深入理解分支预测原理,揭开AMD Zen 5的高性能秘诀
前言
今年,AMD Zen 5架构随着AMD旗下锐龙、霄龙等新一代处理器的发布而亮相。Zen 5对比上一代架构 Zen 4在性能上有了大幅提升,其中,IPC(每时钟周期执行的指令数量)更是提升了16%。
在Zen 5 高性能的背后,分支预测器的优化功不可没,其中,对2-ahead分支预测的支持尤为重要。
本文将从CPU分支预测原理讲起,试图带大家理解Zen 5在分支预测上的优化,揭开性能提升的秘密。
分支预测大体可以分成两部分,分支方向的预测和分支目的地址的预测,本文主要介绍前者。
从CPU流水线说起
在现代计算机体系结构下,程序都会被转换成一条条指令,在CPU中执行。
我们能想到的最简单的指令执行流程是串行执行,比如现有指令A,B,C和D,那么,串行执行流程如下:

然而,串行执行的效率无疑是低下的。为了充分榨干CPU的性能,指令流水线出现了,它把指令执行的流程划分成多个阶段,每个阶段可以独立执行。比如,下图中为2级流水线的示例图:
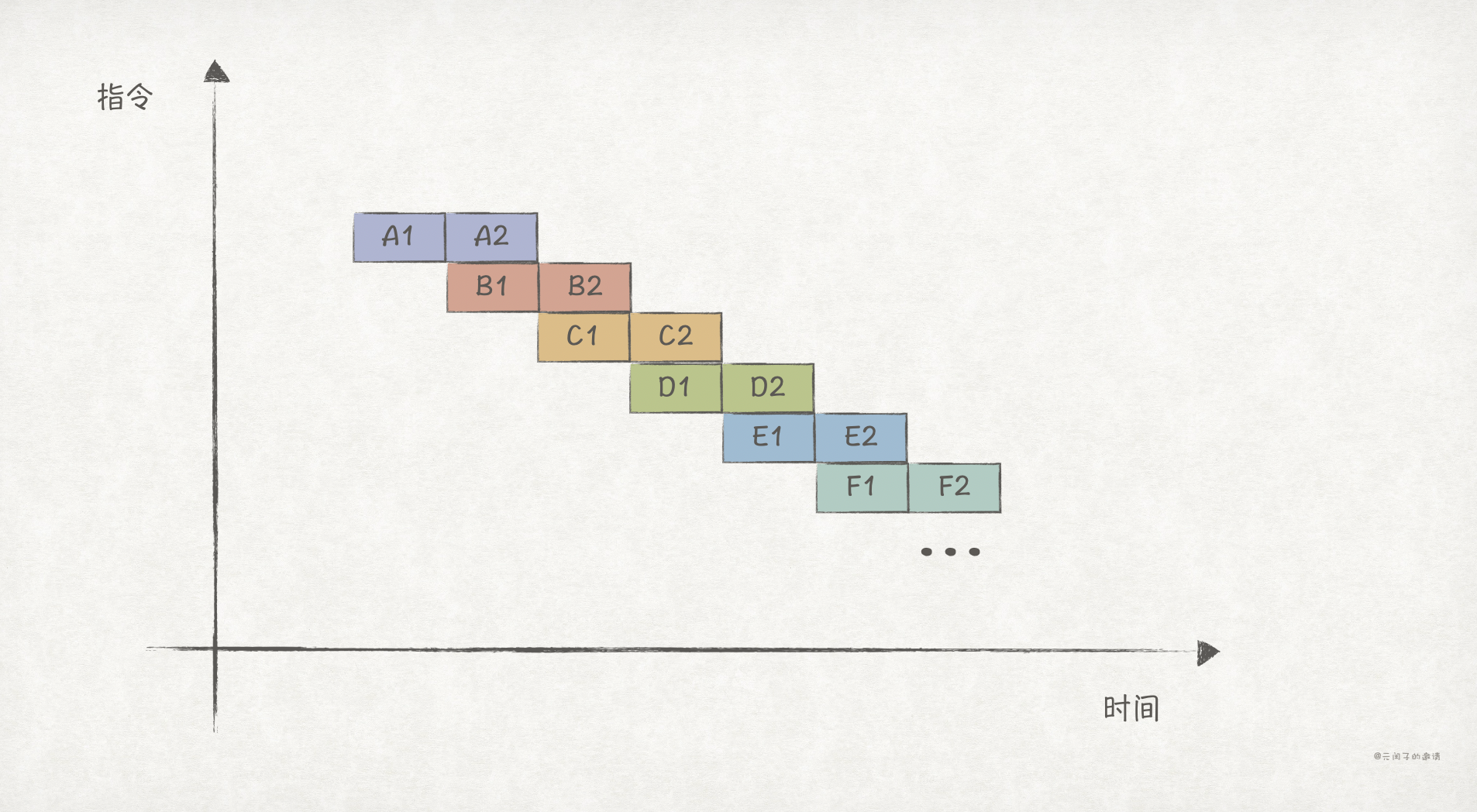
在流水线下,虽然单个指令执行的耗时不变,但指令执行的吞吐量增大了。
分支指令是众多指令中的一种,它伴随着程序中 if/for/while 等可能出现分支跳转的代码而出现。
if (x == 0) {// doTingA
} else {// doTingB
}
上述的代码,可能会转换成如下的汇编代码:
branch_if_not_equal x, 0, else_label
// doTingA
goto end_label
else_label:
// doTingB
end_label:
// whatever happens later
分支指令的出现使得流水线执行变回了串行,因为在branch_if_not_equal执行完之前,CPU无法不知道下一步应该是doTingA,还是doTingB。
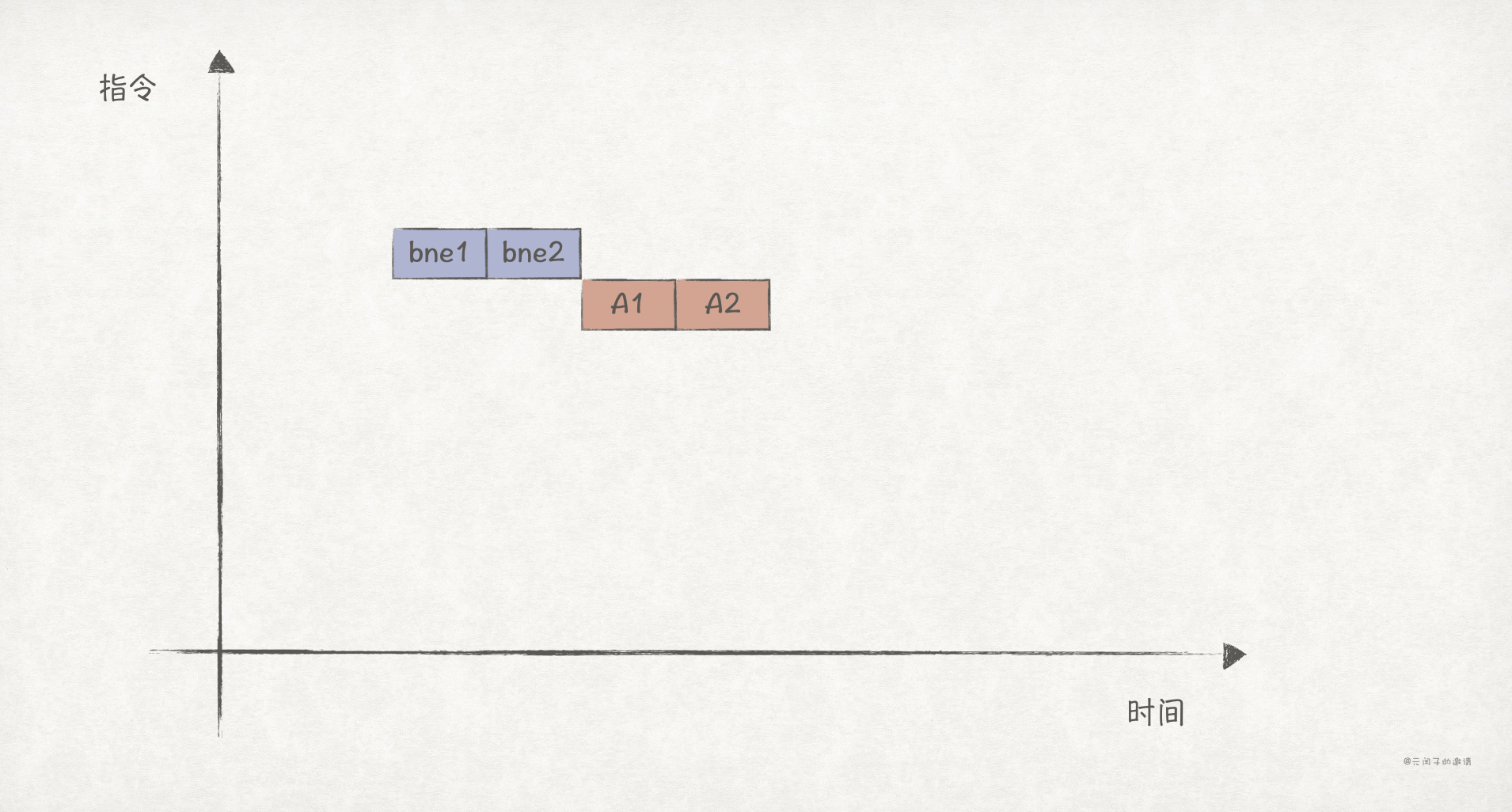
我们可以加入分支预测的机制,提前“猜测”下一条指令,虽然猜错了会有惩罚代价,但只要我们猜得足够准确,CPU的性能就会得到大幅的提升。

分支预测的发展
静态分支预测
静态分支预测机制最简单,可认为是工程师根据大多数程序的特征总结出来的规律,常见的有2种机制:
- Alway taken。每次都执行跳转操作,对循环逻辑效果很好。
- BTFNT。如果目的地址为向前,则选择不跳转,向后则选择跳转。
静态分支预测机制实现简单、硬件开销低,但在复杂的程序上预测成功率低。因此,在现代处理器中占主导地位的为动态分支预测。
动态分支预测
动态分支预测基本都基于分支执行历史进行,这里有个关键前提,分支行为是重复的,这意味着分支行为是可以学习和预测的!
