Transformer系列(三):编码器—解码器架构
Transformer架构
- 一、多头自注意力 (Multi-head self-attention)
- 将矩阵维度从d降到d/k的优点
- 二、层归一化 (Lary Norm)
- 三、残差连接 (Residual Connections)
- Add and Norm
- 四、注意力对数几率缩放 (Attention logit scaling)
- 五、Transformer 编码器(Encoder)
- 六、Transformer 解码器 (Decoder)
- 七、Transformer完整架构(Encoder-decoder)
- 交叉注意力 (Cross-attention)
之前的两篇博客分别讲了 为什么自然语言处理要弃用循环神经网络架构以及 自注意力机制,这篇博客将为大家来详细介绍大家所熟知的Transformer架构。
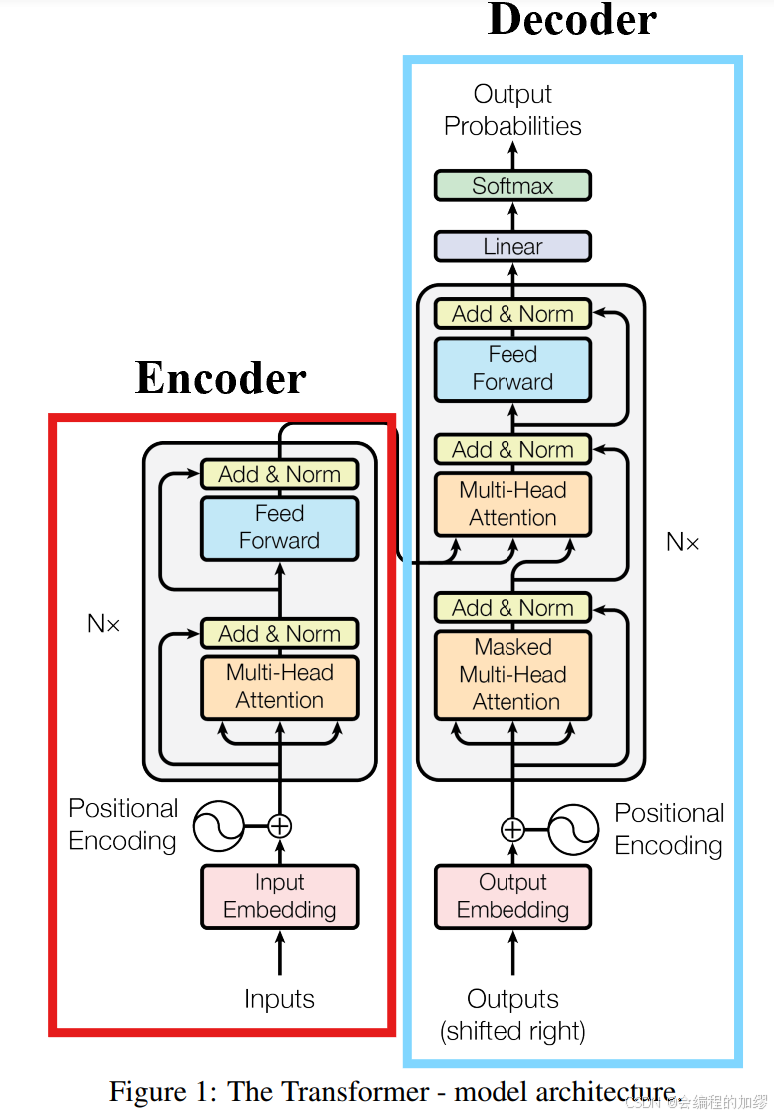
Transformer是一种基于自注意力机制的架构,由多个堆叠的模块组成,每个模块都包含自注意力层和前馈神经网络层,以及一些我们即将讨论的其他组件。如果你想先有个直观的了解,下图展示了Transformer语言模型的架构图。目前尚未介绍的组件有多头自注意力机制、层归一化、残差连接和注意力得分缩放——当然,我们将讨论这些组件是如何组合形成Transformer架构的。
一、多头自注意力 (Multi-head self-attention)
直观地说,单次调用自注意力机制最擅长从输入值集中挑选出单个值。它通过对所有值求平均来实现这一 “软选择” (softly select),但为了精确地对两个或更多事物进行平均,需要在键-查询点积计算中进行权衡。现在我们要介绍的多头自注意力机制,直观来讲,是同时多次应用自注意力机制,每次对相同的输入进行不同的键、查询和值变换,然后将输出结果进行组合。
对于整数个注意力头 k k k,我们为 ℓ ∈ { 1 , … , k } \ell \in \{1, \ldots, k\} ℓ∈{1,…,k} 定义矩阵 K ( ℓ ) , Q ( ℓ ) , V ( ℓ ) ∈ R d × d / k \mathbf{K}^{(\ell)}, \mathbf{Q}^{(\ell)}, \mathbf{V}^{(\ell)} \in \mathbb{R}^{d\times d/k} K(ℓ),Q(ℓ),V(ℓ)∈Rd×d/k(我们很快就会明白为什么要将维度降至 d/k)。这些是每个注意力头的键矩阵、查询矩阵和值矩阵。相应地,和单头自注意力机制一样,我们可以得到键、查询和值 k 1 : n ( ℓ ) , q 1 : n ( ℓ ) , v 1 : n ( ℓ ) \mathbf{k}_{1:n}^{(\ell)}, \mathbf{q}_{1:n}^{(\ell)}, \mathbf{v}_{1:n}^{(\ell)} k1:n(ℓ),q1:n(ℓ),v1:n(ℓ)。 