大语言模型 04:模型量化详解 KTransformers MoE推理优化技术
基本介绍
随着大语言模型(LLM)的规模不断扩大,模型的推理效率和计算资源的需求也在迅速增加。DeepSeek-V2作为当前热门的LLM之一,通过创新的架构设计与优化策略,在资源受限环境下实现了高效推理。
本文将详细介绍DeepSeek-V2是如何通过“异构和局部MoE推理”、优化算子以及量化技术,实现推理效率的显著提升。此外,本文还将探讨MoE模型的背景、优势、应用场景,以及未来可能的发展趋势。
官方对这块做了详细的解读,有兴趣可以详细了解:https://kvcache-ai.github.io/ktransformers/en/deepseek-v2-injection.html
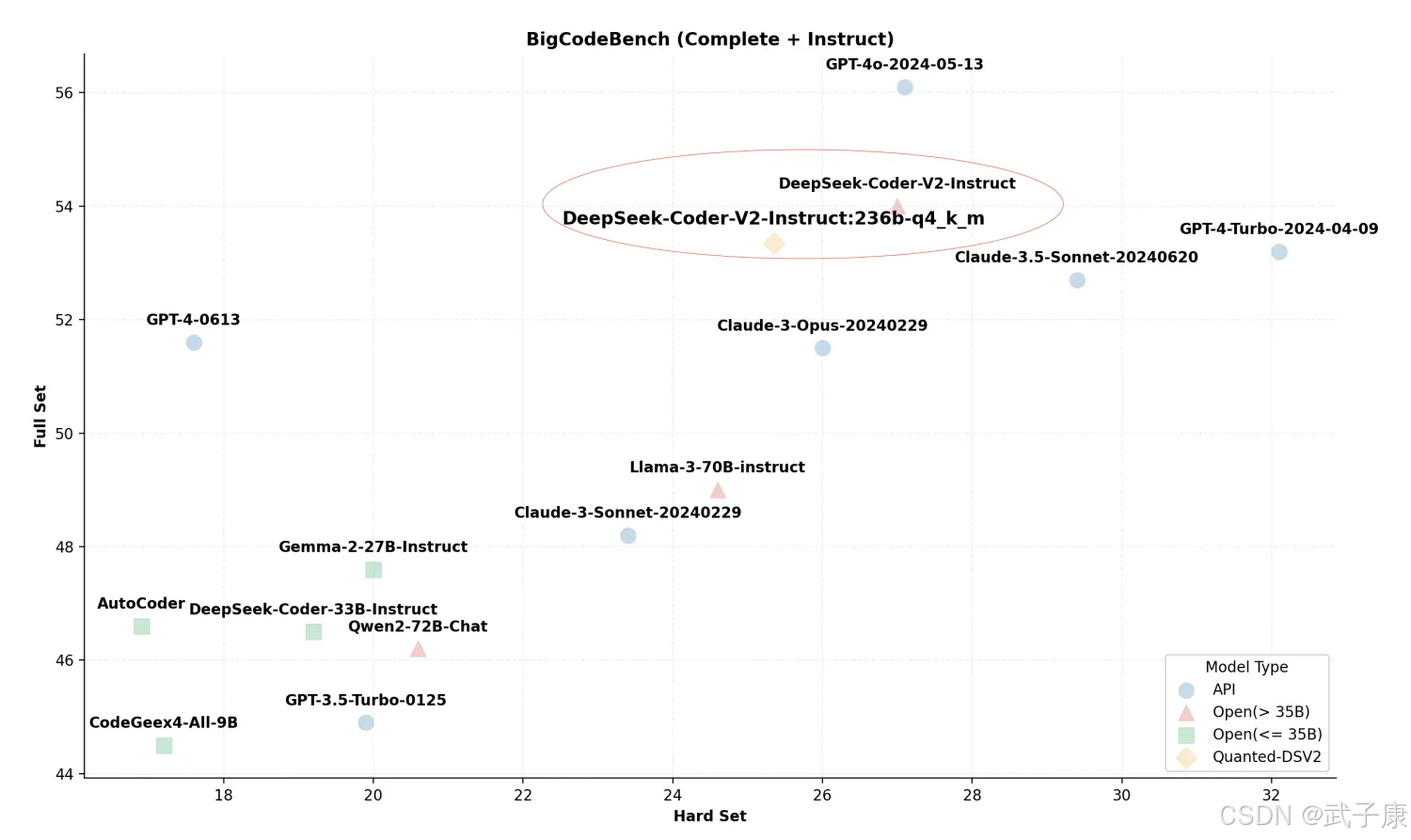
简单来说,是通过 “异构和局部 MoE 推理” 实现的。
【MoE = mixture-of-experts 专家混合模型】
在 V2 版本中,总共是 2360 亿个参数,每个 token 会激活 210 亿个参数。
在传统注意力机制模型中,采用的是分组查询注意力(Grouped-Query Attention = GQA);在 DeepSeek-V2 中引入了多头潜在注意力(Multi-head Latent Attention = MLA)。
通过这种方式减少了推理过程中所需要的KV缓存的大小,以此来提高效率。
DeepSeek-V2 本身大约需要:80GB GPU * 8 才可以运行,但是在项目组努力下,实现了在 21GB VRAM 和 136GB DRAM 的机器上运行。
什么是DeepSeek-V2?