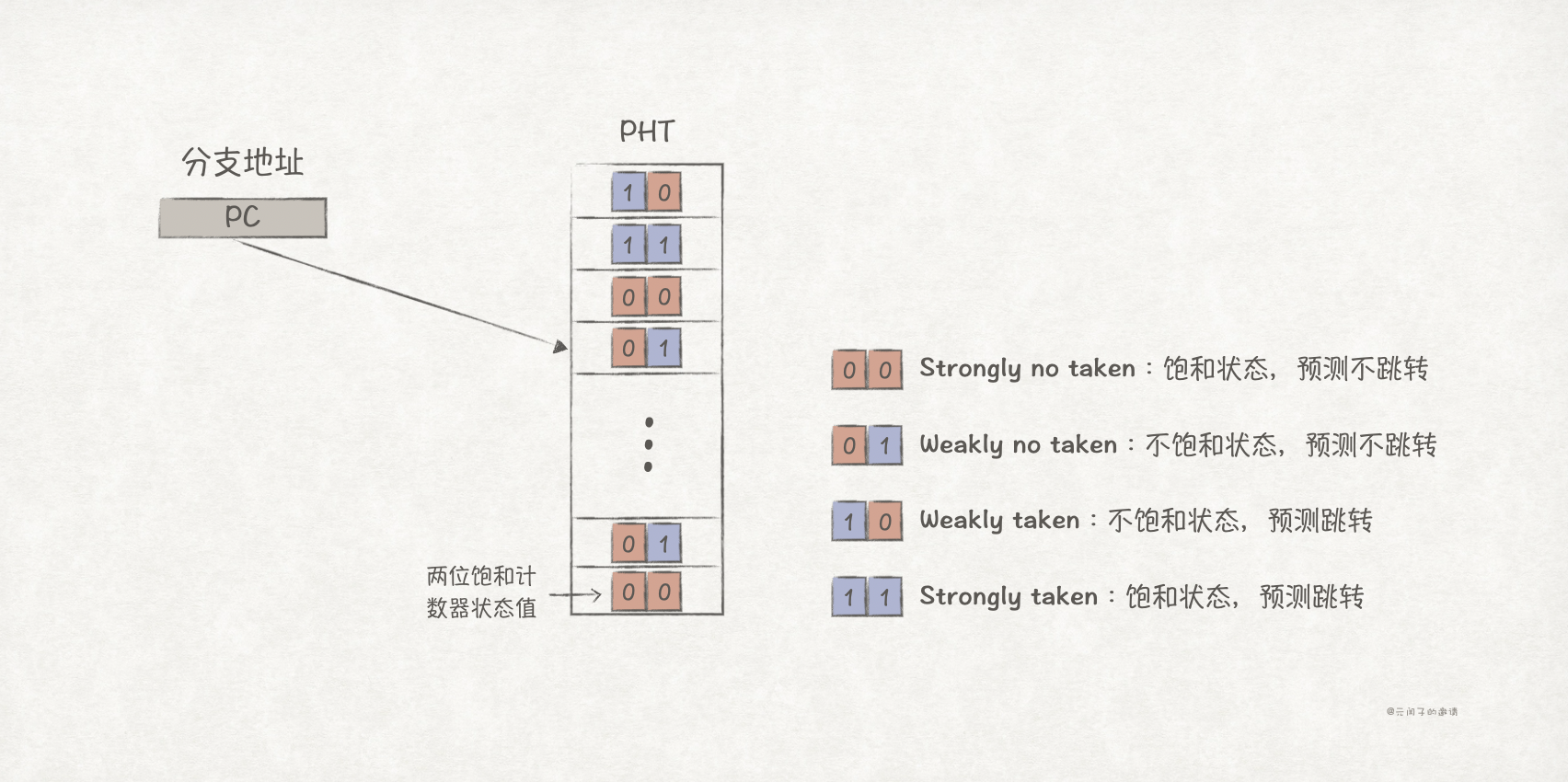
最简单的预测策略是基于最近一次分支执行的结果。在实现上通常使用1 bit来存储最近一次分支执行结果,1表示跳转(taken),0表示不跳转(no taken)。
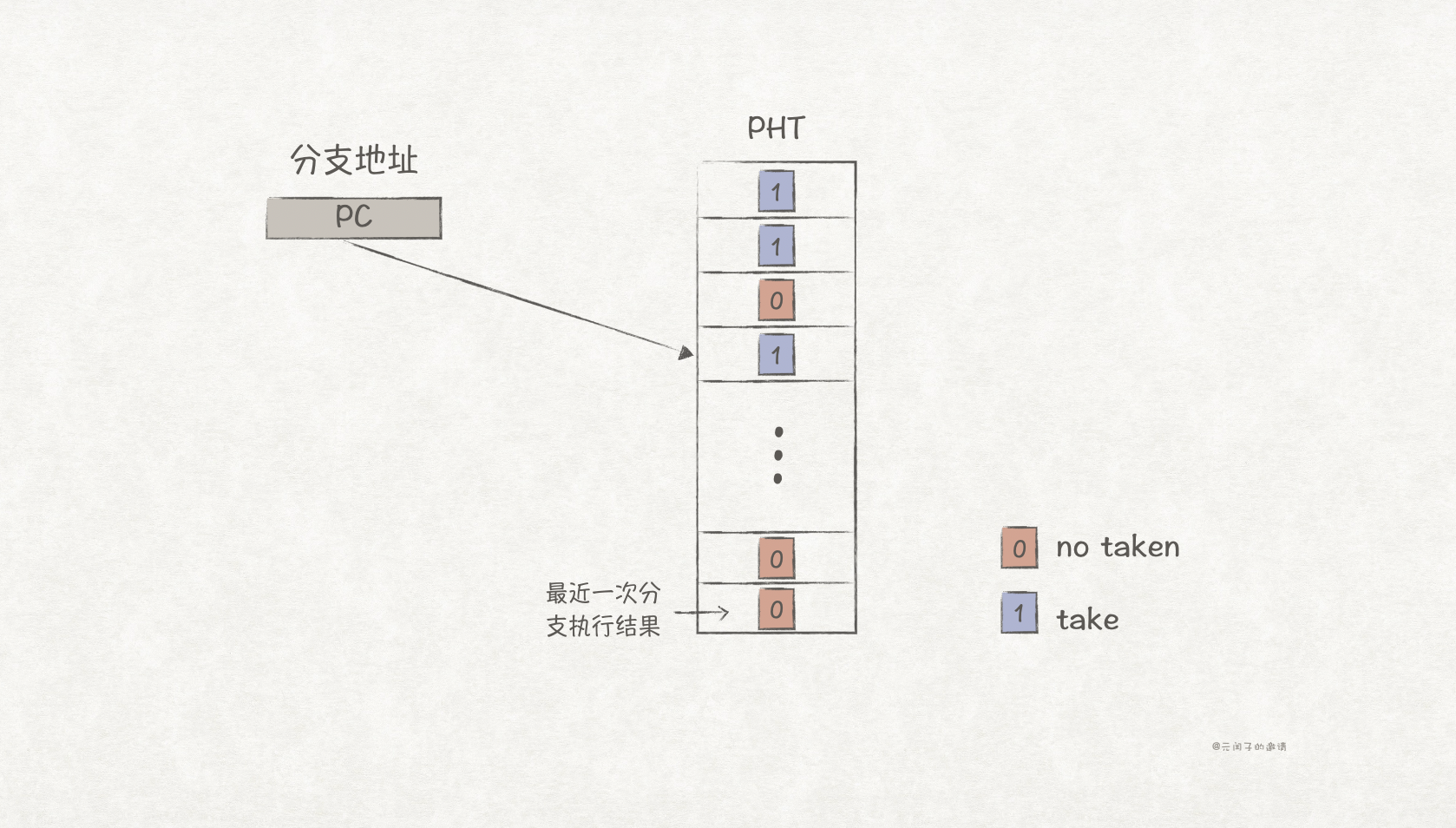
上图中,分支执行历史被存放到PHT(Pattern History Table)上,并通过分支指令的地址(PC)进行索引。
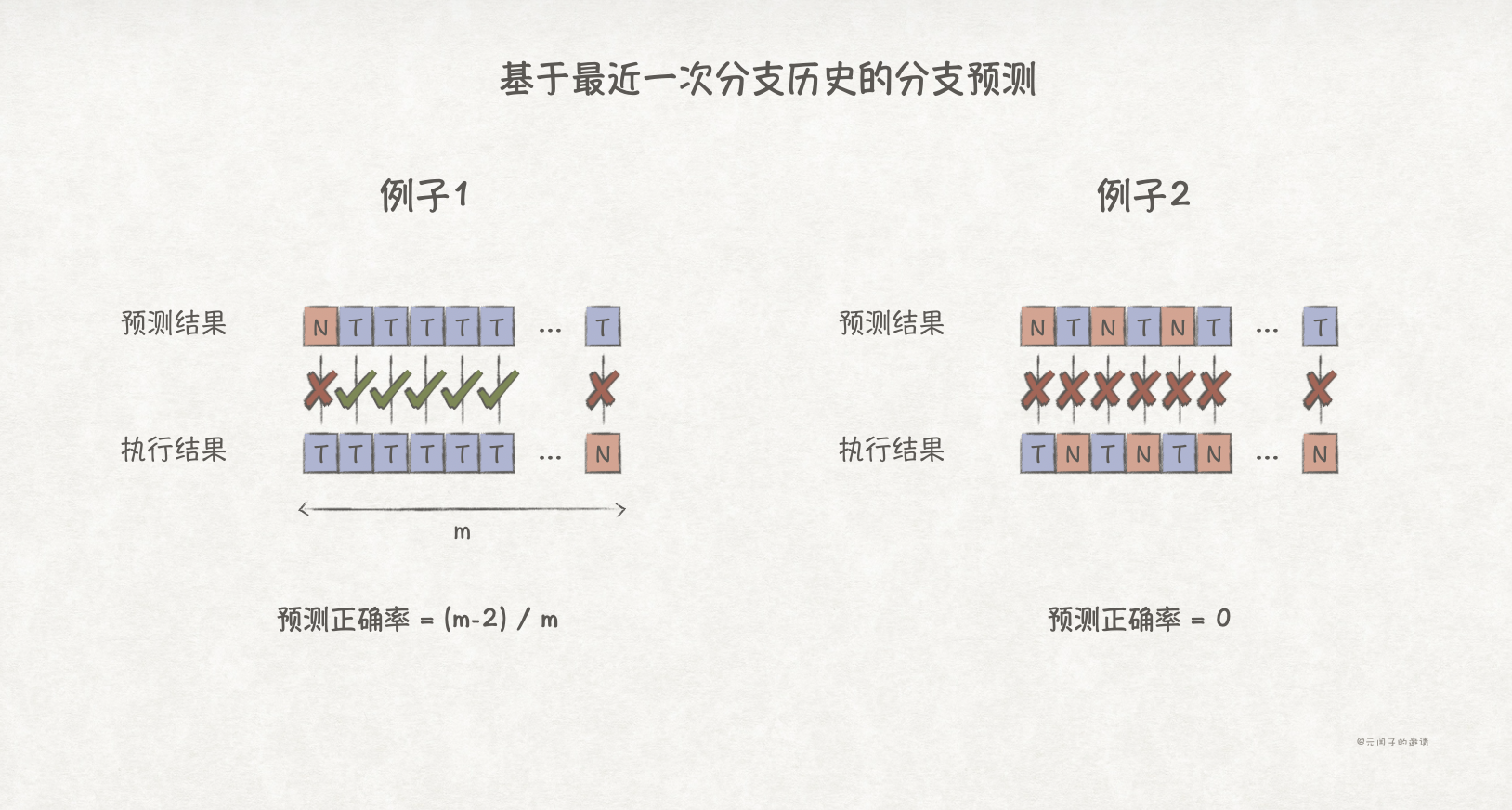
该策略在分支方向变化不频繁的场景能够取得较高的预测成功率,比如下面的例子1:
// 例子1
for(i = 0; i < m; i++) {// 循环体
}
该策略下,只会在首次进入循环,以及出循环时会预测失败,因此,预测准确率为(m-2)/m,当m足够大时,能够取得较好的准确率。
现考虑下面的例子2,该场景下,每次分支方向都不一样:
// 例子2
if (flag) {// doting
}
flag = !flag
在该预测策略下,分支预测准确率会是0!
