MOTR: End-to-End Multiple-Object Tracking with Transformer
多目标跟踪MOTR: End-to-End Multiple-Object Tracking with TRansformer_目标跟踪_qq_1041357701-开放原子开发者工作坊
https://blog.csdn.net/ZauberC/article/details/124553241
简介:
时间:2021
会议:ECCV
作者:Fangao Zeng, Bin Dong, Yuang Zhang, Tiancai Wang,Xiangyu Zhang, and Yichen Wei
摘要:
扩展了 DETR并引入了 “track query” 来对整个视频中的跟踪实例进行建模
提出了 tracklet 感知标签分配来训练 track 查询和新生对象查询
创新点:
①提出MOTR 完全端到端的 MOT 框架,可以以联合方式隐式学习外观和位置差异
②将 MOT 表述为序列预测集的问题,从之前的隐藏状态生成跟踪查询,用于迭代更新和预测
③ 提出了一种新的标签分配策略TALA,用于训练跟踪查询和新出现对象查询
④提出 TAN ,通过聚合历史状态信息,增强了对长时间序列的建模能力
⑤提出了一种新的损失函数CAL,用于在训练过程中考虑整个视频序列
与DETR对比:

DETR:
针对于目标检测
对象查询与图像特征交互,通过DETR Decoder后输出边界框
一对一,每个对象查询一个边界框
object query只是对一个区域目标负责,并不具体到id级别

MOTR:
针对于多目标跟踪
通过DETR解码器迭代更新(Iterative Update)
每个track query代表一个跟踪的目标
MOTR:
总体工作流程:
原论文图示

用于视频流中多目标跟踪的MOTR流程:

视频流中有连续的帧
对于第1帧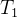 :
:
①通过卷积神经网络(CNN)骨干网络和DETR编码器(Enc),用于提取每帧的图像特征,帧的特征为
②用DETR提取到检测结果为detect query,记为,
仅包含该帧新出现的目标
③将和
输入到Decoder中,产生原始的轨迹查询
④经过查询交互模块QIM后,变成track query
⑤用来预测生成最终的
,包含当前帧的全部信息
对于第i帧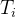 :
:
①CNN和可变形DETR编码器(Enc)提取每帧的图像特征,帧的特征为
②接收帧QIM输出的
并且与
一同输入到Decoder,产生原始的轨迹查询
,而这个
会被输入到QIM中生成为下一帧参考的
③用来预测生成最终的
,包含当前帧的全部信息
④进行完N帧的跟踪后,最终生成,利用GT
和CAL进行优化
QIM和TALA:
QIM:
QIM 包括对象进入和退出机制以及时间聚合网络 (TAN)
QIM相当于一个桥梁, 其将上一帧的信息传递给下一帧

输入:Transformer隐状态+相应预测的分数
出入:
object entrance:保留高分数

object exit:删除低分数

TAN:
用于处理Transformer的隐状态并更新状态输出;增强时间关系建模并为跟踪对象提供上下文先验


通过聚合时间信息更新跟踪查询,为下一帧提供信息
输入为隐状态
TALA:
对于检测查询,我们将 DETR 中的分配策略修改为仅限当前帧新检测的目标;对于跟踪查询,设计了目标一致的分配策略,预测所有被跟踪的对象。

过程:
①Track Query初始化为空

②跟踪查询集动态更新,长度可变;检测到新对象,每个检测的对象都会产生一个跟踪查询加入Track Query
例如像第一帧中检测到object1和object2,就会产生跟踪查询加入到Track Query

例如object1和object3(新)的隐藏状态更新Track Query

③不被检测到的移除,例如像object2在第四帧消失,Track Query中就将其删除

公式:
对于第帧,检测查询的标签分配是通过检测查询和新出现对象之间的二分图匹配获得的

对于(不是第一帧),将上一帧跟踪对象和新出现对象的分配结果合并

CAL:
CAL 是整个视频序列的总体损失,按对象数量进行标准化

