一文读懂HPA弹性扩展以及实践攻略
一文读懂HPA弹性扩展以及实践攻略
目录
- 1 概念:
- 1.1 什么是弹性扩展
- 1.2 HPA 的工作原理
- 1.3 通过监控指标来调整副本数
- 1.3.1 计算公式说明
- 1.3.2 平均值计算
- 1.3.3 未就绪 Pod 和丢失的指标处理
- 1.3.4 多指标支持
- 1.3.5 缩减副本的平滑策略
- 1.4 HPA的优缺点
- 2 实践攻略:部署和配置 HPA
- 2.1 安装metric-server
- 2.2 部署一个应用
- 2.3 创建 HPA
- 2.4验证 HPA 工作情况
- 2.4.1 查看HPA当前状态
- 2.4.2 验证HPA扩缩
- 3 总结
- 4 参考文献
❤️ 摘要: Horizontal Pod Autoscaler(HPA)是 Kubernetes 提供的强大功能,能够根据应用的负载情况动态调整 Pod 数量,实现弹性扩展。本文将通过生动有趣的比喻,深入解析 HPA 的工作原理,并分享具体的配置和实践经验,让你轻松驾驭 Kubernetes 中的弹性扩展。
❤️ 本文内容关联文章:
- 《一文读懂Deployment以及实践攻略》
- 《一文读懂StatefulSet以及实践攻略》
- 《一文读懂Pod以及实践攻略》
1 概念:

1.1 什么是弹性扩展
假设你是一家餐厅的老板,通常情况下每天只有几桌顾客,安排两三个服务员足够了。但突然某天,有几个旅行团的客户同时光顾你的餐厅,服务员忙得团团转,而且顾客们也排起了长队。为了应对突如其来的客流高峰,你只能临时增派几个服务员,当客流高峰过后,你再遣散这批临时工。
在 Kubernetes 里,Pod 就像服务员,用户请求是顾客。当负载增加时,需要更多的 Pod 处理请求,这就是 弹性扩展。弹性扩展让系统根据实际需求自动增加或减少资源,确保高效运行。
在Kubernetes 中的 Horizontal Pod Autoscaler(HPA),就是“弹性扩展”的核心组件。HPA 是一个智能的“店长”,它能根据系统的实时负载情况(比如 CPU 使用率或自定义指标),自动调整 Pod 的数量。这样既能在业务高峰时提供足够的计算资源,又能在闲时减少资源浪费。
1.2 HPA 的工作原理
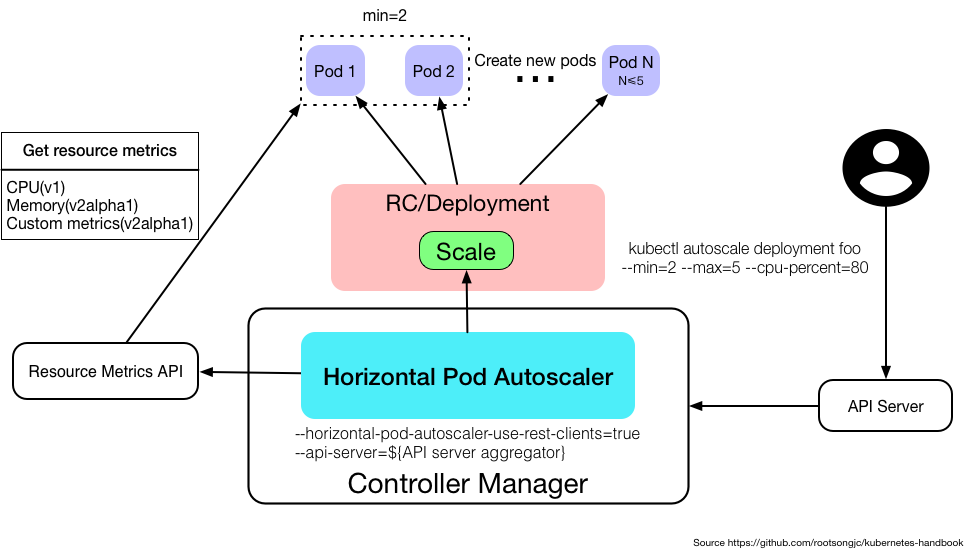
上图说明了HPA 的运作机制与其他资源或组件的关联。
HPA作为系统负载监控员,职责就是时刻关注着系统的负载。它会根据预设的规则自动进行扩展和收缩。例如,当 CPU 使用率飙升到80%时,HPA 就会触发 Pod 的扩展过程;而当负载减轻到30%时,它又会减少 Pod 数量。
- Metric Server: HorizontalPodAutoscaler 默认会从资源聚合 API(
