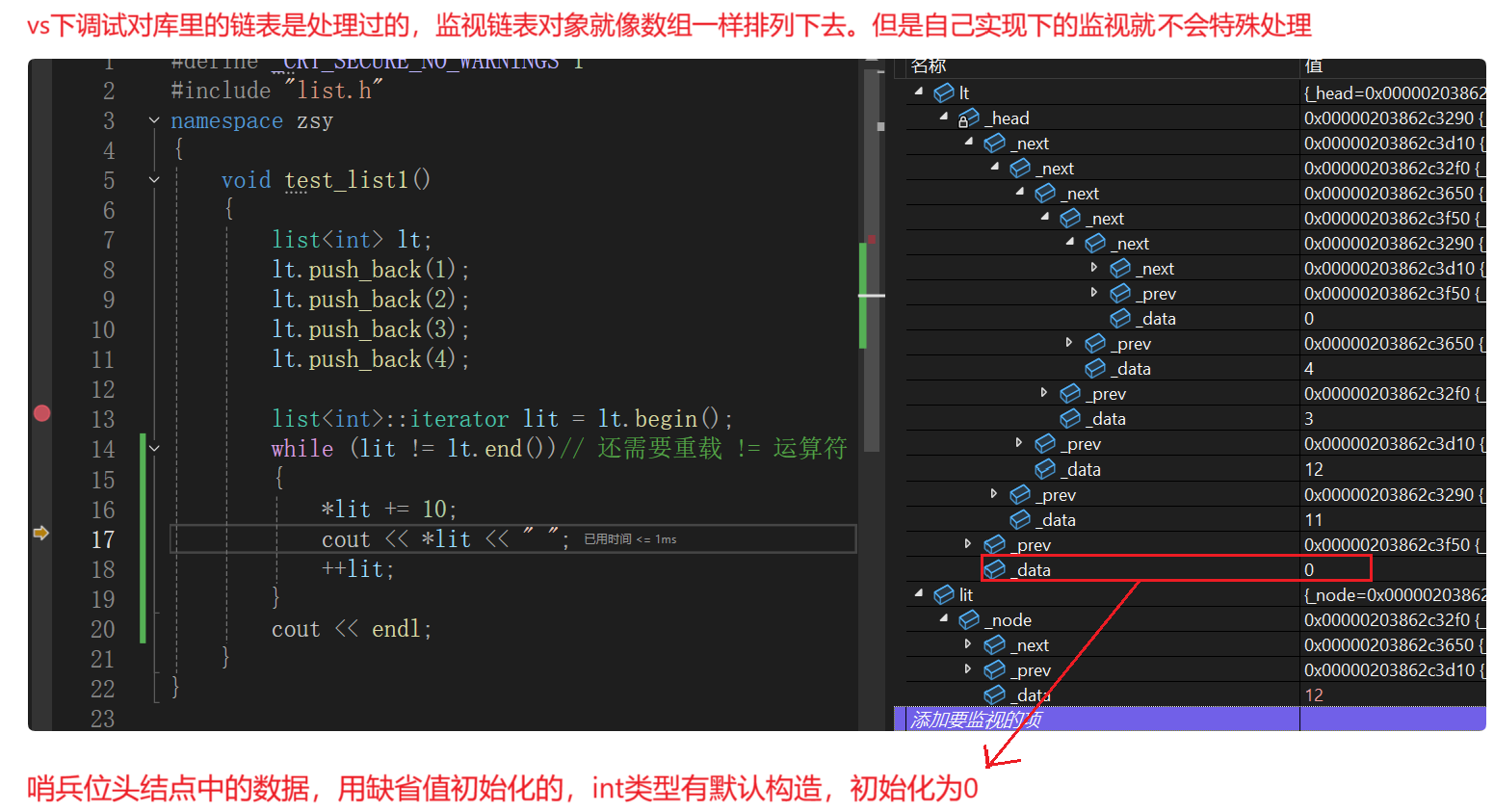
第七讲 | list的使用及其模拟实现
list的使用及其模拟实现
- 一、list的使用
- 1、push_front、pop_front
- 2、只有一种遍历方式:迭代器
- 3、Capacity
- 4、list自己增加的接口
- sort
- 迭代器分类
- splice(剪切粘贴)
- 场景一:一个链表的结点移动到另一个链表里
- 场景二:调整一个链表里的结点顺序
- 二、list的底层及其模拟实现
- 1、list的底层
- 三个类模板:结点、迭代器、带头双向循环链表
- 成员变量
- 构造函数
- 尾插、头插利用insert
- 迭代器
- insert
- 2、list的模拟实现
- (1)、关于用struct定义类
- (2)、结点类模板
- (3)、list类模板
- 结点、链表的基本结构(含构造、push_back)
- (4)、迭代器类模板
- 迭代器和链表是如何配合的?为什么一定要定义出3个类模板?
- 完善迭代器中运算符的重载:后置`++`、`==`、前置`--`、后置`--`。
- (5)、目前list的基本结构
- (6)、完善list常见的接口
- 插入删除
- size的两种实现方式
- 析构函数
- 拷贝构造
- 赋值运算符重载
- const迭代器
- 向链表中插入存储自定义类型数据的结点
- (7)、迭代器类模板的完善
- (8)、list的模拟实现完整代码
一、list的使用
list就是带头双向循环链表,之前初阶数据结构中实现的双向链表就是list。
文档链接:list
1、push_front、pop_front
我们可以查看list的接口与之前学习过的容器接口的差异,发现list提供了头删、头插接口,因为在list任意位置插入删除效率都很高。之前学习过的容器没有提供头删、头插接口是因为头部的插入删除效率低,并且可以用insert、erase实现。

2、只有一种遍历方式:迭代器
list与vector的核心区别:list没有提供operator[ ]。对底层是数组结构的容器,例如vector,用operator[ ]访问,速度很快。对底层不是数组结构的容器,例如list,用operator[ ]访问的话,时间复杂度就是O(n)(list物理空间不连续),再加个for循环就是O(n^2)。
所以,list只有一种遍历方式:迭代器,所以说迭代器是一种通用的遍历方式。
3、Capacity
Capacity里的内容不是很多,因为list没有reserve的概念,链表结点就是用一个就新建一个,不用一个就删除一个,使用起来更简单一点。而vector底层是顺序表,需要扩容,要一次性开好空间。

4、list自己增加的接口
常规的list的使用介绍就到这里,不同的是list自己增加了一些与链表相关的接口:

merge:归并/合并两个有序序列,merge后依然有序。
remove:删除容器中与指定的值相等的所有的值。与erase不同,erase是删除指定的迭代器位置的数据。
// 删除序列中所有值为6的数
#include <iostream>
#include <list>
using namespace std;
int main()
{list<int> lt = { 1, 1, 2, 3, 4, 2, 4, 5, 6, 6, 8, 9, 5, 6 };for (auto e : lt){cout << e << " ";}cout << endl;lt.remove(6);for (auto e : lt){cout << e << " ";}cout << endl;return 0;
}

remove_if:配合仿函数使用,满足某种条件删除数据。
sort:默认排升序(<),排降序需要传递个仿函数greater(降序>)。
unique:对有序序列中的重复元素去重。只能在有序的情况下删除连续重复的值,只保留一个;数据是不连续的话,相同的值是删不到只剩一个的,数据是不连续的情况下可以在去重前用sort排好序。unique的去重操作类似双指针,有序序列下,一前一后两个指针,若双指针所指数据相等,则erase后面的指针所指,若双指针所指数据不相等,则双指针同时往后移动。
#include <iostream>
#include <list>
using namespace std;
int main()
{// 有序序列list<int> lt = { 1, 1, 2, 3, 4, 4, 5, 6, 6, 6, 8, 9 };for (auto e : lt){cout << e << " ";}cout << endl;lt.unique();for (auto e : lt){cout << e << " ";}cout << endl;return 0;
}

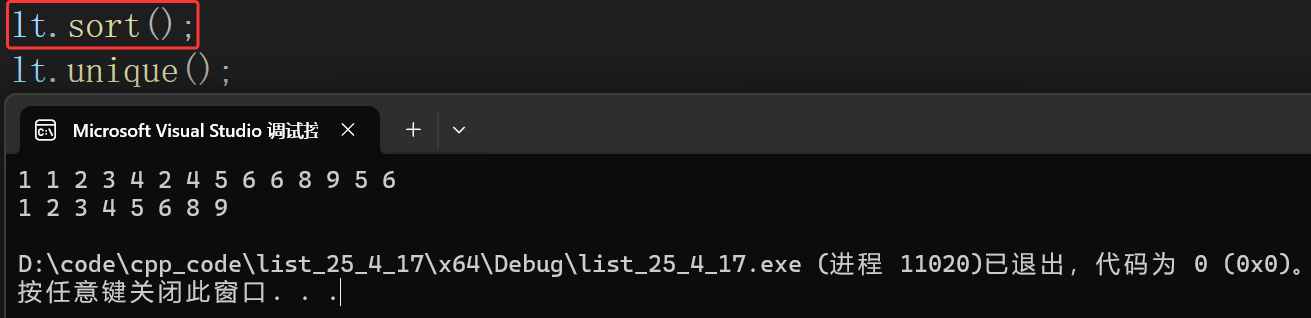
非有序序列,会导致重复元素没有删除干净:
list<int> lt = { 1, 1, 2, 3, 4, 2, 4, 5, 6, 6, 8, 9, 5, 6 };

值得深入探索的list的接口:sort和splice
sort
有两个问题:
- 为什么list不像vector一样不自己实现sort而是直接调用算法库里的sort,而是list自己单独实现了一个sort呢?
- list里的sort效率如何?
问题1解答:因为list用不了算法库里的sort,用了的话,报错会报到底层的算法库里的sort上,发现算法库sort实施了两个迭代器相减,而链表的迭代器不支持减,所以会报错。算法库里的sort对迭代器有要求,是快排,迭代器会相减。list里的sort底层用的是归并排序,链表没办法用快排。
// list用不了算法库里的sort
sort(lt.begin(), lt.end());

算法库里的算法会对使用什么类型的迭代器进行提示:

这里就要补充之前提到过的:算法库里的算法对于迭代器是有要求的,没有传递对迭代器的类型是会报错的。这里就涉及到了迭代器的分类~
迭代器分类
- 单向(Forward)迭代器。比如forward_list(单链表)、unordered_map等容器的迭代器类型就是单向迭代器。
- 双向(Bidirectional)迭代器。比如list、map等容器的迭代器类型就是双向迭代器。
- 随机(Random Access)迭代器。比如:string、vector、deque等容器的迭代器类型就是随机迭代器。
那么怎么看不同的容器各自用的是什么迭代器呢?文档中容器的Member types里会有说明,比如:
list里就是双向迭代器:

vector里就是随机迭代器:
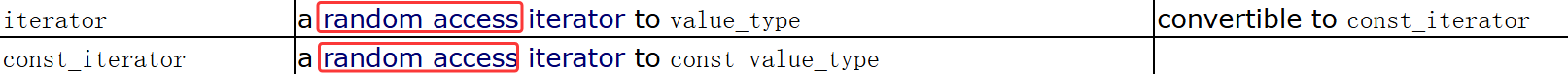
不同的迭代器支持的操作也不同,不过它们都支持解引用、== 、!= 、->等操作,它们真正的不同其实是移动迭代方式的不同,这也是迭代器分成3类的依据:
- 单向(Forward)迭代器:支持
++ - 双向(Bidirectional)迭代器:支持
++、-- - 随机(Random Access)迭代器:支持
++、--、+、-
一个容器使用什么类型的迭代器其实是由容器的底层结构决定的。
- 比如随机迭代器支持
+,一个容器用随机迭代器是因为容器的物理空间偏向连续,当然也不一定完全连续,像deque这样太复杂的就不一定连续,但是随机迭代器支持+整体而言还是比较快,可以从一个位置快速地加到你需要的位置。 - 双向迭代器支持
++向后走、--向前走都没有问题,但是双向迭代器支持+的话代价太大,原因就拿链表来说,比如加到第五个结点是不好加的,因为这些结点的地址是没有关联的,只能一个一个移动是个O(n)的结构,所以双向迭代器这里就不提供+、-了。 - 单向迭代器,像单链表这种结构就只能向前走,而不能向后走。
不同的算法对使用什么类型的迭代器是有各自的要求的,因为是通过迭代器去访问数据的,会用到迭代器的移动迭代方式。
算法的迭代器类型参数名字,暗示了要求的迭代器类型。例如,sort要随机迭代器,不用随机迭代器就会报错,因为里面的迭代器会相减求出距离;reverse要双向迭代器,问题来了:要求传递双向迭代器,但是传递的是随机迭代器,行不行?答案是行,因为这些迭代器之间有着兼容的关系,随机迭代器是个特殊的单、双向迭代器,单向的 ++ 和双向的 ++ - - 随机迭代器都满足。 同理,双向迭代器是个特殊的单向迭代器。

对于这些迭代器之间有着兼容的关系可以参考下图:

总结:要求传递单向迭代器,那么三种迭代器都可以传递;要求传递双向迭代器,那么可以传递双向、随机迭代器;要求传递随机迭代器,那么只能传递随机迭代器。

比如,find就是要求3种迭代器都可以传递。find这里用了继承体系,继承体系把3种迭代器的关系称为父子类,随机是双向的子类,双向是单向的子类,子类是一个特殊的父类。在继承模型上还加上了单独的两种迭代器:Input(只写迭代器)、Output(只读迭代器),单向迭代器继承的是只写迭代器,但是只读、只写迭代器不具有实体,可以理解为没有哪一种迭代器是只读或只写的,真实的迭代器就单向、双向、随机3种。find的迭代器类型参数名字是只写迭代器,意思是可以传递只写迭代器的子类:单向、双向、随机迭代器。结合下图理解。继承多态章节会详解。const迭代器就是一个只读迭代器。
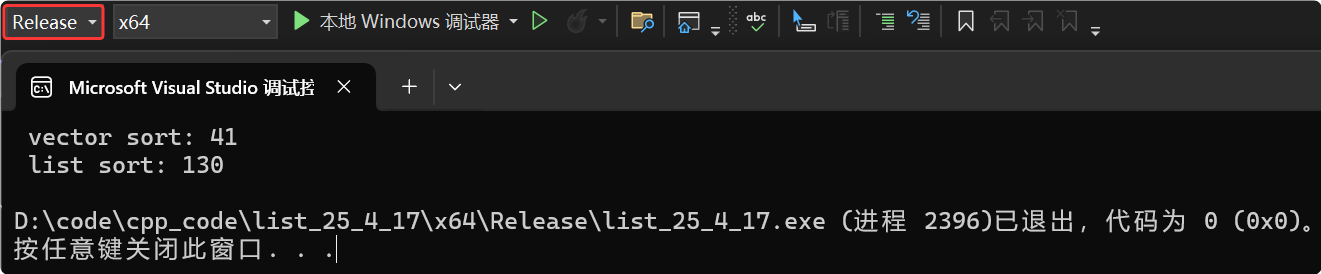
问题2解答:list里的sort效率如何?与算法库里的sort对比下来很糟糕,数据量小可以用list的sort,但是数据量大就不要用了。示例test_op1,vector使用算法库里的sort与list用自己的sort,对比一下两个sort的性能,数据量是1000000个。
void test_op1()
{srand(time(0));const int N = 1000000;list<int> lt;vector<int> v;for (int i = 0; i < N; ++i){auto e = rand() + i;lt.push_back(e);v.push_back(e);}int begin1 = clock();sort(v.begin(), v.end());int end1 = clock();int begin2 = clock();lt.sort();int end2 = clock();cout << " vector sort: " << end1 - begin1 << endl;cout << " list sort: " << end2 - begin2 << endl;
}
凡是涉及到递归的程序,不能用Debug作为结论。因为Debug版本要加各种调试信息,递归调用在Debug版本下会非常的吃亏,递归因为是多次函数的调用,要加入各种寄存器什么的没有达到极致的优化,相当于建立栈帧的代价相对较大,vector的sort用的是递归版本的快速排序,而list用的是非递归版本的归并排序,所以就导致vector的sort排序起来很吃亏。所以用Release版本下比较才对,算法库里sort和list的sort差了3倍多的性能。
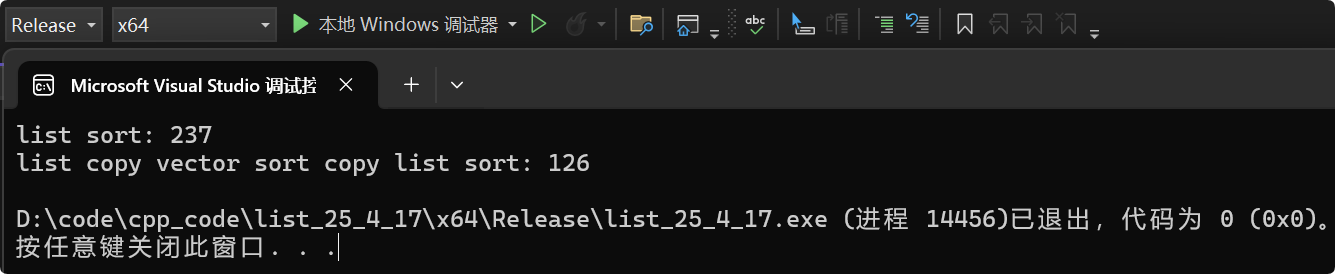
对两个链表进行排序,两个链表里有一样的数据,一个链表调用自己的sort;一个链表的数据拷贝给vector< int >,算法库sort排序,再把数据拷贝回给list。1000000个数据,再对比一下性能。
void test_op2()
{srand(time(0));// 存在着从 time_t 向 unsigned int 进行转变的过程,隐式类型转换现象const int N = 1000000;list<int> lt1;list<int> lt2;for (int i = 0; i < N; ++i){auto e = rand() + i;lt1.push_back(e);lt2.push_back(e);}int begin1 = clock();vector<int> v(lt1.begin(), lt1.end());sort(v.begin(), v.end());lt1.assign(v.begin(), v.end());int end1 = clock();int begin2 = clock();lt2.sort();int end2 = clock();cout << "list sort: " << end2 - begin2 << endl;cout << "list copy vector sort copy list sort: " << end1 - begin1 << endl;
}
在数据量大的前提下,即便把数据拷贝给vector< int >再拷贝回来的性能也比list用自己的sort快得多,所以,数据量大时别用list的sort,可以让vector去排序。
数据量为10000个时,两种sort都可以。这里的0表示小于1ms,要不然是0ms的话就太快了。

splice(剪切粘贴)
不是新建结点拷贝数据,而是直接就把结点移走了,所以同类型的链表才能用粘接接口。转移到position位置之前。
场景一:一个链表的结点移动到另一个链表里
void test_list1()
{std::list<int> lt1 = { 1, 2, 3, 4, 5 };std::list<int> lt2 = { 10, 20, 30, 40 };for (auto e : lt1){cout << e << " ";}cout << endl;for (auto e : lt2){cout << e << " ";}cout << endl;lt1.splice(lt1.begin(), lt2);for (auto e : lt2){cout << e << " ";}cout << endl;for (auto e : lt1){cout << e << " ";}
}

双向迭代器不支持+:

场景二:调整一个链表里的结点顺序
void test_list2()
{std::list<int> lt = { 1, 2, 3, 4, 5 };int x;cin >> x;auto it = find(lt.begin(), lt.end(), x);if (it != lt.end())lt.splice(lt.begin(), lt, it);for (auto e : lt){cout << e << " ";}cout << endl;
}

二、list的底层及其模拟实现
1、list的底层
直接切入重点:stl_list.h
三个类模板:结点、迭代器、带头双向循环链表
成员变量
构造函数
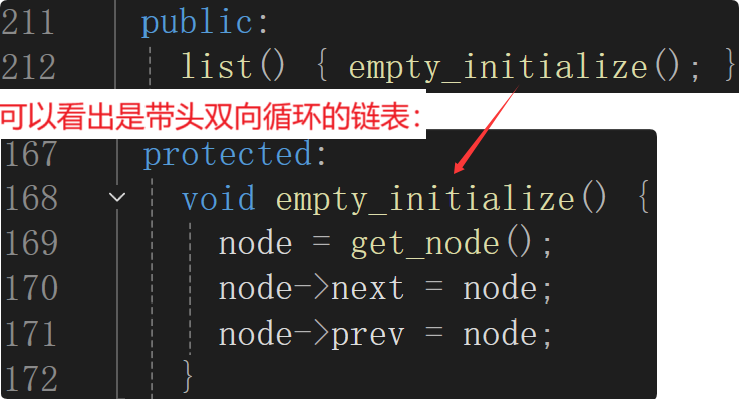
STL中不会向系统malloc()/new结点空间,而是直接调用内存池里的空间,相当于operator new/malloc()了一个结点空间,但是这个结点没有初始化,所以写了下面两个函数。destroy_node功能类似于delete,析构函数(显示调用析构函数destroy())+释放结点的空间(put_node()释放的空间给回内存池)。
尾插、头插利用insert
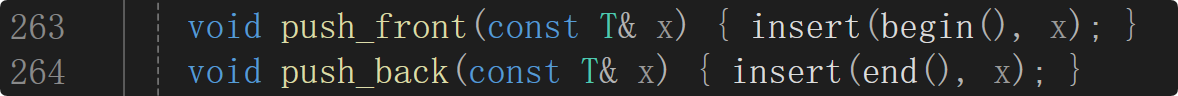
迭代器
迭代器对结点指针的封装。
若直接用结点指针是达不到迭代器的行为的,因为指针不一定是迭代器,只有指向数组的指针的行为才与迭代器一样:解引用就是当前位置的数据,++就是下一个位置。
如果迭代器是个结点指针,结点指针解引用是这个结点而不是这个结点中的数据。而迭代器的两个核心行为:解引用*it、 ++it。迭代器解引用会直接获取数据,而结点指针解引用不能获取数据;结点指针++也不是当前结点指向的下一个结点的位置,因为链表里的结点之间的物理地址不一定连续。 解决办法:用一个自定义类类型封装结点指针就能达到迭代器的效果 ,因为结点指针达不到迭代器的效果。封装了之后,核心行为operator*、operator++。*和++运算符都可以重载。*有两种意义:乘(两个操作数)和解引用(一个操作数),就算两种运算符重载同时存在也构成函数重载。
insert
position是个迭代器,里面有公有成员node:
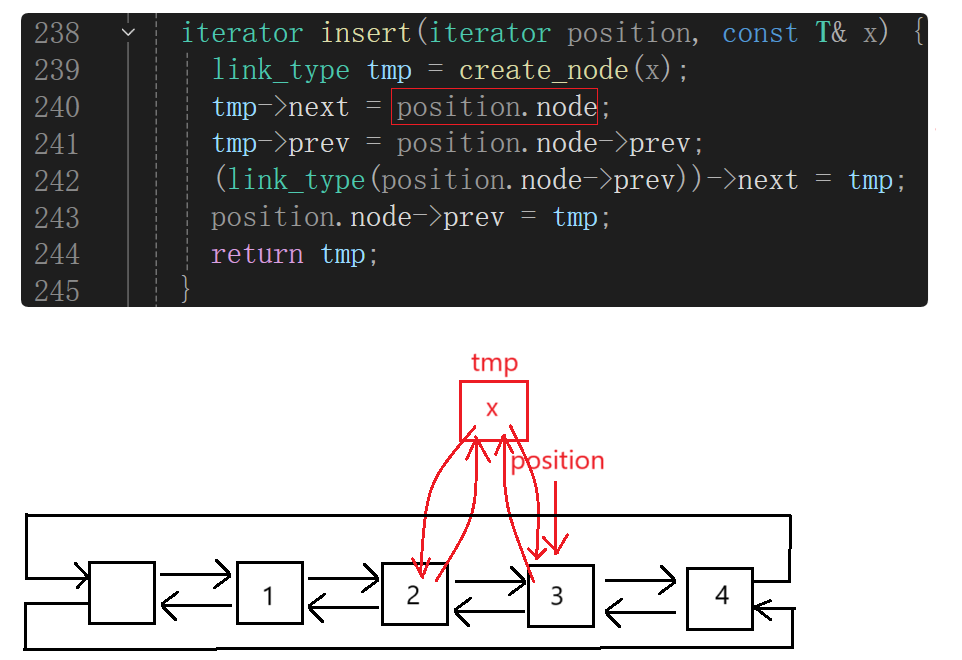
2、list的模拟实现
(1)、关于用struct定义类
一般定义一个类用class,但是在类里不想进行访问限定符的限制就用struct。若是受访问限定符private的限制,想访问私有还要通过Getxxx或友元,就很繁琐。访问结点就肯定要访问它的成员变量,要么定义类用class,对成员变量限定为公有,要么直接干脆一点用struct定义类。类似库里实现的:

用struct定义类,这样别人(例如测试的行为)不就能访问成员变量了吗?想想用链表时用得到结点吗?——是根本用不到的,因为用的都是迭代器,而迭代器在底层到底是什么是不清楚的,我们只管用,所以这都是隐形的封装。这些容器统一提供了迭代器给我们进行使用,这个迭代器有可能是个原生指针,也有可能是个自定义类型封装指针,甚至底层的成员变量是公有的,但是这些我们都不关注的,我们也不敢关注,例如,不敢通过迭代器去访问结点指针,因为可能底层结点指针叫什么名字都不知道,原因是不同平台底层实现是不一样的,比如,结点名字叫node,但是在别的平台可能叫_Ptr;next在别的平台可能叫_next;data在别的平台可能叫value。哪怕他是公有的也不敢去访问,因为不同平台底层实现是不一样的。
隐形的封装:没有用访问限定符限制,虽然可以从语法的角度上可以直接访问,但是不敢去访问的,因为不同平台底层实现是不一样的。而且也没有必要去访问,用迭代器就很好用。
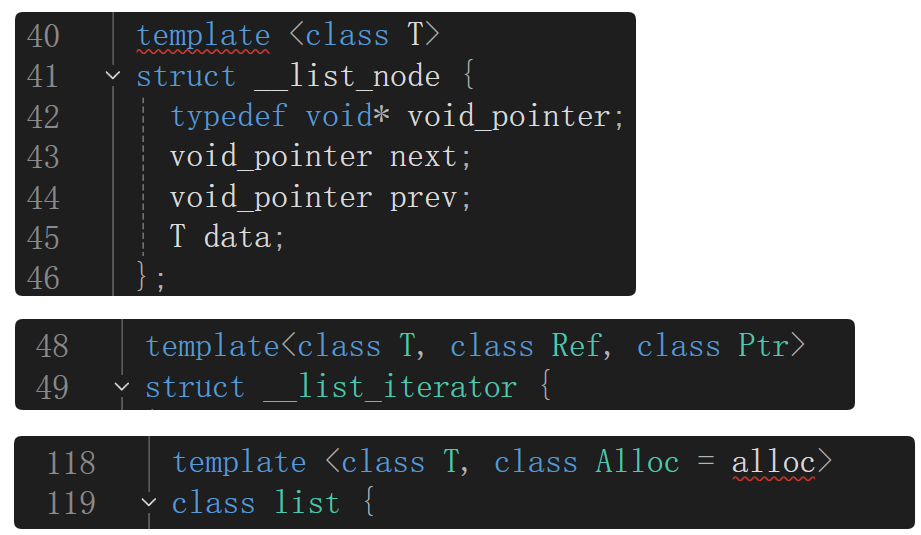
(2)、结点类模板
// 结点
template<class T>
struct list_node
{list_node* _next;list_node* _prev;T _data;// 结点的全缺省默认构造函数list_node(const T& x = T()):_next(nullptr),_prev(nullptr),_data(x){}
};
(3)、list类模板

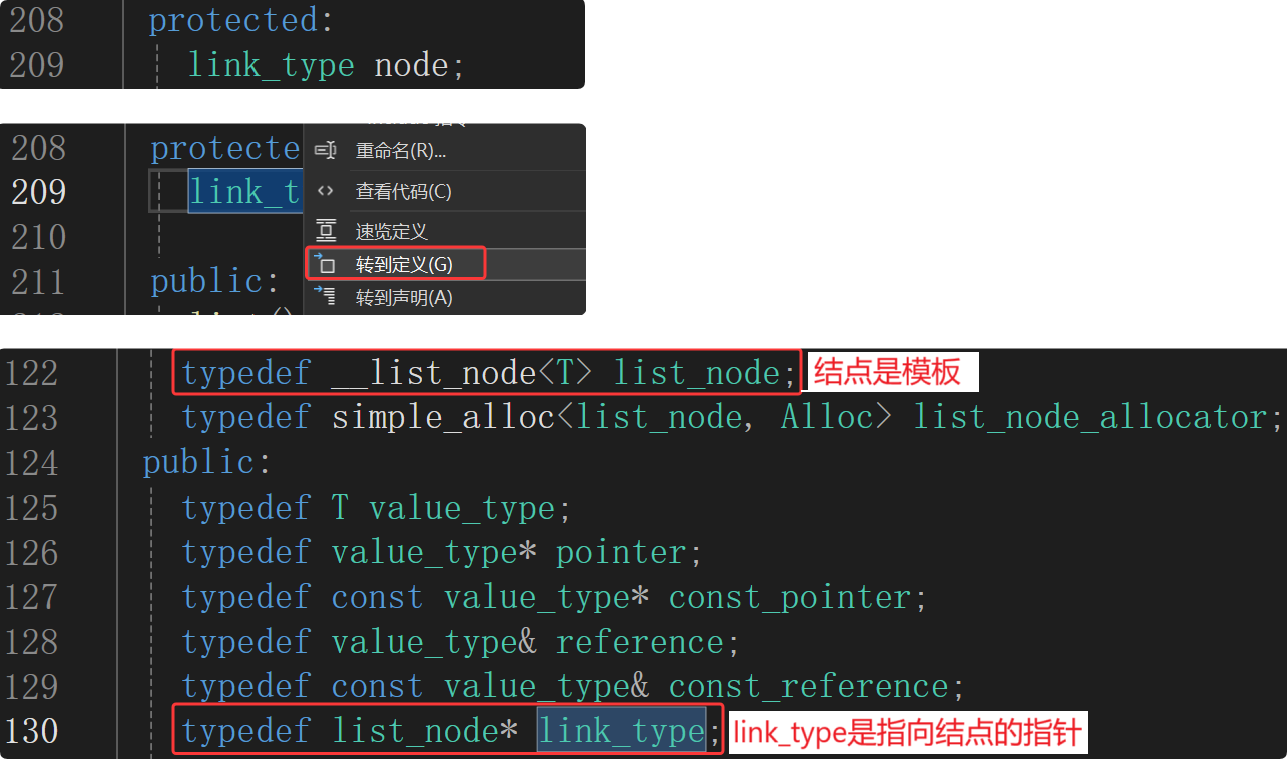
类模板实例化出的类类型一般都需要typedef成别名,因为太长了。typedef受到访问限定符private的限制,因为不想让外面的访问Node:
// 链表
template<class T>
class list
{// 结点类型typedef list_node<T> Node;
};
结点、链表的基本结构(含构造、push_back)
(4)、迭代器类模板
可以在迭代器类外面的链表类里访问被封装的结点指针,说明结点指针在迭代器类中是不受访问限定符限制的。
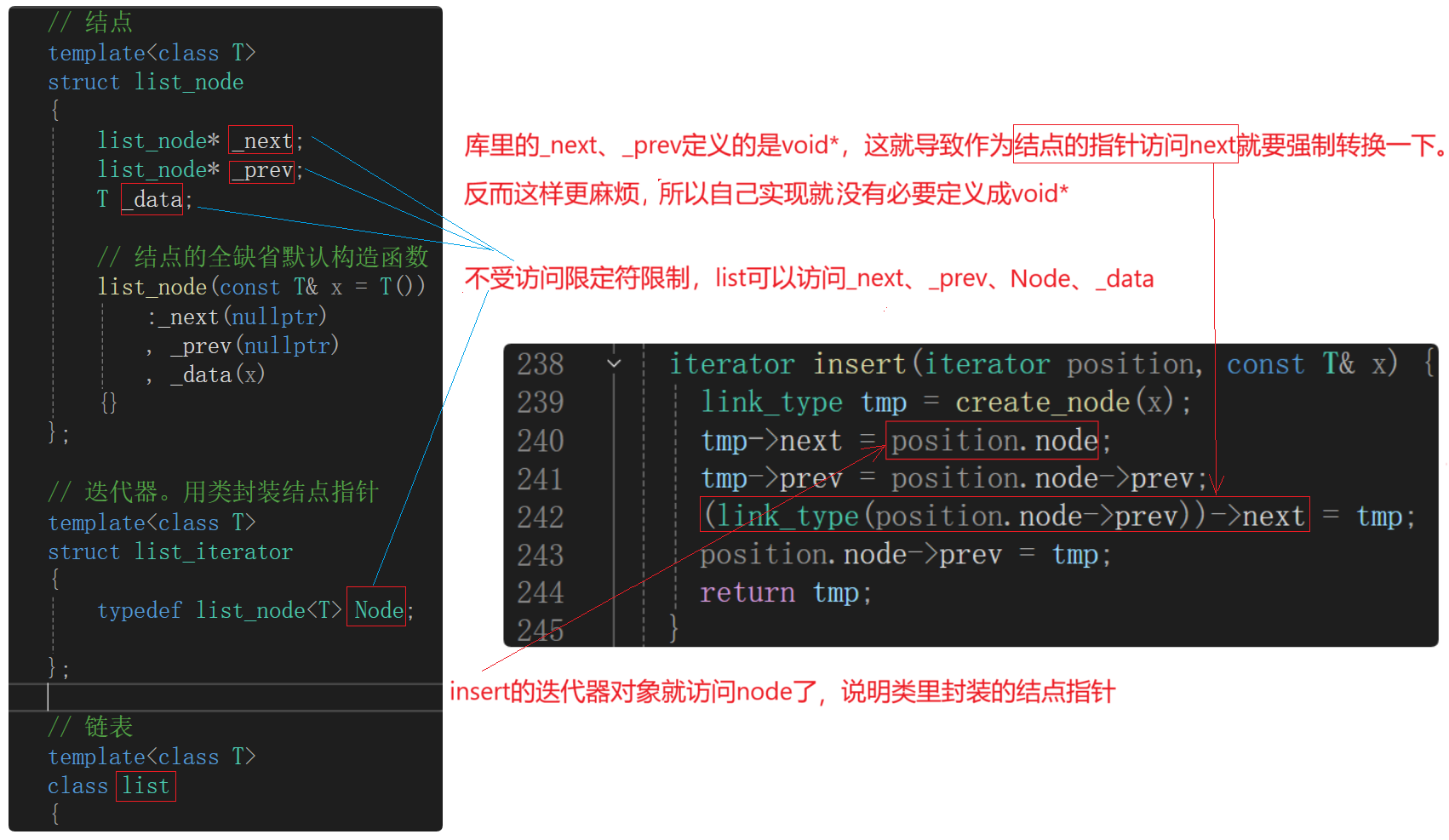
迭代器核心:用结点指针来构造
// 迭代器
template<class T>
struct list_iterator
{// 用类封装结点指针typedef list_node<T> Node;Node* _node;// 迭代器核心:用结点指针构造list_iterator(Node* node):_node(node){}
};
类里要重载迭代器核心行为:operator*、operator++
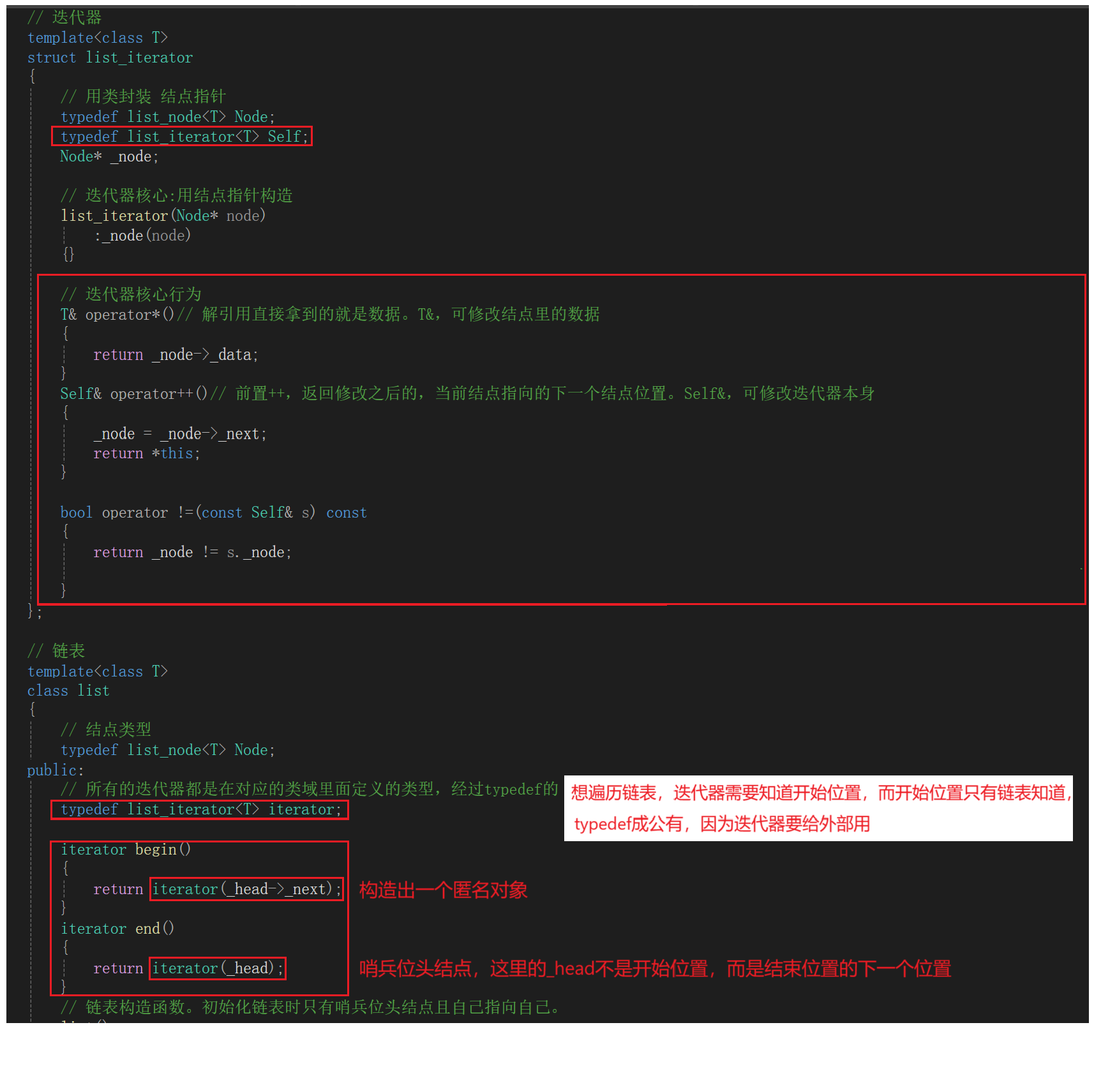
迭代器和链表是如何配合的?为什么一定要定义出3个类模板?
首先,结点和链表的类模板没办法合在一起,链表是控制整个结构,结点是控制部分结构。链表的特点与顺序表相比,顺序表是一整块数组,链表是一块一块的小内存存储数据和指针,所以结点和链表的类模板没办法合在一起。其次,关于迭代器类模板,假设有一个链表对象list< int > lt,,若想访问这个链表,可以有一个迭代器访问它,也可以有两个、三个迭代器访问它。三个迭代器访问它可以想象成三个指针访问它,不过结点的指针没办法达到我们预期的行为,比如要对这个链表用逆置算法,传递开始和结束位置的迭代器,假设这个迭代器就是结点指针,那么迭代器应该有以下行为:解引用就是结点中的数据、++就是当前结点指向的下一个结点、--就是当前结点指向的前一个结点。但是结点指针没办法达到预期的行为,所以要用类封装一下结点指针,本身遍历容器都是用指针,由于底层结构的原因,迭代器都或多或少跟指针有着很强的关联,要么迭代器直接是指针,要么迭代器是用类封装指针:因为指针达不到行为,封装了之后重载运算符,这些运算符可以达到我们想要的迭代器行为。
想遍历链表,迭代器需要知道开始位置,而开始位置(开始存储有效数据的结点位置,头结点指向的下一个结点)只有链表知道,在链表模板里typedef成公有,因为迭代器要给外部用。迭代器都要统一名字,都叫iterator,所有容器的迭代器都是容器类型 域作用限定符 iterator,都叫iterator是因为typedef达到的目的,虽然都是不同类型,但是在类域里面都被tepedef成iterator迭代器。所以从用的角度感觉所有的迭代器都很相似,在上层很相似但是在下层是千差万别的。
vector 和 string 可以用<判断迭代器的大小,因为它们的迭代器所到的不同位置是有大小关系的。但是在list里不能用<,因为结点之间的地址没有办法判断大小关系,必须用!=,操作数是自定义类型的,需要重载!=运算符,迭代器是否相等就是看里面的指针是否相等(比较的是指针是否相等,不需要重载!=,比较的是地址。类型只有在++这种情况时才会体现,+1那就加对应类型步长,实际还是指针)。

