如何在建设 DataOps 体系中选择合适的工具或平台?
纵观企业数据工程架构,在 2010 年前后有着明显变革。之前我们可称为“传统数据工程架构”,之后可称为“现代数据工程架构”,用海外的业内术语也可称为“传统数据堆栈”(Traditional Data Stack)和“现代数据堆栈”(Modern Data Stack)。
如今,随着“现代数据工程架构”的广泛应用,产生出越来越多的新问题,如:多系统分散组织,彼此间的割裂导致企业需要跨多系统工作,且每个系统只解决一部分问题,缺乏一个面向最终交付的平台,以及多系统间的运维操作风险难以把控等。同时,随着数据工程体系的复杂度进入亿级、十亿级、百亿级,“现代数据工程架构”面临着更大的挑战:
一、数据协同难:企业数据应用场景增加,参与数据管道构建团队增多,数据管道持续增长,下游团队持续增多,数据管道“烟囱化”越来越严重,形成日益复杂的工作流和数据流。
二、数据管理难:数据量成倍增加,ETL 任务成倍增长, ETL 工程师人均维护数据流中的表和数据管道的数量成倍增加,依靠 ETL 工程师很难在高度复杂数据流中找到优化方案。
三、数据交付难:越来越多的业务场景要求需求响应效率从月/周到天/时,数据分析更灵活性,支持多维度明细下探,强调数据分析一致性,以及技术上成本、风险的平衡。
在此背景下,DataOps 的出现,可以突破“现代数据工程架构”的困境,帮助企业实现“数据优先工程架构”,通过“端到端”打通数据流水线,打破“点对点”的低效数据协作流程,实现“手递手”的数据价值释放。一言以蔽之,按时按质高效交付高质量数据。
具体到建设 DataOps 体系,我们需要进行分层设计,分别负责“工作流”、“数据流”和“控制流”。“工作流”涵盖数据探查、开发、测试、部署、运维和监控等活动;“数据流”涵盖数据从入湖仓、湖仓内加工、湖仓内流转到数据出仓湖进入各个应用场景的完整链路;“控制流”是 DataOps 体系的感知决策中心,通过实时采集、解析和分析各项元数据信息,驱动工作流和数据流的敏捷流转和持续迭代。而要基于元数据构建控制流,需要从传统的被动模式改变为主动模式。
