[项目总结] 在线OJ刷题系统项目技术应用(上)
🌸个人主页:https://blog.csdn.net/2301_80050796?spm=1000.2115.3001.5343
🏵️热门专栏:
🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm=1001.2014.3001.5482
🍕 Collection与数据结构 (93平均质量分)https://blog.csdn.net/2301_80050796/category_12621348.html?spm=1001.2014.3001.5482
🧀线程与网络(96平均质量分) https://blog.csdn.net/2301_80050796/category_12643370.html?spm=1001.2014.3001.5482
🍭MySql数据库(93平均质量分)https://blog.csdn.net/2301_80050796/category_12629890.html?spm=1001.2014.3001.5482
🍬算法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12676091.html?spm=1001.2014.3001.5482
🍃 Spring(97平均质量分)https://blog.csdn.net/2301_80050796/category_12724152.html?spm=1001.2014.3001.5482
🎃Redis(97平均质量分)https://blog.csdn.net/2301_80050796/category_12777129.html?spm=1001.2014.3001.5482
🐰RabbitMQ(97平均质量分) https://blog.csdn.net/2301_80050796/category_12792900.html?spm=1001.2014.3001.5482
感谢点赞与关注~~~

目录
- 0. 项目简介
- 1. JWT令牌解析技术
- 1.1 技术原理
- 1.2 项目应用
- 2. 密码加密技术(哈希加密技术)
- 2.1 技术原理
- 2.2 项目应用
- 3. 雪花算法
- 3.1 技术原理
- 3.2 项目应用
- 4. 统一返回结果
- 5. 统一异常处理
- 5.1 技术原理
- 5.2 项目应用
- 6. 拦截器
- 6.1 技术原理
- 6.2 项目应用
- 7. ElasticSearch
- 7.1 技术原理
- 7.2 项目应用
- 8. Redis缓存
- 8.1 用户层面
- 8.2 题目层面
- 8.3 竞赛层面
- 8.4 站内信层面
- 9. Spring AOP
- 9.1 技术原理
- 9.2 项目应用
0. 项目简介
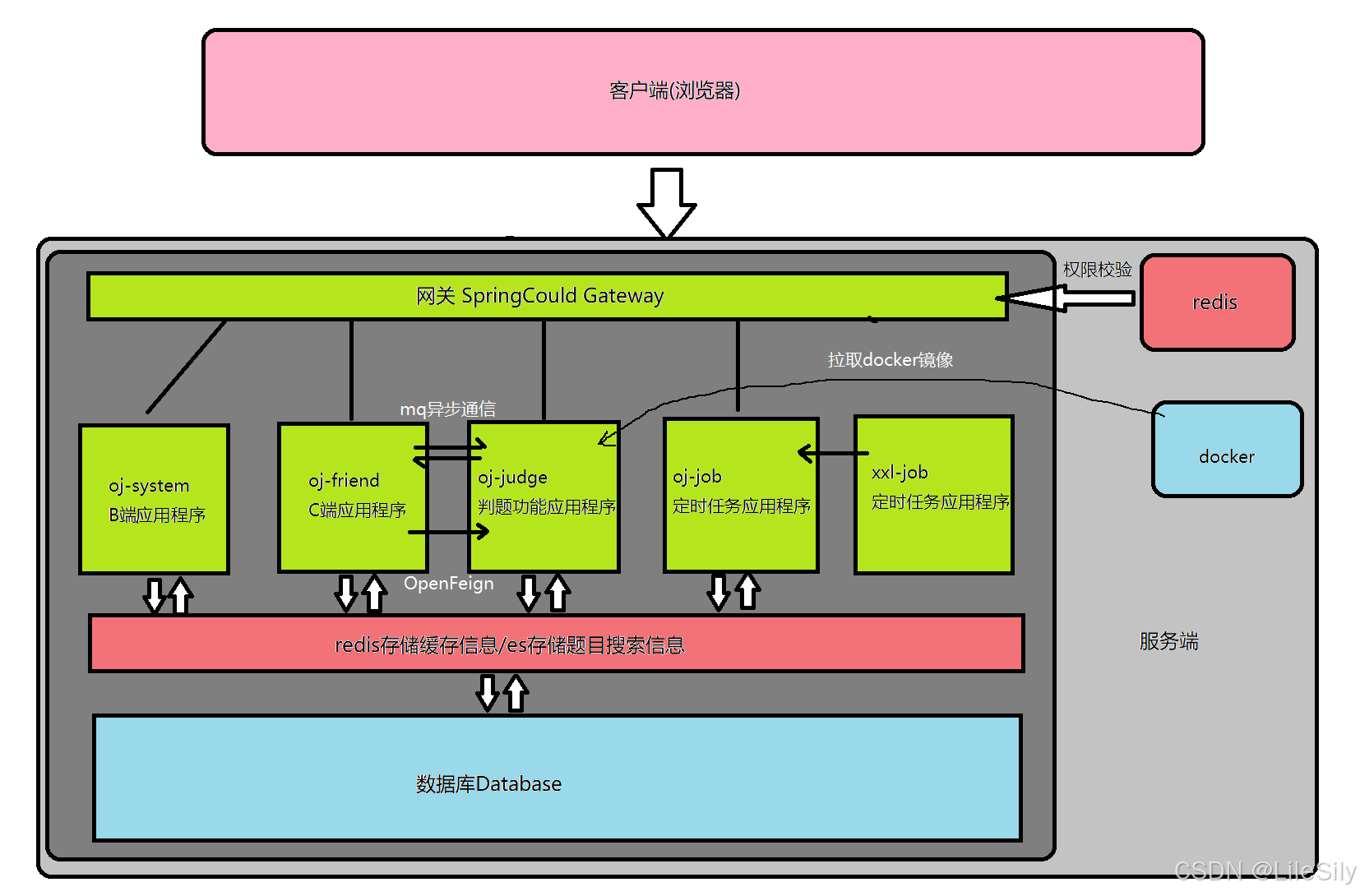
- 本项目是一个提供在线OJ刷题功能的微服务项目,该项目分为B端和C端,B端可以对题目,用户,竞赛进行管理,C端可供用户登录,刷题,参加竞赛使用.
- 在微服务架构上,采用SpringCould相关组件来完成项目架构设计.其中包含使用Nacos进行服务发现与配置管理,使用OpenFeign进行微服务之间的服务调用.采用SpringCould Gateway进行网关限制.
