ArcGIS arcpy代码工具——根据属性结构表创建shape图层
系列文章目录
ArcGIS arcpy代码工具——关于工具使用的软件环境说明
ArcGIS arcpy代码工具——批量对MXD文件的页面布局设置修改
ArcGIS arcpy代码工具——数据驱动工具批量导出MXD文档并同步导出图片
ArcGIS arcpy代码工具——将要素属性表字段及要素截图插入word模板
ArcGIS arcpy代码工具——定制属性表字段输出表格
ArcGIS arcpy代码工具——批量栅格转点文件导出属性表
ArcGIS arcpy代码工具——关于标识码的那些事(查找最大标识码、唯一性检查、重排序、空值赋值)
ArcGIS arcpy代码工具——批量要素裁剪栅格影像
文章目录
- 系列文章目录
- 功能说明
- 1 准备工作
- ==知识点:== 关于常见字段类型
- 2 代码分段
- (1) 设置工作空间
- (2) 新建图层
- 特别提醒:arcgis新建的图层要求至少有一个字段,系统会自动生成 ID 字段。
- (3) 读取属性结构表
- (4) 解析属性结构表
- (5) 创建字段
- 1. TEXT 文本型字段
- 2. SHORT 短整型、LONG 长整型字段
- 3. FLOAT 浮点型、DOUBLE 双精度型字段
- 4. 其他类型字段
- (6) 重命名图层
- (7) 删除多余字段
- 3 完整代码
- 4 后记
- 在arcgis软件中运行代码
功能说明
作为一个GISer,根据给定的图层属性结构表,创建shape图层是经常遇到的工作。一个图层里有各种字段类型、字段精度,小数位数要求,动辄甚至1个图层有30个字段,如果在GIS软件一个一个字段进行新建,那是非常繁琐和容易出错的。
本文旨在通过arcpy编程,读取本地属性结构表,自动创建shape图层。
本代码目标为:
- 1 准备属性结构表
- 2 编写代码,读取结构表
- 3 创建shape图层
我使用的arcgis软件版本为 10.8.2 版本。
温馨提示:如果觉得文章不错,请多多点赞添加关注,您的支持就是我的动力。
1 准备工作
首先第一步工作,就是准备txt格式(或者CSV格式,只要是逗号 分隔开就好)的属性结构表,一般新建图层的工作都是按照某个数据库标准执行,能找到电子版标准文件摘取最好,没有电子版就对照的标准录入,可以先录入到 Excel表格中,最后另存为CSV格式即可。
下面是我用于演示的属性结构表:

我保存的是 CSV格式,用逗号分隔,平时编辑的时候使用Excel打开方便分列查看。属性结构表中列出了常见的几种字段类型。
知识点: 关于常见字段类型
在 ArcGIS 中,图层的字段主要有以下几种类型:
-
文本型(String):用于存储字符数据,例如名称、地址、描述等。它可以包含字母、数字、符号等各种字符,长度可根据需要设置。
-
数值型:整型(Integer):用于存储整数,如人口数量、建筑物数量等。根据存储范围不同,又有不同的精度类型,如 16 位整数、32 位整数等。实践中,如果标准中字段类型为INT(int)并且字段长度>4时,arcgis中均视为 LONG长整形。long 包含 short 的 关系。
-
- 关于 整形(int)字段,细分为 short 类型(短整型) 和 long 类型(长整型),区别如下:
-
- short 类型:一般采用 16 位(2 字节)来存储数据。其取值范围是 -32,768 到 32,767,即 最大精度 4 位数,因为> 32767的五位数就是long长整形,
精度 5应该为 long。它仅适用于存储数值不大的整数。
- short 类型:一般采用 16 位(2 字节)来存储数据。其取值范围是 -32,768 到 32,767,即 最大精度 4 位数,因为> 32767的五位数就是long长整形,
-
- long 类型:通常用 32 位(4 字节)存储数据。取值范围为 -2,147,483,648 到 2,147,483,647,即 最大精度 10 位数。适用于需要存储较大整数的场景。
-
- 新建字段时,可以根据要求的字段长度选择 short 或者 long,长度超过 5 均为 long。不同类型涉及到存储空间大小不同,如果对存储空间要求不是那么在意都可以设为long(其实1条记录多一倍,上万条记录也不少,具体视数据量而定)。
-
数值型:浮点型(Float):用于存储 带有小数部分 的数字,适用于表示测量值、比例等,如海拔高度、面积、温度等。同样有不同的精度类型,如单精度(32 位)和双精度(64 位)。只有浮点型字段才能设置小数位数。
-
日期型(Date):用于存储日期和时间信息,格式通常为年 / 月 / 日 时:分: 秒。可以进行日期的计算、排序和筛选等操作。
-
二进制型(Binary):用于存储二进制数据,如图像、文档、音频或视频文件等。不过,直接在 ArcGIS 中处理二进制字段可能较为复杂,通常需要结合其他工具或编程语言来操作。
-
几何型(Geometry):用于存储地理要素的几何信息,如点、线、面等。这是 ArcGIS 中非常重要的一种字段类型,它定义了要素在地图上的位置和形状。
