优先级队列(堆二叉树)底层的实现:
我们继续来看我们的优先级队列:
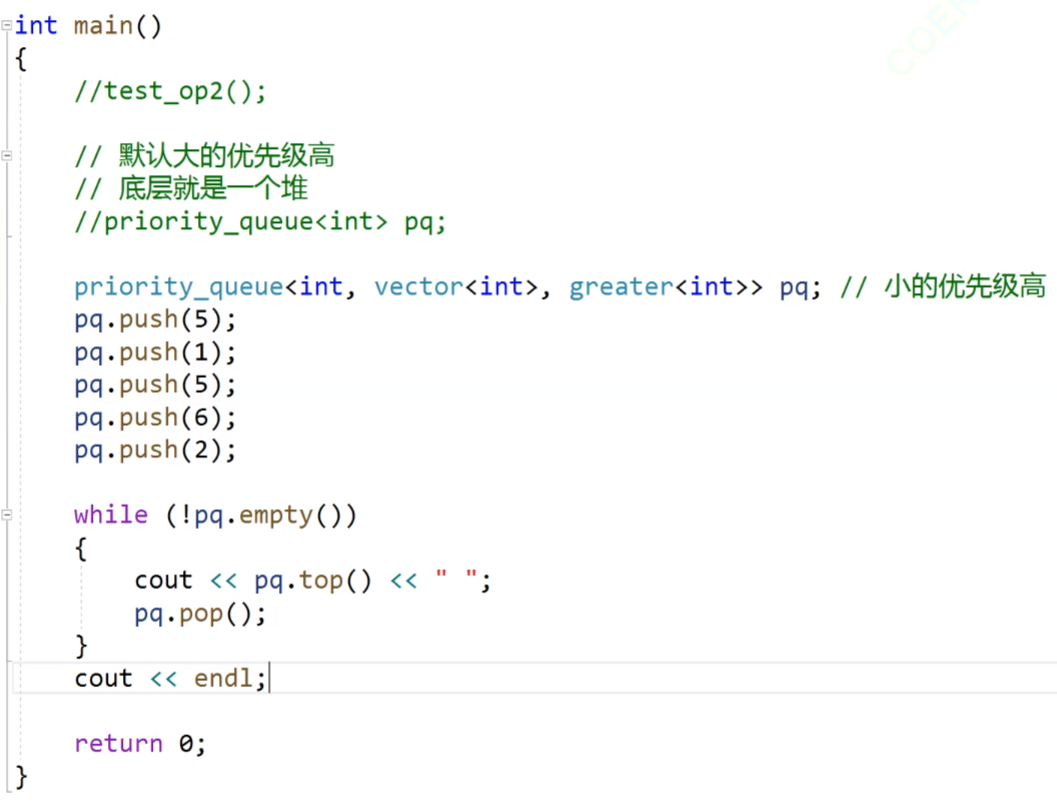
优先级队列我们说过,他也是一个容器适配器,要依赖我们的容器来存储数据;
他的第二个参数就是我们的容器,这个容器的默认的缺省值是vector,然后他的第三个参数,我们上节讲到,他的top和pop接口都是按照优先级的顺序来进行去取的,然后我们的优先级顺序默认的是大的优先级比较高,这里有一个比较坑的点,那就是我们如果想让大的数据优先级高的话,我们可以直接不传,他的默认的缺省值就是大的优先级高,这个缺省值就是less,然后我们如果想让小的数据的优先级高的话,我们就传greater,是的,这里就是刚好相反的。
优先级队列的实现:
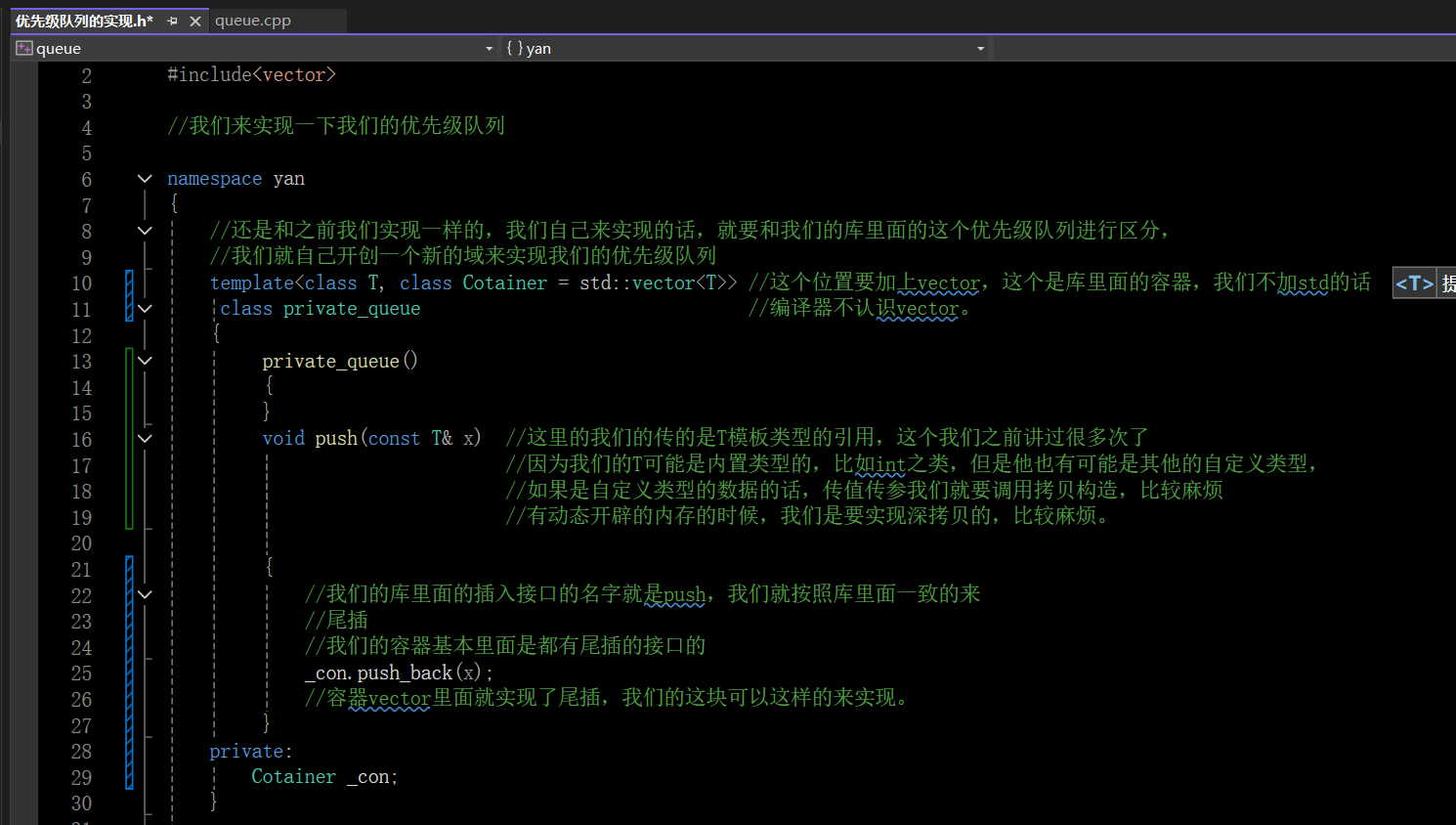
我们来实现我们的优先级队列的底层,我们看这个push函数,我们的库里面的插入函数就是push,我们在这里的名字就是push,这个函数表示的其实还是尾插,我们的容器vector里面也是实现了push_back() 函数接口的,我们直接调用;
我们看我们的插入函数的参数,我们这里还是使用了引用来进行,这个东西我们已经说过很多次了。
因为我们不能确定这个模板T到底是什么类型的,他可能是内置类型的,比如int,也可能是其他的自定义的类型,如果是自定义的类型的话,我们的传值调用就要调用拷贝构造了,如果我们的自定义类型有动态开辟的内存的时候,我们调用拷贝构造就要给这个临时的变量开辟一段内存空间,深拷贝就比较麻烦。我们这里就选择传引用来进行,就不需要调用拷贝构造了。
我们来接着看:
由于堆具有高效维护最大或最小元素的特性,它是实现优先级队列的一种非常合适的数据结构。
我们的堆删除数据也是删除栈顶的数据,优先级最高的进行删除。(优先级队列也是先删除优先级高的)。
优先级队列的实现都是基于堆的。(我们的这个优先级队列就是我们的堆二叉树);