metrics.k8s.io、custom.metrics.k8s.io或external.metrics.k8s.io)获取指标。 而这类的API 通常是由Metrics Server 组件提供,所以HPA策略配置前提是要安装Metric Server组件。 - 资源请求与限制: 因为HPA 需要根据 Pod定义 的 资源请求(requests)和限制(limits) 来进行判断,所以在Deployment、StatefulSet创建时必须设置请求(requests,资源请求决定了 Pod 在创建时会获取的最小资源)和限制(limits,而资源限制决定了它可以使用的最大资源)。如果资源配置不合理,HPA 的扩展行为可能不准确。
- 监控负载: HPA 定期监控 Pods 的 CPU 或其他资源使用情况,确保实时了解集群的健康状况。而监测间隔可以根据需求调整
kube-controller-manager组件的--horizontal-pod-autoscaler-sync-period参数(默认间隔为 15 秒) - 自动扩展: 当负载增加超过设定的阈值(如 CPU 使用率超过 80%),HPA 会请求 Kubernetes 动态增加更多的 Pods 来处理请求。
- 自动缩减: 当负载减少低于设定的阈值(如 CPU 使用率低于30%),HPA 也会减少 Pods 数量,节省资源。
1.3 通过监控指标来调整副本数
1.3.1 计算公式说明
HPA 的核心是通过 当前指标值(currentMetricValue)和 期望指标值(desiredMetricValue)之间的比例,来决定是否需要增加或减少 Pod 的副本数。其公式为:
desiredReplicas = ceil[currentReplicas * (currentMetricValue / desiredMetricValue)]
❔字段解释:
desiredReplicas:HPA 计算出的期望副本数。currentReplicas:当前 Pod 副本数。currentMetricValue:所有Pod实际的当前指标值(如 CPU 使用率、内存等)。desiredMetricValue:用户设置的所有Pod期望指标值(如目标的 CPU 使用率)。
举例:
- 如果当前指标值为
200m,期望值为100m,HPA 认为当前负载过高,于是将副本数翻倍(200/100 = 2.0)。 - 如果当前指标值为
30m,期望值为100m,HPA 认为负载过低,因此将副本数减半(30/100 = 0.3)。 - 如果比例接近 1(即负载接近期望值),HPA 不会执行缩放操作。默认的容忍范围是 0.1(或 10%)。
1.3.2 平均值计算
当设置了 targetAverageValue 或 targetAverageUtilization 时,HPA 会通过所有 Pod 的平均值来计算 currentMetricValue,然后决定是否进行缩放操作。
1.3.3 未就绪 Pod 和丢失的指标处理
❓ 思考:如果Pod状态异常或者无法抓取负载指标,那HPA如何处理?
