【Java集合】HashMap源码深度分析
参考笔记:java HashMap 源码分析(深度讲解)_怎么看hashmap底层源码-CSDN博客
目录
一、前言
二、HashMap简介
三、HashMap的底层实现
四、HashMap源码解读
0.准备工作
1.跳入无参构造
2.向集合中添加第一个键值对
① 跳入put方法
② 跳入putVal方法
③ 跳入resize方法
④ 回到 putVal 方法
⑤ 回到演示类
3.向集合中添加第二个键值对
4.向集合中添加第三个键值对:演示put方法对重复key的处理过程
① 跳入putVal方法
② 回到演示类
5.扩容机制+链表转换为红黑树
五、完结
一、前言
本文将通过 Debug 流程分析,解读 HashMap 类的底层源码。在之前我写了一篇HashSet 的源码分析,而 HashSet 的底层其实就是 HaspMap ,只不过 HashSet 是单列集合, 所以相当于只使用了 HashMap 的 key(键),而没有使用 value(值)罢了。所以,强烈建议看本文之前对于 HashSet 的源码比较了解或者看过我的这篇博文:
【Java集合】HashSet源码深度分析-CSDN博客文章浏览阅读502次,点赞10次,收藏20次。本篇博文是对单列集合Set的实现类HashSet的内容补充。之前在Set集合的详解篇,只是拿HashSet演示了Set接口中的常用方法,并没有对它进行深究本文会从底层源码的角度对HashSet进入深入研究通过Debug从底层解释HashSet如何添加元素如何判断重复元素扩容机制链表转化为红黑树的过程本篇博文对HashSet源码的解读基于主流的JDK 8.0的版本HashSet是单列集合Set接口的常用实现类之一,满足Set集合"无序,不可重复"的特点。
https://blog.csdn.net/m0_55908255/article/details/146999979?sharetype=blogdetail&sharerId=146999979&sharerefer=PC&sharesource=m0_55908255&spm=1011.2480.3001.8118 HashMap 和 HashSet 源码分析可以说非常相似,只有细微的一些区别,所以本文写得比较简略
注意:本篇博文对 HashMap 源码的解读基于主流的 JDK 8.0 的版本

