MySQL 面经
1、什么是 MySQL?
MySQL 是一个开源的关系型数据库,现在隶属于 Oracle 公司。是我们国内使用频率最高的一种数据库,我本地安装的是比较新的 8.0 版本。
1.1 怎么删除/创建一张表?
可以使用 DROP TABLE 来删除表,使用 CREATE TABLE 来创建表。创建表的时候,可以通过 PRIMARY KEY 设定主键。
CREATE TABLE users (id INT AUTO_INCREMENT,name VARCHAR(100) NOT NULL,email VARCHAR(100),PRIMARY KEY (id)
);
1.2 请写一个升序/降序的 SQL 语句?
在 SQL 中,可以使用 ORDER BY 子句来对查询结果进行升序或者降序。默认情况下,查询结果是升序的,如果需要降序,可以通过 DESC 关键字来实现。如果需对多个字段进行排序,例如按工资降序,按名字升序,就可以 ORDER BY salary DESC, name ASC 来完成:
SELECT id, name, salary
FROM employees
ORDER BY salary DESC, name ASC;
1.3 MySQL出现性能差的原因有哪些?
可能是 SQL 查询使用了全表扫描,也可能是查询语句过于复杂,如多表 JOIN 或嵌套子查询。也有可能是单表数据量过大。通常情况下,添加索引就能解决大部分性能问题。对于一些热点数据,还可以通过增加 Redis 缓存,来减轻数据库的访问压力。
2、两张表怎么进行连接?
可以通过内连接 inner join、外连接 outer join、交叉连接 cross join 来合并多个表的查询结果。
2.1 什么是内连接?
内连接用于返回两个表中有匹配关系的行。假设有两张表:用户表和订单表,想查询有订单的用户就可以使用内连接 users INNER JOIN orders,按照用户 ID 关联就行了。
SELECT users.name, orders.order_id
FROM users
INNER JOIN orders ON users.id = orders.user_id;
只有那些在两个表中都存在 user_id 的记录才会出现在查询结果中。
2.2 什么是外连接?
和内连接不同,外连接不仅返回两个表中匹配的行,还返回没有匹配的行,用 null 来填充。外连接又分为左外连接 left join 和右外连接 right join。left join 会保留左表中符合条件的所有记录,如果右表中有匹配的记录,就返回匹配记录,否则就用 null 填充,常用于某表中有,但另外一张表中可能没有的数据的查询场景。假设要查询所有用户以及他们的订单,即使用户没有下单,就可以使用左连接:
SELECT users.id, users.name, orders.order_id
FROM users
LEFT JOIN orders ON users.id = orders.user_id;
右连接就是左连接的镜像,right join 会保留右表中符合条件的所有记录。
2.3 什么是交叉连接?