-
OID 型(Object ID):是一种特殊的整型字段,用于唯一标识图层中的每个要素。它在数据库中充当主键,不能被编辑,由系统自动生成和维护。
-
除 “OID” 和 “Shape” 字段之外,“要素类”和“表”还必须至少具有一个字段,默认会自动生成一个 名称 为 ID 的字段。一般情况下新建了其他字段后,ID字段就多余了,可删除之,否则提示多余字段。
2 代码分段
下面开始编写代码,把步骤分解一步一步来。
思路:设置工作空间——新建图层——读取属性结构表——解析结构表(字段类型、字段长度等)——根据不同字段类型创建字段
(1) 设置工作空间
工作空间,也就是 图层生成的文件夹,给代码定位在这里工作。
如果新建的是 shape图层文件,则工作空间设置为文件夹;
//设置工作空间 文件夹
arcpy.env.workspace = r"D:\mulu\tc"
如果新建的是地理数据库中的图层,则工作空间设置为mdb或者gdb的地理数据库。
//设置工作空间 地理数据库
arcpy.env.workspace = r"D:\mulu\tc\test.mdb"
注意: 这两种方式,新建图层的字段,结果是有区别的。后面细说。
(2) 新建图层
shape的要素类型主要有 点、线、面型,首先定义类型,再定义坐标系统。
我准备新建的图层为XZQ,是面型。投影坐标系 CGCS2000 40 度分带。
// 定义新Shapefile的名称和要素类型
output_shapefile = "XZQ" + ".shp" # 可以是 带后缀名的shapefile 也可以是不带后缀名的数据库图层
geometry_type = "POLYGON" # 面型
# geometry_type = "POLYLINE" # 线型
# geometry_type = "POINT" # 点型// 创建新的Shapefile
arcpy.CreateFeatureclass_management(arcpy.env.workspace, output_shapefile, geometry_type)// 设置投影坐标系统 为 CGCS2000 40 度分带
cgcs2000_40 = arcpy.SpatialReference(4528) # CGCS2000 / 高斯投影 3-degree Gauss-Kruger zone 40
arcpy.DefineProjection_management(output_shapefile, cgcs2000_40)坐标系统分为地理坐标系和投影坐标系, 注意标准的要求。
-
常用的地理坐标系和WKID:
地理坐标 4214 GCS_Beijing_1954;
地理坐标 4326 GCS_WGS_1984;
地理坐标 4490 GCS_China_Geodetic_Coordinate_System_2000;
地理坐标 4555 GCS_New_Beijing;
地理坐标 4610 GCS_Xian_1980. -
常用的投影坐标系和WKID:
投影坐标 2364 Xian_1980 3度分带 40度带;
投影坐标 4528 CGCS2000 3度分带 40度带;
投影坐标 4529 CGCS2000 3度分带 41度带。
特别提醒:arcgis新建的图层要求至少有一个字段,系统会自动生成 ID 字段。

(3) 读取属性结构表
读取属性结构表,先判定一下文件是否存在。首行为字段标题行,需要跳过。
// 读取CSV文件中的字段信息
csv_file = r"D:\MULU\tc\aa.csv"
if not os.path.exists(csv_file):print("文件不存在: {}.".format(csv_file))
else:with open(csv_file, 'r') as SXB:reader = csv.reader(SXB)next(reader) # 跳过标题行
(4) 解析属性结构表
在解析过程中,首先判定的应该是字段类型是否符合arcgis的要求。
给定一个符合要求的字段类型集合进行判定。
// 支持的字段类型
valid_field_types = ["TEXT", "FLOAT", "DOUBLE", "SHORT", "LONG", "DATE", "BLOB", "RASTER", "GUID"]
我编制的属性结构表,结构为:字段别名、字段名称、字段类型、字段长度、小数位数。
按照这个顺序解析字段,存储值。
// 解析属性表,按 列 读取for row in reader:fieldalias = row[0] # 字段别名fieldname = row[1] # 字段名称fieldtype = row[2].upper() # 字段类型,强制转换为大写fieldprecision = row[3] # 字段长度,字段精度
从支持的字段类型集合中可以看到,并没有 int 整形,故如果属性结构表中有 int需要按照字段精度修改为 SHORT 或 LONG。
实践中,如果 int 的精度 ≤4,arcgis生成的是 SHORT 短整型字段。