- 采用redis对用户,竞赛等相关信息进行保存,使用ElasticSearch对题目相关信息进行保存,方便C端进行题目搜索.
- 采用docker制造判题功能隔离沙箱,避免用户提交的代码对系统性能造成影响.
- 由于判题功能业务逻辑复杂且需要处理大量用户提交的代码,我们采用了RabbitMQ对消息进行异步处理与削峰处理.
- 集成阿里云短信服务,用来给c端用户登录时发送验证码.集成阿里云OSS对象存储服务,用来保存c端用户的头像.
- 采用MyBatis-Plus简化数据库CRUD操作.
项目大体架构设计如下:
1. JWT令牌解析技术
1.1 技术原理
JWT是一种令牌加密技术,他由三部分组成,头部,负载,签名.各个部分之间用.分割开.
Header.Payload.Signature
头部中包含令牌类型和加密算法两个信息
{"alg": "HS256","typ": "JWT"
}
负载中包含声明(claim),是关于实体(一般是用户)和其他数据的声明.简单来说就是实实在在保存数据的部分.
{"sub": "1234567890","name": "John Doe","admin": true,"iat": 1516239022
}
其次是签名,通过编码后的header,编码后的payload,一个密钥和header中的加密算法生成,用来校验消息在传递过程中是否有被修改.
工作流程如下:
- 用户登录,服务器验证权限是否正确.
- 如果正确,服务器生成JWT并返回给客户端.
- 客户端把JWT令牌保存在本地(通常保存在LocalStorage或者是cookie中).
- 客户端在后续的请求中都携带JWT令牌,一般保存在请求头中的
Authorization中. - 服务器校验JWT令牌,具体校验过程如下:
由于JWT令牌是由三部分组成的,服务器首先会校验是否有且仅有两个.,即三个部分是否都存在.由于头部是经过了Base64Url编码的,所以首先先对头部进行解码.解码之后得到头部信息,对头部信息进行解析,针对不安全的加密算法,如none,服务器会直接拒绝.
{"alg": "HS256", // 必须与服务器预期的算法一致"typ": "JWT" // 必须为"JWT"
}
接下来是最关键的一步,服务器会使用签名密钥对签名进行重新计算,并与令牌中的签名进行严格的比较.如果比较不同过,直接进行拒绝.
验证全部通过之后,服务器就可以针对payload中的信息进行解码,解码之后拿到声明(claim),即拿到了用户的详细信息.
1.2 项目应用
- 首先我们在管理员的登录功能中使用到了JWT令牌技术.
if (BCryptUtils.matchesPassword(password, sysUser.getPassword())) {return R.ok(tokenService.createToken(sysUser.getUserId(),secret, UserIdentity.ADMIN.getValue(), sysUser.getNickName(), null));
}
public String createToken(Long userId, String secret, Integer identity, String nickName, String headImage) {Map<String, Object> claims = new HashMap<>();String userKey = UUID.fastUUID().toString();claims.put(JwtConstants.LOGIN_USER_ID, userId);claims.put(JwtConstants.LOGIN_USER_KEY, userKey);String token = JwtUtils.createToken(claims, secret);String tokenKey = getTokenKey(userKey);LoginUser loginUser = new LoginUser();loginUser.setIdentity(identity);loginUser.setNickName(nickName);loginUser.setHeadImage(headImage);redisService.setCacheObject(tokenKey, loginUser, CacheConstants.EXP, TimeUnit.MINUTES);return token;
}
public static String createToken(Map<String, Object> claims, String secret) {String token = Jwts.builder().setClaims(claims).signWith(SignatureAlgorithm.HS512, secret).compact();return token;
}
在密码校验通过之后,我们首先正对claim进行构造,即payload进行构造,我们在claim中设置了用户的userId和UserKey.(注意,用户的一些详细信息并没有加载到payload中,而是保存到了Redis中).之后我们我们把claim保存到了JWT的payload中,即setClaims(claims),并使用了加密算法和密钥生成了JWT签名,即signWith(SignatureAlgorithm.HS512, secret).最终把JWT令牌返回给了前端.
- 在网关那里,我们对JWT令牌进行了校验,即处理网关中的白名单请求,其他的请求均需要用户携带JWT令牌来访问.网关的具体解析见前面 的博文.如果没有从令牌中校验除了claims,就直接在网关中返回一个错误信息.
try {claims = JwtUtils.parseToken(token, secret); //获取令牌中信息 解析payload中信息 存储着用户唯一标识信息if (claims == null) {//springcloud gateway 基于webfluxreturn unauthorizedResponse(exchange, "令牌已过期或验证不正确!");}
} catch (Exception e) {return unauthorizedResponse(exchange, "令牌已过期或验证不正确!");
}
在对token信息进行解析的时候,我们还是需要用到密钥重新生成签名,并与JWT中的签名进行严格的比对.对应代码中的是setSigningKey(secret).
public static Claims parseToken(String token, String secret) {return Jwts.parser().setSigningKey(secret).parseClaimsJws(token).getBody();
}
- 其次,在拦截器中,我们同样使用到了JWT令牌,首先是因为我们需要在当前的ThreadLocal中设置用户的信息,首先从使用密钥从token中解析出Claims信息
Claims claims = tokenService.getClaims(token, secret);,之后从Claim中把userId和userKey全部获取到.把这些信息保存到ThreadLocal中.
其次是因为,在用户的每一次请求之后,都需要对Redis中保存的用户userKey信息的过期时间进行延长.
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {String token = getToken(request); //请求头中获取tokenif (StrUtil.isEmpty(token)) {return true;}Claims claims = tokenService.getClaims(token, secret);Long userId = tokenService.getUserId(claims);String userKey = tokenService.getUserKey(claims);ThreadLocalUtil.set(Constants.USER_ID, userId);ThreadLocalUtil.set(Constants.USER_KEY, userKey);tokenService.extendToken(claims);return true;
}
当Redis中的UserKey数据剩余时间少于180min的时候,且获取到的UserKey不为空的时候,我们对其在Redis中的缓存进行延长.防止用户正在答题的过程中,发生了token过期,给用户带来不好的体验.
public void extendToken(Claims claims) {String userKey = getUserKey(claims);if (userKey == null) {return;}String tokenKey = getTokenKey(userKey);Long expire = redisService.getExpire(tokenKey, TimeUnit.MINUTES);if (expire != null && expire < CacheConstants.REFRESH_TIME) {redisService.expire(tokenKey, CacheConstants.EXP, TimeUnit.MINUTES);}
}
- 在c端用户进行登录的时候,也会使用到JWT令牌.在用户验证码校验通过之后,和B端一样,需要给前端返回一个令牌,把
UserKey和UserId构造进入Claim中,加入payload,使用签名密钥和加密算法生成签名之后把JWT令牌返回给前端.
