注意力机制:从 MHA、MQA、GQA、MLA 到 NSA、MoBA
文章目录
- 注意力机制:从 MHA、MQA、GQA、MLA 到 NSA、MoBA(超全总结+代码示例)
- 一、MHA(Multi-Head Attention)
- 二、MQA(Multi-Query Attention)
- 三、GQA(Grouped-Query Attention)
- 四、MLA(Multi-Head Latent Attention)
- 五、NSA(Native Sparse Attention)
- NSA 代码示例(简化版 PyTorch)
- NSA总结一句话
- 六、MoBA(Mixture of Block Attention)
- MoBA 代码示例(简化 PyTorch版)
- MoBA总结一句话
- 七、各方法对比总结
- 对比总结与演进趋势
- 八、应用案例场景
- 九、代码示例合集
- 1. MHA 代码(简化版 PyTorch)
- 2. MQA 示例
- 3. GQA 示例
- 4. MLA 简单示例
- 十、总结展望
注意力机制:从 MHA、MQA、GQA、MLA 到 NSA、MoBA(超全总结+代码示例)
近年来,注意力机制不断演进,从最早的多头注意力(MHA)到单头简化(MQA、GQA),再到模块化升级(MLA、NSA、MoBA),不断提升模型效率和表达能力。本文系统总结各类注意力机制,剖析概念、作用、优缺点,提供应用案例及对应代码示例,助力大家全面理解注意力机制的演变!
一、MHA(Multi-Head Attention)
论文标题:Attention Is All You Need
论文链接:https://arxiv.org/pdf/1706.03762
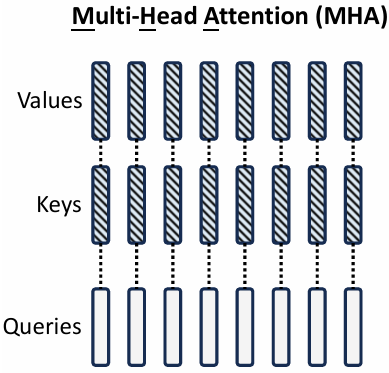
概念:
多头注意力(MHA,2017)是 Transformer 中的核心机制,首次在《Attention Is All You Need》中提出。通过多个不同的注意力头来并行学习不同子空间的信息表达。MHA(Multi-Head Attention)是Transformer的核心组件,通过多个独立的注意力头并行捕捉输入序列的不同语义特征。每个头将输入映射为独立的查询(Q)、键(K)、值(V)向量,并通过点积计算注意力得分,最终拼接各头输出并通过线性变换融合。
公式:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
