19种RAG结构
文章目录
- 什么是RAG
- 19种RAG总览
- Standard RAG
- Corrective RAG,纠错型RAG
- Speculative RAG,推测型RAG
- Fusion RAG,融合型RAG
- Agentic RAG,智能代理型RAG
- Self RAG,自增强型RAG
- Graph RAG,图谱RAG
- Adaptive RAG
- REALM: Retrieval augmented language model pre-training
- RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
- REFEED: Retrieval Feedback
- Iterative RAG,迭代RAG
- REVEAL: Retrieval-Augmented Visual-Language Model
- REACT: Retrieval-Enhanced Action generation
- REPLUG: Retrieval Plugin
- MEMO RAG: Memory-Augmented RAG
- ATLAS: Attention-based retrieval Augmented Sequence generation
- RETRO: Retrieval-Enhanced Transformer
- LightRAG: Simple and Fast Retrieval-Augmented Generation
🍃作者介绍:双非本科大四网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应用开发,目前开始人工智能领域相关知识的学习
🦅个人主页:@逐梦苍穹
📕所属专栏:人工智能;
🌻gitee地址:xzl的人工智能代码仓库
✈ 您的一键三连,是我创作的最大动力🌹
什么是RAG
检索增强生成(Retrieval-Augmented Generation,简称RAG)是一种将信息检索与生成模型相结合的技术,旨在提升大型语言模型(LLM)的回答准确性和上下文相关性。其主要工作流程包括:
- 检索:根据用户的查询,从外部知识库中检索相关信息。这些知识库可以是结构化的数据库、文档集合或其他信息源。
- 增强:将检索到的相关信息与用户的查询相结合,形成增强的输入。
- 生成:将增强后的输入提供给生成模型,生成最终的回答。
通过引入外部知识,RAG能够弥补语言模型在特定领域知识或最新信息方面的不足,减少模型生成错误信息的可能性。此外,RAG还具有以下优势:
- 知识更新便捷:外部知识库可以独立于模型进行更新,确保模型能够及时获取最新信息。
- 减少幻觉现象:通过提供真实的外部信息,降低模型生成虚假或不准确内容的风险。
RAG在问答系统、对话系统和内容生成等领域有广泛应用,特别适用于需要实时获取最新信息或特定领域知识的场景。
19种RAG总览
以下是19种RAG(检索增强生成)结构的简要概述:
- Standard RAG:基础版本,通过检索外部信息提升回答准确性。
- Corrective RAG:利用反馈机制改进生成内容,适用于高精度需求场景。
- Speculative RAG:并行生成多个草稿,并验证选择最佳内容,提升效率。
- Fusion RAG:从多个检索源获取信息,生成更加全面的回答。
- Agentic RAG:引入智能代理,适应复杂多任务,增强灵活性。
- Self-RAG:利用自身生成内容做反馈,提升多轮对话中的一致性。
- Graph RAG:构建知识图谱,提高检索效率和处理复杂任务的能力。
- Adaptive RAG:根据查询复杂度决定是否检索外部知识,提升响应效率。
- REALM:基于检索的语言模型预训练,适用于开放领域问答。
- RAPTOR:采用树状结构组织信息,提升长文档和复杂问答的性能。
- REFEED:通过检索反馈优化输出,无需模型微调。
- Iterative RAG:多轮检索生成,逐步提升回答质量。
- REVEAL:视觉-语言增强模型,结合多模态知识处理图像任务。
- REACT:结合推理与行动生成,提高模型决策透明度和准确性。
- REPLUG:检索插件,通过外部文档增强预测能力,减少幻觉现象。
- Memo RAG:结合记忆和检索功能,适用于模糊查询和大量信息处理。
- ATLAS:基于注意力的检索增强序列生成,支持动态知识更新。
- RETRO:检索增强Transformer,通过外部数据库片段提升生成质量。