HPA 在计算时,会这样处理以下特殊情况:
- 缺失的指标:如果某些 Pod 缺少指标(比如由于启动时间较短或其他原因),这些 Pod 会被暂时忽略。Pod 的指标丢失时,HPA 在缩容时假设这些 Pod 使用了 100% 的期望值,而在扩容时假设它们使用了 0% 的期望值。这样处理可以避免过度缩放。
- 未就绪的 Pod:如果某些 Pod 尚未准备就绪(如仍在启动或不健康),它们的指标也会被忽略。这些 Pod 可能还没有准备好提供正确的指标,因此在扩容时假设它们的指标为 0%。
此外,HPA 在确定 Pod 是否准备就绪时,可能会因为技术限制无法立即准确判断一个 Pod 的“就绪状态”。因此,HPA 使用两个时间窗口来处理:
- 初始就绪延迟:
--horizontal-pod-autoscaler-initial-readiness-delay,默认是 30 秒。 - CPU 初始化时间:
--horizontal-pod-autoscaler-cpu-initialization-period,默认是 5 分钟。
1.3.4 多指标支持
如果 HPA 同时监控多个指标(如 CPU 和内存),它会分别计算每个指标对应的 desiredReplicas,然后选择其中最大的负载指标作为扩容依据,对副本进行扩容。这样确保不会因为单个指标低而错过扩容的需求。
1.3.5 缩减副本的平滑策略
为了防止缩容过于频繁造成的不稳定,HPA 使用了一个配置项 --horizontal-pod-autoscaler-downscale-stabilization(默认 5 分钟),在这个时间窗口内,HPA 会选择最近一段时间内最高的缩容建议,从而平滑缩容操作,避免因指标波动频繁触发缩放。
1.4 HPA的优缺点
HPA 为应用管理提供了灵活性和自动化,但也有一些局限性,以下是整理HPA优缺点对比:
| 序号 | 优点 | 缺点 |
|---|---|---|
| 1 | 自动扩缩容:HPA 能够自动调整 Pod 副本数量,减少手动操作的需求。根据系统负载自动扩展和缩减 Pod,确保资源的有效利用。 | 延迟性:HPA 的扩缩容行为通常基于资源使用率等指标,这些指标有时不能立即反映负载的变化。特别是在使用基于 CPU 的指标时,系统的实际负载增长可能已经超出预期,而 HPA 才开始扩容。 |
| 2 | 节省成本:在负载减少时,HPA 会缩减 Pod 副本数量,释放不必要占用的资源,从而降低云资源的成本。 | 无法处理跨地域扩展:HPA 仅针对单个 Kubernetes 集群中的 Pod 进行扩缩容,而无法对多区域的集群进行扩展和协调。在需要跨地域部署时,HPA 的作用有限。 |
| 3 | 实时调整:HPA 能够根据实时监控的指标(如 CPU 使用率、内存利用率或自定义的业务指标)做出即时反应,及时调整 Pod 的数量,避免因负载激增导致系统性能下降。 | 依赖监控系统:HPA 需要依赖指标采集工具(如 Metrics Server 或 Prometheus)来获取资源使用情况或自定义指标。如果监控系统不稳定或数据不准确,HPA 的扩缩容决策可能会受到影响。 |
| 4 | 支持多种指标:HPA 支持基于多种指标进行扩缩容,包括 CPU、内存、外部指标(如请求数、队列长度)或自定义指标(如来自 Prometheus 的 HTTP 请求数)。 | 对高峰流量的应对能力有限:HPA 对突发的大规模流量高峰(如“黑色星期五”或大型促销活动)可能反应不够迅速,因为它依赖于指标反馈和自动扩容的过程,这可能无法及时应对流量激增。 |
| 5 | 稳定化策略:HPA 提供了自定义的 稳定化窗口 和 扩缩容策略,允许用户控制扩容和缩容的速率,避免频繁的副本数量波动(即“flapping”问题)。 |
2 实践攻略:部署和配置 HPA
通过理解 HPA 的原理,我们接下来看看如何实际配置 HPA。在这部分中,我们将分步骤介绍如何设置 HPA,确保它能根据负载动态调整 Pod 数量。
2.1 安装metric-server
如果你的Kubernetes环境没有安装Metric Server,可以参考以下流程完成安装。
下载metric-server.yaml文件
wget -o metric-server.yaml https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml根据实际环境,修改配置:
metrics-server的Deployment参数
containers:- args:- --cert-dir=/tmp- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname- --kubelet-use-node-status-port- --metric-resolution=15s- --kubelet-insecure-tls- --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.pem- --requestheader-username-headers=X-Remote-User- --requestheader-group-headers=X-Remote-Group- --requestheader-extra-headers-prefix=X-Remote-Extra-
❔ 参数说明:
- –kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname: 指定 Metrics Server 首选的 kubelet 地址类型顺序,以便与集群节点进行通信。
- –kubelet-use-node-status-port: 使用 Kubernetes 节点状态中定义的端口与 Kubelet 通信,而不是默认的端口
10250。 - –metric-resolution=15s: 指定 Metrics Server 的数据采集频率,在这里设置为每 15 秒 收集一次数据。
