CogCoM: A Visual Language Model with Chain-of-Manipulations Reasoning 学习笔记
1 Motivation
当前 VLMs 通过对齐视觉输入和语言输出训练,虽然整体表现好,但在需要细致视觉推理的任务上容易出错,比如无法正确识别图片中的细节内容。这是因为现有模型习惯直接给出结论,而缺乏中间推理步骤。
人类解决视觉问题时,会逐步操作(比如圈出目标、放大细节区域),不是直接回答。
方法:Chain of Manipulations (CoM)
- 让模型自己一步步处理图像(比如:标注区域、放大、裁剪等),并在每一步输出中间结果(比如 bbox、生成局部图像)。
2 Method
2.1 基本操作
做了一个实验:
- 用 GPT-4 自动生成解决图像问题的步骤,允许它在需要时对图片做操作
- 处理了 170K 个 TextVQA 问题(需要细粒度视觉推理的数据集)
- 提供了4个手写示例给GPT-4作为指导,保证生成质量
- 然后用 StanfordCoreNLP 提取回答中的动词短语(表示操作动作)
通过频率统计,发现绝大多数动作可以归结为6种基本操作:
| 操作名称 | 功能描述 |
|---|---|
| OCR(tgt) → txt | 识别目标区域(tgt)的文字,输出文字(txt) |
| Grounding(tgt) → bbx | 找到目标(tgt)的定位框(bounding box) |
| Counting(tgt) → num | 数目标(tgt)的数量,输出数字(num) |
| Calculate(tgt) → num | 对目标(tgt)进行计算,输出数字(num) |
| CropZoomIn(bbx, x) → img | 按比例(x)放大或裁剪bbx区域,输出局部图片(img) |
| Line(pts) → img | 在图片上画线(连接指定的点pts),输出新的图像(img) |
2.2 数据收集
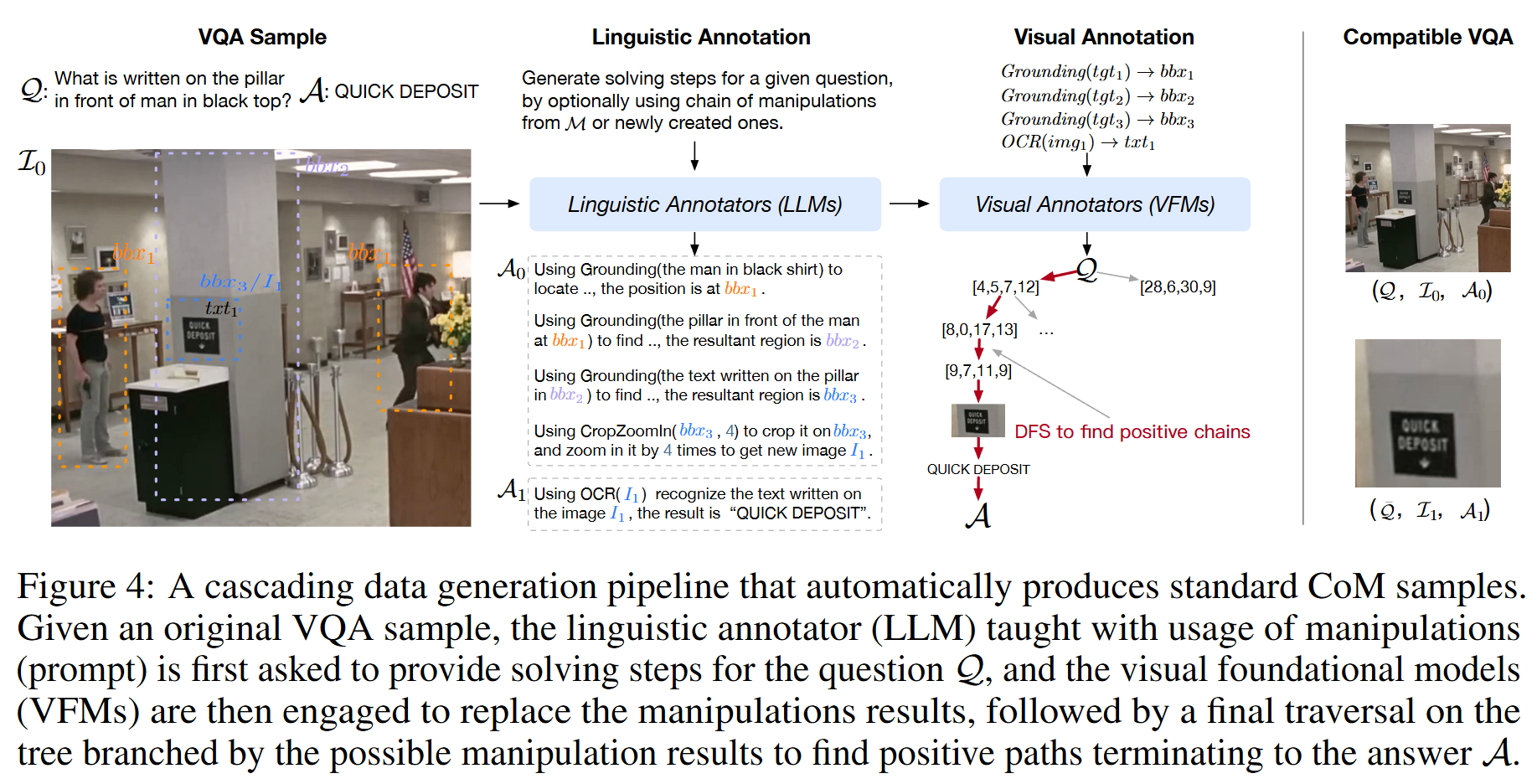
基于普通VQA数据集 {(I, Q, A)},自动生成标准的CoM样本(特别是数学问题领域再结合人工标注)
📌自动流程:
-
LLM 生成语言推理链:让 GPT-4 生成带操作的推理链(结果用变量占位)
-
VFM(GroundingDINO、PaddleOCR) 执行视觉操作补全结果
