Python 网络请求利器:requests 包详解与实战
诸神缄默不语-个人技术博文与视频目录
文章目录
- 一、前言
- 二、安装方式
- 三、基本使用
- 1. 发起 GET 请求
- 2. 发起 POST 请求
- 四、requests请求调用常用参数
- 1. URL
- 2. 数据data
- 3. 请求头 headers
- 4. 参数 params
- 5. 超时时间 timeout
- 6. 文件上传 file:上传纯文本文件流
- 7. json
- 五. 响应的属性和函数
- 1. 属性:headers、cookies、编码格式
- 2. 异常处理:raise_for_status()
- 六、Session 会话对象(保持登录态)
- 七、进阶用法
- 1. 上传压缩文件
- 2. 并发
- 七、常见异常
- 1. requests.exceptions.JSONDecodeError
- 2. requests.exceptions.Timeout
- 3. requests.exceptions.ProxyError: HTTPSConnectionPool
- 八、实战案例:爬取豆瓣电影 Top250(示例)
- 本文撰写过程中参考的其他网络资料
一、前言
在进行网络编程或爬虫开发时,我们经常需要向网页或服务器发送 HTTP 请求,获取数据。这时,requests 包无疑是最受欢迎、最简洁易用的 Python 库之一。
相比原生的 urllib 模块,requests 提供了更人性化的 API,更容易上手,几乎成为了网络请求的“标准库”。
本文将介绍 requests 的基本用法、进阶操作以及常见问题处理,配合实际代码演示,带你快速掌握这个神器!
https://httpbin.org/是一个简单的用来模拟各种HTTP服务请求的网站,以下很多代码示例都会用这个网站的链接来实现。
因为这个网站部署在海外,所以可能会出现网络访问的问题,可以通过部署到本地来解决。部署到本地可以参考官方教程,或者这篇博文:五、接口测试 — Httpbin介绍(请求调试工具) - 知乎
二、安装方式
pip install requests
三、基本使用
关于get请求和post请求的区别请参考我撰写的另一篇博文:Web应用中的GET与POST请求详解
1. 发起 GET 请求
import requestsresponse = requests.get('https://httpbin.org/get')
print(response.status_code) # 状态码
print(response.text) # 响应内容(字符串)
print(response.json()) # 如果是 JSON,解析成字典
2. 发起 POST 请求
payload = {'username': 'test', 'password': '123456'}
response = requests.post('https://httpbin.org/post', data=payload)
print(response.json())
四、requests请求调用常用参数
1. URL
就是第一个参数,网站的链接地址
2. 数据data
请求携带的数据。
如果值是字符串或字节流,默认不设置Content-Type会设置。
如果值是字典、元组组成的列表或列表对象,会默认Content-Type会设置为application/x-www-form-urlencoded,也就是HTML表单形式的键值对数据。(对Content-Type的详细介绍请见下一节headers参数)
import requests
import jsonpayload = {"key1": "value1", "key2": "value2"}# String payload in json format
r = requests.post("https://httpbin.org/post", data="a random sentence")
print(r.json())
print(r.json()["headers"].get("Content-Type","None"))# String payload in json format
r = requests.post("https://httpbin.org/post", data=json.dumps(payload))
print(r.json())
print(r.json()["headers"].get("Content-Type","None"))# String payload in json content type
r = requests.post("https://httpbin.org/post",data=json.dumps(payload),headers={"Content-Type": "application/json"},
)
print(r.json())
print(r.json()["headers"].get("Content-Type","None"))# Dictionary payload
r = requests.post("https://httpbin.org/post", data=payload)
print(r.json())
print(r.json()["headers"].get("Content-Type","None"))# List of tuples payload
payload_tuples = [("key1", "value1"), ("key2", "value2")]
r = requests.post("https://httpbin.org/post", data=payload_tuples)
print(r.json())
print(r.json()["headers"].get("Content-Type","None"))# Bytes payload
payload_bytes = "key1=value1&key2=value2".encode("utf-8")
r = requests.post("https://httpbin.org/post", data=payload_bytes)
print(r.json())
print(r.json()["headers"].get("Content-Type","None"))
3. 请求头 headers
一般会携带请求的Content-Type、系统信息(如使用的设备、编码方式等)、认证信息、时间戳等
headers = {'User-Agent': 'MyUserAgent/1.0'}
response = requests.get('https://httpbin.org/headers', headers=headers)
print(response.json())
Content-Type的常见类型:
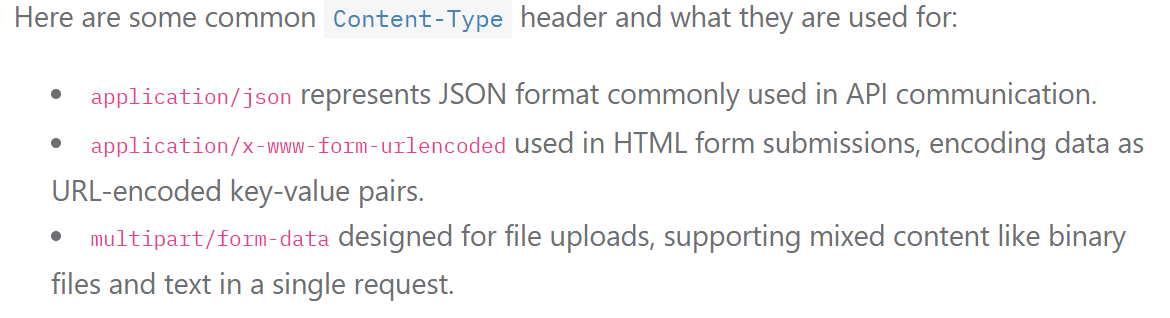
(图源1)
