面试题之数据库-mysql高阶及业务场景设计
最近开始面试了,410面试了一家公司 针对自己薄弱的面试题库,深入了解下,也应付下面试。在这里先祝愿大家在现有公司好好沉淀,定位好自己的目标,在自己的领域上发光发热,在自己想要的领域上(技术管理、项目管理、业务管理等)越走越远!希望各位面试都能稳过,待遇都是杠杠的!
mysql基础问题可以查看:两篇博客会进行不定期更新,更新慢了请大家谅解,大家有想了解的面试题相关,可以评论下,我会尽快更新进去,有些还没更新的稍等,我可能同时在更新各个面试题,抱歉。希望在下个月能读透所有的技术问题,并找到合适的一个公司:面试题之数据库相关-mysql篇-CSDN博客
1.如何设计一个支撑每秒10万写入的高并发MySQL系统
-
分布式架构核心原则
- 分布式架构原则:
- 分而治之:讲写入负载分散到多个节点中
- 异步处理:解耦即使相应与数据持久化
- 冗余扩展:所有组件无单点故障
- 典型架构拓扑
-
客户端 → 负载均衡 → 写入API层 → 消息队列 → 分库分表集群↓缓存集群↓数据分析层
- 分布式架构原则:
-
分库分表详细方案
- 分片策略设计
- 水平分库分表
- 分片路由策略
- 一致性哈希扩容流程:
-
新增物理节点注册到元数据中心
-
数据迁移工具扫描待迁移分片
-
双写新旧分片直至数据同步完成
-
流量切换至新分片
-
清理旧分片冗余数据
-
- 分片策略设计
-
写入链路优化
- 异步写入架构
-
1. 客户端请求 → 2. API服务验证 → 3. 写入Kafka → 4. 返回成功响应↓ 5. 消费者批量写入MySQL → 6. 更新Redis缓存- 批量写入优化
- 消息队列配置:kafka生产配置
-
mysql极致优化
- 关键的innodb参数
- 连接与线程配置
-
高可用保障措施
- 多活数据中心:设置双主同步且都有备库,主库通过专线同步到热备主库,热备主库同步热备从库信息
- 故障自动转移机制
- 性能验证方法
- 压测工具
- 关键指标监控
-
指标 阈值 监控工具 QPS 单库<1万 Prometheus 主从延迟 <100ms pt-heartbeat 线程运行数 <max_connections×80% Grafana 磁盘IOPS <标称值70% iostat
-
典型解决方案
- 热点数据问题
-
动态分片:将热点分片进一步拆分
-
本地缓存:在应用层缓存热点分片路由
-
限流保护:对特定分片实施写入限流
-
-
分布式事务处理
-
本地写入消息队列
-
异步发送MQ(可靠消息服务保证)
-
- 热点数据问题
2.MySQL Group Replication vs MGR vs 传统主从复制?
- 核心架构差异
| 特性 | 传统主从复制 | MySQL Group Replication (MGR) |
|---|---|---|
| 拓扑结构 | 主从星型拓扑 | 全对称P2P架构 |
| 数据同步方式 | 异步/半同步复制 | 基于Paxos协议的原子广播 |
| 组成员管理 | 手动配置 | 自动故障检测与成员管理 |
| 一致性级别 | 最终一致性 | 即时一致性(可配置) |
| 故障切换 | 需手动或借助工具 | 自动选举新Primary |
- 技术对比
- 传统同步
- 数据流:基于binlog的逻辑日志复制
- 模式:
- 异步复制(默认)
- 半同步复制(after_commit/after_sync)
- 局限:
- 脑裂风险
- 切换时可能丢数据
- 从库可能落后
- MGR架构
- 核心组件:
- group communication engine:基于paxos的xcom协议
- certification layer:冲突检测
- 工作流程
- 事务在本地执行
- 广播到组内所有节点
- 多数节点确认后提交
- 应用事务到所有节点
- 关键能力对比
- 核心组件:
- 传统同步
| 能力维度 | 传统复制 | MGR |
|---|---|---|
| 自动故障转移 | ❌ 需要VIP/Proxy | ✅ 内置自动选举 |
| 多主写入 | ❌ 单主 | ✅ 支持多主(需配置) |
| 数据一致性 | 最终一致 | 强一致(多数节点确认) |
| 网络分区容忍 | ❌ 可能丢数据 | ✅ 遵循CP原则 |
| 节点扩展性 | 线性扩展读能力 | 建议3-9个节点 |
- 性能指标对比
| 指标 | 传统半同步复制 | MGR单主模式 | MGR多主模式 |
|---|---|---|---|
| 写入TPS | 12,000 | 9,500 | 7,200 |
| 平均延迟(ms) | 8 | 15 | 22 |
| 故障切换时间(s) | 5-30(手动) | 1-3 | 1-3 |
| 网络带宽消耗 | 1X | 2.5X | 3X |
-
适用场景
-
传统复制适合:
-
读写分离的报表系统
-
异地灾备场景
-
对一致性要求不高的业务
-
已有成熟中间件管理的环境
-
-
MGR适合:
-
需要高可用的核心业务系统
-
金融级数据一致性要求的场景
-
云原生/K8s环境部署
-
希望减少外部依赖的架构
-
-
Q:MGR的Paxos协议如何保证数据一致性?