然后,我们对每个头执行自注意力计算: h i ( ℓ ) = ∑ j = 1 n α i j ( ℓ ) v j ( ℓ ) (1) h_{i}^{(\ell)}=\sum_{j = 1}^{n}\alpha_{ij}^{(\ell)}v_{j}^{(\ell)} \tag{1} hi(ℓ)=j=1∑nαij(ℓ)vj(ℓ)(1) α i j ( ℓ ) = exp ( q i ( ℓ ) ⊤ k j ( ℓ ) ) ∑ j ′ = 1 n exp ( q i ( ℓ ) ⊤ k j ′ ( ℓ ) ) (2) \alpha_{ij}^{(\ell)}=\frac{\exp\left(q_{i}^{(\ell)\top}k_{j}^{(\ell)}\right)}{\sum_{j' = 1}^{n}\exp\left(q_{i}^{(\ell)\top}k_{j'}^{(\ell)}\right)} \tag{2} αij(ℓ)=∑j′=1nexp(qi(ℓ)⊤kj′(ℓ))exp(qi(ℓ)⊤kj(ℓ))(2)
请注意,每个头的输出 h i ( ℓ ) h_{i}^{(\ell)} hi(ℓ)的维度被降为 d / k d/k d/k(因为有k个头,将每一个头的输出降维方便后面加权)。 最后,我们将多头自注意力的输出定义为各个头输出连接后的线性变换。设 O ∈ R d × d O \in \mathbb{R}^{d×d} O∈Rd×d,则有: h i = O [ v i ( 1 ) ; ⋯ ; v i ( k ) ] (3) h_{i} = O\left[\mathbf{v}_{i}^{(1)} ; \cdots ; \mathbf{v}_{i}^{(k)}\right] \tag{3} hi=O[vi(1);⋯;vi(k)](3) 其中,我们将每个维度为 d × d / k d×d/k d×d/k的头输出沿着它们的第二维进行连接,这样连接后的维度为 d × d d×d d×d。
将矩阵维度从d降到d/k的优点
为了理解为什么每个头的输出维度会降低,深入了解多头自注意力在代码中的实现方式很有帮助。在实践中,由于我们应用的变换具有低秩特性,多头自注意力的计算成本并不比单头自注意力高。
对于单个注意力头,回想一下, x 1 : n x_{1:n} x1:n是一个 R n × d \mathbb{R}^{n\times d} Rn×d的矩阵。那么我们可以将值向量计算为矩阵形式 x 1 : n V x_{1:n}V x1:nV,同样地,键和查询分别为 x 1 : n K x_{1:n}K x1:nK和 x 1 : n Q x_{1:n}Q x1:nQ,它们都是 R n × d \mathbb{R}^{n\times d} Rn×d的矩阵。