GPU释放威力:在Gymnasium环境中使用稳定基线3在AMD GPU上训练强化学习代理
GPU Unleashed: Training Reinforcement Learning Agents with Stable Baselines3 on an AMD GPU in Gymnasium Environment — ROCm Blogs

2024年4月11日 作者: Douglas Jia.
本博客将深入探讨深度强化学习的基本原理,通过一个实用的代码示例,指导您如何利用AMD GPU在Gymnasium环境中训练深度Q网络(DQN)策略。
您可以在 Github repo中找到本博客提到的所有文件。
介绍
什么是强化学习
强化学习(Reinforcement Learning,简称RL)是一种强大的机器学习范式,其核心思想是训练智能体在动态环境中做出连续决策。与监督学习不同,RL智能体通过与环境的互动,根据所采取的行动接收奖励或惩罚形式的反馈。强化学习的根本目标是让智能体学习一种策略,将状态映射到行动的方式,以增加预期奖励。学习过程包括智能体探索环境、做出决策、观察结果,并根据所获得的反馈调整其策略。这种探索与利用的迭代循环使RL智能体能适应变化的条件,学习复杂的决策策略,最终优化其行为以实现长期目标。强化学习在各个领域有广泛的应用,从机器人技术和游戏到金融和自主系统,智能体可以在复杂和动态的场景中自主学习并改善其决策能力。
深度学习如何发挥作用
在强化学习 (RL) 中,深度学习能够解决由高维状态空间带来的挑战,并提升函数(即状态-行动值函数或策略)近似。这在具有广泛或连续状态空间的环境中尤为重要,尤其是当这些环境由高维输入(如图像)表示时。神经网络凭借其相互连接的神经元层,擅长从原始数据中自动学习层次表示。这种能力对于捕捉决策所需的复杂模式至关重要。深度 RL 算法,如 DQN 或策略梯度方法,利用深度学习的力量来泛化各种状态,使其非常适合传统方法可能难以应对的真实世界应用。深度学习和RL的协同,使得训练出的代理能够在动态和多样化的环境中掌握复杂任务。具体来说,深度强化学习系统的输入通常是来自环境的观测值,目标是学习一个策略(由神经网络表示),该策略输出动作以在一段时间内最大化累积奖励。学习过程涉及根据从环境中收到的奖励形式的反馈来优化策略的参数。
如果你想深入了解深度强化学习,你可以访问 Hugging Face 提供的深度强化学习课程 .
什么是Gymnasium和Stable Baselines3?
想象一下一个供人工智能运动员使用的虚拟操场——这就是Gymnasium!Gymnasium是OpenAI的Gym库的一个维护分支。这个开源工具包提供了各种虚拟环境,从平衡Cartpole机器人到导航Lunar Lander挑战。这里是你的AI代理通过实际操作学习的地方。
但训练这些运动员需要一个有经验且技巧娴熟的教练。这时,Stable Baselines3就登场了。这个包为你提供了现成的强化学习算法,从DQN到策略梯度。你可以把它看作一个装满了经过验证的训练技术的工具箱,随时可以在Gym的多样环境中释放你的AI代理的全部潜力。
本质上,Gymnasium是应用Stable Baselines3提供的深度学习算法来学习和优化策略的环境。为了提高训练过程的效率,我们利用了AMD GPU的强大性能。在下面的代码示例中,我们将展示通过这种方法可以实现的加速效果。
代码示例:训练一个赛车代理
实现环境
我们使用一块 AMD GPU,并安装了 PyTorch 2.0.1 和 ROCm 5.7.0 来实现代码示例(具体使用的 Docker 镜像)。关于支持的操作系统和硬件列表,请参阅此 ROCm 文档页面。我们建议您在具有 AMD GPU 的机器上使用下面的代码块,拉取预装有 ROCm 和 PyTorch 的 Docker 镜像。
docker run -it --ipc=host --network=host --device=/dev/kfd --device=/dev/dri \--group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined \--name=rl-gym rocm/pytorch:rocm5.7_ubuntu22.04_py3.10_pytorch_2.0.1 /bin/bash
要开始这个示例,我们需要安装运行此代码示例所需的 Python 包。
%%capture!pip install stable-baselines3 gymnasium[all]
Gymnasium 环境
我们将使用 Gymnasium 中具有离散动作空间的 CarRacing-v2 环境。有关此环境的详细信息,请参阅 官方文档. 。Gymnasium 中的 Car Racing 环境是一种模拟环境,旨在训练强化学习代理进行汽车赛车。该环境的主要目标是让代理有效地导航赛道,考虑速度、转向和刹车等因素,同时最大化累积奖励。CarRacing 中的状态空间包括以 RGB 图像表示的视觉观测,为代理提供有关当前环境状态的信息。离散动作空间由 5 个动作组成:`0: 什么都不做`, 1: 左转向, 2: 右转向, 3: 加速, 4: 制动,允许代理控制汽车的运动。奖励函数可以从官方文档 here中找到。