交叉连接会返回两张表的笛卡尔积,将左表的每一行与右表的每一行进行组合,返回的行数是两张表行数的乘积。
SELECT A.id, B.id
FROM A
CROSS JOIN B;
3、内连接、左连接、右连接有什么区别?
MySQL 的连接主要分为内连接和外连接,外连接又可以分为左连接和右连接。
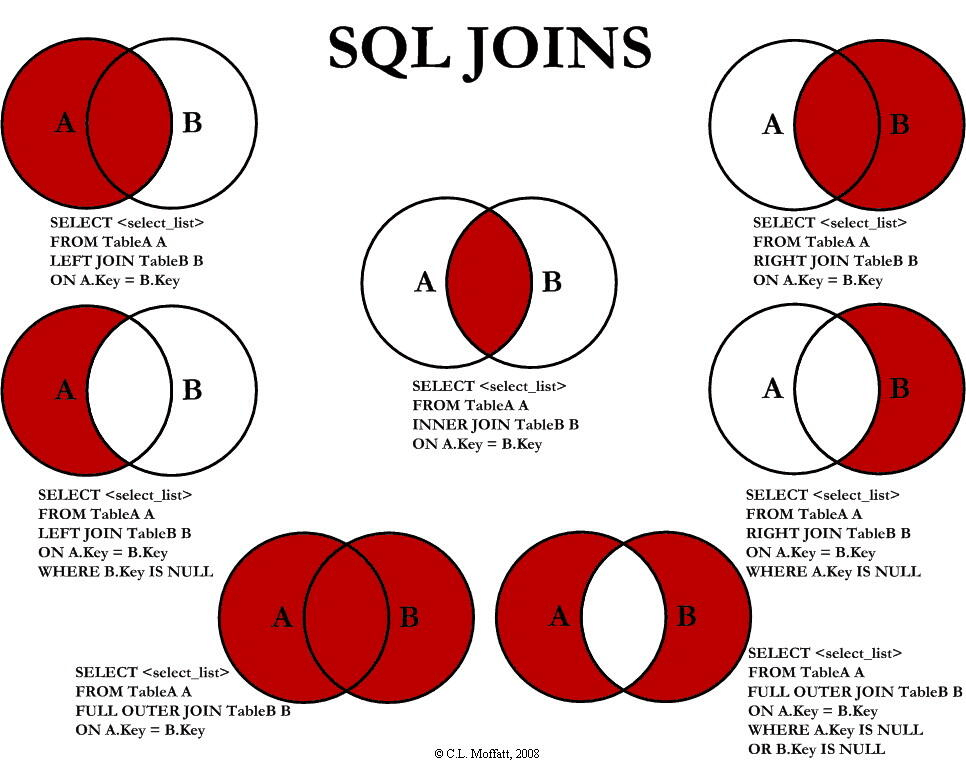
内连接可以用来找出两个表中共同的记录,相当于两个数据集的交集。左连接和右连接可以用来找出两个表中不同的记录,相当于两个数据集的并集。两者的区别是,左连接会保留左表中符合条件的所有记录,右连接则刚好相反。
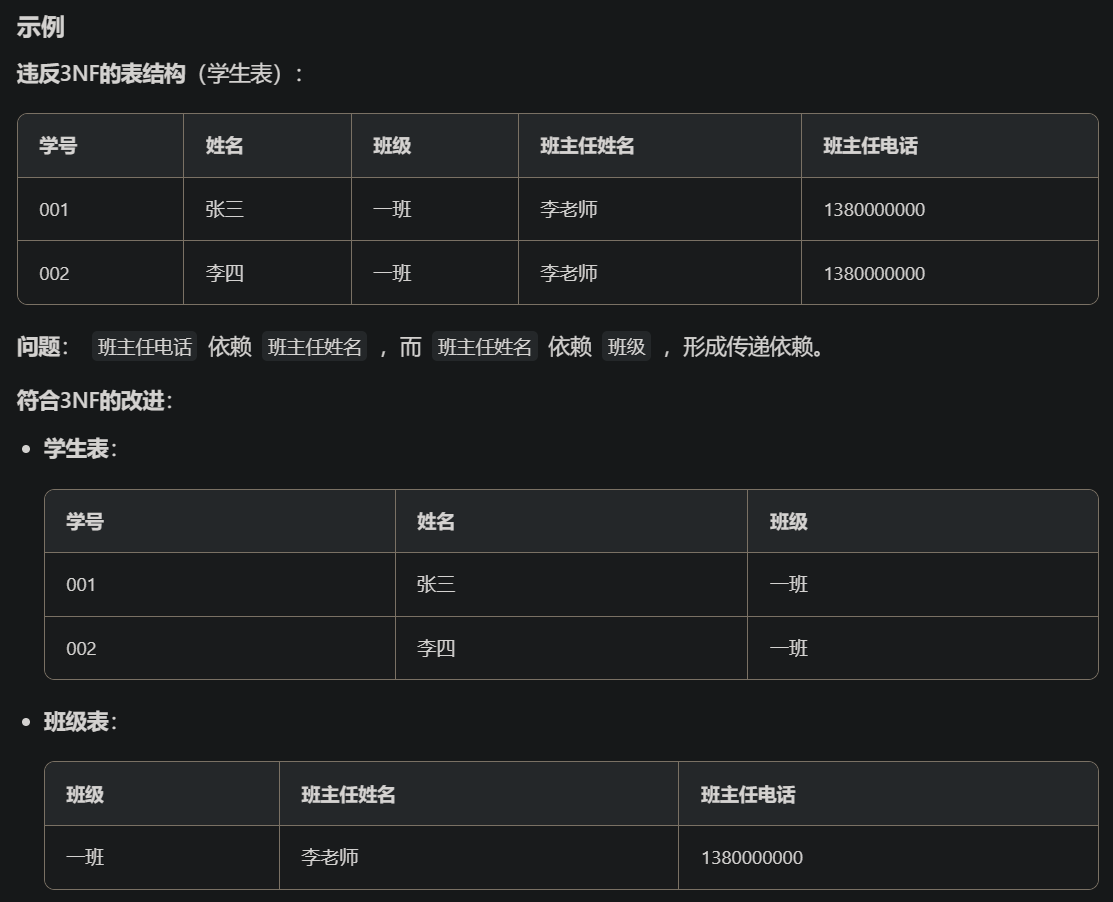
4、说一下数据库的三大范式?
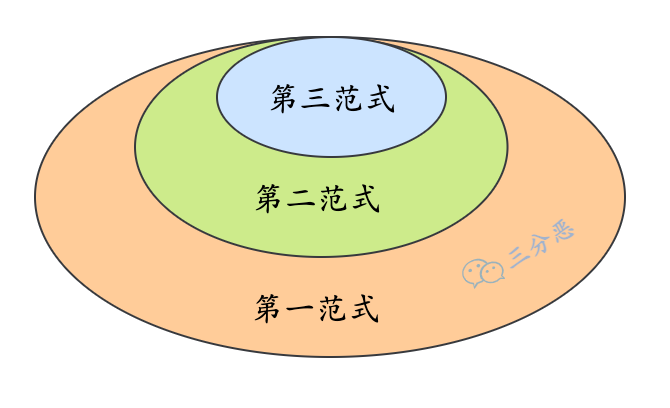
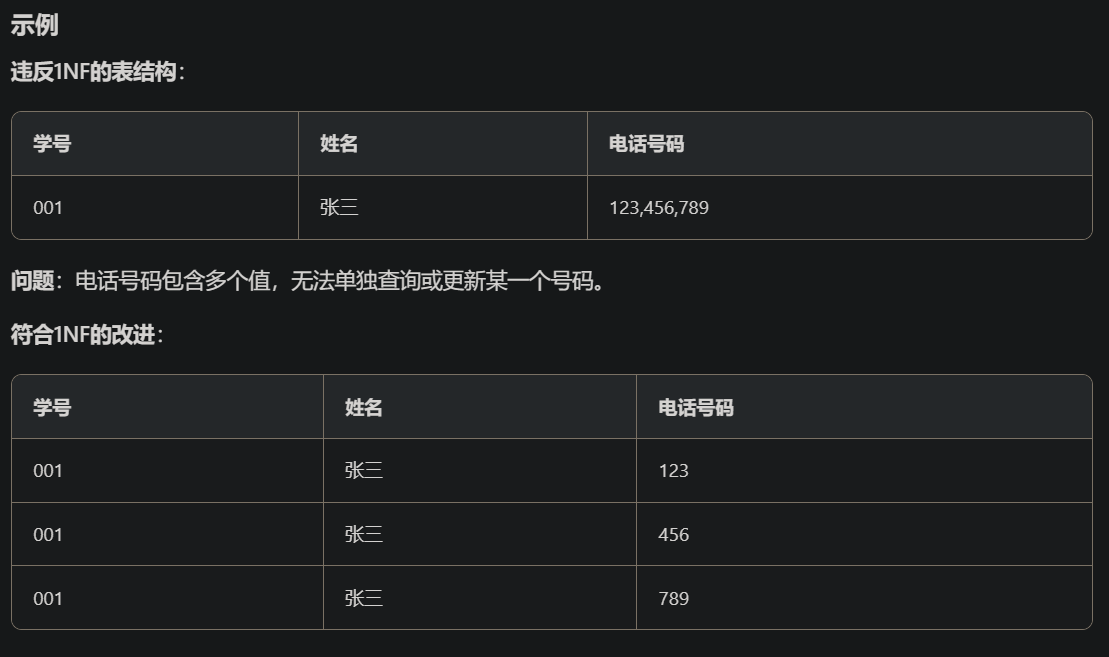
- 第一范式:表的每一列都是不可分割的基本数据单元:
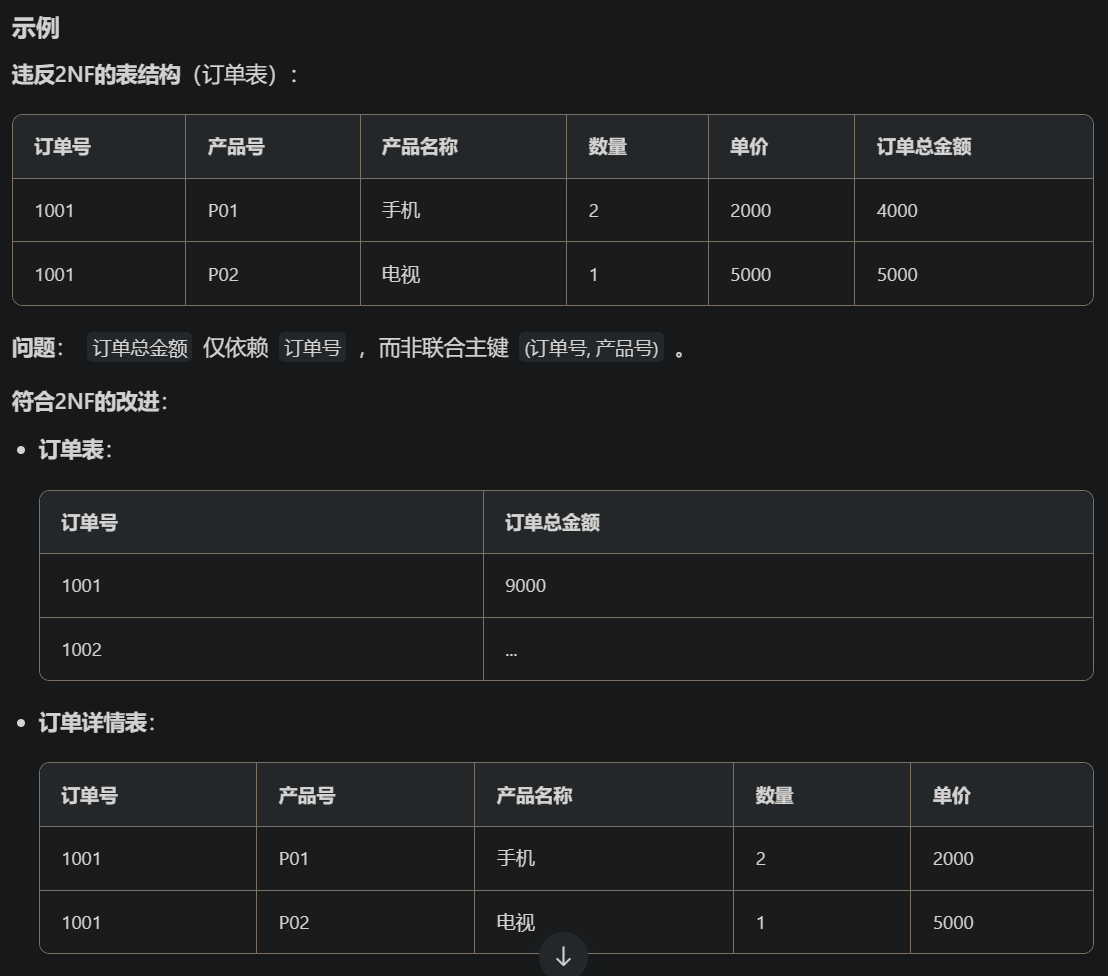
- 第二范式:在满足1NF的基础上,非主键字段必须完全依赖于整个主键。
- 第三范式:在满足2NF的基础上,非主键字段不能间接依赖其他非主键字段(消除传递依赖)。
4.1 建表的时候需要考虑哪些问题?
首先需要考虑表是否符合数据库的三大范式,确保字段不可再分,消除非主键依赖,确保字段仅依赖于主键等。然后在选择字段类型时,应该尽量选择合适的数据类型。在字符集上,尽量选择 utf8mb4,不仅可以支持中文和英文,还可以支持表情符号等。当数据量较大时,比如上千万行数据,需要考虑分表。比如订单表,可以采用水平分表的方式来分散单表存储压力。
5、varchar 与 char 的区别?
- varchar 是可变长度的字符类型,理论上最多可以容纳 65535 个字符,但考虑到字符集,以及 MySQL 需要 1 到 2 个字节来表示字符串长度,所以实际上最大可以容纳到 65533。
- char 是固定长度的字符类型,当定义一个 CHAR(10) 字段时,不管实际存储的字符长度是多少,都只会占用 10 个字符的空间。如果插入的数据小于 10 个字符,剩余的部分会用空格填充。(GBK 中文占 2 字节,UTF-8 占 3 字节)
6、blob 和 text 有什么区别?
blob 用于存储二进制数据,比如图片、音频、视频、文件等;但实际开发中,我们都会把这些文件存储到 OSS 或者文件服务器上,然后在数据库中存储文件的 URL。text 用于存储文本数据,比如文章、评论、日志等。
7、DATETIME 和 TIMESTAMP 有什么区别?
- DATETIME 直接存储日期和时间的完整值,与时区无关。
- TIMESTAMP 存储的是 Unix 时间戳,1970-01-01 00:00:01 UTC 以来的秒数,受时区影响。
另外,DATETIME 的默认值为 null,占用 8 个字节;TIMESTAMP 的默认值为当前时间 CURRENT_TIMESTAMP,占 4 个字节,实际开发中更常用,因为可以自动更新。