针对这种分支方向变化频繁的场景,现代处理器通常采用饱和计数器来进行优化。
(1)基于两位饱和计数器的分支预测
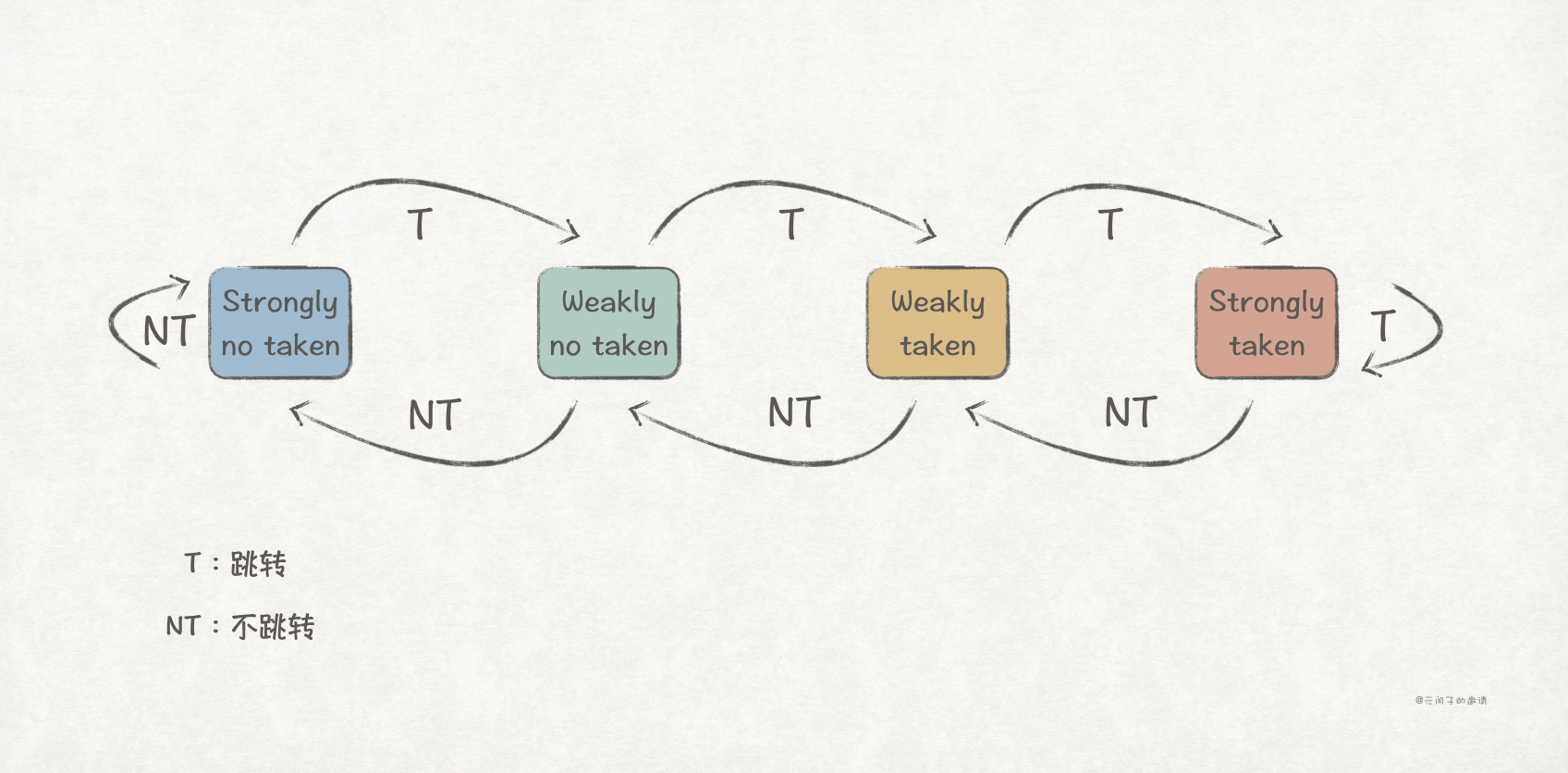
两位饱和计数器的原理是降低分支预测器对分支方向变化的敏感度,它通过2 bit来存储分支预测状态,一共有4种状态:
当计数器处于饱和状态,单次预测失败并不会更改预测方向,只有连续两次预测失败时,才会。
两位饱和计数器的分支预测算法,在预测正确率上要优于基于最近一次结果的预测算法,还是考虑前面2个例子:
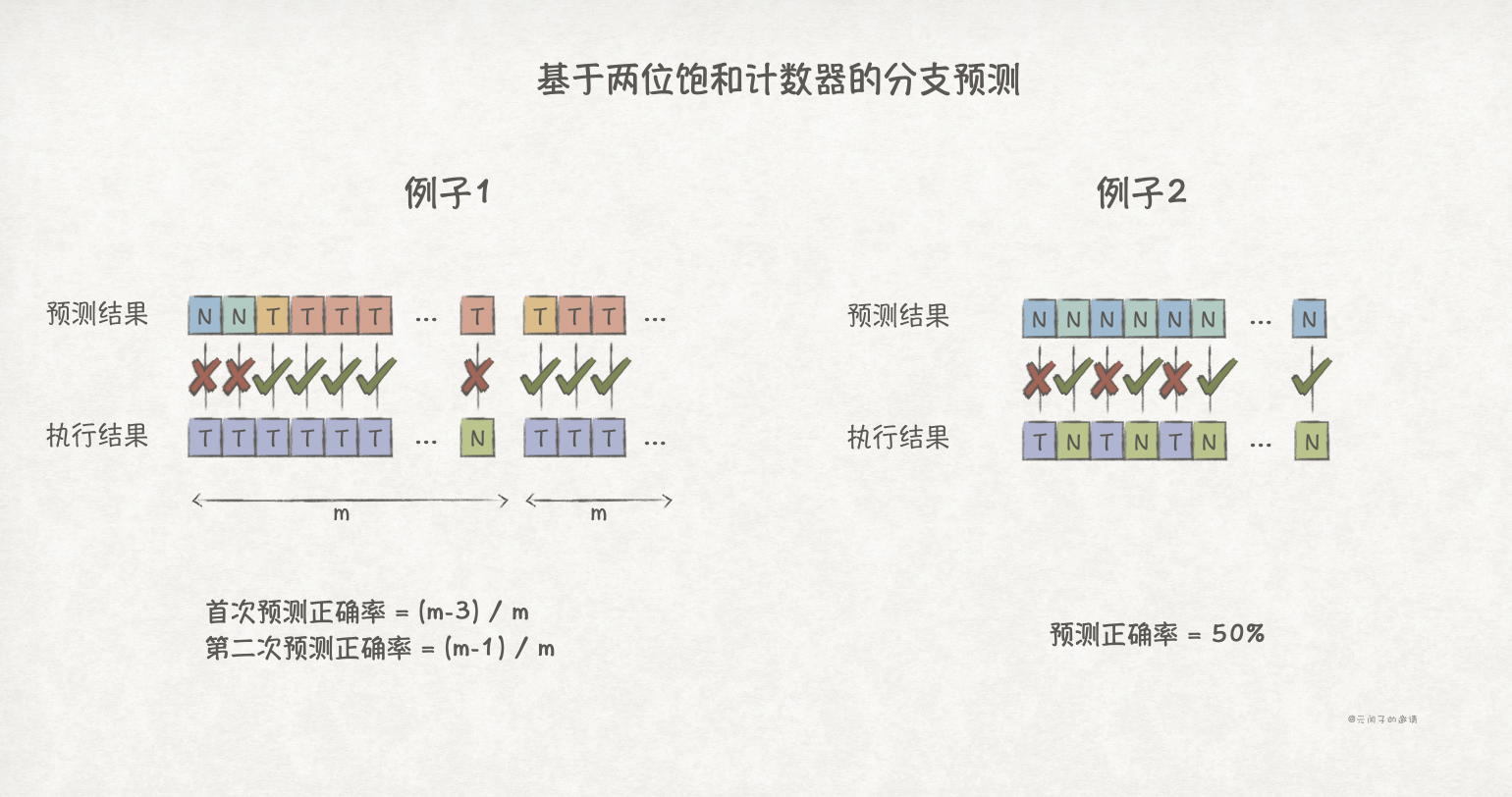
我们选取Strongly no taken作为初始状态,在例子1中第二次进入循环时,预测正确率提升到(m-1)/m;而在例子2中,预测正确率提升到50%。
然而,基于两位饱和计数器的预测正确率有一个极限值,很难达到98%以上的正确率,因此现代处理器并不会直接使用它,而且与其他算法结合使用。
(2)基于局部历史的分支预测
在例子2中,两位饱和计数器虽然有所优化,但也只能达到50%的正确率,仍然无法接受。