因此,挑战在于学习一种策略,使代理能够有效地驾驶汽车通过赛道,避开障碍物,并根据环境中定义的奖励结构实现最佳性能。
通过下面的代码块,您可以输出动作空间、观测空间和其他环境规格。
import gymnasium as gym
env = gym.make("CarRacing-v2", domain_randomize=True, continuous=False)print("Action Space:", env.action_space)# 注意,在输出的观测空间 Box(0, 255, (96, 96, 3), uint8) 中,
# 0 和 255 分别表示该 (96, 96, 3) 数组中数值的下限和上限。print("Observation Space: ", env.observation_space)print("Env Spec: ", env.spec)
输出:
Action Space: Discrete(5)Observation Space: Box(0, 255, (96, 96, 3), uint8)Env Spec: EnvSpec(id='CarRacing-v2', entry_point='gymnasium.envs.box2d.car_racing:CarRacing', reward_threshold=900, nondeterministic=False, max_episode_steps=1000, order_enforce=True, autoreset=False, disable_env_checker=False, apply_api_compatibility=False, kwargs={'domain_randomize': True, 'continuous': False}, namespace=None, name='CarRacing', version=2, additional_wrappers=(), vector_entry_point=None)
接下来,我们将通过一个随机做出动作决策的代理向您展示 Gymnasium 环境是如何工作的。代理将做 10 个连续动作。实现每个动作后,环境将返回:
-
下一次观测(或状态)
-
执行该动作的奖励
-
环境是否由于满足预定义条件而终止或截断
-
有关步骤的信息,例如度量和调试信息。
import gymnasium as gym# 首先,我们创建一个名为 CarRacing-v2 的环境。
env = gym.make("CarRacing-v2", domain_randomize=True, continuous=False)# 然后我们重置这个环境
observation, info = env.reset()for _ in range(10):# 从动作空间中随机选择一个动作。action = env.action_space.sample()# 在环境中执行这个动作并获取# next_state, reward, terminated, truncated and infoobservation, reward, terminated, truncated, info = env.step(action)print(f"Action taken: {action}, reward: {reward}.")# 如果游戏终止(在我们的情况下是着陆、碰撞)或截断(超时),# 重置环境。if terminated or truncated:# 重置环境print("Environment is reset")observation, info = env.reset()env.close()
输出:
Action taken: 0, reward: 7.1463768115942035. Action taken: 4, reward: -0.09999999999999964. Action taken: 1, reward: -0.09999999999999964. Action taken: 0, reward: -0.09999999999999964. Action taken: 4, reward: -0.09999999999999964. Action taken: 1, reward: -0.09999999999999964. Action taken: 4, reward: -0.09999999999999964. Action taken: 4, reward: -0.09999999999999964. Action taken: 2, reward: -0.09999999999999964. Action taken: 0, reward: -0.09999999999999964.
