LLMs之PDF:zeroX(一款PDF到Markdown 的视觉模型转换工具)的简介、安装和使用方法、案例应用之详细攻略
LLMs之PDF:zeroX(一款PDF到Markdown 的视觉模型转换工具)的简介、安装和使用方法、案例应用之详细攻略
目录
zeroX的简介
1、支持的文件类型
zeroX的安装和使用方法
T1、Node.js 版本:
安装
使用方法
使用文件 URL:
使用本地路径:
示例输出
T2、Python 版本
安装
使用方法
示例输出(来自“azure/gpt-4o-mini”的输出)
zeroX的案例应用
1、测试手写稿
zeroX的简介
Zerox 是一个简单易用的 PDF 到 Markdown 转换工具,它利用视觉模型(例如 OpenAI 的 GPT 模型)来处理文档的 OCR(光学字符识别)并将其转换为 Markdown 格式。 它能够处理各种复杂的文档布局,包括表格、图表等,这得益于其基于视觉模型的处理方式。 Zerox 的核心逻辑是:将输入文件(PDF、docx、图像等)转换为一系列图像,然后将每个图像传递给 GPT 模型,请求生成 Markdown,最后将所有 Markdown 片段聚合起来返回最终结果。 该项目提供了一个在线演示版本:https://getomni.ai/ocr-demo。
官方地址:https://getomni.ai/ocr-demo
GitHub地址:https://github.com/getomni-ai/zerox
1、支持的文件类型
Zerox 使用 libreoffice 和 graphicsmagick 进行文档到图像的转换,支持以下文件类型
["pdf", // Portable Document Format"doc", // Microsoft Word 97-2003"docx", // Microsoft Word 2007-2019"odt", // OpenDocument Text"ott", // OpenDocument Text Template"rtf", // Rich Text Format"txt", // Plain Text"html", // HTML Document"htm", // HTML Document (alternative extension)"xml", // XML Document"wps", // Microsoft Works Word Processor"wpd", // WordPerfect Document"xls", // Microsoft Excel 97-2003"xlsx", // Microsoft Excel 2007-2019"ods", // OpenDocument Spreadsheet"ots", // OpenDocument Spreadsheet Template"csv", // Comma-Separated Values"tsv", // Tab-Separated Values"ppt", // Microsoft PowerPoint 97-2003"pptx", // Microsoft PowerPoint 2007-2019"odp", // OpenDocument Presentation"otp", // OpenDocument Presentation Template
];zeroX的安装和使用方法
Zerox 提供了 Node.js 和 Python 两种版本的软件包。
T1、Node.js 版本:
安装
使用 npm 安装
npm install zerox依赖: Zerox 使用 graphicsmagick 和 ghostscript 进行 PDF 到图像的转换。 这些依赖通常会自动安装,但你可能需要手动安装它们。在 Linux 系统上,可以使用以下命令:
sudo apt-get update
sudo apt-get install -y graphicsmagick使用方法
使用文件 URL:
import { zerox } from "zerox";const result = await zerox({filePath: "https://omni-demo-data.s3.amazonaws.com/test/cs101.pdf",openaiAPIKey: process.env.OPENAI_API_KEY,
});使用本地路径:
import path from "path";
import { zerox } from "zerox";const result = await zerox({filePath: path.resolve(__dirname, "./cs101.pdf"),openaiAPIKey: process.env.OPENAI_API_KEY,
});可选参数: zerox 函数接受许多可选参数,用于控制转换过程:
const result = await zerox({// RequiredfilePath: "path/to/file",openaiAPIKey: process.env.OPENAI_API_KEY,// Optionalcleanup: true, // Clear images from tmp after run.concurrency: 10, // Number of pages to run at a time.correctOrientation: true, // True by default, attempts to identify and correct page orientation.maintainFormat: false, // Slower but helps maintain consistent formatting.model: 'gpt-4o-mini' // Model to use (gpt-4o-mini or gpt-4o).outputDir: undefined, // Save combined result.md to a file.pagesToConvertAsImages: -1, // Page numbers to convert to image as array (e.g. `[1, 2, 3]`) or a number (e.g. `1`). Set to -1 to convert all pages.tempDir: "/os/tmp", // Directory to use for temporary files (default: system temp directory).trimEdges: true, // True by default, trims pixels from all edges that contain values similar to the given background colour, which defaults to that of the top-left pixel.