理论上,只要分支指令很有规律,应该都能被预测。
为此,我们需要引入一个分支历史寄存器(Branch History Register,BHR)来存储分支的历史状态。一个n bit大小的BHR,可以记录一个分支过去n次的结果。每次执行该分支指令后,就会往BHR的右边插入一次结果,1表示taken,0表示no taken,然后左移一位,将最左边的值移除。
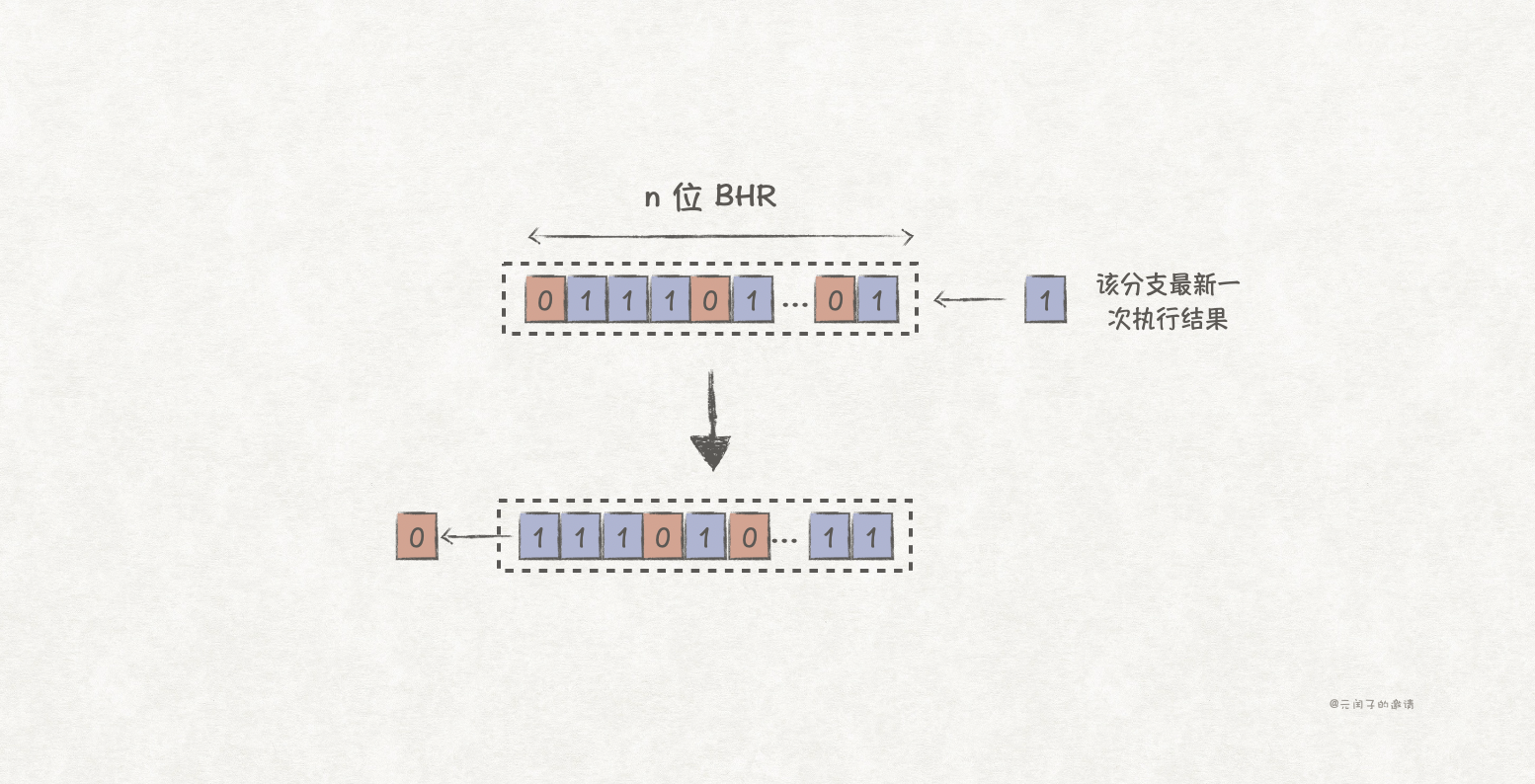
这被称为基于局部历史的分支预测方法,它同时需要一个大小为2*2^n bit大小的PHT去存储每个历史对应的两位饱和计数器值。
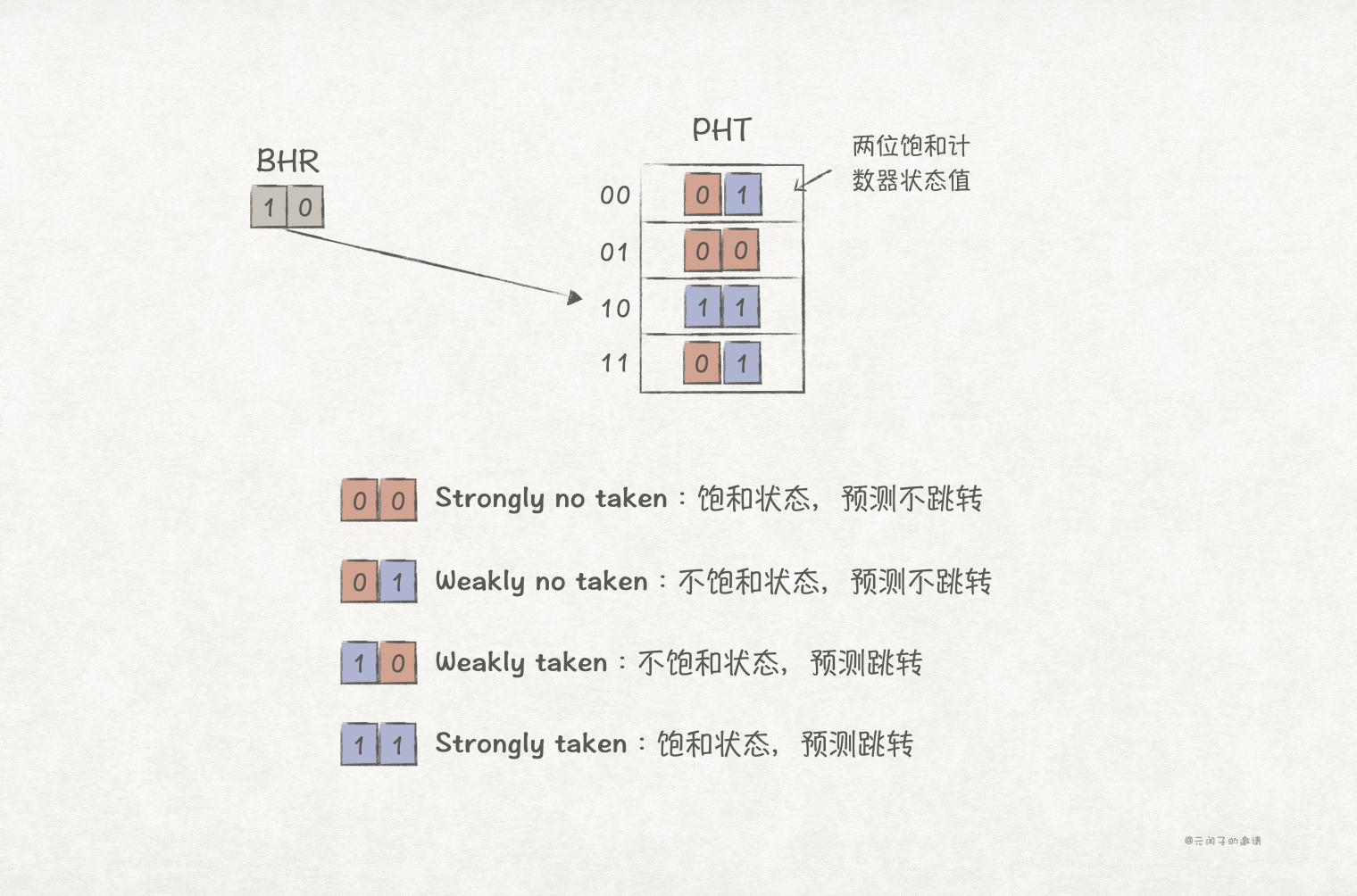
上述图中,我们使用2位的BHR,比如,当它的值为10时,表示过去2次分支结果为taken->no taken。
对于例子2的场景,可以推测出BHR的变化情况为01->10->01->10->...,因此,当BHR值为01时,下一次分支结果必定为0,即不跳转;BHR值为10时,下次必定为1,即跳转。
经过充分预热后,预测正确率能达到100%!
