音视频开发之旅(98) -潜扩散模型(Latent Diffusion Model)原理及源码解析
目录
1.背景
2. 潜扩散模型(Latent Diffusion Model)原理
3. 应用场景
4. 推理源码解析
5. 资料
一、背景
前面我们分析扩散模型(Diffusion Model)了解到,它通过向数据中添加噪声,然后训练一个去噪模型实现数据的还原,扩散模型在图像生成、图像修复等任务中表现了很好的效果,尤其是生成质量和多向性方面有显著的优势。但其本身是一个马尔科夫链的过程,即前后时刻数据有非常紧密的绑定关系,无法进行跳跃预测,生成过程通常需要超多轮次迭代导致生成速度较慢。并且它是直接在原始像素空间进行操作,对于高分辨率的图像生成任务,训练和推理都需要大量的计算资源。
为了在有限的计算资源上进行Diffusion Model的训练,同时保证其生成质量和灵活性,本论文作者创新性的提出将扩散过程应用于高度压缩的潜空间而不是原始的像素空间,并且通过交叉注意力机制,将条件输入(例如:文本描述,图像语义等)注入到网络,使得生成更符合预期的图像。
二、潜扩散模型(Latent Diffusion Model)原理
2.1 语义压缩(Semantic Compression)和感知压缩(Perceptual Compression)
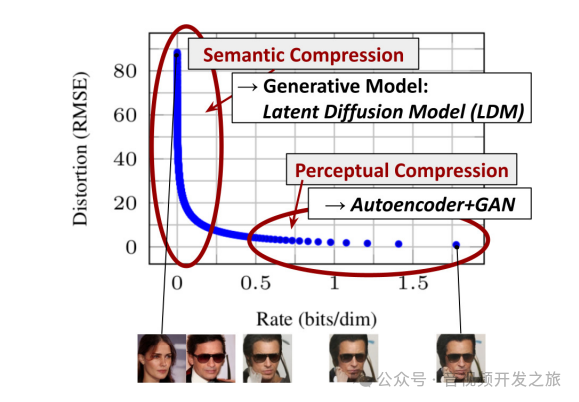
上图横坐标Rate(bits/dim)表示每个像素所需的比特数,Rate越高,表示编码压缩后的图像包含的细节越多,最左侧原图的Rate被设置为接近0,是因为进行语义压缩之前,原图在这条压缩率-失真曲线上没有经过压缩状态,将其设置为0作为参考点。
纵坐标(Distortion RMSE)是通过均方根RMSE计算的失真,值越大表示原图失真率越低。
右上角展示了语义压缩(Semantic Compression),目标是去除图像中对语义(或者称为人类视觉)不重要的信息。这个阶段失真(RMSE)从100快速下降到10左右,这意味着大部分图像数据的减少,而图像中很多的位信息对应的是人类视觉系统感知不到的细节,这些细节可以被大量压缩或者丢弃,不影响对整体图像的理解。
语义压缩在库潜扩散模型中被应用于,将输入的图像x经过编码器ϵ进入潜空间z的过程,编码器会在这个过程中丢弃图像中不重要的细节信息,只保留图像的核心语义,即高层语义信息。
右下角展示了感知压缩(Perceptual Compression),目标是保留图像的视觉细节,即使细微的变换也要保证图像的视觉效果不发生明显的变换。它是通过自动编码器(Autoencoder)+生成对抗网络(GAN)来保证图像的细节和质感。这个阶段的比特率Rate上升主要用于保存图像的精细特征。
感知压缩主要用在图像重建的过程,特别是潜空间中的扩散过程和去噪过程,扩散过程的每个步都在逐渐去噪恢复图像的细节,尤其是去噪UNet网络中的交叉注意力机制(Cross-Attention)和跳跃连接(Skip Connection)在这个过程中通过起到重要作用。通过感知压缩机制,逐渐生成那些细微的、对人类视觉重要的细节(如面部纹理、光影变化等)。
如果注意看会发现:上图下方人脸图像,第一张是女生图像,后面变成了男生图像。这是因为,随着语义压缩,模型逐渐丢弃了图像中的”不重要的“细节信息,只保留了大致的语义结构,后续模型在极低Rate情况下重建的图像可能因缺乏性别等细节特征,生成了男生形象,这反映了生成模型在生成图像时高层语义上的一些不确定性。