作为国内 Data Fabric 架构理念的实践者与引领者,Aloudata 大应科技首倡 NoETL 理念,通过自主研发的算子级血缘解析技术,打造了全球首个算子级血缘主动元数据平台——Aloudata BIG,自动构建精细、准确、全面、实时的数据血缘图谱,彻底改变过往元数据不准确、不连通、不精细、不保鲜的顽疾,“让元数据能用起来”。
在此基础上,Aloudata BIG 主动元数据平台,能够作为企业内统一的元数据中心和 DataOps 体系的控制中心,即控制流,驱动企业 DataOps 体系实现主动数据管理和敏捷数据协同。
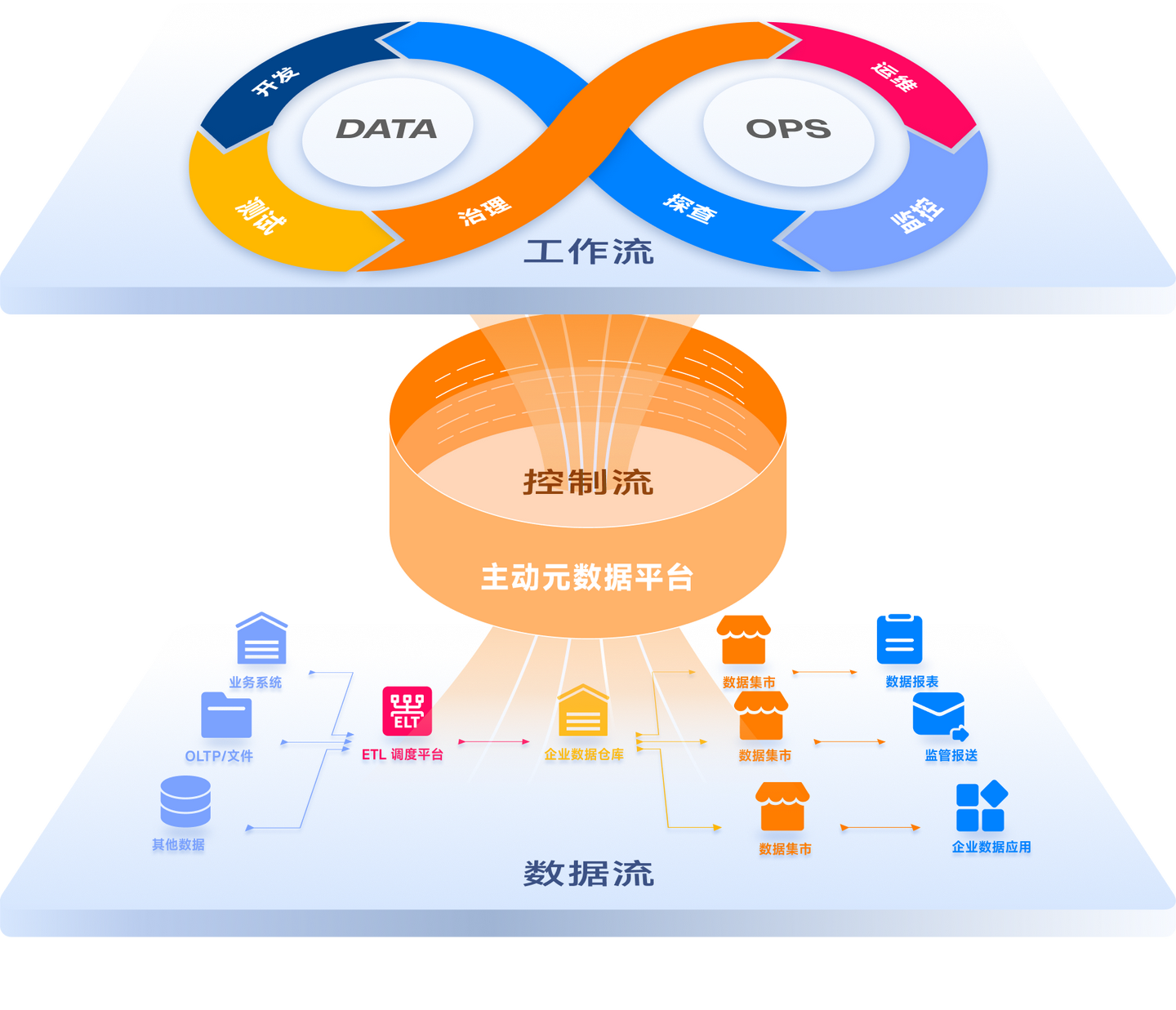
通过 Aloudata BIG 主动元数据平台,能够为企业 DataOps 体系建设提供四大能力支持:
一、算子级血缘解析:基于语义分析技术实现对 SQL 脚本的算子级自动解析和算子级血缘图谱构建,实现了对全域字段计算语义的精准刻画。
二、元数据语义挖掘:自动抽取字段算子级加工口径,结合上下游元数据信息挖掘业务语义,自动生成业务描述;对元数据进行分类、关联分析等,实现全域数据自动判重和编目。
三、主动元数据服务:基于对元数据的深入分析和挖掘,可提供高置信的建议或设计方案;通过挖掘行为元数据提供数据使用建议;通过分析链路冗余依赖提供时效优化建议。
四、反向元数据集成:可配置化提供各类服务 API,与客户的数据资产管理平台、数据集成开发平台或其他数据工具无缝集成,无需改变使用习惯,与 DataOps 工作流、数据流打通。
目前,Aloudata BIG 已帮助招商银行逐步推进 DataOps 体系建设,不仅将现有血缘图谱升级为算子级血缘图谱,实现 99% 的血缘解析准确率,更实现了元数据应用智能化、链路保障自动化和架构治理长效化,推动数仓快速实现资产数量下降 40%、平均链路缩短 50%。如您对 DataOps 体系建设和主动元数据感兴趣,欢迎访问 Aloudata 官网,了解更多。