});cleanup: (boolean, 默认 true) 处理完成后是否清理临时文件。
concurrency: (integer, 默认 10) 并发处理的页面数量。
correctOrientation: (boolean, 默认 true) 是否尝试纠正页面方向。
maintainFormat: (boolean, 默认 false) 是否保持一致的格式 (较慢,但对于表格跨页等情况很有用)。
model: (string, 默认 'gpt-4o-mini') 使用的模型 ('gpt-4o-mini' 或 'gpt-4o')。
outputDir: (string, 可选) 保存合并后的 result.md 文件的目录。
pagesToConvertAsImages: (number 或 array, 可选) 需要转换为图像的页码,-1 表示所有页面。
tempDir: (string, 可选) 临时文件的目录。
trimEdges: (boolean, 默认 true) 是否修剪图像边缘。该maintainFormat选项尝试通过将前一页的输出作为下一页的附加上下文传递,以一致的格式返回 markdown。这需要请求同步运行,因此速度会慢很多。但如果您的文档包含大量表格数据,或者经常有跨页的表格,则此选项非常有用。
Request #1 => page_1_image
Request #2 => page_1_markdown + page_2_image
Request #3 => page_2_markdown + page_3_image示例输出
{completionTime: 10038,fileName: 'invoice_36258',inputTokens: 25543,outputTokens: 210,pages: [{content: '# INVOICE # 36258\n' +'**Date:** Mar 06 2012 \n' +'**Ship Mode:** First Class \n' +'**Balance Due:** $50.10 \n' +'## Bill To:\n' +'Aaron Bergman \n' +'98103, Seattle, \n' +'Washington, United States \n' +'## Ship To:\n' +'Aaron Bergman \n' +'98103, Seattle, \n' +'Washington, United States \n' +'\n' +'| Item | Quantity | Rate | Amount |\n' +'|--------------------------------------------|----------|--------|---------|\n' +"| Global Push Button Manager's Chair, Indigo | 1 | $48.71 | $48.71 |\n" +'| Chairs, Furniture, FUR-CH-4421 | | | |\n' +'\n' +'**Subtotal:** $48.71 \n' +'**Discount (20%):** $9.74 \n' +'**Shipping:** $11.13 \n' +'**Total:** $50.10 \n' +'---\n' +'**Notes:** \n' +'Thanks for your business! \n' +'**Terms:** \n' +'Order ID : CA-2012-AB10015140-40974 ',page: 1,contentLength: 747}]
}T2、Python 版本
安装
需要先安装 poppler-utils (确保在系统 PATH 变量中),然后使用 pip 安装
pip install py-zerox依赖: 依赖于 LiteLLM 库,支持多种视觉模型提供商 (OpenAI, Azure OpenAI, Anthropic, AWS Bedrock 等)。 需要配置相应的环境变量。 请参考 LiteLLM 文档:https://docs.litellm.ai/docs/providers
使用方法
该代码的核心思路是使用pyzerox库中的zerox函数来异步处理PDF文件,通过指定的AI模型提取文本内容,可选择性地处理特定页面,并将结果保存为Markdown文件,同时支持自定义系统提示和不同的AI服务提供商,如OpenAI、Azure OpenAI、Gemini、Anthropic和Vertex AI,通过环境变量或文件加载服务凭证。
zerox 函数的参数与 Node.js 版本类似,但 model 参数需要根据选择的模型提供商和模型名称进行调整。 custom_system_prompt 参数允许自定义系统提示,select_pages 参数允许选择需要处理的页面。
from pyzerox import zerox
import os
import json