根据输出,可以看到大多数随机动作都会导致负奖励。
使用Stable Baselines3训练智能代理
显然,依赖随机动作不会在这款赛车游戏中取得成功。我们的目标是通过从环境中学习知识来训练深度神经网络,使其能够做出最大化累积奖励的动作选择。
在这个特定的环境中,我们将使用带有卷积神经网络(CNN)的DQN来训练智能代理。通过最小化预测的Q值与目标Q值之间的时间差误差来训练DQN。CNN架构用于处理原始像素输入(游戏帧或观察状态)并提取有用的特征来进行预测。
import gymnasium as gym from stable_baselines3 import DQN from stable_baselines3.common.callbacks import EvalCallback
from typing import Callable# 在我们的实验中,使用逐渐减小学习率的线性调度比使用固定学习率表现更好。 def linear_schedule(initial_value: float) -> Callable[[float], float]:"""线性学习率调度:param initial_value: 初始学习率:return: 根据剩余进度计算当前学习率的调度"""def func(progress_remaining: float) -> float:"""进度将从1(开始)减少到:param progress_remaining:剩余进度:return: 当前学习率"""return progress_remaining * initial_valuereturn func
要了解以下单元格输出中的每个度量意味着什么,你可以访问 this page 。请注意,我们已经简化了输出以节省页面空间。然而,你仍然可以看到代理逐渐获得环境知识,并对应地在以下显示的输出中增加奖励。
import osenv = gym.make("CarRacing-v2", domain_randomize=True, continuous=False)# 设置种子以确保可复现性
env.reset(seed=1234)
env.action_space.seed(123)# 实例化代理并指定Tensorboard日志的目录。
# 过Tensorboard日志,我们可以监控模型的训练进度。
model = DQN('CnnPolicy', env, verbose=1, device="cuda", learning_rate=linear_schedule(0.0001), tensorboard_log="./dqn_carrace_tensorboard_lr0001_1e7/")
# 指定保存最佳模型的目录。
dnq_path = os.path.join('./Saved_Models/dqn_best_model_lr0001_1e7')# EvalCallback定期评估代理的性能,使用一个独立的测试环境。如果
# 指定了best_model_save_path文件夹,它将保存最佳模型。
eval_env = model.get_env()
eval_callback = EvalCallback(eval_env=eval_env, best_model_save_path=dnq_path,n_eval_episodes=50,eval_freq=100000,verbose=1,deterministic=True, render=False)# 训练代理
model.learn(total_timesteps=10000000,callback=eval_callback)# 指定保存最终模型的路径
final_path = os.path.join('./Saved_Models/dqn_final_model_lr0001_1e7')
model.save(final_path)
Using cuda device Wrapping the env with a `Monitor` wrapper Wrapping the env in a DummyVecEnv. Wrapping the env in a VecTransposeImage. Logging to ./dqn_carrace_tensorboard_lr0001_1e7/DQN_1 ---------------------------------- | rollout/ | | | ep_len_mean | 1e+03 | | ep_rew_mean | -52.4 | | exploration_rate | 0.996 | | time/ | | | episodes | 4 | | fps | 167 | | time_elapsed | 23 | | total_timesteps | 4000 | ---------------------------------- ---------------------------------- | rollout/ | | | ep_len_mean | 1e+03 | | ep_rew_mean | -52.7 | | exploration_rate | 0.992 | | time/ | | | episodes | 8 | | fps | 167 | | time_elapsed | 47 | | total_timesteps | 8000 | ---------------------------------- ---------------------------------- | rollout/ | | | ep_len_mean | 1e+03 | | ep_rew_mean | -53.9 | | exploration_rate | 0.989 | | time/ | | | episodes | 12 | | fps | 167 | | time_elapsed | 71 | | total_timesteps | 12000 | ----------------------------------... ... ...