C++ KMP算法
一个人能走的多远 不在于他在顺境走的多快 而在于 他在逆境中多久能找到曾经的自己
-----KMP
1.匹配字符串
问题:
s1="mississippi"(主串) m个数据
s2="issip"(子串 ) n个数据
我怎么才确认在s1中是否存在s2呢?
当然我们一眼可以看出来 那计算机怎么办?
暴力方法:我们首先在主串中找到 和子串首字符相同的字符
(标红的位置表示指针指向的位置!)
s1="mississippi" ( i为指针指向的位置 该指针设为ptr1)
s2="issip"" (i为指针指向的位置 该指针设为ptr2)
然后我们ptr1 ptr2 同时走 会出现三种情况
(1) 直到子串全部遍历完 ptr1和ptr2指向的都完全相同 说明就找到了
(2)在遍历过程中 ptr1和ptr2指向的内容不同 这说明我们没有找到 要重新再开始找!
(3)ptr1把主串遍历完 子串没遍历完 这也就没找到!
比如上面这个例子 ptr1 和 ptr2同时走 遇到的就是第二种情况!
s1="mississippi"(主串)
s2="issip"(子串)
ptr1 和 ptr2指向的不同
那遇到第二种情况 指针ptr2指向的位置肯定是要重新回溯到字串的第一个字符的
那么ptr1呢? ptr1可以不回溯吗?
我假设ptr1不回溯 接着往后面走 ptr2回溯后不变
s1="mississippi"(主串)
s2="issip"(子串)
好 这个时候匹配到了子串的第一个字符 那么ptr1 ptr2同时往后面走
这个时候和上面一样三种情况
最后一直不回溯走下去的结果是主串中不存在子串
但是实际结果是
s1="mississippi"(主串)
s2="issip"(子串)
明显存在
结论:暴力算法ptr1要回溯!
回溯可以保证正确性(这里不详细介绍)
但是又引出了新的问题
如果回溯次数过多 回溯回去的区间长度太大 最坏情况下 时间复杂度会达到O(n*m)
这个时间复杂度就太高了
那么有没有什么方法可以解决ptr1回溯的问题 让时间复杂度降下来呢?
这便是我们本期学习的KMP 算法 时间复杂度是O(m+n) 空间复杂度是O(n)
2.相同前后缀
KMP解决回溯的核心思路是相同前后缀
比如我们来看下面的主串和子串

我们来看子串的前面四个字符的部分
ABAB
紫色的是前缀 黄色的后缀
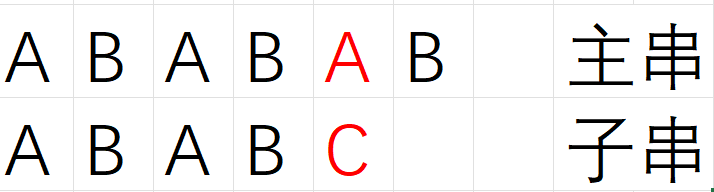
当我们发现ptr1指向的和ptr2指向的不同的时候 (上图) 子串和前缀对齐 如果是暴力解法 ptr1就要回溯到第三个元素A了
但是我们发现子串的 部分串(设为it,it==ABABC)(标红的部分) 前缀和后缀相同 我原本it的前缀和对应的主串部分匹配 it的后缀和前缀一模一样
是不是也意味着 it的后缀和 原本it的前缀对应的主串部分 匹配
我们是不是就可以将原先 主串中和it前缀 对齐的 部分 和it的后缀对齐