- LightRAG:轻量型、快速检索增强系统,支持多层次信息检索和动态更新。
这些结构各自优化检索生成模型的不同方面,包括准确性、效率、灵活性和可解释性等,以满足不同应用需求。
Standard RAG
标准RAG架构是RAG技术的基础版本,它将检索与生成结合起来,通过外部数据源增强语言模型的生成能力。
在此架构下,系统会根据输入查询,从外部文档中检索相关信息,并将其与语言模型的生成能力结合,从而生成更符合上下文的回答,并且支持实时信息检索,能够在几秒内生成高质量的响应。
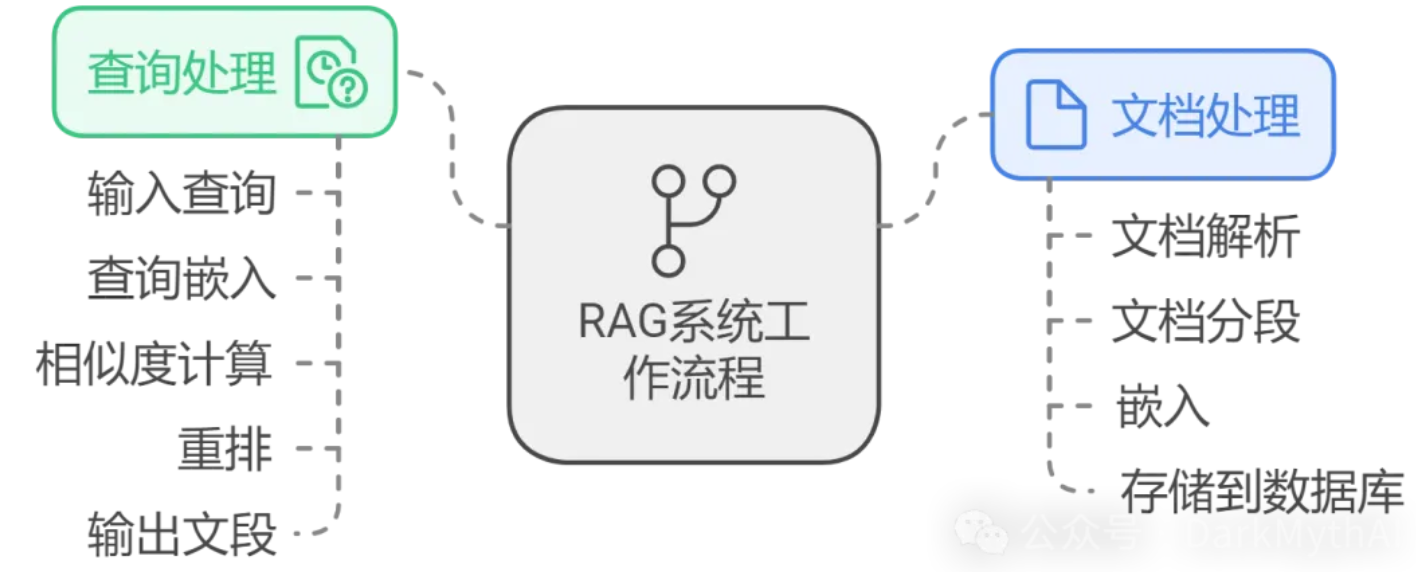
其工作流程通常包括以下步骤:
- 用户查询:用户输入一个问题或查询。
- 查询向量化:将用户的查询转换为向量表示,以便在向量空间中进行相似度计算。
- 检索相关文档:在预先构建的知识库中,使用查询向量检索与之相似的文档或段落。
- 生成模型输入:将检索到的相关文档与原始查询一起作为输入,提供给生成模型。
- 生成回答:生成模型根据输入,生成连贯且信息丰富的回答。
通过这种方式,RAG模型能够在生成回答时参考外部知识库中的信息,提升回答的准确性和丰富性。
Corrective RAG,纠错型RAG
纠错型RAG旨在通过反馈机制不断改进生成结果。
模型生成的初始内容会经过反馈循环进行调整,以确保最终输出的准确性,特别适用于需要高准确度的领域。
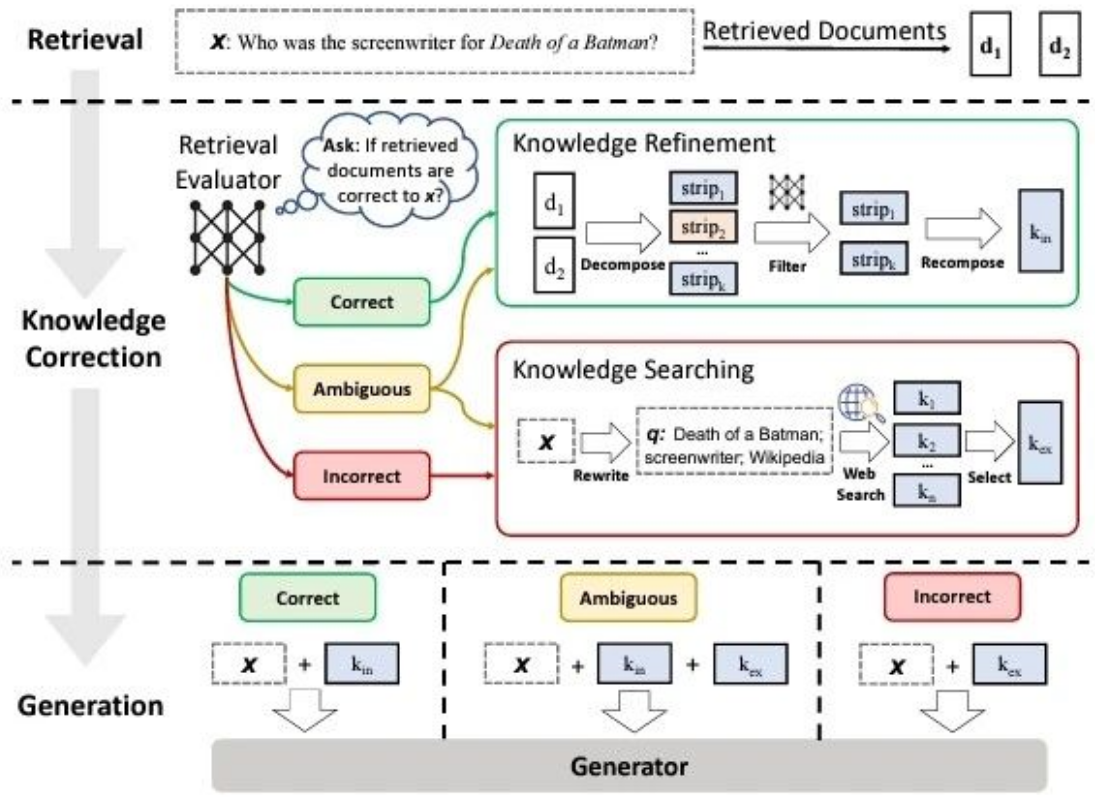
这个流程包括以下几个阶段:
- 检索阶段(Retrieval)
- 用户输入一个问题(例如,“谁是《Death of a Batman?》的编剧?”)。
- 系统检索出与该问题相关的文档(如
d1、d2等),这些文档包含可能的答案。
- 知识纠错阶段(Knowledge Correction)
- 检索评估器:系统通过检索评估器来判断这些检索到的文档是否与用户的查询相关。
- 如果检索到的文档被认为是正确的,则进入“
知识精炼”流程。 - 如果判断为模糊,系统会尝试通过进一步搜索或其他手段来获取更多信息。
- 如果文档被认为不正确,则进行“知识搜索”流程来找到准确的内容。
- 2.1 知识精炼(Knowledge Refinement)
- 系统会将检索到的文档进行分解、过滤、重新组合,以提取更为精确的知识片段(如
k_in)
- 系统会将检索到的文档进行分解、过滤、重新组合,以提取更为精确的知识片段(如
- 2.2 知识搜索(Knowledge Searching)
- 针对不正确的信息,系统会通过网络搜索、查询数据库等方式重新检索相关信息,找到符合要求的知识片段(如
k_ex)
- 针对不正确的信息,系统会通过网络搜索、查询数据库等方式重新检索相关信息,找到符合要求的知识片段(如
- 生成阶段(Generation)
- 经过知识纠错后,系统进入生成阶段。
- 正确的回答:直接结合用户问题和相关的知识片段
k_in进行生成。 - 模糊的回答:结合模糊的知识片段
k_ambiguous生成相对不确定的回答。 - 不正确的回答:结合新的知识片段
k_ex来生成准确的回答。
- 正确的回答:直接结合用户问题和相关的知识片段
该流程通过多层次的知识检索与评估,确保生成的回答更加准确和具有参考性,同时避免了因为知识库不准确导致的错误回答。
Speculative RAG,推测型RAG
推测型RAG通过 并行生成多个草稿 并采用 验证模型 ,提升生成效率和质量,提高了生成速度并保持较高的准确性,特别适用于需要快速生成内容的应用场景。
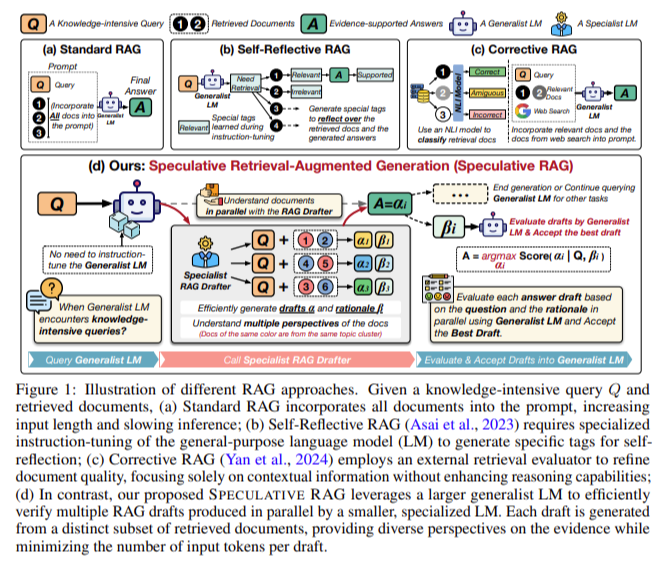
推测型检索增强生成(Speculative Retrieval-Augmented Generation,简称Speculative RAG)是一种将信息检索与生成模型相结合的技术,旨在提升生成模型的知识性和准确性。
其工作流程通常包括以下步骤:
- 用户查询:用户输入一个问题或查询。
- 查询向量化:将用户的查询转换为向量表示,以便在向量空间中进行相似度计算。
- 检索相关文档:在预先构建的知识库中,使用查询向量检索与之相似的文档或段落。
- 生成模型输入:将检索到的相关文档与原始查询一起作为输入,提供给生成模型。
- 生成回答:生成模型根据输入,生成连贯且信息丰富的回答。
通过这种方式,Speculative RAG模型能够在生成回答时参考外部知识库中的信息,提升回答的准确性和丰富性。
从上面的流程步骤看,好像跟Standard RAG有点类似?