push函数的实现:
Adjustup函数的实现:

当我们的优先级队列(堆)入数据的时候,这个数据的插入有可能会破坏我们的优先级队列(堆)自身的结构,如果插入数据以后,我们的大堆的结构被改变,我们就要进行向上调整。
上面的这个数据的插入没有改变我们的堆的类型,他还是大堆,我们就不进行调整了;
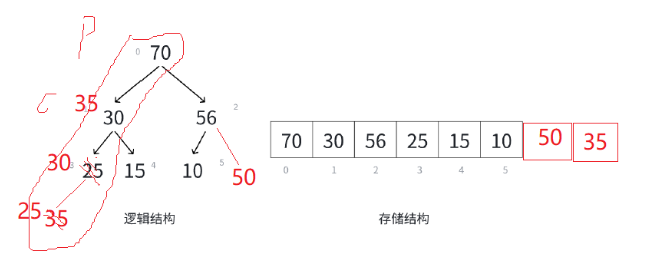
当我们再给他插入一个数据的时候,我们这时候的大堆就不成型了,我们就要进行调整,我们把插入的数据找出来,然后我们求出他的parent结点,然后比较大小,如果child比parent大的时候,我们就交换数据,然后不断比较:


为什么我们要实现向上调整呢?

一般我们入数据的时候,我们就会用到向上调整。
我们看我们的push函数:

我们插入一个数据以后,我们一般都是插入到最后一个位置,然后我们对这个位置进行向上调整。
我们这里是size()-1,因为我们的堆二叉树,我们的第一个数据是从下标0开始的。
pop函数的实现:

我们实现我们的删除函数,想一下我们之前实现堆的时候的删除数据是怎么删除的:
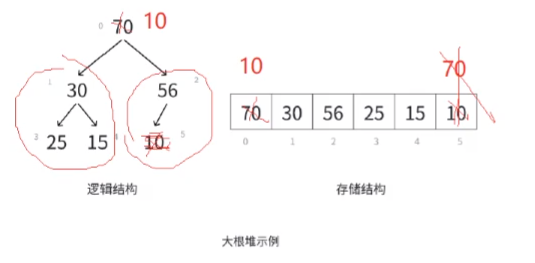
我们交换堆顶和最后一个数据,然后把最后一个数据删除。这时候我们进行一个向下调整,这时候除了第一个堆顶的数据,其他的位置的数据都是有序的满足堆的要求。(这个也刚好满足向下调整的算法的条件)。
然后左右两个堆都是有序的,我们就比较现在堆顶(10)的左右孩子,因为是大堆,我们就选出比较大的数据,然后我们的堆顶和这个位置进行交换。当然,比较完后我们的这棵发生交换的子树还要和下面的孩子进行比较,直到最后合适。
Adjustdown向下调整的实现:
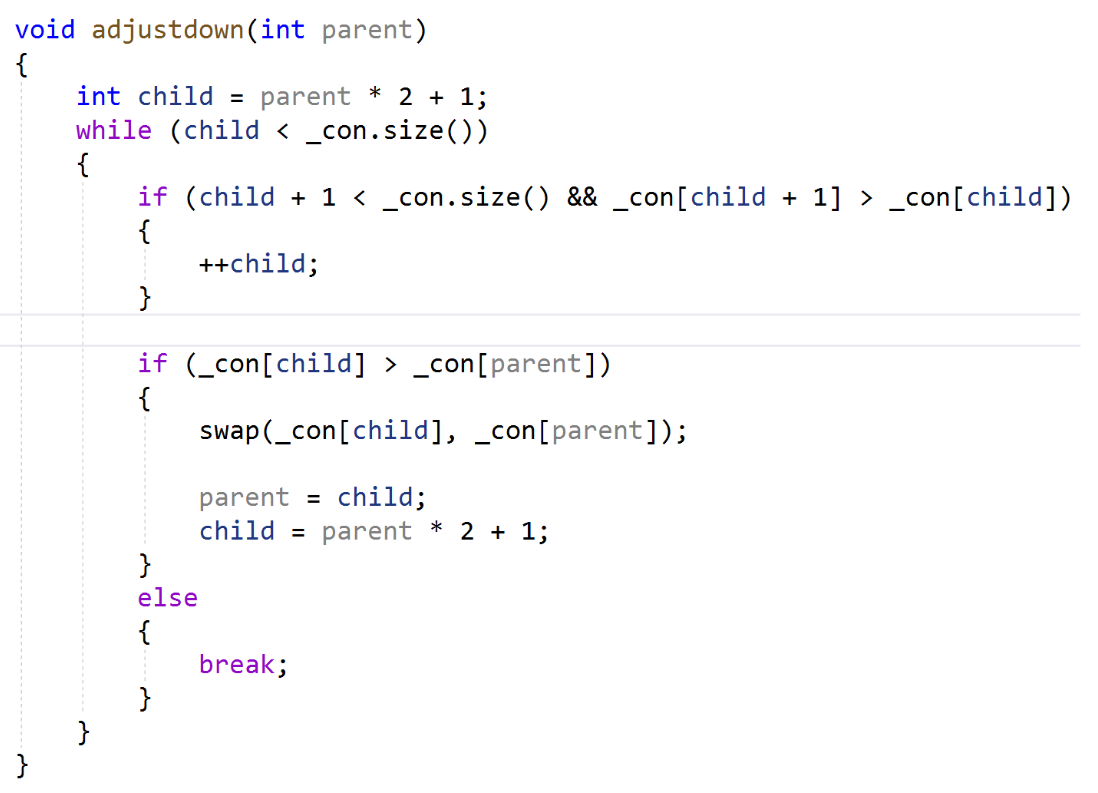
pop函数:


我们的向下调整的前体就是我们是pop数据的时候,我们会需要这个。
综上所述:
向上调整的前提是向堆中插入新元素,向下调整的前提是从堆中删除堆顶元素。
仿函数:
我们的仿函数是一个类
在 C++ 里,仿函数是重载了函数调用运算符 () 的类或结构体的对象。这意味着这些对象能够像函数一样被调用。

这个就是我们的仿函数,重载了()。
这个类的对象可以像函数一样的去使用,这个类就是我们的仿函数。
我们来看一个仿函数:

我们在我们的优先级队列里面的时候,我们的模板参数的第三个参数就是我们的仿函数,我们的仿函数也是一个类:

这个就是我们的仿函数。 这个是less,我们重载的 () 是小于的类型。

这个是我们的greater,我们重载的 () 是大于的类型。
我们这里实现的和我们的库里面的有所不同,我们的库里面的,和我们的这里的相反,库里面的gerater表示小于,less表示大于。
然后当我们的这个大模板下的函数想要使用比较的时候,我们就可以使用仿函数,我们看下面的向下调整的方法,我们里面的条件比较如果是小于的话,我们就可以直接调用仿函数,看他是不是满足小于的,如果是满足小于的,返回1,我们的if条件成立。
当然,使用的前提也是,我们要先使用这个类来实例化出一个对象。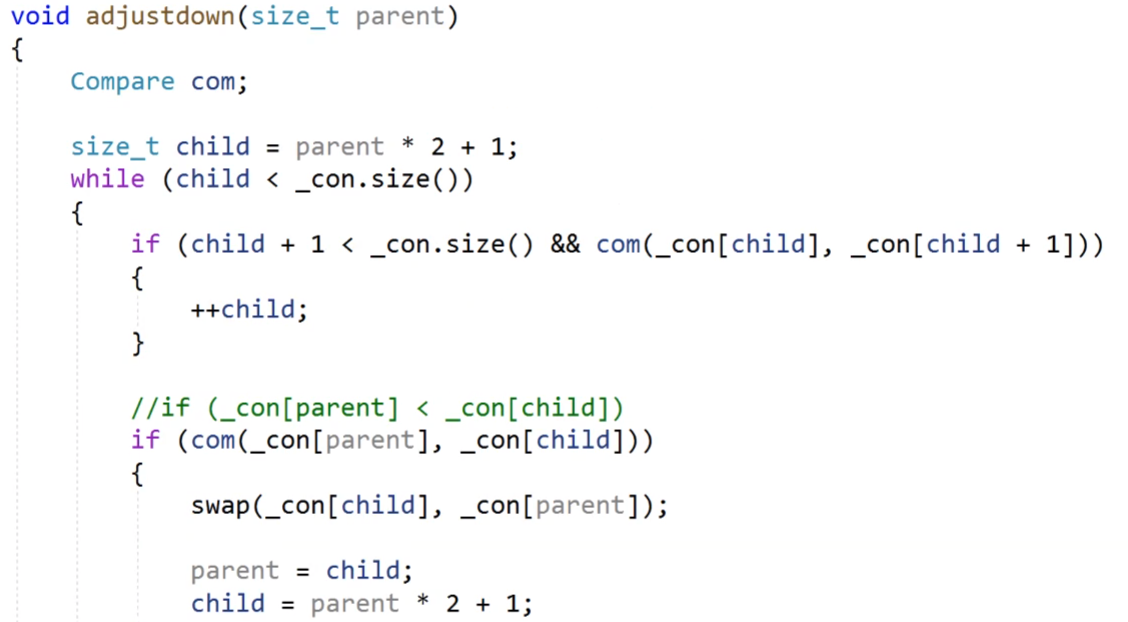
我们的compare是我们的仿函数,我们实例化出一个对象com,然后我们的这个类的对象我们可以直接的当作一个函数去使用。
我们这里调用仿函数可以是实例化出一个对象然后我们调用,这个有名调用是可以的,我们也可以是进行匿名调用。
上面的就是有名调用,匿名调用的话,我们就不实例化出对象,然后把图中的com替换成less<int>。
我们接着看:
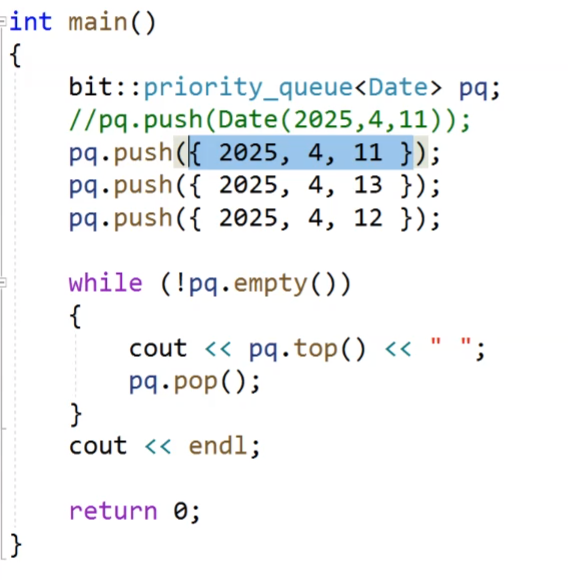
我们看这个,我们说我们push的话,我们可以传有名对象,也可以传匿名对象,我们也可以像我们的图片中的样子,我们传我们要初始化的值,进行一个隐式类型转换,也会生成一个匿名对象。和我们的上面的屏蔽的那个匿名对象的效果是一样的。
我们接着来看我们的仿函数:

我们看一下这个代码,我们的这个优先级队列,我们的第一个参数为我们的日期类的地址,然后后面的两个参数不传,我们的第二个参数的缺省值为vector,第三个参数缺省值为less,然后我们进行打印,但是打印出来的结果不是我们想要的结果。
我们这次的模板T不是int,是我们的日期类的指针,我们进行push尾插,然后我们的new的返回值是我们的开辟的内存的指针,我们把指针插入到我们的数组里面,然后比较的时候,我们比较的就是我们的地址,我们的new开辟的内存的地址是随机的,所以我们在这里比较出来的结果就是无意义的。
那怎么办呢?
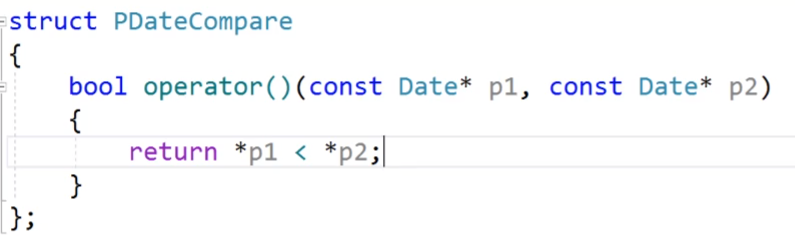
我们就可以利用我们的仿函数,我们这里的优先级队列我们的第三个仿函数我们是没有传的,所以这时候我们的里面就是缺省值less,这样的结果就是比较地址的大小,但是我们可以修改我们的仿函数,我们这里的仿函数是不期望使用指针来进行比较的,我们期望的是使用指针解引用后的数据来比较。
之前我们的仿函数:
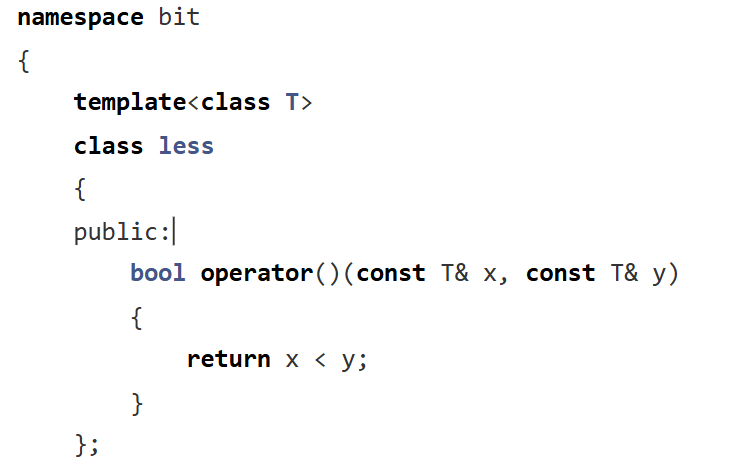
我们就设置一个新的仿函数来解决我们的问题:
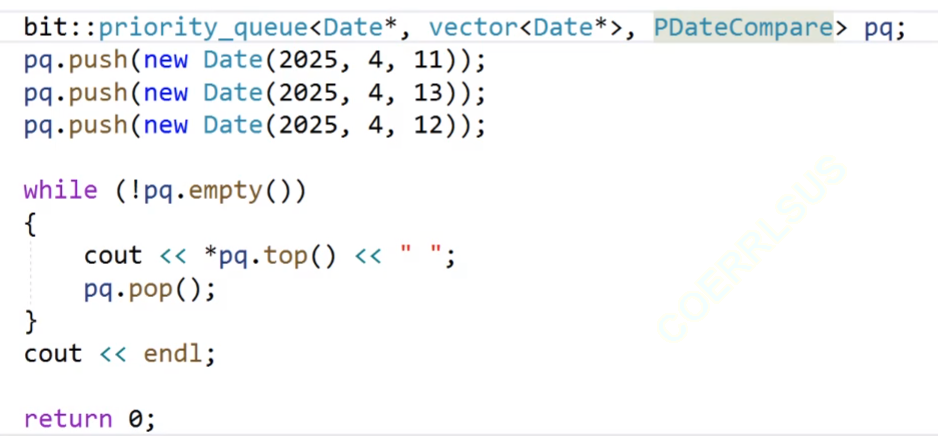
这时候得到的就是我们要的;(按照里面的数据来进行比较)。
还有:
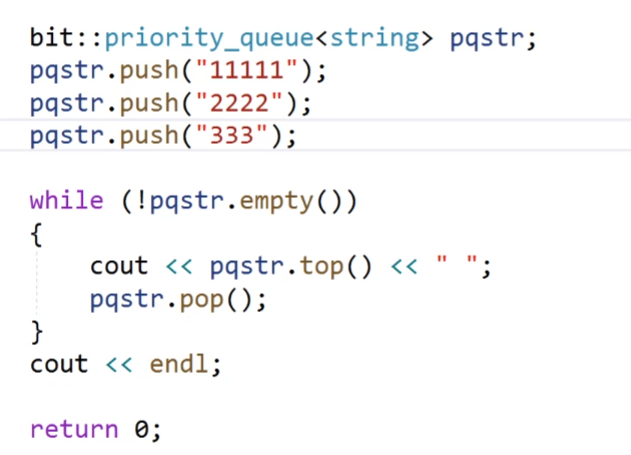
我们看这个代码,这个代码我们的优先级队列传过去的容器是string,然后我们的后面的两个函数参数都是缺省值,我们的最后一个参数仿函数就是less。
我们然后尾插三个字符串,然后不断的取然后pop,![]() 这个就是最后的结果,这个就是按照他的大小进行排列的。
这个就是最后的结果,这个就是按照他的大小进行排列的。
但是我们现在不想按照顺序的给他进行排列了,我们想按照每个字符串的长度来进行排列;
我们这时候就可以使用仿函数来调整我们的比较逻辑;


我们看,我们自己来实现一个仿函数,来满足我们的要求,我们比较两个string的长度。
如果默认的函数不符合我们的逻辑,我们就自己来实现一个仿函数。