RCU机制以及内存优化屏障
一、RCU机制
1.RCU机制
RCU 英文全称为 Read-Copy-Update,顾名思义就是 “读 - 拷贝 - 更新”,是 Linux 内核中重要的同步机制。Linux 内核已有原子操作、读写信号量等锁机制,为什么要单独设计一个比较复杂的新机制?
RCU 记录所有指向共享数据的指针的使用者,当要修改该共享数据时,首先创建一个副本,在副本中修改。所有读访问线程都离开读临界区之后,指针指向新的修改后副本的指针,并且删除旧数据。
2.链表操作
RCU 保护的不仅是一般的指针。Linux 内核提供标准函数,使得能通过 RCU 机制保护双链表,这是 RCU 机制在 Linux 内核内部最重要的应用。
有关通过 RCU 保护的链表,好消息是仍然可以使用标准的链表元素。只有在遍历链表、修改和删除链表元素时,必须调用标准函数的 RCU 变体。
- RCU 重要的应用场景是链表,有效地提高遍历读取数据的效率,读取链表成员数据时通常只需要
rcu_read_lock(),允许多个线程同时读取链表,并且允许一个线程同时修改链表。- RCU 的意思就是读 - 复制 - 更新,它是根据原理命名。写者修改对象的流程为:首先复制生成一个副本,然后更新此副本,最后使用新对象替换旧的对象。在写者执行复制更新时读者可以读数据。
- 写者删除对象,必须等待所有访问被删除对象读者访问结束时,才能够执行销毁操作。RCU 优势是读者没有任何同步开销:不需要获取锁、执行原子指令或内存屏障。但写者同步开销大,需延迟对象释放、复制被修改对象,写者之间必须用锁互斥。
- RCU 常用于读者性能要求高的场景,只能保护动态分配的数据结构(通过指针访问);受 RCU 保护的临界区内不能 sleep;读写不对称,对写者性能无要求,但读者性能要求高。
- 缺点:写者同步开销大,写者之间需互斥处理,应用比其他机制更复杂。
A.读拷贝更新(RCU)模式添加链表项,具体源码如下:

B.读拷贝更新(RCU)模式删除链表项,具体内核源码如下:

C.读拷贝更新(RCU)模式更新链表项,具体内核源码分析如下:
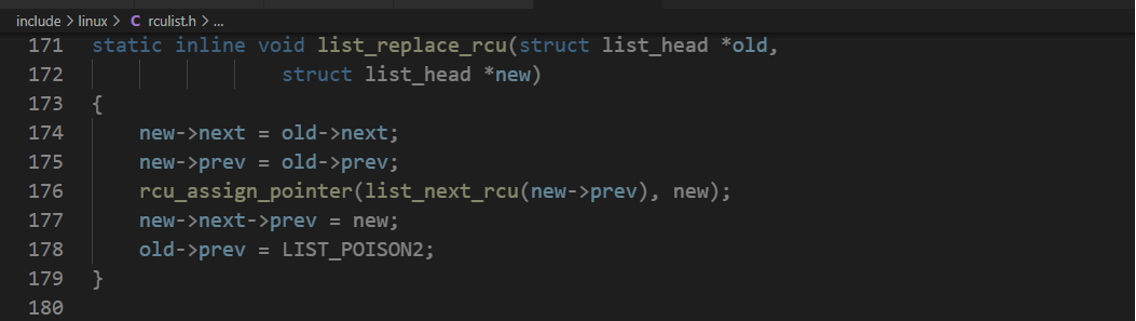
【代码案例】
#include <linux/module.h>
#include <linux/init.h>
#include <linux/list.h>
#include <linux/rculist.h>struct my_struct {struct list_head list;int data;
};static struct list_head my_list_head;static int __init my_module_init(void)
{struct my_struct *old_struct, *new_struct;INIT_LIST_HEAD(&my_list_head);// 分配并初始化旧结构体实例old_struct = kmalloc(sizeof(struct my_struct), GFP_KERNEL);if (!old_struct) {pr_err("Memory allocation for old_struct failed\n");return -ENOMEM;}old_struct->data = 30;list_add_rcu(&old_struct->list, &my_list_head);// 分配并初始化新结构体实例new_struct = kmalloc(sizeof(struct my_struct), GFP_KERNEL);if (!new_struct) {pr_err("Memory allocation for new_struct failed\n");kfree(old_struct);return -ENOMEM;}new_struct->data = 40;// 使用list_replace_rcu更新链表元素list_replace_rcu(&old_struct->list, &new_struct->list);call_rcu(&old_struct->list, [](struct rcu_head *head) {struct my_struct *s = container_of(head, struct my_struct, list);kfree(s);});return 0;