Speculative RAG和Standard RAG在信息处理流程和效率上存在一些 关键区别:
- 工作流程:
- Standard RAG 是最基础的检索增强生成架构。在这个框架中,查询会触发一次检索过程,系统从外部知识库中检索相关文档,然后将这些文档与原始查询一同输入生成模型,生成答案。
- Speculative RAG 则通过并行生成多个回答草稿,并对这些草稿进行筛选和验证,选出最佳答案。这一流程不仅使生成的答案更具参考性和准确性,还能显著提升生成效率。
- 并行处理与效率:
- Standard RAG 一次检索和生成的过程是串行的,即需要等到检索完成后再进行生成。因此,检索结果的质量直接影响最终答案。
- Speculative RAG 则采取了并行化策略,能够同时生成多个草稿回答。通过筛选机制来选择最佳答案,从而在多个潜在答案中找到最优解,大大提高了生成过程的效率。
- 生成质量与准确性:
- Standard RAG 在生成回答时仅依赖一次检索结果,如果检索到的信息不足,可能会影响答案的完整性或准确性。
- Speculative RAG 通过多次生成和筛选,使得回答更加精准,并减少生成幻觉的可能性。
总结而言,Speculative RAG是对Standard RAG的一种优化,通过并行生成和筛选提高了生成效率,并在准确性和丰富性上有更好的表现。
Fusion RAG,融合型RAG
融合型RAG利用多个检索源同时提供信息,生成更全面的回答。
它能够根据用户查询动态调整检索策略,减少对单一数据源的依赖,提供多源检索,增加生成结果的多样性与完整性。
融合型检索增强生成(Fusion Retrieval-Augmented Generation,简称Fusion RAG)是一种将信息检索与生成模型深度融合的技术,旨在提升生成模型的知识性和准确性。
Fusion RAG 的工作流程可以分为以下几个关键步骤:
- 用户查询输入:用户提交查询,通常是一个需要综合多个信息源回答的问题。
- 多源检索:
- 生成多个查询:根据用户的输入查询,模型可以生成多个子查询,这些子查询会根据不同的信息源的特点进行调整,以适应特定数据源的内容结构。
- 并行检索:系统并行地向多个信息源发出查询请求,每个信息源返回与用户查询相关的多个文档。信息源可以是不同的数据库、知识库,或网络资源。
- 结果重排序:
- 基于相关性排序:将每个信息源返回的文档按相关性进行初步排序。
- 综合重排序:系统会将来自多个信息源的文档整合到一起,通过重排序算法(如 Reciprocal Rank Fusion 等)来优先展示最相关的内容,消除信息重复。
- 信息融合:
- 信息去重与整合:将各个信息源返回的结果进行去重和整合,保留重要信息,避免信息冲突。
- 生成输入:将整理后的信息与用户的原始查询共同输入到生成模型,形成一个综合性的信息输入。
- 生成答案:生成模型结合整合后的信息,生成一个连贯且全面的回答。此答案包含了多个来源的信息,确保内容的丰富性和准确性。
- 反馈优化(可选):根据用户的反馈,对检索和生成模型进行微调,以优化未来的回答质量。
Fusion RAG 的工作流程本质上是一个多源检索、整合与生成的过程,强调通过融合不同信息源的数据来提升回答的全面性和准确性。
这一流程适合应用在需要整合多个信息来源的复杂问答任务中。
Agentic RAG,智能代理型RAG
智能代理型RAG通过集成动态代理进行实时调整,能够自动适应用户的需求和上下文变化。该模型设计为模块化结构,允许整合新的数据源和功能,能够高效并行处理复杂任务,适合复杂多任务的场景
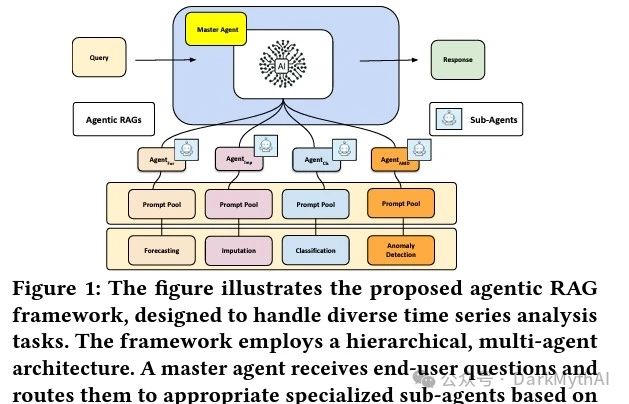
Agentic RAG(智能代理型检索增强生成)是一种将智能代理(Agent)引入检索增强生成(RAG)系统的技术,旨在提升模型处理复杂任务的能力。
传统的RAG系统通过检索相关文档并将其与生成模型结合,以生成更准确的回答。
然而,在面对需要多步骤推理、工具调用或动态规划的复杂任务时,传统RAG可能表现不足。
工作流程:
- 用户查询接收:
- 用户输入一个查询或任务请求,通常是多任务或需要多步推理的问题。
- 主代理(Master Agent)分配任务:
- 主代理负责接收用户查询,根据任务的特点和需求,将其分配给适合的子代理。
- 主代理会分析查询的需求,并判断需要调用哪些子代理来完成任务。
- 子代理(Sub-Agents)执行:
- 各个子代理被设计为模块化的功能单元,专注于特定的任务类型,例如预测(Forecasting)、分类(Classification)、异常检测(Anomaly Detection)等。
- 子代理从自己的 提示池(Prompt Pool) 中选择合适的提示,结合特定的数据源或检索方法完成子任务。
- 子代理可以独立完成特定任务,或在任务中进行多步推理,以提高答案的准确性和上下文适应性。
- 信息整合与生成:
- 主代理收集各子代理的输出,进行信息整合。主代理会根据子代理的反馈和任务的上下文,对生成内容进行最终处理和优化。
- 输出结果:
- 最终的回答通过主代理输出给用户,包含各子代理处理的信息,从而提供完整且多角度的答案。
主要特点:
- 模块化架构:框架以模块化设计为基础,允许灵活添加新的数据源和功能模块。
- 多任务并行处理:Agentic RAG通过并行子代理实现复杂任务的分解和并行处理,提高了任务处理效率。
- 动态适应:通过主代理的控制,系统能够根据任务需求实时调整策略,自动适应不同的用户需求和上下文变化。
- 高度可扩展:可以为框架添加新的代理,以处理更多任务类型,实现持续扩展。