---------------------------------- | rollout/ | | | ep_len_mean | 960 | | ep_rew_mean | 844 | | exploration_rate | 0.05 | | time/ | | | episodes | 4060 | | fps | 91 | | time_elapsed | 43427 | | total_timesteps | 3966401 | | train/ | | | learning_rate | 6.03e-05 | | loss | 0.669 | | n_updates | 979100 | ---------------------------------- ---------------------------------- | rollout/ | | | ep_len_mean | 960 | | ep_rew_mean | 846 | | exploration_rate | 0.05 | | time/ | | | episodes | 4064 | | fps | 91 | | time_elapsed | 43456 | | total_timesteps | 3970095 | | train/ | | | learning_rate | 6.03e-05 | | loss | 0.838 | | n_updates | 980023 | ----------------------------------
在加载TensorBoard文件后 (请参考 this tutorial 进行指导), 查看`eval/mean_reward`下的奖励,你会注意到在完成大约350万次训练步数后,奖励收敛到约870分。这是一个值得注意的成就,尤其是考虑到理论上的最高奖励在1000以下。请注意,黑线和亮线实际上基于同一组数据。黑线是亮线的平滑版本(基于原始数据),可以更好地反映整体趋势。
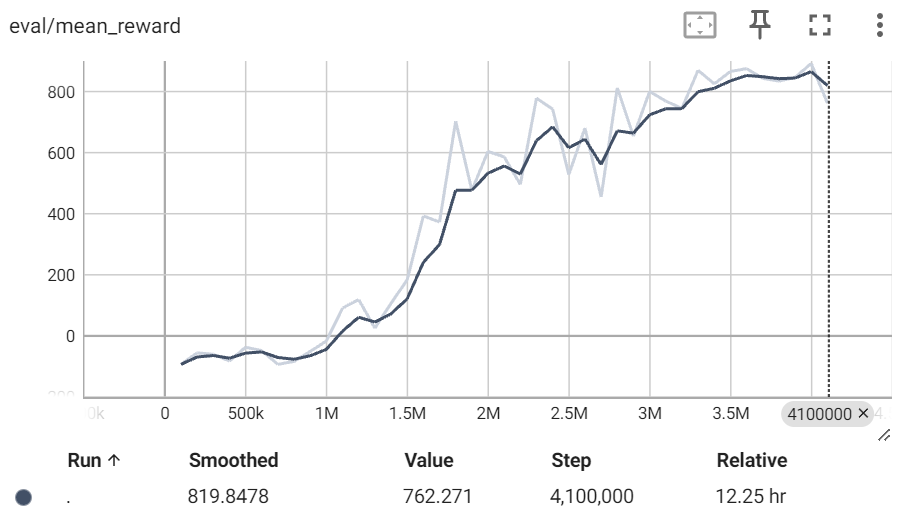
你可以在`src`文件夹中找到我们保存的最佳模型,文件名为`best_model.zip`,以及TensorBoard文件。使用这个模型文件,你可以加载并使用它来以最高累计奖励玩游戏。
可视化赛车
现在,让我们深入到令人兴奋的部分! 我们可以在卡通设置中直观地比较训练好的智能体与随机选择动作的效果。
随机动作的智能体
在本节中,我们将让智能体从动作空间中随机选择动作。正如卡通中所展示的,当随机选择动作时,汽车移动缓慢且始终获取负奖励(卡通左下角显示累积奖励)。
%%capture # 通过以下命令来安装依赖项。如果你已经安装了 ffmpeg,可以跳过这一步。 !sudo apt update -y && sudo apt upgrade -y !sudo apt install ffmpeg -y
import gymnasium as gym
from matplotlib import rcParams
from matplotlib import pyplot as plt, animation
from IPython.display import HTML
from stable_baselines3 import DQN
rcParams['animation.embed_limit'] = 2**128# 定义一些用于生成和保存卡通的实用函数。
def create_anim(frames, dpi, fps):plt.figure(figsize=(frames[0].shape[1] / dpi, frames[0].shape[0] / dpi), dpi=dpi)patch = plt.imshow(frames[0])def setup():plt.axis('off')def animate(i):patch.set_data(frames[i])anim = animation.FuncAnimation(plt.gcf(), animate, init_func=setup, frames=len(frames), interval=fps)return animdef display_anim(frames, dpi=72, fps=60):anim = create_anim(frames, dpi, fps)return anim.to_jshtml()def save_anim(frames, filename, dpi=72, fps=50):anim = create_anim(frames, dpi, fps)anim.save(filename)
env = gym.make("CarRacing-v2", domain_randomize=True, continuous=False, render_mode='rgb_array')# 使用随机动作生成一个回合的观察结果。
frames = []
episodes = 1for episode in range(1, episodes+1):state = env.reset()terminated = truncated = Falsescore = 0while not (terminated or truncated):frames.append(env.render())# 注意: 这里我们随机选择一个动作。action = env.action_space.sample()observation, reward, terminated, truncated, info = env.step(action)score += reward# 在回合结束时打印出回合数和累积奖励。print("Episode:{} Score:{}".format(episode,score))