4. 参数 params
这个在get请求中的效果就类似于直接在URL后面加?k=v
params = {'q': 'python'}
response = requests.get('https://httpbin.org/get', params=params)
print(response.url) # 实际请求的完整 URL
输出:https://httpbin.org/get?q=python
5. 超时时间 timeout
response = requests.get('https://httpbin.org/delay/3', timeout=2)
如果超过2秒没响应,会抛出
requests.exceptions.Timeout异常。
6. 文件上传 file:上传纯文本文件流
files = {'file': open('test.txt', 'rb')}
response = requests.post('https://httpbin.org/post', files=files)
print(response.text)
↑ 需要注意的是虽然file参数确实可以直接这么传文件流……但我没咋见过真这么干的。
一般纯文本不用file传,一般都直接塞data里面带过去。
非纯文本文件流(二进制字节流),我一般看比较多的传输方式是把字节流转换为base64编码塞到data里带。用base64编码的代码可参考我写的另一篇博文:深入理解 Python 的 base64 模块
(不过说实话直接用file参数传文件流好像实际上背后也经过了base64编码-解码的过程,但是大家都这么干一定有大家的道理)
7. json
用json参数传JSON对象(在Python 3中表现为字典对象)就相当于用data参数传JSON对象、然后显示设置Content-Type为application/json
payload = {'id': 1, 'name': 'chatgpt'}
response = requests.post('https://httpbin.org/post', json=payload)
print(response.json())
上面这个请求和下面这个请求是一样的:
response = requests.post("https://httpbin.org/post",data=json.dumps(payload),headers={"Content-Type": "application/json"},
)
print(response.json())
作为对比可以看看另外两种请求参数格式的效果(可以注意到第一种写法返回的data和json值好歹还是一样的,第二种写法的话对象就放到form里了,因为是以表单对象形式来解析的):
response = requests.post("https://httpbin.org/post",data=json.dumps(payload)
)
print(response.json())response = requests.post("https://httpbin.org/post",data=payload
)
print(response.json())
五. 响应的属性和函数
1. 属性:headers、cookies、编码格式
r = requests.get('https://httpbin.org/get')
print(r.headers)
print(r.cookies)
print(r.encoding)
2. 异常处理:raise_for_status()
如果status_code不是200就报错
六、Session 会话对象(保持登录态)
requests.Session() 可以模拟保持会话,适合需要登录认证的网站。
s = requests.Session()
s.post('https://httpbin.org/cookies/set', data={'cookie': 'value'})
response = s.get('https://httpbin.org/cookies')
print(response.text)
七、进阶用法
1. 上传压缩文件
- gzip实现
import requests import gzip import jsondata = json.dumps({'key': 'value'}).encode('utf-8') compressed_data = gzip.compress(data)headers = {'Content-Encoding': 'gzip'}response = requests.post('https://httpbin.dev/api', data=compressed_data, headers=headers) response.raise_for_status()print("Gzip Compressed Request Status:", response.status_code) - brotli实现
import requests import brotlidata = json.dumps({'key': 'value'}).encode('utf-8') compressed_data = brotli.compress(data)headers = {'Content-Encoding': 'br'}response = requests.post('https://httpbin.dev/api', data=compressed_data, headers=headers) response.raise_for_status()print("Brotli Compressed Request Status:", response.status_code)
2. 并发
- httpx实现(来源于Concurrency vs Parallelism)
import asyncio import httpx import time# Asynchronous function to fetch the content of a URL async def fetch(url):async with httpx.AsyncClient(timeout=10.0) as client:response = await client.get(url)return response.text# Concurrently fetch multiple URLs using asyncio.gather async def concurrent_fetch(urls):tasks = [fetch(url) for url in urls]return await asyncio.gather(*tasks)# Synchronous version to demonstrate performance difference def sync_fetch(urls):results = []for url in