开源智能语音转写系统:助力高效会议记录,精确还原访谈内容
一、系统概述
面对日益增长的音频数据需求,手动转写的低效率和高出错率成为各类会议、听证会和访谈管理中的突出问题。思通数科AI语音转写系统运用先进的声学建模、语言建模技术,支持实时语音转文字,满足企业、政府、法律和媒体等多元化应用场景的需求。
二、应用场景
1. 会议记录和多语言支持
在跨国企业会议中,实时记录和自动翻译是实现高效沟通的关键。思通数科AI语音转写系统不仅支持实时转写,还能同时生成中文和英文等多语言文本。系统结合特征提取与语言建模技术,将多国人员的发言高效转换为精确文本,大大提高了信息获取与整理的效率,特别是在国际会议和多语种项目管理中显著提升沟通效率。
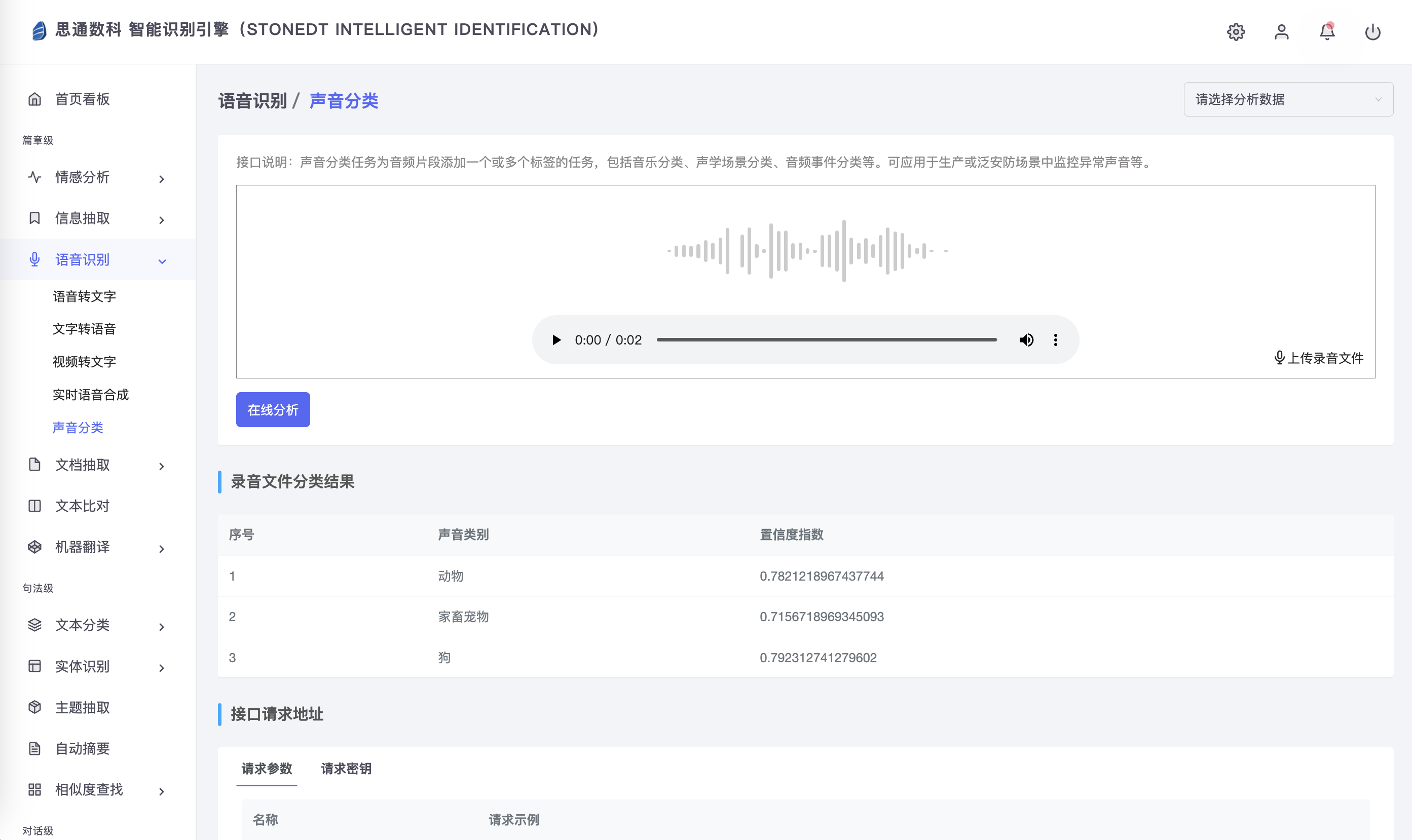
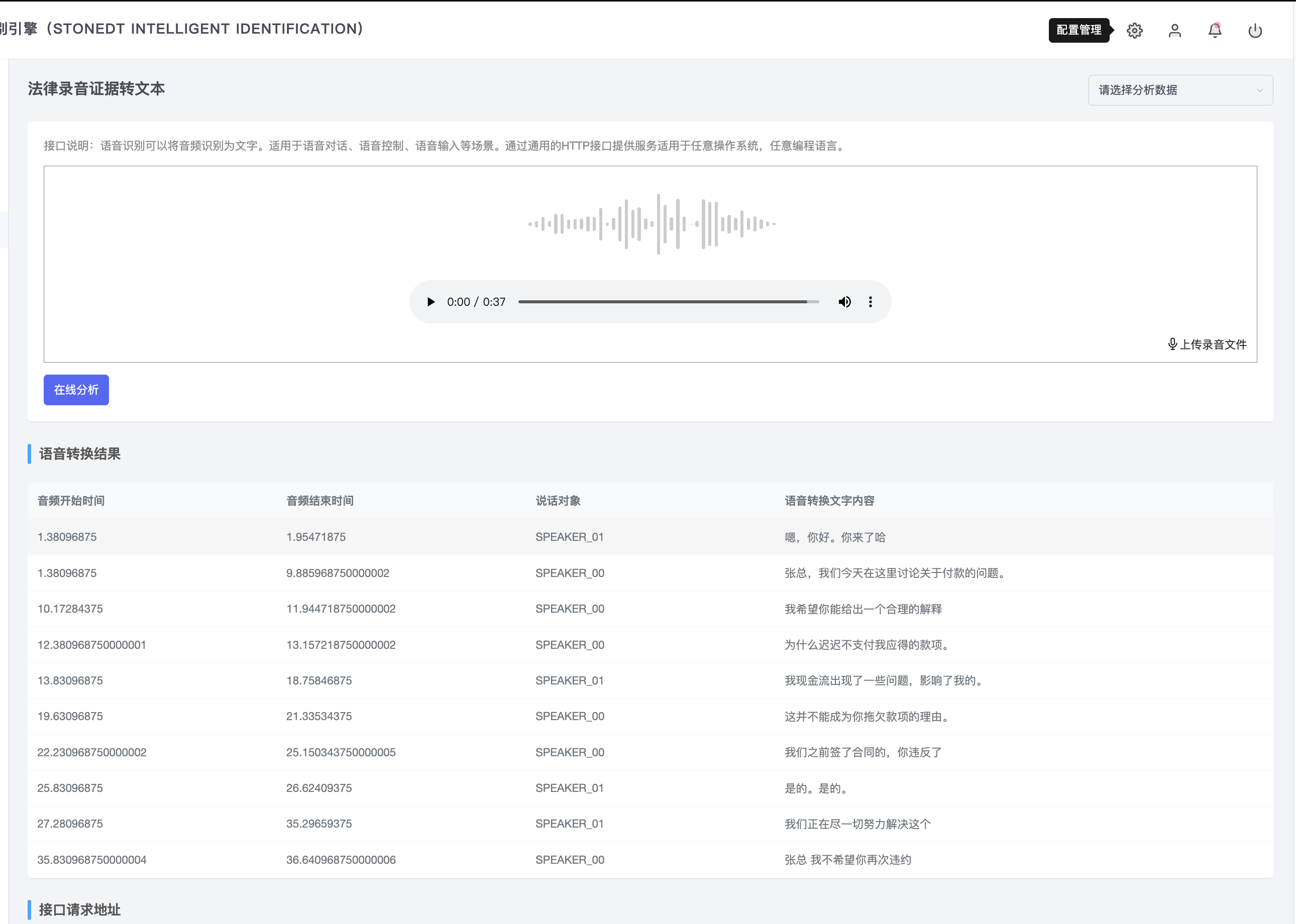