MHA则是多个这种 attention 的并行组合。
作用:
- 捕获不同子空间的多样化特征。捕捉多维度语义信息,适用于复杂任务(如翻译、文本生成)
- 提升模型学习复杂关系的能力。
优点:
- 强大的特征捕获能力。
- 在多任务、多模态场景表现优异。
缺点:
- 参数量大,计算量高(尤其是大模型时代)。推理时KV缓存占用显存高,导致内存带宽瓶颈
二、MQA(Multi-Query Attention)
论文标题:Fast Transformer Decoding: One Write-Head is All You Need
论文链接:https://arxiv.org/pdf/1911.02150
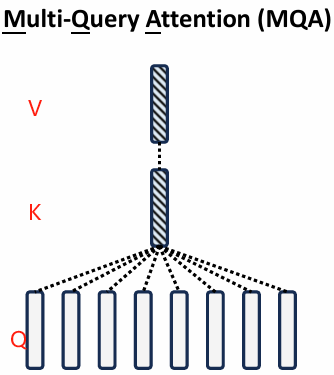
概念:
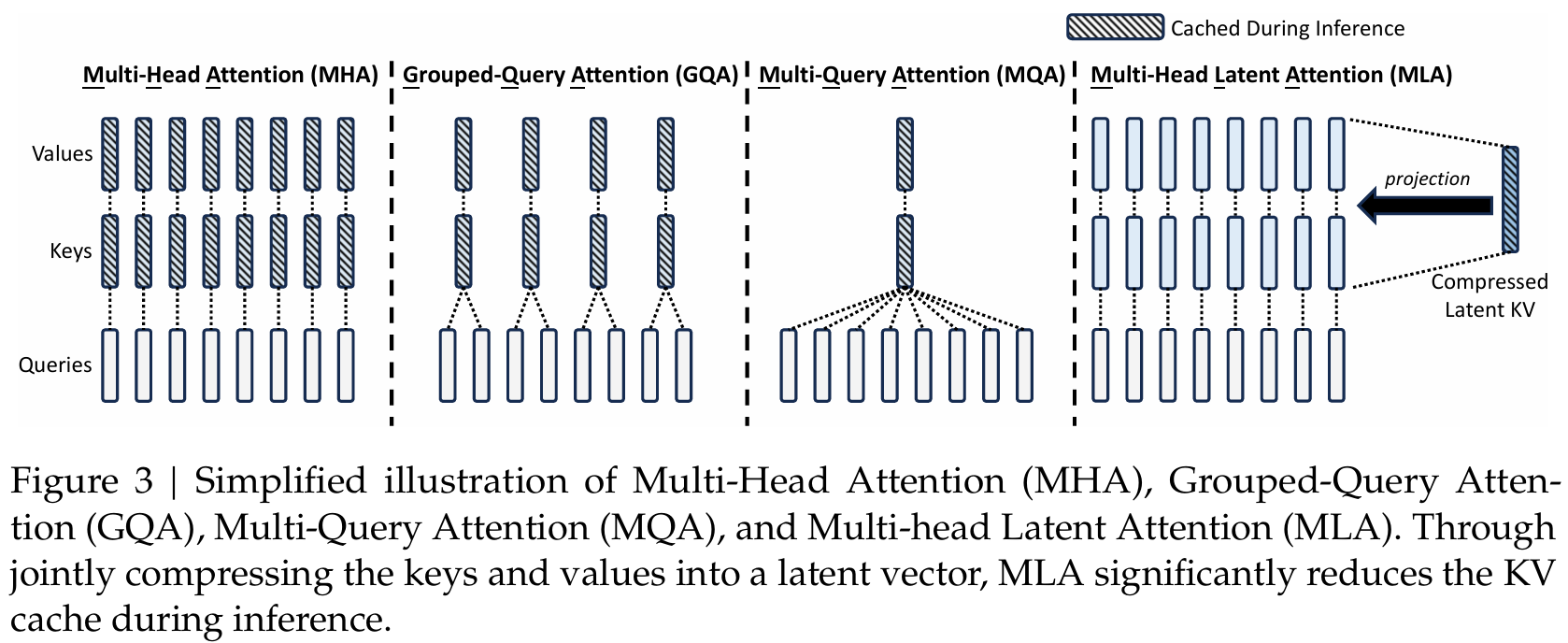
多查询注意力(MQA,2019):MQA 将所有的 Query 使用同一个 Key/Value 组,只有 Query 是多头的,所有查询头共享同一组键(K)和值(V),减少KV缓存显存占用,Key 和 Value 是共享的。
作用:
- 大幅减少存储开销,尤其在大模型(如 LLMs)推理阶段。推理速度提升12倍,显存占用减少至MHA的1/H(H为头数)
优点:
- 更少的 KV 缓存量。
- 推理更快、更省内存。
缺点:
- 多头间失去独立性,可能略微损失表示能力。模型精度下降,需从头训练。
应用:
- GPT-4 推理优化、Google PaLM大模型。
三、GQA(Grouped-Query Attention)
论文标题:GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
论文链接:https://arxiv.org/pdf/2305.13245
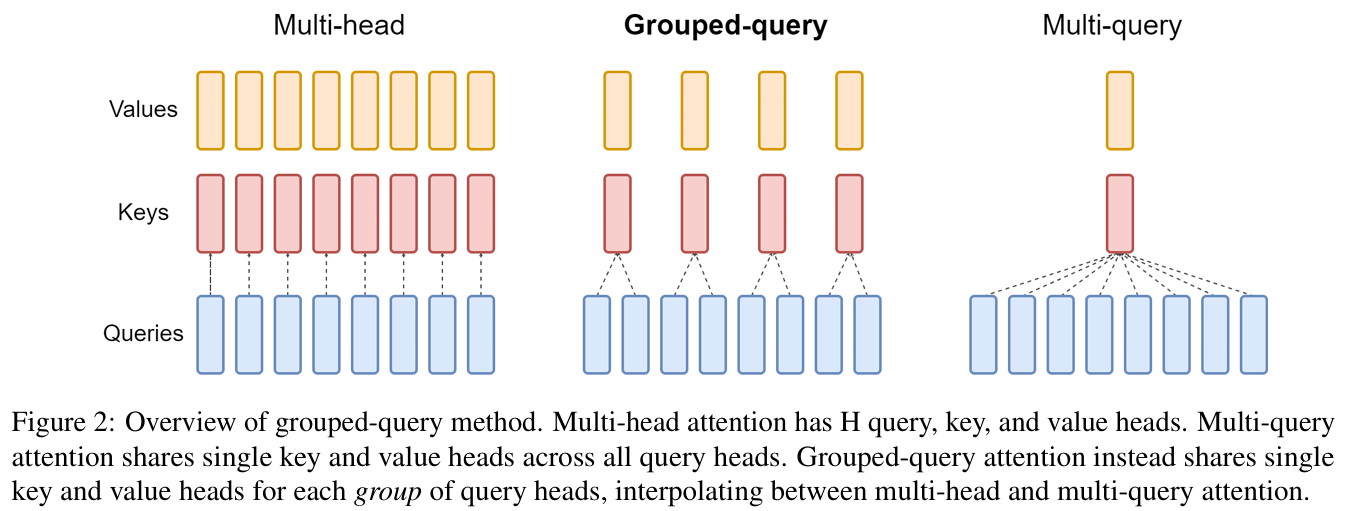
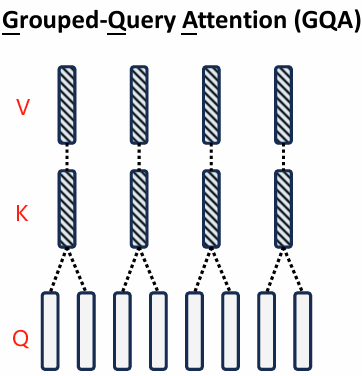
概念:
分组查询注意力(GQA,2023):GQA 在 MQA 和 MHA 之间做了折中:多个 Query 组共用同一个 Key/Value,但不同组是独立的。将查询头分组,每组共享KV头(如ChatGLM2-6B中组数为2),平衡效率与精度。
比如:32 个 Attention Head,8 组,每组 4 个 Query 共享一组 KV。
作用:
- 兼顾表示能力和存储效率。推理速度接近MQA,性能逼近MHA(如T5-XXL实验显示延迟降低50%,精度损失<1%)。GQA的速度相比MHA有明显提升,而效果上比MQA也好一些,能做到和MHA基本没差距。
优点:
- 比 MQA 表达更好。
- 比 MHA 更省显存。
缺点:
- 需要调整组数以适配不同任务。
应用:
- LLaMA-2、Claude、Gemini、ChatGLM2 都大量使用 GQA。
四、MLA(Multi-Head Latent Attention)
论文标题:DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
论文链接:https://arxiv.org/abs/2405.04434
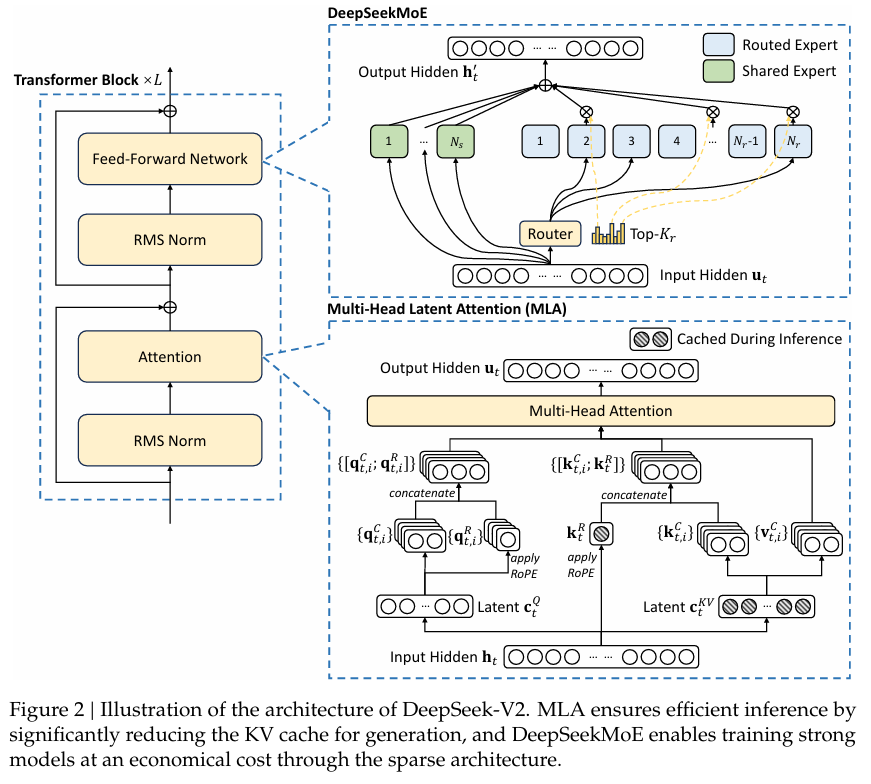
概念:
多头潜在注意力(MLA, 2024):MLA 引入隐变量(latent tokens),而不是直接对全部 Token 做 Attention。每个 Head 注意的是一组低维隐空间的表示。MLA(Multi-head Latent Attention)通过低维潜在向量压缩KV缓存,结合解耦式RoPE(旋转位置编码),减少显存占用。具体步骤包括:
- 将输入投影到低维潜在空间;
- 动态映射回高维空间生成KV。
常见于 Perceiver、CoAtNet、Latent Transformer 等架构。
作用:
- 映射原空间到隐空间,减少计算量。
- 支持大规模输入(如图像、视频)。
- MLA 的核心思想是通过低秩联合压缩技术,减少 K 和 V 矩阵的存储和计算开销。
- MLA从LoRA的成功借鉴经验,实现了比GQA这种通过复制参数压缩矩阵尺度的方法更为节省的低秩推理,同时对模型的效果损耗不大。
优点:
- 大幅降低计算复杂度。
- 显存效率:KV缓存减少至传统MHA的1/10,适合长序列生成
- 保持良好性能。
- 兼容性:保留多头并行计算能力,避免MQA/GQA的性能损失
缺点:
- 训练初期收敛稍慢。
- 隐空间容量需要精心设计。
应用场景:
- DeepSeek-V3等资源受限场景的长文本推理
五、NSA(Native Sparse Attention)
论文标题:Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
论文地址:https://arxiv.org/abs/2502.11089
概念:
- 原生稀疏注意力NSA(Native Sparse Attention,2025)是为了提升注意力计算的稀疏性而提出的一种机制。通过动态稀疏掩码跳过无关的注意力计算,减少计算量。
- 它直接在注意力矩阵中施加稀疏性规则(如 Top-k 筛选、局部窗口选择、轴向稀疏),而不是对每一对 Query-Key 全部计算。
- 最早可追溯到 Sparse Transformer(2019, OpenAI)中的思想,同时后续像 Big Bird、Longformer 都属于 NSA 思路扩展。
核心特点:
- 注意力权重矩阵不是密集计算,而是只计算特定模式下的一小部分元素。
- 保持 Transformer 的表达能力,同时降低时间和空间复杂度。理论计算复杂度从O(n²)降至O(n log n)
常见稀疏模式:
- 局部窗口注意力(Local Attention)
- 行列稀疏(Strided Attention)
- 随机稀疏(Random Attention)
- 全局 Token(Global Attention)
公式对比:
普通 Dense Attention:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right)V Attention(Q,K,V)=softmax(dkQKT)V
是对所有 ( n \times n ) 计算,复杂度 ( O(n^2) )。
NSA 稀疏 Attention:
Attention ( Q , K , V ) = softmax ( Q K T ⊙ M d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T \odot M}{\sqrt{d_k}} \right)V Attention(Q,K,V)=softmax(dkQKT⊙M)V
其中 ( M ) 是稀疏掩码,只在选中的位置计算,复杂度降到 ( O(n\sqrt{n}) ) 或 ( O(n) ) 级别。
优点:
- 大幅降低长序列计算量(尤其是输入 Token 数超千时)。
- 内存占用少,推理速度快。
缺点:
- 稀疏模式设计不合理的话,容易破坏远距离依赖。
- 对硬件优化要求高(稀疏矩阵计算不友好)。
应用:
- Longformer(局部窗口+全局 Token)
- Big Bird(窗口+随机+全局 Attention)
- Sparse Transformer(OpenAI)
- FlashAttention v2也支持稀疏结构推理!