适用场景:Agentic RAG特别适合复杂多任务场景,例如金融数据分析、医疗多任务诊断、企业大数据处理等需要整合不同数据源和任务类型的应用场景。
Self RAG,自增强型RAG
自增强型检索增强生成(Self-Enhanced Retrieval-Augmented Generation,简称Self-RAG)是一种在传统RAG(检索增强生成)基础上,加入自我反馈机制的技术。
自增强型RAG利用先前生成的内容作为下一轮检索的基础,不断提升生成的上下文一致性与准确性。
在多轮对话和长时间任务中,保持一致的上下文参考。

工作流程:
- 初始查询与检索:
- 用户输入一个查询,系统根据该查询进行初步的检索,获取相关的文档或信息片段。
- 生成初始回答:
- 系统将检索到的文档片段与用户的查询一同输入到生成模型,生成第一个回答。
- 自我增强检索:
- Self-RAG会分析先前生成的内容,将其作为新的上下文信息,结合原始查询,再次进行检索。这种方式可以在每一轮迭代中补充新的相关信息,扩展和强化答案的准确性。
- 多轮迭代:
- 系统不断进行上述的检索-生成循环,通过迭代逐步改善回答内容,每一轮生成的回答都会成为下一轮的基础。
- 在每一轮中,系统会根据新的上下文选择最相关的文档片段,确保每一轮的回答在语义上连贯。
- 输出最终回答:
- 当系统认为回答内容已经满足准确性和完整性要求后,停止迭代,并输出最终的回答。
主要特点:
- 上下文一致性:通过每轮生成内容的自我增强,Self-RAG能够在多轮对话或长时间任务中保持一致的上下文参考,不易出现内容偏差。
- 动态内容更新:每一轮检索和生成都能根据当前的上下文动态调整,确保回答的内容准确、与最新上下文相关。
- 适用于长时间交互任务:在多轮对话、复杂问题解答等需要连续生成内容的任务中,Self-RAG的自我增强机制能够显著提升体验。
适用场景:Self-RAG特别适合于需要长时间保持上下文一致性的任务,例如客户服务对话、学术问答和复杂技术支持等情境。
Graph RAG,图谱RAG
在图谱RAG中,模型通过动态构建知识图谱(Knowledge Graph),链接相关实体以提升检索的效率和准确度。能够根据查询构建紧凑的知识图,避免检索冗余,提升复杂任务的处理能力。

Graph RAG(图谱检索增强生成)是一种将知识图谱与大语言模型(LLM)相结合的技术,旨在提升模型在处理复杂任务时的推理能力和回答准确性。
传统的RAG方法主要依赖于向量数据库进行语义相似性检索,但在处理需要多跳推理或联系不同信息片段的问题时,可能存在局限性。Graph RAG通过引入知识图谱,提供了更结构化和关联性的知识表示,增强了模型的推理能力。
工作流程:
- 文本单元分解:
- 将文档分解成小的文本块(Text Units)并嵌入为向量表示(Embedded Chunks)。
- 图结构提取:
- 从文本块中提取出实体和它们之间的关系,并生成图结构数据。图结构包含了实体、关系、声明(Claims)等元素,形成一个知识图谱(Graph Tables),用于丰富信息语境。
- 图增强:
- 通过社区检测(Community Detection)和图嵌入(Graph Embeddings)来扩展图谱。社区检测可以发现数据中的相关子群体,而图嵌入则通过将实体和关系向量化,便于后续检索。
- 社区总结:
- 对图谱中相关社区进行总结,形成更高层次的语义信息,提升生成内容的连贯性和精确性。
- 文档处理:
- 处理图谱中的节点和关系,通过嵌入技术生成文档向量并创建可视化网络,便于检索和查看信息。
- 检索与生成:
- 在用户查询时,系统基于图结构检索相关信息,通过将图谱中的实体和关系转化为语义丰富的提示(Prompts),提供给生成模型。
主要特点:
- 知识图谱增强:Graph RAG 将文本内容转化为知识图谱,捕捉了实体间的复杂关系,增强了模型对上下文的理解能力。
- 社区检测与图嵌入:通过社区检测,发现数据中潜在的主题和子群体;图嵌入使得实体和关系能够更有效地参与检索,提升查询效率。
- 高效信息检索与总结:通过图结构的帮助,Graph RAG 在复杂查询和信息密集型任务中,能够更准确地获取和总结信息。
- 应用场景广泛:适用于需要理解复杂关系的任务,例如医疗问答、知识管理和学术研究等。
Graph RAG 通过知识图谱和实体关系的整合,解决了传统 RAG 在复杂语义处理中的不足,特别适合在需要高级推理和数据关联的场景中应用。
Adaptive RAG
Adaptive RAG 动态决定何时检索外部知识,平衡内部和外部知识的使用。
它利用语言模型内部状态的置信度评分来判断是否需要进行检索,并通过“诚实探针”防止幻觉现象,使输出与实际知识保持一致。
该方法减少了不必要的检索,提升了效率和响应的准确性。
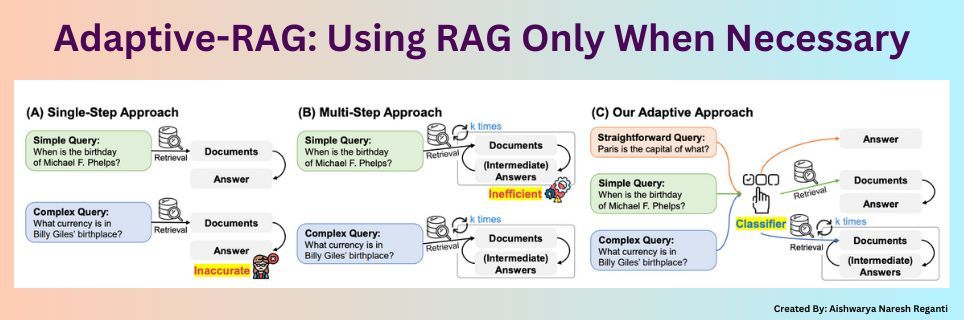
工作流程:
- 查询输入:用户输入一个查询。
- 复杂性预测:分类器评估查询的复杂性,确定其属于简单、中等或复杂类别。
- 策略选择:根据预测结果,选择相应的处理策略(无检索、单步检索或多步检索)。
- 答案生成:采用选定的策略,生成并返回答案。
优势:
- 效率提升:通过避免对简单查询进行不必要的复杂处理,减少计算资源的浪费。
- 准确性提高:针对复杂查询,采用多步检索和推理,确保答案的准确性。
- 灵活性增强:能够根据查询的实际需求,动态调整处理策略,适应不同类型的查询。
通过这种自适应的方法,Adaptive RAG在处理各种复杂性的查询时,实现了效率和准确性的平衡,提升了问答系统的整体性能。
REALM: Retrieval augmented language model pre-training