实际上,一个复杂的程序会有很多分支指令,我们不可能为每个分支指令都分配一个BHR和PHT。因此通常只会实现一定大小的BHT和PHT,其中BHT的每一项为BHR。
分支预测时,先通过PC索引到BHR,再根据PC和BHR索引到PHT。在索引PHT表项时,通常会将PC和BHR值进行异或操作,以降低分支冲突的影响。
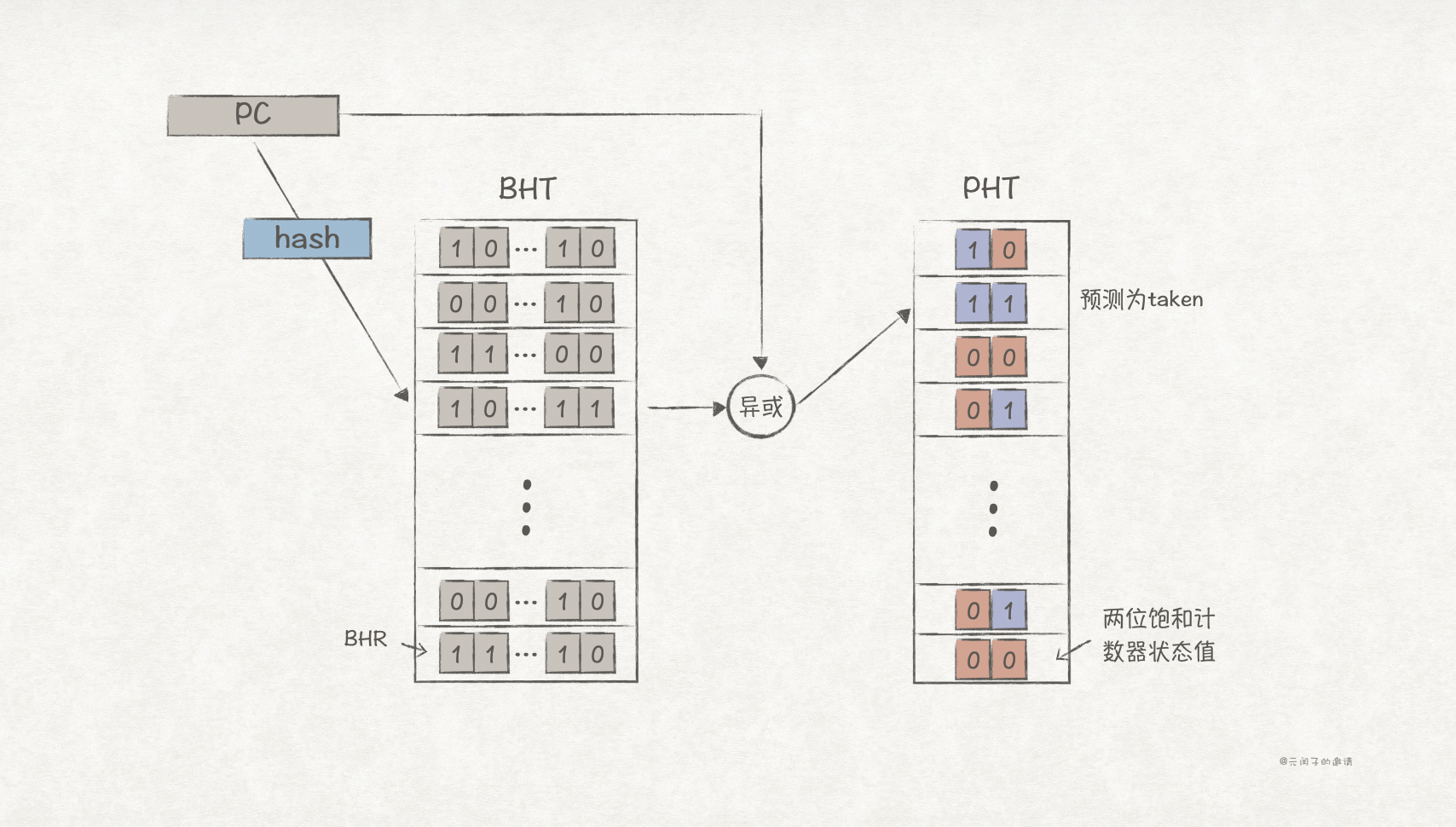
分支冲突会导致PHT重新训练,预测正确率降低。
(3)基于全局历史的分支预测
一个复杂的程序中,很多分支指令是相关的,比如下面的例子3:
// 例子3
if(aa == 2 ) /b1/aa = 0;
if (bb == 2) /b2/bb = 0;
if(aa!= bb) /b3/ …
如果分支b1和b2都跳转了,则分支b3就不会跳转,这时,基于分支b3的局部历史永远无法学习到的规律。
因此,我们需要把分支b1和b2的历史也考虑进来,这就是基于全局历史的分支预测。
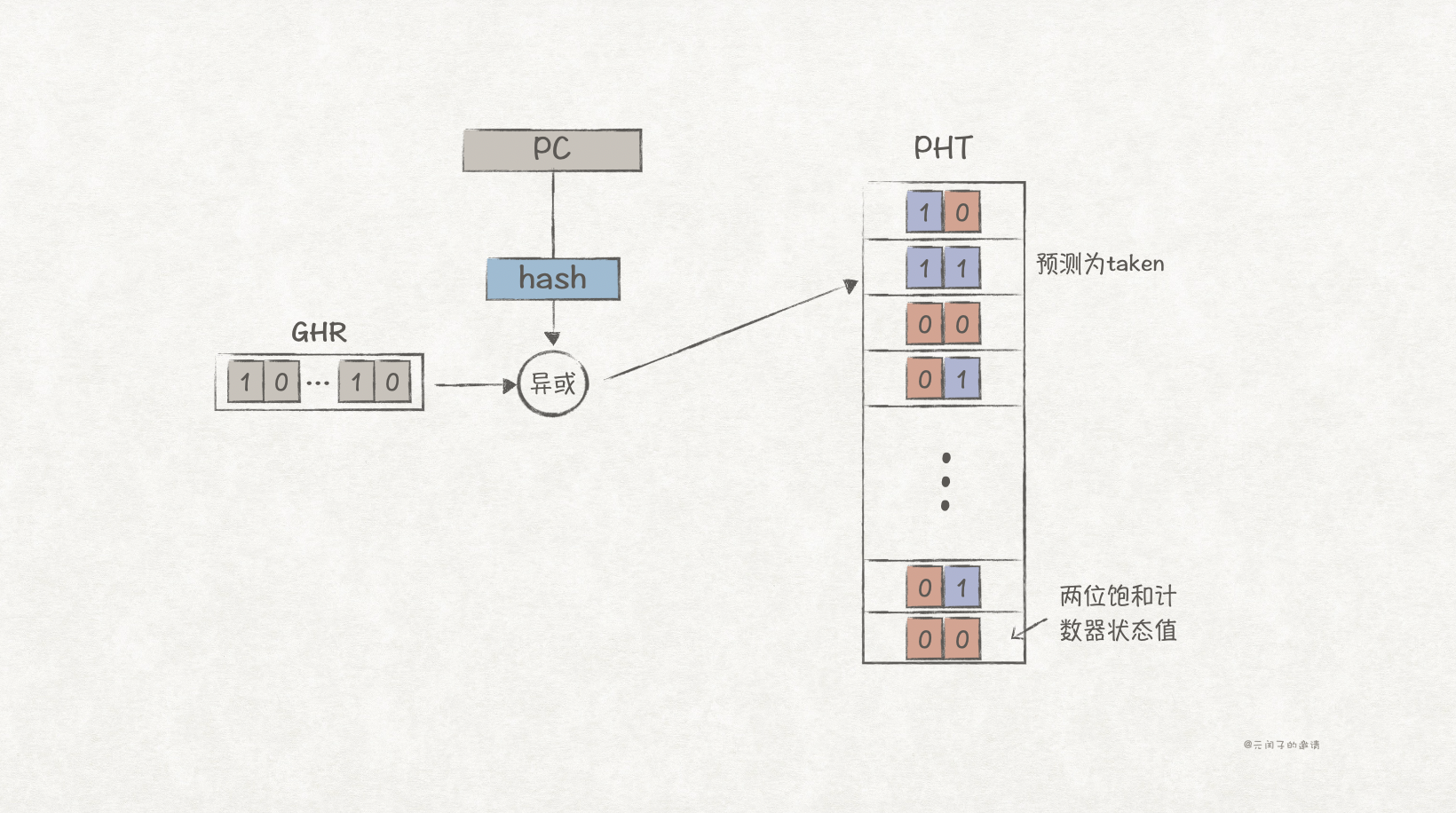
基于全局历史的分支预测需要一个存放过去所有分支执行历史的全局历史寄存器(Global History Register,GHR)。一个n bit大小的GHR能保存过去n次分支执行的历史,每当遇到一个新的分支指令执行后,就会往GHR右边插入执行结果,1表示taken,0表示no taken,然后左移一位。
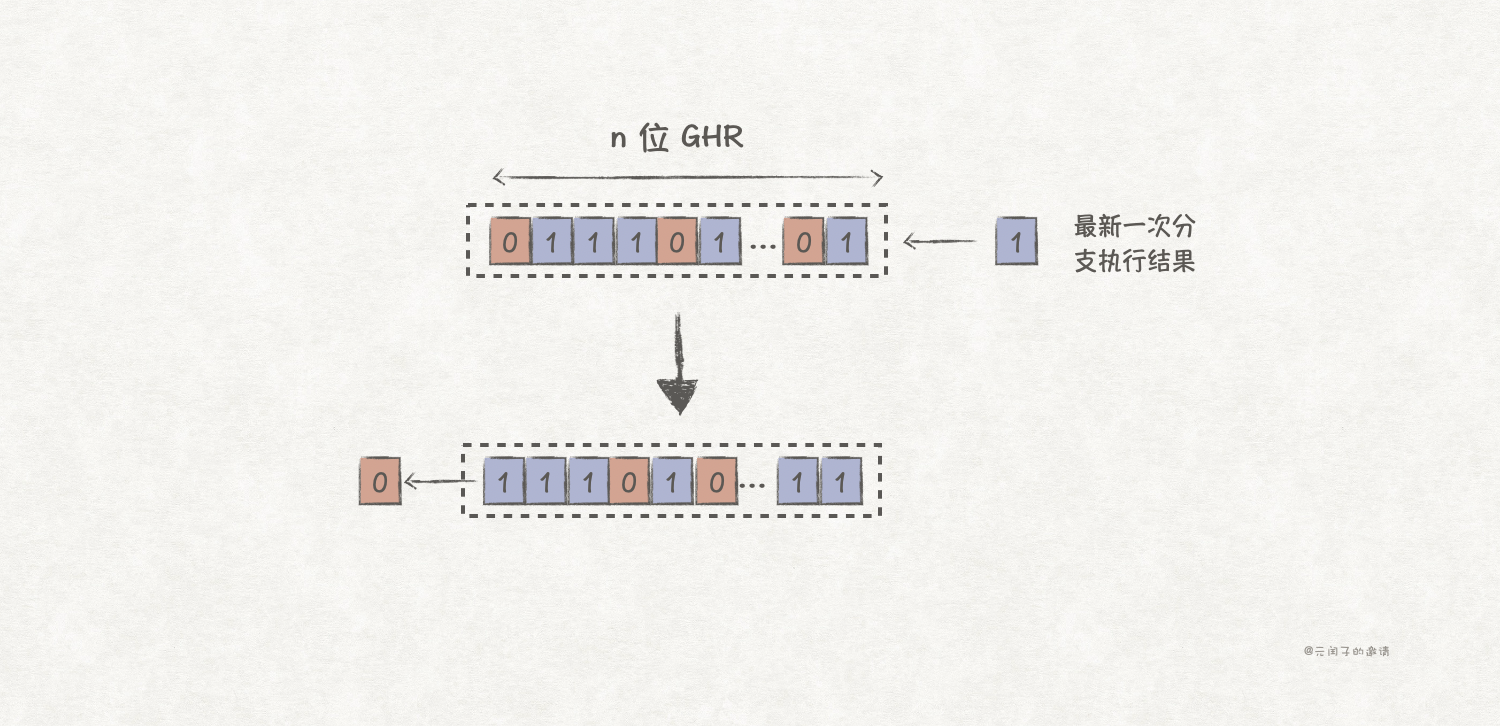
全局历史分支预测与局部历史分支预测实现类似,也需要一个大小为2^n*2 bit大小的PHT去存储对应历史的饱和计数器状态,并根据PC和GHR的值去索引PHT表项。不同点是,它只有一个GHR。
基于全局历史的分支预测算法的一个关键问题是,分支历史记录应该设计成多长?
