贪心算法之最小生成树问题
1. 贪心算法的基本思想
贪心算法在每一步都选择局部最优的边,希望最终得到整体最优的生成树。常见的两种 MST 算法为 Kruskal 算法 和 Prim 算法。这两者均满足贪心选择性质和最优子结构性质,即:
-
贪心选择性质:局部最优选择(比如选择当前权值最小的边)可以构成全局最优解。
-
最优子结构:一个最优解包含其子问题的最优解。
2. 正确性证明
2.1 交换论证法
以 Kruskal 算法为例,正确性证明常使用“交换论证法”:
-
假设在某一步选取了当前权值最小的边
e,若该边不在某最优解中,则存在一个边f(在最优解中)可以与e交换,并且不会增加生成树的总权值。 -
通过不断的“交换”,最终可构造出与 Kruskal 算法选取的边集合相同的生成树,从而证明其最优性。
2.2 剪枝证明(Cut Property)
-
割定理(Cut Property):对于图中的任一割,跨割的最小边必定属于某个 MST。
-
Kruskal 算法每次选择全图中最小且不会形成环的边,正好满足割定理,从而确保了所选边集一定可以扩展为 MST。
类似地,Prim 算法从任意一个点开始,每次添加连接已构造生成树和其他顶点之间最小的边,这也遵循割定理,从而保证了正确性。
3. 算法步骤
3.1 Kruskal 算法步骤
-
排序:将所有边按权值从小到大排序。
-
初始化:每个顶点为一个独立的集合(并查集数据结构)。
-
遍历边集:依次取出最小边,判断其两个顶点是否在同一集合:
-
如果不在同一集合,则将该边加入生成树,并合并两个集合;
-
否则,跳过该边(避免环的产生)。
-
-
终止条件:当生成树边数达到 n−1(n 为顶点数)时结束。
3.2 Prim 算法步骤
-
初始化:任选一个顶点,将其加入 MST 集合。
-
维护优先队列:将所有与当前生成树相连的边加入优先队列。
-
选择边:从队列中取出最小边,若其另一端未被访问,则加入生成树,并将该顶点所有相连边更新到队列。
-
重复:直到所有顶点均已加入 MST。
4. 时间复杂度分析
4.1 Kruskal 算法
-
排序:对所有 E 条边进行排序,时间复杂度为 O(ElogE) 。
-
合并查找:利用路径压缩和按秩合并,合并与查询的时间复杂度近似为 O(α(n))(α 为阿克曼函数的反函数,几乎看作常数)。
-
总体:总体时间复杂度为 O(ElogE),当图稀疏时可近似看作 O(ElogV)。
4.2 Prim 算法
-
利用最小堆:每次从堆中取出最小边和更新堆的操作总体复杂度为 O((E+V)logV)。
-
总体:因此总体时间复杂度为 O(ElogV)。
5. 实例分析
考虑下列图:
-
顶点集合:{A, B, C, D, E}
-
边集合及权值:
-
A-B: 1
-
A-C: 3
-
B-C: 3
-
B-D: 6
-
C-D: 4
-
C-E: 2
-
D-E: 5
-
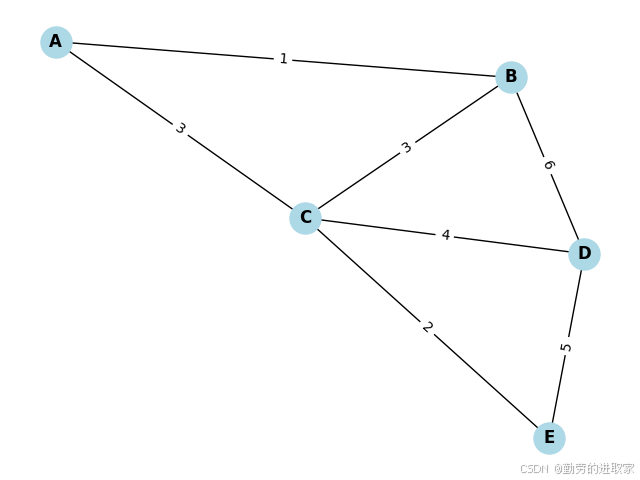
利用 Kruskal 算法构造 MST:
-
排序边:A-B(1), C-E(2), A-C(3), B-C(3), C-D(4), D-E(5), B-D(6)。
-
选边:
-
A-B (1):加入,集合合并 {A, B}。
-
C-E (2):加入,集合合并 {C, E}。
-
A-C (3):A 属于 {A, B},C 属于 {C, E},加入,集合合并 {A, B, C, E}。
-
B-C (3):跳过(形成环)。
-
C-D (4):D 未加入集合,加入后合并为 {A, B, C, D, E}。
-
-
完成:共选 4 条边,即生成 MST,总权值 1+2+3+4=10。
6. Python代码举例
以下代码使用 Kruskal 算法实现 MST 求解,并展示了如何使用并查集数据结构:
class UnionFind:def __init__(self, n):self.parent = list(range(n))self.rank = [0] * ndef find(self, u):if self.parent[u] != u:self.parent[u] = self.find(self.parent[u])return self.parent[u]def union(self, u, v):root_u = self.find(u)root_v = self.find(v)if root_u == root_v:return False # u 和 v 已经在同一集合# 按秩合并if self.rank[root_u] < self.rank[root_v]:self.parent[root_u] = root_velif self.rank[root_u] > self.rank[root_v]:self.parent[root_v] = root_uelse:self.parent[root_v] = root_uself.rank[root_u] += 1return Truedef kruskal(n, edges):"""n: 顶点数,顶点编号为 0 到 n-1edges: 边列表,每个元素 (u, v, weight)返回最小生成树的边列表及总权值"""# 按权值排序边edges.sort(key=lambda x: x[2])uf = UnionFind(n)mst = []total_weight = 0for u, v, weight in edges:if uf.union(u, v):mst.append((u, v, weight))total_weight += weightif len(mst) == n - 1:breakreturn mst, total_weight# 示例数据
# 对应上面的实例,顶点 A,B,C,D,E 分别用 0,1,2,3,4 表示
edges = [(0, 1, 1), # A-B(0, 2, 3), # A-C(1, 2, 3), # B-C(1, 3, 6), # B-D(2, 3, 4), # C-D(2, 4, 2), # C-E(3, 4, 5) # D-E
]
n = 5mst, total_weight = kruskal(n, edges)
print("最小生成树边集:", mst)
print("总权值:", total_weight)
运行结果将输出 MST 边集及其总权值。例如,上述代码可能输出:
最小生成树边集: [(0, 1, 1), (2, 4, 2), (0, 2, 3), (2, 3, 4)]
总权值: 10
最小生成树边集: [(0, 1, 1), (2, 4, 2), (0, 2, 3), (2, 3, 4)] 总权值: 10
总结
-
逻辑推理与正确性证明:贪心算法基于割定理及交换论证法保证了局部最优选择可推导出全局最优解。
-
算法步骤:Kruskal 和 Prim 分别通过排序边或维护最小堆实现贪心选择。
-
时间复杂度:Kruskal 算法主要为 O(ElogE) ;Prim 算法为 O(ElogV) 。
-
实例与代码:通过一个实例和 Python 代码演示了 MST 的求解过程。