12. DataLoader的基本使用
DataLoader的基本使用
1. 为什么要使用DataLoader
-
DataLoader对创建好的DataSet的样本取样进行了集成操作,非常方便对于后续网络训练、测试的数据集的选择和使用
-
DataLoader可以集成了数据批量加载的方法,可以使用
batch_size设置批量大小,DataLoader就会自动处理批量数据的加载,下面给出批量处理的作用- 内存管理:对于需要处理的大量数据,直接投入模型训练是不现实的,小批次处理可以解决这个问题
- 梯度估计的稳定性:小批次梯度估计能够获得更稳定的梯度更新,比整个数据集计算的梯度更快、比单个样本计算的梯度更可靠
- 模型参数更新:小批次运行模型每处理完一个批次就进行参数更新,可以加快模型的训练过程,前期阶段就可以更快地学习到有用特征,减少迭代次数
- 调优更方便:可以灵活调整批次大小,找到适合的训练配置。
- 可以通过不断保存每批次训练后的模型结果,避免代码考虑不周带来的后续模型无法训练的问题
-
DataLoader集成了自动化打乱数据的逻辑代码。确保每个epoch都有不同的数据顺序,
shuffle=True -
DataLoader处理的DataSet数据,要符合第一章中创建的Dataset类的标准,需要对部分魔法函数进行重写。
class Mydata(Dataset):def __init__(self, ):def __getitem__(self, index):return img, labeldef __len__(self):return len(xxx)
2. 使用DataLoader
-
首先加载torchvision的CIFAR10数据集,并将图片数据转换为Tensor
import torchvision test_data = torchvision.datasets.CIFAR10(root='./data_torchvision', train=False,transform=torchvision.transforms.ToTensor(),download=True)- 查看CIFAR10的父类,可以发现该数据集是一个Dataset子类的子类
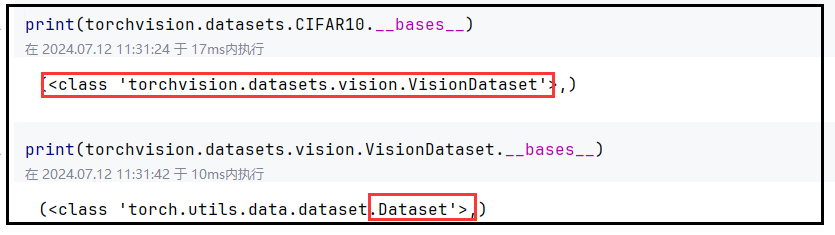
-
创建Dataloader实例
from torch.utils.data import DataLoadertest_loader = DataLoader(dataset = test_data,batch_size=64,shuffle=True,drop_last=True)dataset:导入基于Dataset类的数据集bact_size:设置数据集中每一次划分图像的数目shuffle:是否打乱样本drop_last:是否舍弃剩余不够分配batc_size的样本- 比如test_data共有100个照片,batch_size设置为11,则创建的Dataloader实例包含9组每组11张照片
- 对于剩余的一张照片,
drop_last=True时直接舍弃,否则单独保留为一组仅包含一张照片
3. DataLoader实例的使用说明
-
数据集说明:test_data共有10000个数据,当
batch_size=64 && drop_last=True时,test_loader共包含156个组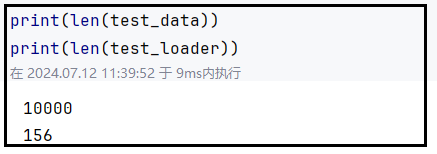
-
通过迭代遍历
test_loader, 每次遍历得到其中一组数据,每组数据的组织方式为images和labels:一组中的所有图片组织为一个Tensor数据,依据图片顺序将标签组织为一个Tensor数据
- 上述输出中,每一个data是test_loader的一个组,一个组包含64个图片
- imgs是64个图片组织成的Tensor数据
- labels是64个图片对应的类别标签
-
imgs可以在TensorBoard中进行展示
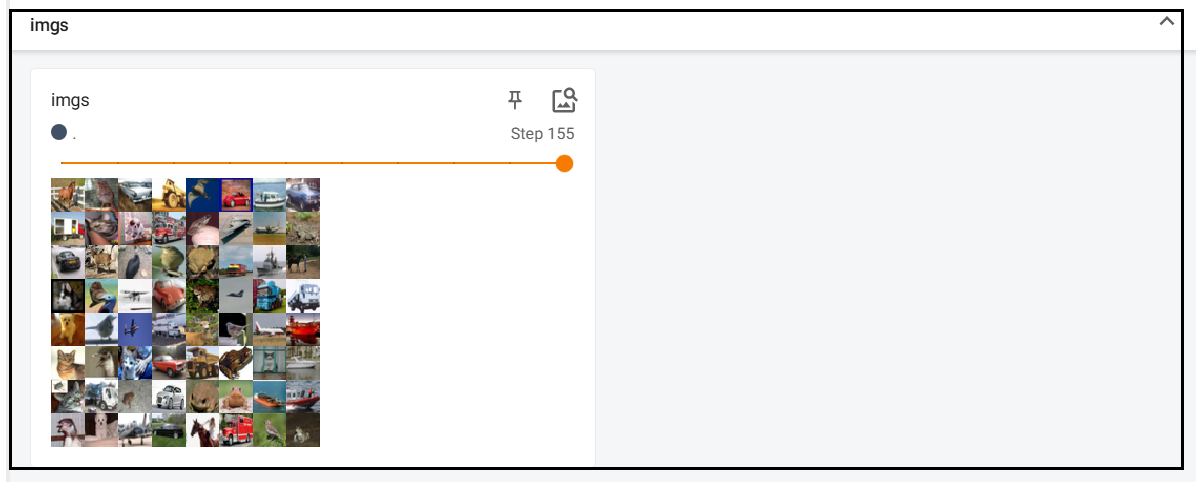
from torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter('./logs') i = 0 for data in test_loader:imgs, labels = datawriter.add_images(tag = "imgs",img_tensor=imgs,global_step=i)i+=1 writer.close()-
add_images:可以一次性添加由多个image组成的Tensor数据,将结果展示如下,共计step有156个,每个step包含64张照片
-