为了计算自注意力,我们可以通过矩阵运算来计算权重: α = softmax ( x 1 : n Q K ⊤ x 1 : n ⊤ ) ∈ R n × n (4) \alpha = \text{softmax}(x_{1:n}QK^{\top}x_{1:n}^{\top}) \in \mathbb{R}^{n\times n} \tag{4} α=softmax(x1:nQK⊤x1:n⊤)∈Rn×n(4) 然后通过以下方式对所有 x 1 : n x_{1:n} x1:n计算自注意力操作: h 1 : n = softmax ( x 1 : n Q K ⊤ x 1 : n ⊤ ) x 1 : n V ∈ R n × d (5) h_{1:n} = \text{softmax}(x_{1:n}QK^{\top}x_{1:n}^{\top})x_{1:n}V \in \mathbb{R}^{n\times d} \tag{5} h1:n=softmax(x1:nQK⊤x1:n⊤)x1:nV∈Rn×d(5)
这里有一张展示矩阵运算的图表:
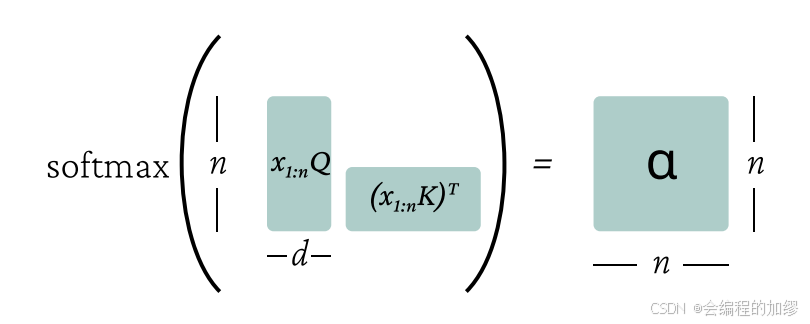
⭐ 当我们以这种矩阵形式执行多头自注意力计算时,我们首先将 x 1 : n Q x_{1:n}Q x1:nQ、 x 1 : n K x_{1:n}K x1:nK和 x 1 : n V x_{1:n}V x1:nV分别重塑为形状为 R n , k , d / k \mathbb{R}^{n,k,d/k} Rn,k,d/k的矩阵,将模型维度拆分为两个轴 d → ( k , d / k ) d \to (k, d/k) d→(k,d/k),分别对应注意力头的数量和每个头的维度数量。然后,我们可以将这些矩阵转置为 R k , n , d / k \mathbb{R}^{k, n, d / k} Rk,n,d/k的形状,直观来看,这就像是 k k k个长度为 n n n、维度为 d / k d/k d/k的序列。这使我们能够跨注意力头并行执行批量softmax操作,将注意力头的数量当作一种批量轴(实际上,在实践中我们还会有一个单独的批量轴)。所以,总的计算量(除了最后用于组合各注意力头输出的线性变换)是相同的,只是分散到了(每个低秩的)注意力头上。这里有一个类似于单头注意力机制的图表,展示了多头注意力操作最终与单头操作有多么相似:
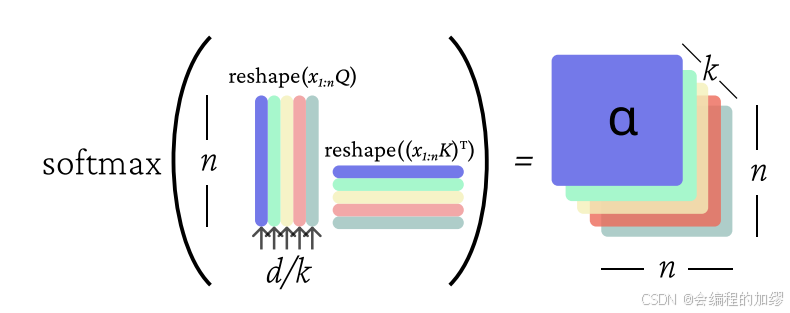
二、层归一化 (Lary Norm)
Transformer中一个重要的学习辅助手段是层归一化(Ba等人,2016)。层归一化的目的是减少某一层激活值中无信息的变化,为下一层提供更稳定的输入。进一步的研究表明,层归一化的最大作用可能不在于对前向传播进行归一化,而实际上是在反向传播中改善梯度(Xu等人,2019)。关于层归一化的介绍在另一篇博客:Transformer without normalization中有提到。
为此,层归一化会执行以下操作:
(1)计算某一层激活值的统计信息,以估计激活值的均值和方差;
(2)根据这些估计值对激活值进行归一化;
(3)(可选地)学习(作为参数)一个逐元素的加性偏差和乘性增益,通过它们以可预测的方式对激活值进行某种程度的反归一化。