- –kubelet-insecure-tls: 允许 Metrics Server 跳过对 Kubelet 证书的验证。
- –requestheader-client-ca-file=/path/to/ca.pem: 指定一个 CA 证书,用于验证客户端请求头中代理认证的客户端证书。
- –requestheader-username-headers=X-Remote-User: 指定 HTTP 请求头中,用来传递用户名信息的请求头名称。
- –requestheader-group-headers=X-Remote-Group: 指定用于传递用户组信息的 HTTP 请求头名称。
- –requestheader-extra-headers-prefix=X-Remote-Extra-: 指定 HTTP 请求头的前缀,用来传递额外的认证信息。
修改metrics-server的volume参数,把证书挂载到pod
---volumeMounts:- mountPath: /tmpname: tmp-dir- name: ca-sslmountPath: /etc/kubernetes/pki
---volumes:- emptyDir: {}name: tmp-dir- name: ca-sslhostPath:path: /etc/kubernetes/pki 替换镜像地址,可以根据自己的仓库地址修改:
sed -i 's#registry.k8s.io/metrics-server/metrics-server:v0.7.1#harbor.zx/hcie/metrics-server:v0.7.1#' metric-server.yaml完整的配置如下,可以参考:
apiVersion: v1
kind: ServiceAccount
metadata:labels:k8s-app: metrics-servername: metrics-servernamespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:labels:k8s-app: metrics-serverrbac.authorization.k8s.io/aggregate-to-admin: "true"rbac.authorization.k8s.io/aggregate-to-edit: "true"rbac.authorization.k8s.io/aggregate-to-view: "true"name: system:aggregated-metrics-reader
rules:
- apiGroups:- metrics.k8s.ioresources:- pods- nodesverbs:- get- list- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:labels:k8s-app: metrics-servername: system:metrics-server
rules:
- apiGroups:- ""resources:- nodes/metricsverbs:- get
- apiGroups:- ""resources:- pods- nodesverbs:- get- list- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:labels:k8s-app: metrics-servername: metrics-server-auth-readernamespace: kube-system
roleRef:apiGroup: rbac.authorization.k8s.iokind: Rolename: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccountname: metrics-servernamespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:labels:k8s-app: metrics-servername: metrics-server:system:auth-delegator
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: system:auth-delegator
subjects:
- kind: ServiceAccountname: metrics-servernamespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:labels:k8s-app: metrics-servername: system:metrics-server
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: system:metrics-server
subjects:
- kind: ServiceAccountname: metrics-servernamespace: kube-system
---
apiVersion: v1
kind: Service
metadata:labels:k8s-app: metrics-servername: metrics-servernamespace: kube-system
spec:ports:- name: httpsport: 443protocol: TCPtargetPort: httpsselector:k8s-app: metrics-server
---
apiVersion: apps/v1
kind: Deployment
metadata:labels:k8s-app: metrics-servername: metrics-servernamespace: kube-system