大部分操作都可以基于 Grounding 和 OCR 衍生:
- CropZoomIn → 基于 Grounding 的框来裁剪
- Counting → 基于检测的box数量
- Calculate → 基于OCR识别出的公式
-
DFS 搜索正向推理路径(最后得到正确答案A)
📌人工数据集:
图形数学题(如几何推理、图表阅读),需要更精准的辅助线绘制、公式推导。受启发于 AlphaGeometry,发现辅助线(或中间推理步骤)能显著帮助 LLMs 解复杂数学问题。招募了10位人类专家,手动完成:约 7K 高质量 CoM 数学样本
- 语言推理步骤
- 操作名称的使用
- 操作结果(图像或数值)
3 Model
3.1 ARCHITECTURE (模型架构)
整体框架采用 CogVLM 的通用VLM架构,包括四个核心组件:
- Visual Encoder:视觉编码器
- MLP Adapter:把视觉特征映射到语言空间
- LLM Backbone:大型语言模型骨干
- Visual Expert Module:视觉专家模块(深度融合视觉特征)
| 组件 | 使用的模型 | 说明 |
|---|---|---|
| Visual Encoder | EVA2-CLIP-E (4B参数) | 视觉特征提取 |
| LLM Backbone | Vicuna-7B-v1.5 | 语言理解与生成 |
| MLP Adapter | 两层 SwiGLU MLP | 映射视觉到语言空间 |
| Visual Expert Module | 加到 LLM 每层的注意力和 FFN 里 | 额外增加6.5B参数 |
整体规模大约 17B参数(7B + 4B + 6.5B)
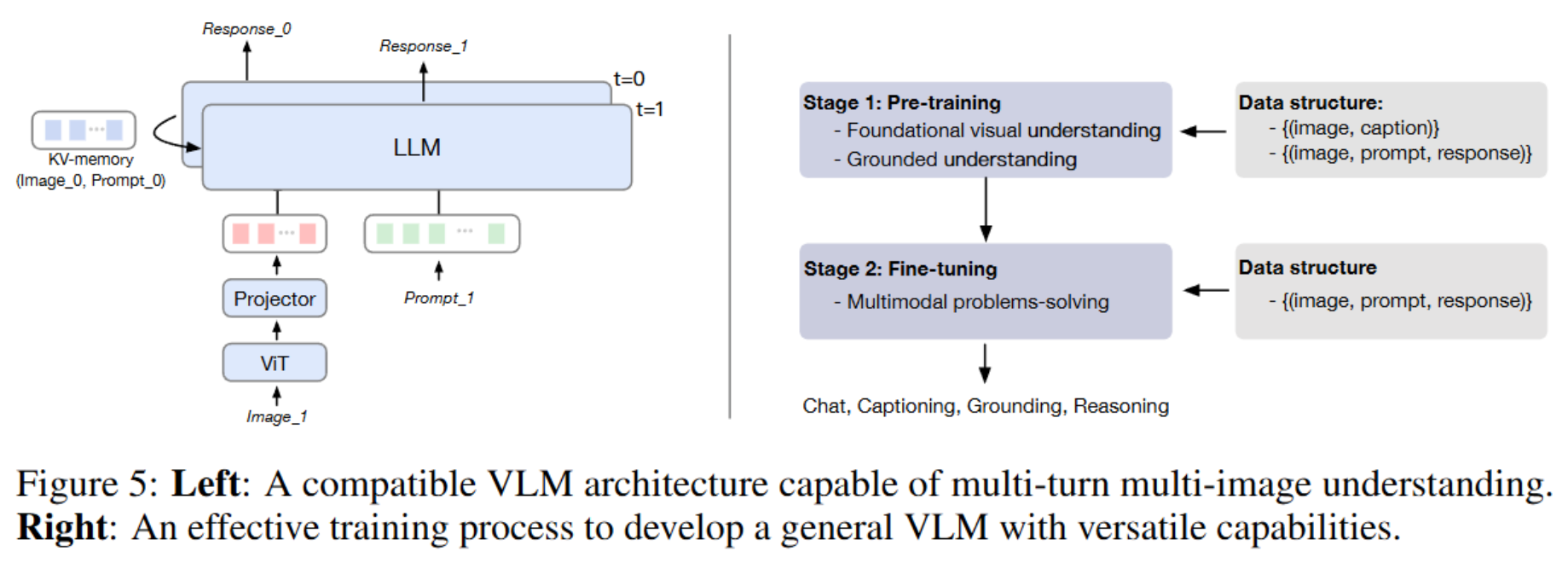
多轮推理机制(Memory-based Multi-turn Multi-image)?
- 支持处理多轮VQA样本: [ ( I t , Q t , A t ) ∣ t = 1 , 2 , . . . ] [(I_t, Q_t, A_t)|t = 1,2,...] [(It,Qt,At)∣t=1,2,...]
- KV缓存(Key-Value Memories)在每一层持续累积。
- 每轮 attention 计算公式(按累积KV):