第三部分似乎并非关键,甚至可能有害(Xu等人,2019),因此我们在介绍中省略了这部分内容。
在理解层归一化(layer norm)如何影响网络时,有一个问题是:“对什么进行统计计算?” 也就是说,什么构成了一个 “层”?在Transformer中,答案始终是,针对序列长度中的单个索引(以及批次中的单个样本)独立计算统计信息,并在d个隐藏维度上共享这些统计信息。换句话说,索引为i的标记的统计信息不会影响索引为 j ≠ i j≠i j=i 的标记。所以,对于单个索引 i ∈ { 1 , … , n } i\in\{1,\ldots,n\} i∈{1,…,n},我们计算统计量的方式如下: μ ^ i = 1 d ∑ j = 1 d h i j \hat{\mu}_{i}=\frac{1}{d}\sum_{j = 1}^{d}h_{ij} μ^i=d1j=1∑dhij σ ^ i = 1 d ∑ j = 1 d ( h i j − μ i ) 2 (6) \hat{\sigma}_{i}=\sqrt{\frac{1}{d}\sum_{j = 1}^{d}(h_{ij}-\mu_{i})^{2}} \tag{6} σ^i=d1j=1∑d(hij−μi)2(6)
通过上面的方式,计算数据的均值与方差。这里(提醒一下), μ ^ i \hat{\mu}_{i} μ^i和 σ ^ i \hat{\sigma}_{i} σ^i是标量,我们按如下公式计算层归一化: L N ( h i ) = h i − μ ^ i σ ^ i (7) LN(h_{i}) = \frac{h_{i} - \hat{\mu}_{i}}{\hat{\sigma}_{i}} \tag{7} LN(hi)=σ^ihi−μ^i(7) 其中,我们将 μ ^ i \hat{\mu}_{i} μ^i和 σ ^ i \hat{\sigma}_{i} σ^i在 h i h_{i} hi的 d d d个维度上进行了广播。一般来说,层归一化是深度学习工具库中的一个非常有用的工具。
💡 这里可以看到层归一化进行归一化的是自注意力操作的输出 h i h_{i} hi,而不是单个的数据量 x i x_{i} xi
三、残差连接 (Residual Connections)
⭐ 残差连接就是简单地将一层的输入加到该层的输出上: f r e s i d u a l ( h 1 : n ) = f ( h 1 : n ) + h 1 : n (8) f_{residual}(h_{1:n}) = f(h_{1:n}) + h_{1:n} \tag{8} fresidual(h1:n)=f(h1:n)+h1:n(8)其背后的原理是:
(1)恒等函数的梯度流很好(其局部梯度处处为1!),所以这种连接方式有助于学习更深的网络;
(2)学习一个函数与恒等函数的差异,比从头开始学习这个函数要更容易。
尽管这些看起来很简单,但它们在深度学习中非常有用,并不只是在Transformer架构中!