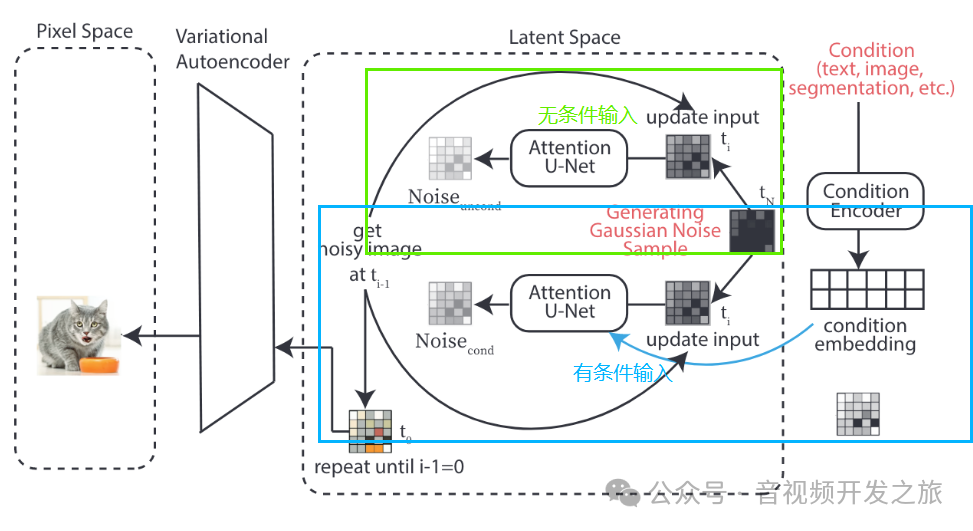
2.2 网络结构和流程
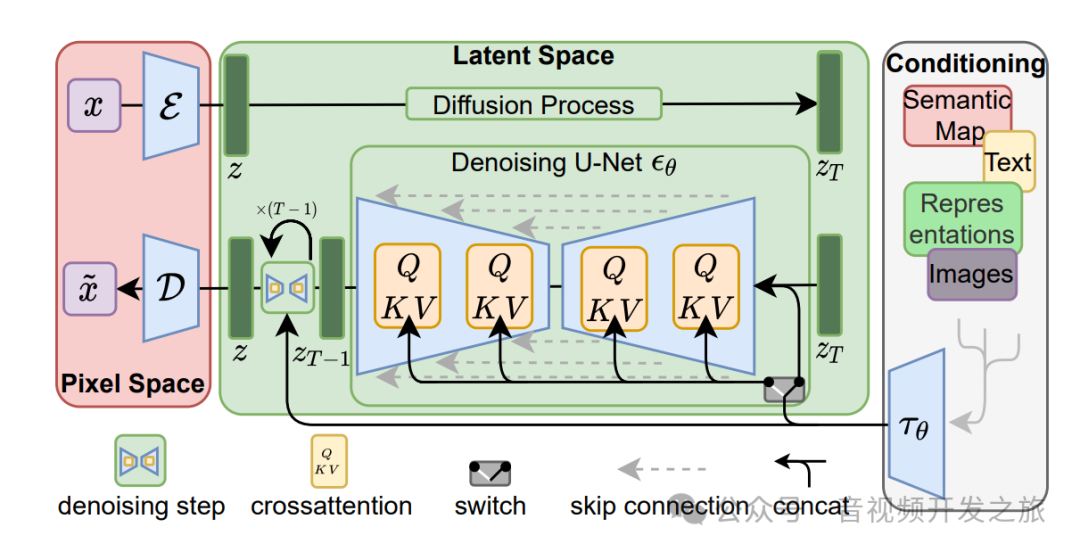
图片来自:论文High-Resolution Image Synthesis with Latent Diffusion Models
训练过程:
1. 像素空间到潜在空间:图像x从原始的高纬的像素空间(Pixel Space)经过编码器ϵ,压缩到低维的潜在空间(Latent Space)表示z;
2. 在潜在空间进行使用U-Net网络进行前向扩散处理(Diffusion Process),训练潜空间的去噪模型
推理阶段:
1. 将文本、语义图等数据作为条件输入(Conditioning),通过特定的编码器映射到和潜在空间相同的维度,用于指导图像生成过程
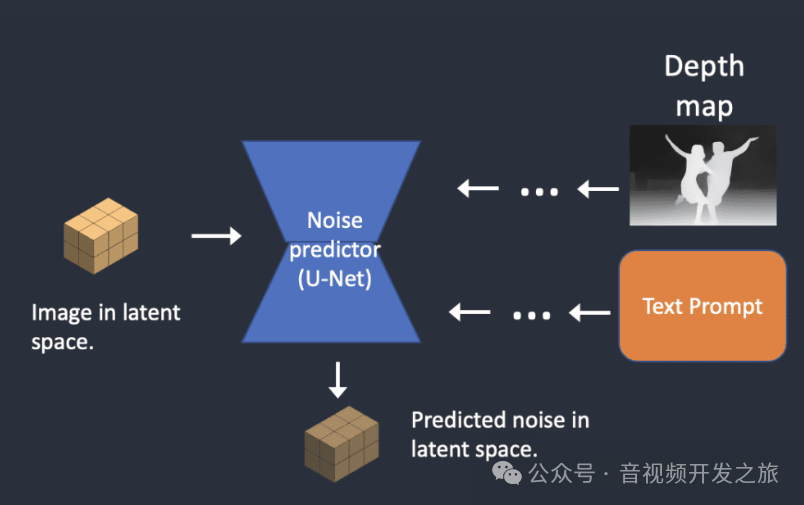
图片来自:how-stable-diffusion-work
2. 使用去噪U-Net网络,在潜空间将噪声图像逐步去噪生成清晰的图像(Z_T,Z_T-1,...,Z_0),U-Net中包含多个跳跃连接(skip connections)和交叉注意力机制(cross-attention),其中跳跃连接有助于不同尺度的特征融合,交叉注意力机制则用来整合条件输入和噪声图像,图像用于Q矩阵的生成,条件输入则用于K和V,使得模型在生成图像的每一步动态地关注条件输入的不同部分,从而生成与条件输入更紧密相关的潜空间图像
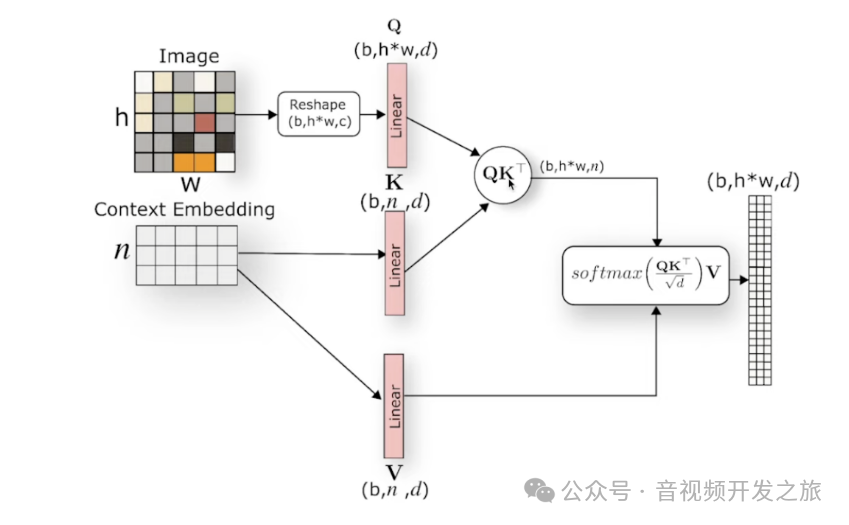
图片来自:Latent Diffusion Models (LDMs) 模型学习笔记
3. 使用解码器D将生成的潜空间图像转换为像素空间,得到重建的图像
另外还有个Switch模块,表示在扩散过程不同阶段可以在不同模式(有条件和无条件生成)之间切换。整体流程如下图所示:
2.3 公式解读
下面两个公式分别表示扩散模型(Diffusion Model,简称DM)和潜扩散模型(Latent Diffusion Model,简称LDM)的核心优化目标。
主要区别在于:DM直接操作的是高维的原始数据空间(像素空间),而LDM直接操作的是经过编码器编码后的ϵ(x)所在的低维的潜在空间,大大降低了计算负担。
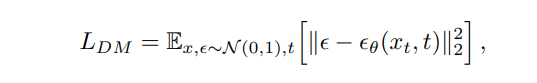
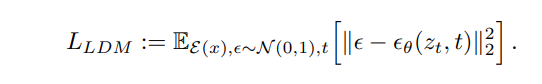
x 是原始图像数据
ϵ(x)是通过编码器ϵ从原始数据x获得的潜在表示
ϵ~N(0,1),是从标准正态分布N(0,1)中采样的噪声
X_t是在时间步骤t时加噪声的数据,Z_t则是在时间步骤t时加噪声的潜在表示
![]()
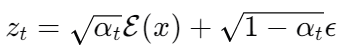
∥⋅∥是欧几里得距离,这里使用的是L2范数,用于衡量预测的噪声和实际噪声之间的差异
三、应用场景
文生图

图生图

图像超分

图像Inpainting修复

四、推理源码解析
基于https://github.com/CompVis/latent-diffusion分析
Latent Dissusion的训练分为两阶段:
第一阶段训练自编码器(AutoencoderKL),具体实现在latent-diffusion/ldm/models/autoencoder.py
第二阶段训练Diffusion(基于DDPM),具体实现在latent-diffusion-main/ldm/models/diffusion/ddpm.py