完善迭代器中运算符的重载:后置++、==、前置--、后置--。
迭代器要不要写析构?迭代器类模板里面有结点指针,要不要把指针指向的结点空间释放了?——不释放,也不能释放,要具体分析。迭代器的目的是访问链表和修改数据,不负责销毁链表。链表中的结点指针是由list管理,list的析构最后会把链表中的结点全部释放。list涉及深浅拷贝的问题,list的析构会在后面实现。
既然在迭代器类模板中不用写析构,那就不写拷贝构造和赋值运算符重载。那么默认生成的拷贝构造和赋值都是浅拷贝,而浅拷贝就是我们想达成的目的。例如begin()返回的迭代器赋值给 lit,两个指针指向同一个结点,就是浅拷贝。
list<int>::iterator lit = lt.begin();
Self operator++(int)// 后置++,返回修改之前的
{Self tmp(*this);// 调用默认拷贝构造,浅拷贝_node = _node->_next;return tmp;
}
那么能重载+和-吗?其实从语法的角度上说是可以的,但是它选择不重载。因为++和 --的效率都很高,但是+和-的效率不高。+和-是O(n)的接口,是几就从哨兵位开始向前/后走。所以一个类中到底重载哪些运算符是看实际的需求。
(5)、目前list的基本结构
// list.h
#include <iostream>
#include <assert.h>
using namespace std;
namespace zsy
{// 结点template<class T>struct list_node{list_node* _next;list_node* _prev;T _data;// 结点的全缺省默认构造函数list_node(const T& x = T()):_next(nullptr),_prev(nullptr),_data(x){}};// 迭代器template<class T>struct list_iterator{// 用类封装 结点指针typedef list_node<T> Node;typedef list_iterator<T> Self;Node* _node;// 迭代器核心:用结点指针构造list_iterator(Node* node):_node(node){}// 迭代器核心行为T& operator*()// 解引用直接拿到的就是数据。T&,可修改结点里的数据{return _node->_data;}Self& operator++()// 前置++,返回修改之后的,当前结点指向的下一个结点位置。Self&,引用返回,返回对象出了作用域不会销毁{_node = _node->_next;return *this;}bool operator !=(const Self& s) const{return _node != s._node;}Self operator++(int)// 后置++,返回修改之前的{Self tmp(*this);// 调用默认拷贝构造,浅拷贝_node = _node->_next;return tmp;}bool operator ==(const Self& s) const{return _node == s._node;}Self& operator --(){_node = _node->_prev;return *this;}Self operator --(int){Self tmp(*this);_node = _node->_prev;return tmp;}};// 链表template<class T>class list{// 结点类型typedef list_node<T> Node;public:// 所有的迭代器都是在对应的类域里面定义的类型,经过typedef的typedef list_iterator<T> iterator;iterator begin(){return iterator(_head->_next);}iterator end(){return iterator(_head);}// 链表构造函数。初始化链表时只有哨兵位头结点且自己指向自己。list(){// 给哨兵位头结点开空间并初始化,初始化调用结点构造函数_head = new Node;// 调用 Node 的构造函数list_node()初始化_head->_next = _head;_head->_prev = _head;}void push_back(const T& x){Node* tail = _head->_prev;Node* newnode = new Node(x);// 调用 Node 的构造函数list_node()初始化//tail newnode _headnewnode->_next = _head;newnode->_prev = tail;tail->_next = newnode;_head->_prev = newnode;}private:Node* _head;// 哨兵位头结点};
}
(6)、完善list常见的接口
插入删除
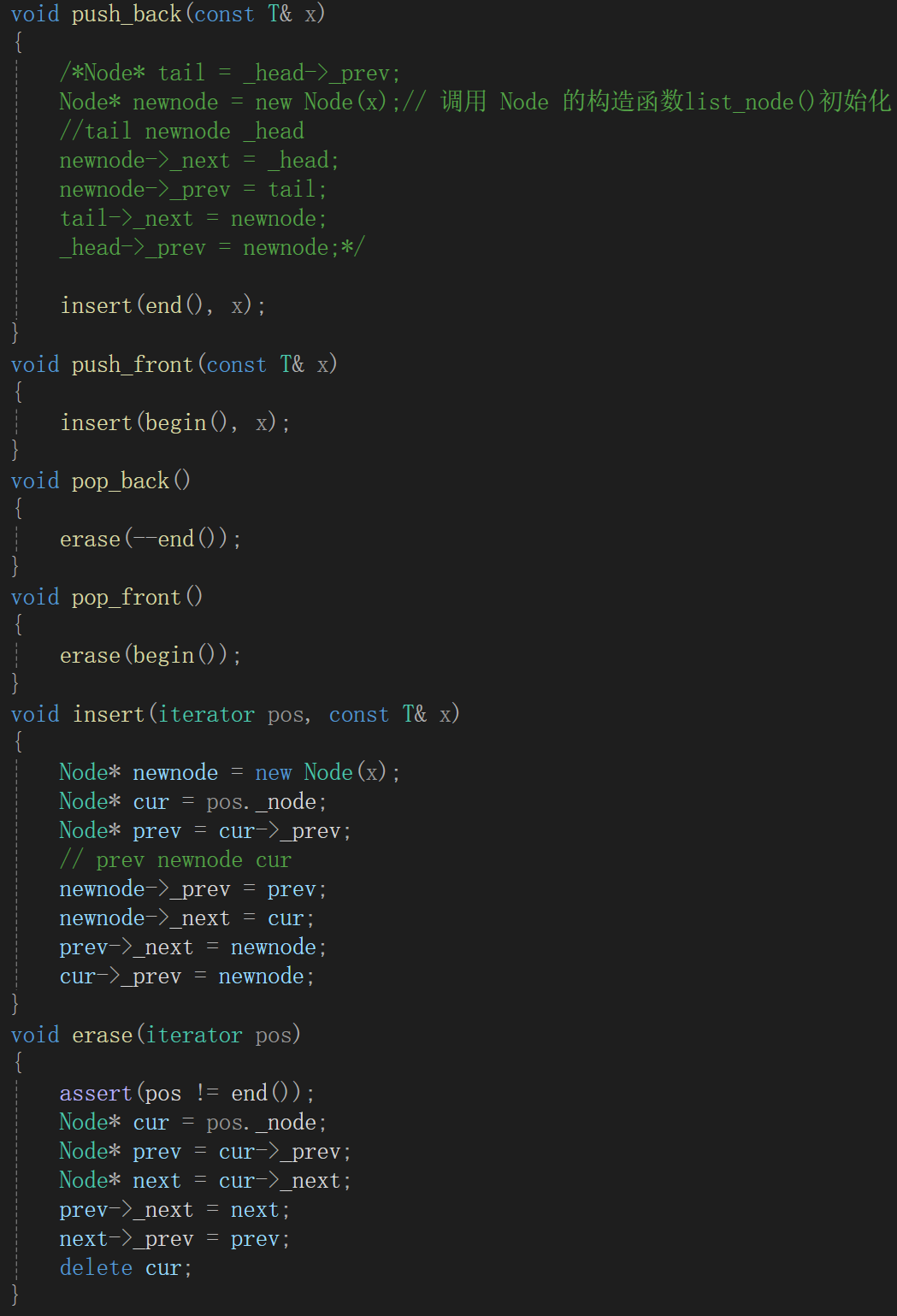
像库里实现的一样,头插尾插复用insert,头删尾删复用erase。
insert中不用断言迭代器,因为在任意位置前面都可以插入,包括哨兵位头结点的前面。而erase不一样,除了哨兵位头结点,其他位置都可以erase,所以erase的迭代器需要断言。
void test_list1()
{list<int> lt;lt.push_back(1);lt.push_back(2);lt.push_back(3);lt.push_back(4);list<int>::iterator lit = lt.begin();while (lit != lt.end())// 还需要重载 != 运算符{*lit += 10;cout << *lit << " ";++lit;}cout << endl;lt.push_front(10);lt.push_front(20);lt.push_front(30);lt.push_front(40);for (auto e : lt){cout << e << " ";}cout << endl;lt.pop_back();lt.pop_back();lt.pop_front();lt.pop_front();for (auto e : lt){cout << e << " ";}cout << endl;
}

探讨两个问题:
1、list的insert有没有迭代器失效的问题?—— 没有,可以使用迭代器,因为list没有扩容的问题。vector中插入数据,数据会有往后挪动的概念,而list没有往后挪动的概念。
2、list的erase有没有迭代器失效的问题?—— 有,pos指向的cur结点被释放了,那这个迭代器lit就类似于野指针了。
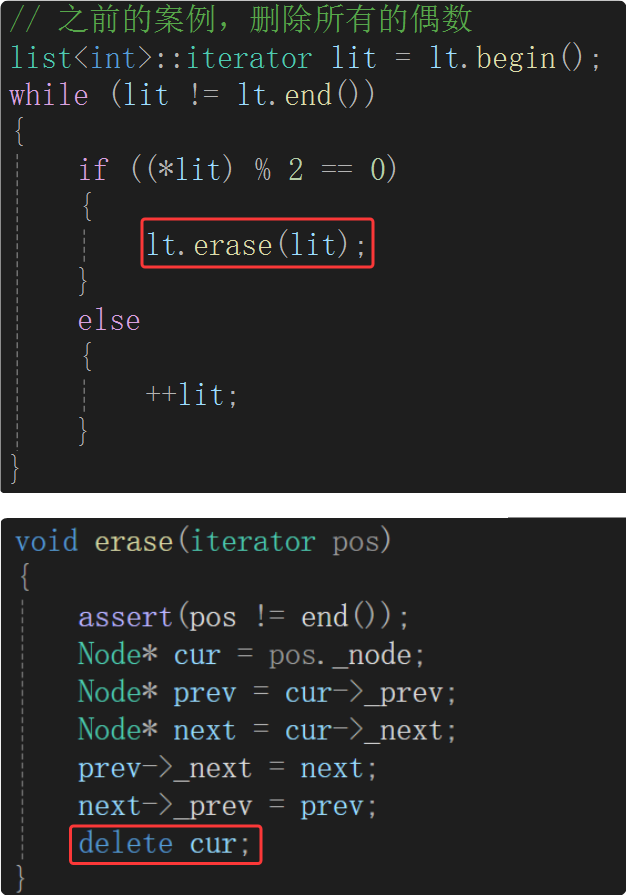
与vector的erase迭代器同理,erase后,迭代器需要重新赋值才能访问。
两种写法都可以:
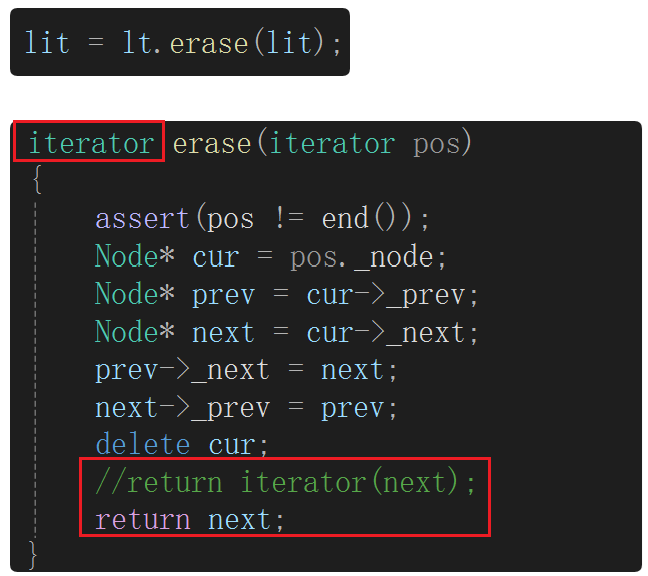
写法一:返回类型是迭代器,构造匿名对象返回。
写法二:next是类型为Node*的结点指针,涉及类型转换,单参数的构造函数支持隐式类型转换,Node*会转换成迭代器类型,用next构造临时对象,这个临时对象作为返回值再拷贝构造,当然编译器会优化。
void test_list2()
{list<int> lt;lt.push_back(1);lt.push_back(2);lt.push_back(3);lt.push_back(4);// 之前的案例,删除所有的偶数list<int>::iterator lit = lt.begin();while (lit != lt.end()){if ((*lit) % 2 == 0){lit = lt.erase(lit);}else{++lit;}}for (auto e : lt){cout << e << " ";}cout << endl;
}