spec:selector:matchLabels:k8s-app: metrics-serverstrategy:rollingUpdate:maxUnavailable: 0template:metadata:labels:k8s-app: metrics-serverspec:containers:- args:- --cert-dir=/tmp- --secure-port=10250- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname- --kubelet-use-node-status-port- --metric-resolution=15s- --kubelet-insecure-tls- --requestheader-client-ca-file=/steven/certs/kubernetes/front-proxy-ca.pem- --requestheader-username-headers=X-Remote-User- --requestheader-group-headers=X-Remote-Group- --requestheader-extra-headers-prefix=X-Remote-Extra-image: harbor.zx/hcie/metrics-server:v0.7.1imagePullPolicy: IfNotPresentlivenessProbe:failureThreshold: 3httpGet:path: /livezport: httpsscheme: HTTPSperiodSeconds: 10name: metrics-serverports:- containerPort: 10250name: httpsprotocol: TCPreadinessProbe:failureThreshold: 3httpGet:path: /readyzport: httpsscheme: HTTPSinitialDelaySeconds: 20periodSeconds: 10resources:requests:cpu: 100mmemory: 200MisecurityContext:allowPrivilegeEscalation: falsecapabilities:drop:- ALLreadOnlyRootFilesystem: truerunAsNonRoot: truerunAsUser: 1000seccompProfile:type: RuntimeDefaultvolumeMounts:- mountPath: /tmpname: tmp-dir- name: ca-sslmountPath: /steven/certs/kubernetes/nodeSelector:kubernetes.io/os: linuxk8s.role: masterpriorityClassName: system-cluster-criticalserviceAccountName: metrics-servervolumes:- emptyDir: {}name: tmp-dir- name: ca-sslhostPath:path: /steven/certs/kubernetes
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:labels:k8s-app: metrics-servername: v1beta1.metrics.k8s.io
spec:group: metrics.k8s.iogroupPriorityMinimum: 100insecureSkipTLSVerify: trueservice:name: metrics-servernamespace: kube-systemversion: v1beta1versionPriority: 100部署metric-server
kubectl apply -f metric-server.yaml
检查集群负载状态
kubectl top node输出如下:
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master1 176m 8% 1495Mi 52%
k8s-master2 187m 9% 1518Mi 53%
k8s-master3 192m 9% 1453Mi 51%
k8s-worker1 590m 29% 1552Mi 40%
k8s-worker2 565m 28% 1563Mi 40%
查看集群pod的负载状态
kubectl top pod输出如下:
NAME CPU(cores) MEMORY(bytes)
fluentd-26ksx 384m 108Mi
fluentd-8wnhj 414m 112Mi
fluentd-ddxbp 396m 115Mi
fluentd-hmqds 470m 106Mi
fluentd-xhl7b 377m 98Mi
redis-0 3m 12Mi
redis-1 2m 10Mi
redis-2 2m 10Mi❔ 说明: metric-server可以获取Kubernetes的负载数据。
❓ 思考:我希望metric-server运行在master节点,如何操作?
以下使用节点标签匹配,在master节点新增label,执行以下命名:
kubectl label nodes k8s-master1 k8s.role=master
kubectl label nodes k8s-master2 k8s.role=master
kubectl label nodes k8s-master3 k8s.role=master修改deployment文件,根据节点新增的便签调度pod:
vim metric-server-components.yaml
...