}static void __exit my_module_exit(void)
{struct my_struct *pos, *n;list_for_each_entry_safe(pos, n, &my_list_head, list) {list_del_rcu(&pos->list);call_rcu(&pos->list, [](struct rcu_head *head) {struct my_struct *s = container_of(head, struct my_struct, list);kfree(s);});}
}module_init(my_module_init);
module_exit(my_module_exit);
MODULE_AUTHOR("jerry");
MODULE_DESCRIPTION("RCU list_replace_rcu example");
MODULE_LICENSE("GPL");3.RCU的层次架构
RCU根据CPU数量的大小按照树形结构来组成其层次结构,成为RCU Hierarchy。具体内核源码如下:
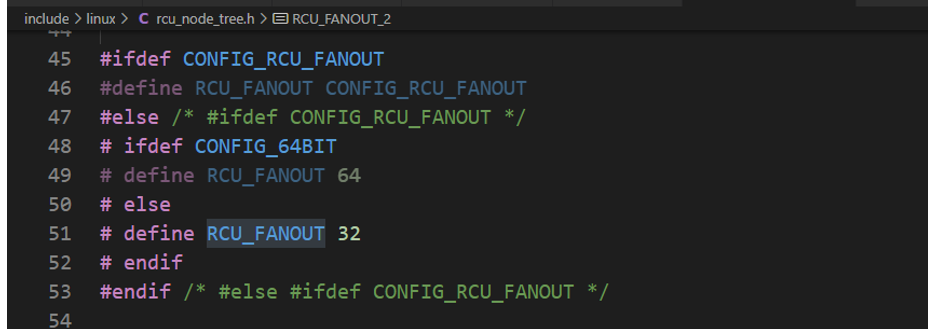
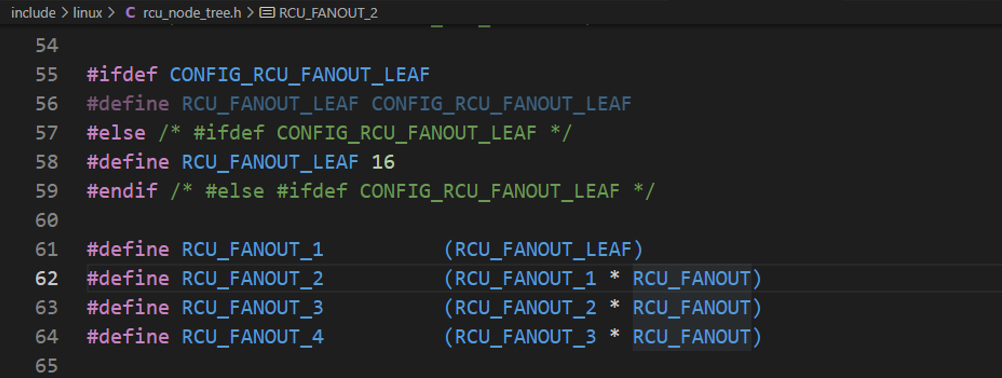
在多核系统中,RCU(Read - Copy - Update)机制借助叶子节点来管理 CPU 主要是出于提升可扩展性、减少同步开销、优化资源管理以及增强系统适应性等多方面的考量,下面为你详细解释:
提升可扩展性
- 应对大规模多核系统:在现代多核乃至众核系统中,CPU 数量可能达到成百上千个。若采用扁平结构管理所有 CPU,管理复杂度会随 CPU 数量急剧增加,导致性能显著下降。而通过叶子节点构建分层管理结构,可将大规模 CPU 分组管理。比如在拥有 128 个 CPU 的系统中,将其划分为 8 个组,每个组由一个叶子节点管理,这样能降低单个节点的管理负担,使系统更易扩展。
- 层次化管理:层次化的 RCU 结构可以根据系统规模灵活调整层次深度和扇出值。例如,当系统中的 CPU 数量进一步增加时,可以增加层次结构的深度,通过
RCU_FANOUT_2、RCU_FANOUT_3等更高层次的节点来管理更多的 CPU 分组,使得系统能够在不同规模下都保持高效的管理。减少同步开销
- 局部化管理:叶子节点仅负责管理一小部分 CPU,这样在进行 RCU 操作(如更新操作)时,只需与这部分 CPU 进行同步,减少了需要同步的范围和 CPU 数量。例如在更新某个共享数据时,只需要等待该叶子节点所管理的 16 个 CPU 完成相关读操作,而不是等待所有 128 个 CPU,从而降低了同步开销。
- 并发性能提升:不同叶子节点管理的 CPU 组可以并行进行操作,因为它们之间的同步需求相对独立。这使得在多核系统中,多个 CPU 组可以同时进行读操作,提高了系统的并发性能。
优化资源管理
- 针对性管理:叶子节点能够针对其所管理的 CPU 组进行特定的资源管理和调度。例如,根据这组 CPU 的负载情况,合理分配 RCU 相关的资源,确保每个 CPU 组都能高效运行。
- 减少内存占用:分层结构可以减少每个节点所需维护的状态信息。每个叶子节点只需要维护其所管理的 CPU 组的状态,而不是整个系统所有 CPU 的状态,从而减少了内存占用。
增强系统适应性
- 灵活配置:通过调整
RCU_FANOUT和RCU_FANOUT_LEAF等参数,可以根据不同系统的硬件特性和应用需求,灵活配置 RCU 层次结构。例如,对于 CPU 性能差异较大的系统,可以通过调整参数,使性能相近的 CPU 被分配到同一个叶子节点管理的组中,提高系统的整体性能。- 适应不同应用场景:不同的应用场景对 RCU 机制的性能要求不同。在一些读操作频繁的场景中,可以通过合理配置叶子节点,优化读操作的性能;而在写操作较多的场景中,也可以通过调整层次结构,减少写操作的延迟。
【具体代码使用案例】
rcu.c
#include <linux/kernel.h> //printk等函数
#include <linux/module.h> //模块加载