2. 法律听证会与数据存档
在法院、政府或法律援助机构的听证会中,精准的实时记录是确保信息完整、准确的基础。思通数科AI平台的语音转写系统利用噪声过滤、声学建模与多层解码等技术,将噪音较大的环境下的发言也能清晰转写,确保记录质量。系统帮助法律机构在后期案件分析和证据归档中更为高效、便捷,实现了比人工记录更高的可靠性。
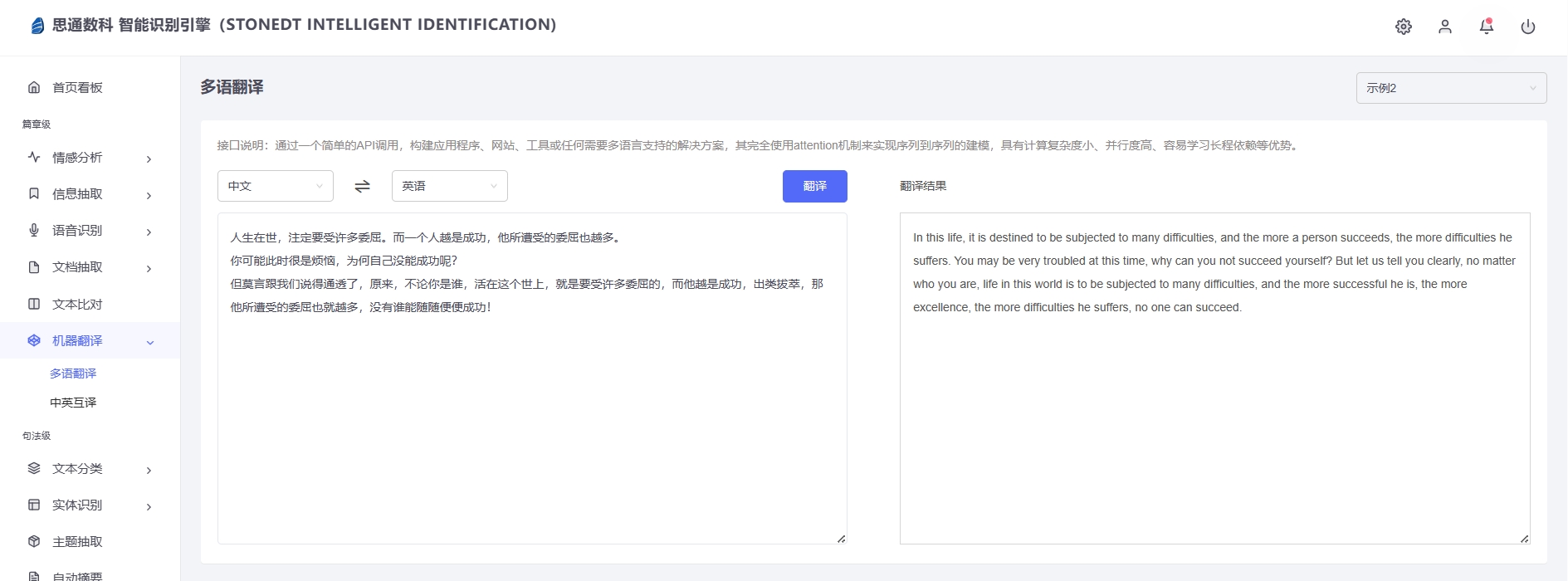
3. 媒体行业访谈存档和分析
在媒体或调研机构的访谈中,海量的访谈音频需要转换为文本以便于后期分析。思通数科AI平台集成的多语种转写功能能够识别访谈者的语言并自动调整模型参数,使音频数据迅速文本化。同时,系统还具备自动分段、标注不同发言者等功能,提升了采访内容的管理和分析效率,满足媒体行业的大量数据处理需求。
三、技术原理
思通数科AI语音转写系统基于以下关键技术原理:
1. 音频输入和预处理
通过高精度麦克风或电话系统获取音频信号,系统使用音频预处理技术进行背景噪音消除和音量标准化。噪音消除技术通过自适应滤波器去除背景噪音,确保声音信号清晰可辨,同时通过频带扩展等处理提升识别效果。
2. 特征提取
使用美尔频率倒谱系数(MFCCs)捕捉语音信号的频谱特征。MFCCs是一种模拟人耳听觉特性的特征提取方法,通过离散余弦变换将语音信号转化为一系列特征值,使机器更好地识别语音信号中的信息。
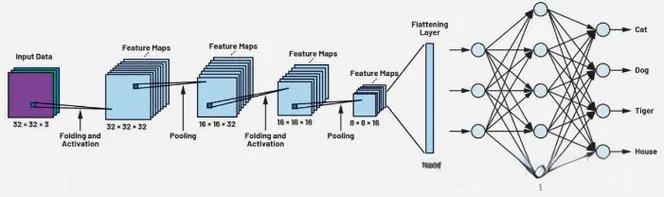
3. 声学建模
声学建模通过训练深度学习模型将特征映射到音素(即语音最小单位),系统使用深度神经网络(DNN)模型,结合卷积神经网络(CNN)处理频谱特征。在开源平台下,用户可自行调整模型参数,进一步提升识别率。
4. 语言建模
