(二)机器学习---常见任务及算法概述
目录
机器学习(Machine Learning)
类别(Class)
标签(Label)
一.机器学习的一般过程
二.机器学习方法分类
(1)有监督学习(supervised learning)
(2)无监督学习(unsupervised learning)
(3)半监督学习(Semi-supervised learning)
(4)强化学习(Reinforcement learning)
三.机器学习任务及常用算法
机器学习(Machine Learning)

是人工智能一个分支和实现方式,研究计算机怎样模拟或实现人类的学习行为以获取新的知识或技能,重新组织已有的知识结构来改善计算机系统自身的性能。

机器学习的三类常见任务:数值预测、分类、聚类
这里我们先了解两个概念:类别和标签
类别(Class)
定义:类别是分类问题中模型需要预测的目标变量的不同取值。它表示数据样本所属的“分组”或“类型”,通常是离散的(如有限的几个选项)。
示例:在垃圾邮件分类中,类别可能是“垃圾邮件”或“非垃圾邮件”。在图像分类中,类别可能是“猫”“狗”“鸟”等
标签(Label)
定义:标签是监督学习中与输入数据(特征)对应的真实答案或目标值,可以是离散的(如类别)或连续的(如回归问题中的数值)。
示例:在多标签分类中,一张图片可能有多个标签(如“沙滩”“日落”“人物”)。在房价预测中,一套房子的标签可能是“500万元”。在图像分类中,一张猫的图片的标签是“猫”。
一.机器学习的一般过程
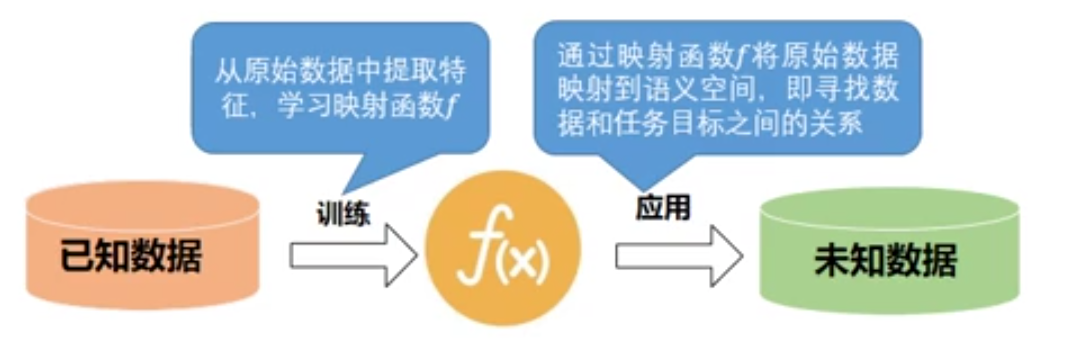
下图是我们举得一个具体例子:

二.机器学习方法分类

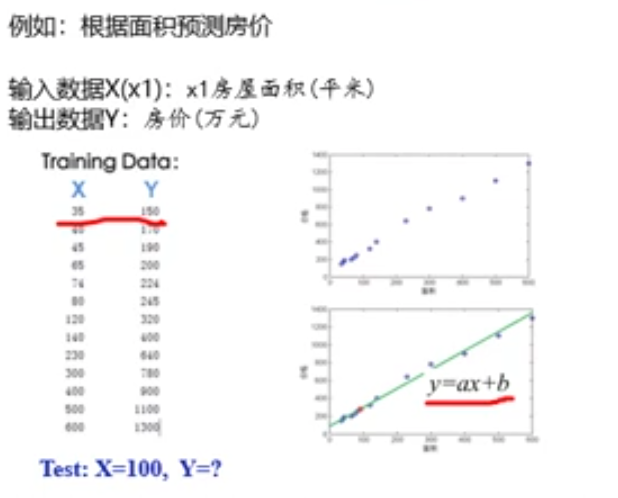
(1)有监督学习(supervised learning)
从给定的有标注的训练数据集中学习出一个模型,然后根据这个模型对未知样本进行预测。常见任务包括分类与回归(即数值预测)
分类:已知类别数,输出是离散的类别标签,定性

