BP神经网络
一、BP神经网络概述
BP神经网络由Rumelhard和McClelland于1986年提出的一种按照误差逆向传播算法训练的多层前馈神经网络。
从结构上讲,BP神经网络是一种典型的多层前向型神经网络,具有一个输入层input、数个隐含层hidden(可以是一层,也可以是多层)和一个输出层output,以及各层之间得权重weight。层与层之间采用全连接的方式,同一层的神经元之间不存在相互连接。
(理论上已经证明,具有一个隐含层的三层网络可以逼近任意非线性函数。)
BP算法是BP神经网络的核心学习算法。
1、输入层:信息的输入端。
2、隐藏层:信息的处理端,神经元多采用S型传递函数。
3、输出层:信息的输出端,神经元多采用线性传递函数。
4、权重:连接每层信息之间的参数。

图1所示为一个典型的三层BP神经网络结构。
二、BP神经网络的流程
BP神经网络是一种多层的前馈神经网络,其主要的特点是:
信号是前向传播的,而误差是反向传播的。
BP神经网络的过程主要分为两个阶段:
第一阶段是信号的前向传播,从输入层经过隐含层,最后到达输出层;
第二阶段是误差的反向传播,从输出层到隐含层,最后到输入层,依次调节隐含层到输出层的权重和偏置,输入层到隐含层的权重和偏置。
神经网络的基本组成单元是神经元。神经元的通用模型如图所示,其中常用的激活函数有阈值函数、sigmoid函数和双曲正切函数。

神经元的输出为:
神经网络是将多个神经元按一定规则联结在一起而形成的网络,例如:

一个神经网络包括输入层、隐含层(中间层)和输出层。输入层神经元个数与输入数据的维数相同,输出层神经元个数与需要拟合的数据个数相同,隐含层神经元个数与层数就需要设计者自己根据一些规则和目标来设定。
三、BP神经网络的相关概念
1、输入层
输入层:指的就是我们输入数据的种类数量,输入几类,输入层神经元就有几层。
它是网络的第一层,负责接收外界输入的数据。输入层的节点数通常与问题的特征数量相匹配。
2、隐含层
隐含层:夹在输入层和输出层之间的神经元,数量可以自行设置,不过一般通过经验公式来确定:
其中:h为隐含层节点数目,输入层节点个数m,输出层节点个数n,a为1-10之间的调节。
它是网络中不直接与输入或输出层相连的层。一个BP神经网络可以包含一个或多个隐含层。隐含层的节点数可以根据问题的复杂性来调整。
3、输出层
输出层:指的就是我们相应得到的指标,一般就一个。
它是网络的最后一层,负责输出网络的最终结果。输出层的节点数通常与问题的输出类别数量相匹配。
4、权值(Weight)
权值是连接输入层、隐含层和输出层节点之间的权重。在训练过程中,这些权值会通过学习算法进行调整,以最小化预测误差。
5、阈值(Biases)
阈值是加在每个节点输入上的一个常数,用于控制节点的激活。与权值一样,阈值也会在训练过程中被调整。
6、激活函数
激活函数在隐含层和输出层的神经元中使用的函数,用于引入非线性因素,使得神经网络能够学习和处理复杂的模式。它决定了节点在接收到输入后是否被激活。BP神经网络使用的激活函数是Sigmoid函数。此外常见的激活函数还有tanh函数、ReLU函数等,激活函数的选择对网络的性能有重要影响。
sigmoid 取值范围(0,1),这个性质让它适合用于将输入信号转化为(0,1)区间的输出信号,通常用于隐藏层和二分类的输出层。此外它还具有特性:单调连续,处处可微,一般用于隐藏层和二分类的输出层。
Sigmod函数:

Sigmoid的导函数:
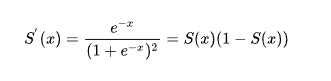
Sigmoid的函数图像:
激活函数由单个神经元的基本结构由线性单元和非线性单元两部分组成。z表示线性单元的输出,g(z)表示非线性单元的输出,函数g就是激活函数。激活函数的作用便是增加非线性因素,解决线性模型表达能力不足的缺陷。
四、梯度下降法
BP网络的梯度下降法是一种优化算法,用于调整神经网络的权重和偏置,以最小化损失函数。(目的:寻求最优解)
梯度下降法模拟了一个下山的过程,通过计算函数在当前位置的梯度(即函数在该点的变化率),然后沿着梯度的反方向(即函数值下降最快的方向)更新权重和偏置,从而逐步接近最小值。这个过程不断迭代,直到达到某个停止条件(如达到预设的迭代次数、损失值的变化小于某个阈值等)

梯度下降法的基本思想可以通过下山的过程来形象地类比,以下是详细的类比过程:
-
山顶与山谷:
在这个类比中,山的高度代表损失函数的值,山顶(最高点)代表高损失,而山谷(最低点)代表低损失。我们的目标是找到山谷的位置,也就是损失函数的最小值。 -
登山者的位置:
登山者(优化算法)开始时站在山的某个位置(初始参数)。这个位置可能是山顶,也可能是山谷,还可能是山腰。 -
寻找下山方向:
登山者想要下到山谷,他会观察周围,找到最陡峭的下山路径。在梯度下降法中,这相当于计算损失函数相对于参数的梯度。梯度指向损失增加最快的方向,因此它的反方向就是最陡的下山方向。 -
下山步伐:
登山者决定下山的步伐大小(学习率)。步伐太小,下山过程会很慢;步伐太大,可能会越过山谷,甚至滑倒或跳跃到另一个山坡上。 -
迭代移动:
登山者沿着最陡的下山方向迈出一步。在梯度下降中,这意味着按照梯度的反方向更新参数。每次迭代后,都希望损失函数的值有所下降。 -
避免局部最小值:
山上可能有多个山谷,有些山谷可能只是局部最低点,而不是我们想要找的全局最低点。在优化中,这对应于局部最小值。选择适当的学习率和算法可以帮助避免陷入局部最小值。 -
收敛:
如果登山者成功,他会到达一个山谷,并且发现四周没有更陡的下山路径。在梯度下降法中,这意味着梯度接近于零,算法找到了损失函数的一个最小值。 -
可能的挑战:
- 如果山势太过陡峭或者有悬崖,登山者可能会遇到危险。在优化中,这可能对应于梯度爆炸或者梯度消失的问题。
- 如果山区被雾气笼罩,登山者可能看不清下山的方向。在优化中,这可能对应于梯度非常小,导致难以确定下一步的移动方向。
可以理解梯度下降法的基本过程(如何通过迭代过程来最小化损失函数)为:
从一个随机点开始,通过不断迭代,逐步逼近最优解(每一步都是朝着减少损失的方向前进)直到找到一个最小值为止。
梯度下降法的基本思想可以用数学公式表示为:
θ₁=θ₀−αΔJ(θ)
其中,θ表示需要优化的参数(权重和偏置),J(θ)是损失函数,α是学习率,控制每一步更新的步长。这个公式表明,每一次迭代,参数都会根据损失函数在当前位置的梯度进行调整,逐步向最小值靠近。
此公式的意义是: J(θ)是关于 θ的一个函数,我们当前所处的位置为θ₀点,要从这个点走到J的最小值点,也就是山底。首先我们先确定前进的方向,也就是梯度的反向,然后走一段距离的步长,也就是 α,走完这个段步长,就到达了θ₁这个点!
具体解释一下, α在梯度下降算法中被称作为学习率或者步长, 意味着我们可以通过 α来控制每一步走的距离, 以保证不要步子跨的太大,其实就是不要走太快, 错过了最低点。同时也要保证不要走的太慢,导致太阳下山了,还没有走到山下.所以 α的选择在梯度下降法中往往是很重要的!α设置的过小时,收敛过程将变得十分缓慢。而当学习率 设置的过大时,梯度可能会在最小值附近来回震荡,甚至可能无法收敛。
五、BP神经网络的训练过程
简单来说神经网络的训练过程可分为两个阶段:
- 通过前向传播算法计算得到预测值,将预测值和真实值作对比,得出两者之间的差距(损失函数)。