@Override
public String codeLogin(String phone, String code) {checkCode(phone, code);User user = userMapper.selectOne(new LambdaQueryWrapper<User>().eq(User::getPhone, phone));if (user == null) { //新用户//注册逻辑user = new User();user.setPhone(phone);user.setStatus(UserStatus.Normal.getValue());user.setCreateBy(Constants.SYSTEM_USER_ID);userMapper.insert(user);}return tokenService.createToken(user.getUserId(), secret, UserIdentity.ORDINARY.getValue(), user.getNickName(), user.getHeadImage());
}
- 查询c端用户首页详细信息(昵称与头像)也会用到JWT.首先我们需要从JWT信息中把
userKey解析出来,即从claims中拿到userkey,之后拿着userKey去Redis中获取当前用户的详细信息,以便展示给前端,这就是我们在用户登录那里我们即需要把生成的token返回给前端,又要把用户的详细信息保存在Redis中.
@Override
public R<LoginUserVO> info(String token) {if (StrUtil.isNotEmpty(token) && token.startsWith(HttpConstants.PREFIX)) {token = token.replaceFirst(HttpConstants.PREFIX, StrUtil.EMPTY);}LoginUser loginUser = tokenService.getLoginUser(token, secret);if (loginUser == null) {return R.fail();}LoginUserVO loginUserVO = new LoginUserVO();loginUserVO.setNickName(loginUser.getNickName());if (StrUtil.isNotEmpty(loginUser.getHeadImage())) {loginUserVO.setHeadImage(downloadUrl + loginUser.getHeadImage());}return R.ok(loginUserVO);
}
public LoginUser getLoginUser(String token, String secret) {String userKey = getUserKey(token, secret);if (userKey == null) {return null;}return redisService.getCacheObject(getTokenKey(userKey), LoginUser.class);
}
2. 密码加密技术(哈希加密技术)
密码是用户最敏感的信息,所以我们必须针对密码进行加密,在当前项目中,我们使用BCrypt加密技术对用户密码进行加密.
2.1 技术原理
BCrypt 是一种专门为密码存储设计的自适应哈希算法,被广泛认为是目前最安全的密码哈希方案之一.
这种算法中有这几个核心的特性来保证密码的安全性.
- 内置盐值: 自动生成随机的盐值包含进入哈希的结果中.
- 抗彩虹表攻击: 内置盐值和自适应特性使其抵抗预先计算的攻击.
- 慢哈希设置: 故意设计为慢哈希计算,增加其破解的成本.
- 工作因子: 通过工作因子(work factor)控制计算强度,可动态配置计算的成本.
经典的格式如下:
$2a$10$N9qo8uLOickgx2ZMRZoMy.Mrq/b1SSFQZJxRKG/tVrW/uQOPSJ96G
$2a$ - 算法标识符
10$ - 工作因子(2^10次迭代)
N9qo8uLOickgx2ZMRZoMy. - 22字符的盐值
Mrq/b1SSFQZJxRKG/tVrW/uQOPSJ96G- 31字符的哈希值
2.2 项目应用
针对这种加密的算法,我专门设置了一个工具类BCryptUtils,encryptPassword用于对密码进行哈希加密,把加密之后的密码返回去.matchesPassword用来匹配用户输入的密码和数据库获取到的加密后的密码.我们首先需要对用户输入的密码进行加密之后再与数据库中的数据进行对比,这样操作是由于哈希算法是一种不可逆的算法,我们无法对已经加密之后的数据再次进行解析得到明文.
public class BCryptUtils {public static String encryptPassword(String password) {BCryptPasswordEncoder passwordEncoder = new BCryptPasswordEncoder();return passwordEncoder.encode(password);}public static boolean matchesPassword(String rawPassword, String encodedPassword) {BCryptPasswordEncoder passwordEncoder = new BCryptPasswordEncoder();return passwordEncoder.matches(rawPassword, encodedPassword);}
}
在新增管理员用户的时候,我们在向数据库中保存用户密码的时候,针对用户设置的密码进行了加密.
SysUser sysUser = new SysUser();
sysUser.setUserAccount(sysUserSaveDTO.getUserAccount());
sysUser.setPassword(BCryptUtils.encryptPassword(sysUserSaveDTO.getPassword()));
sysUser.setCreateBy(Constants.SYSTEM_USER_ID);
return sysUserMapper.insert(sysUser);
在管理员登录功能中,我们对用户输入的密码进行了哈希加密之后,与数据库中加密之后的密码进行对比,即可判断用户输入的密码是否正确.
if (BCryptUtils.matchesPassword(password, sysUser.getPassword())) {return R.ok(tokenService.createToken(sysUser.getUserId(),secret, UserIdentity.ADMIN.getValue(), sysUser.getNickName(), null));
}
3. 雪花算法
3.1 技术原理
雪花算法是一种专门用于分布式系统中生成全局唯一有序的id.雪花算法是一个64位长整型的数据,具体由一下的部分组成:
0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
- 一位符号位,始终为0,保证为正数.
- 41位时间戳,精确到毫秒,每一毫秒生成的时间戳都不同
- 5位数据中心id,支持最多32个数据中心.主要用来标志不同的集群.
- 5为机器id,每台服务器生成的id都是不同的.
- 12位序列号,用来解决同一毫秒内需要生成多个ID时的序号标识.
为什么不使用自增id和UUID?
自增id虽然简单易用,但是在分布式系统中存在明显的缺陷:
- 扩展性不强:分库分表的时候很难保证全局id的唯一性
- 安全性问题:黑客容易通过id推断业务量.如果id是连续的话,攻击者可能会预测到将来的id值以插入一些恶意数据.
- 删除和插入操作: 如果表中存在大量的删除和插入操作,可能会导致id的值不连续,造成存储空间的浪费.
- 性能能问题: 在高并发的场景中,可能会导致性能瓶颈,数据库在每次插入数据的时候都需要找到下一个可用的自增id,可能会增加写操作的延迟.
为什么不使用UUID?
- 存储空间: UUID存储会占用更大的空间,会增加数据库的存储需求,这可能会造成性能瓶颈.