8、in 和 exists 的区别?
使用 IN 时,MySQL 会首先执行子查询,然后将子查询的结果集用于外部查询的条件。这意味着子查询的结果集需要全部加载到内存中。而 EXISTS 会对外部查询的每一行,执行一次子查询。如果子查询返回任何行,则 EXISTS 条件为真。EXISTS 关注的是子查询是否返回行,而不是返回的具体值。
-- IN 的临时表可能成为性能瓶颈
SELECT * FROM users
WHERE id IN (SELECT user_id FROM orders WHERE amount > 100);
-- EXISTS 可以利用关联索引
SELECT * FROM users u
WHERE EXISTS (SELECT 1 FROM orders o WHERE o.user_id = u.id AND o.amount > 100);
IN 适用于子查询结果集较小的情况。如果子查询返回大量数据,IN 的性能可能会下降,因为它需要将整个结果集加载到内存。而 EXISTS 适用于子查询结果集可能很大的情况。由于 EXISTS 只需要判断子查询是否返回行,不需要加载整个结果集,因此在某些情况下性能更好,特别是当子查询可以使用索引时。
8.1 NULL 值陷阱了解吗?
- IN: 如果子查询的结果集中包含 NULL 值,可能会导致意外的结果。例如,WHERE column IN (subquery),如果 subquery 返回 NULL,则 column IN (subquery) 永远不会为真,除非 column 本身也为 NULL。
- EXISTS: 对 NULL 值的处理更加直接。EXISTS 只是检查子查询是否返回行,不关心行的具体值,因此不受 NULL 值的影响。
9、记录货币用什么字段类型比较好?
货币在数据库中 MySQL 常用 Decimal 和 Numeric 类型表示,这两种类型被 MySQL 实现为同样的类型。他们被用于保存与货币有关的数据。例如 salary DECIMAL(9,2),9 (precision) 代表将被用于存储值的总的小数位数,而 2 (scale) 代表将被用于存储小数点后的位数。存储在 salary 列中的值的范围是从-9999999.99 到 9999999.99。DECIMAL 和 NUMERIC 值作为字符串存储,而不是作为二进制浮点数,以便保存那些值的小数精度。之所以不使用 float 或者 double 是为了避免二进制误差。
10、怎么存储 emoji?
MySQL 的 utf8 字符集仅支持最多 3 个字节的 UTF-8 字符,但是 emoji 表情(😊)是 4 个字节的 UTF-8 字符,所以在 MySQL 中存储 emoji 表情时,需要使用 utf8mb4 字符集。MySQL 8.0 已经默认支持 utf8mb4 字符集。
ALTER TABLE mytable CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
11、drop、delete 与 truncate 的区别?