urls:response = httpx.get(url)results.append(response.text)return resultsdef run_concurrent():urls = ["http://httpbin.org/delay/2"] * 100 # Use the same delay for simplicitystart_time = time.time()# Running fetch requests concurrentlyasyncio.run(concurrent_fetch(urls))duration = time.time() - start_timeprint(f"Concurrent fetch completed in {duration:.2f} seconds")def run_sync():urls = ["http://httpbin.org/delay/2"] * 100 # Use the same delay for simplicitystart_time = time.time()# Running fetch requests synchronouslysync_fetch(urls)duration = time.time() - start_timeprint(f"Synchronous fetch completed in {duration:.2f} seconds")if __name__ == "__main__":print("Running concurrent version:")# Concurrent fetch completed in 2.05 secondsrun_concurrent()print("Running synchronous version:")# Synchronous fetch completed in 200.15 secondsrun_sync() - threading实现
import threading import requestsdef post_data(data):requests.post('https://httpbin.dev/api', json=data)# Sample data list data_list = [{'name': 'User1'}, {'name': 'User2'}]threads = [] for data in data_list:thread = threading.Thread(target=post_data, args=(data,))threads.append(thread)thread.start()for thread in threads:thread.join()
关于并发的相关知识也可以参考我写的另一篇博文:Python中的并发与并行
七、常见异常
1. requests.exceptions.JSONDecodeError
如果response带的报文不是JSON,还调用response.json()函数,会报requests.exceptions.JSONDecodeError错误,完整的报错信息类似这样:
Traceback (most recent call last):File "myenv_path\Lib\site-packages\requests\models.py", line 974, in jsonreturn complexjson.loads(self.text, **kwargs)^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "myenv_path\Lib\json\__init__.py", line 346, in
loadsreturn _default_decoder.decode(s)^^^^^^^^^^^^^^^^^^^^^^^^^^File "myenv_path\Lib\json\decoder.py", line 337, in decodeobj, end = self.raw_decode(s, idx=_w(s, 0).end())^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "myenv_path\Lib\json\decoder.py", line 355, in raw_decoderaise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)During handling of the above exception, another exception occurred:Traceback (most recent call last):File "tryrequests1.py", line 6, in <module>print(response.json()) # 如果是 JSON,解析成字典^^^^^^^^^^^^^^^File "myenv_path\Lib\site-packages\requests\models.py", line 978, in jsonraise RequestsJSONDecodeError(e.msg, e.doc, e.pos)
requests.exceptions.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
2. requests.exceptions.Timeout
等待请求返回结果的时长超过了timeout参数设置的时长。
3. requests.exceptions.ProxyError: HTTPSConnectionPool
访问URL失败。
有时候网络服务不稳定是临时的,直接重试几次就行。重试的策略可以参考我撰写的另一篇博文:Python3:在访问不可靠服务时的重试策略(持续更新ing…)
一个典型的由于临时的网络不稳定而产生的访问失败报错输出全文:
Traceback (most recent call last):File "myenv_path\Lib\site-packages\urllib3\connectionpool.py", line 789, in urlopenresponse = self._make_request(^^^^^^^^^^^^^^^^^^^File "myenv_path\Lib\site-packages\urllib3\connectionpool.py", line 536, in _make_requestresponse = conn.getresponse()^^^^^^^^^^^^^^^^^^File "myenv_path\Lib\site-packages\urllib3\connection.py", line 507, in getresponsehttplib_response = super().getresponse()^^^^^^^^^^^^^^^^^^^^^File "myenv_path\Lib\http\client.py", line 1374, in getresponseresponse.begin()File "myenv_path\Lib\http\client.py", line 318, in beginversion, status, reason = self._read_status()^^^^^^^^^^^^^^^^^^^File "myenv_path\Lib\http\client.py", line 287, in _read_statusraise RemoteDisconnected("Remote end closed connection without"