- 索引新能: 由于UUID相对较大,使用UUID作为主键的时候会导致索引变大,从而影响查询性能.
3.2 项目应用
在为数据库中插入数据的时候,在插入id这一项的时候,我们使用了MyBatis-Plus中提供的生成雪花算法的方法.我们使用@TableId(value = "USER_ID", type = IdType.ASSIGN_ID)注解直接对id使用雪花算法进行插入.其中IdType.ASSIGN_ID就表示的是雪花算法.
@Getter
@Setter
@TableName("tb_user")
public class User extends BaseEntity {@JsonSerialize(using = ToStringSerializer.class)@TableId(value = "USER_ID", type = IdType.ASSIGN_ID)private Long userId;private String nickName;private String headImage;private Integer sex;private String phone;private String code;private String email;private String wechat;private String schoolName;private String majorName;private String introduce;private Integer status;
}
4. 统一返回结果
- 我们之所以要定义统一返回结果,是为了前端在处理响应的时候方便处理,这样前端就不需要正对不同的接口编写特殊的处理逻辑,我们使用
R<T>定义一个统一返回结果.其中包含响应码code,使用不同的响应码来表示不同的结果.包含状态码说明信息msg,用来说明当前状态码表示的是什么状态.还包含需要给前端返回的必要的数据data.其中还包含了一些静态的方法,针对一些常用的成功或者是失败的返回结果进行了封装.
@Getter
@Setter
public class R<T> {private int code;private String msg;private T data;public static <T> R<T> ok() {return assembleResult(null, ResultCode.SUCCESS);}public static <T> R<T> ok(T data) {return assembleResult(data, ResultCode.SUCCESS);}public static <T> R<T> fail() {return assembleResult(null, ResultCode.FAILED);}public static <T> R<T> fail(int code, String msg) {return assembleResult(code, msg, null);}public static <T> R<T> fail(ResultCode resultCode) {return assembleResult(null, resultCode);}private static <T> R<T> assembleResult(T data, ResultCode resultCode) {R<T> r = new R<>();r.setCode(resultCode.getCode());r.setData(data);r.setMsg(resultCode.getMsg());return r;}private static <T> R<T> assembleResult(int code, String msg, T data) {R<T> r = new R<>();r.setCode(code);r.setData(data);r.setMsg(msg);return r;}
}
- 其次,我们在查询某种列表的时候,我们会使用分页显示,我们针对这种分页显示也做出了统一返回结果的处理.
其中包含数据总数total,主要通过PageInfo去获取,分页查询之后的List,通过为PageHelper设置需要查询的页数和一页中的数据数量即可去数据中查询到对应的数据.当然其中还是包含和R相同的信息,code和msg.其中封装了两个现成的静态的方法,当我们查询到的列表为空的时候,我们就使用empty()进行返回,当我们查询到的列表不为空的时候,我们就使用success(List<?> list,long total)方法进行返回,同时设置需要返回的list和total.
@Getter
@Setter
public class TableDataInfo {private long total;private List<?> rows;private int code;private String msg;public TableDataInfo() {}//未查出任何数据时调用public static TableDataInfo empty() {TableDataInfo rspData = new TableDataInfo();rspData.setCode(ResultCode.SUCCESS.getCode());rspData.setRows(new ArrayList<>());rspData.setMsg(ResultCode.SUCCESS.getMsg());rspData.setTotal(0);return rspData;}//查出数据时调用public static TableDataInfo success(List<?> list,long total) {TableDataInfo rspData = new TableDataInfo();rspData.setCode(ResultCode.SUCCESS.getCode());rspData.setRows(list);rspData.setMsg(ResultCode.SUCCESS.getMsg());rspData.setTotal(total);return rspData;}
}
- 我们对返回结果
R和TableDataInfo进行了进一步的封装,我们在使用MyBatis-Plus中提供的默认的方法修改数据库中的数据,方法会默认返回一个整数,用来表示数据库的改变行数,所以我们封装了toR(int rows)方法,如果数据库返回的值<=0,则证明修改失败,直接返回一个R.fail(),否则返回R.ok().其次Service层还会返回一个boolean类型的数据,表示执行结果的成功或者失败,我们在可以直接在Controller层调用toR(boolean result)方法.针对TableDataInfo封装,我们使用了getTableDataInfo(List<?> list)方法进行了封装,我们直接传入list即可,针对total的计算,我们在这个方法中直接使用了new PageInfo<>(list).getTotal()的方式对其进行了设置,避免了调用方再次进行多次设置.
public class BaseController {public R<Void> toR(int rows) {return rows > 0 ? R.ok() : R.fail();}public R<Void> toR(boolean result) {return result ? R.ok() : R.fail();}public TableDataInfo getTableDataInfo(List<?> list) {//list == null || list.isEmpty()if (CollectionUtil.isEmpty(list)) {return TableDataInfo.empty();}return TableDataInfo.success(list, new PageInfo<>(list).getTotal());}
}
5. 统一异常处理
5.1 技术原理
见Spring专栏"统一功能处理"篇.
5.2 项目应用
统一异常处理使用的是@ControllerAdvice +@ExceptionHandler来实现的,@ControllerAdvice表示控制器通知类,@ExceptionHandler 是异常处理器,可以通过在@ExceptionHandler后面加上参数,指定该类处理异常的类型.
首先我们对HttpRequestMethodNotSupportedException异常进行了处理,即请求方法错误,该接口是使用GetMapping注解修饰的,则只可以接收get请求,不可以接收其他的请求.其次是处理我们的自定义异常ServiceException,即在我们的业务逻辑过程中出现异常的时候会进行统一的处理.其次是BindException即参数校验的错误,比如我们在一个参数上加上了@Validated注解(一般是DTO对象),当参数传入不合法的时候,就会统一处理异常.然后是兜底的两个异常RuntimeException和Exception,当在异常统一处理中没有查询到对应的异常之后,我们就会向父类查询,对没有对应异常处理的异常,最后可能就会打到RuntimeException和Exception上.
