Opencv计算机视觉编程攻略-第十节 估算图像之间的投影关系
目录
1. 计算图像对的基础矩阵
2. 用RANSAC 算法匹配图像
3. 计算两幅图像之间的单应矩阵
4. 检测图像中的平面目标
图像通常是由数码相机拍摄的,它通过透镜投射光线成像,是三维场景在二维平面上的投影,这表明场景和它的图像之间以及同一场景的不同图像之间都有着重要的关联。投影几何学是用数学术语描述和区分成像过程的工具。下文将介绍几种多视图图像中基本的投影关系,并解释如何在计算机视觉编程中将其投入应用。
光线从被摄景象发出并穿过前置孔径,被相机捕获,捕获到的光线触发相机后面的成像平面(或图像传感器)
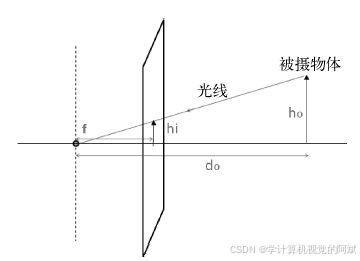
进一步构建,世界坐标系-图像坐标系转换矩阵:
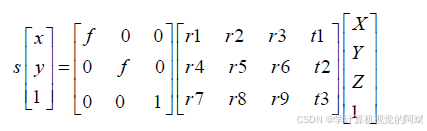
1. 计算图像对的基础矩阵
上述投影方程解释了真实的场景是如何投影到单目相机的成像平面上的。在同一场景的两幅图像之间的投影关系:可以移动相机,从两个视角拍摄两幅照片;也可以使用两个相机,分别对同一个场景拍摄照片,如果这两个相机被刚性基线分割,我们就称之为立体视觉。
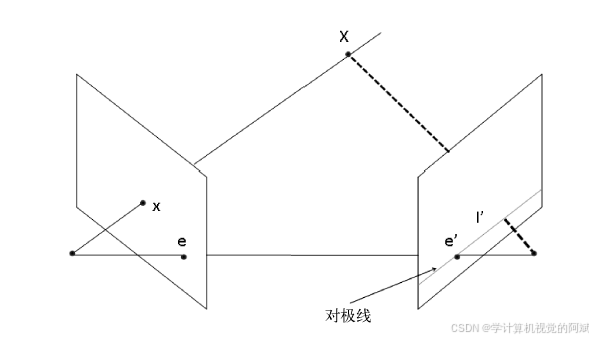
沿着三维点X 和相机中心点之间的连线,可在图像上找到对应的点x,反过来,在三维空间中,与成像平面上的位置x 对应的场景点可以位于线条上的任何位置。这说明如果要根据图像中的一个点找到另一幅图像中对应的点,就需要在第二个成像平面上沿着这条线的投影搜索。这条虚线称为点x 的对极线。它规定了两个对应点必须满足的基本条件,即对于一个点,在另一视图中与它匹配的点必须位于它的对极线上,并且对极线的准确方向取决于两个相机的相对位置。
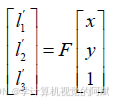
即所有的对极线都通过同一个点。这个点对应着一个相机中心点在另一个相机上的投影(上图中的e 和e')。这个特殊的点称为极点,矩阵F(称为基础矩阵)的作用就是把一个视图上的二维图像点映射到另一个视图上的对极线上。如果两幅图像之间有一定数量的已知匹配点,就可以利用方程组来计算图像对的基础矩阵,即假设点(x, y)的对应点为(x', y'),这两个视图间的基础矩阵为F,由于(x', y') 位于(x, y)和F 相乘得到的对极线上(用齐次坐标表示)。
这样的匹配项至少要有7 对,用OpenCV 函数cv::findFundamentalMat 计算基础矩阵时,将使用上一节获得的匹配点匹配项。
//1. 这些匹配项存储在cv::DMatch 类型的容器中,其中每个元素代表一个cv::keypoint 实例的索引。为了在cv::findFundamentalMat 中使用,需要先把这些关键点转换成cv::Point2f类型。为此可用下面的OpenCV 函数:
// 把关键点转换成Point2f
std::vector<cv::Point2f> selPoints1, selPoints2;
std::vector<int> pointIndexes1, pointIndexes2;
cv::KeyPoint::convert(keypoints1,selPoints1,pointIndexes1);
cv::KeyPoint::convert(keypoints2,selPoints2,pointIndexes2);//2. 结果是selPoints1 和selPoints2 这两个容器,容器的元素为两幅图像中相关像素的坐标。容器pointIndexes1 和pointIndexes2 包含这些被转换的关键点的索引。于是调用cv::findFundamentalMat 函数的方法为:
// 用7 对匹配项计算基础矩阵
cv::Mat fundamental= cv::findFundamentalMat(selPoints1, // 第一幅图像中的7 个点selPoints2, // 第二幅图像中的7 个点cv::FM_7POINT); // 7 个点的方法//3. 要想直观地验证这个基础矩阵的效果,可以选取一些点,画出它们的对极线。OpenCV 中有一个函数可计算指定点集的对极线。计算出对极线后,可用函数cv::line 画出它们。
// 在右侧图像上画出对极线的左侧点
std::vector<cv::Vec3f> lines1;
cv::computeCorrespondEpilines(selPoints1, // 图像点1, // 在第一幅图像中(也可以是在第二幅图像中)fundamental, // 基础矩阵lines1); // 对极线的向量// 遍历全部对极线
for (vector<cv::Vec3f>::const_iterator it= lines1.begin();it!=lines1.end(); ++it) {// 画出第一列和最后一列之间的线条cv::line(image2, cv::Point(0,-(*it)[2]/(*it)[1]),cv::Point(image2.cols,-((*it)[2]+ (*it)[0]*image2.cols)/(*it)[1]),cv::Scalar(255,255,255));
}
2. 用RANSAC 算法匹配图像
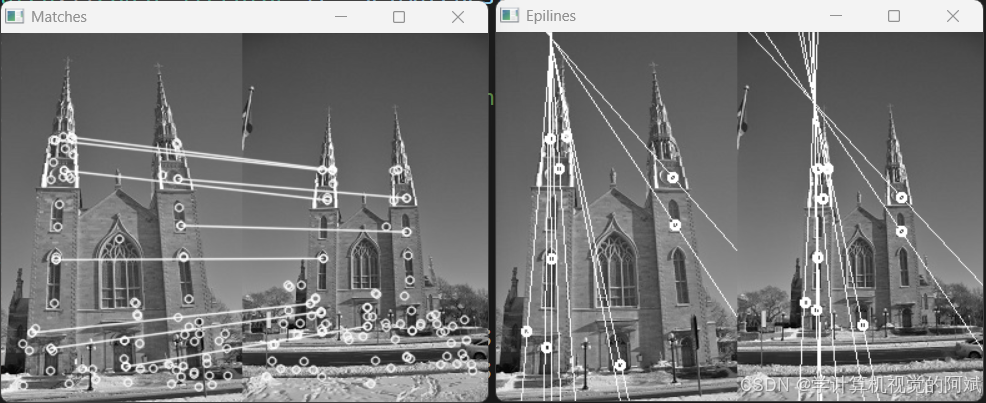
如何进一步使用上一节介绍的极线约束,使图像特征的匹配更加可靠:在匹配两幅图像的特征点时,只接受位于对极线上的匹配项。若要判断是否满足这个条件,必须先知道基础矩阵,但计算基础矩阵又需要优质的匹配项。这看起来像是“先有鸡还是先有蛋”的问题,下图为原始匹配结果。

我们的目的是计算两个视图间的基础矩阵和优质匹配项。因此,所有已发现的特征点的匹配度都要用上一节的极线约束验证
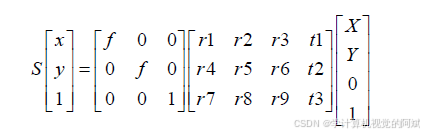
通过单应矩阵可以将假设仅通过旋转变换得到得两张图片进行极线对齐,从而服务于下一步得视差估计。场景点中值为0 的坐标会消除掉投影矩阵的第三列,从而又变成一个3×3 的矩阵。这种特殊矩阵称为单应矩阵(homography),表示在特殊情况下(这里指纯旋转或平面目标),世界坐标系的点和它的影像之间是线性关系。此外,由于该矩阵是可逆的,所以只要两个视图只是经过了旋转,或者拍摄的是平面物体,那么就可以将一个视图中的像素点与另一个视图中对应的像素点直接关联起来。单应矩阵的格式为:
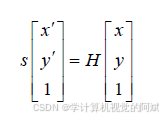
其中H 是一个3×3 矩阵。这个关系式包含了一个尺度因子,用s 表示。计算得到这个矩阵后,一个视图中的所有点都可以根据这个关系式转换到另一个视图。
// 用RANSAC 算法匹配特征点
// 返回基础矩阵和输出的匹配项
cv::Mat match(cv::Mat& image1,cv::Mat& image2, // 输入图像std::vector<cv::DMatch>& matches, // 输出匹配项std::vector<cv::KeyPoint>& keypoints1, // 输出关键点std::vector<cv::KeyPoint>& keypoints2) {// 1.检测特征点detector->detect(image1,keypoints1);detector->detect(image2,keypoints2);// 2.