音视频开发之旅(88) - 视频画质评测算法之Dover
目录
1. 背景与拟解决的问题
2.Dover算法的解决措施
3. 实验评估
4. 源码分析
5. 不足与可改善点
6. 参考
一. 背景与拟解决的问题
对视频进行画质评测是一个长期存在且未解决的问题,随着UGC视频的快速增长,开发有效的视频质量评估(VQA)算法是非常有必要的,本论文作者从 技术和美学两个角度进行分析研究。
技术角度包含: 1)噪声;2)伪影;3)低锐度;4)失焦;5)运动模糊;6)停顿;7)抖动;8)过曝光/欠曝光 等
美学角度包含: 人类对内容语义和构图的偏好
该研究通过设计视图分解策略,将视频中与美学相关和与技术相关的信息进行分解,分别进行评估,提升算法对视频画质评估结果和人类主观感受的一致性.
二. Dover算法的解决措施
2.1 Dover主要贡献
1)构建 DIVIDE-3k(3590 个视频),其中包含45万条美学和技术视角的的主观质量意见
2)设计了视图分解策略,将视频中与美学相关和与技术相关的信息进行分解,提升了PLCC等指标和算法得分与人类感知的一致性.
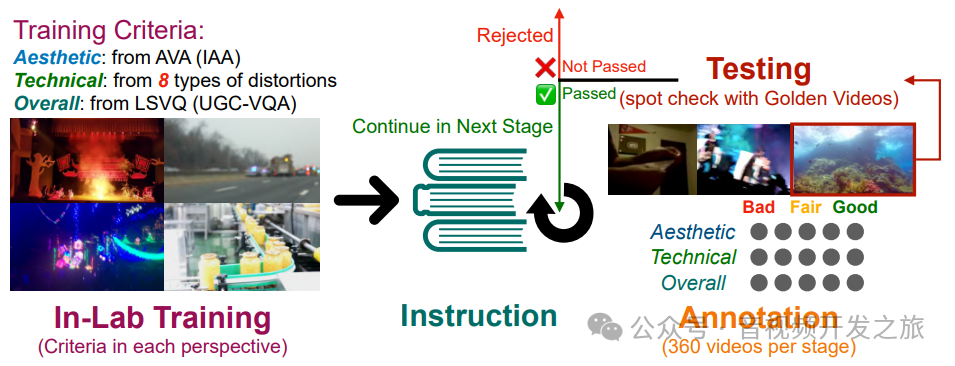
2.2 数据集构建
(1)评测标准的制定
• 美学评分:根据美学视角(例如,语义偏好)对视频的质量进行评级。
• 技术评分:仅考虑技术失真对视频的质量进行评级。
• 整体评分:对视频的质量进行评级。
• 主观推理:给出评分受美学或技术视角影响的原因
美学视角关注视频的语义和构图,而技术视角与低级纹理和失真等相关

(2) 标注数据集的构建:
共3590 个UGC视频, 对YFCC-100M和 Kinetics-400数据集共40w个视频中进行直方图统计,随机选择3270视频移除声音作为子集,
然后从LVSQ中分别选择一定量的良好、中等和差质量的视频作为黄金视频(确保标注的质量)
2.3方法流程
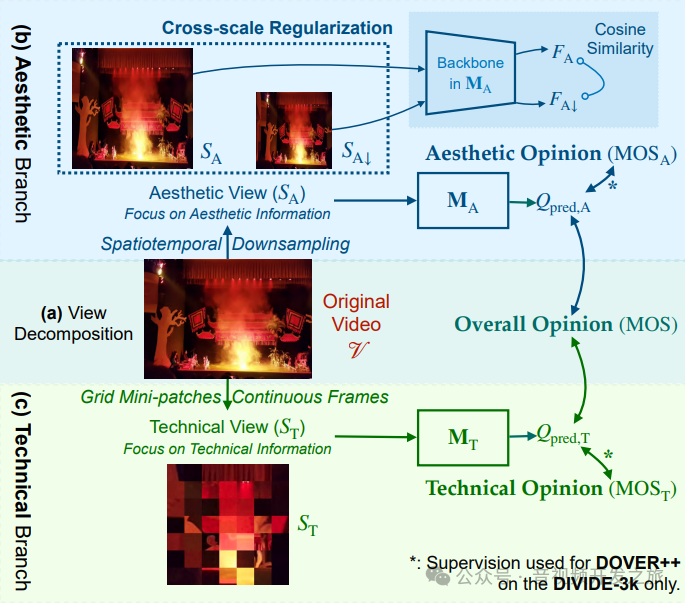
视图分解:美学(SA)和技术(ST)视角
美学视角:主要与语义以及构图有关,这些通常为高级视觉感知
技术视角:主要和模糊、噪声 伪影等相关,这些通常未低级视觉感知
但有一小部分感知因素与两个视角都相关,比如与曝光(技术方面)和光照(美学方面),或者运动模糊(可能在美学上是好的朦胧感,但是技术上是差的)。对于这些分不开的因素,将它们保留在两个分支中.