REALM(检索增强语言模型预训练)通过从大型语料库(如维基百科)中检索相关文档来提升模型预测能力。其检索器通过掩码语言模型(MLM)进行训练,优化检索以提高预测准确性。在训练中,它使用最大内积搜索(Maximum Inner Product Search)高效地从数百万候选文档中找到相关内容。通过整合外部知识,REALM 在开放领域问答任务中表现优于以往模型。
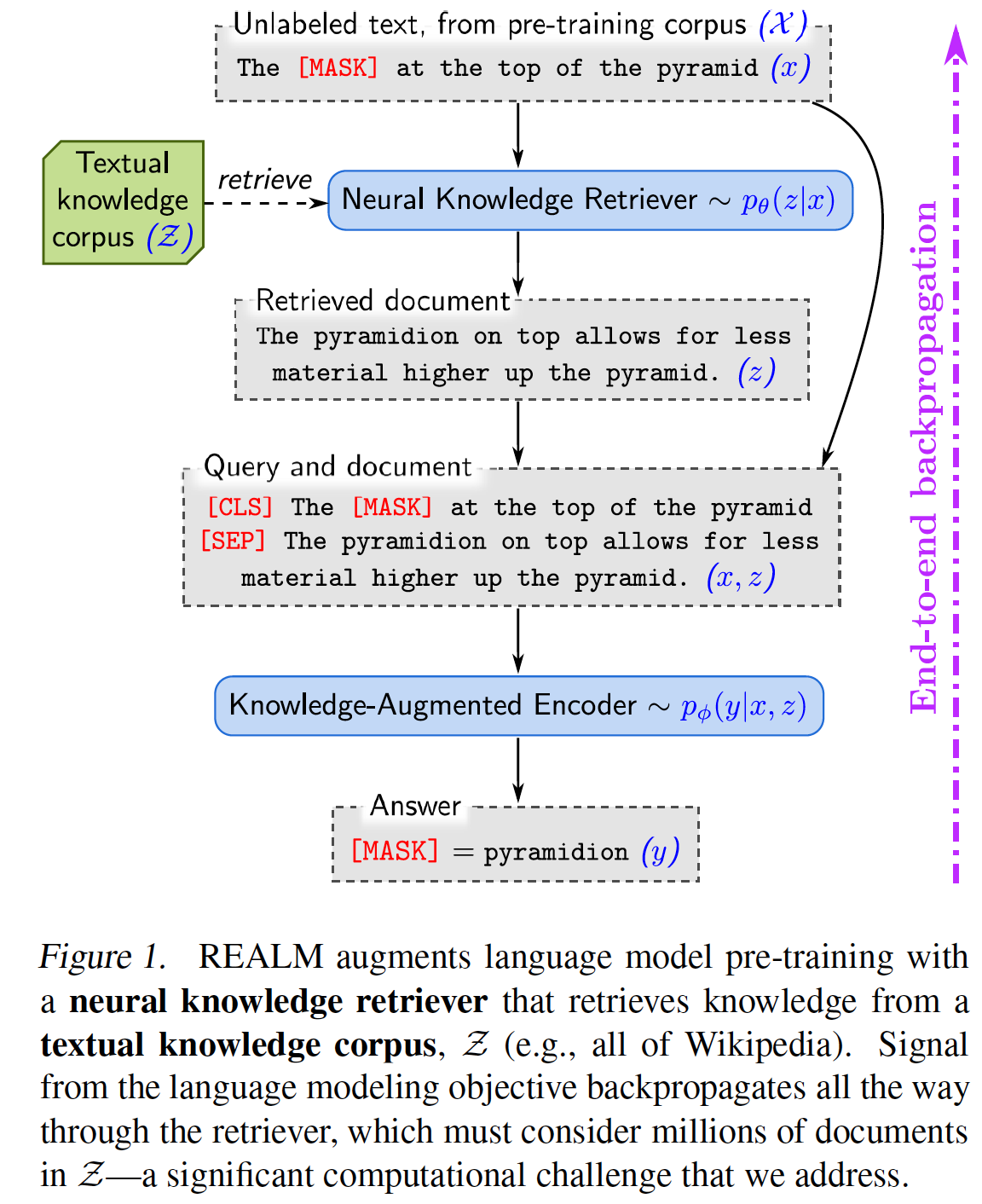
REALM(Retrieval-Augmented Language Model Pre-Training)是一种由谷歌提出的预训练语言模型方法,旨在通过引入检索机制,增强模型的知识获取能力。传统的语言模型在预训练过程中主要依赖于大规模语料库,但这些知识隐含地存储在模型参数中,难以解释且扩展性有限。REALM通过在预训练阶段引入一个知识检索器,使模型能够在推理时显式地使用外部知识库(如维基百科)中的信息,从而提升模型的性能和可解释性。
主要特点:
- 知识检索器的引入:REALM在预训练阶段引入了一个独立的“语境知识抽取器”(contextual knowledge retriever),通过该检索器决定在推理时使用哪些知识。
- 端到端优化:REALM的预训练和微调阶段的任务都是最大化正确答案对应的对数似然,且以上描述的两个任务都是可以端到端优化的。
- 模块化设计:REALM的方法是训练一个独立的“语境知识抽取器”,通过这个抽取器来决定应该在推理时使用哪些知识。
工作流程:
- 预训练阶段:模型从预训练语料中采样句子,并将部分词语进行掩码处理。然后,利用知识检索器从外部知识库中检索相关文档,结合输入句子和检索到的文档,共同预测被掩码的词语。
- 微调阶段:在开放领域问答任务中,模型根据输入的问题,利用知识检索器从知识库中检索相关文档,然后结合输入问题和检索到的文档,生成答案。
优势:
- 可解释性强:通过显式的知识检索,模型的推理过程更加透明,便于理解和分析。
- 性能提升:在开放领域问答任务上,REALM在多个数据集上取得了领先的性能,特别是在仅使用少量检索文档的情况下,优于传统方法和类似方法。
- 模块化设计:独立的知识检索器使模型具有更强的扩展性和灵活性,便于在不同任务中应用。
通过引入知识检索机制,REALM在预训练语言模型的过程中,显式地利用外部知识库中的信息,提升了模型的性能和可解释性,为自然语言处理任务提供了新的思路。
源
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
RAPTOR 通过递归聚类和总结文本构建层次化的树结构,支持在不同抽象层次上的检索,结合广泛主题和具体细节。它在复杂问答任务中表现优于传统方法,提供树遍历和折叠树方法,以实现高效的信息检索。
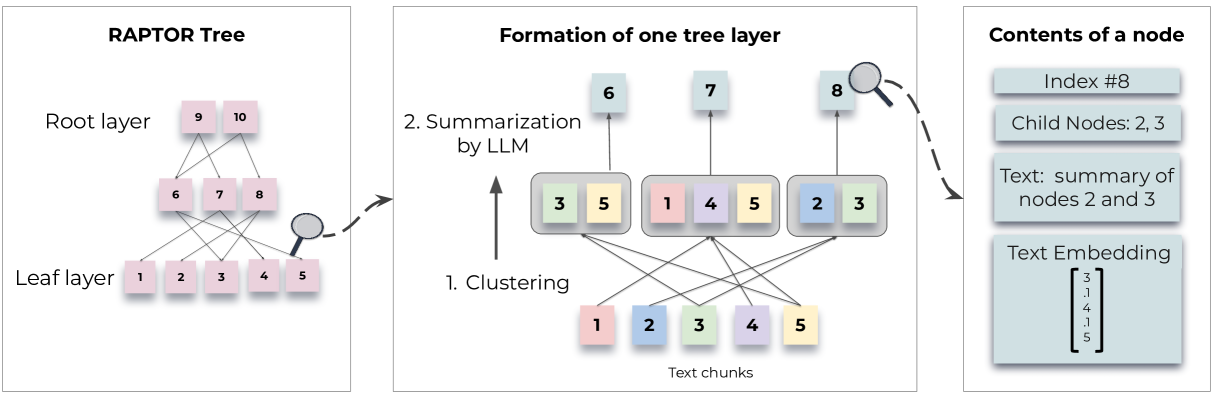
RAPTOR(Recursive Abstractive Processing for Tree-Organized Retrieval)是一种创新的检索增强生成(RAG)方法,旨在通过递归抽象处理和树状组织结构,提升大型语言模型在长文档处理和复杂问答任务中的性能。
主要特点:
- 递归抽象处理:RAPTOR将长文档分割成较小的文本块,使用嵌入技术对其进行表示,然后通过聚类算法将相似的文本块分组。对每个分组,利用语言模型生成摘要,并将这些摘要重新嵌入,重复此过程,逐层构建出文档的树状结构。
- 树状组织结构:通过上述递归过程,RAPTOR构建出一个多层次的树状结构,每个节点代表不同抽象层次的文本信息,从细节到全局主题都有所涵盖。
- 高效检索机制:在推理阶段,RAPTOR利用构建的树状结构,根据查询的具体需求,在不同抽象层次上检索相关信息,确保检索结果既包含全局概览,又保留必要的细节。
工作流程:
- 文档分割与嵌入:将长文档分割成长度约为100个词的短文本块,使用SBERT等嵌入模型对其进行向量化表示。
- 聚类与摘要:对嵌入后的文本块进行聚类,将相似的块分组。对每个分组,利用语言模型生成摘要,形成上层节点。
- 递归构建树结构:对生成的摘要重复嵌入、聚类和摘要的过程,逐层向上,直到无法再进行有效的聚类,最终形成完整的树状结构。
- 查询与检索:在推理阶段,根据用户的查询,RAPTOR在树状结构中自上而下地检索相关节点,整合不同层次的信息,生成最终的回答。
优势:
- 处理长文档的能力:通过树状结构,RAPTOR能够有效地表示和检索长文档中的信息,避免了传统方法在处理长上下文时的性能下降问题。
- 多层次信息整合:RAPTOR在不同抽象层次上整合信息,既能提供全局概览,又能保留必要的细节,适用于需要综合理解的复杂问答任务。
- 提升检索效率:通过递归抽象和树状组织,RAPTOR在检索阶段能够快速定位相关信息,减少不必要的计算,提高检索效率。
总体而言,RAPTOR通过创新的递归抽象处理和树状组织结构,为检索增强生成方法提供了新的思路,特别是在处理长文档和复杂问答任务时,展现出显著的性能提升。
REFEED: Retrieval Feedback
REFEED 通过检索反馈来优化模型输出,而无需微调。它通过检索相关文档改进初始答案,并基于新信息调整生成结果。REFEED 还生成多个答案来提高检索的准确性,并结合检索前后的结果,使用排序系统增强答案的可靠性。
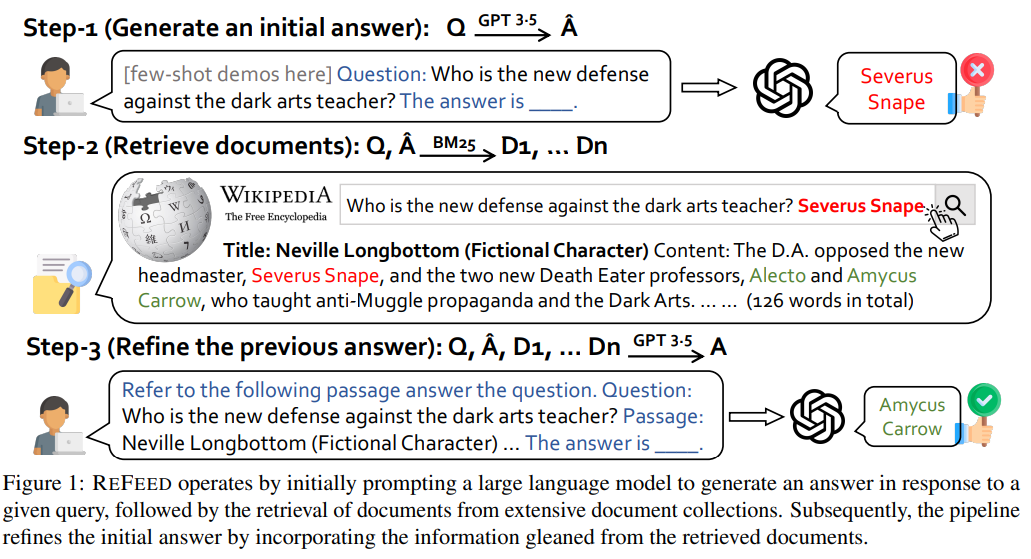
ReFeed(Retrieval Feedback)是一种旨在提升大型语言模型(LLM)生成质量的技术框架。其核心思想是利用检索反馈机制,在无需对模型进行昂贵微调的情况下,优化生成结果。
主要特点:
- 自动检索反馈:ReFeed框架在模型生成初始输出后,使用检索模型将原始查询和生成结果作为新查询,检索相关文档。这些检索到的文档作为反馈,帮助模型修正和完善初始生成内容。
- 即插即用框架:ReFeed采用即插即用的设计,无需对语言模型进行昂贵的微调。通过引入检索反馈机制,直接在推理过程中优化生成结果,提升效率。
- 多样化生成与集成:在基础检索反馈概念的基础上,ReFeed引入了多样化生成输出和初始与反馈后答案集成等模块,进一步提升生成质量。
工作流程:
- 初始生成:语言模型根据用户输入生成初步回答。
- 检索反馈:将用户输入和初始生成结果组合,作为新查询输入检索模型,获取相关文档。
- 反馈整合:将检索到的文档作为反馈信息,整合到初始生成结果中,优化最终输出。
优势:
- 提升生成质量:通过引入检索反馈,ReFeed有效减少了模型生成中的幻觉现象,增强了生成内容的准确性和可靠性。
- 无需微调:ReFeed框架无需对语言模型进行昂贵的微调,降低了部署和维护成本。
- 灵活性强:即插即用的设计使ReFeed能够与多种语言模型兼容,适用于不同的应用场景。
通过引入检索反馈机制,ReFeed框架在提升大型语言模型生成质量方面展现出显著的效果,为自然语言处理任务提供了新的思路。
Iterative RAG,迭代RAG
迭代RAG通过多次检索步骤,根据先前检索到的文档反馈不断优化结果。检索决策遵循马尔可夫决策过程,强化学习用于提升检索性能。模型保持内部状态,基于累积的知识调整后续检索步骤,从而逐步提高检索准确性。
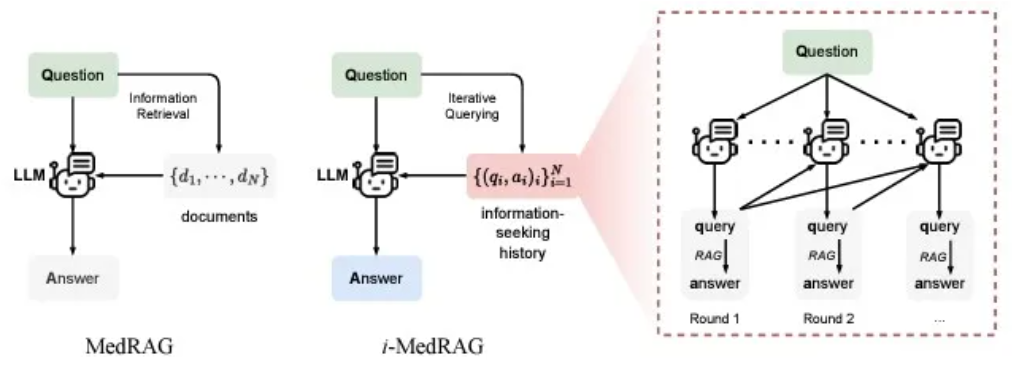
迭代检索增强生成(Iterative Retrieval-Augmented Generation,简称Iterative RAG)是一种在传统RAG基础上,通过多轮检索和生成循环,逐步提升回答质量的方法。其主要特点包括:
- 多轮检索-生成循环:模型在每一轮迭代中,利用前一轮的生成结果,结合原始查询,进行新的检索,获取更相关的文档。然后,基于这些文档和先前的生成结果,生成新的回答。这一过程持续进行,直至满足预设的终止条件。
- 生成增强检索:在每一轮迭代中,生成模型的输出用于改进下一轮的检索查询,使检索器能够获取更精确的文档。这种方法被称为生成增强检索(Generation-Augmented Retrieval)。
- 检索增强生成:每轮检索到的文档用于丰富生成模型的输入,提升生成内容的准确性和相关性。这被称为检索增强生成(Retrieval-Augmented Generation)。
通过上述循环,迭代RAG能够在处理复杂查询、需要多步推理或综合多源信息的任务中,逐步优化回答质量。例如,在多跳问答任务中,迭代RAG通过多轮检索和生成,逐步获取并整合相关信息,最终生成准确的回答。
REVEAL: Retrieval-Augmented Visual-Language Model
REVEAL 是一种结合了推理、任务特定动作和外部知识的视觉-语言增强模型。这种方法通过依赖现实世界的事实减少错误和虚假信息,使推理更为准确。它生成清晰、类似人类的任务解决步骤,提升了透明度。REVEAL 在任务中表现优异,使用较少的训练数据即可实现高效和适应性强的表现,且具备灵活的互动调整能力,使模型在实际应用中更具可控性和响应性
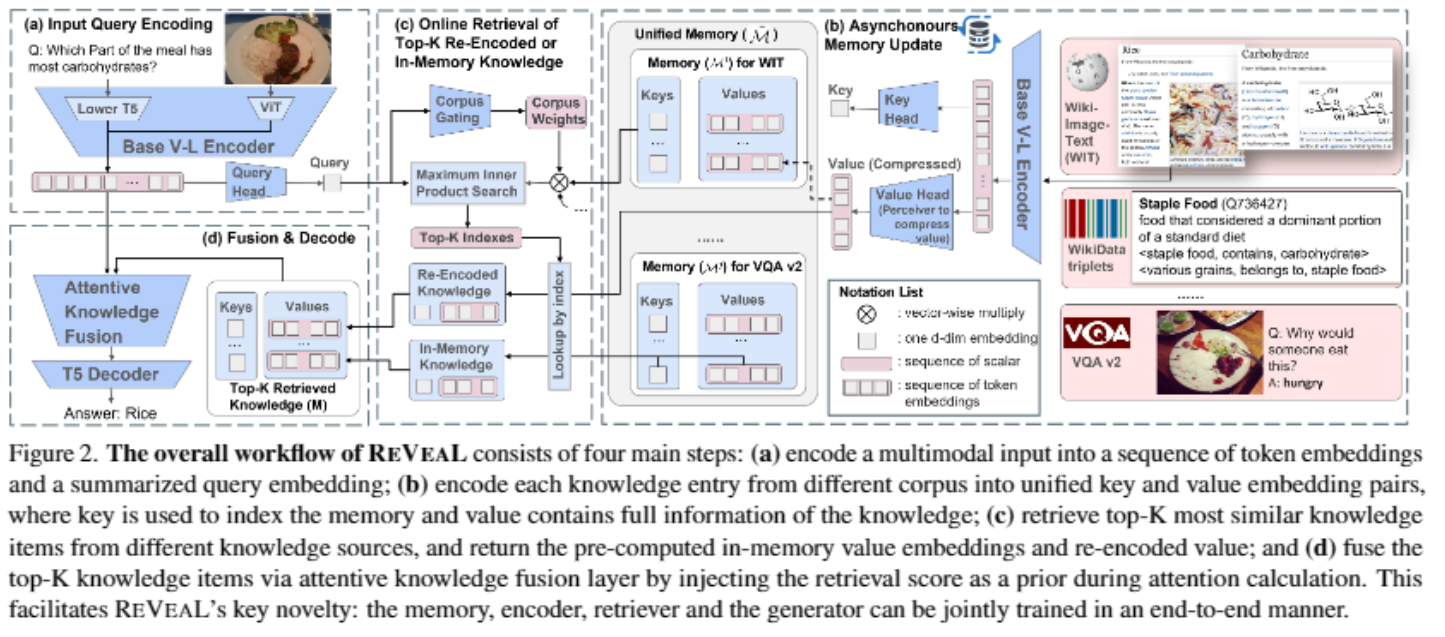
REVEAL(Retrieval-Augmented Visual-Language Model)是一种由谷歌研究团队提出的端到端检索增强视觉语言模型,旨在通过引入大规模多模态知识记忆库,提升模型在知识密集型任务中的表现。
主要特点:
- 多模态知识记忆库:REVEAL构建了一个包含多种知识来源的记忆库,包括图文对、问答对和知识图谱三元组等。这些知识通过统一的编码器进行编码,形成大规模的记忆库。
- 端到端训练:模型的记忆库、编码器、检索器和生成器在大规模数据上进行端到端的预训练,使各组件协同优化,提升整体性能。
- 多源知识融合:REVEAL能够利用多种模态的知识来源,在回答视觉问答和图像描述等任务时,综合不同类型的信息,生成更准确和丰富的回答。
工作流程:
- 输入编码:将输入的图像和文本通过视觉语言编码器进行编码,生成查询嵌入。
- 知识检索:利用查询嵌入在大规模记忆库中检索相关的知识条目。
- 生成回答:将检索到的知识与输入的查询融合,通过生成器生成最终的回答。
优势:
- 知识更新便捷:通过更新记忆库中的知识条目,无需重新训练模型即可实现知识的更新,保持模型对最新信息的掌握。
- 性能提升显著:在视觉问答和图像描述等任务上,REVEAL在多个基准数据集上取得了领先的性能表现。
通过引入大规模多模态知识记忆库和端到端的训练方式,REVEAL在处理知识密集型的视觉语言任务中展现出强大的能力,为相关领域的研究和应用提供了新的思路。
REACT: Retrieval-Enhanced Action generation
REACT 是一种结合推理与行动的技术,模型从环境中接收观察信息后,基于过去的行动和思考更新其上下文,以保持对情境的理解。模型会生成引导下一步行动的思路,确保决策逻辑清晰并与任务保持一致。执行行动后,新的反馈会进一步优化模型的理解。这种推理与行动的结合减少了错误,能够适应实时变化,并提供更加透明、可靠的决策。

ReAct(Reasoning and Acting)是一种将推理与行动相结合的框架,旨在提升大型语言模型(LLM)在复杂任务中的表现。该方法通过引入外部知识检索和工具使用,使模型能够在推理过程中动态获取所需信息,从而生成更准确和上下文相关的回答。
主要特点:
- 推理与行动结合:ReAct框架将推理(Reasoning)与行动(Acting)相结合,使模型在推理过程中能够主动采取行动,如检索外部信息或调用工具,以获取所需的知识。