@RestControllerAdvice
@Slf4j
public class GlobalExceptionHandler {@ExceptionHandler(HttpRequestMethodNotSupportedException.class)public R<?> handleHttpRequestMethodNotSupported(HttpRequestMethodNotSupportedException e,HttpServletRequest request) {String requestURI = request.getRequestURI();log.error("请求地址'{}',不支持'{}'请求", requestURI, e.getMethod());return R.fail(ResultCode.ERROR);}@ExceptionHandler(ServiceException.class)public R<?> handleServiceException(ServiceException e, HttpServletRequest request) {String requestURI = request.getRequestURI();ResultCode resultCode = e.getResultCode();log.error("请求地址'{}',发生业务异常: {}", requestURI, resultCode.getMsg(), e);return R.fail(resultCode);}@ExceptionHandler(BindException.class)public R<Void> handleBindException(BindException e) {log.error(e.getMessage());String message = join(e.getAllErrors(),DefaultMessageSourceResolvable::getDefaultMessage, ", ");return R.fail(ResultCode.FAILED_PARAMS_VALIDATE.getCode(), message);}private <E> String join(Collection<E> collection, Function<E, String>function, CharSequence delimiter) {if (CollUtil.isEmpty(collection)) {return StrUtil.EMPTY;}return collection.stream().map(function).filter(Objects::nonNull).collect(Collectors.joining(delimiter));}@ExceptionHandler(RuntimeException.class)public R<?> handleRuntimeException(RuntimeException e, HttpServletRequest request) {String requestURI = request.getRequestURI();log.error("请求地址'{}',发生运行时异常.", requestURI, e);return R.fail(ResultCode.ERROR);}@ExceptionHandler(Exception.class)public R<?> handleException(Exception e, HttpServletRequest request) {String requestURI = request.getRequestURI();log.error("请求地址'{}',发生异常.", requestURI, e);return R.fail(ResultCode.ERROR);}
}
6. 拦截器
6.1 技术原理
见Spring专栏"统一功能处理"篇
6.2 项目应用
想要配置一个拦截器,我们需要实现HandlerInterceptor类,实现其中的preHandle方法,即在请求到达接口之前进行统一功能处理,包括在ThreadLocal中设置用户信息,为什么不在网关哪里为ThreadLocal设置用户信息呢,因为网关与其他的服务属于不同的进程,不同的进程一定属于不同的线程,ThreadLocal中的变量不共享,所以我们选择在拦截器中设置,拦截器与网关不同的是,那个服务调用拦截器,拦截器就属于哪个服务,所以ThreadLocal中的变量即可共享.同时在拦截器中,我们需要延长当前用户在Redis中存储的用户信息,即服务器用来校验用户token的信息.
@Component
public class TokenInterceptor implements HandlerInterceptor {@Autowiredprivate TokenService tokenService;@Value("${jwt.secret}")private String secret; //从哪个服务的配置文件中读取,取决于这个bean对象交给了哪个服务的spring容器进行管理。@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {String token = getToken(request); //请求头中获取tokenif (StrUtil.isEmpty(token)) {return true;}Claims claims = tokenService.getClaims(token, secret);Long userId = tokenService.getUserId(claims);String userKey = tokenService.getUserKey(claims);ThreadLocalUtil.set(Constants.USER_ID, userId);ThreadLocalUtil.set(Constants.USER_KEY, userKey);tokenService.extendToken(claims);return true;}@Overridepublic void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex)throws Exception {ThreadLocalUtil.remove();}private String getToken(HttpServletRequest request) {String token = request.getHeader(HttpConstants.AUTHENTICATION);if (StrUtil.isNotEmpty(token) && token.startsWith(HttpConstants.PREFIX)) {token = token.replaceFirst(HttpConstants.PREFIX, "");}return token;}
}
7. ElasticSearch
7.1 技术原理
ES是一个开源的分布式搜索引擎,其核心原理是倒排索引: 将文档的内容拆分为词项,建立"词项–>文档"的映射.即建立词项与主键id的映射关系.
文档1: "Elasticsearch is fast"
文档2: "Elasticsearch is scalable"倒排索引:
Term | Doc IDs
---------------------
elasticsearch | [1, 2]
fast | [1]
scalable | [2]
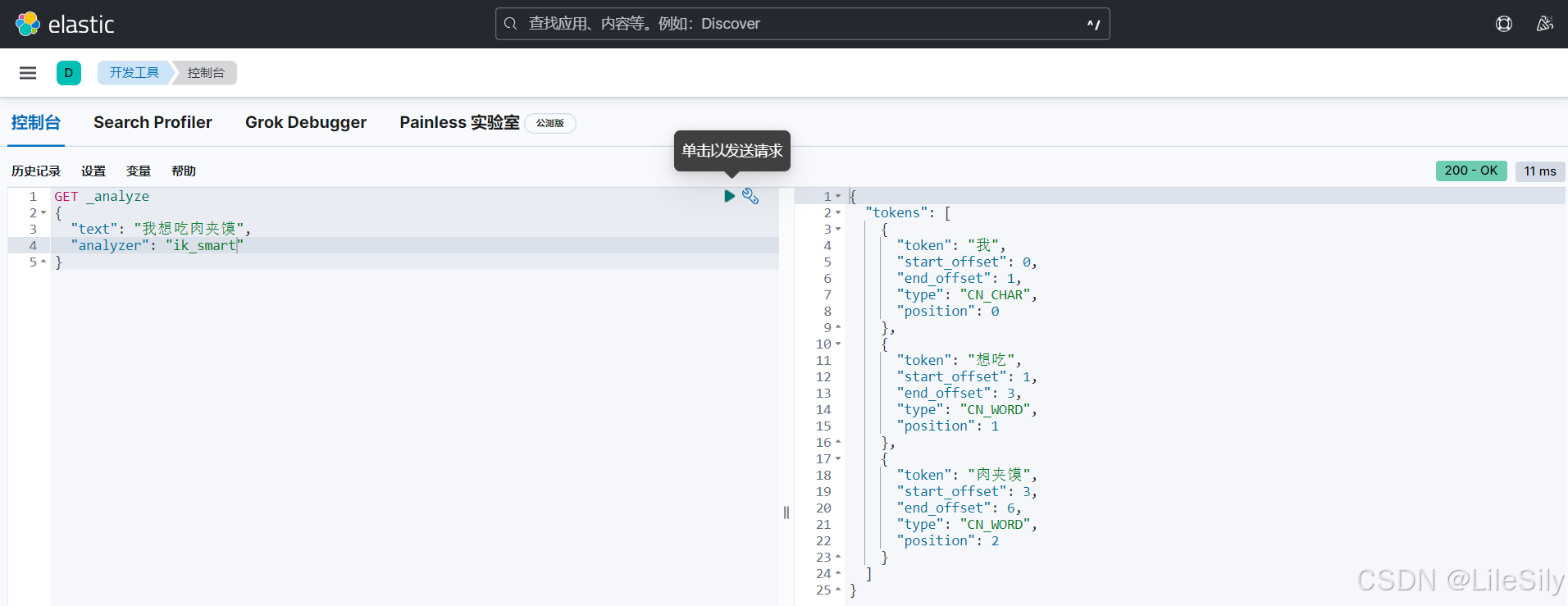
其中,分词的时候会使用到分词器,根据前面学习的倒排索引的概念,倒排索引是按照文档中的关键词汇来组织的,索引的键是文档集合中出现过的每个独特的词汇或者是关键词,那es是怎么讲这些词汇提取出来的呢?这其实就是es中的分词器起着作用,它负责将文本切分成一个个有意义的词语,以建立索引或进行搜索和分析.我们业务中常用的是中文分词器,es的默认中文分词器会把每一个字看做是一个词,这显然不符合用户的使用习惯.所以我们需要安装ik分词器来将中文内容分解成更加符合用户使用的关键词.