Add and Norm
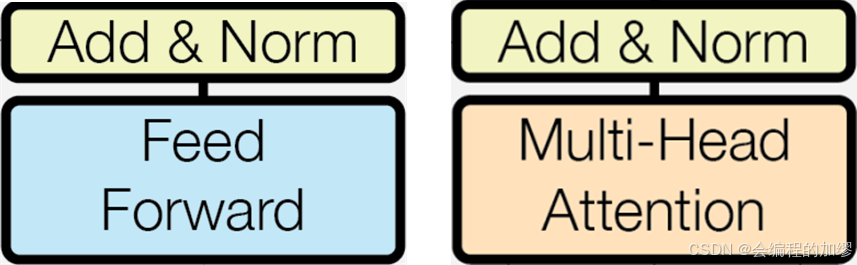
层归一化和残差连接组合:在可以看到的Transformer架构图中,层归一化和残差连接的应用常常在一个标有“Add & Norm”的单个可视化模块中组合在一起。这样的一层可能如下所示:
h p r e − n o r m = f ( L N ( h ) ) + h (9) h_{pre-norm } = f(LN(h)) + h \tag{9} hpre−norm=f(LN(h))+h(9)
其中, f f f 是一个前馈操作或者是一个自注意力操作(这被称为预归一化),
或者像这样:
h p o s t − n o r m = L N ( f ( h ) + h ) (10) h_{post-norm } = LN(f(h) + h) \tag{10} hpost−norm=LN(f(h)+h)(10)这被称为后归一化。事实证明,预归一化的梯度在初始化时表现要好得多,从而使得训练速度快得多(xiong等人,2020)。
四、注意力对数几率缩放 (Attention logit scaling)
在[Vaswani等人,2017]中引入的另一个技巧,他们称之为缩放点积注意力。点积这一部分来自我们正在计算的查询与键的点积 q i ⊤ k j q_{i}^{\top}k_{j} qi⊤kj。缩放的原理是,当我们进行点积运算的向量维度 d d d变大时,即使是随机向量的点积(例如,在初始化时)也大致会随着 d \sqrt{d} d增长。所以,我们用 d \sqrt{d} d来对这些点积进行归一化,以阻止这种缩放情况:
α = softmax ( x 1 : n Q K ⊤ x 1 : n ⊤ d ) ∈ R n × n (11) \alpha = \text{softmax}\left(\frac{x_{1:n}QK^{\top}x_{1:n}^{\top}}{\sqrt{d}}\right) \in \mathbb{R}^{n \times n} \tag{11} α=softmax(dx1:nQK⊤x1:n⊤)∈Rn×n(11)
五、Transformer 编码器(Encoder)
一个Transformer编码器接收单个序列 w 1 : n w_{1:n} w1:n,并且不进行未来位置的掩码操作。它使用嵌入矩阵 E E E对该序列进行嵌入得到 x 1 : n x_{1:n} x1:n,并添加位置表示 P P P,然后应用一叠相互独立参数化的编码器模块。
每个编码器模块由两部分组成:
(1)多头注意力机制和“归一化层与残差连接”操作;
(2)前馈神经网络和“归一化层与残差连接”操作。
因此,每个模块的输出会作为下一个模块的输入。下图展示了这一过程。
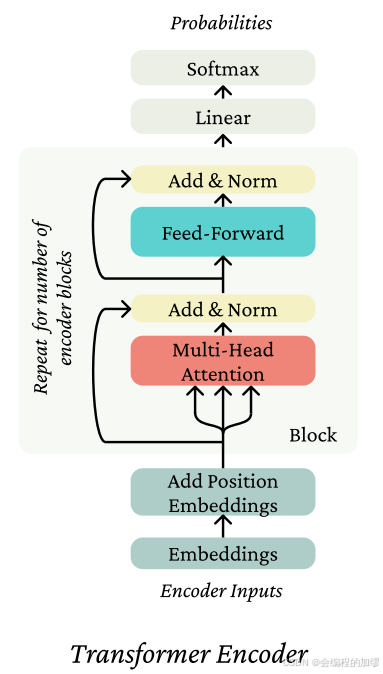