分解后的视图SA和ST分别做为美学分支MA和技术分支MT的输入。
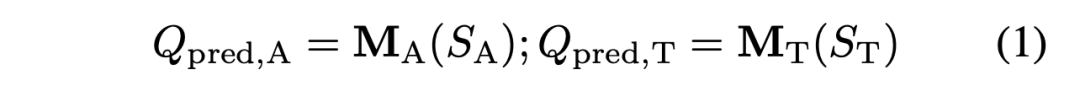
2.3.1 美学分支
语义和构图是决定一个视频美学的两个关键因素,通过空间下采样(resize到224*224)和时间稀疏帧采样(从视频片段中获取32帧)来获得美学视图
这两种策略显著降低了对模糊、噪声、伪影(通过空间下采样)、抖动、闪烁(通过时间稀疏采样)等技术失真的敏感度,专注于美学感知
为了在这个分支中更好地减少技术影响,在训练期间通过对视频进行进一步下采样,获得过度下采样视图(SA↓)添加跨尺度约束(LCR)作为正则化,通过鼓励 SA↓和 SA 之间的特征相似性(Cosine Simiarity)来进一步减少美学预测中的技术影响
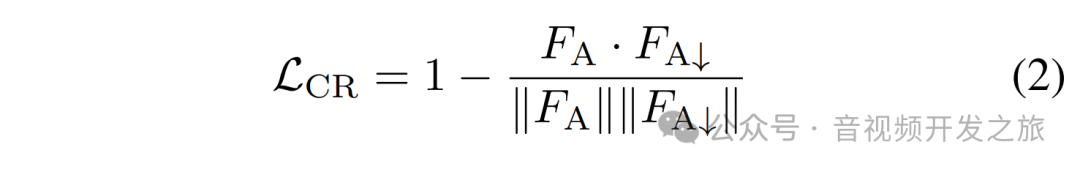
2.3.2 技术分支
在技术分支,保留技术失真,淡化美学影响,为此作者设计了技术试图(ST),引入了片段(有随机裁剪的patch拼接而成), 对视频帧进行分网格化处理,每个网格中取出连续的32*32像素作为一个patch,它丢弃了视频帧大部分内容,拼接的视图也破坏了原有的构图关系,严重降低了美学的影响. 在时间上采用连续帧采样保留时间失真.
2.3.3 得分融合策略
从主观研究中,我们观察到平均主观评分可以很好地近似为 0.428 倍的美学平均主观评分加 0.572 倍的技术平均主观评分。
通过简单的加权融合,从两个视角获得最终的整体质量预测(Qpred):Qpred = 0.428Qpred,A + 0.572Qpred,T。
三. 实验评估
3.1实验设置
在美学分支中,我们在推理时使用大小为 224×224 的自注意力,并且过度下采样大小为 128×128 的自注意力↓以更好地排除技术质量问题。从每个视频中均匀采样 N=32 帧,骨干网络是使用 AVA 预训练的膨胀卷积ConvNet。
在技术分支中,我们从 7×7 空间网格中裁剪大小为 Sf=32 的单个补丁,并在训练时采样 32 连续帧的一个片段,在推理时采样三个片段。技术分支的骨干网络是SwinTransformer
3.2 实验结果
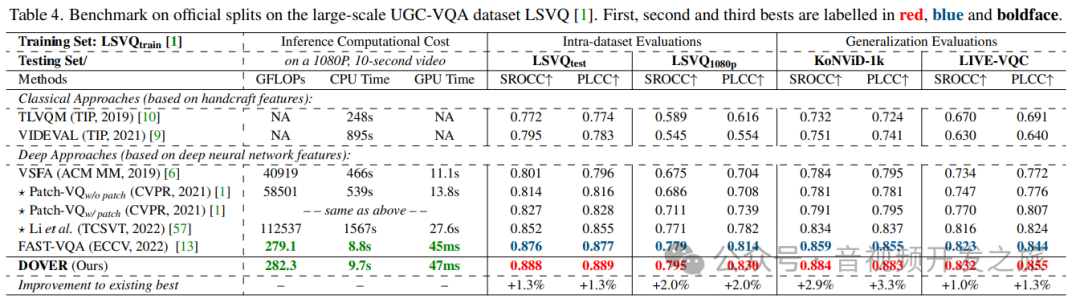
在LSVQ和KonViD等数据集上使用VSFA FAST-VQA以及Dover等算法进行评分, Dover在PLCC以及SROCC均表现最优
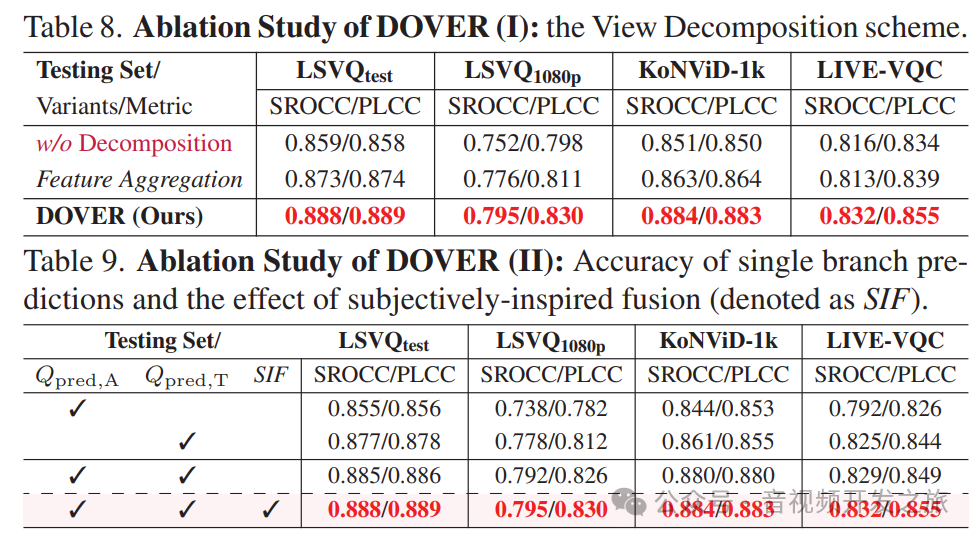
3.3 消融实验
表8展示了 有视图分解和无视图分解的效果,
表9展示了技术和美学分时融合策略比其他方式更优
四. 源码分析
4.1 数据处理 代码解析
数据帧的采样以及技术分支的网格处理以及美学分支的resize
包含三部分: 采样配置(dover.yml), 帧采样器(UnifiedFrameSampler)和帧处理函数spatial_temporal_view_decomposition(在技术分支和美学分支不同的处理)
1). 采样配置 dover.yml
name: DOVERnum_epochs: 0l_num_epochs: 10warmup_epochs: 2.5ema: truesave_model: truebatch_size: 8num_workers: 6split_seed: 42data:val-l1080p:type: ViewDecompositionDatasetargs:weight: 0.620phase: testanno_file: ./examplar_data_labels/LSVQ/labels_1080p.txtdata_prefix: ../datasets/LSVQ/sample_types:technical:fragments_h: 7fragments_w: 7fsize_h: 32fsize_w: 32aligned: 32clip_len: 32frame_interval: 2num_clips: 3aesthetic:size_h: 224size_w: 224clip_len: 32frame_interval: 2t_frag: 32num_clips: 1model:type: DOVERargs:backbone:technical:type: swin_tiny_grpbcheckpoint: truepretrained:aesthetic:type: conv_tinybackbone_preserve_keys: technical,aestheticdivide_head: truevqa_head:in_channels: 768hidden_channels: 64optimizer:lr: !!float 1e-3backbone_lr_mult: !!float 1e-1wd: 0.05test_load_path: ./pretrained_weights/DOVER.pth
2). 帧采样器 UnifiedFrameSampler
"""获取采样的帧数据,具体获取多少帧以及哪些帧有yaml参数和get_frame_indices函数计算控制"""import randomimport numpy as npclass UnifiedFrameSampler:def __init__(self, fsize_t, fragments_t, frame_interval=1, num_clips=1, drop_rate=0.0,):#多少个片段 ,#technical默认值为3 sopt["num_clips"]; aesthetic 该值为32 sopt["t_frag"]self.fragments_t = fragments_t# 每个片段多少帧# technical默认值为32 sopt["clip_len"]; aesthetic默认值是1 (32//32) sopt["clip_len"] // sopt["t_frag"]self.fsize_t = fsize_t#所有片段的所有帧数和self.size_t = fragments_t * fsize_t#提取的每帧相隔的帧数量 technical和aesthetic默认值都是2self.frame_interval = frame_interval#technical默认值为1#technical默认值为1 sopt["num_clips"]self.num_clips = num_clipsself.drop_rate = drop_ratedef get_frame_indices(self, num_frames, train=False):tgrids = np.array([num_frames // self.fragments_t * i for i in range(self.fragments_t)],dtype=np.int32,)tlength = num_frames // self.fragments_tif tlength > self.fsize_t * self.frame_interval:#np.random.randint用于随机生成整数,#第一个参数(0)为随机数的下线;#第二个参数是随机数的上线(tlength - self.fsize_t * self.frame_interval,eg: tlength=139 ,fsize_t=32,frame_interval=2,结果为75)#第三个参数是生成随机整数的数量(eg:tgrids=[0,139,278],size为3)#得到的结果可能是 [22,70,24]#用于获得一个每个视频片段的取帧的初始帧indexrnd_t = np.random.randint(0, tlength - self.fsize_t * self.frame_interval, size=len(tgrids))else:rnd_t = np.zeros(len(tgrids), dtype=np.int32)#使用numpy的广播机制生成一个二维ranges_t,这个数组的每一行表示一个时间窗口的起止帧的index#self.fsize_t=32,np.arange(self.fsize_t)生成数组 [0, 1, 2, ..., 30, 31],np.arange(self.fsize_t)[None, :],将这数组扩展为二维数组,其中第一维度的大小为1,第二维的大小为self.fize_t即32,数组的形状从(32)变为了(1,32)#rnd_t 将数组扩展为二维,其中第二维的长度为1,rnd_t形状有3变成了(3,1)#tgrids 同理rnd_t#根据广播机制,数组可以沿着长度为1的维度扩展,#得到结果 eg:[[ 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56, 58 60 62 64 66 68 70 72 74 76 78 80 82 84], [209 211 213 215 217 219 221 223 225 227 229 231 233 235 237 239 241 243, 245 247 249 251 253 255 257 259 261 263 265 267 269 271], [302 304 306 308 310 312 314 316 318 320 322 324 326 328 330 332 334 336, 338 340 342 344 346 348 350 352 354 356 358 360 362 364]]ranges_t = (np.arange(self.fsize_t)[None, :] * self.frame_interval+ rnd_t[:, None]+ tgrids[:, None])drop = random.sample(list(range(self.fragments_t)), int(self.fragments_t * self.drop_rate))dropped_ranges_t = []for i, rt in enumerate(ranges_t):if i not in drop:dropped_ranges_t.append(rt)#concatenate将多个数据集合并为单个数据集进行分析或训练模型时。它简化了将多个时间序列数据合并成单一序列的过程,便于后续的处理或分析#[ 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56, 58 60 62 64 66 68 70 72 74 76 78 80 82 84 209 211 213 215, 217 219 221 223 225 227 229 231 233 235 237 239 241 243 245 247 249 251, 253 255 257 259 261 263 265 267 269 ...]return np.concatenate(dropped_ranges_t)#python中__call__是一个特殊的方法,允许一个对象的实例可以像函数一样被调用def __call__(self, total_frames, train=False, start_index=0):frame_inds = []for i in range(self.num_clips):frame_inds += [self.get_frame_indices(total_frames)]frame_inds = np.concatenate(frame_inds)#取模运算,防止越界frame_inds = np.mod(frame_inds + start_index, total_frames)return frame_inds.astype(np.int32)
3). 视图分解代码解析
最终返回 美学分支:缩放为224*24; 技术分支: 把原视频帧分割为7*7的网格,每个网格中取连续的32*32的片段,拼接为7*32=224的新的视频帧"""video_path:视频路径sample_types:采样的配置,即yaml中sample_types(包含technical分支和aesthetic分支的配置 )samplers:帧采样器,即UnifiedFrameSampler返回:包含处理后的美学和技术帧数据views和inds索引"""def spatial_temporal_view_decomposition(video_path, sample_types, samplers, is_train=False, augment=False,):video = {}decord.bridge.set_bridge("torch")#使用decord的VideoReader对视频进行解码提取帧vreader = VideoReader(video_path)### Avoid duplicated video decoding!!! Important!!!!all_frame_inds = []frame_inds = {}#时间和技术两个维度的samplers,都是UnifiedFrameSampler实例for stype in samplers:# print(f"stype:{stype},len(vreader):{len(vreader)},istrain:{is_train}")#这里的sampler是 UnifiedFrameSampler,调用UnifiedFrameSampler的__call__进行迭代frame_inds[stype] = samplers[stype](len(vreader), is_train)all_frame_inds.append(frame_inds[stype])### Each frame is only decoded one time!!!#把technical和aesthetic需要的帧进行concatnate,然后unique,进行去重处理.all_frame_inds = np.concatenate(all_frame_inds, 0)#这里建立索引,idx和对应的帧数据,加载在了内存中,#注意!! 