其实可以给出结论:所有容器的erase都会导致迭代器失效,insert是否导致迭代器失效需要看情况。
顺带提一下,string的迭代器有没有失效的问题?—— 有,而且跟vector一样。不过,string的insert和erase不太用迭代器,vector的insert和erase才开始用迭代器。string的insert和erase除了有迭代器版本的,还有下标版本的,其实string更喜欢用下标版本的。
size的两种实现方式
方式一:迭代器/范围for遍历计算个数。
方式二:方式一效果不太好,所以考虑在链表里增加一个成员变量来记录。插入一个结点就++,删除一个结点就--。
析构函数
当前list有内存泄漏的问题。
写析构之前,先提供clear清除除了哨兵位头结点以外的所有结点,因为clear不清除哨兵位头结点。析构与clear不同,析构是要把所有的结点(包括哨兵位头结点)空间释放了。
~list()
{clear();delete _head;_head = nullptr;
}
void clear()
{auto it = begin();while (it != end()){it = erase(it);}
}
拷贝构造
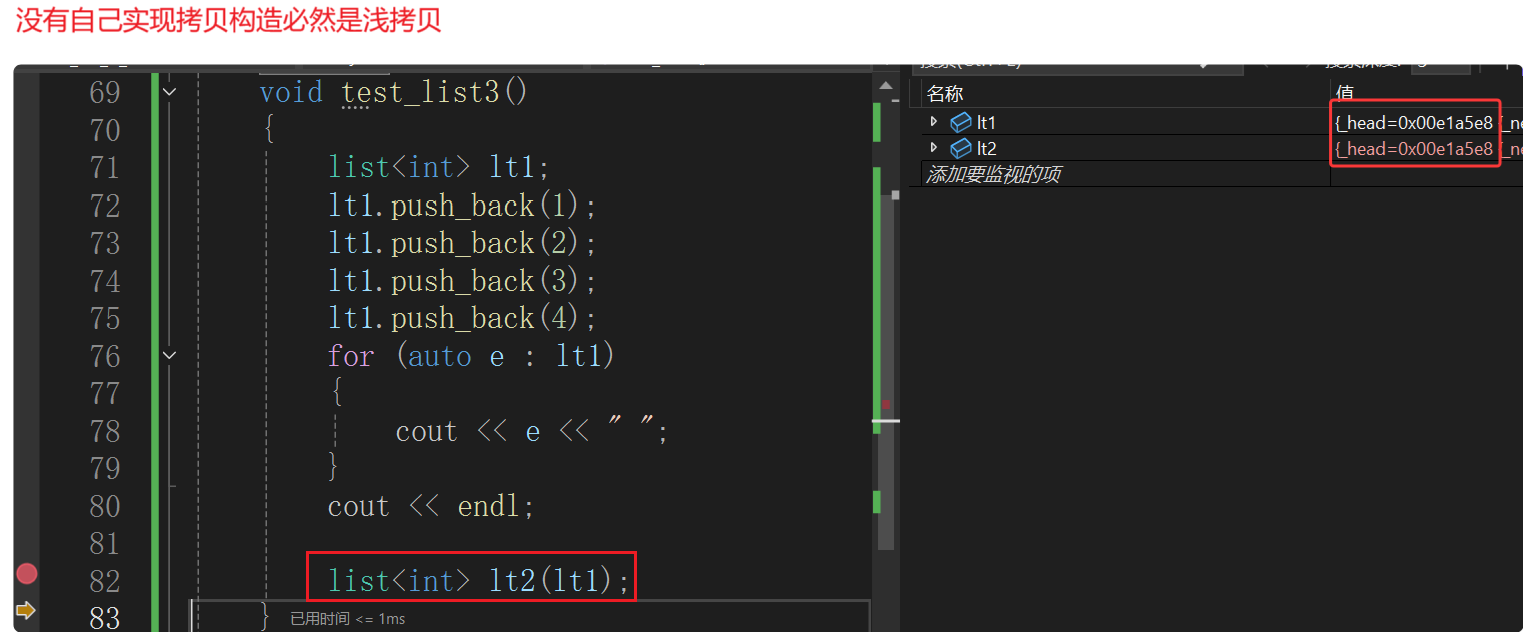
自己写拷贝构造(深拷贝)更简单的实现方式:lt2 先有哨兵位头结点(每一个list实例化出的类的结构都要有哨兵位头结点,且自己指向自己)。再遍历链表 lt1,将数据push_back到 lt2 中。所以干脆就与库里实现的一样,直接来个空初始化函数 empty_init,把之前链表的构造函数体拿到这里。所以有初始化列表也不一定就只用初始化列表,还可以直接复用。都放到公共的函数 empty_init 里,构造函数、拷贝构造函数都先调用 empty_init ,下面的拷贝构造函数体里相当于先初始化 lt2 为空链表。
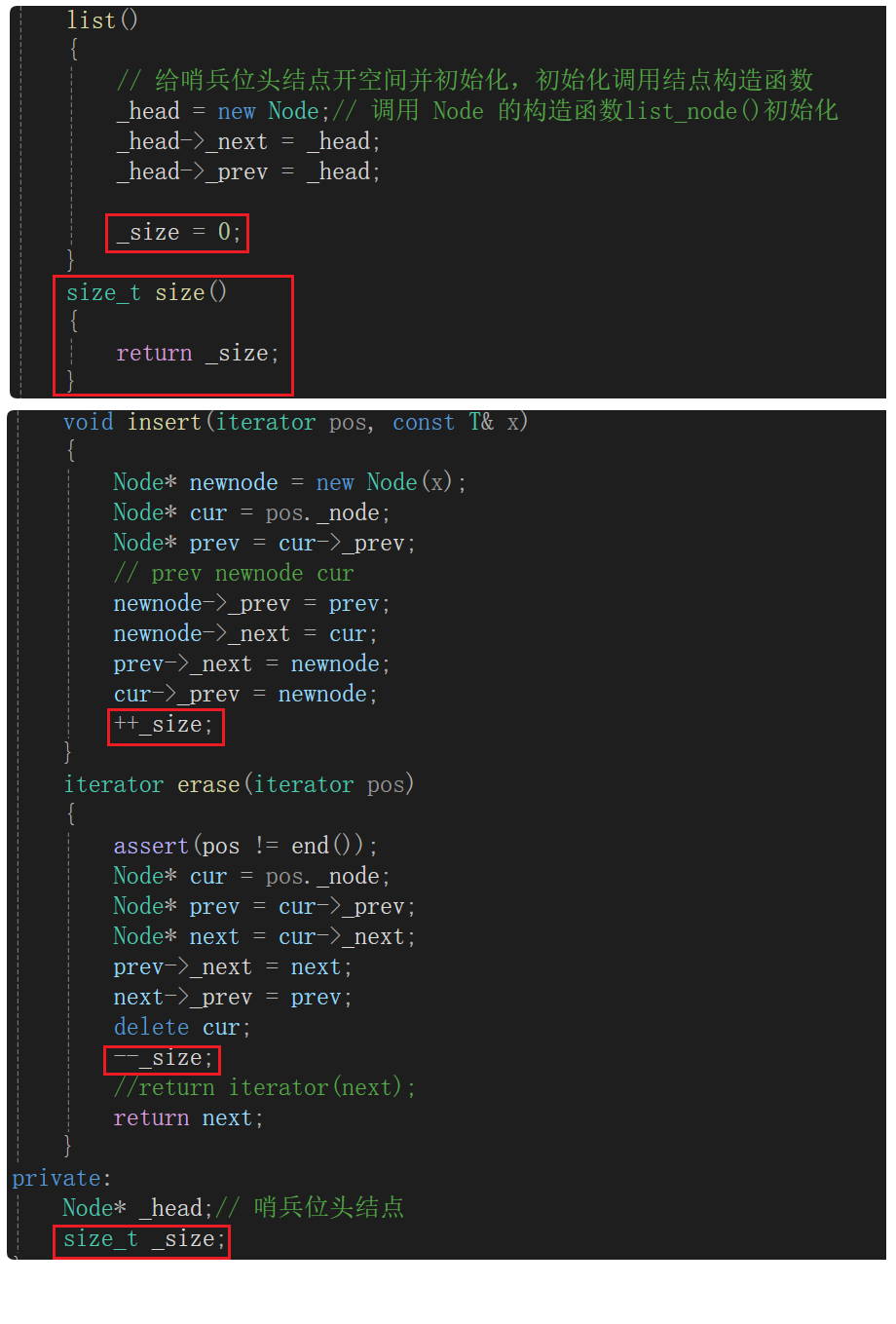
void empty_init()
{// 给哨兵位头结点开空间并初始化,初始化调用结点构造函数_head = new Node;// 调用 Node 的构造函数list_node()初始化_head->_next = _head;_head->_prev = _head;_size = 0;
}
// 链表构造函数。初始化链表时只有哨兵位头结点且自己指向自己。
list()
{empty_init();
}
// 拷贝构造 lt2(lt1)
list(const list<T>& lt)
{empty_init();for (auto& e : lt){push_back(e);}
}
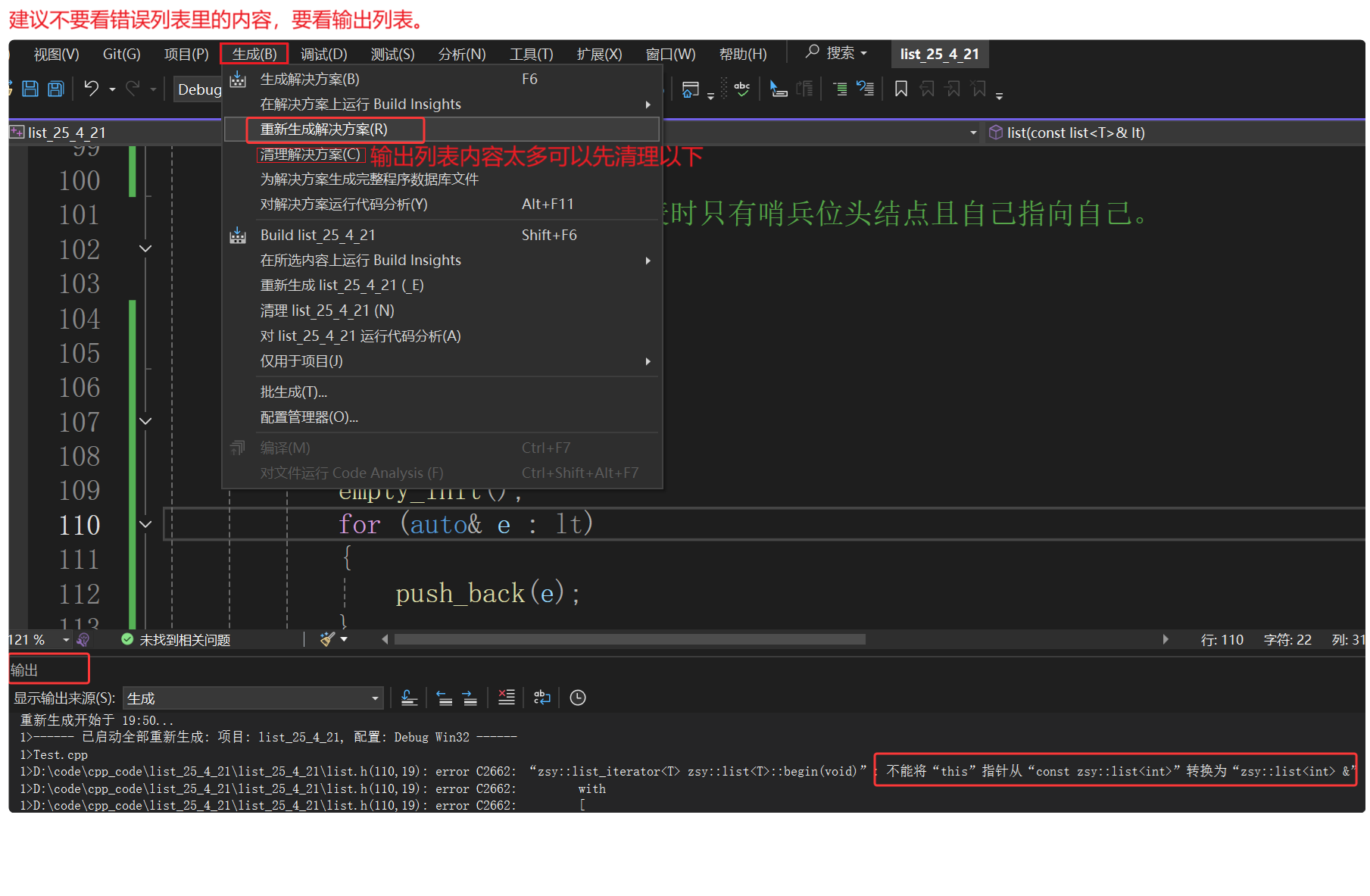
范围for遍历出现了问题。范围for遍历const对象,范围for要转换成const迭代器(我们这时还没有自己实现const迭代器)。先验证拷贝构造,暂且把const去掉,结果运行成功。