DeepSeek-V2是一种采用专家混合模型(Mixture-of-Experts, MoE)的新型大语言模型。在V2版本中,该模型共拥有2360亿个参数,但每个token仅激活210亿个参数,大幅减少了推理计算量。
传统的Transformer模型通常采用分组查询注意力机制(Grouped-Query Attention, GQA),而DeepSeek-V2则引入了多头潜在注意力机制(Multi-head Latent Attention, MLA),从而有效降低推理阶段的KV缓存大小,提升推理性能。
MoE(专家混合模型)的背景与优势
- 专家混合模型最早由Jacobs等人在1991年提出,旨在通过多个子模型(专家)协作解决单个复杂问题。MoE模型具有以下优势:
- 高效参数利用:通过稀疏激活机制,每个输入仅激活少数专家,大大降低了推理成本。
- 强大的模型容量:相比传统单一模型,MoE能够以较少的计算资源实现更高的模型容量。
- 更好的泛化能力:不同的专家擅长处理不同类型的输入,整体表现更加稳定和鲁棒。
MoE 特点
- 减少计算复杂度:通过动态选择激活的专家数量,DeepSeek 的 MoE 可以在保持较高模型表达能力的同时,显著降低计算成本和推理时间。
- 大规模参数:DeepSeek 的 MoE 采用大规模的参数量(例如 2360 亿个参数),但每个 token 只激活一部分参数,这使得推理过程更加高效,避免了计算冗余。
- 提高推理速度:通过专家模型的局部激活和精简的计算,DeepSeek 的 MoE 在推理速度上取得了显著的提升。例如,DeepSeek 在 V2 版本中的 MoE 推理性能相比传统的全模型推理提升了约 6 倍。
MoE 工作原理
- 专家选择:MoE 模型会根据输入数据自动选择一些专家模型进行推理,而不是让所有专家参与计算。这种选择机制通常依赖于输入的特征或预设的策略。例如,输入的不同部分可以激活不同的专家,从而根据任务的需求只激活一部分网络,减少不必要的计算。