如果原始图像分辨率比较大会影响内存大小# --->可以把源视频切分为多个片段,每个次计算一个片段的分值在进行平均化处理frame_dict = {idx: vreader[idx] for idx in np.unique(all_frame_inds)}for stype in samplers:imgs = [frame_dict[idx] for idx in frame_inds[stype]]# print(f"frame_dict[0].shape:{frame_dict[frame_inds[stype][0]].shape}")#上面print输出torch.Size([960, 540, 3]),即[H,W,C]#torch.stack(imgs, 0),将imgs张量堆叠为一个新的张量,其中0表示新维度将被添加到最前面# 堆叠后的张量相当于添加一个batchsize通道[B,H,W,C],其中B为imgs中张量的数量,然后permute转置后为[C,B,H,W]video[stype] = torch.stack(imgs, 0).permute(3, 0, 1, 2)sampled_video = {}for stype, sopt in sample_types.items():sampled_video[stype] = get_single_view(video[stype], stype, **sopt)return sampled_video, frame_inds#根据 技术或者美学分支对对应的帧做处理def get_single_view(video, sample_type="aesthetic", **kwargs,):if sample_type.startswith("aesthetic"):video = get_resized_video(video, **kwargs)elif sample_type.startswith("technical"):video = get_spatial_fragments(video, **kwargs)elif sample_type == "original":return videoreturn video"""对于美学分支分支,把图像resize到224*224"""def get_resized_video(video, size_h=224, size_w=224, random_crop=False, arp=False, **kwargs,):#重排序[C,B,H,W]为pytorch预期的[B,C,H,W]video = video.permute(1, 0, 2, 3)resize_opt = get_resize_function(size_h, size_w, video.shape[-2] / video.shape[-1] if arp else 1, random_crop)#调用resize函数,然后再重排序为[C,B,H,W]video = resize_opt(video).permute(1, 0, 2, 3)return video"""对视频帧进行空间切片,切片为7*7的patchfragments_h/fragments_w: 每个帧垂直和水平都被分为7分fsize_h/fsize_w 切分的每个片段的h和w, 7*32=224最终返回的是:在每个网格(7*7个网格)中进行裁剪(32*32的大小)的片段拼接为新的视频帧序列,最终输出的帧大小也是7*32=224"""def get_spatial_fragments(video,fragments_h=7,fragments_w=7,fsize_h=32,fsize_w=32,aligned=32,nfrags=1,random=False,random_upsample=False,fallback_type="upsample",upsample=-1,**kwargs,):size_h = fragments_h * fsize_hsize_w = fragments_w * fsize_wdur_t, res_h, res_w = video.shape[-3:]print(f"dur_t:{dur_t},video.shape[-3:]:{video.shape[-3:]}")#获取视频wh和被切片的wh(res_h/224)的比例ratio = min(res_h / size_h, res_w / size_w)size = size_h, size_w## make sure that sampling will not run out of the picture"""#构建水平和垂直网格 eg:912*1920,#垂直网格等分为7分,每个网格开始的位置为:tensor([0,274,548,822,1096,1370,1644]);#水平网格开始位置:tensor([0,130,260,390,520,650,780])"""hgrids = torch.LongTensor([min(res_h // fragments_h * i, res_h - fsize_h) for i in range(fragments_h)])wgrids = torch.LongTensor([min(res_w // fragments_w * i, res_w - fsize_w) for i in range(fragments_w)])#使用视频的h和w 除以网格线的数量,得到每个网格的hw eg:912*1920的视频,得到的每个网格h为1920//7=274; w为912//7=130hlength, wlength = res_h // fragments_h, res_w // fragments_w#如果网格的高度大于模型需要的网格高度(32)if hlength > fsize_h:"""在每个网格视频片h的大小(hlength,上述912*1920视频中对应274)-模型需要的网格的高度(fsize_h)的范围内,随机生成每个网格的偏移值"""rnd_h = torch.randint(hlength - fsize_h, (len(hgrids), len(wgrids), dur_t // aligned))else:rnd_h = torch.zeros((len(hgrids), len(wgrids), dur_t // aligned)).int()if wlength > fsize_w:rnd_w = torch.randint(wlength - fsize_w, (len(hgrids), len(wgrids), dur_t // aligned))else:rnd_w = torch.zeros((len(hgrids), len(wgrids), dur_t // aligned)).int()target_video = torch.zeros(video.shape[:-2] + size).to(video.device)# target_videos = []#hs,ws,为每个网格起始的坐标,下面这个嵌套循环就是原视频网格中获取fsize_h/fsize_w的内容,然后把每个网格中裁剪后的片段拼接为新的视频帧for i, hs in enumerate(hgrids):for j, ws in enumerate(wgrids):for t in range(dur_t // aligned):t_s, t_e = t * aligned, (t + 1) * alignedh_s, h_e = i * fsize_h, (i + 1) * fsize_hw_s, w_e = j * fsize_w, (j + 1) * fsize_wif random:h_so, h_eo = rnd_h[i][j][t], rnd_h[i][j][t] + fsize_hw_so, w_eo = rnd_w[i][j][t], rnd_w[i][j][t] + fsize_welse:#从每个网络中获取32*32的内容,拼接为新的视频h_so, h_eo = hs + rnd_h[i][j][t], hs + rnd_h[i][j][t] + fsize_hw_so, w_eo = ws + rnd_w[i][j][t], ws + rnd_w[i][j][t] + fsize_wtarget_video[:, t_s:t_e, h_s:h_e, w_s:w_e] = video[:, t_s:t_e, h_so:h_eo, w_so:w_eo]return target_video