A:MySQL Group Replication (MGR) 通过改进的Paxos协议(具体实现为XCom)来保证分布式环境下的数据一致性
- 一致性保证核心步骤
- 事务准备阶段:
-
客户端事务在Primary节点执行
-
生成包含所有修改的写集(writeset)
-
写集通过认证层进行冲突检测
-
-
提案广播:
-
Primary节点作为Proposer将写集广播给所有节点
-
节点收到提案后:
-
检查自身状态是否正常
-
验证写集冲突
-
返回Promise应答
-
-
-
多数派确认(Accept/Accepted)
-
当收到多数节点(N/2+1)的Promise后
-
Primary发送Accept请求
-
各节点将事务写入relay log(内存+磁盘)
-
-
全局提交(Learn)
-
收到多数节点的Accepted响应后
-
Primary提交本地事务
-
广播Commit消息通知所有节点
-
所有节点应用该事务
-
- 事务准备阶段:
- 关键一致性保护机制
- 多数派原则(Quorum)
-
每个事务必须得到多数节点确认
-
3节点集群至少2个确认
-
5节点集群至少3个确认
-
公式:
W + R > N(W写节点数, R读节点数, N总节点数)
-
- 冲突检测与解决
-
基于GTID的认证:检查冲突
-
版本向量:每个事务携带版本信息
-
视图同步
-
- 多数派原则(Quorum)
-
异常处理机制
-
节点故障处理
-
故障类型 处理方式 少数节点宕机 继续服务 多数节点宕机 停止服务 网络分区 多数派分区继续服务
-
-
脑裂预防
-
世代时钟(Epoch Number):每次视图变更递增
-
Fencing机制:旧Primary自动降级
-
-
恢复流程
-
故障节点重新加入
-
从最新节点拉取GTID集合
-
自动选择增量同步或全量同步
-
追平数据后重新加入组
-
-
-
与经典的paxos区别
-
特性 经典Paxos MGR-XCom 成员管理 静态 动态 消息传输 原始UDP TCP+流控 领导者角色 临时选举 稳定Primary 数据载体 任意值 事务写集 持久化点 多数接受 多数确认
-
-
性能优化
-
流水线化处理
-
批量认证:合并多个事务的写集检测,减少网络往返次数
-
流控机制
-
-
一致性级别配置
-
MGR支持两种模式:
-
单主模式:SET GLOBAL group_replication_single_primary_mode=ON;
-
所有写操作到primary
-
保证线程一致性
-
-
多主模式:SET GLOBAL group_replication_enforce_update_everywhere_checks=ON;
-
任何节点可写
-
保证因果一致性
-
-
-
3.数据误删后,如何快速恢复(删库删表后的操作)
- 紧急处理流程:
- A[发现误删] --> B[立即停止相关服务] --> C[评估影响范围] --> D[选择恢复方案] --> E[执行恢复] --> F[数据验证] --> G[恢复服务]
- 基于备份恢复流程
- 全量数据备份恢复:根据每日备份的数据进行dump恢复
- 根据时间点恢复:需要binlog有完整的日志
- 前提需要打开binlog日志,查看脚本:show variales like 'log_bin%';-- 相关内容
- 根据binlog日志一个个去找:mysqlbinlog -v binlog.000007 | grep -i "drop table AAA";根据该命令找对应的日志文件。推荐下载到本地,根据binlog中的位置点对数据回滚# at 1020
- 恢复其他节点的日志到1020
- 恢复其他binlog日志7之前的所有的文件恢复:
- mysqlbinlog ./binlog.000001 ./binlog.000002 ./binlog.000003 ./binlog.000004 ./binlog.000005 ./binlog.000006 | mysql -uroot -password
- 恢复日志文件7的到某个节点:mysqlbinlog --stop-position =1020 ./binlog.000007 |mysql -uroot -password
- 恢复其他binlog日志7之前的所有的文件恢复:
- 无备份恢复方案
-
使用binlog2sql工具
-
使用美团开源的myflash工具
-
-
innodb引擎特殊恢复
-
使用undrop-for-innodb工具适用场景:无备份且binlog不可用
-
数据库恢复服务:MySQL数据恢复专家、DiskInternals MySQL Recovery、Kroll Ontrack
-
-
不同操作的恢复策略
| 操作类型 | 恢复难度 | 推荐方案 |
|---|---|---|
| DELETE误删 | ★★☆ | binlog2sql闪回 |
| DROP TABLE | ★★★ | 全备恢复+binlog |
| TRUNCATE | ★★★☆ | 解析表空间文件 |
| DROP DATABASE | ★★★★ | 全备恢复 |
| 磁盘损坏 | ★★★★★ | 专业恢复工具 |
- 预防措施
- 备份策略配置:每天进行数据备份
- 安全防护配置:设置延迟复制从库,启动回收站功能
- 操作审计措施:使用预生产环境测试更新功能并对DDL操作的语句进行审计后执行
- 关键恢复原则
-
立即停止写入:防止覆盖原有数据页
-
优先使用逻辑备份:比物理恢复更安全可控
-
测试恢复流程:定期验证备份有效性
-
保留多个副本:采用3-2-1备份策略(3份副本,2种介质,1份离线)
-
Q:基于binlog的闪回(Flashback)技术实现?
A:MySQL闪回技术是通过逆向解析binlog来恢复误操作数据的关键手段
- 闪回基础原理
- binlog记录机制
- ROW格式:记录行级别变更前镜像(before_image)和变更后镜像(after_image)
- 写入时机:事务提交时一次性写入整个事务的binlog
- 闪回核心思想:delete逆向操作原理
- binlog记录机制
- 主流的闪回技术
| 工具名称 | 开发方 | 语言 | 特点 | 适用场景 |
|---|---|---|---|---|
| binlog2sql | 大众点评 | Python | 纯SQL实现 | 精细恢复 |
| MyFlash | 美团 | C | 二进制级别 | 高性能恢复 |
| mysqlbinlog_flashback | 阿里 | C++ | 集成补丁 | 云环境 |
- binlog2sql实现深度解析
- 核心的处理流程:
- A[解析binlog] --> B[提取DML事件] --> C[构建行变更对象] --> D[生成逆向SQL] --> E[过滤与排序] --> F[输出恢复脚本]
- 关键实现代码:
- 逆向使用update操作
- 解析闪回sql,执行恢复
- 核心的处理流程:
4.主从延迟的根本原因即解决方案
5.InnoDB的自适应哈希索引(AHI)适用场景?
Q:为什么高频等值查询能加速?
6.MySQL的CPU利用率飙高,如何定位?
Q:通过performance_schema分析热点SQL与锁争用?
7.如何优化一条SELECT COUNT(*) FROM big_table?
Q:为什么InnoDB不缓存总行数?替代方案?
8.如果让你设计一个分布式MySQL,你会考虑哪些问题?
Q:数据分片、一致性协议(Raft/Paxos)、分布式事务(XA/TCC)的选择?