#include <linux/init.h> //模块初始化和退出相关的一些辅助定义和函数声明
#include <linux/slab.h> //内核中的内存分配相关操作,提供了像 kmalloc、kzalloc 等函数的声明
#include <linux/spinlock.h>//声明了自旋锁相关的结构体和函数
#include <linux/kthread.h> //包含了创建和管理内核线程的相关函数声明,例如代码中用到的 kthread_run 函数
#include <linux/delay.h> //提供了一些用于在内核中实现延迟功能的函数声明,像 msleep
#include <linux/types.h>
#include <linux/rcupdate.h>// 定义一个阈值,当value达到这个值后,关闭线程
#define STOP_THRESHOLD 100struct RCUStruct{int a;struct rcu_head rcu;
};static struct RCUStruct *Global_pointer;
// 创建2个读内核线程和1个写内核线程
static struct task_struct *RCURD_Thr1, *RCURD_Thr2, *RCUWriter_Thread;// 读者线程1
static int MyRCU_ReaderThreadFunc1(void *data){struct RCUStruct *pointer = NULL;while(1){// msleep相当于互斥锁,mdelay相当于自旋锁// 这里的休眠5秒,相当于模拟线程在每次读取操作之间的一个短暂的间隔msleep(5);// 读多写少的并发场景rcu_read_lock(); // 加锁// 模拟获取锁之后的一些处理操作mdelay(10);// 这是通过 rcu_dereference 函数获取共享数据指针,rcu_dereference 函数在 RCU 机制中有特殊作用,// 它可以在保证并发安全的前提下返回共享指针的值,允许读者线程获取到当前有效的共享数据指针pointer = rcu_dereference(Global_pointer);if(pointer){printk("%s:read a=%d\n", __func__, pointer->a);}rcu_read_unlock();// 检查是否收到停止线程的信号,如果收到则退出循环,结束线程if (kthread_should_stop()) {break;}}return 0;
}static int MyRCU_ReaderThreadFunc2(void *data) // 读者线程2
{struct RCUStruct *pointer2 = NULL;while(1){msleep(5);// 读多写少并发场景:高效、低开销rcu_read_lock();mdelay(10);pointer2 = rcu_dereference(Global_pointer);if(pointer2)printk("%s:read a=%d\n", __func__, pointer2->a);rcu_read_unlock();// 检查是否收到停止线程的信号,如果收到则退出循环,结束线程if (kthread_should_stop()) {break;}}return 0;
}// 回调函数的定义部分
static void myrcu_del(struct rcu_head *rcuh){// container_of 是一个常用的宏,通常用于从 嵌套结构体 中获取外部结构体的指针。// 它的基本作用是通过结构体中的某个字段的地址,反推得到整个结构体的地址。struct RCUStruct *p = container_of(rcuh, struct RCUStruct, rcu);printk("%s:a=%d\n", __func__, p->a);kfree(p);
}// 写者线程