- drop:属于 DDL,不可回滚,从数据库中删除表,所有数据行,索引和权限也会被删除,删除速度最快。
- delete:属于 DML,可回滚,表结构还在,删除表的全部或者一部分数据行,删除速度慢,需要逐行删除 。
- truncate:属于 DDL,不可回滚,表结构还在,删除表中的所有数据,删除速度快。
因此,在不再需要一张表的时候,用 drop;在想删除部分数据行时候,用 delete;在保留表而删除所有数据的时候用 truncate。
12、UNION 与 UNION ALL 的区别?
- 如果使用 UNION,合并后会去除重复的记录行。
- 如果使用 UNION ALL,合并后不会去除重复的记录行。
- 从效率上说,UNION ALL 要比 UNION 快很多,如果合并没有刻意要删除重复行,那么就使用 UNION All。
13、count(*)、count(1) 与 count(列名) 的区别?
- count(*):统计表中所有行的数量,无论列值是否为 NULL。
- count(1):与 count(*) 功能完全相同,1 是一个常量值,不依赖任何列。
- count(列名):仅统计指定列中非 NULL 值的行数。若某行的该列为 NULL,则不计入统计。
14、SQL 查询语句的执行顺序了解吗?

- FROM:对 FROM 子句中的左表 <left_table> 和右表 <right_table> 执行笛卡儿积,产生虚拟表 VT1。
- ON:对虚拟表 VT1 应用 ON 筛选,只有那些符合 <join_condition> 的行才被插入虚拟表 VT2 中。
- JOIN:如果指定了 OUTER JOIN,那么保留表中未匹配的行作为外部行添加到虚拟表 VT2 中,产生虚拟表 VT3。
- WHERE:对虚拟表 VT3 应用 WHERE 过滤条件,只有符合 <where_condition> 的记录才被插入虚拟表 VT4 中。
- GROUP BY:根据 GROUP BY 子句中的列,对 VT4 中的记录进行分组操作,产生 VT5。
- CUBE|ROLLUP:对表 VT5 进行 CUBE 或 ROLLUP 操作,产生表 VT6。
- HAVING:对虚拟表 VT6 应用 HAVING 过滤器,只有符合 <having_condition> 的记录才被插入虚拟表 VT7 中。
- SELECT:第二次执行 SELECT 操作,选择指定的列,插入到虚拟表 VT8 中。
- DISTINCT:去除重复数据,产生虚拟表 VT9。
- ORDER BY:将虚拟表 VT9 中的记录按照 <order_by_list> 进行排序操作,产生虚拟表 VT10。
- LIMIT:取出指定行的记录,产生虚拟表 VT11,并返回给查询用户。
15、介绍一下 MySQL 的常用命令?
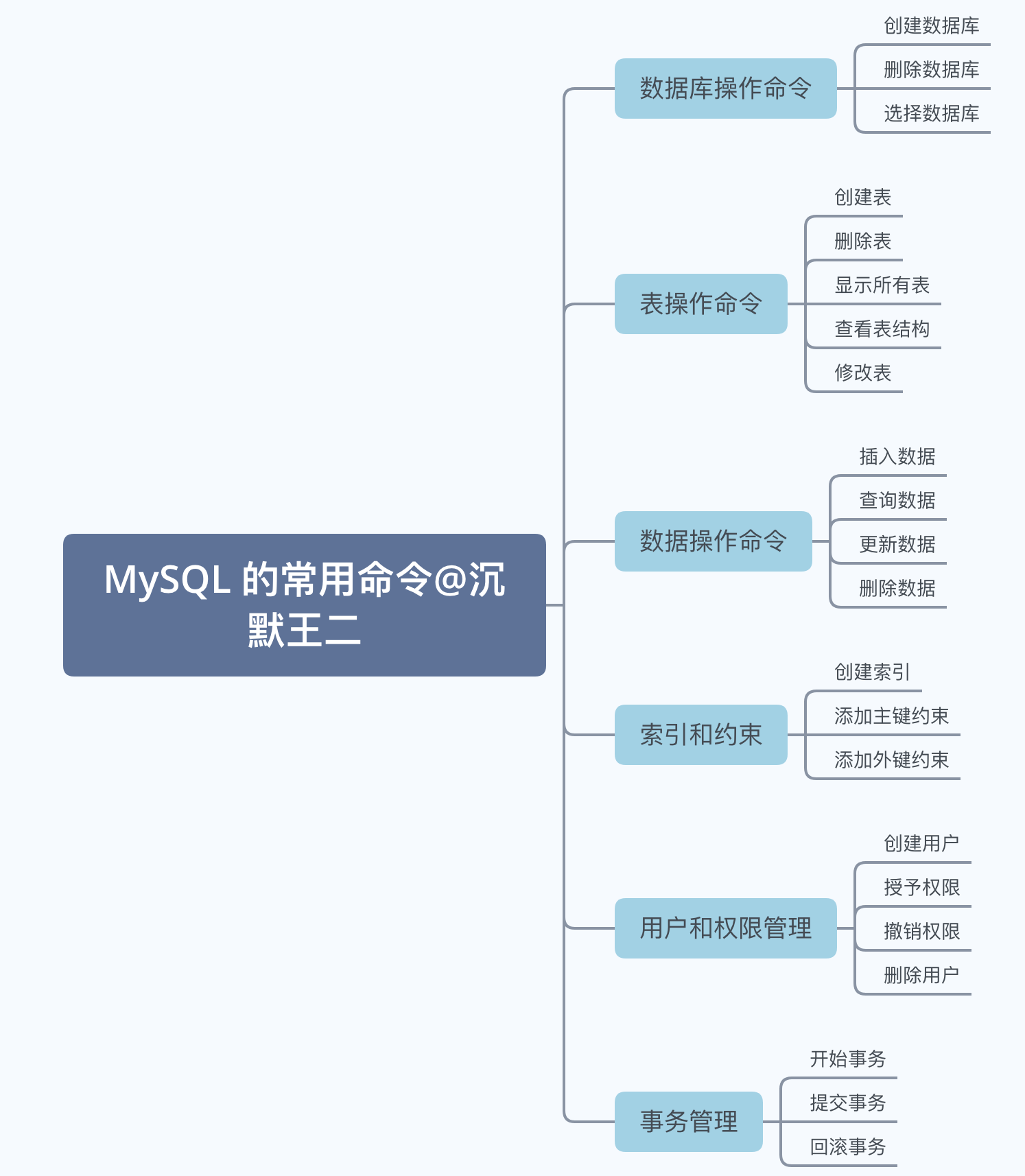
15.1 说说数据库操作命令?
- 创建数据库:
CREATE DATABASE database_name;
- 删除数据库:
DROP DATABASE database_name;
- 选择数据库:
USE database_name;
15.2 说说表操作命令?