- 局部专家:与传统的深度学习模型相比,MoE 模型并不会在每个时间步都使用所有的参数,而是通过“局部专家”策略仅激活一部分专家来处理输入数据。这意味着模型会动态选择合适的专家进行推理,节省了计算资源。
- 异构结构:DeepSeek 在其 MoE 机制中采用了异构结构,能够在不同的硬件环境下灵活运行。比如,可以根据计算需求调整使用的专家数目,或者根据 GPU 的可用资源选择不同的网络结构。
MoE 的应用
- 大规模语言模型:DeepSeek 的 MoE 模型在自然语言处理任务中表现出色,特别是在生成式任务和大规模文本推理中,MoE 的优势可以有效减少计算和提升响应速度。
- 高效推理:由于 MoE 能够根据输入的内容选择性地激活专家,DeepSeek 的推理过程非常高效,尤其适用于需要大规模计算和实时响应的应用场景,如聊天机器人、搜索引擎优化等。
KTransformers对DeepSeek-V2的关键优化
优化的MLA算子
原始DeepSeek-V2的MLA算子在解压后进行KV缓存键值对存储,这种方法会扩大KV缓存大小并降低性能。KTransformers项目组基于原始论文,开发了专门针对推理场景的优化版本,大幅减少KV缓存大小,同时提高算子的计算性能,充分发挥GPU的计算能力。
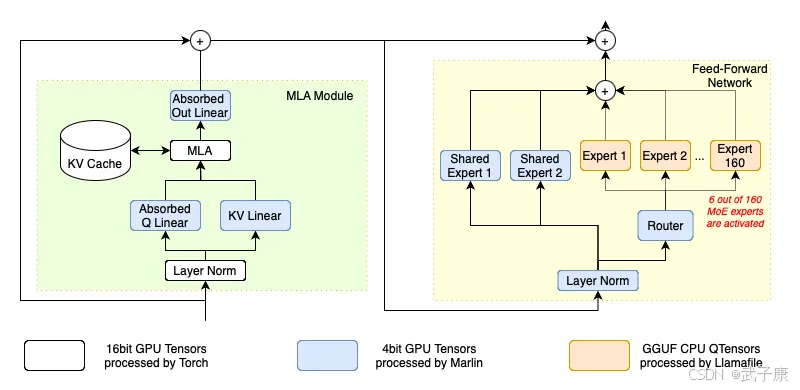
高级量化内核
原始DeepSeek-V2以BF16精度运行,需要约470GB的存储空间。项目组采用了社区中广泛认可的GGUF量化方法,并开发了直接处理量化数据类型的高级内核,有效优化了模型的推理性能。此外,团队选择Marlin作为GPU内核,llamafile作为CPU内核。这些内核都是经过专门设计的,并通过专家并行性和其他优化策略,实现了高效的CPU端MoE推理,被称为CPUInfer。
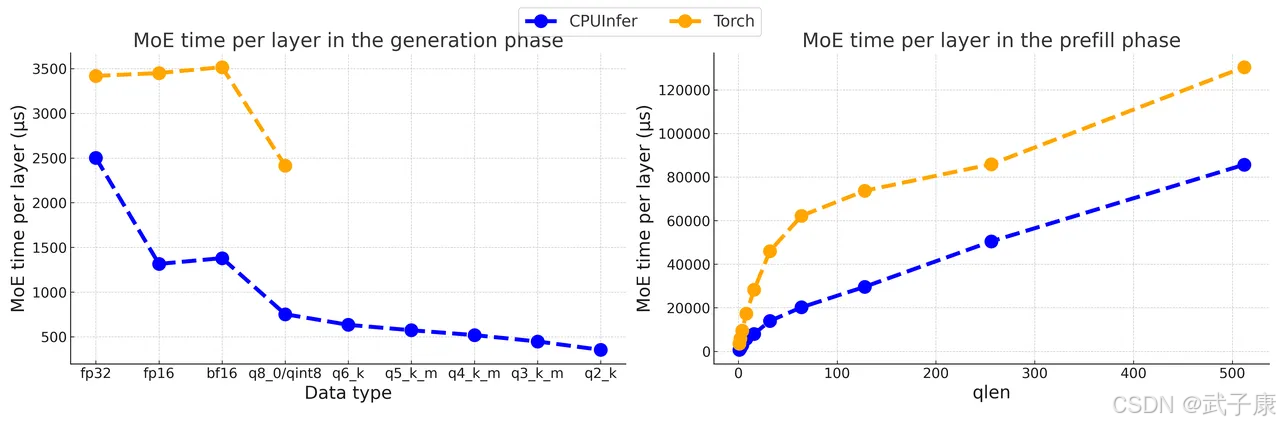
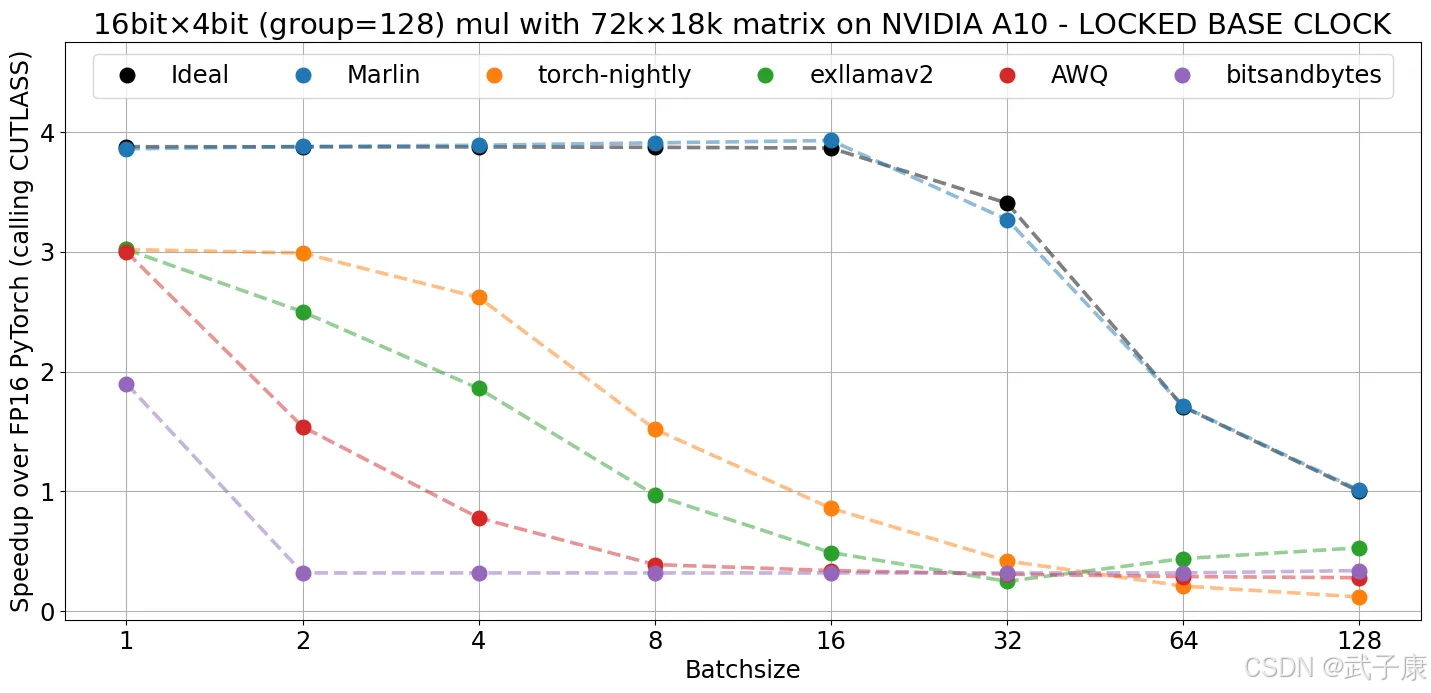
算术强度引导卸载策略