拷贝构造和赋值运算符重载有传统写法和现代写法,传统写法是一个一个拷贝,但是现代写法可以对插入等接口进行复用。C++并没有规定必须怎么写,只要根据场景灵活使用达到要求即可。
赋值运算符重载

自己实现赋值:
传统写法:lt1 = lt3,clear lt1,遍历 lt3,push_back到 lt1 中。
现代写法:传值传参,swap,delete
void swap(list<T>& lt)
{std::swap(_head, lt._head);std::swap(_size, lt._size);
}
// 赋值运算符重载 lt1 = lt3
list<T>& operator=(list<T> lt)
{swap(lt);return *this;
}
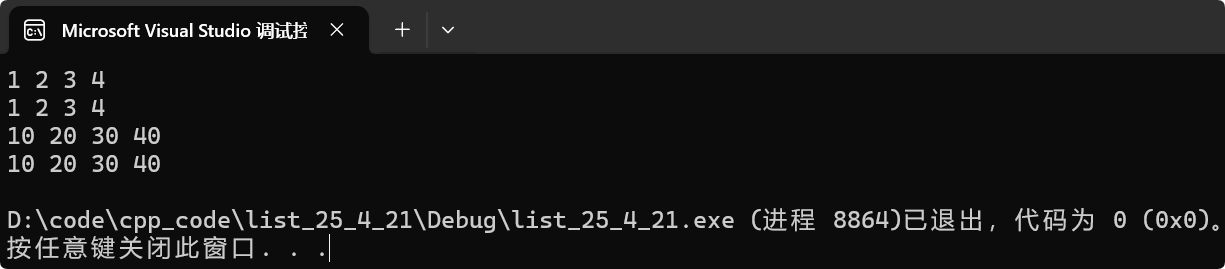
void test_list3()
{list<int> lt1;lt1.push_back(1);lt1.push_back(2);lt1.push_back(3);lt1.push_back(4);for (auto e : lt1){cout << e << " ";}cout << endl;list<int> lt2(lt1);for (auto e : lt2){cout << e << " ";}cout << endl;list<int> lt3 = { 10, 20, 30, 40 };lt1 = lt3;for (auto e : lt3){cout << e << " ";}cout << endl;for (auto e : lt1){cout << e << " ";}cout << endl;
}
n个value构造、迭代器区间构造与vector类似,复用push_back。其实实现好了push_back,其他就都好实现了。
const迭代器
一般不容易出现const对象,因为一上来就定义成const对象不方便插入操作什么的。一般const对象出现在函数参数,因为不想在函数体内改变对象,还要加上引用减少拷贝构造:

此时还没有实现const迭代器,下面这样写肯定会出错。先来探讨const迭代器是什么,是下面框住的吗?——不是
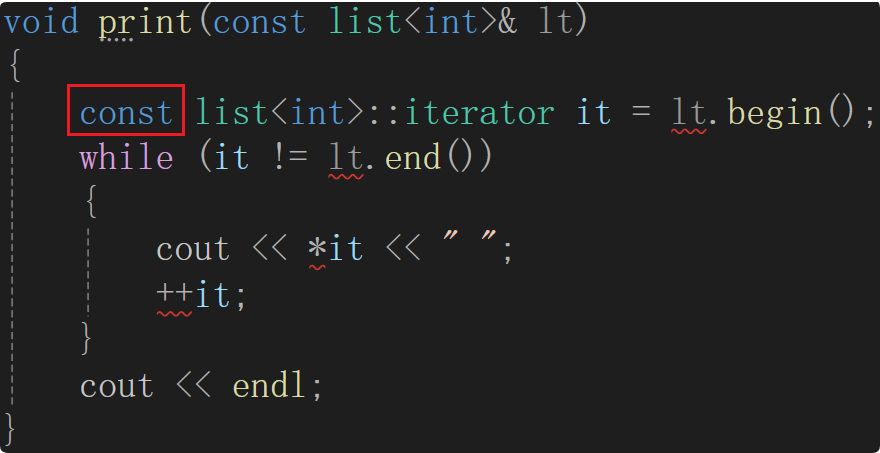
能在前面加const吗?—— 不能,就拿指针来说,指针有两类:
1、const T* p1。指向内容不能修改,本身可修改。
2、T* const p2。本身不能修改,指向内容可修改。
迭代器模拟的是指针的行为,const迭代器模拟的是 p1 :本身可修改,指向内容不能修改。
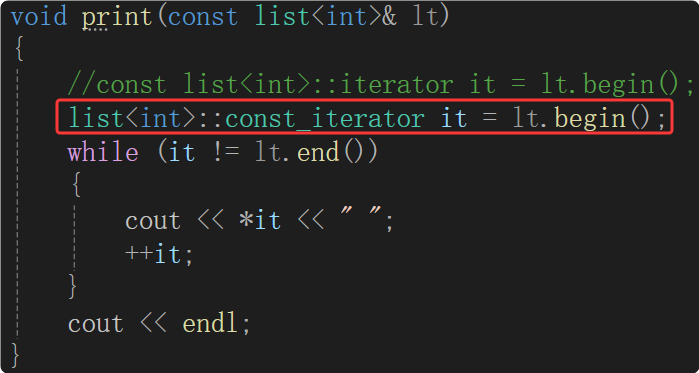
要做到指向的内容不能修改的核心:从operator*下手,返回类型改为const T&。

所以在这里再整出一个 const迭代器 类模板,因为不能即是T&也是const T&,返回类型不同不能作为函数重载的条件。
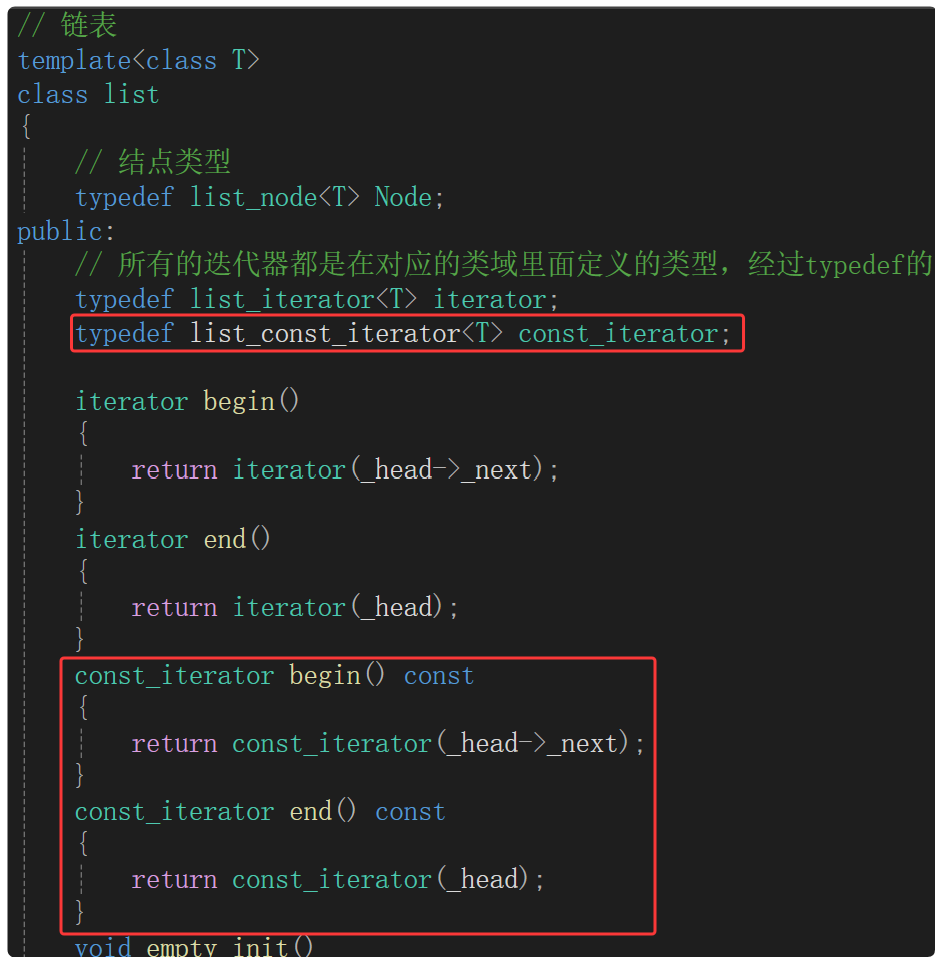
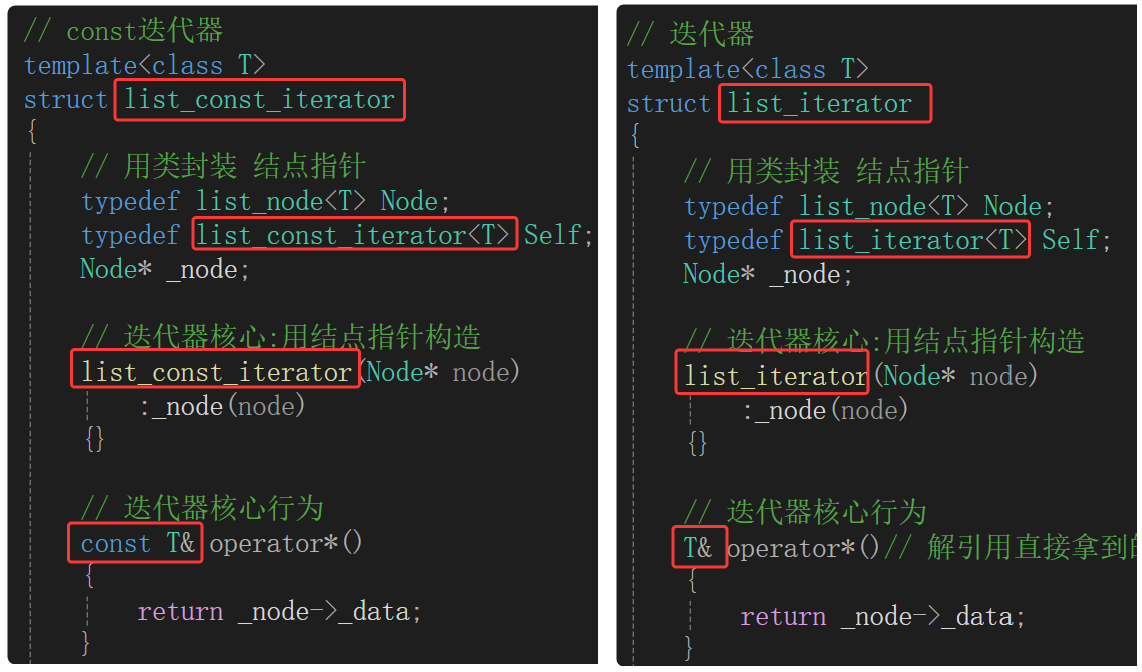
const迭代器与普通迭代器的唯一区别:const迭代器中,*it调用operator*时,返回值是const引用,就不能修改指向的内容了。
这里的const迭代器和普通迭代器是两个不同的类模板,二者只有类名和operator*的返回类型不一样,那么这样看两个几乎一样的类模板有点冗余。若两个类除了类名不一样,单纯的只有接口返回类型不一样,那么就可以考虑复用,把不同的类直接替换成模板,用一个类模板去实现。模板的原理:传递不同的模板参数,实例化出不同的类型。实际上还是需要两个类(普通迭代器和const迭代器),之前是自己写出来两个类,现在可以让编译器帮我们生成两个类。
用模板参数Ref(Reference 引用)作为函数operator*的返回类型。
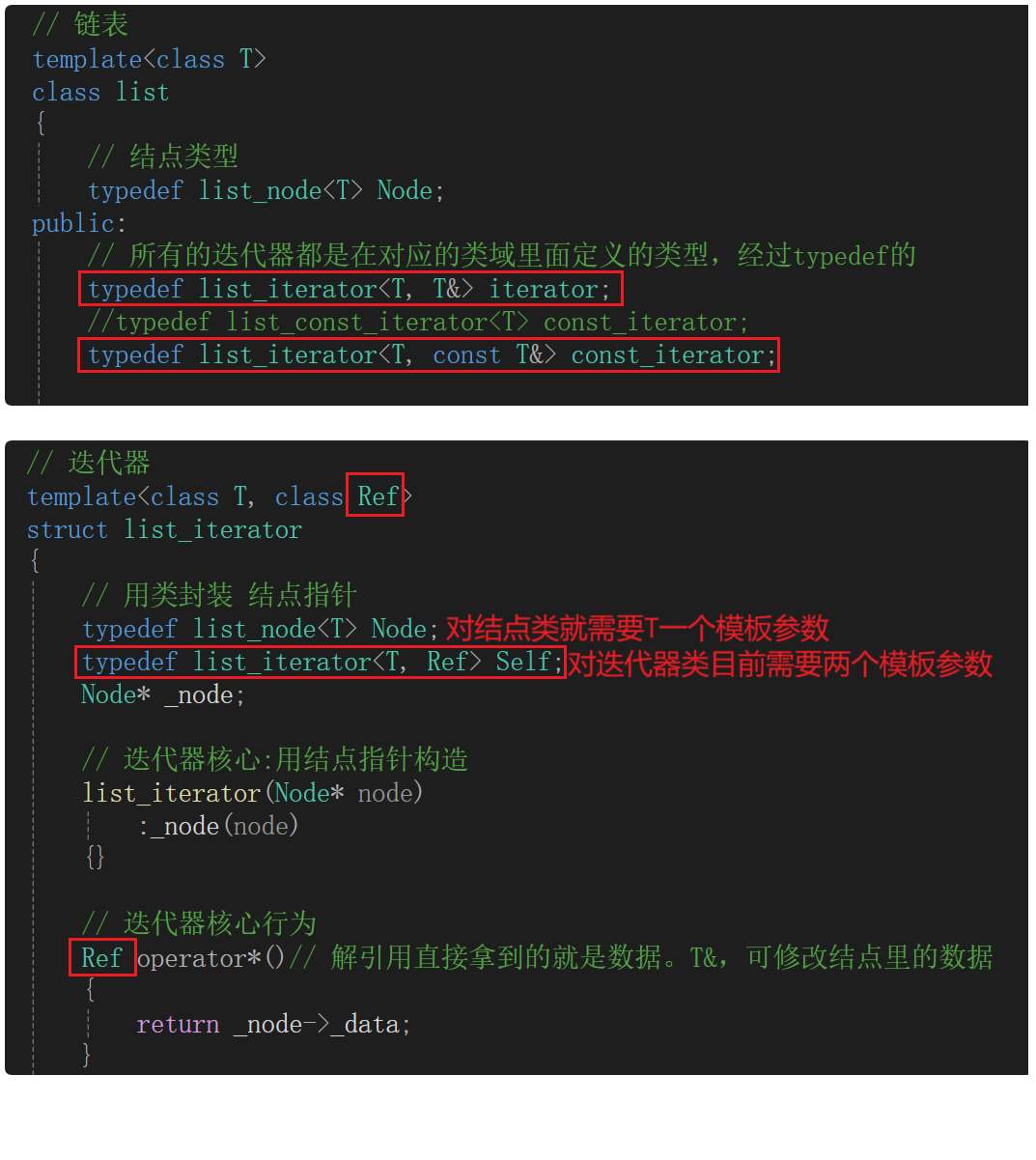
记得把拷贝构造改回来:
// 拷贝构造 lt2(lt1)
list(const list<T>& lt)
//list(list<T>& lt)
{empty_init();for (auto& e : lt){push_back(e);}
}
向链表中插入存储自定义类型数据的结点
- 先拿vector举例,插入的数据是自定义类型的。