9.MySQL 8.0相比5.7的核心改进?
Q:窗口函数、CTE、原子DDL、直方图统计?
10.为什么MySQL默认隔离级别是RR(可重复读)?
- mysql主从复制是通过binlog日志进行数据同步的,而早期的版本中binlog记录的是sql语句的原文。若此时binlog格式设置为statement时,mysql可能在从库执行的sql逻辑与主库不一致。
- 比如在删除某个区间数据时:delete from user where age >=13 and create_time <= '2025-4-15' limit 1;
- 为什么在sql执行结果不一致:
- 在主库执行这条sql的时候,用的是索引age;而在备库执行这条语句的时候,却使用了索引create_time.mysql执行优化器会进行采样预估,在不同的mysql库里面,采样计算出来的预估结果不一样,会影响优化器的判断,由于优化器会进行成本分析,可能最终选择索引不一致。这跟sql执行过程有一定关系。
- 而因为这条delete语句带了limit,所以查出来的记录很大可能不会是同一条数据,排序可能不一样,会导致准备数据不一致的情况。
- 另外使用RC或者RU的话,是不会添加GAP LOCK间隙锁,而主从复制过程中出现的事务乱序问题,更容易导致备库在SQL回滚后与主库内容不一致。所以mysql选择了RR隔离级别
- RR级别在更新数据时会增加记录锁和间隙锁,可以避免事务乱序导致的数据不一致问题。
Q:为啥ORACLE选择的默认级别是RC?
A:oracle目前支持三种事务隔离级别,RC(读已提交,默认),serializable(可串行化),read-only(只读);其中Read-only隔离级别类似于序列化隔离级别,但只读事务甚至不允许在事务中进行数据修改,显然只能选择RC
Q:为何大厂要改成RC?
A:出于性能、死锁和实时性高的需求
- 提高并发性,RC隔离级别下,锁粒度小,只锁住一行数据,提高了并发性,尤其读密集的应用下表现优异。行级锁,减少了锁冲突,提升了并发度。
- 减少死锁,RR级别下会增加GAP Lock和next-key lock,是的所得粒度变大,死锁的概率也增大。而RC隔离级别下不存在间隙锁,只需行锁即可,减少了死锁的发生概率。
- 满足实时性:RC每次读取数据都会获取最新的行版本,适合实时性要求高的应用,而RR读取的数据可能不会反应出其他事务对数据的更改,无法满足对实时性要求高的场景
- 简化主从同步,RC要求实行行式binlog,有助于减少主从同步时数据不一致问题
11.分库分表下如何实现精准分页?
- 全局排序发(推荐)
- 实现步骤:
- 统一排序字段,确保所有的分片使用相同的排序规则,如使用时间排序
-
-- 每个分片执行 SELECT * FROM table ORDER BY sort_field LIMIT (pageNo-1)*pageSize + pageSize - 各分片查询,想所有分片发送相同的分页查询请求
- 内存归并,将分片返回的结果在内存中排序,然后截取制定页数据
- 性能优化:使用流式处理避免内存溢出
- 优点是结果绝对精确,缺点是随着页码增大性能会下降,出现深分页问题
- 二次查询法(优化深分页)
- 实现步骤
- 各分片查询排序字段值(不返回具体完整行数据)
-
SELECT id FROM table ORDER BY create_time LIMIT 10000, 10 - 获取最小/最大边界值
- 用边界值精确查询完整数据
-
SELECT * FROM table WHERE create_time BETWEEN ? AND ? ORDER BY create_time LIMIT 10
- 分片键连续分页法
- 适用场景:
- 分片键本身具有连续性,如时间范围分片
- 能预先确定分片键的分布情况
- 实现方式:
- 根据分片键确定数据所在分片
- 只向特定分片发起查询
- 在该分片内做常规分页
- 适用场景:
- 适用elasticSeach等搜索引擎
- 将分库分表数据同步到ES
- 利用ES的分布式分页能力
- 注意:
- ES的form+size方式也有深分页限制
- 可考虑使用search_after或者scroll api
- 业务层解决方案
- 禁止跳页
- 只提供下一页功能
- 每次携带最后一条记录的排序字段值
-
SELECT * FROM table WHERE create_time < ? ORDER BY create_time DESC LIMIT pageSize
- 禁止跳页
- 性能优化建议
- 避免深分页:产品设计上限制最大页码
- 使用覆盖索引:减少回表操作
- 缓冲热门页:对前几页结果进行缓冲
- 预计算:对静态数据可提前计算分页结果
- 分批获取:客户端分批加载数据(无线滚动)
- 技术选型
| 方案 | 精准度 | 性能 | 实现复杂度 | 适用场景 |
|---|---|---|---|---|
| 全局排序 | 高 | 中/差 | 中 | 数据量中等,要求绝对准确 |
| 二次查询 | 高 | 较好 | 高 | 深分页场景 |
| 分片键连续 | 高 | 优 | 低 | 分片键分布规律明显 |
| ES搜索 | 高 | 优 | 中 | 已使用ES的场景 |
| 禁止跳页 | 中 | 优 | 低 | 用户浏览行为 |
12.mysql如何同步ES?