- 通过反向传播算法计算损失函数对每一个参数的梯度,再根据梯度和学习率使用梯度下降算法更新每一个参数。
1、前向传播
输入数据从输入层经过隐含层传递到输出层,每一层的输出都是下一层的输入。
具体来说,输入层的信号经过加权和运算后传递给隐藏层,隐藏层的神经元接收来自前一层的信号,经过激活函数处理后再传递给下一层,直到最终到达输出层。每一层的输出都是下一层输入的来源。
在前向传播过程中,神经元的输出计算方式通常为:
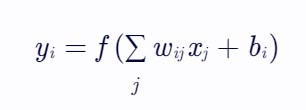
其中,yi表示当前神经元的输出,f(⋅)为激活函数,wij为从神经元j到神经元i的连接权重,xj为前一层的输入(或神经元j的输出),bi为神经元i的偏置项。
2、损失计算
计算输出层的结果与真实值之间的差异,通常使用均方误差或其他损失函数来衡量。
损失值衡量了网络预测的准确性。
3、反向传播
根据损失函数,计算损失对每个权值和阈值的梯度,然后更新这些参数以减少损失。
反向传播是误差从输出层向输入层反向传播的过程,用于调整网络中的连接权重和偏置项,以减小网络输出与期望输出之间的误差。
首先,计算网络输出与期望输出之间的误差,常用的误差函数为均方误差(Mean Squared Error, MSE):
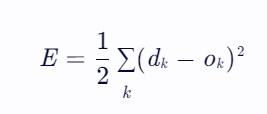
其中,dk为期望输出,ok为实际输出。
然后,利用链式法则计算误差关于各层权重的梯度,即误差信号在各层之间的反向传播。梯度表示了权重变化对误差减少的影响程度,通过梯度下降法更新权重,使误差逐步减小。
权重更新公式为:
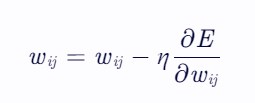
其中,η为学习率,决定了权重更新的步长。
4、迭代优化
重复前向传播和反向传播的过程,直到网络的性能达到满意的水平或达到预定的迭代次数。
六、建立一个BP神经网络步骤
- 定义输入和输出:明确你输入的特征/数据是什么,输出是你希望神经网络预测/分类的目标。
- 设计网络结构:确定输入层的节点数量(与输入特征数相同)、输出层的节点数量(与输出维度相同),以及中间的隐藏层的数量和节点数量。层数的增加只可能是隐含层的增加。
- 初始化权值和阈值:这两个值一般会被初始化为随机值
- 前向传播(Forward Propagation):数据从输入层传到输出层,每个神经元中,输入值乘以权重加上阈值,通过激活函数计算神经元的输出。直到累计产生最终预测结果。
- 计算损失(Loss):损失函数用于衡量神经网络的预测输出与实际输出之间的误差。常见的损失函数包括包括均方误差和交叉熵损失等。目标是通过训练来最小化损失,使得神经网络的输出尽可能接近真实值。
- 反向传播(Back Propagation):反向传播是训练神经网络的核心步骤,通过比较预测输出和实际输出,计算损失函数对权值和阈值的梯度,然后,使用优化算法(如梯度下降法)来根据这些梯度逐渐调整权值和阈值,使损失函数减小。
- 重复训练
- 验证测试
- 模型应用
七、BP算法概述
BP算法,全称为Back Propagation,即误差反向传播算法,是一种用于训练多层前馈神经网络的学习算法。它的基本思想是通过计算预测值与实际值之间的误差,并将这个误差反向传播到网络的各个层级,通过调整神经元之间的连接权值和阈值,使得网络的预测误差最小化。这种通过反向传播误差来调整网络参数的方法,是BP算法的核心。
BP算法的思想就是:通过梯度下降来搜索可能的值的假设空间,以找到最佳的拟合样本的权值。具体而言,即利用损失函数,每次向损失函数负梯度方向移动,直到损失函数取得最小值。也可以这么理解,反向传播算法,是根据损失函数,求出损失函数关于每一层的权值及偏置项的偏导数,也称为梯度,用该值更新初始的权值和偏置项,一直更新到损失函数取得最小值或是设置的迭代次数完成为止。以此来计算神经网络中的最佳的参数。