实践中,因为大于 32767的五位数就是LONG长整形,如果字段精度是 ≥ 5 则会生成 LONG 长整形字段。LONG 包含 SHORT 的 关系。

// 根据精度判定 int ,修改为 short 或者 long# 如果字段类型为 'INT',替换为 'LONG'或者 shortif fieldtype in ["INT", "INTEGER"]:if fieldprecision and fieldprecision.isdigit() and int(fieldprecision) <= 4:fieldtype = "SHORT"else:fieldtype = "LONG"
关于小数位数,只有 FLOAT 浮点型, DOUBLE 双精度型,才有小数位数,故 fieldscale 并不是每个字段类型都有值。
// 小数位数fieldscale = int(row[4]) if len(row) > 4 and row[4].isdigit() else None # 小数位数
最后,判定一下,字段类型 是否有效,如果存在无效字段,则跳过该字段,继续下一个字段。
//检查字段类型是否有效if fieldtype not in valid_field_types:print("字段类型无效: {},跳过字段: {}".format(fieldtype, fieldname))continue
(5) 创建字段
在 ArcGIS 中,创建 字段 时,可以通过 arcpy.AddField_management 方法的,各类型的字段创建参数有所差异。
下面分字段类型看一下代码:正常情况需要对 字段长度等验证为非空,但是在编制属性结构表阶段就保证了数据的完整性,故代码中不再验证。
1. TEXT 文本型字段
要求字段长度 field_length 为 >0的数字。
// 添加字段到新的Shapefileif fieldtype.upper() == "TEXT":# 对于文本型字段,设置 field_lengtharcpy.AddField_management(output_shapefile,fieldname,fieldtype,field_length=int(fieldprecision),field_alias=fieldalias)
2. SHORT 短整型、LONG 长整型字段
要求字段精度(等效于字段长度) field_precision 为 >0的数字。
elif fieldtype in ["LONG", "SHORT"]:# 对于整型字段,设置 field_precisionarcpy.AddField_management(output_shapefile,fieldname,fieldtype,field_precision=int(fieldprecision),field_alias=fieldalias)
3. FLOAT 浮点型、DOUBLE 双精度型字段
要求字段精度(等效于字段长度) field_precision 为 >0的数字。
增加有 小数位数 field_scale 属性为 ≥ 0 的数字。
elif fieldtype in ["FLOAT", "DOUBLE"]:# 对于浮点类型字段,设置 field_precision 和 field_scalearcpy.AddField_management(output_shapefile,fieldname,fieldtype,field_precision=int(fieldprecision),field_scale=fieldscale,field_alias=fieldalias)
4. 其他类型字段
其他类型字段,如 DATE ,无需字段精度 、小数位数 属性,arcgis固定的字段格式。
else:# 对于其他类型的字段,不传递 field_precision 和 field_scalearcpy.AddField_management(output_shapefile,fieldname,fieldtype,field_alias=fieldalias)
特别说明:
- 关于字段别名 field_alias,在 shape层中 创建字段时,即使设置了 字段别名属性,如 field_alias =“行政区” ,但是在创建字段完成后,字段别名的属性值会丢失,字段别名 等于默认值 字段名称 XZQ。
- 但是 ,在 地理数据库 中新建层中创建字段,如 field_alias =“行政区” ,字段别名会 成功保留属性值 “行政区”。
- 如果将 地理数据库 中的 带 字段别名值的 图层,导出到 shape层文件,你会发现原来的字段别名值 丢失了,又变成了 默认值 字段名称 XZQ。
- 关于浮点型 双精度 的 字段精度 和小数位数,只有在 shape层 中才有意义,在 地理数据库 中无意义,但存储的值仍符合字段类型要求。
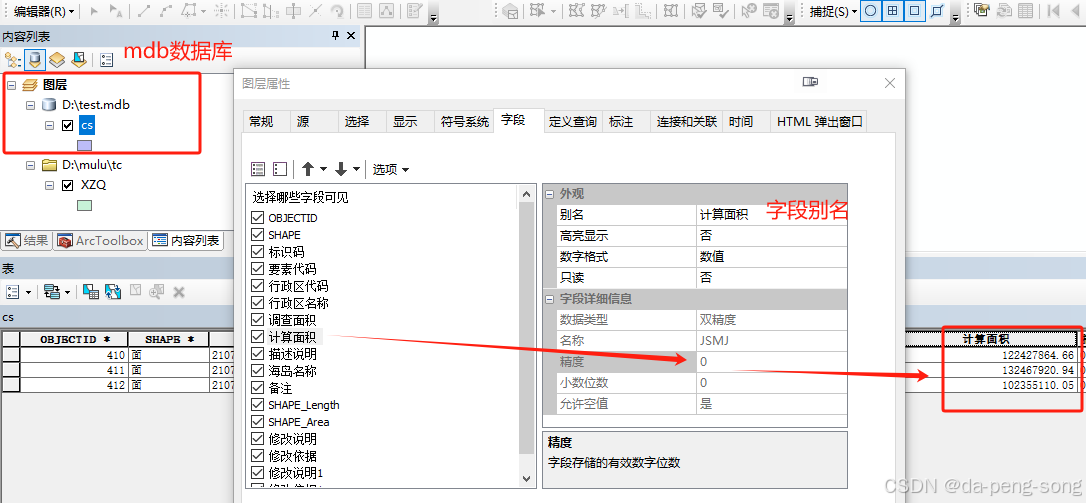