http.client.RemoteDisconnected: Remote end closed connection without responseThe above exception was the direct cause of the following exception:urllib3.exceptions.ProxyError: ('Unable to connect to proxy', RemoteDisconnected('Remote end closed connection without response'))The above exception was the direct cause of the following exception:Traceback (most recent call last):File "myenv_path\Lib\site-packages\requests\adapters.py", line 667, in sendresp = conn.urlopen(^^^^^^^^^^^^^File "myenv_path\Lib\site-packages\urllib3\connectionpool.py", line 843, in urlopenretries = retries.increment(^^^^^^^^^^^^^^^^^^File "myenv_path\Lib\site-packages\urllib3\util\retry.py", line 519, in incrementraise MaxRetryError(_pool, url, reason) from reason # type: ignore[arg-type]^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='httpbin.org', port=443): Max retries exceeded with url: /cookies (Caused by ProxyError('Unable to connect to proxy', RemoteDisconnected('Remote end
closed connection without response')))During handling of the above exception, another exception occurred:Traceback (most recent call last):File "tryrequests1.py", line 5, in <module>response = s.get('https://httpbin.org/cookies')^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "myenv_path\Lib\site-packages\requests\sessions.py", line 602, in getreturn self.request("GET", url, **kwargs)^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "myenv_path\Lib\site-packages\requests\sessions.py", line 589, in requestresp = self.send(prep, **send_kwargs)^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "myenv_path\Lib\site-packages\requests\sessions.py", line 703, in sendr = adapter.send(request, **kwargs)^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "myenv_path\Lib\site-packages\requests\adapters.py", line 694, in sendraise ProxyError(e, request=request)
requests.exceptions.ProxyError: HTTPSConnectionPool(host='httpbin.org', port=443): Max retries exceeded
with url: /cookies (Caused by ProxyError('Unable to connect to proxy', RemoteDisconnected('Remote end closed connection without response')))
八、实战案例:爬取豆瓣电影 Top250(示例)
import requests
from bs4 import BeautifulSoupheaders = {'User-Agent': 'Mozilla/5.0'}for start in range(0, 250, 25):url = f'https://movie.douban.com/top250?start={start}'r = requests.get(url, headers=headers)soup = BeautifulSoup(r.text, 'html.parser')titles = soup.find_all('span', class_='title')for title in titles:print(title.text)
本文撰写过程中参考的其他网络资料
- What is the difference between the ‘json’ and ‘data’ parameters in Requests? | WebScraping.AI
- python requests.post() 请求中 json 和 data 的区别 - 小嘉欣 - 博客园
- Python requests.post()方法中data和json参数的使用_requests.post中data和json是否可以同时设置-CSDN博客

Python requests POST ↩︎