二、HashMap简介
① HashMap 是 Map 集合体系中使用频率最高的一个实现类。HashMap 的方法没有使用synchronized 关键字修饰,因此 HashMap 是线程不同步的
② HashMap 类位于 java.util.HashMap 下,其类定义、继承关系图如下:
三、HashMap的底层实现
① HashMap 底层维护了 HashMap$Node 类型的数组 table ,默认为 null 。HashMap 的底层是 "数组 + 链表 + 红黑树" 的结构。简单来说,即 table 数组的元素是一个链表,并且在某些条件下会将链表树化为红黑树
② 向 HashMap 集合添加一个 key-value 键值对时,会先得到 key 的 hash 值(哈希值),然后在底层将它转化为一个索引值。这个索引值决定该元素在集合中应该存放的位置
③ 得到 key 的 hash 值,将其转换为索引值后,添加 key-value 键值对 的规则如下:
-
当索引值对应的位置没有 key-value 键值对存在时:直接将当前键值对加入集合
-
当索引值对应的位置有 key-value 键值对存在时,判断新添加的键值对的 key 与该位置的键值对的 key 是否相等:
-
相等:放弃添加该键值对,用新 value 覆盖旧 value ,并返回旧的 value 值
-
不相等:还要作进一步的判断,判断添加的键值对的 key 是否与该索引处链表中某个键值对的 key 相等
-
是:放弃添加该键值对,用新 value 覆盖旧 value ,并返回旧的 value 值
-
否:将添加的 key-value 键值对挂载到链表后面
-
-
以上便实现了 "数组+链表+红黑树" 的结构,如下图所示:
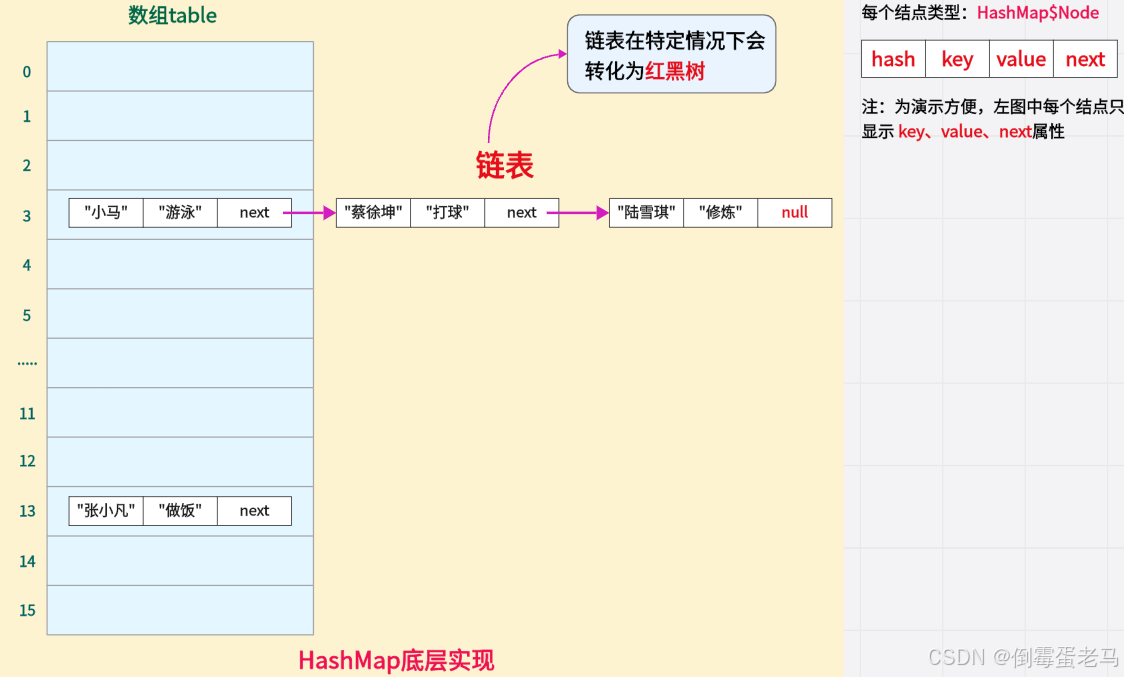
注:上图中 "table数组长度" = 16 ,"table数组的元素个数" = 3 + 1 = 4
可以看到,table 数组中每个结点都是 HashMap$Node 类型,Node 是 HashMap 的一个静态内部类,其源码定义如下:
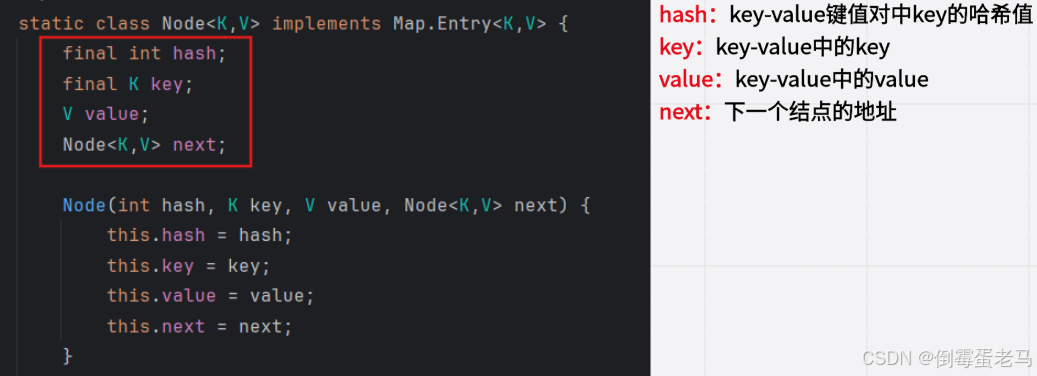
④ 第一次向 HashMap 集合中添加元素时,底层的 table 数组长度会扩容到 16 ,临界值 threshold = 16 * 0.75 = 12 ;之后每当 table 数组中的元素个数超过临界值时,就要对 table 数组进行扩容,容量和临界值都扩大 1 倍,以此类推