原理是什么? 原理是子串前缀和后缀相同 子串的前缀如果能和 主串对应的部分匹配
那么后缀是不是也能和那部分匹配呢?
如果后面我们发现ptr1 和 ptr2指向不同 我们可以直接前缀变后缀
这个时候我们就不用把主串的指针(ptr1)回溯了!
3.next数组用法
但是我们怎么知道和后缀对齐要怎么移动 移动多少个位置呢?
这个时候就要引入KMP算法中的next数组了(next数组后面详细解释) 我们这里先介绍next数组的用法
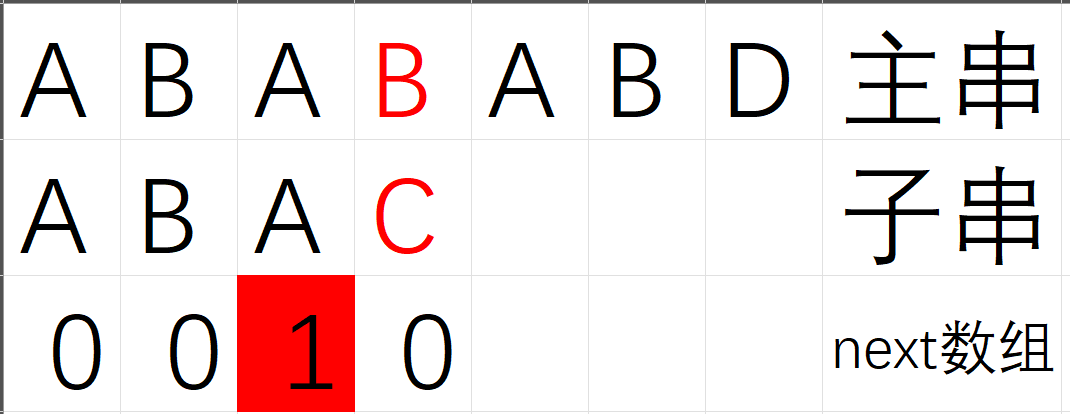
如果ptr1和ptr2指向的不同的时候 我们找到子串指针 指向元素的位置 的前一个位置的next数组里面储存的值(设为value==1)
上图要找的是next数组里面标红的1
找到1 意味着
1.ptr1不动
2.ptr2指向的位置是 从首元素偏移value个元素的位置
3.ptr2指向的位置和ptr1对齐