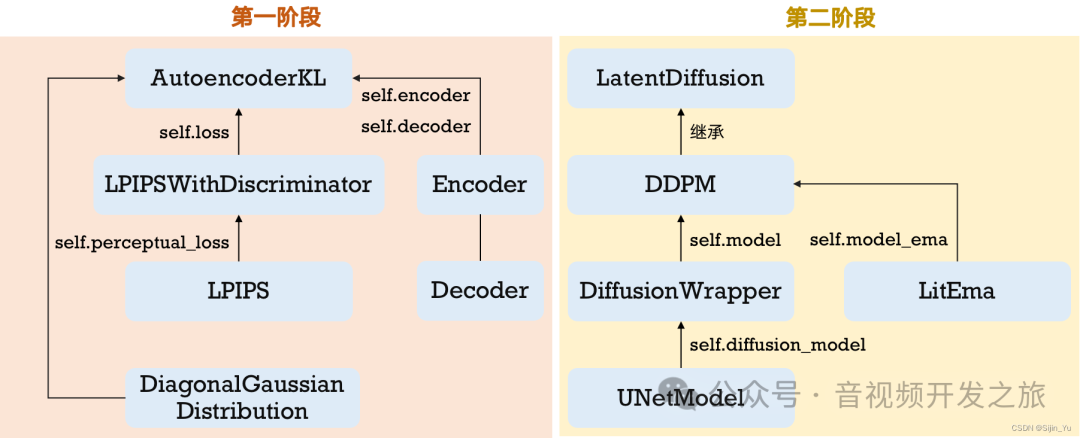
图片来自:一文详解 Latent Diffusion官方源码
下面我们看下推理的过程
使用示例(以文生图为例)
流程:获取配置、加载模型,初始化DDIM采样器、进行采样去噪生成图片
这里使用的DDIM采样器(Denoising Diffusion Implicit Models)而不是DDPM采样器(Denoising Diffusion Probabilistic Models),DDIM的主要改进点有:
1. 不再严格遵循马尔科夫过程,允许在采样过程中跳过部分中间步骤,直接从高噪声状态向低噪声状态过渡。使得采样步数大幅减少(10-20步 vs 1000步),从而显著降低计算量和加快生成速度。
2. DDIM提供了一种更灵活的采样策略,可以通过调整参数来控制生成过程的方差。这使得DDIM在生成样本的多样性和质量之间提供了更好的平衡。
class Txt2Img():def __init__(self):#txt2img-1p4B-eval.yaml中配置了LatentDiffusion、UNetModel、AutoencoderKL和BERTEmbedder相关配置config = OmegaConf.load("configs/latent-diffusion/txt2img-1p4B-eval.yaml")#加载模型self.model = load_model_from_config(config, "models/ldm/text2img-large/model.ckpt")device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")self.model = self.model.to(device)#设置采样器,这里使用DDIM,而不是DDPM,加速推理过程self.sampler = DDIMSampler(model)def do_predict(self,prompt,outpath,ddim_steps=50,ddim_eta=0.0,n_iter=4.0,W=256,H=256,n_samples=4,scale=5.0):sample_path = os.path.join(outpath, "samples")os.makedirs(sample_path, exist_ok=True)all_samples=list()with torch.no_grad():with self.model.ema_scope():uc = Noneif scale != 1.0:uc = self.model.get_learned_conditioning(n_samples * [""])for n in trange(n_iter, desc="Sampling"):c = self.model.get_learned_conditioning(n_samples * [prompt])shape = [4, H//8, W//8]#调用DDIM采用器,进行图像生成samples_ddim, _ = self.sampler.sample(S=ddim_steps,conditioning=c,batch_size=n_samples,shape=shape,verbose=False,unconditional_guidance_scale=scale,unconditional_conditioning=uc,eta=ddim_eta)x_samples_ddim = self.model.decode_first_stage(samples_ddim)x_samples_ddim = torch.clamp((x_samples_ddim+1.0)/2.0, min=0.0, max=1.0)for x_sample in x_samples_ddim:x_sample = 255. * rearrange(x_sample.cpu().numpy(), 'c h w -> h w c')Image.fromarray(x_sample.astype(np.uint8)).save(os.path.join(sample_path, f"{base_count:04}.png"))base_count += 1all_samples.append(x_samples_ddim)# additionally, save as gridgrid = torch.stack(all_samples, 0)grid = rearrange(grid, 'n b c h w -> (n b) c h w')grid = make_grid(grid, nrow=n_samples)# to imagegrid = 255. * rearrange(grid, 'c h w -> h w c').cpu().numpy()Image.fromarray(grid.astype(np.uint8)).save(os.path.join(outpath, f'{prompt.replace(" ", "-")}.png'))
DDIMSampler
latent-diffusion-main/ldm/models/diffusion/ddim.py
sample 方法是类的主入口点,用于生成样本。它接受多个参数,包括采样步数 S、批量大小 batch_size、图像形状 shape 等。
ddim_sampling 方法执行实际的采样过程。它使用 tqdm 进度条来跟踪采样进度,并在每一步中调用 p_sample_ddim 方法来更新图像。p_sample_ddim 方法执行单个时间步的采样。它计算当前时间步的预测值 pred_x0 和下一个时间步的图像 x_prev。这个方法使用了模型的参数,如 alphas、betas 和 sigmas,以及一些辅助函数来计算噪声和预测值。p_sample_ddim 实现如下所示
def p_sample_ddim(self,x, # 当前时刻的噪声图像c, # 条件信息(如文本提示)t, # 当前时间步index, # 时间步索引repeat_noise=False, # 是否重复使用噪声use_original_steps=False, # 是否使用原始DDPM步数quantize_denoised=False, # 是否量化去噪结果temperature=1., # 采样温度noise_dropout=0., # 噪声dropout率score_corrector=None, # 分数修正器unconditional_guidance_scale=1., # 无条件引导比例unconditional_conditioning=None # 无条件信息):# 如果没有无条件引导或比例为1,直接用条件信息预测噪声if unconditional_conditioning is None or