static int MyRCU_WriterThread_Func(void *pointer){struct RCUStruct *old;struct RCUStruct *new_ptr;int value = (unsigned long)pointer;while(1){msleep(10);// GFP_KERNEL为内核级别的内存分配,支持阻塞操作。适用于大多数普通的内存分配场景new_ptr = kmalloc(sizeof(struct RCUStruct), GFP_KERNEL);old = Global_pointer;*new_ptr = *old;new_ptr->a = value;// rcu_assign_pointer 函数将新的共享数据结构体指针赋值给全局的共享指针 Global_pointer,// 这个函数在 RCU 机制下可以确保在合适的时候让读者线程能看到新的数据,保证数据更新的并发安全性和一致性rcu_assign_pointer(Global_pointer, new_ptr);// 调用 call_rcu 函数,注册一个回调函数(这里就是前面定义的 myrcu_del 函数),// 当所有正在访问旧数据的读者线程完成访问后(在 RCU 机制的协调下),// 会自动调用这个回调函数来释放旧数据结构体占用的内存空间,实现内存的安全回收call_rcu(&old->rcu, myrcu_del);printk("%s:write to new %d\n", __func__, value);value++;// 判断value是否达到阈值,如果达到则停止所有相关线程if (value >= STOP_THRESHOLD) {kthread_stop(RCURD_Thr1);kthread_stop(RCURD_Thr2);kthread_stop(RCUWriter_Thread);break;}}return 0;
}// 模块加载
static int __init MyRCU_TestFunc_Init(void){int value = 2;// 提示:初始化内核模块成功printk("Prompt:Successfully initialized the kernel module.\n");Global_pointer = kzalloc(sizeof(struct RCUStruct), GFP_KERNEL);RCURD_Thr1 = kthread_run(MyRCU_ReaderThreadFunc1, NULL, "RCU_RDer1");RCURD_Thr2 = kthread_run(MyRCU_ReaderThreadFunc2, NULL, "RCU_RDer2");RCUWriter_Thread = kthread_run(MyRCU_WriterThread_Func, (void*)(unsigned long)value, "RCU_Writer");return 0;
}// 模块卸载
static void __exit MyRCU_TestFunc_Exit(void){// 卸载内核模块printk("Prompt:Successfully uninstalled kernel module!\n");if (RCURD_Thr1) {kthread_stop(RCURD_Thr1);}if (RCURD_Thr2) {kthread_stop(RCURD_Thr2);}if (RCUWriter_Thread) {kthread_stop(RCUWriter_Thread);}if(Global_pointer)kfree(Global_pointer);
}module_init(MyRCU_TestFunc_Init); // 内核模块入口函数
module_exit(MyRCU_TestFunc_Exit); // 内核模块退出函数
MODULE_LICENSE("GPL"); // 模块的许可证声明Makefile
# 指定要构建的内核模块对应的目标文件
obj-m := rcu.o# 构建所有模块的目标规则
all:$(MAKE) -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules# 清理模块的目标规则
clean:$(MAKE) -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
插入运行

二、优化内存屏障
1.优化屏障