- 如果 你 将 设置好字段属性的 shape层文件,导入到 地理数据库中,你会发现,浮点型 双精度的精度和 小数位数同样失效了。跟上图一样 变为 0,但不影响该字段的数据存储。这个时候,即使你再 导出为 shape图层文件,字段精度和 小数位数依然无法恢复了。
- 把 shape层 导入 mdb等地理数据库中进行编辑和管理,再导出为shape层文件作为最终成果提交的格式,这种操作非常 常见,但是再通过质检软件检查的时候,容易提示 字段类型不符。修正很简单,在 shape层上重新创建标准字段 把原来的值赋值回来就可以了。
(6) 重命名图层
各种标准或者某个成果提交要求中,对shape层的命名规则 ,如 “6位行政区代码”数字+ “XZQ”诸如此类,在arcgis的图层命名规则中不允许数字或特殊符号作为图层名称首字符。
在创建新图层的时候,不能够一步到位的直接命名图层,需要在最后阶段对shape层进行重命名 ,给图层名称增加 前缀。
// 重命名图层,在名称前缀增加“(111111)”
Add_prefix = "(111111)"
if Add_prefix:new_shapefile_name = str(Add_prefix) + output_shapefilearcpy.Rename_management(output_shapefile, new_shapefile_name)
else:new_shapefile_name = output_shapefile
如果没有重命名 这一步,把 Add_prefix 赋值为空即可。
Add_prefix = ""
......
(7) 删除多余字段
前面也说了,在新建shape图层文件的时候,自动添加 了一个字段 ID,因为图层已经添加了其他字段,这个 ID字段已经没有用处了。需要删除。
// 删除 new_shapefile_name 图层中的 id 字段
arcpy.DeleteField_management(new_shapefile_name, "id")
3 完整代码
下面列出完整代码,代码经测试成功运行,实现按照属性结构表创建图层的功能。
# coding=utf-8
import arcpy
import csv
import os# 在 ArcGIS 中,创建 Shapefile 时,可以通过 arcpy.AddField_management 方法的
# 字段别名 ,只能在 地类数据库中设置,如果是新建shape层会失败
# field_precision 和 field_scale 参数设置双精度字段的位数和小数位数。# 设置工作空间
arcpy.env.workspace = r"D:\mulu\tc"# 定义新Shapefile的名称和要素类型
output_shapefile = "XZQ" + ".shp" # 可以是 带后缀名的shapefile 也可以是不带后缀名的数据库图层
geometry_type = "POLYGON"
# geometry_type = "POLYLINE"
# geometry_type = "POINT"# 创建新的Shapefile
arcpy.CreateFeatureclass_management(arcpy.env.workspace, output_shapefile, geometry_type)# 设置坐标系统为 CGCS2000 40 度分带
# cgcs2000_40 = arcpy.SpatialReference(4490) # CGCS2000 / 大地坐标系 2000
cgcs2000_40 = arcpy.SpatialReference(4528) # CGCS2000 / 高斯投影 3-degree Gauss-Kruger zone 40
arcpy.DefineProjection_management(output_shapefile, cgcs2000_40)# 支持的字段类型
valid_field_types = ["TEXT", "FLOAT", "DOUBLE", "SHORT", "LONG", "DATE", "BLOB", "RASTER", "GUID"]# 读取CSV文件中的字段信息
csv_file = r"D:\MULU\tc\aa.csv"
if not os.path.exists(csv_file):print("文件不存在: {}.".format(csv_file))