分库分表的情况下,如果需要精确的查找数据,需要用elasticsearch的集成,此时如何同步ES,有四种方案,应用同步双写、MQ队列双写、基于SQL脚本同步、基于binlog同步组件
- 应用数据库同步双写
- 特点:应用在同步数据库的时候也同步给ES,保障了ES的实时性,实现起来相对简单,不需要引入额外的组件或者复杂的逻辑。但是每次写入mysql的同时写入ES可能会对两个系统的性能产生影响,在高并发的情况下会到值双写失败导致数据不一致等问题,且每次写入操作都需要双写逻辑,增加了业务逻辑的复杂性和维护难度
- 具体实现:
- 代码调整:每次数据库调整的时候,复制相同逻辑到elasticsearch
- 事务管理:使用数据库的事务确保操作的院子性,避免数据不一致
- 性能优化:尽量批量操作或者使用异步方式来处理,降低对性能的影响
- MQ队列异步双写
- 特点:利用MQ队列可以实现异步处理,通过异步方式,可以降低对数据库写入性能的影响,利用消息队列的持久化和重试机制,可以调数据的可靠性。但是由于异步处理会存在数据延迟问题,而且需要引入消息队列和额外的消费者逻辑,增加系统的复杂性。
- 具体实现:
- 消息队列集成:选择兵集成一个消息队列,如kafka或者RabbitMQ
- 业务逻辑修改:将数据写入Mysql后,将变更信息发送到消息队列
- 消费者开发:开发消费者服务,从消息队列中读取消息并异步写入到elasticsearch。
- 异步处理:为消息队列的消费这实现异步处理和重试逻辑
- 基于SQL抽取:
- 特点:通过定时任务,根据数据库的时间戳字段来抽取并同步数据到elasticsearch,同步哦该方式无序修改业务逻辑对原系统无感知,通过定时任务逻辑相对简单易于理解与维护。但是数据库同步存在延迟无法满足实时性要求,定时任务可能对数据库产生额外的查询压力。
- 具体实现:
- 时间戳字段添加,在对应的数据库表中添加时间戳,用于记录数据变更
- 定时任务配置:按照固定频率查询mysql中自上次同步后发生变化的数据。
- 数据抽取:定时任务将查询结果抽取出来,同步到elasticsearch。
- 数据同步:将抽取的数据写入到elasticsearch完成同步过程。
- 利用binlog进行同步
- 特点:利用binlog日志,通过消息队列或者直接消费binlog变化来同步数据库到ES中。不需要修改现有的业务代码,对现有系统无感知,可以利用binlog精确捕捉到数据库的所有变更,确保数据同步的完整性,binlog可以高效地处理数据变更,对源数据库性能营销较小,通常配合消息队列使用,在网络波动或者服务故障的情况下也能保证数据库最终一致性。但是需要搭建和维护binlog监听和消息对垒系统,增加了系统架构的复杂性,虽然基于实时同步,但是遇到消息队列积压,可能会出现数据延迟。
- 具体实现:
- binlog启用:确保mysql实例开启了binlog功能,并且binlog格式(row或者mixed)能够支持所需的数据库同步需求
- binlog监听配置:部署并配置binlog监听器(如debezium),监听制定的mysql实例和数据库
- 消息队列集成:将binlog监听器和消息队列(kafka等)集成,确保binlog变更能够转换成消息并发送到队列中
- 消息消费者开发:开发消息消费者服务,该服务从消息队列中读取binlog变更消息,将其转换成ES可以理解的格式
- 数据同步:消息消费者将转换的数据写入ES完成同步
- 异常处理:实现异常处理机制,确保数据在同步失败后能够进行重试或者日志记录一遍排障。
13.order by如何工作的呢?
ORDER BY 是SQL中用于排序结果集的关键子句,其工作原理在不同数据库系统中有所不同,但核心机制相似。
- 基本流程
-
数据获取阶段:
-
数据库首先执行WHERE条件过滤,获取满足条件的记录集
-
如果使用了索引覆盖扫描,可能直接从索引获取数据
-
-
排序缓冲区(Sort Buffer)操作:
-
数据库分配一块内存区域作为排序缓冲区
-
将待排序数据加载到缓冲区(可能只加载排序键和行指针)
-
当缓冲区不够,会使用磁盘辅助排序
-
-
排序执行阶段:
-
在内存或磁盘上对数据进行排序
-
使用快速排序、归并排序等算法
-
-
结果返回阶段:
-
按照排序后的顺序访问数据行
-
返回给客户端或下一处理阶段
-
-
-
不同场景下的排序
-
能够使用索引排序(最优情况)
-
-- 当有索引(idx_age_name)时
SELECT * FROM users ORDER BY age, name; -
工作方式:
-
直接按索引顺序读取数据(索引本身是有序的)
-
不需要额外排序操作
-
性能最佳(称为"Using index"执行计划)
-
-
-
内存排序(小数据量)
-
-- 数据量小于sort_buffer_size
SELECT * FROM small_table ORDER BY create_time DESC; -
工作方式:
-
在内存排序缓冲区完成全部排序
-
使用快速排序法
-
速度较快(毫秒级完成)
-
-
-
外部排序(大数据量)
-
-- 数据量超过内存限制
SELECT * FROM large_table ORDER BY revenue; -
工作方式:
-
将数据分成多个块,每块在内存中排序后写入临时文件
-
对这些有序临时文件进行多路归并
-
最终得到完全有序的结果集
-
可能涉及磁盘I/O,性能较差
-
-
-
-
关键参数与优化
-
sort_buffer_size
-
控制排序内存缓冲区大小
-
过小会导致频繁磁盘临时文件
-
过大可能浪费内存
-
-
max_length_for_sort_data
-
决定排序时存储完整行还是仅排序键+行指针
-
影响内存使用效率
-
-
tmpdir
-
外部排序时临时文件存储位置
-
应放在高性能存储设备上
-
-
-
执行计划分析
-
通过explain查看排序方式:
-
using filesort:需要额外排序不走
-
using index:可利用索引顺序,无需排序
-
-
-
性能优化
-
为order by 创建合适索引
-
-- 为排序创建复合索引
ALTER TABLE orders ADD INDEX idx_status_created(status, created_at);
-
-
避免select ***
-
-- 只查询需要的列,减少排序数据量
SELECT id, name FROM users ORDER BY age;
-
-
合理设置缓冲区大小
-
-- 会话级调整
SET SESSION sort_buffer_size = 8*1024*1024;
-
-
利用覆盖索引
-
-- 索引包含所有查询字段
SELECT user_id FROM orders
WHERE status='paid'
ORDER BY create_time;
-
-
避免复杂表达是排序
-
-- 不推荐
SELECT * FROM products ORDER BY ROUND(price*0.9);-- 推荐
SELECT *, ROUND(price*0.9) AS discounted_price
FROM products
ORDER BY discounted_price;
-
-
-
特殊场景处理
-
多字段混合排序
-
-- 注意索引设计顺序
SELECT * FROM employees
ORDER BY department ASC, salary DESC;
-
-
limit分页深化
-
-- 深分页问题解决方案
SELECT * FROM large_table
WHERE id > last_seen_id
ORDER BY id
LIMIT 100;
-
-
null值排序控制
-
-- 控制NULL值的排序位置
SELECT * FROM customers
ORDER BY last_purchase_date NULLS LAST;
-
-
Q:我们查询语句怎么匹配到数据的呢?