4.2 模型实现
class DOVER(nn.Module):def __init__(self,backbone_size="divided",backbone_preserve_keys="fragments,resize",multi=False,layer=-1,backbone=dict(resize={"window_size": (4, 4, 4)}, fragments={"window_size": (4, 4, 4)}),divide_head=False,vqa_head=dict(in_channels=768),var=False,):#backbone_preserve_keys对应dover.yml中的model.backbone_preserve_keys,值为technical,aesthetic 即技术和美学两个模型self.backbone_preserve_keys = backbone_preserve_keys.split(",")self.multi = multiself.layer = layersuper().__init__()"""#backbone对应对应dover.yml中的下面配置,定义技术和美学骨干网络使用的网络模型backbone:technical:type: swin_tiny_grpbcheckpoint: truepretrained:aesthetic:type: conv_tiny"""for key, hypers in backbone.items():# print(backbone_size)if key not in self.backbone_preserve_keys:continueif backbone_size == "divided":t_backbone_size = hypers["type"]if t_backbone_size == "swin_tiny_grpb":#使用重现的Fast-vqa的骨干网络b = VideoBackbone()elif t_backbone_size == "conv_tiny":b = convnext_3d_tiny(pretrained=True)"""确定使用的骨干网络# technical_backbone:VideoBackbone;# aesthetic_backbone: convnext_3d_tiny"""setattr(self, key + "_backbone", b)for key in backbone:if key not in self.backbone_preserve_keys:continueb = VQAHead(pre_pool=pre_pool, **vqa_head)"""确定使用的Head网络# technical_head:VQAHead;# aesthetic_head:VQAHead"""setattr(self, key + "_head", b)def forward(self,vclips,inference=True,return_pooled_feats=False,return_raw_feats=False,reduce_scores=False,pooled=False,**kwargs):self.eval()with torch.no_grad():scores = []feats = {}for key in vclips:"""#技术分支的backbone为:SwinTransformer3D论文 https://arxiv.org/pdf/2103.14030Swin Transformer 是一种基于 Transformer 架构的模型,专为计算机视觉任务设计,能够处理图像数据。这个模型基于论文 "Swin Transformer: Hierarchical Vision Transformer using Shifted Windows" 实现,该论文提出了一种新的 Transformer 架构,通过使用移位窗口来构建层次化的特征表示,并且具有与输入图像大小成线性关系的计算复杂度#美学分支的backbone为ConvNeXt3D论文:https://arxiv.org/pdf/2201.03545.pdfConvNeXt 是一个现代的卷积神经网络架构,旨在与 Transformer 模型竞争,同时保持标准卷积网络的简洁性和效率。"""feat = getattr(self, key.split("_")[0] + "_backbone")(vclips[key], multi=self.multi, layer=self.layer, **kwargs)#技术和美学分支的head网络都是 VQAHead,内部通过MLP实现scores += [getattr(self, key.split("_")[0] + "_head")(feat)]self.train()return scores
4.3 推理代码解析
#ImageNet的均值方差mean, std = (torch.FloatTensor([123.675, 116.28, 103.53]),torch.FloatTensor([58.395, 57.12, 57.375]),)def fuse_results(results: list):x = (results[0] - 0.1107) / 0.07355 * 0.6104 + (results[1] + 0.08285) / 0.03774 * 0.3896return 1 / (1 + np.exp(-x))class DoverVQA():def __init__(self,device='cuda'):self.device= devicewith open(os.path.join(root_dir,'dover.yml'), "r") as f:opt = yaml.safe_load(f)self.dopt = opt["data"]["val-l1080p"]["args"]### Load DOVERself.model = DOVER(**opt["model"]["args"]).to(self.device)self.model.load_state_dict(torch.load(os.path.join(root_dir,'pretrained_weights/DOVER.pth'), map_location=self.device))self.temporal_samplers = {}for stype, sopt in self.dopt["sample_types"].items():if "t_frag" not in sopt:# resized temporal sampling for TQE in