unconditional_guidance_scale == 1.:e_t = self.model.apply_model(x, t, c)else:# Classifier-Free Guidance (CFG)实现x_in = torch.cat([x] * 2) # 复制输入t_in = torch.cat([t] * 2) # 复制时间步c_in = torch.cat([unconditional_conditioning, c]) # 拼接条件# 分别得到无条件和有条件的预测e_t_uncond, e_t = self.model.apply_model(x_in, t_in, c_in).chunk(2)# CFG公式:预测 = 无条件预测 + scale * (有条件预测 - 无条件预测)e_t = e_t_uncond + unconditional_guidance_scale * (e_t - e_t_uncond)# 根据是否使用原始步数选择相应的参数alphas = self.model.alphas_cumprod if use_original_steps else self.ddim_alphasalphas_prev = self.model.alphas_cumprod_prev if use_original_steps else self.ddim_alphas_prevsqrt_one_minus_alphas = self.model.sqrt_one_minus_alphas_cumprod if use_original_steps else self.ddim_sqrt_one_minus_alphassigmas = self.model.ddim_sigmas_for_original_num_steps if use_original_steps else self.ddim_sigmas# 获取当前时间步的参数值a_t = torch.full((b, 1, 1, 1), alphas[index], device=device)a_prev = torch.full((b, 1, 1, 1), alphas_prev[index], device=device)sigma_t = torch.full((b, 1, 1, 1), sigmas[index], device=device)sqrt_one_minus_at = torch.full((b, 1, 1, 1), sqrt_one_minus_alphas[index], device=device)#DDIM采样核心步骤# 预测x0(原始图像)pred_x0 = (x - sqrt_one_minus_at * e_t) / a_t.sqrt()# 可选的量化操作if quantize_denoised:pred_x0, *_ = self.model.first_stage_model.quantize(pred_x0)dir_xt = (1. - a_prev - sigma_t**2).sqrt() * e_t# 生成噪声noise = sigma_t * noise_like(x.shape, device, repeat_noise) * temperatureif noise_dropout > 0.:noise = torch.nn.functional.dropout(noise, p=noise_dropout)# DDIM更新公式:计算上一时刻的图像x_prev = a_prev.sqrt() * pred_x0 + dir_xt + noisereturn x_prev, pred_x0