分支本身的预测难度不尽相同,较长的历史记录可以准确预测一些较难预测的分支;
但,对于一些预测难度低的分支,较长的历史记录一方面会浪费存储空间,另一方面也会使得PHT需要花更长的时间进行预热,从而降低预测正确性。
如果有一种分支预测机制,能够同时兼顾不同预测难度的分支,就好了!
TAGE就是这样的一种分支预测算法。
现代工业界的王者:TAGE分支预测
TAGE可以说是现今最为成功的分支预测算法,它是现在高性能处理器的分支预测器的基础,包括今年最新发布的AMD Zen 5。
那么,为什么TAGE如此受业界欢迎呢?下文我们试着解答这个问题。
TAGE分支预测原理
TAGE的全称是TAgged GEometric history length,即基于带标签的几何级数递增历史长度的分支预测算法,它的两个核心部分为:
- 呈几何级数递增的分支历史长度匹配机制。
- 带标签的索引表项。
TAGE预测期的结构如下图所示:
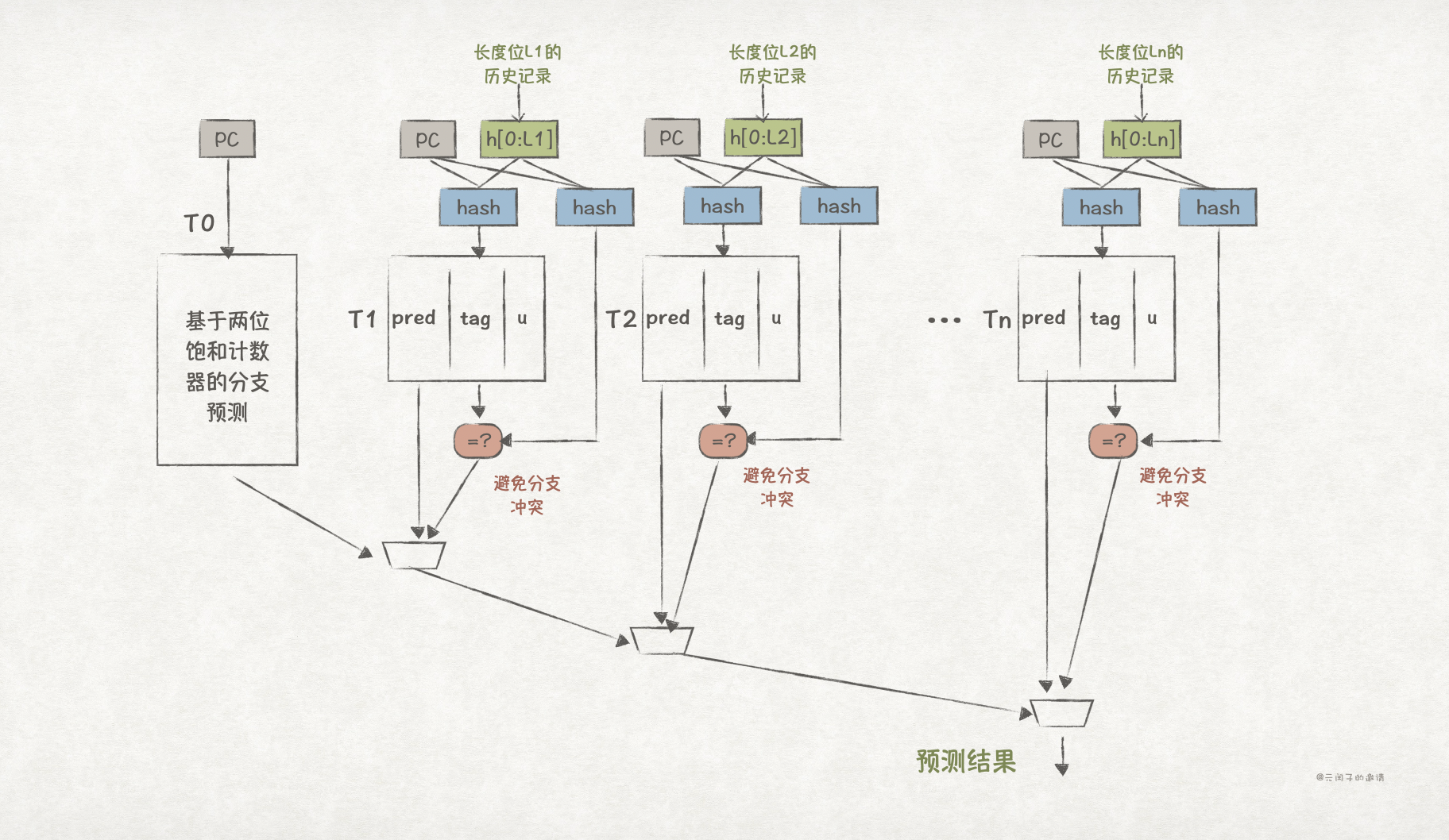
T0表使用分支地址直接索引,表项为两位饱和计数器的状态值,相当于前文介绍的基于两位饱和计数器的分支预测机制。
Tn表使用分支地址和对应历史长度进行哈希索引,表项有3部分组成:
pred是一个3位饱和计数器的状态值,用于标识分支是否跳转;tag是分支地址与分支历史哈希得到的标签信息,用于区分不同的分支;u是一个2位的useful计数器,标识当前表项“有用”程度,0表示无用。
TAGE的预测思想是,每次在Tn表中,选取tag匹配的、u标识为有用的、分支历史长度最长的表项中pred的状态值进行预测;如果无法命中Tn表,则默认使用T0表进行预测。
TAGE详细的预测机制细节本文不再介绍,感兴趣的读者可以参考原论文《A case for (partially)TAggedGEometric history length branch prediction》,或文章《分支预测算法(一):TAGE》
TAGE的变种
TAGE属于基于全局历史的分支预测,因此,一些适合适用局部历史预测的分支,TAGE并不能很好地兼顾。
在分支预测的发展过程中,存在一种称为竞争的分支预测算法,它将全局历史预测器和局部历史预测器结合在一起,相互补充,以此达到一个更好的预测结果。
TAGE也有类似的优化机制,常见的两类辅助器为Loop Predictor(L)和Statistical Corrector(SC),对应的TAGE变体为TAGE-L/TAGE-S/TAGE-SC-L。
Loop Predictor主要用于补偿TAGE在具有固定次数的循环的预测短板;Statistical Corrector则用于补偿不具备相关性的分支预测短板。TAGE-SC-L的结构图如下:
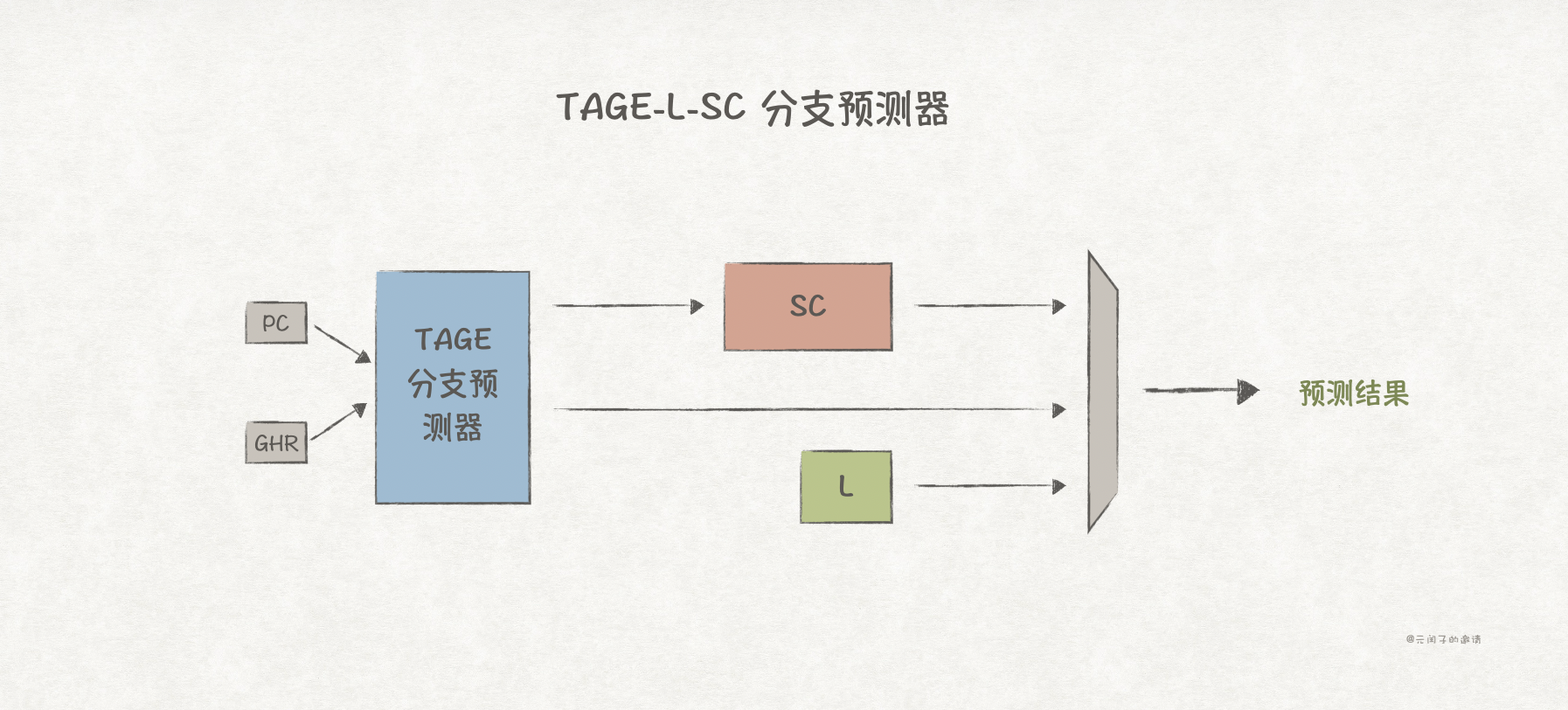
虽然TAGE-SC-L理论上比TAGE具有更高的预测准确率,在主流的商业处理器中却很少应用,因为新增的L和SC部件一方面新增芯片的面积、功耗、验证成本等;另一方面,它比TAGE的预测延迟要更大!
