GraphRAG与VectorRAG我都选:HybridRAG
从金融应用中产生的非结构化文本数据(如财报电话会议记录)提取和解释复杂信息,即使采用当前最佳实践使用检索增强生成(RAG)技术,对于大型语言模型(LLMs)来说仍存在重大挑战。这些挑战包括领域特定术语和文档格式的复杂性。本文介绍了一种称为 _HybridRAG _的新方法,它结合了基于知识图谱(KGs)的RAG技术(称为GraphRAG)与VectorRAG技术,以提高从金融文件中提取信息的问答系统性能,并能够生成准确且上下文相关的答案。
通过实验表明,当评估检索和生成阶段时,从向量数据库和知识图谱同时检索上下文的 HybridRAG,在检索准确性及答案生成方面优于传统的 VectorRAG 和单独的 GraphRAG。所提出的技术不仅限于金融领域,还有更广泛的应用潜力。
一、VectorRAG
VectorRAG从与外部文档相关的查询开始,这些文档不是 LLM 训练数据集的一部分。查询用于搜索外部存储库(如向量数据库或索引语料库),以检索包含有用信息的相关文档或段落。检索到的文档随后作为额外上下文反馈到 LLM 中,从而生成基于查询的响应。这确保了生成内容不仅基于内部训练数据,还结合了检索到的外部信息。
描述RAG应用向量数据库创建的示意图
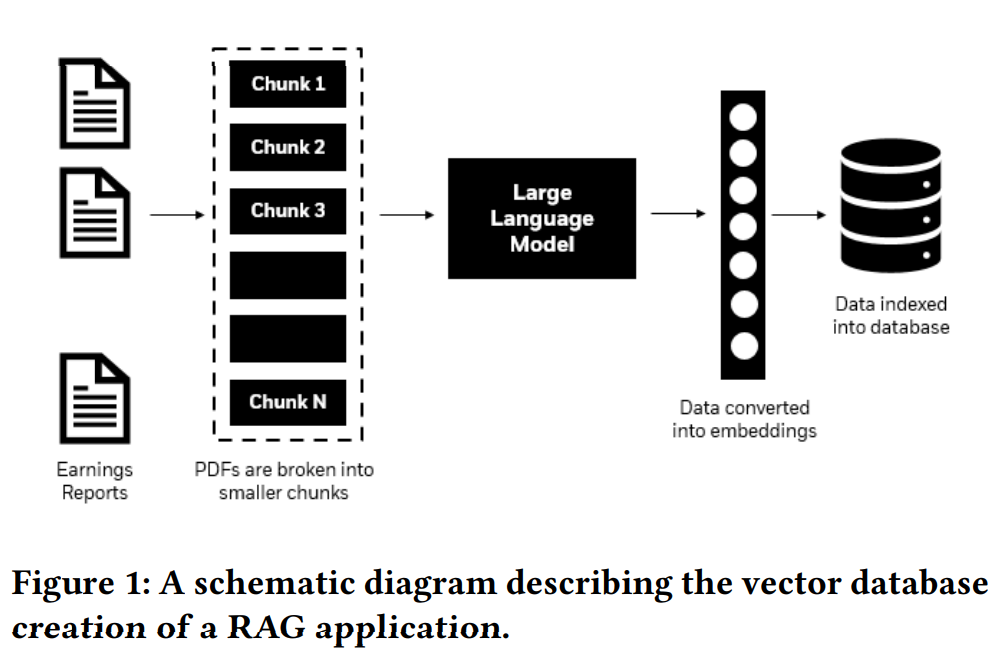
二、GraphRAG
利用知识图谱来增强 NLP 任务的性能,通过将知识图谱与 RAG 技术整合,GraphRAG 能够基于从金融文档中提取的结构化信息生成更准确和上下文感知的回答。
2.1 知识图谱构建(Knowledge Graph Construction)
这包括三个主要步骤:知识提取、知识改进和知识适应。
知识提取涉及从非结构化或半结构化数据中提取结构化信息,包括实体识别、关系提取和共指消解。知识改进旨在通过移除冗余和填补信息空白来提高 KG 的质量和完整性。知识融合则结合来自多个源的信息,创建一个一致和统一的 KG。