A:先通过索引树,找到对应的主键,然后在拿到对应的主键ID,搜索id主键索引树,找到对应的行数据,这里前提是为排序字段加上索引且不用*,需要什么字段直接查询什么字段,eg:select name,age,city from user where city ='fuzhou' order by age limit 10,加上order by后的执行流程就是
- mysql为对应的线程初始化sort_buffer,放入需要查询的name、age、city字段
- 从索引树idx_city,找到第一个满足city='fuzhou'条件的id
- 到主键id索引树中,拿到对应的行数据,取name、age、city三个字段值,存到sort_buffer
- 从索引树idx_city拿下一个记录的主键id
- 重复上面两个步骤,知道找不到city=fuzhou的数据为止
- 根据前面找到的所有数据,在sort_buffer中将所有age进行排序
- 按照排序结果前10行返回给调用方
- 找数据->回表->取数据->排序->取前10条记录
Q:sort_buffer不够的时候,磁盘临时文件如何辅助处理?
sort_buffer大小是通过sort_buffer_size来控制的,如果排序的数据小于sort_buffer_size则正在内存中完成,否则需要借助磁盘临时文件处理。
可以通过optimizer_trace,开启统计,在执行sql语句的时候 查询输出统计信息:
-- 打开optimizer_trace,开启统计
set optimizer_trace = "enabled=on";
--执行sql语句
select name,age,city from user where city = 'fuzhou' order by age limit 10;
--查询输出统计信息
select * from information_shcema.optimizer_trace;
根据查询结果中的number_of_tmp_files是否大于0 来查看是否使用了临时文件,sort_mode默认为additional_feilds若使用了临时文件即归并排序算法,大致流程如下:
- 从主键id索引树拿到需要的数据后,放到sort_buffer内存块中,当sort_buffer快满时,对sort_buffer中的数据进行排序,排序后,将数据放到磁盘的一个小文件中。
- 继续回到主键ID索引树种取数据,继续放到sort_buffer内存中,排序后,也要把这些数据写入到磁盘临时小文件中。
- 继续循环,知道去除所有满足条件的数据,最后把磁盘排序好的小文件合并成大文件。
Q:既然sort_buffer中存储不下数据,为何sort_buffer不只放age字段,节省空间呢?
rowid的排序就是只查询sql排序的字段和主键id,然后在sort_buffer中进行排序。
是否开启rowid排序主要通过max_length_for_sort_data参数,该参数mysql用于表示排序行数据的长度,超过这个值,mysql就会主动换成rowid排序,默认为1024,根据我们表设计的字段长度来计算。
将max_length_for_sort_data参数改小后,通过optimizer_trace,开启统计,在执行sql语句的时候 查询输出统计信息:
--设置排序字段单行最大长度为64
set max_length_for_sort_data = 64;-- 打开optimizer_trace,开启统计
set optimizer_trace = "enabled=on";
--执行sql语句
select name,age,city from user where city = 'fuzhou' order by age limit 10;
--查询输出统计信息
select * from information_shcema.optimizer_trace;
根据查询结果中的number_of_tmp_files是否大于0 来查看是否使用了临时文件。
sort_mode来看是否走了rowidrowid排序的一个流程:
- mysql为对应的线程初始化sort_buffer,放入需要排序的age字段以及主键id
- 从索引树中拿到对应符合的数据行,取出排序条件的age和主键id值存储到sort_buffer
- 从索引树中拿到下一个记录的主键id值
- 重复上面两个步骤知道条件不符合即city!='fuzhou'
- 前面几步已经找到city='fuzhou'的数据,在sort_buffer中将所有数据根据age进行排序
- 遍历排序后,取前10行,并按照id的值回表,取出其他需要的字段(city、age、name)返回给调用方
总结:全字段排序与rowid排序对比
- 全字段排序:sort_buffer内存不够的话,就需要用到磁盘临时文件,造成磁盘访问
- rowid排序:sort_buffer可以放更多的数据,但是需要回到原表区数,比全字段多一次回表
一般情况下,对于innodb存储引擎,会优先使用全字段排序,其中max_length_for_sort_data一般为1024,排序字段一般也不会超过这个长度。
14.存储引擎的三大特性
mysql存储引擎中包含三大特性分别为buffer pool、adaptive hash index、double write。
- buffer pool:
- 原理:buffer pool是innodb存储引擎用于缓存数据也和索引的内存区域。它提高了数据库的读写性能,因为数据和索引在内存中读写比在磁盘读写快,当需要访问数据时,会先从buffer pool查找,在进去磁盘查找
- 工作方式:buffer pool采用LRU(最近最少使用)算法来管理内存中的页。当buffer pool满时,会把最近最少使用的也淘汰,腾出新的空间。
- 配置参数:
- innodb_buffer_pool_size:设置buffer pool的大小,通常建议设置为物理内存的70%,以平衡数据库和其他系统的需求。
- innobd_buffer_pool_instances:设置buffer pool的实例数量,用于减少所得竞争,提高并发性能。
- 应用场景适用于频繁读取数据的场景,如事务处理、查询优化等
- Adaptive hash index
- 原理:adaptive hash index (AHI)是innodb存储引擎中的一种内存结构,用于加速等值查询。inodb会自动监控索引的使用情况,如果发现某个索引频繁被访问,就会在内存中为该索引创建哈希索引,减少查询时间。
- 工作方法:AHI是一个哈希表结构,键是索引键值,值是该键值对应的页面位置。需二级索引频繁查询(固定时间内连续多次等值查询==号,>=号不行order by无效)成为热点数据会建立hash index带来速度的提升。可通过%hash_index%查询
- 配置参数
- innodb_adaptive_hash_index:控制是否启用AHI,默认启用。在高并发的场景下,如果CPU资源紧张,可考虑禁用
- innodb_adaptive_hash_index_partitions:设置AHI的分区数量,增加分区数量可以减少哈希冲突,但也会增加内存消耗。
- 应用场景:使用与频繁等值查询,如主键查询或者唯一索引查询。在高并发读取的场景下,AHI可以减少磁盘I/O,条查询应用速度。
- 限制:
- 只能用于等值比较如=,<=> ,IN等
- 无法用于排序
- 存在哈希冲突的可能性,可能导致性能下降
- 维护AHI需要额外的内存和CPU资源
- double write:
- 原理:double write是innodb存储引擎用于提高数据完整性和可靠性的机制。它通常在数据页写入数据文件之前,将他们写入成double write buffer的连续存储区域,确保数据的一致性。如果在写入过程中发生崩溃,innodb可以从double write buffer中恢复数据
- 工作方式:数据页首先被写入double write buffer 然后通过两次写入操作(顺序写)将数据写入文件的适当位置。这种方式减少I/O开销,因为数据是连续写入的。
- 配置参数:
- innodb_doublewrite:控制是否启用,默认启用
- innodb_doublewrite_dir:设置文件存储位置
- innodb_doublewrite_files:定义文件数量
- innodb_doublewrite_pages:控制每个线程的最大double write页数
- 应用场景:用于需要高可靠性和数据一致性的场景。如生产环境中的数据库系统
15.自增id用完了怎么办?
