Transformer-PyTorch实战项目——文本分类
Transformer-PyTorch实战项目——文本分类
————————————————————————————————————————————
【前言】
这篇文章将带领大家使用Hugging Face里的模型进行微调,并运用在我们自己的新项目——文本分类中。需要大家提前下载好Trasformers库,并配置好环境。
【数据集来源】link
————————————————————————————————————————————
目录
- Transformer-PyTorch实战项目——文本分类
- 【前言】
- Step1 导入相关包
- Step2 加载数据
- Step3 创建Dataset
- Step4 划分数据集
- Step5 创建Dataloader
- Step6 创建模型及优化器
- Step7 训练与验证
- Step8 模型训练
- Step9 模型预测
————————————————————————————————————————————
Step1 导入相关包
from transformers import AutoTokenizer, AutoModelForSequenceClassification
————————————————————————————————————————————
Step2 加载数据
import pandas as pddata = pd.read_csv("./ChnSentiCorp_htl_all.csv")
data
运行结果:

我们可以看到这是一个关于酒店评论的数据集,内容为“review”,标签为“label”
【注意】这里我们需要提醒一下:数据集中有可能会存在空项。这时我们需要将数据集中的空项去除,将数据集规整。
我们可以用下面代码进行处理:
data = data.dropna()
data
运行结果:

我们可以看到这张图片的维度是 {7765 × 2},而上一张图片的维度是 {7766 × 2},也就是说在这个数据集中有一条空项。
当数据量很大时我们无法通过常规检索方式检查数据集中是否有空项,那么我们可以在每一次加载数据集的时候运行这段代码,以确保一处数据集中的空项
————————————————————————————————————————————
Step3 创建Dataset
from torch.utils.data import Datasetclass MyDataset(Dataset):def __init__(self) -> None:super().__init__()self.data = pd.read_csv("./ChnSentiCorp_htl_all.csv")self.data = self.data.dropna()def __getitem__(self, index):return self.data.iloc[index]["review"], self.data.iloc[index]["label"]def __len__(self):return len(self.data)
1.初始化时,MyDataset会调用pandas中的read_csv()函数从地址中读取解析数据集
2.getitem()定义通过索引访问类的实例中的数据
3.len()用于返回对象的长度,它用于告诉 DataLoader 数据集的大小,从而正确地分批加载数据。
dataset = MyDataset()
for i in range(5):print(dataset[i])
运行和结果:

————————————————————————————————————————————
Step4 划分数据集
from torch.utils.data import random_splittrainset, validset = random_split(dataset, lengths=[0.9, 0.1])
len(trainset), len(validset)
这一步主要用于将数据集划分为训练集和测试集。
lengths=[0.9,0.1]
将数据集按照【训练集 :测试集】=【0.9 :0.1】的比例来划分
除了这种方式,一下这种方式也可以划分数据集
# 手动划分数据集
train_data = data[:90]
train_labels = labels[:90]
valid_data = data[90:]