五、资料
论文High-Resolution Image Synthesis with Latent Diffusion Models:https://arxiv.org/pdf/2112.10752
论文源码:GitHub - CompVis/latent-diffusion: High-Resolution Image Synthesis with Latent Diffusion Models
sd-v1:GitHub - CompVis/stable-diffusion: A latent text-to-image diffusion model
sd-v2:GitHub - Stability-AI/stablediffusion: High-Resolution Image Synthesis with Latent Diffusion Models
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis:https://arxiv.org/pdf/2307.01952
how-stable-diffusion-work:https://stable-diffusion-art.com/how-stable-diffusion-work
The Illustrated Stable Diffusion:The Illustrated Stable Diffusion – Jay Alammar – Visualizing machine learning one concept at a time.
一文读懂Stable Diffusion 论文原理+代码超详细解读:https://zhuanlan.zhihu.com/p/640545463
深入浅出完整解析Stable Diffusion(SD)核心基础知识:https://zhuanlan.zhihu.com/p/632809634
一文详解 Latent Diffusion官方源码: https://blog.csdn.net/yusijinfs/article/details/134684608
Latent Diffusion Models (LDMs) 模型学习笔记 https://blog.csdn.net/hjhr2018/article/details/140152429
DIFFUSION 系列笔记| Latent Diffusion Model https://kevinng77.github.io/posts/notes/articles/%E7%AC%94%E8%AE%B0latent_diffusion.html
深入浅出 diffusion(5):理解 Latent Diffusion Models(LDMs) https://blog.csdn.net/m0_37324740/article/details/135939637
Latent Diffusion:开始的开始 https://zhuanlan.zhihu.com/p/652186695
一文带你看懂DDPM和DDIM(含原理简易推导,pytorch代码)https://zhuanlan.zhihu.com/p/666552214
感谢你的阅读
接下来我们继续学习输出AI相关内容,欢迎关注公众号“音视频开发之旅”,一起学习成长。
欢迎交流