- 创建表:
CREATE TABLE table_name (column1 datatype,column2 datatype,...
);
- 删除表:
DROP TABLE table_name;
- 显示所有表:
SHOW TABLES;
- 查看表结构:
DESCRIBE table_name;
- 修改表
ALTER TABLE table_name ADD column_name datatype;
15.3 CRUD 命令?
- 插入数据:
INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...);
- 查询数据:
SELECT column_names FROM table_name WHERE condition;
- 更新数据:
UPDATE table_name SET column1 = value1, column2 = value2 WHERE condition;
- 删除数据:
DELETE FROM table_name WHERE condition;
15.4 说说索引和约束的创建修改命令?
- 创建索引:
CREATE INDEX index_name ON table_name (column_name);
- 添加主键约束:
ALTER TABLE table_name ADD PRIMARY KEY (column_name);
- 添加外键约束:
ALTER TABLE table_name ADD CONSTRAINT fk_name FOREIGN KEY (column_name) REFERENCES parent_table (parent_column_name);
15.5 说说用户和权限管理的命令?
- 创建用户:
CREATE USER 'username'@'host' IDENTIFIED BY 'password';
- 授予权限:
GRANT ALL PRIVILEGES ON database_name.table_name TO 'username'@'host';
- 撤销权限:
REVOKE ALL PRIVILEGES ON database_name.table_name FROM 'username'@'host';
- 删除用户:
DROP USER 'username'@'host';
15.6 说说事务控制的命令?
- 开始事务:
START TRANSACTION;
- 提交事务:
COMMIT;
- 回滚事务:
ROLLBACK;
16、MySQL bin 目录下的可执行文件了解吗?
- mysql:客户端程序,用于连接 MySQL 服务器。
- mysqladmin:MySQL 管理工具,可以用来执行一些管理操作。
- mysqlcheck:MySQL 命令行工具,用于检查、修复、分析和优化数据库表。
- mysqldump:MySQL 数据库备份工具,用于创建一个或多个 MySQL 数据库的 SQL 转储文件。
- mysqlimport:用于从文本文件中导入数据到数据库表中,非常适合用于批量导入数据。
- mysqlshow:用于显示 MySQL 数据库服务器中的数据库、表、列等信息。
- mysqlbinlog:用于查看 MySQL 二进制日志文件的内容,可以用于恢复数据、查看数据变更等。
17、MySQL 第 3-10 条记录怎么查?
可以使用 limit 语句,结合偏移量 offset 和行数 row_count 来实现:
SELECT * FROM table_name LIMIT 2, 8;
- 2:偏移量,表示跳过前两条记录,从第 3 条记录开始。
- 8:行数,表示从偏移量开始,返回 8 条记录。
偏移量是从 0 开始的,即第一条记录的偏移量是 0;如果想从第 3 条记录开始,偏移量就应该是 2。
18、用过哪些 MySQL 函数?
MySQL 支持很多内置函数,包括字符串函数、数值函数、日期和时间函数、汇总函数、逻辑函数、格式化函数、类型转换函数等。
18.1 用过哪些字符串函数来处理文本?
- LENGTH():返回字符串的长度。
- CONCAT():连接两个或多个字符串。
- REPLACE():替换字符串中的某部分。
- SUBSTRING():从字符串中提取子字符串。
- LOWER() 和 UPPER():分别将字符串转换为小写或大写。
- TRIM():去除字符串两侧的空格或其他指定字符。
-- 获取字符串长度
SELECT LENGTH('沉默 王二') AS string_length;
-- 连接字符串
SELECT CONCAT('沉默', ' ', '王二') AS concatenated_string;
-- 替换字符串内容
SELECT REPLACE('沉默 王二', '王二', 'MySQL') AS replaced_string;
-- 提取子字符串
SELECT SUBSTRING('沉默 王二', 1, 5) AS substring;
-- 字符串转小写
SELECT LOWER('HELLO WORLD') AS lower_case;
-- 字符串转大写
SELECT UPPER('hello world') AS upper_case;
-- 去除字符串两侧的空格
SELECT TRIM(' 沉默 王二 ') AS trimmed_string;
18.2 用过哪些数值函数?
- ABS():返回一个数的绝对值。
- CEILING():返回大于或等于给定数值的最小整数。
- FLOOR():返回小于或等于给定数值的最大整数。
- ROUND():四舍五入到指定的小数位数。
- MOD():返回除法操作的余数。
-- 返回绝对值
SELECT ABS(-123) AS absolute_value;
-- 向上取整
SELECT CEILING(123.45) AS ceiling_value;
-- 向下取整
SELECT FLOOR(123.45) AS floor_value;
-- 四舍五入
SELECT ROUND(123.4567, 2) AS rounded_value;
-- 余数
SELECT MOD(10, 3) AS modulus;
18.3 用过哪些日期和时间函数?
- NOW():返回当前的日期和时间。
- CURDATE():返回当前的日期。
- CURTIME():返回当前的时间。
- DATE_ADD() 和 DATE_SUB():在日期上加上或减去指定的时间间隔。
- DATEDIFF():返回两个日期之间的天数。
- YEAR(),MONTH(),DAY():分别返回日期的年、月、日部分。
-- 返回当前日期和时间
SELECT NOW() AS current_date_time;
-- 返回当前日期
SELECT CURDATE() AS current_date;
-- 返回当前时间
SELECT CURTIME() AS current_time;
-- 在日期上添加天数
SELECT DATE_ADD(CURDATE(), INTERVAL 10 DAY) AS date_in_future;
-- 计算两个日期之间的天数
SELECT DATEDIFF('2024-12-31', '2024-01-01') AS days_difference;
-- 返回日期的年份
SELECT YEAR(CURDATE()) AS current_year;
18.4 用过哪些汇总函数?
- SUM():计算数值列的总和。
- AVG():计算数值列的平均值。
- COUNT():计算某列的行数。
- MAX() 和 MIN():分别返回列中的最大值和最小值。
- GROUP_CONCAT():将多个行值连接为一个字符串。
-- 创建一个表并插入数据进行聚合查询
CREATE TABLE sales (product_id INT,sales_amount DECIMAL(10, 2)
);INSERT INTO sales (product_id, sales_amount) VALUES (1, 100.00);
INSERT INTO sales (product_id, sales_amount) VALUES (1, 150.00);
INSERT INTO sales (product_id, sales_amount) VALUES (2, 200.00);-- 计算总和
SELECT SUM(sales_amount) AS total_sales FROM sales;
-- 计算平均值
SELECT AVG(sales_amount) AS average_sales FROM sales;
-- 计算总行数
SELECT COUNT(*) AS total_entries FROM sales;
-- 最大值和最小值
SELECT MAX(sales_amount) AS max_sale, MIN(sales_amount) AS min_sale FROM sales;
18.5 用过哪些逻辑函数?