valid_labels = labels[90:]
运行结果:

训练集有6989个样例,测试集有776个样例
————————————————————————————————————————————
Step5 创建Dataloader
import torchtokenizer = AutoTokenizer.from_pretrained("hfl/rbt3")def collate_func(batch):texts, labels = [], []for item in batch:texts.append(item[0])labels.append(item[1])#将输入统一规整到一定的长度inputs = tokenizer(texts, max_length=128, padding="max_length", truncation=True, return_tensors="pt")inputs["labels"] = torch.tensor(labels)return inputs
这段代码定义了一个 collate_func 函数,用于在使用 PyTorch 的 DataLoader 时对数据进行批处理。这个函数的作用是将一个批次的数据(batch)转换为模型可以直接输入的格式。
1.AutoTokenizer.from_pretrained(“hfl/rbt3”):
①使用 Hugging Face 的 transformers 库加载预训练的分词器(hfl/rbt3 是一个预训练的中文模型)。
②分词器的作用是将文本转换为模型可以理解的输入格式(如 token IDs 和注意力掩码)。
2.batch:
①batch 是一个列表,每个元素是一个元组 (text, label),表示一个样本及其对应的标签。
②这个列表是由 DataLoader 提供的,DataLoader 会将数据集中的样本按批次加载。
3.texts 和 labels:
①texts 是一个列表,存储所有样本的文本内容。
②labels 是一个列表,存储所有样本的标签。
3.tokenizer(texts, …):
①使用分词器对文本进行处理,将文本转换为模型可以理解的格式。
②max_length=128:将所有文本的长度统一为 128。
③padding=“max_length”:如果文本长度不足 128,用填充符([PAD])填充到 128。
④truncation=True:如果文本长度超过 128,截断为 128。
⑤return_tensors=“pt”:返回 PyTorch 张量。
⑥inputs[“labels”]:将标签列表转换为 PyTorch 张量,并存储在 inputs 字典中,键为 “labels”。
4.返回值:
inputs 是一个字典,包含处理后的输入数据和标签,可以直接传递给模型进行训练或推理。
from torch.utils.data import DataLoadertrainloader = DataLoader(trainset, batch_size=32, shuffle=True, collate_fn=collate_func)
validloader = DataLoader(validset, batch_size=64, shuffle=False, collate_fn=collate_func)
这段代码展示了如何使用 PyTorch 的 DataLoader 类来创建训练集和验证集的数据加载器(DataLoader)。DataLoader 是 PyTorch 中用于加载数据的工具,它支持批量加载、打乱数据、多线程数据加载等功能。
1.trainset 和 validset:
①trainset 和 validset 是数据集对象,通常是继承自 torch.utils.data.Dataset 的自定义类的实例。
②这些数据集对象需要实现 len 和 getitem 方法,以便 DataLoader 可以正确地加载数据。
2.batch_size:
①batch_size 参数指定每个批次加载的数据样本数量。
②在训练时,通常使用较小的批次大小(如 32),以便更好地利用 GPU 的计算能力。
③在验证时,可以使用较大的批次大小(如 64),以加快验证速度。
.3.shuffle:
①shuffle 参数控制是否在每个 epoch 开始时打乱数据。
②在训练时,通常设置为 True,以避免模型对数据的顺序产生依赖。