- 表的自增id达到上限后,在申请时它的值就不会该表,进而导致插入时报主键冲突,无法继续插入
- 当表未创建自增Id时rowid自增达到上限后,会归0再重新递增,若出现相同的rowid则覆盖前面的数据
- thread_id自增到上限,重置为0,然后继续增加,但我们在show processlist不会看到两个一样的线程id
16.jion算法说明
jion算法包含了简单嵌套循环,索引嵌套循环,块嵌套循环,哈希连接,排序合并连接
-
简单嵌套循环(simple nested-loop join snlj)
- 原理:驱动表中的每一条记录,会依次与被驱动表中的每一条记录比较,寻找符合条件的匹配记录。
- 特点:SNLJ实现简单,直接,同时也非常低效,通常在小表连接大表的时候使用。
- 优点:实现机器简单,可广泛应用快速验证
- 缺点:性能差,对大数据量的查询效率非常低,尤其是驱动表和被驱动表数据差大的时候。
- 执行过程:
- 从驱动表取出一条记录
- 遍历被驱动表中的所有记录,找到匹配的记录
- 将匹配的结果加入结果集
-
索引嵌套循环连接(index nested-loop join ,inlj)
- 原理:INLJ是嵌套循环连接的优化版本,通过被驱动表上的索引,可以避免对其进行全表扫描,而直接通过索引定位到匹配的记录
- 特点:利用了被驱动表索引提升查询效率,非常适合·小标连接大表·或者·大表间的少量匹配·场景
- 优点:速度快,大幅减少了被驱动表的扫描此书
- 依赖被驱动表索引,若索引丢失,性能直接退化为简单嵌套循环
- 执行过程
- 从驱动表中取出一条记录
- 使用该记录的连接键,通过索引快速定位被驱动表中的匹配记录
- 将匹配结果加入结果集
-
块嵌套循环连接(block nested-loop join,bnlj)
- 原理:在BNLJ中,驱动表的一部分数据会首先被加载到内存缓冲区(join buffer)中,然后在于被驱动表进行比较匹配操作
- 特点:通过批量加载缓冲区减少被驱动表的扫描此书,适合于·大表主键无索引连接·
- 优点:缓冲机制可以显著降低被驱动表扫描次数
- 缺点:对内存消耗较大,缓冲取不足会导致效率下降
- 执行过程:
- 将驱动表的一部分数据加载到join buffer中。
- 遍历被驱动表的所有记录,与join buffer中的数据匹配
- 重复上述过程,知道驱动表的数据全部处理完毕
-
哈希连接(hash join)
- 原理:哈希连接是一种高效的连接算法,适用于·等值连接·,核心思想是
- 构建阶段:以较小的表为基准,基于连接键构建哈希表 作为构建表
- 探测阶段:扫描较大的表(探测表),根据哈希值快速定位构建表中的匹配项
- 特点:哈希连接使用于需要连接的大表之间的数据量大,缺少索引、但连接条件是·等值条件·
- 优点:在等值连接上效率极高,尤其适合无索引的大数据集
- 缺点:无法处理范围条件、不等式条件,哈希表构建阶段对内存的依赖较大
- 执行流程:
- 哈希连接(hash join)是mysql8.0引入的一种高效的连接算法,适用于大数据集的等值连接
- 构建阶段:将较小的表加载到内存中,并基于连接构建哈希表
- 探测阶段:扫描较大的表,根据连接键查找哈希表中的匹配记录
- 原理:哈希连接是一种高效的连接算法,适用于·等值连接·,核心思想是
-
排序合并连接(sort-merge join)
- 原理:排序合并连接通过·先对表的连接键进行排序·,然后使用类似归并排序的方式合并两个表:
- 为表A和表B基于连接键进行排序
- 分别从两个排序后的表读取数据,对比连接键合并匹配的记录
- 对不满足条件的记录,通过移动较小的一方指针解决
- 特点:非常适合需要排序的大表或者需要进行范围条件连接的时候
- 优点:适用于范围条件和等值条件,特别适合超大数据集
- 缺点:排序阶段可能会导致较高的I/O开销
- 执行流程:
- 排序合并连接(sort-merge join)是一种高效的连接算法,特别适用于没有索引的大数据集和需要范围连接的场景。
- 排序阶段:对两个表的连接键进行排序
- 合并阶段:使用类似·归并排序·的方式,依次扫描两个排序后的表
- 原理:排序合并连接通过·先对表的连接键进行排序·,然后使用类似归并排序的方式合并两个表:
-
总结:
- SNLJ:适合小表或者快速验证
- INLJ:优选小表到大表且有索引的场景
- BNLJ:适合无索引的场景
- HASH JOIN:等值连接的高效利器
- SORT-MERGE JOIN:格式和范围查询和排序场景
- Q:为何大厂都不建议使用多表join
- 性能问题:
- 计算复杂性:多表关联需要进行复杂的计算,如哈希连接、合并连接,这些会增加查询的计算开销,影响相应时间
- 资源消耗:join操作特别是在多表参与时,会占用大量的内存和cpu资源,尤其是当色剂大表或者需要大量数据进行join是
- 索引依赖:join性能很大程度上依赖于索引的错在和选择,当索引不当或者没有搜因时,查询性能会大幅度下降
- 可扩展性:
- 水平扩展挑战,在分布式数据库架构中,join操作可能需要跨多个节点获取数据,即跨节点join,这往往会导致大量的数据传输,增加系统负担
- 难以分片,复杂的join查询在分片数据中难以优化,因为涉及多个分片的数据可能位于不同的物理节点上,难以高效的进行
- 维护与复杂度
- 代码复杂性:复杂的多表join查询往往导致sql语句难以理解和维护
- 调试困难:当数据错误或者查询性能不佳时,复杂join查询更难以调试和定位问题
- 架构设计:
- 领域模型割裂:join通常需要深度了解不同表之间的关系,容易导致领域模型设计上不一致
- 微服务架构限制:在微服务架构中,数据通常是中心化和跨服务的,join查询往往违反服务数据自治原则
- 替代策略
- 反范式化:适当的冗余存储以减少join需求
- 数据冗余:在不同表中冗余存储一些公共字段,避免频繁的join
- 分而治之:将复杂的查询拆分为多个简单查询,在应用层进行数据组合