然后再ptr1和ptr2同时往后走并且比较其指向的元素是否相同!
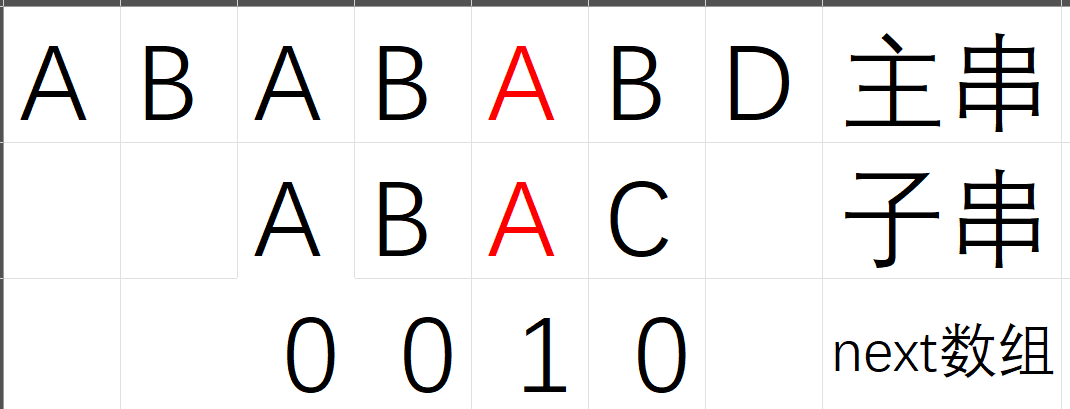
4.next数组求法
我们为什么可以这样调整 核心原理是前缀和后缀相同
你猜对了 next数组里面存的就是 最长的相同前后缀 的长度
***注意 我们找的最长的前后缀 不能是这个串本身!!!***
因为如果找的是本身你会发现(按照前面next数组使用的步骤)就是死循环了!
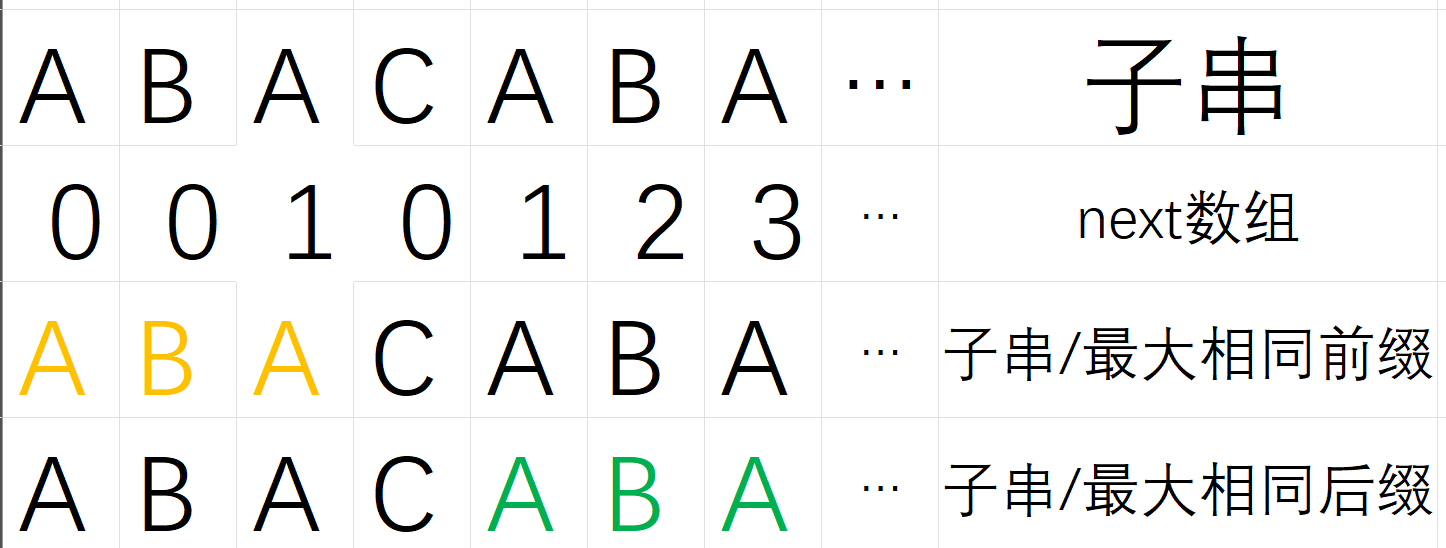
我们以子串ABACABA为例来实现一下 next数组
首先是A 一个元素 没有前后缀 next值为0
AB没有相同前后缀 next值为0
ABA 两个A分别是最大相同前后缀 next值为1
ABAC 没有相同前后缀 next值为0
ABACA 第一个A和最后一个A分别是最大相同前后缀 next值为1
ABACAB 两个AB是最大的前后缀 next值为2
ABACABA 两个ABA是最大的相同前后缀 next值为3
那么怎么通过算法把next数组弄出来呢?
有个很简单的方法 就是递推法 类似数学的数学归纳法
假设我知道当前串(ABACABA)next的值也就是3
下面有两种情况!
(1).最大相同的 前缀和后缀 的下一个值相同的时候
这个时候不就构成了更长的一个相同前后缀吗!其这个时候next的值是原先next的值+1 如下图

(2).最大相同的 前缀和后缀 的下一个值不同的时候
这个时候next的值肯定就比相同情况下的小! 但是具体小多少呢?

我们很容易看出来是2 但是怎么转换成算法和代码呢?
首先我们原先的最大相同前缀和后缀是标红的地方 这个时候我们要找的最长相同前后缀肯定不可能比 原先的(ABACABA)大

也就是(ABACABAB)的最大相同后缀只是 原先(ABACABA)最大相同后缀(ABACABA)(标红位置) 的后半部分(不含全部 )+末尾的B
为什么不能是只能是后半部分 而不能是全部呢?
因为含全部+末尾的B加起来就比原先 ABACABA的最大相同前后缀要大了 这明显不可能
最大的相同前缀就是 原先(ABACABA)最大相同前缀(ABACABAB)(标红的部分)的部分(含全部)