env.close()
Episode:1 Score:-56.20437956204454
# 内嵌显示卡通。这个智能体采取的是随机动作。 # 由于视频的大小太大,我们删除了输出。 # 你可以查看'videos'文件夹以查看根据下面步骤保存的生成视频。 HTML(display_anim(frames))
# 卡通中的动作基于随机动作。 # 保存卡通。我们在 /videos 文件夹中提供了生成的卡通。 filename = 'CarRacing-v2_random.mp4' save_anim(frames, filename=filename)
生成的视频如下所示:
https://github.com/ROCm/rocm-blogs/assets/13548555/c836a82e-1ad8-44cf-90dd-fba86f648d45
基于最佳模型预测动作的智能体
在本节中,我们将让智能体根据训练模型预测的最佳动作进行操作。正如你在卡通动画中看到的那样,使用训练后的智能体,汽车快速加速并巧妙地穿越各种路况。这很了不起,不是吗?
# 根据评估结果加载最佳模型。您可能需要更改模型路径,具体取决于您的最佳模型存储位置。 model_path = "./Saved_Models/dqn_best_model_lr0001_1e7/best_model" model = DQN.load(model_path, env=env)
Wrapping the env with a `Monitor` wrapper Wrapping the env in a DummyVecEnv. Wrapping the env in a VecTransposeImage.
# 生成一集由最佳模型预测的动作的观察结果。frames = []
episodes = 1for episode in range(1, episodes+1):observation, _ = env.reset()terminated = truncated = Falsescore = 0while not (terminated or truncated):frames.append(env.render())action , _ = model.predict(observation) observation, reward, terminated, truncated, info = env.step(action)score += rewardprint("Episode:{} Score:{}".format(episode,score))
env.close()
Episode:1 Score:917.1999999999867
# 内嵌显示卡通动画。此智能体采取随机动作。 # 由于视频尺寸过大,我们删除了输出内容。 # 您可以参考'videos'文件夹查看生成的视频, # 并通过以下步骤保存。 HTML(display_anim(frames))
# 卡通动画中的动作是使用训练后的最佳模型选择的。 # 保存卡通动画。我们将生成的卡通动画保存在 /videos 文件夹中。 filename = 'CarRacing-v2_best.mp4' save_anim(frames, filename=filename)
这是生成的视频:
https://github.com/ROCm/rocm-blogs/assets/13548555/1db55b04-afde-4ab5-9bbc-291d160dbcf1
CPU与GPU性能对比
鉴于它们在深度学习模型训练中的并行处理能力,GPU通常显著优于CPU。在下面的代码块中,我们展示了通过利用AMD GPU,性能能够远超CPU。具体的数值差异可能会根据你所使用的硬件而有所不同。
import time
from stable_baselines3 import DQN
import gymnasium as gymenv = gym.make("CarRacing-v2", domain_randomize=True,continuous=False)
env.reset(seed=1234)
env.action_space.seed(123)
t1 = time.time()
model = DQN("CnnPolicy", env, verbose=0, device="cuda")
model.learn(total_timesteps=100000)
print(f"Time with gpu : {time.time()-t1:.2f}s")env.reset(seed=1234)
env.action_space.seed(123)
t1 = time.time()
model = DQN("CnnPolicy", env, verbose=0, device="cpu")
model.learn(total_timesteps=100000)
print(f"Time with cpu : {time.time()-t1:.2f}s")env.close()
Time with gpu : 652.19s Time with cpu : 5837.96s
致谢
我们对这个笔记本的作者Manthan Bhagat表示感谢,他的工作为我们的博客提供了宝贵的参考,尤其是在创建和保存卡通动画的函数代码方面。