- 预先计算:通过ETL作业预先计算和存储结果
- 使用nosql数据库:设计生产系统数据时,采用文档数据库或者键值存储一类的nosql数据库来支持复杂数据需求
- 性能问题:
17.NULL值引发的命案
- 命案1:count/distinct数据丢失
- count是mysql常用的统计函数,当字段值为NULL时,count(column)会忽略这些记录导致统计不准确
- 解决方案:使用count(*):统计所有的记录,包括字段值为NULL的行
- 扩展:避免使用count(常量),因为他的行为与count(*)一致,但可读性较差
- 当使用count(distinct column1, column2)时,如果任意一个字段值为null,即使另一列有不同的值,查询结果也会忽略这些记录。
- 解决方案:
- 避免字段值为null,在建表时设置字段值非空,并指定默认值;
- 使用代替函数,通过IFNULL(column,default_value)将NULL转换为默认值。
- 解决方案:
- count是mysql常用的统计函数,当字段值为NULL时,count(column)会忽略这些记录导致统计不准确
- 命案2:NULL对比结果为未知
- 在使用非等于查询(<>或者!=)时,NULL值的记录会被忽略
- 解决方案:显示处理NULL,在查询条件中加入对NULL的判断
- 命案3:NULL值运算都为NULL
- 在使用NULL值进行运算,比如加减乘除,拼接等,最终结果都NULL
- 命案4:聚合空指针异常
- 在使用聚合函数(如SUM、AVG)时,如果字段值为NULL,查询结果也会为NULL,而不是预期为0,这可能是导致程序在处理结果时出现空指针异常等。
- 解决方案:使用IFNULL函数,将NULL转换成0
- 命案5:GROUP BY/ORDER BY会统计NULL值
- 在使用group by与order by时,不会剔除NULL,会将NULL作为最小值
- 解决方案:使用is not null ,剔除NULL记录
- 命案6:NULL值导致索引失效?
- 结论:NULL值不一定会导致索引失效,但会影响索引效率
- 字段定义为NOT NULL时
- 查询IS NULL被任务是impossible where 不会走索引
- 查询is not null 通常不走索引,而是全表扫描
- 如果查询只涉及索引字段(覆盖索引场景),is not null查询可以走索引
- 字段允许null时
- 查询条件 is null5.7之后可以走索引,is not null通常不使用索引除非覆盖索引。
- null值分布占比会显著影响查询性能和索引使用
- NULL值分布占比的影响:
- 当NULL值占比较小时,IS NULL查询更倾向于使用索引
- 当非NULL值占比比较小时,is not null 查询更倾向于使用索引
- 优化建议:
- 合理的设计字段属性,对不会存储NULL值的字段建议定义为NOT NULL,减少NULL值处理开销,若字段需要存储NULL值,确保查询条件能够充分利用索引
- 定期更新统计信息:使用analyze table 更新表的统计信息,确保优化器成本估算更准确
- 小结:
- 字段中的NULL值赞比对索引使用有重要影响,
- 当NULL值占比小,IS NULL查询走索引,IS NOT NULL查询可能全表扫描;
- NULL值占比大时,IS NOT NULL查询走索引,IS NULL查询可能全表扫描
- 优化器的成本计算可能出现误判
- 统计信息不准确时,优化器可能错误的选择使用索引。定期更新统计信息避免误判
- 回表操作可能导致性能下降
- 二级索引扫描行数过多时,回表成本可能高于全表扫描
- 字段中的NULL值赞比对索引使用有重要影响,
- 总结:
- 表设计时,尽量避免NULL值,设置字段的默认值为空字符串''或者0
- 查询时显示处理NULL,使用IF NULL或者COALESCE函数将NULL转换成默认值;在查询条件中加入IS NULL或者IS NOT NULL
- 优先使用ISNULL(COLUMN)判断NULL值,提升代码可读性和执行效率
18.mysql备份的方式
- 备份数据三种方式:热备份、温备份、冷备份
- 热备份:当数据库进行备份时,数据库的读写操作不受影响
- 温备份:当数据库备份时,数据库的读操作可以执行,但是不能执行写操作
- 冷备份:当数据库备份时,数据库不能进行读写操作,需要下线处理
- innodb支持三种备份方式,而myisam不支持热备份
- 数据库备份两种方式:物理备份、逻辑备份
- 物理备份:通过tar、cp等命令直接打包复制数据库的书库文件,达到备份效果
- 逻辑备份:通过特定工具从数据库导出数据并另存备份(逻辑备份丢失数据的精度)
- 备份策略
- 一般备份需要备份:数据、二进制日志 innodb事务日志、代码(存储过程、存储函数、触发器、事件调度器)、服务器配置文件
- 直接cp,tar复制数据库文件:数据量小,直接复制数据库文件
- mysqldump:数据量一般,先使用mysqldump对数据库进行完全备份
- xtrabackup:数据量很大,而又不过分影响运行,使用xtarback进行完全备份后,定期使用xtrabackup进行增量备份或者差异备份
- 备份工具:
- mysqldump:逻辑备份工具,适合所有的存储引擎,支持温备、完全备份、部分备份,对于innodb存储引擎支持热备cp,tar等归档复制工具
- 物理备份工具,使用与所有的存储引擎,冷备、完全备份和部分备份
- lvm2 snapshot:几乎热备,借助文件系统管理工具进行备份
- mysqlhot copy:名不副实的一个工具,几乎冷备,仅支持myisam存储引擎,
- xtrabackup:一款非常强大的innodb/etardb热备工具,支持完全备份、增量备份
19.数据库在线迁移方案
20.对大表的查询,为何不会把内存撑爆?