att ( X ) = softmax ( Q t K t ′ T d ) V t ′ \text{att}(X) = \text{softmax}\left( \frac{Q_t K'_t{}^T}{\sqrt{d}} \right) V'_t att(X)=softmax(dQtKt′T)Vt′
3.2 Training
📌 第一阶段 Pre-Training
- 步骤一:视觉理解
- 数据:1.5B对图文对(清洗自 LAION-2B 和 COYO-700M)
- 训练:120K step,batch size 8192
- 步骤二:定位生成(Grounded Generation)
- 数据:40M条图像-问题-答案三元组(清洗自 LAION-115M)
- 训练:60K step,batch size 1024
- 答案中每个名词短语都配了位置坐标 [ [ x 0 , y 0 , x 1 , y 1 ] , . . . ] [[x0,y0,x1,y1],...] [[x0,y0,x1,y1],...]
这阶段主要训练的是视觉专家模块(6.5B参数)。
📌 第二阶段 Alignment
将CoM数据与其他三类数据混合训练:MultiInstruct(指令跟随能力)、LLaVAR(识别文本能力)、ShareGPT4V(细粒度描述能力)
总融合得到大约 570K条(I, Q, A)样本。
- 其中 CoM 样本是多轮式的答案(包含推理链)
- 对 CoM 样本,还会在问题前随机加触发prompt P M P_M PM,提示模型可以主动使用 manipulation 推理
训练:14K step,batch size 160,warm-up 280步,最高学习率 1 0 − 5 10^{-5} 10−5,然后线性下降。
这阶段也是只训练视觉专家模块(6.5B参数)
这阶段也是只训练视觉专家模块(6.5B参数)
我理解的 inference 过程,设输入如下:
图像:一张表格图片
Q:请问“销售额最高的月份”是哪一个?
- 理解任务类型:识别出这是一道“图表+文本识别+比较”的视觉问题;
- 判断需要信息获取:知道不能直接回答,需要先读取图表;
- 使用 manipulation:
- 先用 OCR 提取文本
- 再识别最大值
- 最后输出答案
确定当前情况是要做什么操作呢?
- CoM 数据中已经通过“多轮+操作序列”的方式示范如何一步步推理
- 多轮上下文累积(KV memory):保持上下文,让模型知道当前已做了什么、接下来该做什么;多轮结构下,模型具备上下文感知能力