ik分词器中,分为最少切分,即ik_smart算法,和最细粒度切分,即ik_max_word,他们两个的分词方法有一定的区别.

7.2 项目应用
由于c端用户在查询题目的时候,有可能带有一定的搜索条件,为了加快c端搜索题目的速度,给用户已最好的体验,我们引入了ElasticSearch,当我们在为数据库中添加题目的时候,我们需要把题目同时加入ES中.我们在添加的时候,使用的是questionRepository提供的 默认的save方法,与MyBatis-Plus类似,questionRepository也是通过继承ElasticsearchRepository类的方式来把这些默认的方法都继承下来的.还是与MyBatis-Plus类似,在其中指定我们要存储的数据类型QuestionES,Long表示的是ES中主键字段的数据类型.在B端,不仅仅是添加题目的时候需要往es中保存数据,包括对题目删除或者是修改的时候,都需要修改es中的数据.
QuestionES questionES = new QuestionES();
BeanUtil.copyProperties(question, questionES);
questionRepository.save(questionES);
questionCacheManager.addCache(question.getQuestionId());
@Repository
public interface QuestionRepository extends ElasticsearchRepository<QuestionES, Long> {
}
包括在c端用户进行搜索题目的时候,不管是统计题目总数,还是搜索所有的题目,还是按照难度搜索,还是按照题目标题搜索,还是两个限制条件都存在,都需要经过es来搜索.如果从es中获取数据的时候,发现总数小于等于0或者是没有当前题目的信息,我们就需要把题目从数据库中先查出来,之后再刷新到es中.
long count = questionRepository.count();
if (count <= 0) {refreshQuestion();
}
Question question = questionMapper.selectById(questionId);
if (question == null) {return null;
}
refreshQuestion();
private void refreshQuestion() {List<Question> questionList = questionMapper.selectList(new LambdaQueryWrapper<Question>());if (CollectionUtil.isEmpty(questionList)) {return;}List<QuestionES> questionESList = BeanUtil.copyToList(questionList, QuestionES.class);questionRepository.saveAll(questionESList);
}
if (difficulty == null && StrUtil.isEmpty(keyword)) {questionESPage = questionRepository.findAll(pageable);
} else if (StrUtil.isEmpty(keyword)) {questionESPage = questionRepository.findQuestionByDifficulty(difficulty, pageable);
} else if (difficulty == null) {questionESPage = questionRepository.findByTitleOrContent(keyword, keyword, pageable);
} else {questionESPage = questionRepository.findByTitleOrContentAndDifficulty(keyword, keyword, difficulty, pageable);
}
@Repository
public interface QuestionRepository extends ElasticsearchRepository<QuestionES, Long> {Page<QuestionES> findQuestionByDifficulty(Integer difficulty, Pageable pageable);//select * from tb_question where (title like '%aaa%' or content like '%bbb%') and difficulty = 1@Query("{\"bool\": {\"should\": [{ \"match\": { \"title\": \"?0\" } }, { \"match\": { \"content\": \"?1\" } }], \"minimum_should_match\": 1, \"must\": [{\"term\": {\"difficulty\": \"?2\"}}]}}")Page<QuestionES> findByTitleOrContentAndDifficulty(String keywordTitle, String keywordContent,Integer difficulty, Pageable pageable);@Query("{\"bool\": {\"should\": [{ \"match\": { \"title\": \"?0\" } }, { \"match\": { \"content\": \"?1\" } }], \"minimum_should_match\": 1}}")Page<QuestionES> findByTitleOrContent(String keywordTitle, String keywordContent, Pageable pageable);
}
包括我们在用户提交功能中,需要构造一个JudgeSubmitDTO请求参数,去把这个参数提交给判题代码沙箱的时候,这个请求参数中包含着题目的详细信息,想要获取到题目的详细信息,我们还是需要从es中根据题目的id去查询题目的信息,如果题目的信息不存在的话,我们则需要从数据库中去查询该题目的详细信息,之后把数据同步给es即可.
Long questionId = submitDTO.getQuestionId();
QuestionES questionES = questionRepository.findById(questionId).orElse(null);
JudgeSubmitDTO judgeSubmitDTO = new JudgeSubmitDTO();
if (questionES != null) {BeanUtil.copyProperties(questionES, judgeSubmitDTO);
} else {Question question = questionMapper.selectById(questionId);BeanUtil.copyProperties(question, judgeSubmitDTO);questionES = new QuestionES();BeanUtil.copyProperties(question, questionES);questionRepository.save(questionES);
}
8. Redis缓存
凡是和c端功能挂钩的,我们大概率都会使用到缓存,加快访问的速度,以提高用户的体验感.
8.1 用户层面
- 首先就是我们在前面JWT部分提到的存储用户token的校验信息,即
userKey,这里不再赘述. - 存储c端用户的详细信息,由于我们在个人中心或者是主页都可能会访问到c端用户的信息,所以需要在缓存中存储用户的信息.获取用户信息的时候,还是首先从缓存中获取用户信息,如果缓存中不存在,就从数据库中查询,查询之后同步到Redis中.