NSA 代码示例(简化版 PyTorch)
假设我们实现一种局部窗口注意力作为 NSA 示例:
import torch
import torch.nn as nnclass LocalSparseAttention(nn.Module):def __init__(self, window_size=8):super().__init__()self.window_size = window_sizedef forward(self, q, k, v):batch_size, seq_len, d_model = q.shapeoutput = torch.zeros_like(q)for start in range(0, seq_len, self.window_size):end = min(start + self.window_size, seq_len)q_slice = q[:, start:end, :]k_slice = k[:, start:end, :]v_slice = v[:, start:end, :]scores = torch.matmul(q_slice, k_slice.transpose(-2, -1)) / d_model**0.5attn = torch.softmax(scores, dim=-1)output[:, start:end, :] = torch.matmul(attn, v_slice)return output
这里每个局部窗口内部做完整 Self-Attention,全局是稀疏连接,复杂度从 O ( n 2 ) O(n^2) O(n2) 降到 O ( n w ) O(nw) O(nw)(w是窗口大小)!
NSA总结一句话
Native Sparse Attention 是通过硬编码的稀疏模式(局部/随机/全局)减少计算开销,使长序列建模可行且高效。
六、MoBA(Mixture of Block Attention)
论文标题:Mixture of Block Attention for Long-Context LLMs
论文地址:https://github.com/MoonshotAI/MoBA/blob/master/MoBA_Tech_Report.pdf
概念:
- MoBA(Mixture of Block Attention)是一种注意力机制优化方案。
- 它将输入序列划分为多个块(Block),每个块内部执行注意力计算,块之间通过一种稀疏或局部连接方式进行交互。
- 这种方法结合了块内密集 Attention 和块间稀疏 Attention 的优点。
核心思想:
- 局部性:同一块内 Token 交互密集,捕获细粒度关系。
- 可扩展性:块间交互可以设计成稀疏连接,降低大规模计算复杂度。
- 混合策略:不同块可以采用不同的注意力处理方式,实现灵活混合。
优点:
- 保持局部细节捕捉能力。
- 显著降低长序列的计算量(从 ( O(n^2) \to O(n \sqrt{n}) ) 甚至线性)。
- 适配大规模视觉、语言、视频输入。
缺点:
- 块划分策略和块间连接设计需要调优。
- 过强的块划分可能丢失全局依赖。
典型应用:
- ViLBERT, BlockSparse Transformer, Swin Transformer 都在某种程度上采用了 Block Attention 思想。
- 大规模图像理解、长文本建模、视频理解场景。
MoBA 简要公式:
如果将序列 ( X ) 划分成 ( B ) 个块,每个块大小为 ( w ):
-
块内 Attention:
Y i = Attention ( Q i , K i , V i ) Y_i = \text{Attention}(Q_i, K_i, V_i) Yi=Attention(Qi,Ki,Vi)
其中 ( i ) 是块的索引。 -
块间交互(可选):
Y i ′ = Attention ( Q i , K j , V j ) for some j ≠ i Y_i' = \text{Attention}(Q_i, K_j, V_j) \quad \text{for some } j \neq i Yi′=Attention(Qi,Kj,Vj)for some j=i
只在选定的块之间计算交互,节省资源。
MoBA 代码示例(简化 PyTorch版)
import torch
import torch.nn as nnclass BlockAttention(nn.Module):def __init__(self, d_model, block_size):super().__init__()self.d_model = d_modelself.block_size = block_sizeself.attn = nn.MultiheadAttention(d_model, num_heads=8)def forward(self, x):batch_size, seq_len, d_model = x.shapeoutput = torch.zeros_like(x)for start in range(0, seq_len, self.block_size):end = min(start + self.block_size, seq_len)block = x[:, start:end, :]block = block.transpose(0, 1) # [seq_len_block, batch_size, d_model]attn_output, _ = self.attn(block, block, block)attn_output = attn_output.transpose(0, 1)output[:, start:end, :] = attn_outputreturn output
这里只对每个块内部做 Attention,块间可以加稀疏或全局连接模块(可扩展)。
MoBA总结一句话
Mixture of Block Attention 通过局部块划分和局部-稀疏混合机制,实现了在长序列上兼顾效率与细粒度建模的平衡。
七、各方法对比总结
| 方法 | 特点 | 优点 | 缺点 | 应用案例 |
|---|---|---|---|---|
| MHA | 标准多头 | 表达力强 | 计算开销大 | Transformer、BERT |
| MQA | KV共享 | 内存省 | 表达下降 | GPT-4、PaLM |
| GQA | 分组共享 | 平衡性能 | 调参复杂 | LLaMA-2、Claude |
| MLA | 隐空间 | 复杂度低 | 初期训练慢 | Perceiver IO、CoAtNet |