为什么TAGE如此受业界欢迎?
现在,我们可以回答这个问题了,要点如下:
- 通过tag来避免分支冲突。先前的大多数分支预测算法,只是简单地通过分支地址和历史来索引表项,而TAGE在此基础上,增加了一个tag校验机制,从而能够更好地避免分支冲突。
- 能够同时兼顾不同难度的分支预测。通过引入多分支历史长度匹配机制,兼顾不同难度的分支预测。
- 更高的芯片面积效率。通过前两点,TAGE能够达到使用较小的存储实现较高的分支预测准确率,因此有着更高的芯片面积效率。
业界对TAGE的优化从未停止,AMD Zen 5也是如此。
AMD Zen5高性能的秘密:2-ahead分支预测
AMD Zen5新一代分支预测
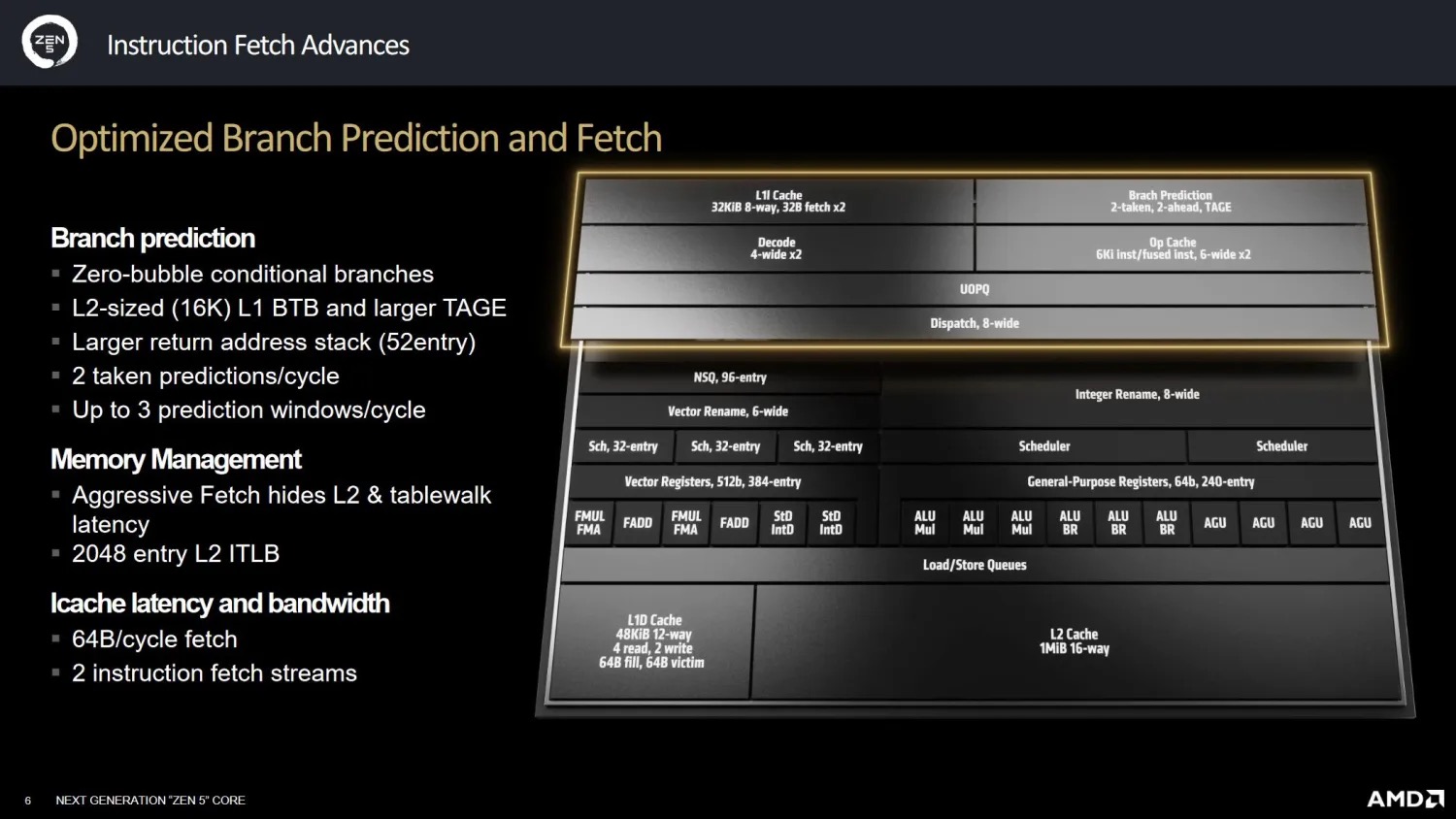
AMD Zen 5针对分支预测做了不少优化,比如,通过更大的TAGE、BTB和RAS(后两者用于分支目标地址的预测)实现更高的预测准确度。
但最重磅的更新是,支持了2-ahead分支预测器,这是Zen系列CPU架构向前发展的重大转变。
目前,很多高性能处理器虽然每周期有2个分支预测窗口,却只能预测1个跳转分支。原因是,假设第一个分支跳转了,那么第二个分支的地址依赖第一个分支的目的地址计算得出,这个过程基本是串行的。而如果第一个分支不跳转,再去预测第二个分支,就很好实现了。
所以,2个分支预测单元在同时预测两个分支,其中一个不跳转,另一个跳转的场景,会有更好的收益。
依此类推,AMD Zen 5扩展到每周期3个分支预测窗口,必然需要每周期能够预测2个跳转分支,否则性能收益很小。
那么,Zen 5是如何做到每周期预测2个跳转分支的呢?答案是,2-ahead分支预测。
一个源于30年前的想法
现代编译器会将指令按照基本块(basic block)组织起来,一个基本块有唯一的入口,其他分支指令只能跳转至该入口;而基本块里的指令是连续执行的,分支指令只能出现在基本块最后一条指令。
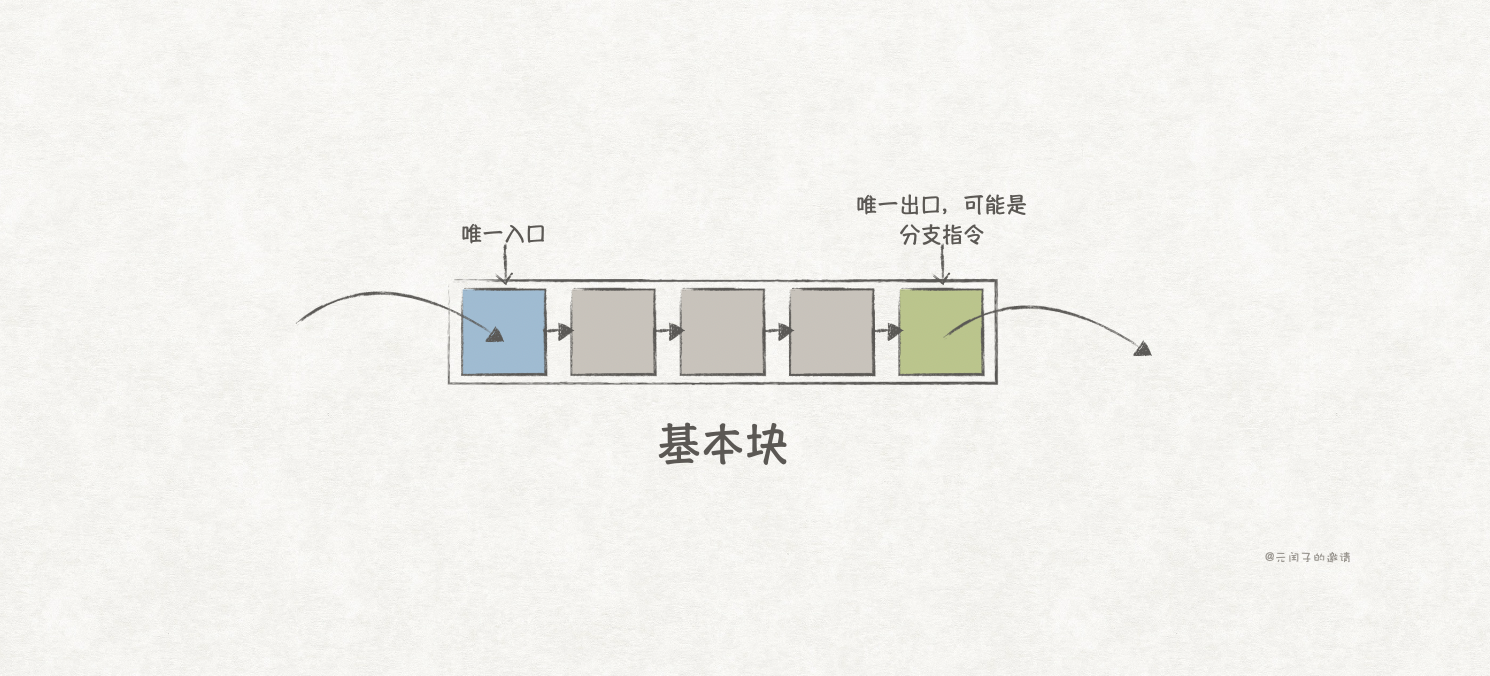
假设现在有4个基本块,A,B,C和D,并且顺序执行,即,A的最后一条为分支指令,跳转到B,同理,B跳转到C,C跳转到D。
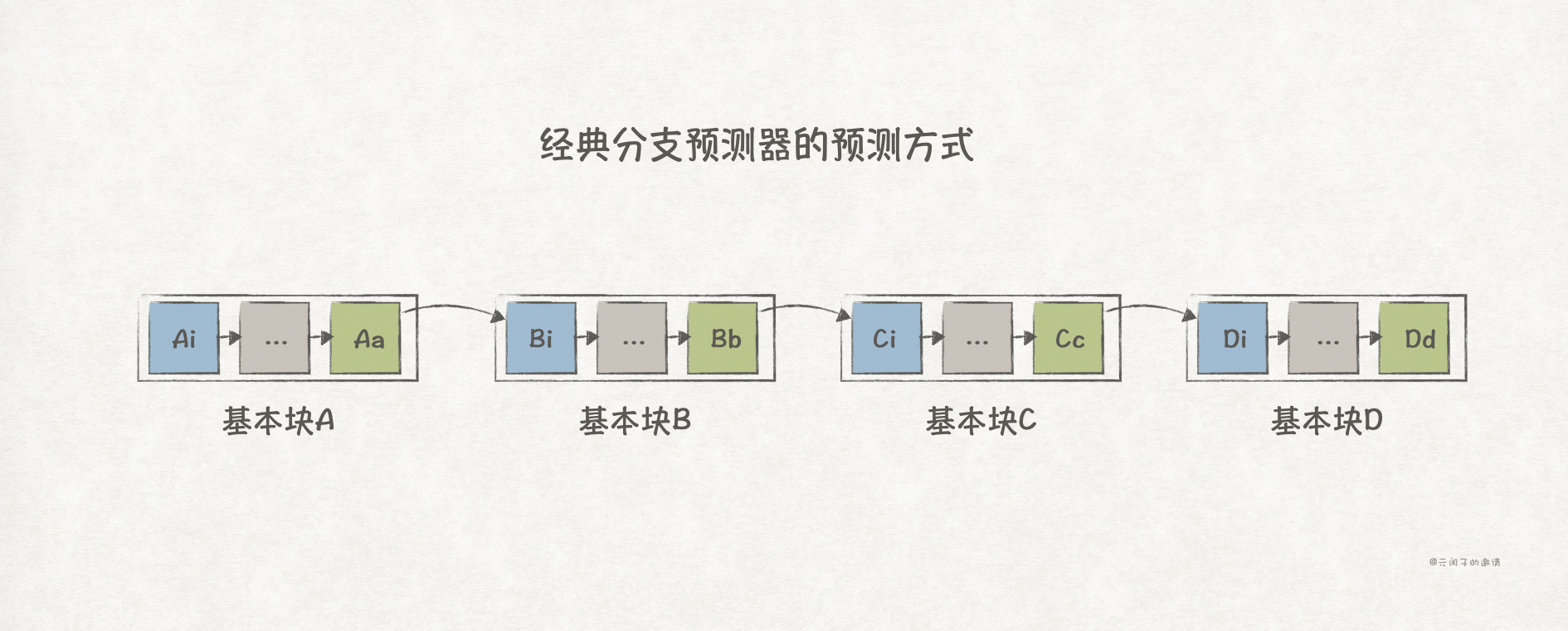
经典的分支预测算法是,用A去预测B,再用B预测C,最后用C去预测D,这样,每周期只能预测1个跳转分支。
而在1996年的论文《Multiple-Block Ahead Branch Predictors》论文中,给出了一种通用的每周期预测2个跳转分支的方法,称为2-ahead分支预测器。
它能够实现用A去预测C,用B去预测D,这样,每周期就能同时预测2个跳转分支!
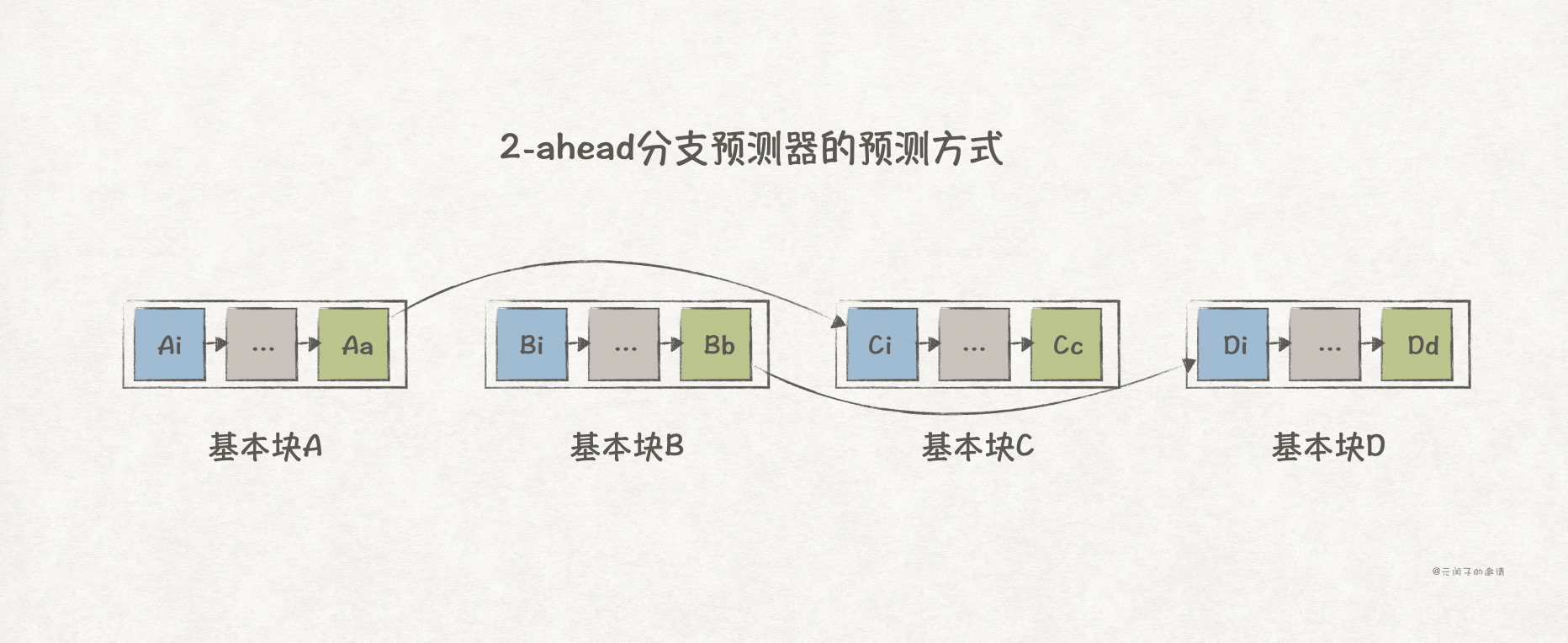