- 假设我们要对一个300G的innodb表A执行一个全表扫描。当未设置查询条件,select * from A;此时innodb的郑航数据保存在主键索引上的,所以全表扫描实际是直接扫描表A的主键索引,由于没有设置条件,所以查到的每一行数据都可以直接放到结果集返回给调用方。
- 执行逻辑
- 获取一行,写到net_buffer。这块内存的大小由参数net_buffer_length定义,默认为16K
- 重复后去行,知道net_buffer写满,调用网络接口发出去
- 如果发送成功,就清空net_buffer,然后继续取下一行数据,并写入到net_buffer。
- 如果发送函数返回eagain或者wsaewouldblock,就标识本地网络栈(socket send buffer)写满了,进入等待,知道网路栈重新可写,在继续发送。
- 执行流程
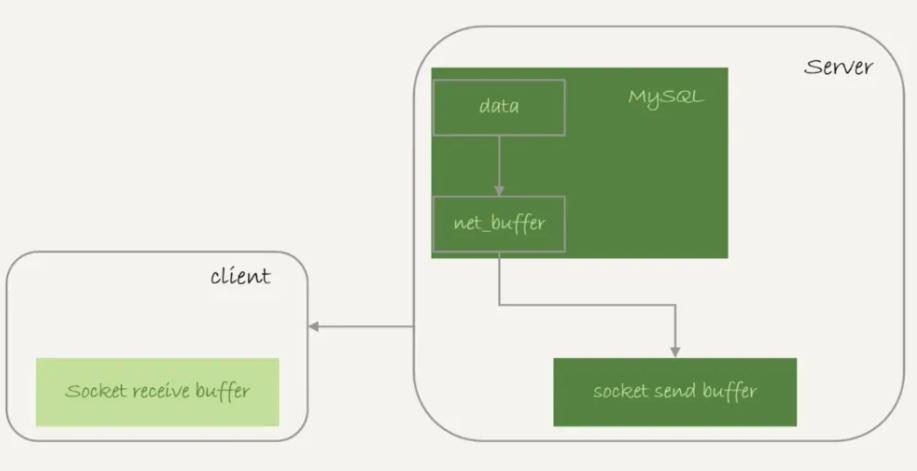
- 一个查询在发送过程中,占用的mysql内部内存最大就是net_buffer_length这么大,并不会达到300G
- socket send buffer 也可能达到300G(默认定义/proc/sys/net/core/wmem_default),如果socket send buffer 被写满,就会暂停读数据的流程
- 也就是说mysql是边读边发的,这就说明若客户端接收比较慢,会导致mysql服务端由于结果发不出去,这个事务的执行时间边长,但是不会导致数据库内存打爆。
21.加密后的数据如何支持模糊查询
- 内存解密:数据量小时,简单方便,但数据量大时可能会导致OOM
- 映射查询:建立两个表的映射关系,加密表通过非加密表进行数据查询
- 加密函数:通过AES DES等方式对字段解密后查询
- 分片查询:根据加密算法的策略对字段值进行分片拆分后查询
22.mysql8的索引跳跃扫描?
- mysql中的索引跳跃扫描(skip scan)是一种优化策略,为了提高特定条件下对符合索引的利用效率。
- 以staff表为例,表中有id、dept、job三个字段,并对dept和job进行复合索引
-
id dept job 1 软件 it 2 软件 it 3 管理 am 4 管理 bm - 跳跃扫描的优化实现
- 分区扫描
- 将索引按照dept的唯一值进行分割,每个分区相当于不同的部门。
- 应用条件
- 对每个dept分区中的position行进行扫描,即跳跃扫描仅搜索job='it'的员工
- 跳过无关分区
- 由于job='it'的限定,我们只在每个dept的分区中寻找匹配的job而不是对整个表进行扫描
- 分区扫描
- 实际效果
- 虽然mysql索引跳跃扫描概率上并不是独立标识的特性,但此类索引优化策略在新版的mysql中能改进索引条件推送和查询优化器来实现。他潜在的减少了读取和滤除不必要的数据开销。
22.分库分表后的分布式ID生成方案
- 步长的方式:
- 自增主键的步长,默认为1,根据分库的数据库数量设置步长
- 缺点是无法进行扩容
- 号段的方式
- 维护号段表,根据号段初始值,号段步长版本号等信息,进行id获取
- 缺点是号段表挂掉后 无法获取
- uuid:
- 缺点是需要将主键ID类型改成varchar,影响B+树排序,插入和查询受到影响
- 进一步优化是将uuid作为业务的唯一主键,而原先的主键在各库中继续执行,不能作为唯一ID,但后续无法合并
- redis生成ID
- 缺点是redis挂掉后,自增ID会收到影响
- 解决方式就是持久化
- RDB每隔一段时间持久化
- AOF:每次执行时进行保存,
- 配合数据库存储redis提高并发安全性
- 雪花算法:
- 41为时间戳+10为工作进程+12序列号
- 缺点 时间回拨
- 参考大厂设计:百度、美团都是使用雪花算法,美团修复了时钟回拨问题,滴滴基于数据库号段唯一模式生成器处理