import asyncio### Model Setup (Use only Vision Models) Refer: https://docs.litellm.ai/docs/providers ##### placeholder for additional model kwargs which might be required for some models
kwargs = {}## system prompt to use for the vision model
custom_system_prompt = None# to override
# custom_system_prompt = "For the below pdf page, do something..something..." ## example###################### Example for OpenAI ######################
model = "gpt-4o-mini" ## openai model
os.environ["OPENAI_API_KEY"] = "" ## your-api-key###################### Example for Azure OpenAI ######################
model = "azure/gpt-4o-mini" ## "azure/<your_deployment_name>" -> format <provider>/<model>
os.environ["AZURE_API_KEY"] = "" # "your-azure-api-key"
os.environ["AZURE_API_BASE"] = "" # "https://example-endpoint.openai.azure.com"
os.environ["AZURE_API_VERSION"] = "" # "2023-05-15"###################### Example for Gemini ######################
model = "gemini/gpt-4o-mini" ## "gemini/<gemini_model>" -> format <provider>/<model>
os.environ['GEMINI_API_KEY'] = "" # your-gemini-api-key###################### Example for Anthropic ######################
model="claude-3-opus-20240229"
os.environ["ANTHROPIC_API_KEY"] = "" # your-anthropic-api-key###################### Vertex ai ######################
model = "vertex_ai/gemini-1.5-flash-001" ## "vertex_ai/<model_name>" -> format <provider>/<model>
## GET CREDENTIALS
## RUN ##
# !gcloud auth application-default login - run this to add vertex credentials to your env
## OR ##
file_path = 'path/to/vertex_ai_service_account.json'# Load the JSON file
with open(file_path, 'r') as file:vertex_credentials = json.load(file)# Convert to JSON string
vertex_credentials_json = json.dumps(vertex_credentials)vertex_credentials=vertex_credentials_json## extra args
kwargs = {"vertex_credentials": vertex_credentials}###################### For other providers refer: https://docs.litellm.ai/docs/providers ####################### Define main async entrypoint