当然,这样的设计需要CPU能够支持每周期获取2个基本块(double I-fetch processor),且BTB等存储结构也需要支持双端口读取(dual-ported memory structures)。
论文提到,2-ahead分支预测器能够适配其他任何“1-ahead”的分支预测算法,并且能够做到预测准确率相同!
对2-ahead预测机制细节感兴趣的读者,可以直接阅读论文原文,本文不再详述。
根据AMD Zen 5现有的资料可推测,它的分支预测器就是2-ahead与TAGE的结合:在TAGE预测算法的基础上,实现每周期预测2个跳转分支,因此性能得到更进一步的提升!
为什么2-ahead至今才实现?
既然2-ahead能带来性能收益,那为什么直到Zen 5才首次商业落地呢?原因个人猜测有2点:
其一,2-ahead分支预测算法需要一定的硬件支持,以前的工艺无法满足。举个例子,论文里实验数据表明,当dispatch为8-width时,2-ahead能够带来最好的性能收益,而AMD Zen系列架构,在Zen 5才首次支持8-width dispatch。
其二,虽然2-ahead在90s年代就被提出,但随后CPU往多核CPU方向发展,每个核的大小称为芯片设计的重要因素,因此大家主要投入在具有极高面积效率的TAGE算法上。而近年来,单个CPU已经能做到上百个核,单核性能重新被关注起来,像2-ahead这类能够提升单核性能的古老算法重新浮出水面。
最后
本文从经典的分支预测算法讲起,先是引出了现代工业界的王者,TAGE分支预测器;然后介绍了AMD Zen 5在分支预测器上的重大优,2-ahead分支预测器。读完全文,希望读者能对分支预测的原理和发展有一个较为清晰的了解。
分支预测是一个很大的课题,本文不可能做到面面俱到,如果读者感兴趣,可详细阅读参考列表中的学习资料。
文章配图
可以在 用Keynote画出手绘风格的配图 中找到文章的绘图方法。
参考
[1] 超标量处理器设计, 姚永斌
[2] Multiple-Block Ahead Branch Predictors, Seznec等
[3] Zen 5’s 2-Ahead Branch Predictor Unit: How a 30 Year Old Idea Allows for New Tricks, George Cozma/Camacho
[4] 现代分支预测:从学术界到工业界, Easton Man
[5] 分支预测算法(一):TAGE, SunnyChen
[6] Branch prediction, Patreon
[7] 分支预测的 2-taken 和 2-ahead, 杰哥的{运维,编程,调板子}小笔记
[8] Why TAGE is the best, rustam
[9] Zen 5’s Leaked Slides, Chester Lam
更多文章请关注微信公众号:元闰子的邀请