项目组采用了一种称为“算术强度引导卸载”的策略,将计算最密集的参数策略性地存储在GPU上,而非将全部2360亿参数放入GPU内存中。
在DeepSeek-V2的每个Transformer Block中,有160位混合专家(MoE),占总参数的96%。但每个token仅激活其中的6个专家,因此解码阶段实际使用的MoE参数仅占3.75%。这一策略极大地减少了GPU的负担,提升了计算资源的利用效率。
YAML模板配置实现优化
为实现上述优化,用户需要定义特定的YAML配置文件,该配置文件主要包括以下三项关键优化规则:
- 将注意力模块替换为优化的MLA算子。
- 将路由专家模块替换为使用llamafile内核的CPUInfer。
- 将非注意力相关的线性模块替换为Marlin内核。
具体的配置流程与细节,建议参考KTransformers官方文档。
MoE模型的应用场景
MoE模型凭借其高效能的特性,广泛应用于多种领域,包括但不限于:
- 自然语言处理(NLP):如语言生成、翻译和问答系统。
- 计算机视觉:如大规模图像分类、目标检测任务。
- 推荐系统:高效处理大规模个性化推荐任务。
MoE模型未来发展趋势
未来,MoE模型预计将朝着以下几个方向发展:
- 更加高效的路由机制:优化专家选择策略,进一步降低延迟。
- 跨模态MoE架构:结合视觉、语言、语音等多种数据类型,构建更加强大的多模态MoE模型。
- 资源受限环境部署优化:持续优化模型压缩与量化技术,进一步降低部署门槛。
最后总结
通过上述优化,DeepSeek-V2能够在仅有21GB VRAM与136GB DRAM的资源条件下稳定运行,展现了强大的推理能力。这些技术创新不仅使得超大规模语言模型的部署更具可行性,也为未来大模型的发展提供了宝贵的实践经验。
DeepSeek 的 MoE 通过灵活的专家选择、局部激活和异构计算的设计,有效提升了模型的推理效率和计算能力。它的应用不仅限于自然语言处理,也可以扩展到其他需要大规模推理的任务中。
希望本文对你理解DeepSeek-V2及其优化策略有所帮助。如需进一步了解,推荐阅读官方文档以获取更深入的信息。