@Component
public class UserCacheManager {@Autowiredprivate RedisService redisService;@Autowiredprivate UserMapper userMapper;public UserVO getUserById(Long userId) {String userKey = getUserKey(userId);UserVO userVO = redisService.getCacheObject(userKey, UserVO.class);if (userVO != null) {//将缓存延长10minredisService.expire(userKey, CacheConstants.USER_EXP, TimeUnit.MINUTES);return userVO;}User user = userMapper.selectOne(new LambdaQueryWrapper<User>().select(User::getUserId,User::getNickName,User::getHeadImage,User::getSex,User::getEmail,User::getPhone,User::getWechat,User::getIntroduce,User::getSchoolName,User::getMajorName,User::getStatus).eq(User::getUserId, userId));if (user == null) {return null;}refreshUser(user);userVO = new UserVO();BeanUtil.copyProperties(user, userVO);return userVO;}public void refreshUser(User user) {//刷新用户缓存String userKey = getUserKey(user.getUserId());redisService.setCacheObject(userKey, user);//设置用户缓存有效期为10分钟redisService.expire(userKey, CacheConstants.USER_EXP, TimeUnit.MINUTES);}//u:d:用户idprivate String getUserKey(Long userId) {return CacheConstants.USER_DETAIL + userId;}
}
- 在B端中我们需要对用户的状态进行修改,即对用户进行拉黑操作或者是解禁操作,我们也需要首先修改Redis中的数据,之后再修改数据库中的数据.
@Component
public class UserCacheManager {@Autowiredprivate RedisService redisService;public void updateStatus(Long userId, Integer status) {//刷新用户缓存String userKey = getUserKey(userId);User user = redisService.getCacheObject(userKey, User.class);if (user == null) {return;}user.setStatus(status);redisService.setCacheObject(userKey, user);//设置用户缓存有效期为10分钟redisService.expire(userKey, CacheConstants.USER_EXP, TimeUnit.MINUTES);}//u:d:用户idprivate String getUserKey(Long userId) {return CacheConstants.USER_DETAIL + userId;}
}
- 在一个c端的用户想要对头像进行修改的时候,为了保证某些恶意用户浪费系统资源,我们对每个用户单日上传头像的此处做了一定的限制,把每个用户上传头像的次数保存在Redis中,在上传头像之前先去Redis中查询当前用户上传头像的次数,如果超过了一定的次数限制,那么直接限制,如果没有超过,直接对Redis中的当前缓存的Value++.同时在每天的凌晨1点的时候对缓存进行刷新.
private void checkUploadCount() {Long userId = ThreadLocalUtil.get(Constants.USER_ID, Long.class);Long times = redisService.getCacheMapValue(CacheConstants.USER_UPLOAD_TIMES_KEY, String.valueOf(userId), Long.class);if (times != null && times >= maxTime) {throw new ServiceException(ResultCode.FAILED_FILE_UPLOAD_TIME_LIMIT);}redisService.incrementHashValue(CacheConstants.USER_UPLOAD_TIMES_KEY, String.valueOf(userId), 1);if (times == null || times == 0) {long seconds = ChronoUnit.SECONDS.between(LocalDateTime.now(),LocalDateTime.now().plusDays(1).withHour(0).withMinute(0).withSecond(0).withNano(0));redisService.expire(CacheConstants.USER_UPLOAD_TIMES_KEY, seconds, TimeUnit.SECONDS);}
}
- 在发送验证码的时候,和上面的OSS对象存储服务一样,我们还是先要对当前用户发送短信的次数进行限制,防止一些用户恶意消耗系统资源,其次我们需要限制当前用户在一定时间之内发送验证码的次数,在1分钟之内不可以重复发送验证码,当发送一个验证码之后,我们需要在缓存中设置一个1分钟有效时间的key,在再次想发送验证码的时候,我们需要去缓存中查询当前key是否已经过期.当然在验证码成功生成之后,需要在Redis中存储验证码,以便用户输入验证码之后,与Redis中的验证码进行校验比对.
@Override
public boolean sendCode(UserDTO userDTO) {if (!checkPhone(userDTO.getPhone())) {throw new ServiceException(ResultCode.FAILED_USER_PHONE);}String phoneCodeKey = getPhoneCodeKey(userDTO.getPhone());Long expire = redisService.getExpire(phoneCodeKey, TimeUnit.SECONDS);if (expire != null && (phoneCodeExpiration * 60 - expire) < 60 ){throw new ServiceException(ResultCode.FAILED_FREQUENT);}String codeTimeKey = getCodeTimeKey(userDTO.getPhone());Long sendTimes = redisService.getCacheObject(codeTimeKey, Long.class);if (sendTimes != null && sendTimes >= sendLimit) {throw new ServiceException(ResultCode.FAILED_TIME_LIMIT);}String code = isSend ? RandomUtil.randomNumbers(6) : Constants.DEFAULT_CODE;//存储到redis 数据结构:String key:p:c:手机号 value :coderedisService.setCacheObject(phoneCodeKey, code, phoneCodeExpiration, TimeUnit.MINUTES);if (isSend) {boolean sendMobileCode = aliSmsService.sendMobileCode(userDTO.getPhone(), code);if (!sendMobileCode) {throw new ServiceException(ResultCode.FAILED_SEND_CODE);}}redisService.increment(codeTimeKey);if (sendTimes == null) { //说明是当天第一次发起获取验证码的请求long seconds = ChronoUnit.SECONDS.between(LocalDateTime.now(),LocalDateTime.now().plusDays(1).withHour(0).withMinute(0).withSecond(0).withNano(0));redisService.expire(codeTimeKey, seconds, TimeUnit.SECONDS);}return true;
}
8.2 题目层面
我们除了在之前提到的es中保存题目的信息之外,我们还需要在缓存中保存题目的id列表,这是由于我们在数据库中保存题目的时候,我们使用的是雪花算法,不可以直接通过id来获取到上一题或者是下一题的id.所以我们需要在Redis中保存一套题目的列表,通过Redis的下标来获取到上一题或者是下一题的id.包括用户在日常刷题中的题目列表和在竞赛中做题的题目列表,都是使用该逻辑完成的.