# 指定pod跑到带标签的节点nodeSelector:kubernetes.io/os: linuxk8s.role: master重新部署metric-server
# 执行部署
kubectl apply -f metric-server.yaml
检查pod所在节点
[root@k8s-master1 ~]# kubectl get pods -n kube-system -owide -l k8s-app=metrics-server
NAME READY STATUS RESTARTS AGE IP NODE NOMINATE D NODE READINESS GATES
metrics-server-5ffdc9fc8d-pxgb9 1/1 Running 1 (7m39s ago) 27m 172.16.224.5 k8s-master2 <none>
2.2 1. 部署一个应用
在配置 HPA 之前,我们需要先部署一个测试php-apache的工作负载,然后进行负载测试,观察HPA的工作原理。
编写测试负载yaml:
apiVersion: apps/v1
kind: Deployment
metadata:name: php-apache
spec:replicas: 1selector:matchLabels:run: php-apachetemplate:metadata:labels:run: php-apachespec:containers:- name: php-apacheimage: harbor.zx/hcie/hpa-exampleports:- containerPort: 80resources:limits:cpu: 300mrequests:cpu: 100m
---
apiVersion: v1
kind: Service
metadata:name: php-apachelabels:run: php-apache
spec:ports:- port: 80selector:run: php-apache❔ 说明:该php-apache 部署文件会启动 1 个 Pod,每个 Pod 的 CPU 请求资源为 100m,CPU 限制为 300m。
部署php-apache ,执行以下命令:
kubectl apply -f hpa-test.yaml
输出如下,证明成功:
deployment.apps/php-apache created
service/php-apache created
2.3 2. 创建 HPA
部署应用后,接下来我们配置 HPA。假设你想基于 CPU 使用率来扩展 Pod,可以使用以下命令创建一个 HPA:
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10❔参数说明:
--cpu-percent=50表示:当 Pod 的 CPU 使用率超过 50% 时,HPA 会开始扩展 Pod 数量。--min=1和--max=10指定了最小和最大 Pod 数量,即 HPA 会确保 Pod 数量不低于 1 个,也不会超过 10 个。
执行成功输出:
horizontalpodautoscaler.autoscaling/php-apache autoscaled2.4 验证 HPA 工作情况
2.4.1 查看HPA当前状态
部署完后,你可以通过运行以下命令来检查新建的 HorizontalPodAutoscaler 的当前状态:
# kubectl get horizontalpodautoscalers.autoscaling
kubectl get hpa
输出如下:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 1%/50% 1 10 1 72s❔ 说明:请注意,当前 CPU 负载为 1%,因为没有客户端向服务器发送请求(
TARGET列显示相应部署控制的所有 Pod 的平均值)。
2.4.2 验证HPA扩缩
接下来测试 HPA 的扩展能力,我们将启动一个busybox 来充当客户端。客户端 Pod 中的容器以无限循环运行,向 php-apache 服务发送查询。
先执行下面命令持续观察php-apache状态:
kubectl get hpa php-apache --watch
执行下面命令进行测试:
kubectl run -i --tty load-generator --rm --image=harbor.zx/hcie/busybox:1.29-2 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache.default.svc.cluster.local; done"再观察HPA的状态
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 1%/50% 1 10 1 35m
php-apache Deployment/php-apache 204%/50% 1 10 1 35m
php-apache Deployment/php-apache 277%/50% 1 10 4 36mphp-apache Deployment/php-apache 258%/50% 1 10 6 36m
php-apache Deployment/php-apache 239%/50% 1 10 6 36m
php-apache Deployment/php-apache 141%/50% 1 10 6 36m
php-apache Deployment/php-apache 124%/50% 1 10 6 37m
看到CPU负载最高达到258%, 套用公式验证6=ceil[1*(258%/50%)], 然后可以看到Deployment的副本数确实扩展到6。
然后关闭load-generator, 过几分钟再观察负载:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 1%/50% 1 10 1 42m
❔ 说明: 看到php-apache的cpu负载和副本数都下降到原来一样了。通过这种方式模拟大量请求,你可以观察到 HPA 会根据 CPU 使用率自动扩展和缩减 Pod 的数量。
3 总结
通过 Horizontal Pod Autoscaler(HPA),Kubernetes 可以提供强大的弹性扩展功能。除了了解其工作原理之外,还需根据实际应用场景进行配置优化,确保资源利用最大化。希望通过本文的讲解和实践操作,你能更好地掌握 Kubernetes 的 HPA,并在实际工作中发挥其最大价值。
那么,你的系统准备好随时迎接流量高峰了吗? 同时预告下文《一文读懂HPA弹性扩展自定义指标和缩放策略》,感谢关注点赞!😊
4 参考文献
[1]Kubernetes 官方文档
[2]HorizontalPodAutoscaler Walkthrough
[3]Kubernetes CPU 与内存限制设置