else:with open(csv_file, 'r') as SXB:reader = csv.reader(SXB)next(reader) # 跳过标题行for row in reader:fieldalias = row[0] # 字段别名fieldname = row[1] # 字段名称fieldtype = row[2].upper() # 字段类型,强制转换为大写fieldprecision = row[3] # 字段长度,字段精度# 如果字段类型为 'INT',替换为 'LONG'或者 shortif fieldtype in ["INT", "INTEGER"]:if fieldprecision and fieldprecision.isdigit() and int(fieldprecision) <= 4:fieldtype = "SHORT"else:fieldtype = "LONG"fieldscale = int(row[4]) if len(row) > 4 and row[4].isdigit() else None # 小数位数# 检查字段类型是否有效if fieldtype not in valid_field_types:print("字段类型无效: {},跳过字段: {}".format(fieldtype, fieldname))continue# 添加字段到新的Shapefileif fieldtype.upper() == "TEXT":# 对于文本型字段,设置 field_lengtharcpy.AddField_management(output_shapefile,fieldname,fieldtype,field_length=int(fieldprecision),field_alias=fieldalias)elif fieldtype in ["LONG", "SHORT"]:# 对于整型字段,设置 field_precisionarcpy.AddField_management(output_shapefile,fieldname,fieldtype,field_precision=int(fieldprecision),field_alias=fieldalias)elif fieldtype in ["FLOAT", "DOUBLE"]:# 对于浮点类型字段,设置 field_precision 和 field_scalearcpy.AddField_management(output_shapefile,fieldname,fieldtype,field_precision=int(fieldprecision),field_scale=fieldscale,field_alias=fieldalias)else:# 对于其他类型的字段,不传递 field_precision 和 field_scalearcpy.AddField_management(output_shapefile,fieldname,fieldtype,field_alias=fieldalias)print("新图层已创建并添加字段。")# 重命名图层,在名称前缀增加“(111111)”
Add_prefix = ""
if Add_prefix:new_shapefile_name = str(Add_prefix) + output_shapefilearcpy.Rename_management(output_shapefile, new_shapefile_name)
else:new_shapefile_name = output_shapefile# 删除 new_shapefile_name 图层中的 id 字段
arcpy.DeleteField_management(new_shapefile_name, "id")看一下运行的效果如何,
4 后记
日常工作中,创建图层的工作非常多,使用代码编程创建,不仅效率高,而且错误更少。推荐朋友们使用.
有朋友就为难了,电脑没有 python环境和编辑软件怎么办?这么好的功能我也想用。没问题,满足。
如果你的电脑安装了 arcgis软件 ,那么你 的电脑中同时也安装了 python2.7版环境,arcgis软件中有个 Python窗口,可以运行python代码。
在arcgis软件中运行代码
操作方法如下:
- 新建1个空白的txt文本文档;
- 把完整代码全选,复制粘贴到 空白的 txt文本文档中;
- 编辑代码,把所有的 注释内容 #… 都删除干净,反复检查没有遗漏 # 为止;
- 首行 “# coding=utf-8“ 也删除不要。
- 把代码中的参数行 ,修改为你自己的 数据,注意 符号均为英文状态的符号
-
- 储存目录 arcpy.env.workspace
-
- 图层名称 output_shapefile
-
- 图层类型 geometry_type
-
- 坐标系代码 cgcs2000_40
-
- 属性代码表 csv_file
-
- 重命名前缀 Add_prefix
- 再次检查代码,确认上述参数都已经修改为自己的值。
- 打开arcgis软件的 Python窗口,全选复制代码粘贴到 Python窗口中
- 检查代码状态,每一样前面都有 三个点 。。。,颜色均为黑色状态,不能有浅灰色的代码行
- 回车键 Enter 2次,开始运行
- 观察运行状态,注意查看Python窗口中的提示信息,是否有错误提示
- 运行结束,检查图层属性。
下面看一下完整的运行过程。祝你成功!SYQ
我还编写了arcgis的工具插件,采用窗口化来创建图层,更加的简便,有需要的可以去下载,插件地址如下:根据属性结构表新建shape图层

如果觉得文章不错,请多多点赞添加关注,您的支持就是我的动力。