在编程时,指令一般不按照源程序顺序执行,原因是为提高程序执行性能,会对它进行优化,主要为两种:编译器优化和 CPU 执行优化。优化屏障避免编译的重新排序优化操作,保证编译程序时在优化屏障之前的指令不会在优化屏障之后执行。
编译器优化示例
假设我们有一段 C 语言代码,功能是计算两个数的和并打印结果:
#include <stdio.h>int add(int a, int b) {int result = a + b;return result; }int main() {int num1 = 5;int num2 = 3;int sum = add(num1, num2);printf("The sum is: %d\n", sum);return 0; }在编译这段代码时,如果使用 GCC 编译器并加上优化选项
-O2(开启二级优化),编译器可能会对代码进行以下优化:
- 常量折叠:在
main函数中,num1 = 5和num2 = 3是常量,编译器在编译阶段就可以计算出add(num1, num2)的结果为8,而不需要在运行时才去调用add函数计算。这样在生成的机器码中,可能就直接将sum的值设为8,减少了函数调用的开销。- 指令调度:编译器会分析指令之间的依赖关系,调整指令顺序,让 CPU 能更高效地执行。比如将一些可以并行执行的指令安排在合适的位置,充分利用 CPU 的流水线等特性,提高执行效率。
CPU 执行优化示例
以简单的循环代码为例:
#include <stdio.h>int main() {int sum = 0;for (int i = 0; i < 1000; i++) {sum += i;}printf("The sum is: %d\n", sum);return 0; }在 CPU 执行过程中:
- 乱序执行:CPU 内部有多个执行单元,在执行上述循环时,当计算
sum += i时,可能后面的指令中存在一些与当前计算没有数据依赖关系的操作(比如后续对寄存器的一些准备操作等)。CPU 的乱序执行机制会分析各指令的执行情况,在不影响最终结果的前提下,让后面这些无依赖关系的指令提前执行,充分利用 CPU 的执行单元,避免空闲等待,提高流水线的利用率。例如,当计算sum += i时,CPU 可能同时去执行后续对缓存预取等相关操作指令,让这些指令在等待sum += i计算结果的空闲时间里并行执行,从而提高整体执行性能。- 寄存器重命名:在上述代码执行过程中,CPU 可能会遇到寄存器冲突问题(例如多个指令都要使用同一个寄存器)。CPU 的寄存器重命名机制会为这些指令分配不同的物理寄存器来代替原来冲突的逻辑寄存器,使得指令可以更顺畅地执行。比如,原本两条指令都要写同一个逻辑寄存器,通过寄存器重命名,它们可以分别写入不同的物理寄存器,然后在合适的时候再将结果合并或转换,保证程序逻辑正确的同时,让指令执行更加高效,避免因寄存器冲突导致的流水线停滞。
在 C 语言中,我们可以使用
__asm__ __volatile__来实现优化屏障的功能。__volatile__告诉编译器不要对这条汇编指令进行优化,__asm__则用于嵌入汇编代码。以下是一个简单的示例:#include <stdio.h>int main() {int a = 10;int b = 20;int result;// 这里使用__asm__ __volatile__ 来实现优化屏障__asm__ __volatile__("" ::: "memory");// 假设这里有一些复杂的计算逻辑,编译器可能会对指令重新排序// 但有了优化屏障,屏障前的指令不会被移到屏障后执行result = a + b; printf("The result is: %d\n", result);return 0; }在这个例子中,
__asm__ __volatile__("" ::: "memory")充当优化屏障。它告诉编译器,不要对这条指令前后的内存访问指令进行重新排序。尽管在这个简单示例中,指令重排可能不会产生明显影响,但在更复杂的代码中,尤其是涉及多线程或者对指令执行顺序敏感的场景下,优化屏障可以确保代码按照预期的顺序执行。
Linux 使用宏barrier实现优化屏障,如 gcc 编译器的优化屏障宏定义,具体查阅 linux 内核源码如下:

【代码案例】
#include <stdio.h>// 模拟共享变量
int shared_variable = 0;// 模拟一个线程函数