③在验证时,通常设置为 False,以保持数据的顺序一致。
4.collate_fn:
①collate_fn 是一个函数,用于将多个样本组合成一个批次。
②默认情况下,DataLoader 会将多个样本组合成一个列表。如果需要对数据进行特殊处理(如填充、截断等),可以自定义 collate_fn。
③在上述代码中,collate_func 是一个自定义的函数,用于处理文本数据并将其转换为模型可以接受的格式。
5.collate_func 的作用
collate_func 是一个自定义函数,用于将一个批次的数据(batch)转换为模型可以直接输入的格式。具体来说,它完成以下任务:
①提取每个样本的文本和标签。
②使用分词器对文本进行处理,将文本转换为 token IDs 和注意力掩码。
③将标签列表转换为 PyTorch 张量。
④返回一个字典,包含处理后的输入数据和标签。
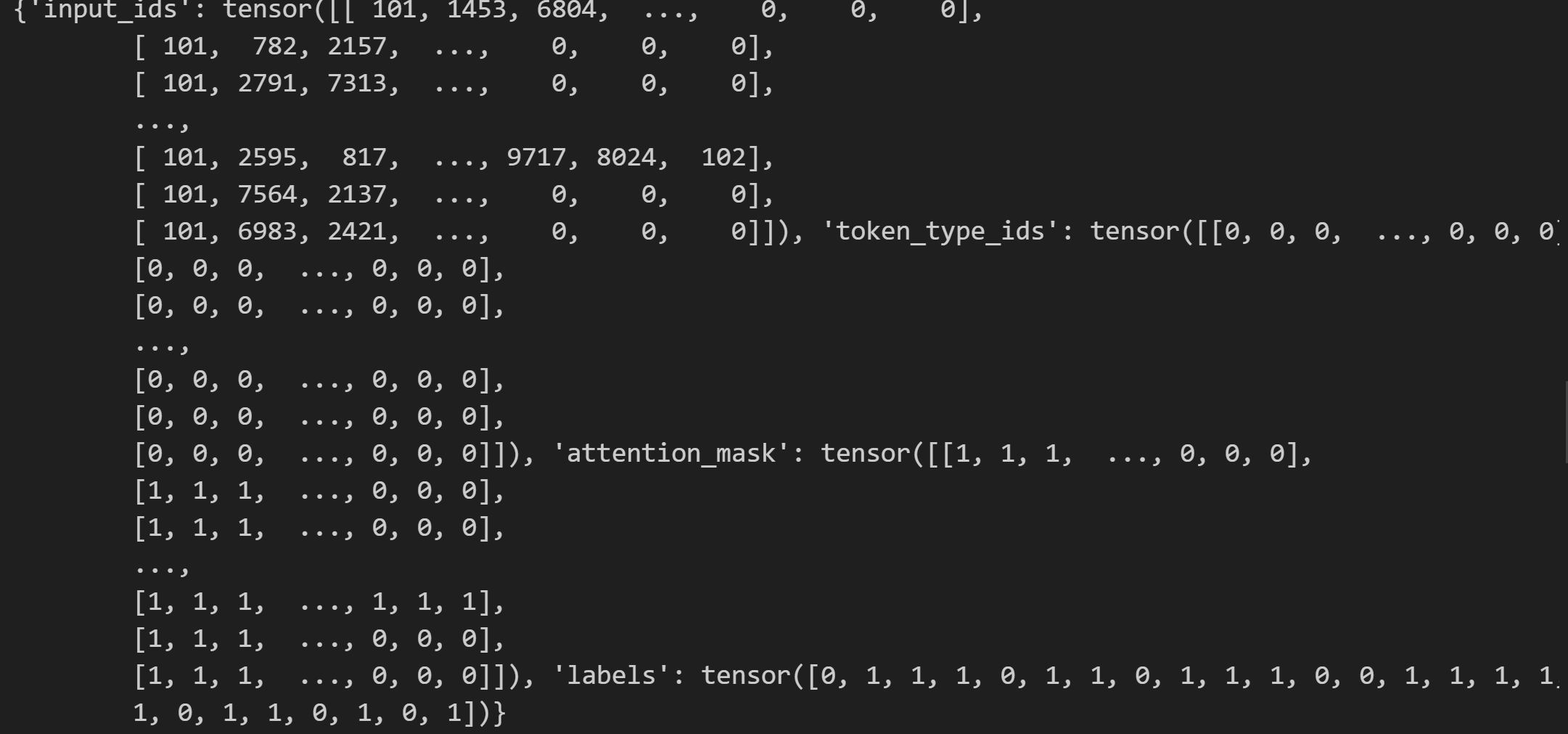
next(enumerate(trainloader))[1]
运行结果:
查看输入的矩阵
————————————————————————————————————————————
Step6 创建模型及优化器
from torch.optim import Adammodel = AutoModelForSequenceClassification.from_pretrained("hfl/rbt3")if torch.cuda.is_available():model = model.cuda()
1.AutoModelForSequenceClassification.from_pretrained(“hfl/rbt3”):
①使用 Hugging Face 的 transformers 库加载预训练的模型。
②hfl/rbt3 是一个预训练的中文模型,适用于序列分类任务(如情感分析、文本分类等)。
③AutoModelForSequenceClassification 是一个通用类,可以根据预训练模型的类型自动加载相应的模型。
2.torch.cuda.is_available():
①检查是否有可用的 GPU。
②如果有可用的 GPU,torch.cuda.is_available() 返回 True,否则返回 False。
3.model.cuda():
①将模型移动到 GPU 上。
②cuda() 方法会将模型的所有参数和缓冲区移动到 GPU 上,从而加速模型的训练和推理。
————————————————————————————————————————————
Step7 训练与验证
def evaluate():model.eval()acc_num = 0with torch.inference_mode():for batch in validloader:if torch.cuda.is_available():batch = {k: v.cuda() for k, v in batch.items()}output = model(**batch)pred = torch.argmax(output.logits, dim=-1)acc_num += (pred.long() == batch["labels"].long()).float().sum()return acc_num / len(validset)
1. model.eval():
将模型设置为评估模式,关闭 Dropout 和 BatchNorm 等训练时的特定行为。
2.torch.inference_mode():
使用 torch.inference_mode() 上下文管理器,禁用梯度计算,提高推理速度并减少内存占用。
3.batch:
①batch 是一个字典,包含输入数据和标签。
②如果 GPU 可用,将数据移动到 GPU 上。
4.output.logits:
①模型的输出是一个包含 logits 的对象。
②使用 torch.argmax 获取预测的类别。
5.acc_num:
①统计预测正确的样本数量。
②使用 (pred.long() == batch[“labels”].long()).float().sum() 计算每个批次中预测正确的样本数量。
6.返回值:
返回准确率,即预测正确的样本数量除以验证集的总样本数量。
