, 0, 0, 0, 0, 1, 1]]),'aeroplane')
0表示对应的像素是背景,1表示对应的像素是飞机。
能不能把上述矩阵不映射到RGB,而是直接保存成一个通道?当然是可以的,但这样我们查看标签文件的时候就不方便了,一个通道的图像是黑白的,0和1在灰度上看起来没差,另外,如果要表示的类别数超过256,一个通道就不够用了。