⑤ 在 JDK 8.0 版本中,对某个链表是否转换为红黑树,会进行下述步骤:
-
判断该链表是否满足元素个数 > 8 ?
-
> 8:还需要进一步的判断:
-
若 table 数组的长度 >= 64:对该链表进行树化,转换为红黑树
-
若 table 数组的长度 < 64:对 table 数组进行扩容,将 table 数组的长度扩大一倍,临界值扩大一致,但不对该链表进行树化
-
-
< = 8:不对该链表进行树化
-
四、HashMap源码解读
0.准备工作
用以下代码作为演示类,一步一步 Debug :
import java.util.HashMap;
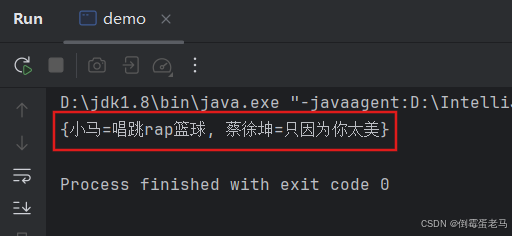
public class demo {public static void main(String[] args) {HashMap hashMap = new HashMap();hashMap.put("小马", "游泳");hashMap.put("蔡徐坤", "只因为你太美");hashMap.put("小马", "唱跳rap篮球");System.out.println(hashMap);}
}运行结果:
1.跳入无参构造
ok,开始 Debug 。先跳入 HashMap 的 无参构造,如下图所示:
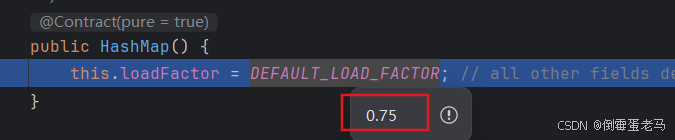
可以看到,无参构造的作用:将默认增长因子 loadFactor 初始为了 0.75
接着跳出构造器。在演示类中查看 HashMap 集合的状态:
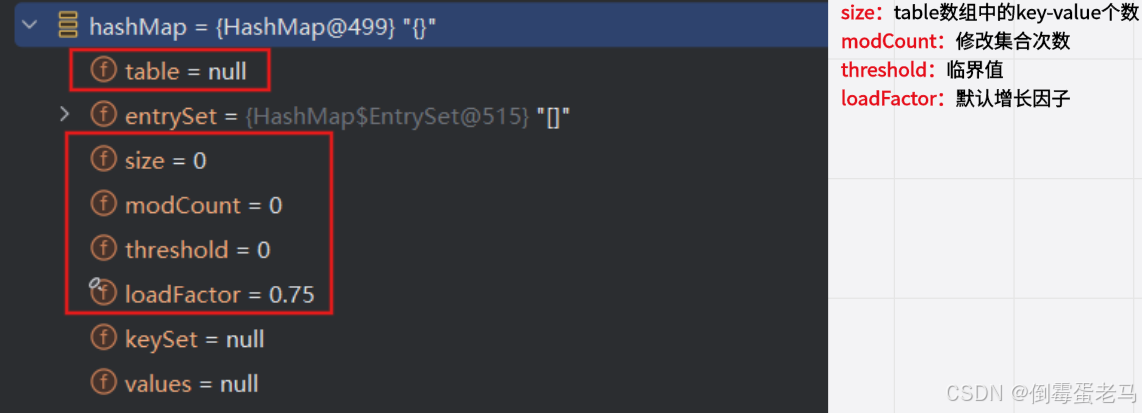
可以看到,此时 HashMap$Node[] table = null
2.向集合中添加第一个键值对
向集合中添加第一个键值对:{key:"小马",value:"游泳"}
① 跳入put方法
首先跳入 put 方法,如下图所示:
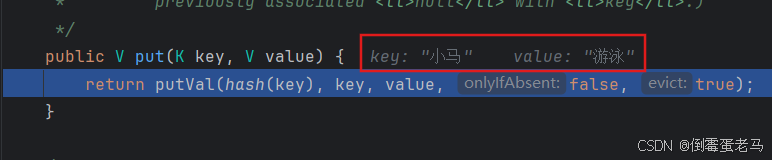
可以看到,key = "小马" ;并且 value 值不再是在 HashSet 源码分析中见到的那个PRESENT 占位符了,而是 value = "游泳"
put 方法的内部又调用了 putVal 方法,并且传入了 5 个实参:① hash方法的返回值;② key;③ value;④ false(传递给onlyIfAbsent);⑤ true(传递给evict)。
先来看看第一个实参:hash(key) ,我们追到 hash 方法中看看,如下:

hash 方法的作用:返回 key 对应的哈希值。return 语句后跟了一个三目运算符, 判断条件是 "key == null" ,显然为 false ,所以要返回的是冒号后面的内容 "(h = key.hashCode()) ^ (h >>> 16)"
"(h = key.hashCode()) ^ (h >>> 16)" 就是得到哈希值的一个算法。另外 hashCode() 方法具体如何实现我们不需要深究,而且该方法在 Java 源码中用 native 关键字修饰,底层是用 C/C++ 实现的,所以也看不到它的方法体,如下:
第二个实参 key 和第三个实参 value 就不用说了吧。至于后两个 boolean 类型的实参onlyIfAbsent:false,evict:true,我们暂时不管他,等用到了再说
接下来跳出 hash 方法,回到 put 方法,准备跳入 putVal 方法
② 跳入putVal方法
我们跳入 putVal 方法,putVal 方法内部语句很多,所以这里直接把源码搬过来,putVal 方法源码如下 :
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();afterNodeInsertion(evict);return null;} ![]() 是不是红温了?
是不是红温了?
一步一步来看
首先,定义了几个辅助变量,如下 :

tab 数组其实就是 table 数组的一个替代品,是 Node 类型的数组,而 p 只是单个 Node 类型的引用, p 后面就是用来充当 tab 数组中的某个键值对的 。至于后面的 n 、 i 变量,n 用来记录 table 数组的长度,i 用来存放索引值。这里暂时不用管,后面会用到的
接着,第一个 if 条件语句的判断,如下 :

可以看到,只要第一个条件满足就会进入 if 语句。将 table 赋值给 tab,这里的 "table" 就是 HashMap 中维护的数组,所以我们说 tab 数组是 table 数组的替代品。 table 的定义如下:

可以看到,table 是一个 Node(HashMap$Node) 类型的数组,并且没有显式初始化,默认为空引用 null 。它就是上文我们提到的 HashMap 的底层是 "数组+链表+红黑树" 中的数组。再回到 if 条件语句,显然第一个条件 "(tab = table) == null" 满足,要执行 if 语句中的内容
if 语句中的内容出现了一个新的方法 resize() 。resize() 的作用是:对 table 数组进行扩容,返回值即为 HashMap$Node 类型的数组
显然,tab = resize()就是对 table 数组进行第一次扩容操作
③ 跳入resize方法
继续,跳入 resize 方法,resize 方法源码如下:
final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length;int oldThr = threshold;int newCap, newThr = 0;if (oldCap > 0) {if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold}else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;else { // zero initial threshold signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}if (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;if (oldTab != null) {for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null)newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else { // preserve orderNode<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) {loTail.next = null;newTab[j] = loHead;}if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;}还是老规矩,一步一步来看
首先,将 table 引用赋值给了一个 Node 类型的数组 oldTab ,即 oldTab 引用现在也是null 了。如下 :

接着,后面几句代码如下:

定义了 oldCap 变量,赋值为 0 ,oldCap 即 oldCapacity,见名知意,指的是旧 table 数组的长度;接着又定义了 oldThr 变量,并为其赋值为 threshold ,此时 threshold = 0,如下图所示:

oldThr 即 oldThreshold,见名知意,指的是旧 table 数组的临界值。至于临界值 threshold变量,在 HashSet 的源码分析一文中已经讲得很详细了,这里不再赘述
继续,又定义了 newCap、newThr 两个变量。newCap 即 newCapacity,指的是新数组的容量,newThr 即 newThreshold ,指的是新的临界值
接着,第一个 if 条件语句我们不进去,如下 :

else if 语句我们也不进去,如下 :
![]()
进入 else 语句,else 语句中为 newCap 变量初始化为了 16 ,并且将 newThr 变量初始化为了 16 * 0.75 = 12。如下图所示 :

继续往下 Debug ,此处的 if 语句不进去,如下:

再往下执行:

先将计算求得的新临界值 newThr = 12 赋值给 threshold ,接着 new 了一个长度为 newCap = 16 的 Node 类型的新数组,然后将新数组的地址赋给了 newTable 引用,并由 newTab 引用传递给 table 。到此, table 已经由 null 变为了长度为 16 的数组,如下图所示:
再往下是一个非常大的 if 条件语句,如下 :

该 if 语句的作用是:如果旧数组不为空,则需要将旧数组中的元素全部拷贝到新数组中。 由于此时旧数组 oldTab = null,因此条件不成立,不执行
OK,这下 resize 方法执行完了,返回 new 出的新数组,如下 :

④ 回到 putVal 方法
执行完 resize 方法,回到 putVal 中,如下:

if 条件语句中,利用获取到的 key 的哈希值,根据特定算法 (n-1)& hash 可以得到一个索引值 i ,该索引即添加的 key-value 在 table 数组中应该存放的位置。显然,此处 p = null,表示 table 数组中索引 i 处无 key-value 键值对存放,所以调用 newNode(hash,key,value,next:null) 将添加的 key-value 键值对包装成 Node 类型,然后加入到 table 数组索引 i 处
后面部分与 HashSet 源码分析中重复,所以就不再啰嗦了
⑤ 回到演示类
回到演示类,查看此时的 HashMap 集合状态,如下:
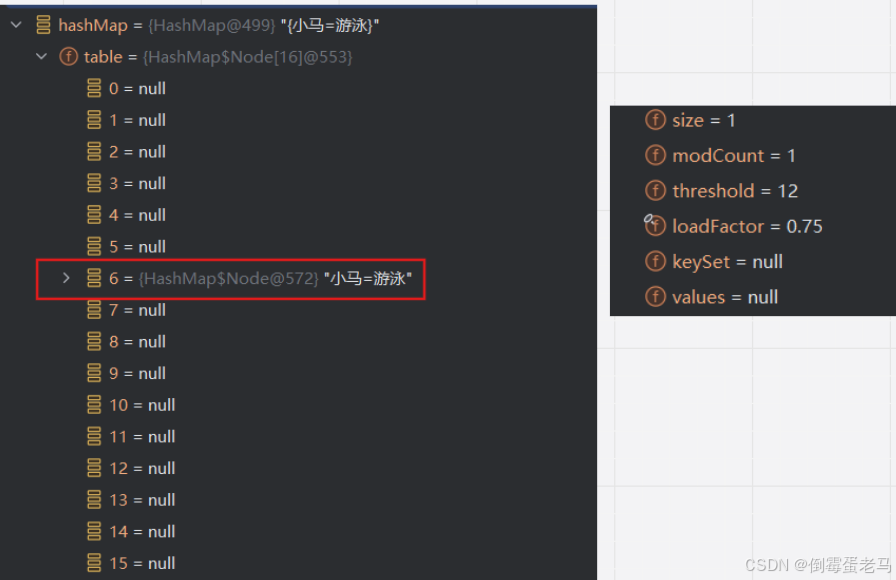
可以看到,第一个键值对 "小马"-"游泳" 存放在 table 数组索引 为 6 的位置。当前 HashMap 集合元素个数 size = 1,修改集合次数 modCount = 1,临界值 threshold = 12 ,默认增长因子 loadFactor = 0.75
🆗,到此第一个 key-value 键值对的添加演示完毕
3.向集合中添加第二个键值对
向集合中添加第二个键值对:{key:"蔡徐坤",value:"只因为你太美"}
第二个键值对的 key = "蔡徐坤",其哈希值肯定与第一个键值对的 key = "小马" 不同。因此,第二个元素的添加过程与第一个元素一样,这里就不演示了,直接把它加进去