void thread_function() {// 假设这里是线程对共享变量的操作shared_variable = 10;// 使用编译器屏障barrier(); // 屏障之后的操作,确保在前面的写操作之后执行int value = shared_variable; printf("Thread read value: %d\n", value);
}int main() {// 这里简单模拟调用线程函数thread_function();return 0;
}2.内存屏障
内存屏障,也称内存栅障或屏障指令等,是一类同步屏障指令,用于确保编译器或 CPU 对内存访问操作时严格按一定顺序执行,使 memory barrier 之前与之后的指令不会因系统优化等原因乱序。
Linux 内核支持 3 种内存屏障:
- 编译器屏障;
- 处理器内存屏障;
- 【内存映射 I/O 写屏障(Memory Mapping I/O,MMIO。此屏障已废弃,新驱动不应该使用)】。

【代码案例】
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/sched.h>
#include <linux/seqlock.h>// 定义共享变量
static int shared_data = 0;
// 定义顺序锁
static struct seqlock my_seqlock;// 模拟写线程函数
static int write_thread_func(void *data)
{// 写操作时获取顺序锁write_seqlock(&my_seqlock);shared_data++;// 使用写内存屏障,确保写操作按顺序执行wmb(); write_sequnlock(&my_seqlock);return 0;
}// 模拟读线程函数
static int read_thread_func(void *data)
{unsigned int seq;int local_data;do {seq = read_seqbegin(&my_seqlock);local_data = shared_data;// 使用读内存屏障,确保读操作按顺序执行rmb(); } while (read_seqretry(&my_seqlock, seq));pr_info("Read value: %d\n", local_data);return 0;
}static int __init my_module_init(void)
{struct task_struct *write_thread, *read_thread;// 初始化顺序锁seqlock_init(&my_seqlock);// 创建写线程write_thread = kthread_create(write_thread_func, NULL, "write_thread");if (IS_ERR(write_thread)) {pr_err("Failed to create write thread\n");return PTR_ERR(write_thread);}// 创建读线程read_thread = kthread_create(read_thread_func, NULL, "read_thread");if (IS_ERR(read_thread)) {pr_err("Failed to create read thread\n");return PTR_ERR(read_thread);}// 唤醒线程wake_up_process(write_thread);wake_up_process(read_thread);return 0;
}static void __exit my_module_exit(void)
{pr_info("Module unloaded\n");
}module_init(my_module_init);
module_exit(my_module_exit);
MODULE_AUTHOR("jerry");
MODULE_DESCRIPTION("Memory Barrier Example");
MODULE_LICENSE("GPL");https://github.com/0voice