DOVERself.temporal_samplers[stype] = UnifiedFrameSampler(sopt["clip_len"], sopt["num_clips"], sopt["frame_interval"])else:# temporal sampling for AQE in DOVERself.temporal_samplers[stype] = UnifiedFrameSampler(sopt["clip_len"] // sopt["t_frag"],sopt["t_frag"],sopt["frame_interval"],sopt["num_clips"],)def getVideoScore(self,video_path):### View Decompositionviews, frame_inds = spatial_temporal_view_decomposition(video_path, self.dopt["sample_types"], self.temporal_samplers)# print(f"frame_inds:{frame_inds},len-technical:{len(frame_inds['technical'])},len-aesthetic:{len(frame_inds['aesthetic'])}")for k, v in views.items():num_clips = self.dopt["sample_types"][k].get("num_clips", 1)#print(f"num_clips:{num_clips},k:{k},v.shape:{v.shape}") 视频帧已经被resize到224#输出 num_clips:3,k:technical,v.shape:torch.Size([3, 96, 224, 224]); num_clips:1,k:aesthetic,v.shape:torch.Size([3, 32, 224, 224])views[k] = (#输入的v为[C,B,H,W],经过v.permute转置后为[B,H,W,C],根据ImageNet的std和mean,做归一化处理((v.permute(1, 2, 3, 0) - mean) / std)#再次转置为[C,B,H,W].permute(3, 0, 1, 2)#重新reshape,v.shape[0]为C; num_clips为单独一维; -1 自动计算; *v.shape[2:]即将H,W展开作为新的两个维度#经过reshape后变为5维度 [C,num_clips,B,H,W].reshape(v.shape[0], num_clips, -1, *v.shape[2:])#交换第一维和第二维,变为[num_clips,C,B,H,W].transpose(0, 1).to(self.device))#计算技术和美学得分的均值results = [r.mean().item() for r in self.model(views)]#转为1-5分,保留2位小数resultvalue = round(fuse_results(results)*5,2)return resultvaluedef interface(self,video_path):score_value = self.getVideoScore(video)return score_value
4.4 训练代码解析
import torchimport cv2import randomimport os.path as ospimport argparsefrom scipy.stats import spearmanr, pearsonrfrom scipy.stats.stats import kendalltau as kendallrimport numpy as npfrom time import timefrom tqdm import tqdmimport pickleimport mathimport yamlfrom collections import OrderedDictfrom functools import reducefrom thop import profileimport copyimport dover.models as modelsimport dover.datasets as datasetsdef inference_set(inf_loader,model,device,best_,save_model=False,suffix="s",save_name="divide",save_type="head",):results = []best_s, best_p, best_k, best_r = best_for i, data in enumerate(tqdm(inf_loader, desc="Validating")):result = dict()video, video_up = {}, {}for key in sample_types:if key in data:video[key] = data[key].to(device)## Reshape into clipsb, c, t, h, w = video[key].shapevideo[key] = (video[key].reshape(b, c, data["num_clips"][key], t // data["num_clips"][key], h, w).permute(0, 2, 1, 3, 4, 5).reshape(b * data["num_clips"][key], c, t // data["num_clips"][key], h, w))with torch.no_grad():result["pr_labels"] = model(video, reduce_scores=True).cpu().numpy()if len(list(video_up.keys())) > 0:result["pr_labels_up"] = model(video_up).cpu().numpy()result["gt_label"] = data["gt_label"].item()del video, video_upresults.append(result)## generate the demo video for video quality localizationgt_labels = [r["gt_label"] for r in results]pr_labels = [np.mean(r["pr_labels"][:]) for r in results]pr_labels = rescale(pr_labels, gt_labels)#根据gt和预测值,计算相关性系数指标s = spearmanr(gt_labels, pr_labels)[0]p = pearsonr(gt_labels, pr_labels)[0]k = kendallr(gt_labels, pr_labels)[0]r = np.sqrt(((gt_labels - pr_labels) ** 2).mean())del results, result # , video, video_uptorch.cuda.empty_cache()#如果plcc和srocc比之前best还要优,则更新best