也就是我们这个时候要找的是这两块背景有颜色区域中 满足前缀等于后缀的 最长前缀和后缀
很熟悉吧 最长相同前后缀不就是ABAB的next数组的值嘛 所以这种情况 就是看
这个的最大的前后缀长度是多少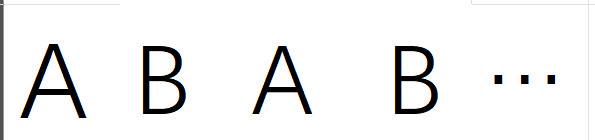
那这个的最大前后缀怎么看?
我们知道ABA的next的值
从ABA 到ABAB 多出的字符B不就是和 ABA 最大相同前缀(ABA) 的下一个值(ABA)相同嘛
不就意味着ABAB的 最大相同前后缀长度 是ABA的next值+1
也就是2 也就是意味着ABACABAB的next值就是2!!!
总结一下 下一个字符 和 最大相同前缀的 下一个字符 不同
我们要找到 原先的 最大相同前缀 (ABACABAB)
并找到此时的字符(整个串的最后一个字符)(ABACABAB)
判断 此时的字符在 原先的 最大相同前缀 后的情况下 对应的next的值
当然 上面这个步骤我们实现的时候 可不能直接将此时的字符放到 原先的 最大相同前缀的后面去 这样会造成 数据覆盖!
那怎么处理呢 以上图为例子
找到 原先的 最大相同前缀 (ABACABAB)
再判断 原先的 最大相同前缀 的 最大相同前缀 (ABACABAB) 的下一个元素 (ABACABAB)
是否和 此时的字符(ABACABAB) 相同
1.如果相同 那么此时字符对应的next的值就是 原先 最大相同前缀末端的next的值+1
2.如果不同 是不是就要重复上面的步骤(类似递归一样)
next数组实现方法如上
我们再来整理一下总的思路
我们解决暴力算法回溯的方式是通过最大相同前后缀
什么时候会产生回溯
就是ptr1 ptr2指向的元素不同的时候
也就意味着我们 ptr1和ptr2指向不同的时候
就要使用 子串 指针指向 的前一个 位置的 next的值
(value)了
然后再
1.ptr1不动
2.ptr2指向的位置是 从首元素偏移value个元素的位置
3.ptr2指向的位置和ptr1对齐
其他思路和暴力算法是一样的
我们通过最长相同前后缀完美 解决了回溯带来的时间复杂度
成功的将时间复杂度降低到O(m+n) 空间复杂度降到了O(n) (next数组)
KMP的算法的核心是ptr1永远不后退!!!
曾经的自己==最大相同前后缀
逆境==ptr1和ptr2指向位置不同时
然后我们可以根据以上原理实代码来!
#include <iostream>
#include <vector>
#include <string>// 计算 next 数组,用于记录模式串中每个位置之前的子串的最长相同前缀和后缀的长度
void computeNext(const std::string& pattern, std::vector<int>& next) {int m = pattern.length();// next 数组的第一个元素始终为 0next[0] = 0;// j 用于记录最长相同前缀的长度int j = 0;// 从模式串的第二个字符开始遍历for (int i = 1; i < m; i++) {// 当当前字符和最长相同前缀的下一个字符不相等时while (j > 0 && pattern[i] != pattern[j]) {// 回溯到 next[j - 1] 的位置j = next[j - 1];}// 如果当前字符和最长相同前缀的下一个字符相等if (pattern[i] == pattern[j]) {// 最长相同前缀的长度加 1j++;}// 更新 next 数组next[i] = j;}
}// KMP 字符串匹配算法
int kmpSearch(const std::string& text, const std::string& pattern) {int n = text.length();int m = pattern.length();// 创建 next 数组std::vector<int> next(m);// 计算 next 数组computeNext(pattern, next);// j 用于记录模式串的当前匹配位置int j = 0;// 遍历文本串for (int i = 0; i < n; i++) {// 当当前字符和模式串的当前字符不相等时while (j > 0 && text[i] != pattern[j]) {// 回溯到 next[j - 1] 的位置j = next[j - 1];}// 如果当前字符和模式串的当前字符相等if (text[i] == pattern[j]) {// 模式串的匹配位置加 1j++;}// 如果模式串已经完全匹配if (j == m) {// 返回匹配的起始位置return i - m + 1;}}// 未找到匹配,返回 -1return -1;
}int main() {std::string text = "ABABDABACDABABCABAB";std::string pattern = "ABABCABAB";// 调用 KMP 搜索函数int index = kmpSearch(text, pattern);if (index != -1) {std::cout << "Pattern found at index: " << index << std::endl;} else {std::cout << "Pattern not found." << std::endl;}return 0;
}