语言模型通过上下文信息约束,预测最有可能的词序列。思通数科AI系统集成了基于深度学习的双向长短期记忆网络(BiLSTM),利用上下文信息和词频统计,准确输出用户常用词汇,并具备较强的跨场景适应能力。
5. 解码与后处理
通过Viterbi解码算法,将特征匹配到可能的单词序列中,并进行后处理以校正错误词、插入标点符号和大写字母化,确保生成符合语法的、便于阅读的文本输出。
6. 多语种支持与自定义扩展
系统支持中文、英文及多语种识别,并允许用户通过在线平台自定义语言模型,快速实现多语言支持。用户可通过平台免费体验,实时测试和调整模型。
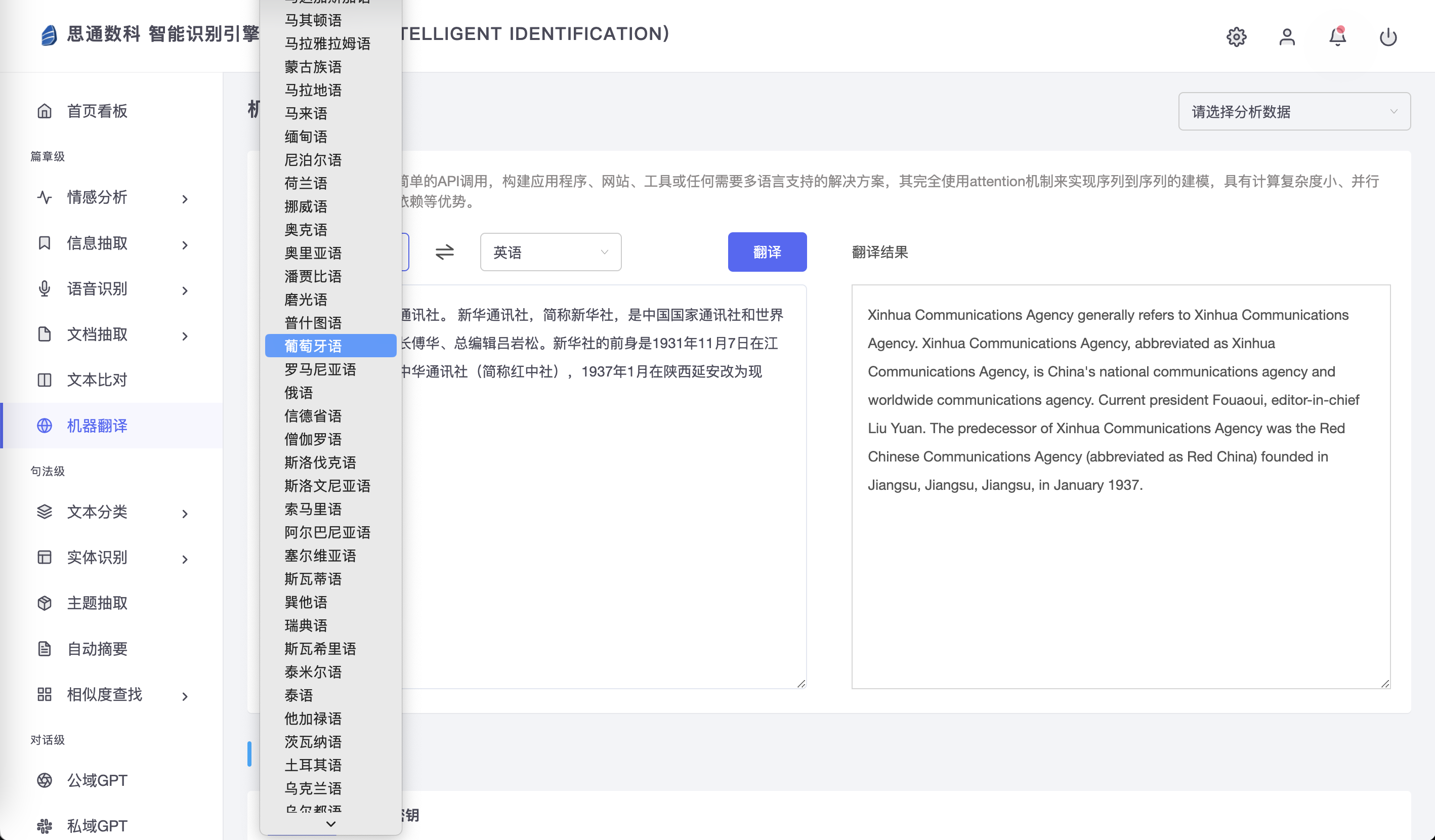
四、技术指标:识别准确率 ≥85%,延迟 ≤2秒;支持多种音频格式(MP3、WAV等),并具备高效的内存和计算资源管理。
体验地址:https://nlp.stonedt.com
或通过网络搜索“思通数科AI多模态能力平台”