- 外部知识检索:在生成回答时,模型可以根据需要检索外部知识库,如维基百科等,确保回答的准确性和时效性。
- 工具调用:模型能够调用外部工具,如计算器、翻译器等,以完成特定任务,增强其功能性。
工作流程:
- 接收用户查询:模型接收用户输入的问题或任务。
- 推理与决策:模型根据已有知识进行初步推理,判断是否需要外部信息或工具支持。
- 采取行动:如果需要,模型将执行相应的行动,如检索外部知识或调用工具。
- 生成回答:结合推理结果和获取的外部信息,模型生成最终的回答。
优势:
- 提升回答准确性:通过动态获取外部信息,模型能够提供更准确和最新的回答。
- 增强功能性:通过调用外部工具,模型能够完成更复杂的任务,如计算、翻译等。
- 减少幻觉现象:通过引入外部知识检索,减少模型生成不准确或虚构信息的可能性。
通过将推理与行动相结合,ReAct框架使大型语言模型在处理复杂任务时表现出更高的智能性和灵活性。
REPLUG: Retrieval Plugin
REPLUG 通过检索外部相关文档来增强大型语言模型(LLMs)的预测能力。它将语言模型视为一个固定的“黑箱”,并在输入之前附加检索到的信息。这种灵活的设计可以无缝应用于现有模型,无需对其进行修改。通过整合外部知识,REPLUG 减少了幻觉等错误,并扩展了模型对小众信息的理解。检索组件还可以根据语言模型的反馈进行微调,进一步提高与模型需求的对齐程度。
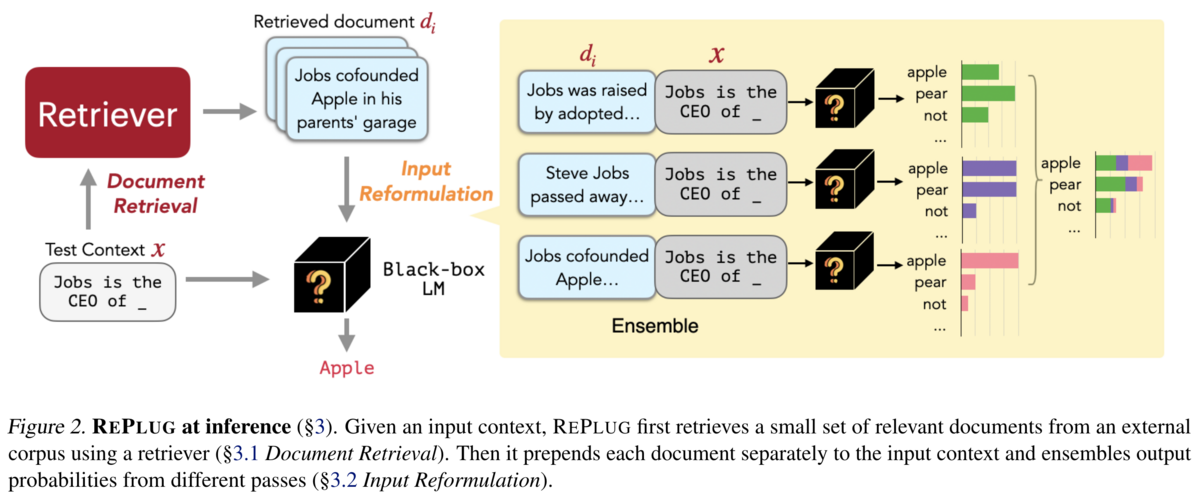
REPLUG(Retrieve and Plug)是一种检索增强的语言模型框架,旨在将语言模型(LM)视为黑盒,通过引入可调的检索模块,提升模型在语言建模和下游任务中的性能。
主要特点:
- 黑盒语言模型:REPLUG将现有的语言模型视为不可更改的黑盒,无需访问其内部参数或结构。
- 可调检索模块:引入一个可调的检索器,从外部语料库中检索相关文档,并将其与输入上下文一起提供给语言模型。
- 端到端优化:通过最小化检索器和语言模型输出之间的KL散度,端到端地训练检索器,使其更好地适应语言模型的需求。
工作流程:
- 文档检索:使用双塔结构的密集检索器,分别编码查询和文档,计算余弦相似度,选出最相关的文档。
- 输入构建:将检索到的文档与原始查询拼接,作为语言模型的输入。
- 概率集成:对每个文档与查询的组合,语言模型分别计算输出概率,并根据文档与查询的相似度进行加权平均,得到最终预测。
优势:
- 适用性广:无需修改语言模型内部结构,适用于各种现有的大型语言模型。
- 性能提升:在语言建模和下游任务(如MMLU和开放域问答)中,显著提高了模型性能。
- 训练高效:通过端到端的训练方法,优化检索器,使其更好地服务于语言模型。
通过引入REPLUG框架,研究者能够在不修改现有语言模型的情况下,利用外部知识库,提升模型的生成质量和任务表现。
MEMO RAG: Memory-Augmented RAG
MEMO RAG 结合了记忆和检索功能来处理复杂查询。记忆模型首先生成初步答案,用于引导外部信息的检索。然后,检索器从数据库中收集相关数据,交由更强大的语言模型生成全面的最终答案。该方法帮助 MEMO RAG 处理模糊查询,并高效处理各类任务中的大量信息。

MemoRAG(Memory-Augmented Retrieval-Augmented Generation)是一种创新的检索增强生成(RAG)框架,旨在通过引入高效的超长记忆模型,提升大语言模型(LLM)在处理复杂查询和大规模数据集时的性能。
主要特点:
- 全局记忆:MemoRAG能够在单个上下文中处理多达100万个标记(tokens),为庞大的数据集提供全面的理解。
- 上下文线索:通过从全局记忆中生成精确线索,MemoRAG将原始输入与答案连接起来,从复杂数据中解锁隐藏的洞察。
- 高效缓存:MemoRAG支持缓存分块、索引和编码,将上下文预填充速度提高多达30倍。
- 上下文重用:MemoRAG一次性编码长上下文,并支持重复使用,提高需要重复数据访问的任务的效率。
工作流程:
- 记忆构建:MemoRAG使用高效的超长记忆模型,对大规模数据集进行编码,形成全局记忆。
- 线索生成:在接收到查询后,MemoRAG从全局记忆中回忆相关线索,指导后续的证据检索。
- 证据检索:根据生成的线索,MemoRAG在数据库中检索相关证据,提供给生成模型。
- 答案生成:生成模型结合检索到的证据,生成准确且全面的答案。
优势:
- 处理复杂查询:MemoRAG在处理需要对整个数据库进行高级理解的查询时,表现出色。
- 高效处理大规模数据:通过全局记忆和高效缓存机制,MemoRAG能够快速处理大规模数据集,提升响应速度。
- 灵活适应新任务:MemoRAG易于适应新任务,仅需少量的额外训练即可实现性能优化。
通过引入高效的超长记忆模型,MemoRAG为检索增强生成提供了新的思路,特别是在处理复杂查询和大规模数据集时,展现出显著的性能提升。
ATLAS: Attention-based retrieval Augmented Sequence generation
ATLAS 是一种基于注意力的检索增强序列生成模型,通过检索外部文档来提高语言模型在问答等任务中的准确性。它使用双编码器检索器在大型文本库中查找最相关的文档,并通过“Fusion-in-Decoder”模型整合查询和文档数据,生成最终答案。ATLAS 依赖动态文档检索,而非记忆大量信息,减少了参数数量。文档索引可以在不重新训练模型的情况下更新,适合处理知识密集型任务。