提取特征描述子cv::Mat descriptors1, descriptors2;descriptor->compute(image1,keypoints1,descriptors1);descriptor->compute(image2,keypoints2,descriptors2);// 3.匹配两幅图像描述子// (用于部分检测方法)// 构造匹配类的实例(带交叉检查)cv::BFMatcher matcher(normType, // 差距衡量true); // 交叉检查标志// 匹配描述子std::vector<cv::DMatch> outputMatches;matcher.match(descriptors1,descriptors2,outputMatches);// 4.用RANSAC 算法验证匹配项cv::Mat fundamental= ransacTest(outputMatches,keypoints1, keypoints2,matches);// 返回基础矩阵return fundamental;
}RANSAC 算法旨在根据一个可能包含大量局外项的数据集,估算一个特定的数学实体。其原理是从数据集中随机选取一些数据点,并仅用这些数据点进行估算。选取的数据点数量,应该是估算数学实体所需的最小数量,对于基础矩阵,最小数量是8 个匹配对(实际上只需要7 个,但是8 个点的线性算法速度较快)。用这8 个随机匹配对估算基础矩阵后,对剩下的全部匹配项进行测试,验证其是否满足根据这个矩阵得到的极线约束。标识出所有满足极线约束的匹配项(即特征点与对极线距离很近的匹配项),这些匹配项就组成了基础矩阵的支撑集。RANSAC 算法背后的核心思想是:支撑集越大,所计算矩阵正确的可能性就越大。反之,如果一个(或多个)随机选取的匹配项是错误的,那么计算得到的基础矩阵也是错误的,并且它的支撑集肯定会很小。反复执行这个过程,最后留下支撑集最大的矩阵作为最佳结果:


通过极线约束后可以将特征点进行限制,找到高质量得匹配点,从而计算H矩阵,并基于H矩阵实现图像拼接,opencv里有内置得拼接函数
// 读取输入的图像
std::vector<cv::Mat> images;
images.push_back(cv::imread("parliament1.jpg"));
images.push_back(cv::imread("parliament2.jpg"));
cv::Mat panorama; // 输出的全景图
// 创建拼接器
cv::Stitcher stitcher = cv::Stitcher::createDefault();
// 拼接图像
cv::Stitcher::Status status = stitcher.stitch(images, panorama);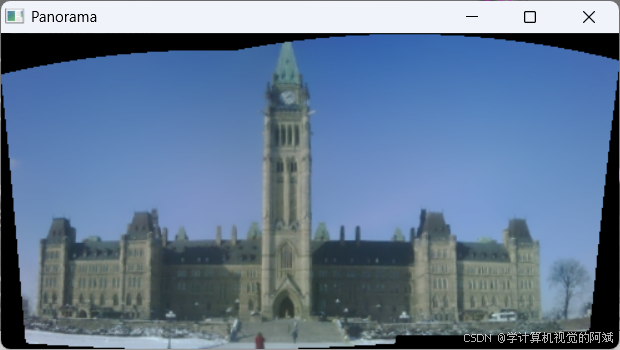
3. 检测图像中的平面目标
假定我们需要检测图像中的平面物体。这个物体可能是一张海报、一幅画等等。采取的方法是检测这个平面物体的特征点,然后试着在图像中匹配这些特征点。然后和前面一样,用鲁棒匹配方案来验证这些匹配项,但这次要基于单应矩阵。
将目标图像依次进行压缩像素采样,得到一系列类似金字塔的图像,从这些图像中就可以检测到特征点。
// 1. 初始化匹配器 使用两个快速得多尺度检测器
TargetMatcher tmatcher(cv::FastFeatureDetector::create(10),cv::BRISK::create());
tmatcher.setNormType(cv::NORM_HAMMING);因为不知道图像中目标物体的大小,所以我们把目标图像转换成一系列不同的尺寸,构建成一个金字塔。除了这种方法,也可以采用尺度不变特征。在金字塔中,目标图像的尺寸按特定比例(属性scaleFactor,默认为0.9)逐层缩小。