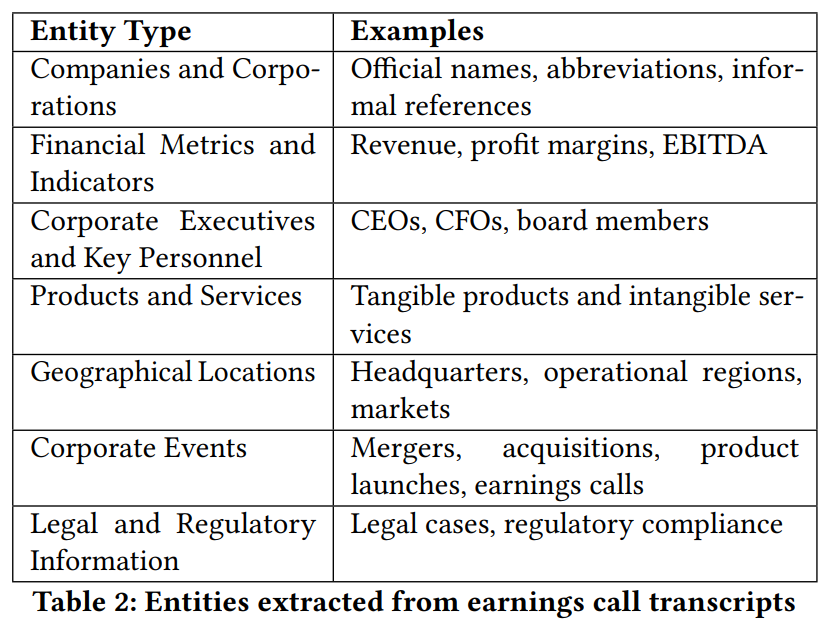
2.2 GraphRAG
基于知识图谱的 RAG(GraphRAG)也是从用户输入的查询开始。与 VectorRAG 的主要区别在于检索部分。在这里,查询用于搜索 KG 以检索与查询相关的节点(实体)和边(关系)。然后从完整的 KG 中提取包含这些相关节点和边的子图,以提供上下文。
描述GraphRAG知识图谱创建过程的示意图
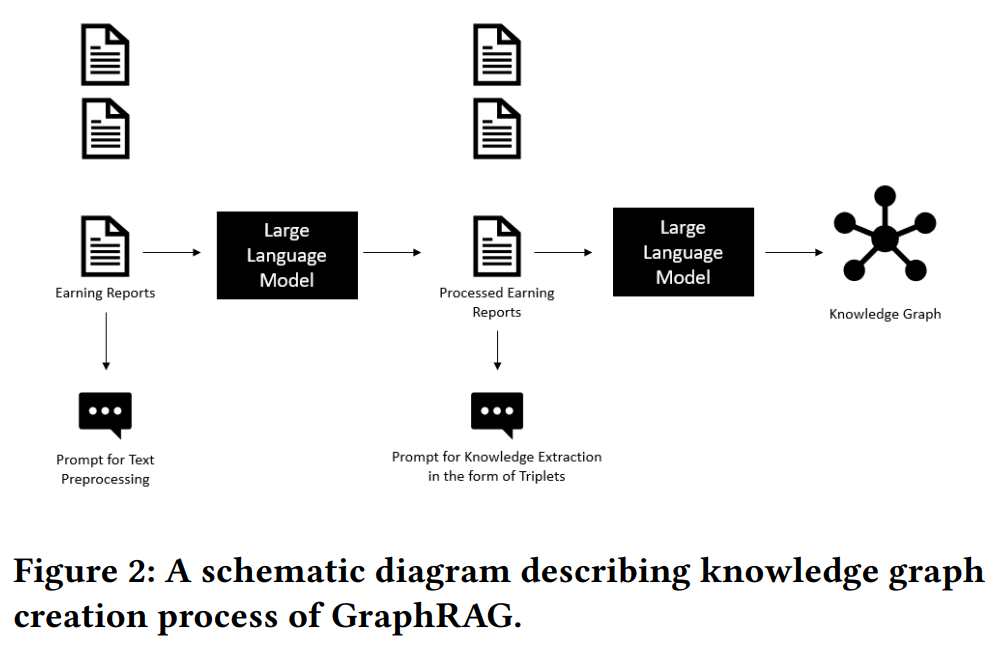
三、HybridRAG
结合了 VectorRAG 和 GraphRAG 的优势,从向量数据库和知识图谱中检索上下文信息,以提供给 LLMs,从而生成更准确的回答。
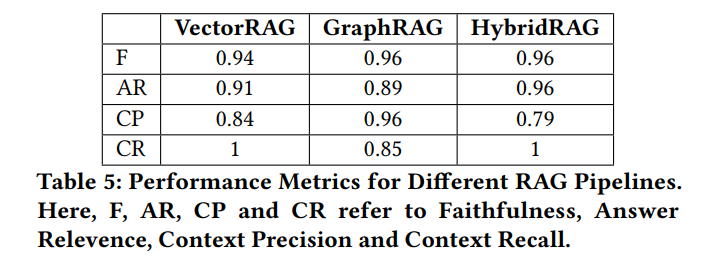
通过在一组金融收益电话会议记录上的实验,展示了 HybridRAG 在检索和生成阶段的性能优于单独使用 VectorRAG 或 GraphRAG:
- 在忠实度方面,GraphRAG 和 HybridRAG 显示出更优越的性能,两者都达到了0.96的得分,而 VectorRAG 略低一些,得分为0.94。
- 答案相关性得分在不同方法之间有所不同,HybridRAG 以0.96的得分领先,其次是 VectorRAG 的0.91,GraphRAG 的0.89。
- 上下文精确度方面,GraphRAG 以0.96的得分最高,显著超过了 VectorRAG 的0.84 和 HybridRAG 的0.79。然而,在上下文召回率方面,VectorRAG 和 HybridRAG 都达到了完美的1分,而 GraphRAG 落后于0.85。
https://arxiv.org/pdf/2408.04948