def train(epoch=3, log_step=100):global_step = 0for ep in range(epoch):model.train()for batch in trainloader:if torch.cuda.is_available():batch = {k: v.cuda() for k, v in batch.items()}optimizer.zero_grad()output = model(**batch)output.loss.backward()optimizer.step()if global_step % log_step == 0:print(f"ep: {ep}, global_step: {global_step}, loss: {output.loss.item()}")global_step += 1acc = evaluate()print(f"ep: {ep}, acc: {acc}")
train() 函数
train() 函数用于训练模型,并在每个 epoch 结束时调用 evaluate() 函数评估模型的准确率。
1.model.train():
将模型设置为训练模式,启用 Dropout 和 BatchNorm 等训练时的特定行为。
2.global_step:
用于记录全局步数,即整个训练过程中处理的批次总数。
3.optimizer.zero_grad():
清空之前的梯度,避免梯度累积。
4.output.loss.backward():
计算损失的梯度,并通过反向传播更新模型参数。
5.optimizer.step():
更新模型参数。
6.日志记录:
每隔 log_step 个步骤打印一次训练损失。
7.调用 evaluate():
在每个 epoch 结束时调用 evaluate() 函数,评估模型在验证集上的准确率。
————————————————————————————————————————————
Step8 模型训练
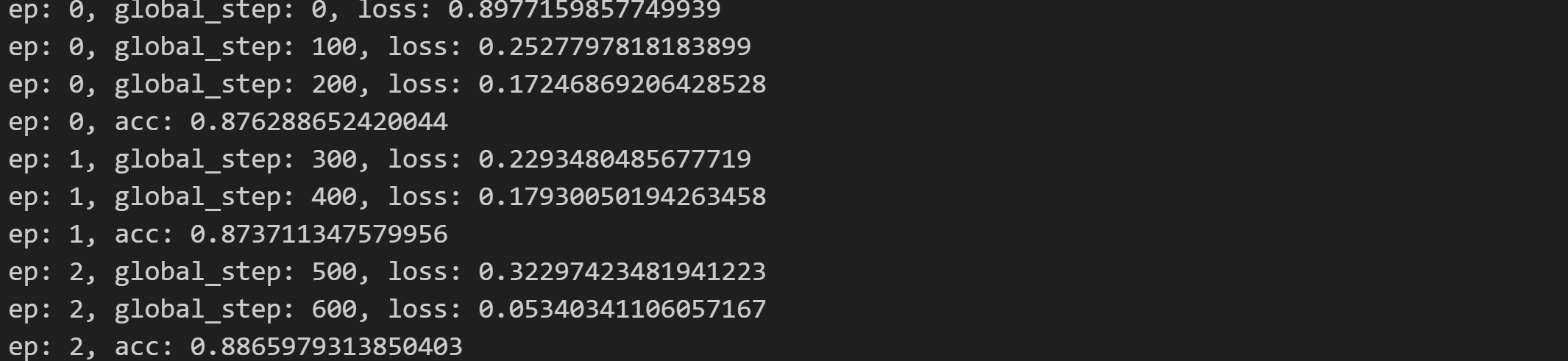
train()
运行结果:
————————————————————————————————————————————
Step9 模型预测
sen = "我觉得这家酒店不错,饭很好吃!"
id2_label = {0: "差评!", 1: "好评!"}
model.eval()
with torch.inference_mode():inputs = tokenizer(sen, return_tensors="pt")#inputs = {k: v.cuda() for k, v in inputs.items()}logits = model(**inputs).logitspred = torch.argmax(logits, dim=-1)print(f"输入:{sen}\n模型预测结果:{id2_label.get(pred.item())}")
1. sen:
输入的文本句子,表示对酒店的评价。
2.id2_label:
一个字典,将模型的预测结果(类别索引)映射为人类可读的标签。0 表示差评,1 表示好评。
3.model.eval():
将模型设置为评估模式,关闭 Dropout 和 BatchNorm 等训练时的特定行为。
4.torch.inference_mode():
使用 torch.inference_mode() 上下文管理器,禁用梯度计算,提高推理速度并减少内存占用。
5.tokenizer(sen, return_tensors=“pt”):
使用分词器对输入文本进行处理,生成模型可以理解的输入格式(如 token IDs 和注意力掩码)。
return_tensors=“pt” 表示返回 PyTorch 张量。
6.inputs = {k: v.cuda() for k, v in inputs.items()}:
如果 GPU 可用,将输入数据移动到 GPU 上。这一步在代码中被注释掉了,可以根据需要启用。
**7.model(**inputs).logits:
将处理后的输入传递给模型,获取模型的输出(logits)。
8.torch.argmax(logits, dim=-1):
使用 torch.argmax 获取 logits 的最大值所在的索引,即预测的类别。
9.id2_label.get(pred.item()):
将预测的类别索引通过 id2_label 映射为人类可读的标签。
10.输出结果:
打印输入句子和模型的预测结果。