| NSA | 局部敏感 | 线性推理 | 丢远距关系 | Swin Transformer |
| MoBA | MoE机制 | 超大模型 | 训练难 | Switch Transformer |
对比总结与演进趋势
| 机制 | 核心创新 | 适用场景 | 典型模型/平台 |
|---|---|---|---|
| MHA | 多头并行捕捉多维度特征 | 通用NLP任务 | BERT、GPT |
| MQA | 共享KV减少显存 | 实时推理 | 部分优化版LLM |
| GQA | 分组共享KV平衡效率与性能 | 平衡型推理 | LLaMA-2、ChatGLM2 |
| MLA | 低维潜在向量压缩KV缓存 | 资源受限长文本生成 | DeepSeek-V3 |
| MoBA | 块稀疏注意力+动态门控 | 超长文本处理 | Kimi(月之暗面) |
八、应用案例场景
- 自然语言处理:ChatGPT, Claude, Gemini → 使用 GQA、MQA 提升推理效率。
- 计算机视觉:Swin Transformer, Mask2Former → 使用 NSA 改进局部 Attention。
- 多模态学习:PaLI-3, Flamingo → MLA、MoBA 加速跨模态建模。
- 超大模型推理:GPT-4 Turbo → 广泛应用 MQA+MoBA 技术组合。
九、代码示例合集
1. MHA 代码(简化版 PyTorch)
import torch
import torch.nn as nnclass MultiHeadAttention(nn.Module):def __init__(self, d_model, n_heads):super().__init__()assert d_model % n_heads == 0self.d_k = d_model // n_headsself.n_heads = n_headsself.q_linear = nn.Linear(d_model, d_model)self.k_linear = nn.Linear(d_model, d_model)self.v_linear = nn.Linear(d_model, d_model)self.out = nn.Linear(d_model, d_model)def forward(self, q, k, v):bs = q.size(0)# Linear projectionsq = self.q_linear(q).view(bs, -1, self.n_heads, self.d_k)k = self.k_linear(k).view(bs, -1, self.n_heads, self.d_k)v = self.v_linear(v).view(bs, -1, self.n_heads, self.d_k)# Transpose for attention calculationq, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)scores = torch.matmul(q, k.transpose(-2, -1)) / self.d_k**0.5scores = torch.softmax(scores, dim=-1)output = torch.matmul(scores, v)# Concatenate headsoutput = output.transpose(1, 2).contiguous().view(bs, -1, self.n_heads * self.d_k)return self.out(output)
2. MQA 示例
# 类似上面,只是 Key/Value 只有一组
k = self.k_linear(k).mean(dim=2, keepdim=True)
v = self.v_linear(v).mean(dim=2, keepdim=True)
3. GQA 示例
# 分组处理 Key/Value
groups = 8 # 自定义组数
q_group = q.view(bs, groups, -1, self.d_k)
k_group = k.view(bs, groups, -1, self.d_k)
v_group = v.view(bs, groups, -1, self.d_k)
------------------------------------
class SelfAttention(torch.nn.Module):def __init__(self, config):super().__init__()self.multi_query_group_num = config.multi_query_group_num # 分组数(如2)self.projection_size = config.kv_channels * config.num_attention_heads# QKV线性变换(分组共享KV)self.qkv_hidden_size = self.projection_size + 2 * self.head_dim * self.multi_query_group_numself.query_key_value = nn.Linear(config.hidden_size, self.qkv_hidden_size)def forward(self, hidden_states):# 拆分Q、K、V(K/V按组共享)q, k, v = split_qkv_according_to_groups(...)# 计算分组注意力attn_output = compute_grouped_attention(q, k, v)return attn_output4. MLA 简单示例
# Latent tokens
latent = nn.Parameter(torch.randn(1, latent_tokens, d_model))
# Cross-attention: Query=latent, Key/Value=inputs
(更多完整版本可进一步扩展)
十、总结展望
注意力机制的演化,基本上遵循了效率优化和容量扩展两大主线:
- 小模型 → 更省内存推理(MQA、GQA)
- 大模型 → 更多表达力(MoBA、MLA)
- 计算提速 → 局部敏感(NSA)
- 显存优化:从MHA到MQA/GQA/MLA,逐步减少KV缓存占用;
- 计算效率:通过稀疏化(NSA、MoBA)降低复杂度;
- 动态适应性:无参数门控(MoBA)让模型自主选择注意力模式。
未来趋势可能是模块化、多尺度、专家化的混合使用,以适配不同的任务和场景需求。
部分参考