回归:输出是连续的实数值,定量
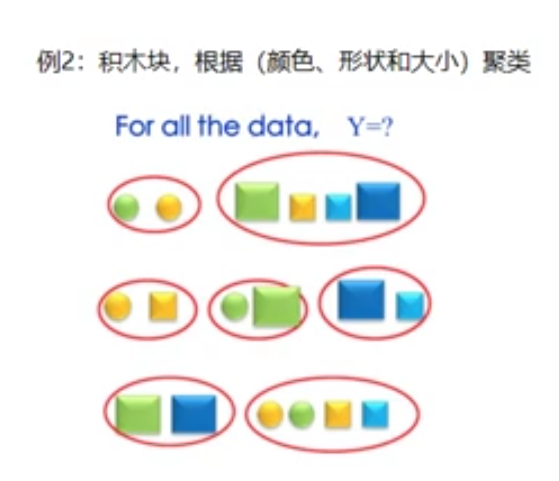
(2)无监督学习(unsupervised learning)
也就是没有标注的训练数据集, 需要根据样本间的统计规律对样本集进行分析, 其常见任务如聚类等。
聚类:未知类别数,将相似的样本归为一簇,输出类别簇
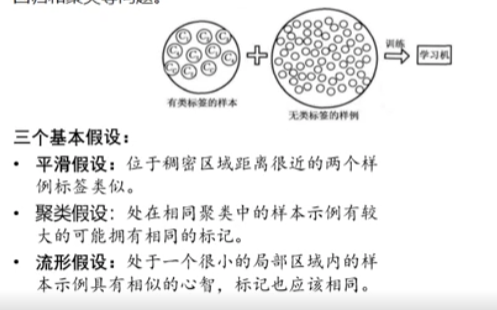
(3)半监督学习(Semi-supervised learning)
结合(少量的)标注训练数据和(大量的)未标注数据来进行模型学习。基本思想是利用数据分布上的模型假设建立学习器对未标签样例进行标签。可用于分类、回归和聚类等问题。
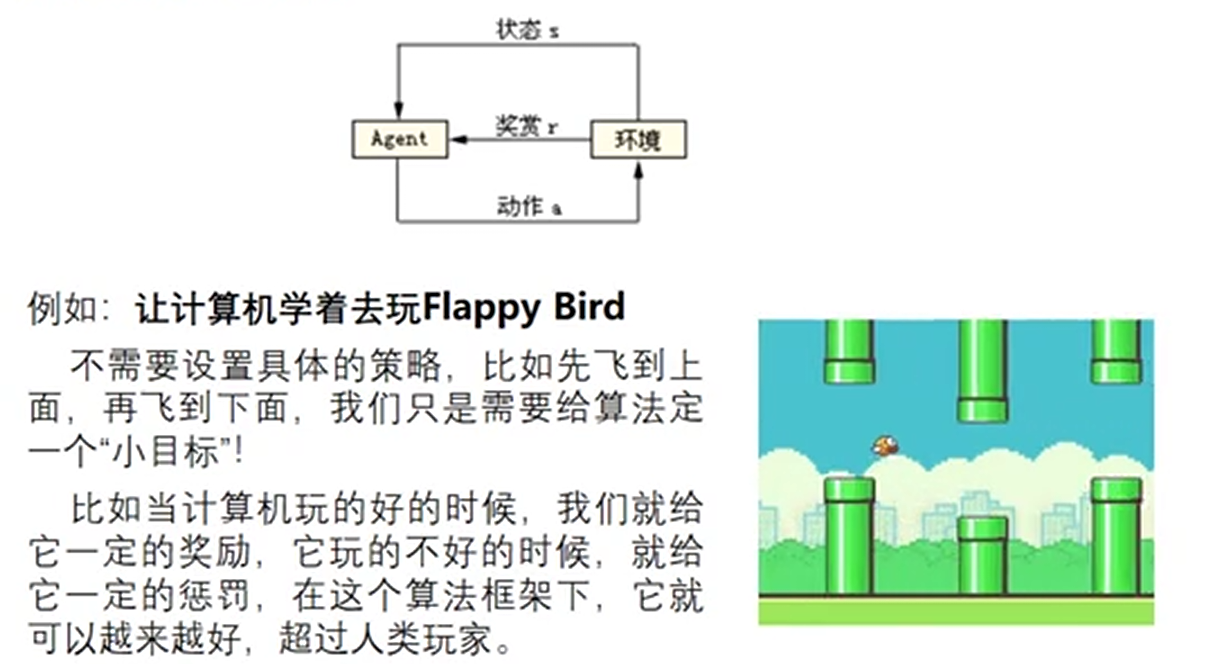
(4)强化学习(Reinforcement learning)
外部环境对输出只给出评价信息而非正确答案,学习机通过强化受奖励的动作来改善自身的性能。
三.机器学习任务及常用算法
| 分类问题 | 回归问题 | 聚类问题 | 各种复杂问题 |
|---|---|---|---|
| 决策树√ | 线性回归√ | K-means√ | 神经网络√ |
| 逻辑回归√ | 岭回归 | 密度聚类 | 深度学习√ |
| 集成学习√ | Lasso回归 | 谱聚类 | 条件随机场 |
| 贝叶斯 | 层次聚类 | 隐马尔可夫模型 | |
| 支持向量机 | 高斯混合聚类 | LDA主题模型 |
而打勾的是我们接下来准备学习的常用算法。
所用的Python机器学习方法库为Scikit-learn