添加完毕之后,HashMap 集合的状态如下:
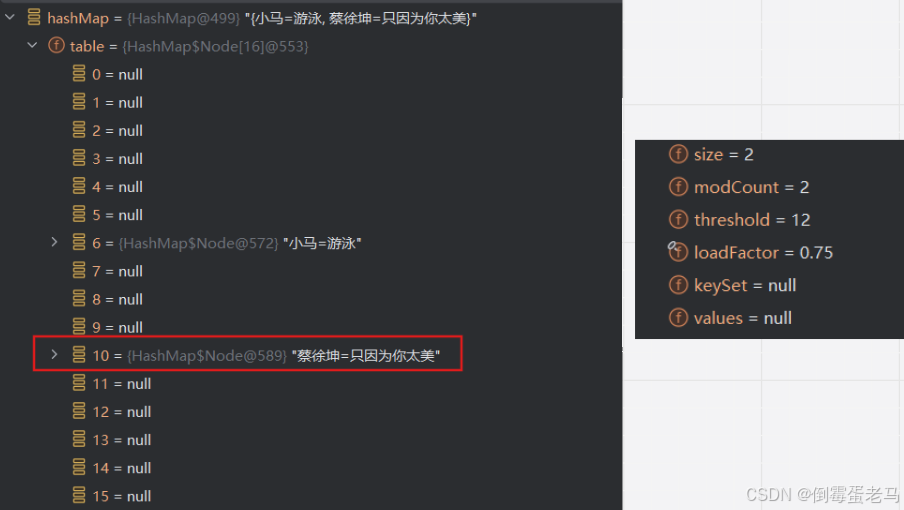
可以看到,第一个键值对 "蔡徐坤"-"只因为你太美" 存放在 table 数组索引 为 10 的位置。当前 HashMap 集合元素个数 size = 2,修改集合次数 modCount = 2,临界值 threshold = 12 ,默认增长因子 loadFactor = 0.75
4.向集合中添加第三个键值对:演示put方法对重复key的处理过程
向集合中添加第三个键值对:{key:"小马",value:"唱跳rap篮球"},该键值对的 key 与第一个键值对 {key:"小马",value:"游泳"} 的 key 相同,我们来看一下源码如何用新 value 覆盖旧 value
① 跳入putVal方法
先跳入 put 方法,然后在 put 法内部调用 putVal 方法,如下 :
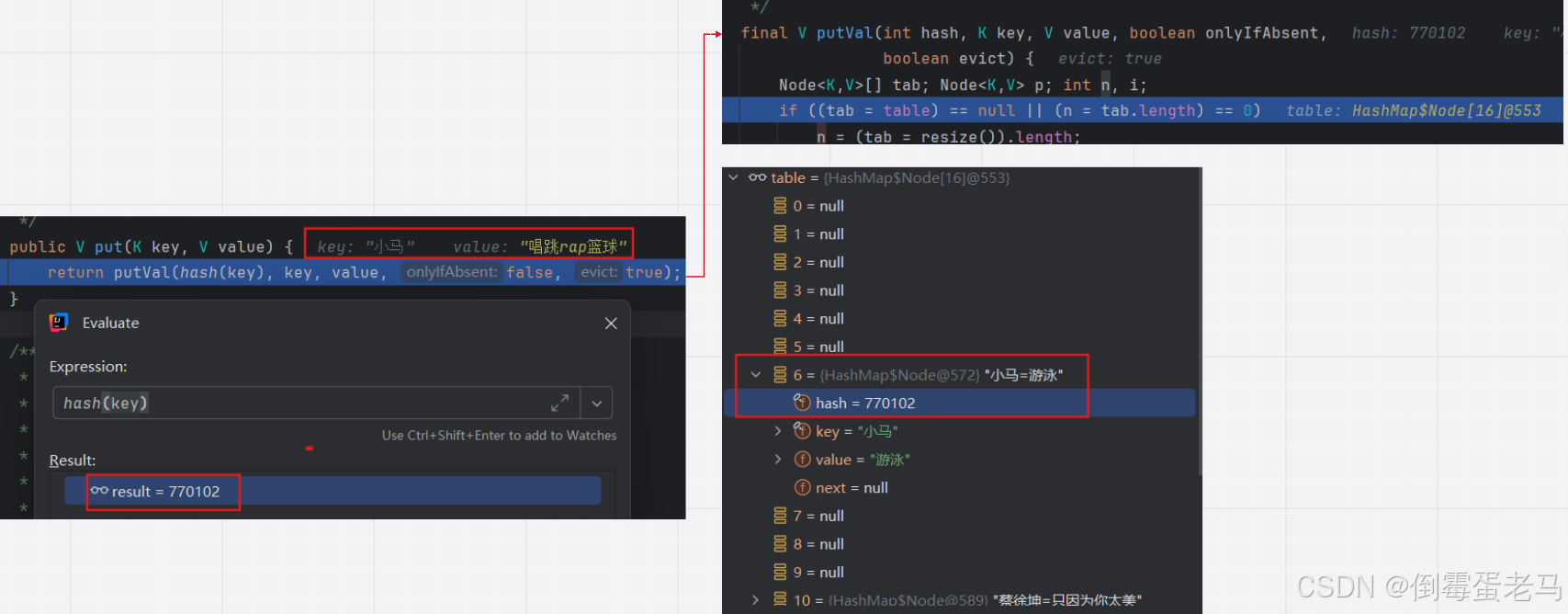
此时 key = "小马",value = "唱跳rap篮球" 。由于与第一个键值对 "小马"-"篮球" 的 key 相同,所以 hash 方法返回的哈希值也相同,均为 770102
由于哈希值均为 770102 ,最终转换为的索引值也必然相同,如下:

可以看到,当前添加的键值对 "小马" - "唱跳rap篮球" 得到的索引值 i 也为 6,所以 putVal 方法的第 2 个 if 语句的 p!=null,不会进入 if 结构,而是进入 else 部分。如下图所示:
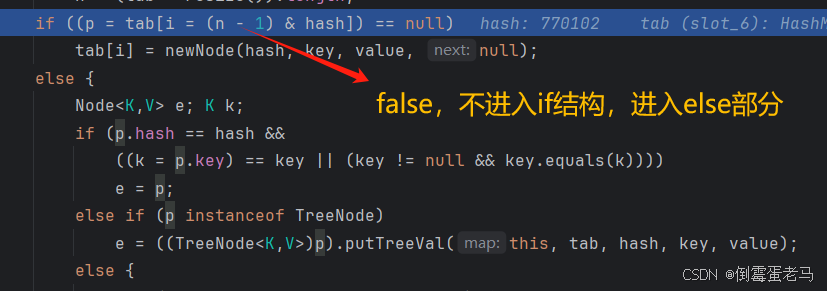
else 部分是由 if --- else if --- else + if 组成,每个部分完成不同的任务,以下是 源码+注释,前面的 if ---else if --- else 在 HashSet 源码分析中已经讲解得很详细了。 我们稍后主要看最后的 if 部分。如下:
else {HashMap.Node<K,V> e; K k;//第一种情况:如果添加的键值对的key与索引处的键值对的key相等,则放弃添加当前键值对if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;//第二种情况:如果添加的键值对的key与索引处的键值对的key不相等,并且该索引处后面是一颗红黑树,则采用红黑树的方法添加else if (p instanceof HashMap.TreeNode)e = ((HashMap.TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);//第三种情况:如果添加的键值对的key与索引处的键值对的key不相等,并且该索引处后面是一个链表else {//for循环作用:判断添加的键值对的key与链表中某个键值对的key是否相同,相同则放弃添加,不相同则踢挂载到链表后面for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}//如果当前添加的键值对的key重复,则用新的value覆盖旧的valueif (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}
}第一种情况:如果 table 数组该索引处键值对的 key 与当前添加的键值对的 key 相同,则放弃添加当前键值对
第二种情况:如果该索引处键值对的 key 与当前添加的键值对的 key 不相同,并且该索引处后面是一棵红黑树,就采用红黑树的方法添加键值对
第三种情况:如果该索引处键值对的 key 与当前添加的键值对的 key 不相同,并且该索引处后面是一个链表,则在 for 循环中判断当前添加的键值对的 key 是否与链表中某个键值对的key 相同,相同则放弃添加,不同则挂载到链表后面
显然,现在符合第一种情况,执行完第一种情况对应的 if 语句后,我们来到了三种情况之后的 if 条件语句,如下 :
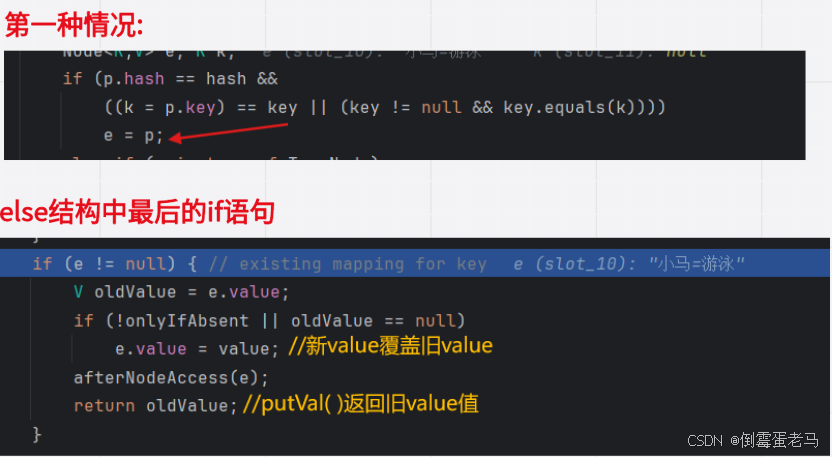
e != null 显然成立(注意,在第一种情况的 if 语句中,执行了 e = p,即 e 代表 table 数组中存在的元素), 注意看内层 if 条件语句中的内容,onlyIfAbsent 是我们一开始调用 putVal 方法时传入的第四个实参 false ,所以 !onlyIfAbsent = true,符合判断条件,执行 e.value = value,即新 value 覆盖旧 value
后面的 afterNodeAccess(e) 不需要管,是一个空方法
最终 putVal 方法以 return oldValue 结束,返回旧 value 值
② 回到演示类
回到演示类,查看此时的 HashMap 集合状态,如下:
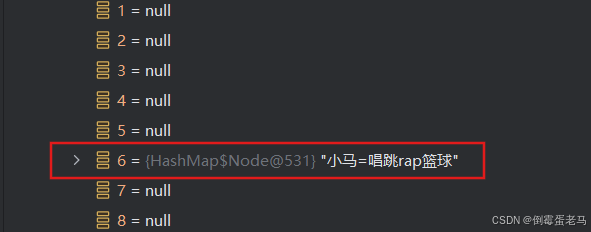
可以看到,table 数组中索引处 6 的旧 value 值 "游泳" 被替换为新 value 值 "唱跳rap篮球"
🆗,添加的键值对的 key 存在重复时,如何完成新 value 覆盖旧 value 的过程演示完毕。过程相比于 HashSet 简略了很多,如果有看不懂的可以去 HashSet 源码分析中查看
5.扩容机制+链表转换为红黑树
扩容机制+链表转换为红黑树的过程在 HashSet 源码分析中讲解得非常详细,有需要的可以去看一下
五、完结
🆗,以上就是本文 HashMap 源码分析的全部内容了