async def main():file_path = "https://omni-demo-data.s3.amazonaws.com/test/cs101.pdf" ## local filepath and file URL supported## process only some pages or allselect_pages = None ## None for all, but could be int or list(int) page numbers (1 indexed)output_dir = "./output_test" ## directory to save the consolidated markdown fileresult = await zerox(file_path=file_path, model=model, output_dir=output_dir,custom_system_prompt=custom_system_prompt,select_pages=select_pages, **kwargs)return result# run the main function:
result = asyncio.run(main())# print markdown result
print(result)参数
async def zerox(cleanup: bool = True,concurrency: int = 10,file_path: Optional[str] = "",maintain_format: bool = False,model: str = "gpt-4o-mini",output_dir: Optional[str] = None,temp_dir: Optional[str] = None,custom_system_prompt: Optional[str] = None,select_pages: Optional[Union[int, Iterable[int]]] = None,**kwargs
) -> ZeroxOutput:...参数
- cleanup(bool,可选):处理后是否清理临时文件。默认为 True。
- concurrency(int,可选):要运行的并发进程数。默认为 10。
- file_path(Optional[str],可选):要处理的 PDF 文件的路径。默认为空字符串。
- keep_format (bool, 可选):是否保留上一页的格式。默认为 False。
- model (str,可选):用于生成补全的模型。默认为“gpt-4o-mini”。请参阅 LiteLLM 提供程序以获取正确的模型名称,因为它可能因提供程序而异。
- output_dir (Optional[str], 可选): 保存 markdown 输出的目录。默认为 None。
- temp_dir (str,可选):存储临时文件的目录,默认为系统临时目录中的某个命名文件夹。如果已经存在,则在 zerox 使用它之前将删除其内容。
- custom_system_prompt (str,可选):模型使用的系统提示,它将覆盖 zerox 的默认系统提示。一般情况下,除非您想要某些特定行为,否则不需要它。设置后,它将发出友好警告。默认为 None。
- select_pages (Optional[Union[int, Iterable[int]]],可选):要处理的页面,可以是单个页码或可迭代的页码,默认为 None
- kwargs(字典,可选):传递给 litellm.completion 方法的附加关键字参数。有关详细信息,请参阅 LiteLLM 文档和完成输入。
返回
- ZeroxOutput:包含模型生成的 markdown 内容以及一些元数据(参见下文)。
示例输出(来自“azure/gpt-4o-mini”的输出)
ZeroxOutput(completion_time=9432.975,file_name='cs101',input_tokens=36877,output_tokens=515,pages=[Page(content='| Type | Description | Wrapper Class |\n' +'|---------|--------------------------------------|---------------|\n' +'| byte | 8-bit signed 2s complement integer | Byte |\n' +'| short | 16-bit signed 2s complement integer | Short |\n' +'| int | 32-bit signed 2s complement integer | Integer |\n' +'| long | 64-bit signed 2s complement integer | Long |\n' +'| float | 32-bit IEEE 754 floating point number| Float |\n' +'| double | 64-bit floating point number | Double |\n' +'| boolean | may be set to true or false | Boolean |\n' +'| char | 16-bit Unicode (UTF-16) character | Character |\n\n' +'Table 26.2.: Primitive types in Java\n\n' +'### 26.3.1. Declaration & Assignment\n\n' +'Java is a statically typed language meaning that all variables must be declared before you can use ' +'them or refer to them. In addition, when declaring a variable, you must specify both its type and ' +'its identifier. For example:\n\n' +'```java\n' +'int numUnits;\n' +'double costPerUnit;\n' +'char firstInitial;\n' +'boolean isStudent;\n' +'```\n\n' +'Each declaration specifies the variable’s type followed by the identifier and ending with a ' +'semicolon. The identifier rules are fairly standard: a name can consist of lowercase and ' +'uppercase alphabetic characters, numbers, and underscores but may not begin with a numeric ' +'character. We adopt the modern camelCasing naming convention for variables in our code. In ' +'general, variables must be assigned a value before you can use them in an expression. You do not ' +'have to immediately assign a value when you declare them (though it is good practice), but some ' +'value must be assigned before they can be used or the compiler will issue an error.\n\n' +'The assignment operator is a single equal sign, `=` and is a right-to-left assignment. That is, ' +'the variable that we wish to assign the value to appears on the left-hand-side while the value ' +'(literal, variable or expression) is on the right-hand-side. Using our variables from before, ' +'we can assign them values:\n\n' +'> 2 Instance variables, that is variables declared as part of an object do have default values. ' +'For objects, the default is `null`, for all numeric types, zero is the default value. For the ' +'boolean type, `false` is the default, and the default char value is `\\0`, the null-terminating ' +'character (zero in the ASCII table).',content_length=2333,page=1)]
)zeroX的案例应用
该项目提供了 cs101.pdf 作为示例文件。 转换后的 Markdown 输出包含了文档的标题、表格、以及文本内容,准确地反映了原文档的结构和信息。
maintainFormat 参数对于处理表格跨页等复杂布局的文档非常有用。输出结果中包含 completionTime, fileName, inputTokens, outputTokens 和 pages 等元数据信息,其中 pages 数组包含每个页面的 Markdown 内容和页码。
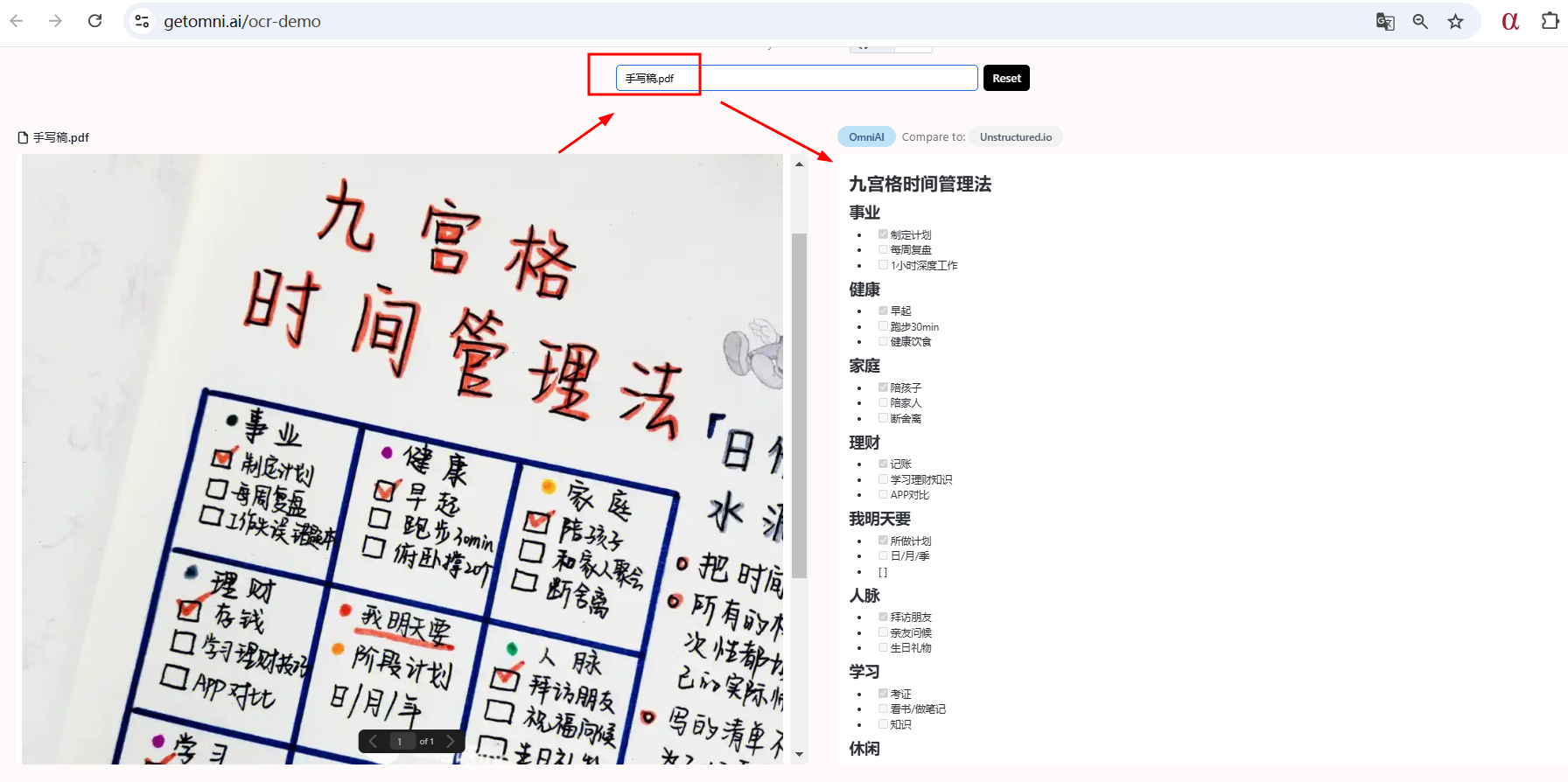
1、测试手写稿
测试地址:https://getomni.ai/ocr-demo
Zerox提供了出色的OCR功能,但这只是整个流程中的第一步。OmniAI可以将文档、文本、图像等转换为结构化数据。只需几分钟即可创建文档流水线,用于批量处理、提取和分类。
文档提取表格
使用Omni,您可以:
>> 结构化数据提取
>> 批量文档处理
>> 实时同步与文档存储库