finetune模型if s + p > best_s + best_p and save_model:state_dict = model.state_dict()torch.save({"state_dict": state_dict, "validation_results": best_,},f"pretrained_weights/{save_name}_{suffix}_finetuned.pth",)best_s, best_p, best_k, best_r = (max(best_s, s),max(best_p, p),max(best_k, k),min(best_r, r),)return best_s, best_p, best_k, best_rparser = argparse.ArgumentParser()parser.add_argument("-o", "--opt", type=str, default="dover.yml", help="the option file")parser.add_argument("-t", "--target_set", type=str, default="val-maxwell", help="target_set")args = parser.parse_args()with open(args.opt, "r") as f:opt = yaml.safe_load(f)device = "cuda" if torch.cuda.is_available() else "cpu"bests_ = []if opt.get("split_seed", -1) > 0:num_splits = 10else:num_splits = 1print(opt["split_seed"])for split in range(10):"""model:type: DOVER # opt["model"]["type"],就是DOVER网络模型args: #**opt["model"]["args"],就是args对应的技术和美学网络结构信息backbone:technical:type: swin_tiny_grpbcheckpoint: truepretrained:aesthetic:type: conv_tinybackbone_preserve_keys: technical,aestheticdivide_head: truevqa_head:in_channels: 768hidden_channels: 64"""model = getattr(models, opt["model"]["type"])(**opt["model"]["args"]).to(device)if opt.get("split_seed", -1) > 0:#args.target_set 就是 要训练的目标数据集配置的名称,在dover.yml中 data的子属性,给出数据集的路径以及网络配置信息(如下所示)"""data:customData:type: ViewDecompositionDatasetargs:weight: 0.540phase: testanno_file: ./examplar_data_labels/customData/labels.txtdata_prefix: /xxx/train_data/customDatasample_types:technical:fragments_h: 7fragments_w: 7fsize_h: 32fsize_w: 32aligned: 32clip_len: 32frame_interval: 2num_clips: 3aesthetic:size_h: 224size_w: 224clip_len: 32frame_interval: 2t_frag: 32num_clips: 1"""opt["data"]["train"] = copy.deepcopy(opt["data"][args.target_set])opt["data"]["eval"] = copy.deepcopy(opt["data"][args.target_set])#调用train_test_split函数 分离训练和验证数据集 (默认 8:2)split_duo = train_test_split(opt["data"][args.target_set]["args"]["data_prefix"],opt["data"][args.target_set]["args"]["anno_file"],seed=opt["split_seed"] * (split + 1),)(opt["data"]["train"]["args"]["anno_file"],opt["data"]["eval"]["args"]["anno_file"],) = split_duoopt["data"]["train"]["args"]["sample_types"]["technical"]["num_clips"] = 1train_datasets = {}for key in opt["data"]:if key.startswith("train"):#根据yml配置可以看出 train_dataset 为 ViewDecompositionDatasettrain_dataset = getattr(datasets, opt["data"][key]["type"])(opt["data"][key]["args"])train_datasets[key] = train_datasetprint(len(train_dataset.video_infos))# 构建训练和验证加载器train_loaders = {}for key, train_dataset in train_datasets.items():train_loaders[key] = torch.utils.data.DataLoader(train_dataset,batch_size=opt["batch_size"],num_workers=opt["num_workers"],shuffle=True,)val_datasets = {}for key in opt["data"]:if key.startswith("eval"):val_dataset = getattr(datasets, opt["data"][key]["type"])(opt["data"][key]["args"])print(len(val_dataset.video_infos))val_datasets[key] = val_datasetval_loaders = {}for key, val_dataset in val_datasets.items():val_loaders[key] = torch.utils.data.DataLoader(val_dataset,batch_size=1,num_workers=opt["num_workers"],pin_memory=True,)#加载预训练模型权重state_dict = torch.load(opt["test_load_path"], map_location=device)head_removed_state_dict = OrderedDict()for key, v in state_dict.items():if "head" not in key:head_removed_state_dict[key] = v# Allowing empty head weightmodel.load_state_dict(state_dict, strict=False)if opt["ema"]:from copy import deepcopymodel_ema = deepcopy(model)else:model_ema = None# profile_inference(val_dataset, model, device)# finetune the modelparam_groups = []#之所以 这里backbone的lr比head的lr低, 是因为backbone通常包含大量参数,比head复杂,较小的学习率进行训练可以更加稳定,避免破坏预训练模型已经学到的特征表示for key, value in dict(model.named_children()).items():if "backbone" in key:#如果是骨干网络,lr根据yml配置设置为原lr(默认为1e-3)的1/10,backbone_lr_mult为1e-1param_groups += [{"params": value.parameters(),"lr": opt["optimizer"]["lr"]* opt["optimizer"]["backbone_lr_mult"],}]else:#如果是head,直接根据yml中lr的配置来设置 默认为(1e-3)param_groups += [{"params": value.parameters(), "lr": opt["optimizer"]["lr"]}]optimizer = torch.optim.AdamW(lr=opt["optimizer"]["lr"],params=param_groups,#权重衰减因子weight_decay=opt["optimizer"]["wd"],)warmup_iter = 0for train_loader in train_loaders.values():warmup_iter += int(opt["warmup_epochs"] * len(train_loader))max_iter = int((opt["num_epochs"] + opt["l_num_epochs"]) * len(train_loader))lr_lambda = (lambda cur_iter: cur_iter / warmup_iterif cur_iter <= warmup_iterelse 0.5 * (1 + math.cos(math.pi * (cur_iter - warmup_iter) / max_iter)))scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lr_lambda,)bests = {}bests_n = {}for key in val_loaders:bests[key] = -1, -1, -1, 1000bests_n[key] = -1, -1, -1, 1000for key, value in dict(model.named_children()).items():if "backbone" in key:for param in value.parameters():param.requires_grad = Falsefor epoch in range(opt["l_num_epochs"]):print(f"Linear Epoch {epoch}:")for key, train_loader in train_loaders.items():finetune_epoch(train_loader,model,model_ema,optimizer,scheduler,device,epoch,opt.get("need_upsampled", False),opt.get("need_feat", False),opt.get("need_fused", False),)for key in val_loaders:bests[key] = inference_set(val_loaders[key],model_ema if model_ema is not None else model,device,bests[key],save_model=opt["save_model"],save_name=opt["name"] + "_head_" + args.target_set + f"_{split}",suffix=key + "_s",save_type="full",)if opt["l_num_epochs"] >= 0:for key in val_loaders:print(f"""For the linear transfer process on {key} with {len(val_loaders[key])} videos,the best validation accuracy of the model-s is as follows:SROCC: {bests[key][0]:.4f}PLCC: {bests[key][1]:.4f}KROCC: {bests[key][2]:.4f}RMSE: {bests[key][3]:.4f}.""")
五. 不足与可改善点
不足:
默认配置是 技术分支的训练和推理是取视频的3个片段,每个片段32帧,帧间隔为2,每帧的大小为7*7的网格,每个网格32*32的大小; 美学分支训练和推理是取视频的一个片段,帧间隔为2共32帧,每帧的大小resize到224*224
因为取帧的实现是随机获取的,这样就会导致,对于同一个视频,多次运行推理代码进行画质评分结果可能不一致.
解决方案有两种:
1. 增大片段的数量,以及每个片段的帧数,这个方案会导致显存 cpu和内存的占用成比例增长,原因是解码后缓存的帧增加,需要计算的量也增加
2. 把视频先cut为多段(eg:1分钟一段),然后针对每段进行VQA评分,以时间换空间(处理速度很快,也不会增加很多 eg4分钟视频 20s左右可以推理完)
虽然PLCC和SROCC相比VSFA 更优,但是整体评分偏低,也会存在一些低画质得分偏高的情况,需要根据自己的数据集进行进一步训练优化.
六. 参考
1. Dover论文: https://arxiv.org/pdf/2211.04894
2. AVA论文(贡献了图像美学数据库): http://refbase.cvc.uab.es/files/MMP2012a.pdf
3. Video Swin Transformer论文(技术分支的骨干网络): https://arxiv.org/pdf/2106.13230
4. A ConvNet for the 2020s论文(美学分支的骨干网络): https://arxiv.org/pdf/2201.03545
5. 代码: https://github.com/VQAssessment/DOVER
感谢你的阅读
接下来我们继续学习输出AI相关内容,欢迎关注公众号“音视频开发之旅”,一起学习成长。
欢迎交流