ATLAS(Attention-based Retrieval Augmented Sequence generation)是一种检索增强的语言模型,旨在通过引入外部知识检索机制,提升模型在知识密集型任务中的表现。该模型由Meta AI提出,能够在少量训练样本的情况下,学习并执行复杂的知识任务。
主要特点:
- 检索增强:ATLAS在生成过程中,利用检索模块从外部文档库中获取相关信息,增强模型的知识基础。
- 少样本学习:通过引入检索机制,ATLAS在少量训练样本的情况下,仍能在多种任务上取得优异表现。
- 可更新性:ATLAS的文档索引内容可以轻松更新,确保模型能够及时获取最新信息。
工作流程:
- 输入处理:接收用户查询,利用检索模块从外部文档库中获取相关文档。
- 信息融合:将检索到的文档与原始查询结合,输入到生成模块。
- 答案生成:生成模块根据融合的信息,生成最终的回答。
优势:
- 提升准确性:通过引入外部知识,ATLAS在回答复杂问题时,能够提供更准确和全面的答案。
- 高效学习:在少样本的情况下,ATLAS仍能快速学习并适应新任务,减少对大量标注数据的依赖。
- 灵活更新:文档索引的可更新性使ATLAS能够及时获取最新信息,保持模型的时效性。
通过引入检索增强机制,ATLAS在处理知识密集型任务时展现出强大的能力,为自然语言处理领域提供了新的思路。
RETRO: Retrieval-Enhanced Transformer
RETRO 是一种检索增强型Transformer,它将输入文本分割为较小的片段,并从大型数据库中检索相关信息。通过预训练的BERT嵌入,它从外部数据中提取相似片段来丰富上下文,并通过分块交叉注意力机制整合这些片段,从而提升预测精度而不显著增加模型规模。此方法更高效地利用外部知识,特别适用于问答和文本生成任务,同时避免了大模型的高计算成本,能更好地处理海量信息。

RETRO(Retrieval-Enhanced Transformer)是一种由DeepMind提出的语言模型架构,通过在生成过程中引入检索机制,显著提升模型的性能和效率。与传统的Transformer模型相比,RETRO在生成每个词时,都会检索外部数据库中的相关文档片段,并将这些检索结果作为额外的上下文信息,辅助生成过程。
主要特点:
- 检索增强生成:在生成每个词时,模型会根据当前的上下文,从外部数据库中检索相关的文档片段,并将这些片段作为额外的输入,提供给生成模型。
- 高效的参数利用:通过引入检索机制,RETRO在参数数量远小于GPT-3的情况下,达到了与之相当的性能。具体而言,RETRO使用了25倍更少的参数,但在多个基准测试中表现出色。
- 可扩展的外部数据库:模型的性能与外部数据库的规模和质量密切相关。通过扩展和更新数据库,RETRO可以持续提升其生成能力。
工作流程:
- 输入处理:接收用户输入的文本序列。
- 检索相关文档:根据当前的上下文,从外部数据库中检索与之相关的文档片段。
- 融合信息生成:将检索到的文档片段与原始上下文信息融合,输入到生成模型中,生成下一个词。
- 重复迭代:重复上述过程,直至生成完整的文本序列。
优势:
- 提升生成质量:通过引入外部知识,模型能够生成更准确和信息丰富的文本。
- 减少参数需求:利用检索机制,模型在参数数量较少的情况下,仍能达到高性能。
- 易于更新:通过更新外部数据库的内容,模型可以快速适应新知识和信息。
通过引入检索机制,RETRO在语言生成任务中展现出强大的能力,为自然语言处理领域提供了新的思路。
LightRAG: Simple and Fast Retrieval-Augmented Generation
LightRAG 是一个简单快速的检索增强生成(RAG)系统,适用于多种自然语言处理任务,支持OpenAI和Hugging Face语言模型,并提供多种检索模式(naive、local、global、hybrid)。与传统RAG系统不同,LightRAG 结合了知识图谱,通过图结构表示实体及其关系,增强了上下文感知能力。这种双层检索系统不仅擅长获取详细信息,还能处理复杂的多跳知识,从而解决了现有RAG系统依赖扁平数据结构、导致答案碎片化的问题,提供了更深度的、满足用户需求的响应。
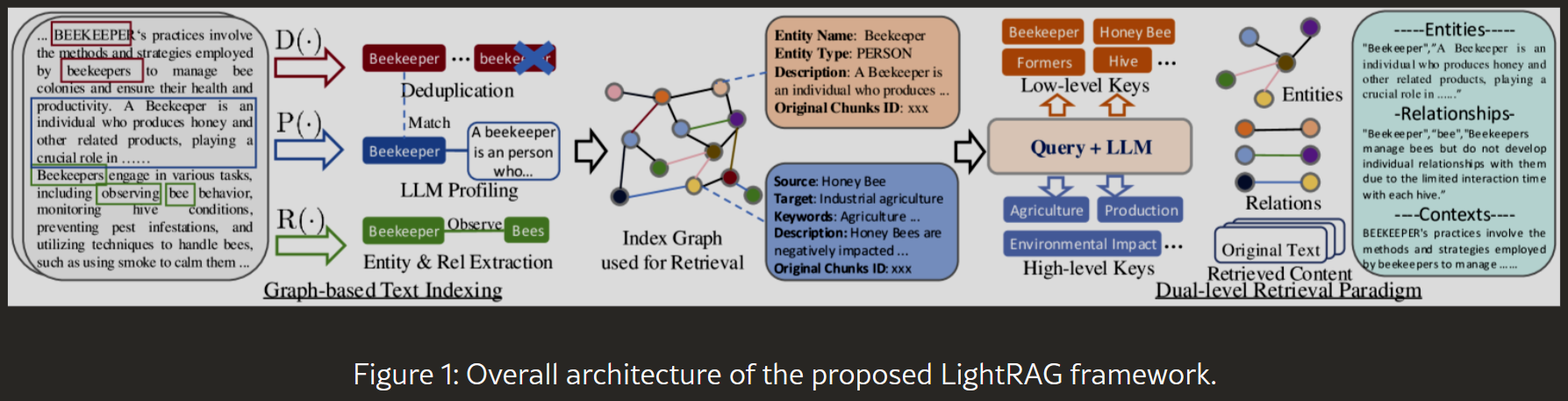
LightRAG(轻量级检索增强生成)是香港大学数据智能实验室于2024年10月推出的开源系统,旨在通过引入图结构索引和双层检索机制,提升大型语言模型在信息检索和生成任务中的准确性和效率。 GitHub
主要特点:
- 图结构索引:将文本数据表示为图结构,捕捉实体之间的复杂关系,增强模型对上下文的理解能力。
- 双层检索机制:包括低层次检索(关注具体实体及其关系)和高层次检索(涵盖更广泛的主题和概念),确保信息检索的全面性。
- 增量更新算法:设计了高效的增量更新算法,确保新数据能够及时整合,使系统在动态数据环境中保持有效性和响应性。
工作流程:
- 图结构构建:将文本数据处理为图结构,节点代表实体,边表示实体之间的关系。
- 双层检索:根据用户查询,首先进行低层次检索,获取具体实体信息;然后进行高层次检索,获取相关主题和概念。
- 生成回答:结合检索结果,利用语言模型生成上下文相关的回答。
优势:
- 提升检索效率:通过图结构和双层检索机制,显著提高信息检索的准确性和效率。
- 处理复杂查询:能够理解和回答涉及多个实体和关系的复杂查询。
- 适应动态数据:增量更新算法使系统能够快速适应数据变化,保持最新状态。
应用场景:
- 搜索引擎:提升搜索结果的相关性和准确性。
- 智能客服:提供更准确和上下文相关的回答。
- 推荐系统:根据用户兴趣,提供更精准的推荐。
LightRAG的开源代码已在GitHub上发布,供研究者和开发者使用和改进。