@Component
public class QuestionCacheManager {@Autowiredprivate RedisService redisService;public void addCache(Long questionId) {redisService.leftPushForList(CacheConstants.QUESTION_LIST, questionId);}public void deleteCache(Long questionId) {redisService.removeForList(CacheConstants.QUESTION_LIST, questionId);}
}
我们在获取上一题或者是下一题的id的时候,可以通过preQuestion方法和nextQuestion方法来获取到,拿到题目id即可去es中或者是数据库中查询当前题目的详细信息.(再次请求question/detail接口)
@Component
public class QuestionCacheManager {@Autowiredprivate RedisService redisService;@Autowiredprivate QuestionMapper questionMapper;public Long getListSize() {return redisService.getListSize(CacheConstants.QUESTION_LIST);}public void refreshCache() {List<Question> questionList = questionMapper.selectList(new LambdaQueryWrapper<Question>().select(Question::getQuestionId).orderByDesc(Question::getCreateTime));if (CollectionUtil.isEmpty(questionList)) {return;}List<Long> questionIdList = questionList.stream().map(Question::getQuestionId).toList();redisService.rightPushAll(CacheConstants.QUESTION_LIST, questionIdList);}public Long preQuestion(Long questionId) {
// List<Long> list = redisService.getCacheListByRange(CacheConstants.QUESTION_LIST, 0, -1, Long.class);Long index = redisService.indexOfForList(CacheConstants.QUESTION_LIST, questionId);if (index == 0) {throw new ServiceException(ResultCode.FAILED_FIRST_QUESTION);}return redisService.indexForList(CacheConstants.QUESTION_LIST, index - 1, Long.class);}public Long nextQuestion(Long questionId) {Long index = redisService.indexOfForList(CacheConstants.QUESTION_LIST, questionId);long lastIndex = getListSize() - 1;if (index == lastIndex) {throw new ServiceException(ResultCode.FAILED_LAST_QUESTION);}return redisService.indexForList(CacheConstants.QUESTION_LIST, index + 1, Long.class);}
}
8.3 竞赛层面
- 由于我们也需要在c端去展示竞赛相关的信息,我们需要在Redis中维护一个已经发布的竞赛id的列表和已经发布的竞赛的详细信息.c端查询竞赛信息的时候,包括查询历史竞赛列表,查询未完赛的竞赛列表,查询指定用户的报名的竞赛,都会涉及到竞赛的查询.此外,针对缓存中的未完赛的竞赛和历史竞赛,需要使用xxl-job在每天的1点钟进行更新,把结束时间超过当前时间的竞赛放到历史竞赛中,并把重新创建的历史竞赛和未完善的竞赛刷新到缓存中.
@Component
public class ExamCacheManager {@Autowiredprivate RedisService redisService;public void addCache(Exam exam) {redisService.leftPushForList(getExamListKey(), exam.getExamId());redisService.setCacheObject(getDetailKey(exam.getExamId()), exam);}public void deleteCache(Long examId) {redisService.removeForList(getExamListKey(), examId);redisService.deleteObject(getDetailKey(examId));redisService.deleteObject(getExamQuestionListKey(examId));}private String getExamListKey() {return CacheConstants.EXAM_UNFINISHED_LIST;}private String getDetailKey(Long examId) {return CacheConstants.EXAM_DETAIL + examId;}private String getExamQuestionListKey(Long examId) {return CacheConstants.EXAM_QUESTION_LIST + examId;}
}
- 由于c端还会涉及到竞赛的排名查询信息,我们还保存了竞赛的排名信息.指定好竞赛id之后,就可以针对用户的排名在缓存中进行分页查询功能.在查询排名的时候,如果缓存中没有对应竞赛排名的数据的时候,我们还是先需要从数据库中查询竞赛排名的相关信息,再同步到Redis中.
public List<ExamRankVO> getExamRankList(ExamRankDTO examRankDTO) {int start = (examRankDTO.getPageNum() - 1) * examRankDTO.getPageSize();int end = start + examRankDTO.getPageSize() - 1; //下标需要 -1return redisService.getCacheListByRange(getExamRankListKey(examRankDTO.getExamId()), start, end, ExamRankVO.class);}
public void refreshExamRankCache(Long examId) {List<ExamRankVO> examRankVOList = userExamMapper.selectExamRankList(examId);if (CollectionUtil.isEmpty(examRankVOList)) {return;}redisService.rightPushAll(getExamRankListKey(examId), examRankVOList);
}
8.4 站内信层面
和上面的竞赛功能一样,我们依然需要在Redis中保存当前用户的站内信id列表和站内性的详细信息.获取的时候先从Redis中获取.
public void refreshCache(Long userId) {List<MessageTextVO> messageTextVOList = messageTextMapper.selectUserMsgList(userId);if (CollectionUtil.isEmpty(messageTextVOList)) {return;}List<Long> textIdList = messageTextVOList.stream().map(MessageTextVO::getTextId).toList();String userMsgListKey = getUserMsgListKey(userId);redisService.rightPushAll(userMsgListKey, textIdList);Map<String, MessageTextVO> messageTextVOMap = new HashMap<>();for (MessageTextVO messageTextVO : messageTextVOList) {messageTextVOMap.put(getMsgDetailKey(messageTextVO.getTextId()), messageTextVO);}redisService.multiSet(messageTextVOMap);
}
9. Spring AOP
9.1 技术原理
见Spring专栏"Spring AOP"博文.
9.2 项目应用
如果管理端对c端的用户进行了拉黑,我们需要使用Spring AOP对用户的行为进行一些限制,我们使用@Aspect指定该类是一个切面类,通过before(JoinPoint point)方法指定当前方法是在到达连接点之前就要执行,在该方法中,我们获取到用户的状态之后,对他的状态进行判断,如果是拉黑状态,那么我们直接抛出异常,对用户的行为进行一些限制.在切点的地方,我们的切点表达式采用的是注解的方式,即加上该注解的方法都要经过该切面.在此项目中,我们对用户的报名功能进行了功能限制.即被拉黑的用户不可以报名竞赛.
@Aspect
@Component
public class UserStatusCheckAspect {@Autowiredprivate UserCacheManager userCacheManager;@Before(value = "@annotation(com.bite.friend.aspect.CheckUserStatus)")public void before(JoinPoint point){Long userId = ThreadLocalUtil.get(Constants.USER_ID, Long.class);UserVO user = userCacheManager.getUserById(userId);if (user == null) {throw new ServiceException(ResultCode.FAILED_USER_NOT_EXISTS);}if (Objects.equals(user.getStatus(), Constants.FALSE)) {throw new ServiceException(ResultCode.FAILED_USER_BANNED);}}
}
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface CheckUserStatus {}
@CheckUserStatus
@PostMapping("/enter")
public R<Void> enter(@RequestHeader(HttpConstants.AUTHENTICATION) String token, @RequestBody ExamDTO examDTO) {return toR(userExamService.enter(token, examDTO.getExamId()));
}