detectTarget 接下来要执行三个步骤。
- 第一步,在输入图像中检测兴趣点。
- 第二步,将该图像与目标金字塔中的每幅图像进行鲁棒匹配,并把优质匹配项最多的那一层保留下来;如果这一层的匹配项足够多,就可认为已经找到目标。
- 第三步,使用得到的单应矩阵和cv::getPerspectiveTransform 函数,把目标中的四个角点重新投影到输入图像中。
// 检测预先定义的平面目标
// 返回单应矩阵和检测到的目标的4 个角点
cv::Mat detectTarget(
const cv::Mat& image, // 目标角点(顺时针方向)的坐标
std::vector<cv::Point2f>& detectedCorners) {
// 1.检测图像的关键点
std::vector<cv::KeyPoint> keypoints;
detector->detect(image, keypoints);
// 计算描述子
cv::Mat descriptors;
descriptor->compute(image, keypoints, descriptors);
std::vector<cv::DMatch> matches;
cv::Mat bestHomography;
cv::Size bestSize;
int maxInliers = 0;
cv::Mat homography;
// 构建匹配器
cv::BFMatcher matcher(normType);
// 2.对金字塔的每层,鲁棒匹配单应矩阵
for (int i = 0; i < numberOfLevels; i++) {
// 在目标和图像之间发现RANSAC 单应矩阵
matches.clear();
// 匹配描述子
matcher.match(pyrDescriptors[i], descriptors, matches);
// 用RANSAC 验证匹配项
std::vector<cv::DMatch> inliers;
homography = ransacTest(matches, pyrKeypoints[i],
keypoints, inliers);
if (inliers.size() > maxInliers) { // 有更好的H
maxInliers = inliers.size();
bestHomography = homography;
bestSize = pyramid[i].size();
}
}
// 3.用最佳单应矩阵找出角点坐标
if (maxInliers > 8) { // 估算值有效
// 最佳尺寸的目标角点
std::vector<cv::Point2f> corners;
corners.push_back(cv::Point2f(0, 0));
corners.push_back(cv::Point2f(bestSize.width - 1, 0));
corners.push_back(cv::Point2f(bestSize.width - 1,
bestSize.height - 1));
corners.push_back(cv::Point2f(0, bestSize.height - 1));
// 重新投影目标角点
cv::perspectiveTransform(corners, detectedCorners, bestHomography);
}
return bestHomography;
}
本节内容还需多多学习,如果感兴趣,请下载上传代码自行研究。代码资源