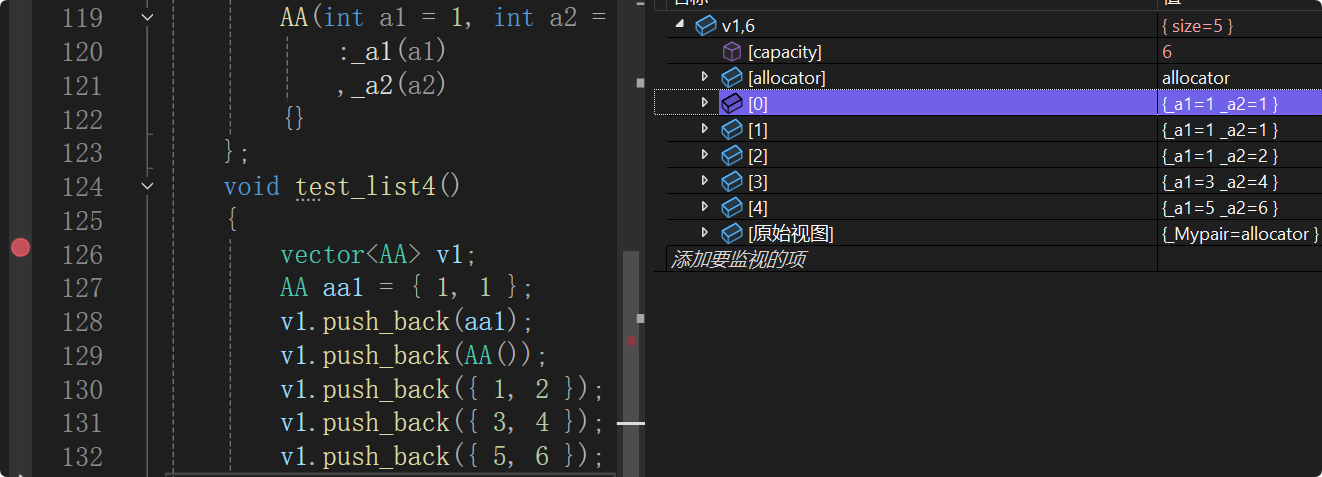
传递的参数:可以是AA的有名/匿名对象,也可以是多参数构造函数支持隐式类型转换。
有名对象aa1,构造AA类的临时对象,再拷贝构造给aa1,编译器优化为直接构造。AA()构造出匿名对象。多参数构造函数支持隐式类型转换,例如v1.push_back({ 1, 2 });。

不能遍历,vector的迭代器是个原生指针,*it1是个自定义类型的数据,对于自定义类型,vector里没有重载 << 运算符。那就只能自己实现 << 运算符重载,但是若不想重载 << 呢?AA类是用struct定义的,说明在外部可以访问它的成员。结构体指针用箭头访问成员。
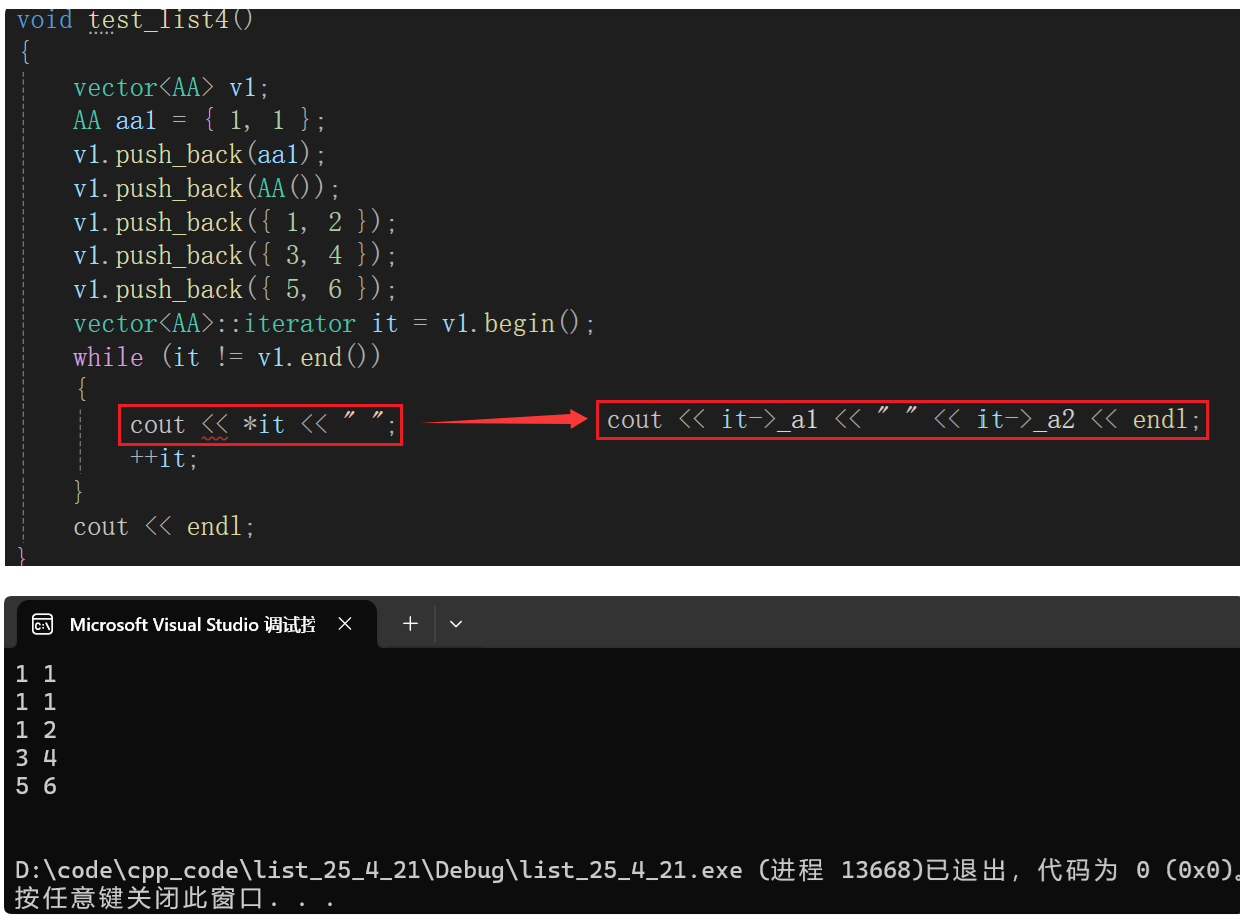
- 现在把这段代码切换成list
面临和vector一样的问题,调用operator*返回结点里的data,结点里的data是个AA类对象,而list中没有支持流插入运算符重载。
前面 vector 的 it 因为是内置类型的指针,可以直接对指针解引用->。而 list 的 it 不能用箭头,可以这样:解引用后是数据AA类对象,再访问变量,上面的vector也可以这样写。
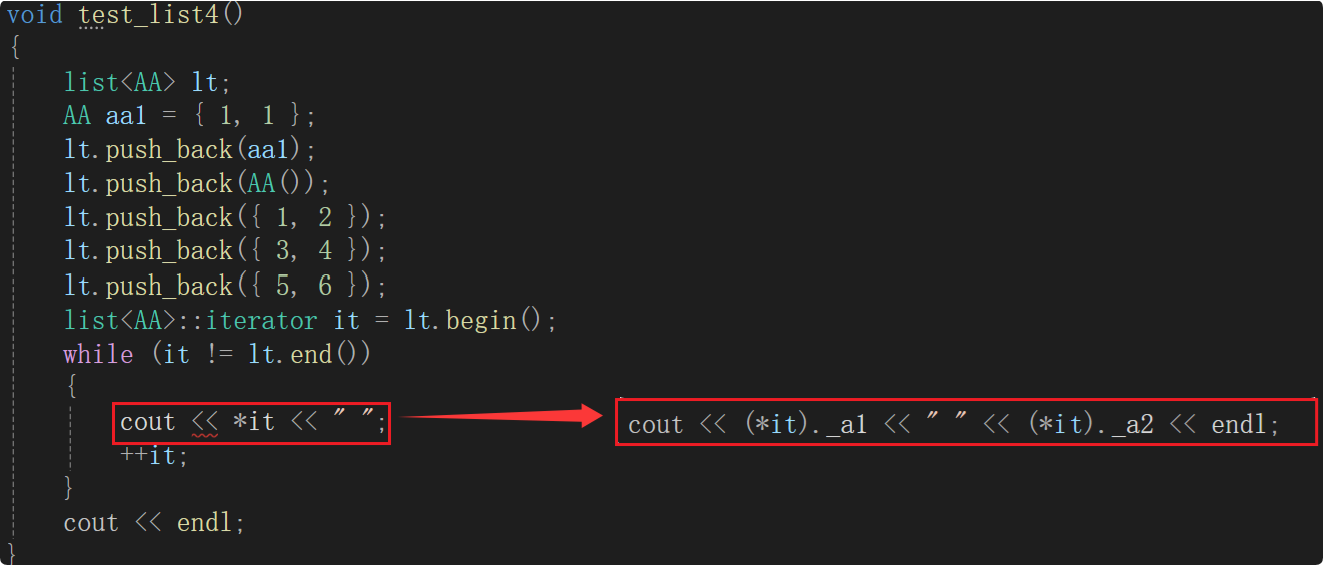
但是这种写法怎么看都怪怪的,迭代器是模拟指针的行为。其实也可以用箭头,it 是自定义类型,要有 -> 的运算符重载。先说结论,是这么写的:

本示例中的 T 就是 AA,_node->_data 就是 AA类对象,&AA类对象的返回类型就是 AA*,AA* 是怎么访问到 _a1 的呢?it->调用operator->返回结构体指针,结构体指针访问成员 _a1 应该还有一个箭头呀?所以是不是这样写的?