- IF():如果条件为真,则返回一个值;否则返回另一个值。
- CASE:根据一系列条件返回值。
- COALESCE():返回参数列表中的第一个非 NULL 值。
-- IF函数
SELECT IF(1 > 0, 'True', 'False') AS simple_if;
-- CASE表达式
SELECT CASE WHEN 1 > 0 THEN 'True' ELSE 'False' END AS case_expression;
-- COALESCE函数
SELECT COALESCE(NULL, NULL, 'First Non-Null Value', 'Second Non-Null Value') AS first_non_null;
18.6 用过哪些格式化函数?
- FORMAT():格式化数字为格式化的字符串,通常用于货币显示。
-- 格式化数字
SELECT FORMAT(1234567.8945, 2) AS formatted_number;
18.6 用过哪些类型转换函数?
- CAST():将一个值转换为指定的数据类型。
- CONVERT():类似于CAST(),用于类型转换。
-- CAST函数
SELECT CAST('2024-01-01' AS DATE) AS casted_date;
-- CONVERT函数
SELECT CONVERT('123', SIGNED INTEGER) AS converted_number;
19、说说 SQL 的隐式数据类型转换?
在 SQL 中,当不同数据类型的值进行运算或比较时,会发生隐式数据类型转换。比如:当一个整数和一个浮点数相加时,整数会被转换为浮点数,然后再相加。当一个字符串和一个整数相加时,字符串会被转换为整数,然后再相加。数据类型隐式转换会导致意想不到的结果,所以要尽量避免隐式转换。
SELECT 1 + 1.0; -- 结果为 2.0
SELECT '1' + 1; -- 结果为 2
可以通过显式转换来规避这种情况:
SELECT CAST('1' AS SIGNED INTEGER) + 1; -- 结果为 2
20、说说 SQL 的语法树解析?
抽象语法树(AST)是 SQL 解析过程的中间表示,使用树形结构表示 SQL 语句的层次和逻辑。语法树由节点组成,每个节点表示 SQL 语句中的一个语法元素。
- 根节点:通常是 SQL 语句的主要操作,例如 SELECT、INSERT、UPDATE、DELETE 等。
- 内部节点:表示语句中的操作符、子查询、连接操作等。例如,WHERE 子句、JOIN 操作等。
- 叶子节点:表示具体的标识符、常量、列名、表名等。例如,users 表、id 列、常量 1 等。
以一个简单的 SQL 查询语句为例:
SELECT name, age FROM users WHERE age > 18;
这个查询语句的语法树可以表示为:
SELECT/ \Columns FROM/ \ |name age users|WHERE|age > 18
21、说说 MySQL 的基础架构?
MySQL 的架构大致可以分为三层,从上到下依次是:连接层、服务层、和存储引擎层。
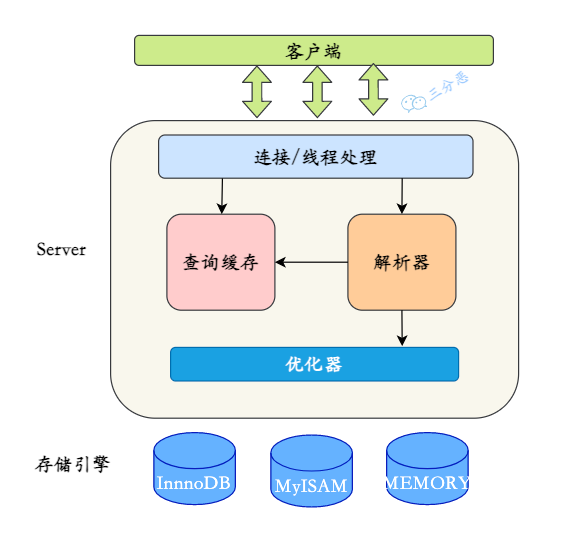
- 连接层主要负责客户端连接的管理,包括验证用户身份、权限校验、连接管理等。通过数据库连接池来提升连接的处理效率。
- 服务层是 MySQL 的核心,主要负责查询解析、优化、执行等操作。在服务层 SQL 语句会经过解析、优化器优化,然后转发到存储引擎执行,并返回结果。服务层包含查询解析器、优化器、执行计划生成器、缓存(如查询缓存)、日志模块等。
- 存储引擎层负责数据的实际存储和提取,是 MySQL 架构中与数据交互最直接的层。MySQL 支持多种存储引擎,如 InnoDB、MyISAM、Memory 等。
21.1 binlog 写入在哪一层?
binlog 在服务层,负责记录 SQL 语句的变化。它记录了所有对数据库进行更改的操作,用于数据恢复、主从复制等。
22、一条查询语句如何执行?
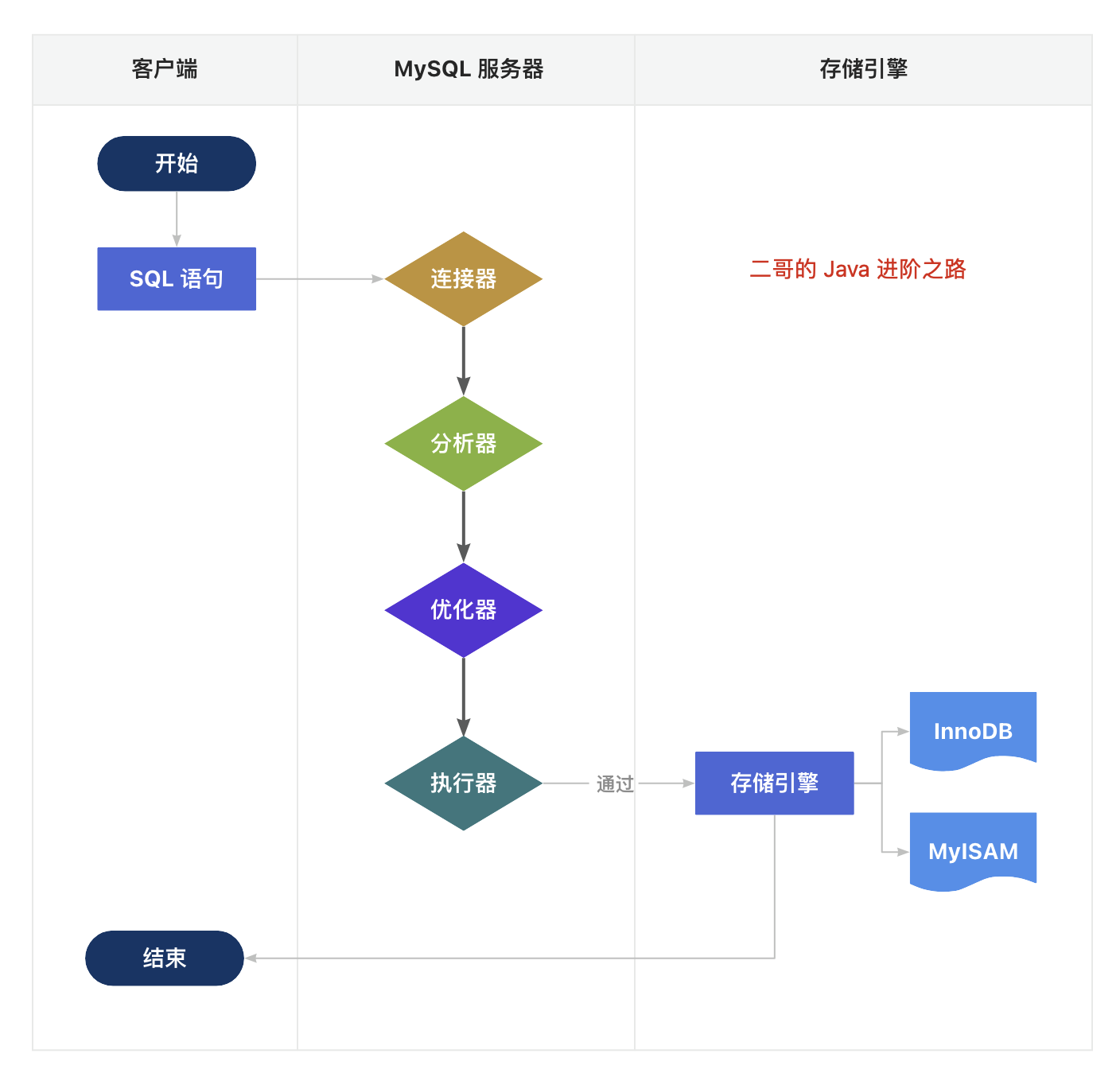
- 客户端发送 SQL 查询语句到 MySQL 服务器。
- MySQL 服务器的连接器开始处理这个请求,跟客户端建立连接、获取权限、管理连接。
- 解析器对 SQL 语句进行解析,检查语句是否符合 SQL 语法规则,确保引用的数据库、表和列都是存在的,并处理 SQL 语句中的名称解析和权限验证。
- 优化器负责确定 SQL 语句的执行计划,这包括选择使用哪些索引,以及决定表之间的连接顺序等。
- 执行器会调用存储引擎的 API 来进行数据的读写。
- MySQL 的存储引擎是插件式的,不同的存储引擎在细节上面有很大不同。例如,InnoDB 是支持事务的,而 MyISAM 是不支持的。之后,会将执行结果返回给客户端。
- 客户端接收到查询结果,完成这次查询请求。
23、一条更新语句怎么执行的?
更新语句的执行是服务层和引擎层配合完成,数据除了要写入表中,还要记录相应的日志。
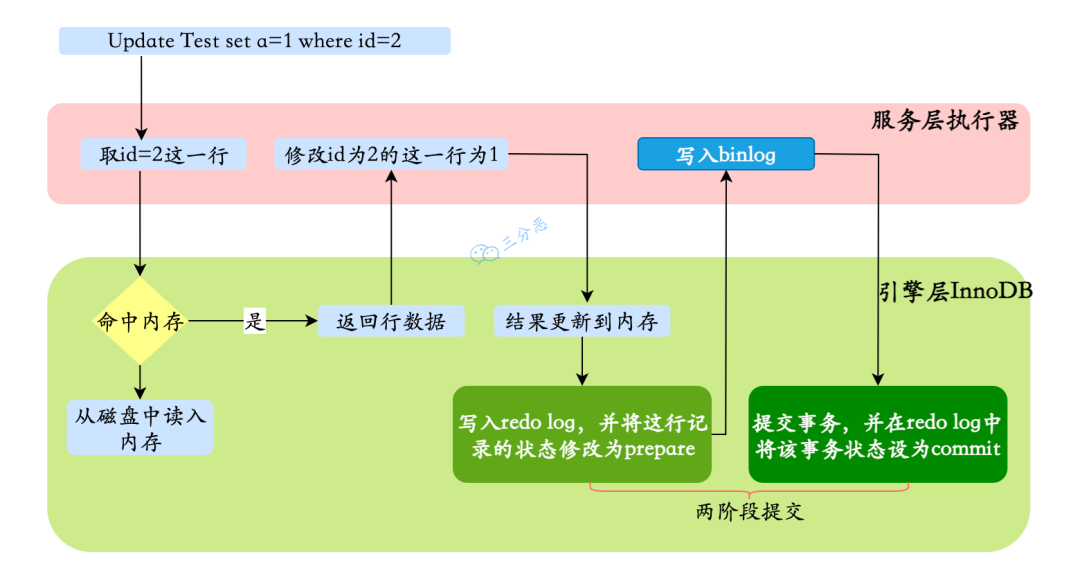
- 执行器先找引擎获取 ID = 2 这一行。ID 是主键,存储引擎检索数据,找到这一行。如果 ID = 2 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据把这个值加上 1,比如原来是 N,现在就是 N + 1,得到新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中,并将这个更新操作记录到 redo log,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
24、说说 MySQL 的数据存储形式?
