Domain Adaptation领域自适应--李宏毅机器学习笔记
个人学习笔记,如有错误欢迎指正,也欢迎交流,其他笔记见个人空间
背景与问题定义
传统监督学习假设:训练集与测试集数据分布一致。
Domain Shift:测试数据分布与训练数据不同,模型泛化性能骤降 。
例如在黑白图像上训练数字分类器,测试时用彩色图像,准确率骤降。
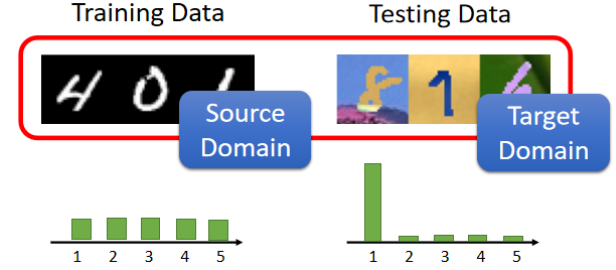
Domain Adaptation(领域自适应)
目标:在Source Domain(有标签)上训练的模型能在Target Domain(无标签或少量标签)上保持良好性能。

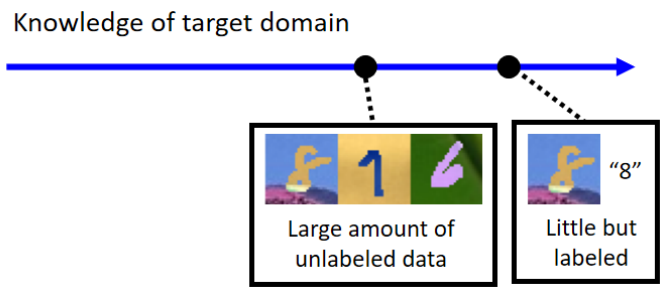
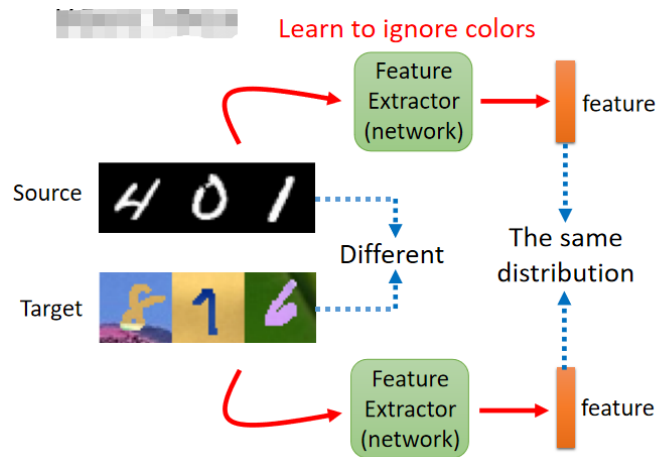
基础思路:学习领域无关的表示
-
引入Feature Extractor,提取源域与目标域的共享特征。
-
要求:无论输入图片来源哪一域,提取的特征分布应尽可能一致。
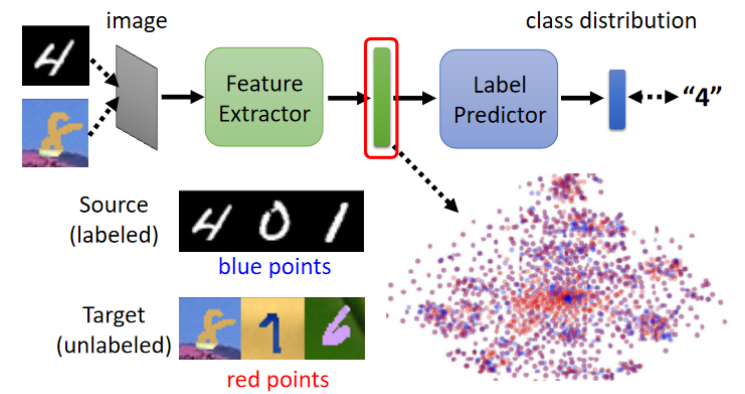
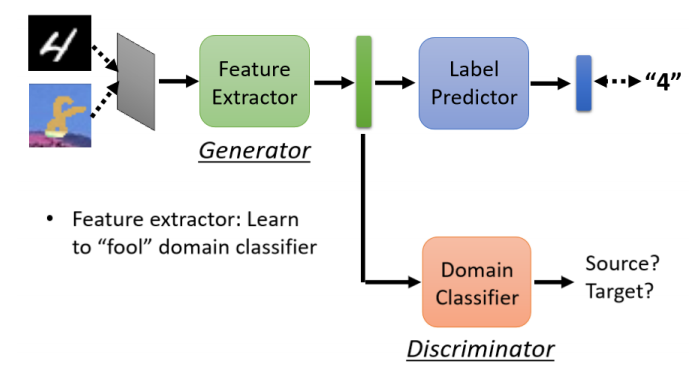
关键技术:Domain Adversarial Training
-
模型结构:
-
Feature Extractor:提取特征。
-
Label Predictor:分类器。
-
Domain Classifier:判断特征来自 Source 还是 Target。
- 希望 Source Domain 的图片 , 丢进 Feature 跟 Target Domain 的图片丢进去 Feature提取出的特征 看起来要分不出 差异
-
-
类比于 GAN:
-
Feature Extractor 类似 Generator;
-
Domain Classifier 类似 Discriminator。
-
问题:会不会Feature Extractor每次故意提取出无效的特征导致训练失败?
并不会,因为虽然需要混淆 Source 和 Target 的域差异(欺骗 Domain Classifier),同时又要提取对分类有用的特征(服务于 Label Predictor)。
训练方法:
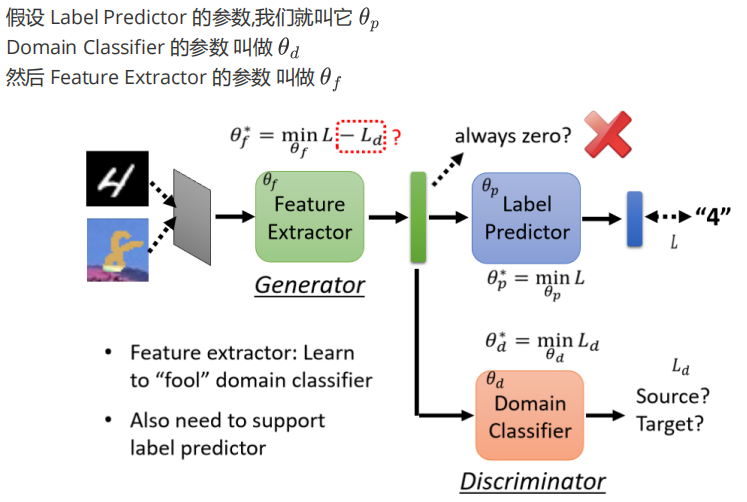
对于 Source Domain的图片,是有标签的。所以可以制定一个Loss L,Ld是 Domain Loss,即领域判别的损失
![]()
可以理解为
-
它想让分类器分类准(minimize L);
-
同时又让 Domain Classifier 无法判断出域(maximize Ld)。
通过这里我们可以再回答一遍Feature Extractor会不会训练成故意提取出无效的特征?
如果Feature Extractor 把所有输入都映射为 zero vector,那么 Domain Classifier 完全无法判断这是 Source 还是 Target → Ld 很高 ✅(它被骗了);但是,Label Predictor 完全无法分类 → L 也会很高 ❌