但是这样写编译不通过的,因为可读性不强,所以这里有个特殊处理,为了可读性其实是省略了一个箭头,看下面第一行写法。还有,运算符重载可以显示调用,所以也可以写成下面第二行写法:
cout << it->_a1 << ":" << it->_a2 << endl;
cout << it.operator->()->_a1 << ":" << it.operator->()->_a2 << endl;
常用上面的写法,一般不会用下面的写法,不过我们需要理解这种写法。
(7)、迭代器类模板的完善
普通迭代器返回 T&、T*;const迭代器返回 const T&、const T*(指向内容不能修改,也就是不能给指向内容赋值)。
平时就用T,但是有特殊代指的话,名字上也要区分:
Ref:reference 引用
Ptr:pointer
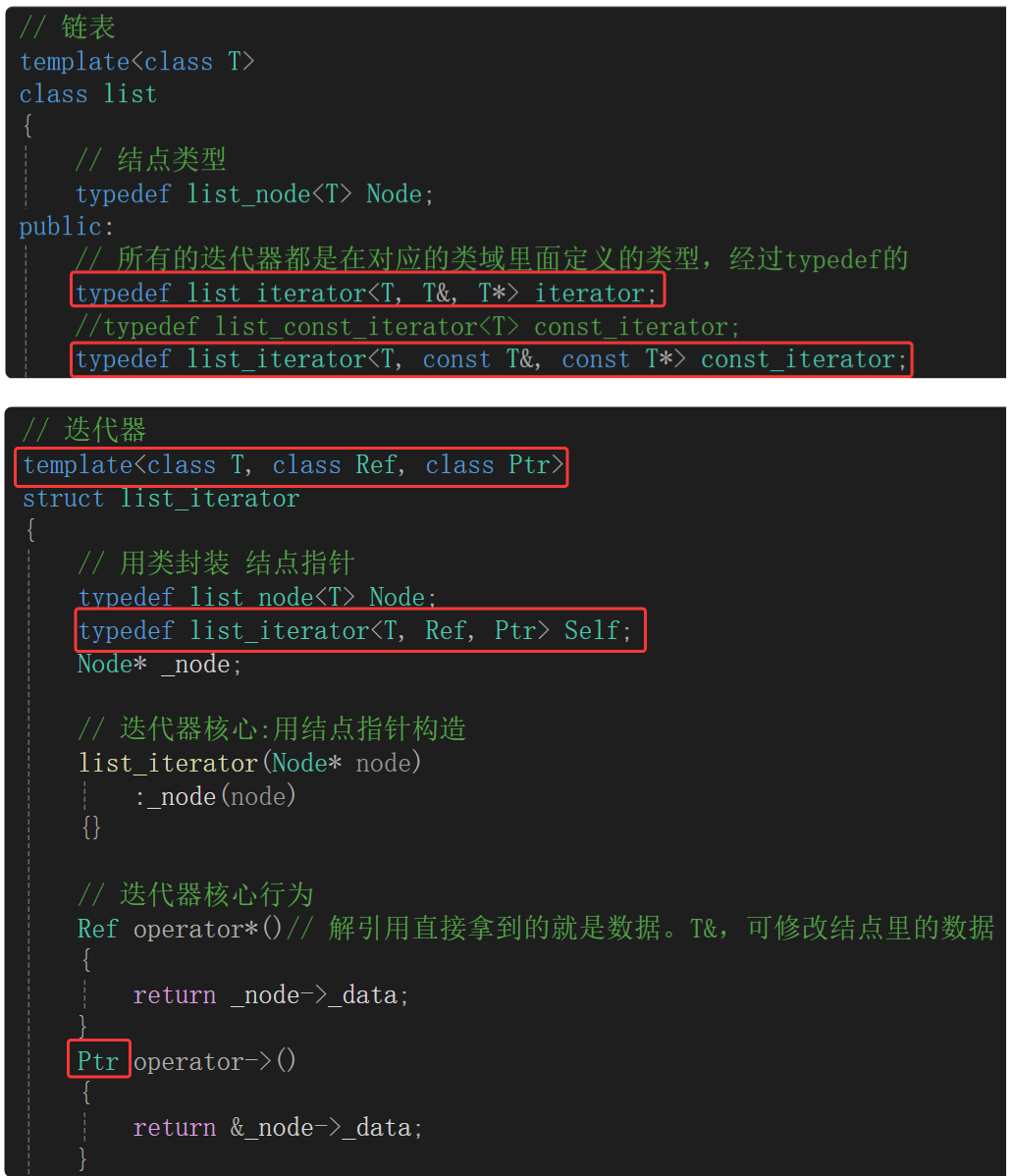
一共三个模板参数,与库里的三个模板参数一致。
(8)、list的模拟实现完整代码
// list.h
#include <iostream>
#include <assert.h>
using namespace std;
namespace zsy
{// 结点template<class T>struct list_node{list_node* _next;list_node* _prev;T _data;// 结点的全缺省默认构造函数list_node(const T& x = T()):_next(nullptr),_prev(nullptr),_data(x){}};// 迭代器template<class T, class Ref, class Ptr>struct list_iterator{// 用类封装 结点指针typedef list_node<T> Node;typedef list_iterator<T, Ref, Ptr> Self;Node* _node;// 迭代器核心:用结点指针构造list_iterator(Node* node):_node(node){}// 迭代器核心行为Ref operator*()// 解引用直接拿到的就是数据。T&,可修改结点里的数据{return _node->_data;}Ptr operator->(){return &_node->_data;}Self& operator++()// 前置++,返回修改之后的,当前结点指向的下一个结点位置。Self&,引用返回,返回对象出了作用域不会销毁{_node = _node->_next;return *this;}bool operator !=(const Self& s) const{return _node != s._node;}Self operator++(int)// 后置++,返回修改之前的{Self tmp(*this);// 调用默认拷贝构造,浅拷贝_node = _node->_next;return tmp;}bool operator ==(const Self& s) const{return _node == s._node;}Self& operator --(){_node = _node->_prev;return *this;}Self operator --(int){Self tmp(*this);_node = _node->_prev;return tmp;}};/*// const迭代器template<class T>struct list_const_iterator{// 用类封装 结点指针typedef list_node<T> Node;typedef list_const_iterator<T> Self;Node* _node;// 迭代器核心:用结点指针构造list_const_iterator(Node* node):_node(node){}// 迭代器核心行为const T& operator*(){return _node->_data;}Self& operator++()// 前置++,返回修改之后的,当前结点指向的下一个结点位置。Self&,引用返回,返回对象出了作用域不会销毁{_node = _node->_next;return *this;}bool operator !=(const Self& s) const{return _node != s._node;}Self operator++(int)// 后置++,返回修改之前的{Self tmp(*this);// 调用默认拷贝构造,浅拷贝_node = _node->_next;return tmp;}bool operator ==(const Self& s) const{return _node == s._node;}Self& operator --(){_node = _node->_prev;return *this;}Self operator --(int){Self tmp(*this);_node = _node->_prev;return tmp;}};*/// 链表template<class T>class list{// 结点类型typedef list_node<T> Node;public:// 所有的迭代器都是在对应的类域里面定义的类型,经过typedef的typedef list_iterator<T, T&, T*> iterator;//typedef list_const_iterator<T> const_iterator;typedef list_iterator<T, const T&, const T*> const_iterator;iterator begin(){return iterator(_head->_next);}iterator end(){return iterator(_head);}const_iterator begin() const{return const_iterator(_head->_next);}const_iterator end() const{return const_iterator(_head);}void empty_init(){// 给哨兵位头结点开空间并初始化,初始化调用结点构造函数_head = new Node;// 调用 Node 的构造函数list_node()初始化_head->_next = _head;_head->_prev = _head;_size = 0;}// 链表构造函数。初始化链表时只有哨兵位头结点且自己指向自己。list(){empty_init();}list(initializer_list<T> il){empty_init();for (auto& e : il){push_back(e);}}// 拷贝构造 lt2(lt1)list(const list<T>& lt)//list(list<T>& lt){empty_init();for (auto& e : lt){push_back(e);}}void swap(list<T>& lt){std::swap(_head, lt._head);std::swap(_size, lt._size);}// 赋值运算符重载 lt1 = lt3list<T>& operator=(list<T> lt){swap(lt);return *this;}~list(){clear();delete _head;_head = nullptr;}void clear(){auto it = begin();while (it != end()){it = erase(it);}}size_t size(){return _size;}void push_back(const T& x){/*Node* tail = _head->_prev;Node* newnode = new Node(x);// 调用 Node 的构造函数list_node()初始化//tail newnode _headnewnode->_next = _head;newnode->_prev = tail;tail->_next = newnode;_head->_prev = newnode;*/insert(end(), x);}void push_front(const T& x){insert(begin(), x);}void pop_back(){erase(--end());}void pop_front(){erase(begin());}void insert(iterator pos, const T& x){Node* newnode = new Node(x);Node* cur = pos._node;Node* prev = cur->_prev;// prev newnode curnewnode->_prev = prev;newnode->_next = cur;prev->_next = newnode;cur->_prev = newnode;++_size;}iterator erase(iterator pos){assert(pos != end());Node* cur = pos._node;Node* prev = cur->_prev;Node* next = cur->_next;prev->_next = next;next->_prev = prev;delete cur;--_size;//return iterator(next);return next;}private:Node* _head;// 哨兵位头结点size_t _size;};
}
// Test.cpp
#include "list.h"
#include <vector>
//#include <list>
namespace zsy
{void test_list1(){list<int> lt;lt.push_back(1);lt.push_back(2);lt.push_back(3);lt.push_back(4);list<int>::iterator lit = lt.begin();while (lit != lt.end())// 还需要重载 != 运算符{*lit += 10;cout << *lit << " ";++lit;}cout << endl;lt.push_front(10);lt.push_front(20);lt.push_front(30);lt.push_front(40);for (auto e : lt){cout << e << " ";}cout << endl;lt.pop_back();lt.pop_back();lt.pop_front();lt.pop_front();for (auto e : lt){cout << e << " ";}cout << endl;}void test_list2(){list<int> lt;lt.push_back(1);lt.push_back(2);lt.push_back(3);lt.push_back(4);// 之前的案例,删除所有的偶数list<int>::iterator lit = lt.begin();while (lit != lt.end()){if ((*lit) % 2 == 0){lit = lt.erase(lit);}else{++lit;}}for (auto e : lt){cout << e << " ";}cout << endl;}void test_list3(){list<int> lt1;lt1.push_back(1);lt1.push_back(2);lt1.push_back(3);lt1.push_back(4);for (auto e : lt1){cout << e << " ";}cout << endl;list<int> lt2(lt1);for (auto e : lt2){cout << e << " ";}cout << endl;list<int> lt3 = { 10, 20, 30, 40 };lt1 = lt3;for (auto e : lt3){cout << e << " ";}cout << endl;for (auto e : lt1){cout << e << " ";}cout << endl;}void print(const list<int>& lt){//const list<int>::iterator it = lt.begin();list<int>::const_iterator it = lt.begin();while (it != lt.end()){cout << *it << " ";++it;}cout << endl;}struct AA{int _a1;int _a2;AA(int a1 = 1, int a2 = 1):_a1(a1),_a2(a2){}};void test_list4(){list<AA> lt;AA aa1 = { 1, 1 };lt.push_back(aa1);lt.push_back(AA());lt.push_back({ 1, 2 });lt.push_back({ 3, 4 });lt.push_back({ 5, 6 });list<AA>::iterator it = lt.begin();while (it != lt.end()){cout << it->_a1 << ":" << it->_a2 << endl;cout << it.operator->()->_a1 << ":" << it.operator->()->_a2 << endl;++it;}cout << endl;}
}int main()
{zsy::test_list4();return 0;
}