MySQL 是以表的形式存储数据的,而表空间的结构则由段、区、页、行组成。
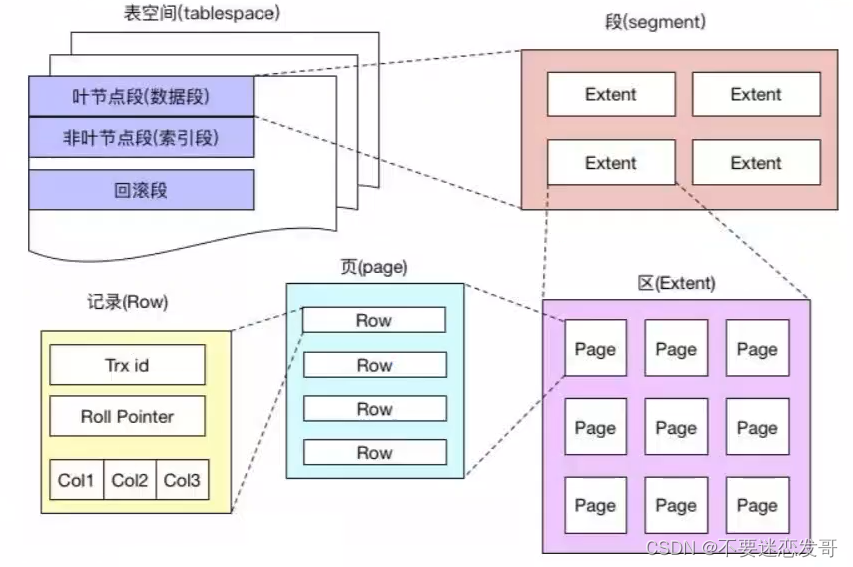
- 段(Segment):表空间由多个段组成,常见的段有数据段、索引段、回滚段等。创建索引时会创建两个段,数据段和索引段,数据段用来存储叶子节点中的数据;索引段用来存储非叶子节点的数据。回滚段包含了事务执行过程中用于数据回滚的旧数据。
- 区(Extent):段由一个或多个区组成,区是一组连续的页,通常包含 64 个连续的页,也就是 1M 的数据。使用区而非单独的页进行数据分配可以优化磁盘操作,减少磁盘寻道时间,特别是在大量数据进行读写时。
- 页(Page):页是 InnoDB 存储数据的基本单元,标准大小为 16 KB,索引树上的一个节点就是一个页。也就意味着数据库每次读写都是以 16 KB 为单位的。
- 行(Row):InnoDB 采用行存储方式,意味着数据按照行进行组织和管理,行数据可能有多个格式,比如说 COMPACT、REDUNDANT、DYNAMIC 等。MySQL 8.0 默认的行格式是 DYNAMIC,由COMPACT 演变而来,意味着这些数据如果超过了页内联存储的限制,则会被存储在溢出页中。
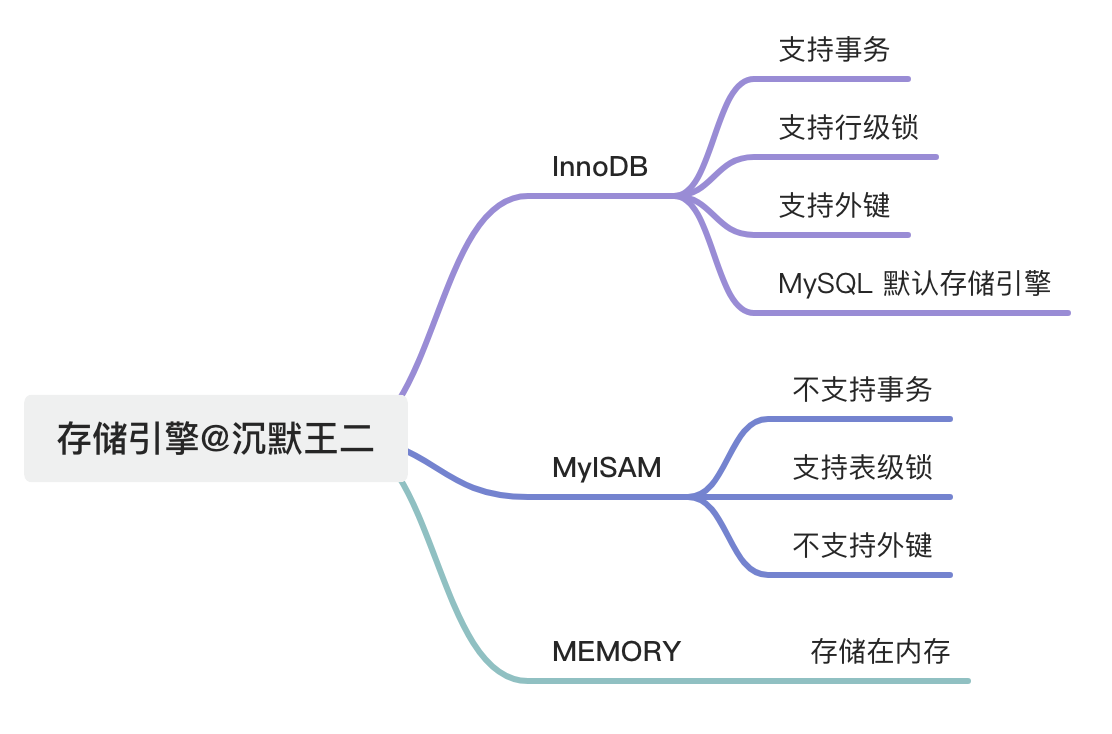
25、MySQL 有哪些常见存储引擎?
MySQL 支持多种存储引擎,常见的有 InnoDB、MyISAM、MEMORY 等。
25.1 如何切换 MySQL 的数据引擎?
可以通过 alter table 语句来切换 MySQL 的数据引擎。不过不建议,应该提前设计好到底用哪一种存储引擎。
ALTER TABLE your_table_name ENGINE=InnoDB;
26、那存储引擎应该怎么选择?
- 大多数情况下,使用默认的 InnoDB 就对了,InnoDB 可以提供事务、行级锁、外键、B+ 树索引等能力。
- MyISAM 适合读更多的场景。
- MEMORY 适合临时表,数据量不大的情况。由于数据都存放在内存,所以速度非常快。
27、InnoDB 和 MyISAM 主要有什么区别?
InnoDB 和 MyISAM 之间的区别主要表现在:存储结构、事务支持、锁粒度、索引类型、主键必需、表的具体行数、外键支持等方面。
- 存储结构:
- InnoDB:用两种格式的文件来存储,.frm 文件存储表的定义;.ibd 存储数据和索引。
- MyISAM:用三种格式的文件来存储,.frm 文件存储表的定义;.myd 存储数据;.myi 存储索引。
- 事务支持:
- InnoDB:支持事务。
- MyISAM:不支持事务。
- 最小锁粒度:
- InnoDB:行级锁,并发写入性能高。
- MyISAM:表级锁,高并发中写操作存在性能瓶颈。
- 索引类型:
- InnoDB 为聚簇索引,索引和数据不分开。

- MyISAM 为非聚簇索引,索引和数据分开存储,索引保存的是数据文件的指针。

- 外键支持:
- InnoDB:支持外键。
- MyISAM:不支持外键。
- 主键必需:
- InnoDB:必须有主键。
- MyISAM:可以没有主键。
- 表的具体行数:
- InnoDB:表的具体行数需要扫描整个表才能返回。
- MyISAM:具体行数存储在表的属性中。
28、InnoDB 的 Buffer Pool了解吗?
Buffer Pool 是 InnoDB 存储引擎中的一个内存缓冲区,它会将数据以页(page)为单位保存在内存中,当有查询请求需要读取数据时,会优先从 Buffer Pool 获取数据,避免直接访问磁盘。也就是说,即便我们只访问了一行数据的一个字段,InnoDB 也会将整个数据页加载到 Buffer Pool 中,以便后续的查询。修改数据时,也会先在缓存页面中修改。当缓存中的数据页被修改后,会在 Buffer Pool 中变为脏页,不会立刻写回到磁盘。InnoDB 会定期将这些脏页刷新到磁盘,保证数据的一致性。通常采用 LRU 算法来管理缓存页,将最近最少使用的数据移出缓存,为新数据腾出空间。
Buffer Pool 能够显著减少对磁盘的访问,从而提升数据库的读写性能。调优上,我们可以设置合理的 Buffer Pool 大小(通常为物理内存的 70%),并配置多个 Buffer Pool 实例(通过 innodb_buffer_pool_instances)来提升并发能力。