在希望从Transformer编码器的标记中得出概率的情况下(就像在BERT的掩码语言建模中那样[Devlin等人,2019]),需要先对输出空间应用一个线性变换,然后再进行softmax操作。Transformer编码器的用途。Transformer编码器在以下情境中非常适用:当你并非试图以自回归的方式生成文本时(编码器中不存在屏蔽操作,因此每个位置索引都能够看到整个序列),并且你希望得到整个序列的强大表示(同样,这是可行的,因为在构建自身表示时,即使是第一个标记也能够看到序列后续的全部内容)。
💡 也就是说,编码器没有设置未来掩码,可以帮助模型看到当前序列的上下文位置。 |
六、Transformer 解码器 (Decoder)
要构建一个Transformer自回归语言模型,需要使用Transformer解码器。Transformer解码器与Transformer编码器的不同之处仅在于,在每次应用自注意力机制时都使用了未来位置屏蔽。这确保了信息约束(不能通过偷看未来的信息来作弊!)在整个架构中都得以保持。我们在图4中展示了这种架构的示意图。这类模型的著名例子有GPT-2(Radford等人,2019年)、GPT-3(Brown等人,2020年)以及BLOOM(Workshop等人,2022年)。
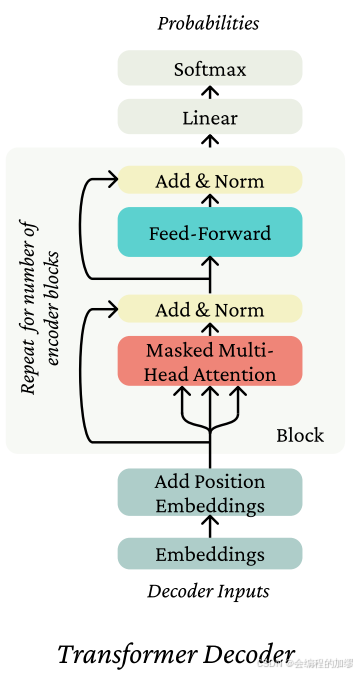
⭐ 补充:先前提到了仅编码器架构(Encoder-only)的语言模型和仅解码器架构(Decoder-only)的语言模型,具体区别如下:
| 架构类型 | 说明 | 代表模型 |
|---|---|---|
| Encoder-Only | 编码器负责将输入数据转换为上下文表示,但不生成输出序列。这种架构通常用于理解型任务 | BERT |
| Decoder-Only | 解码器专注于生成任务,从输入的编码中生成相应的输出序列。这种架构因其简洁高效而成为当前主流 | GPT系列 |
七、Transformer完整架构(Encoder-decoder)
一个Transformer编码器-解码器接收两个序列作为输入。下图展示了整个编码器-解码器的结构。
第一个序列 x 1 : n x_{1:n} x1:n会通过一个Transformer编码器来构建上下文表示。
第二个序列 y 1 : m y_{1:m} y1:m则通过一个经过修改的Transformer解码器架构进行编码,在这个架构中,会从 y 1 : m y_{1:m} y1:m的编码表示对编码器的输出应用交叉注意力机制(我们还未定义这个概念!)。
所以,让我们先稍微绕一下来讨论交叉注意力机制;它与我们已经了解的内容并没有太大的不同。
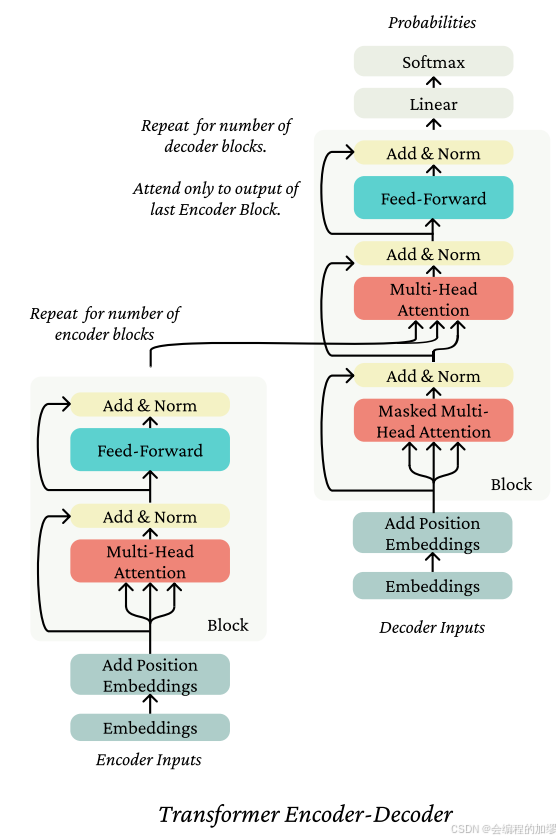
交叉注意力 (Cross-attention)
交叉注意力机制。 交叉注意力机制使用一个序列来定义自注意力机制中的键(keys)和值(values),而使用另一个序列来定义查询(queries)。
| 注意力机制类型 | 序列 |
|---|---|
| 自注意力机制 | 一个序列为键与查询的点积qk, 一个序列为值v |
| 交叉注意力机制 | 一个序列为自注意力机制中的键和值k,v,一个序列为查询q |
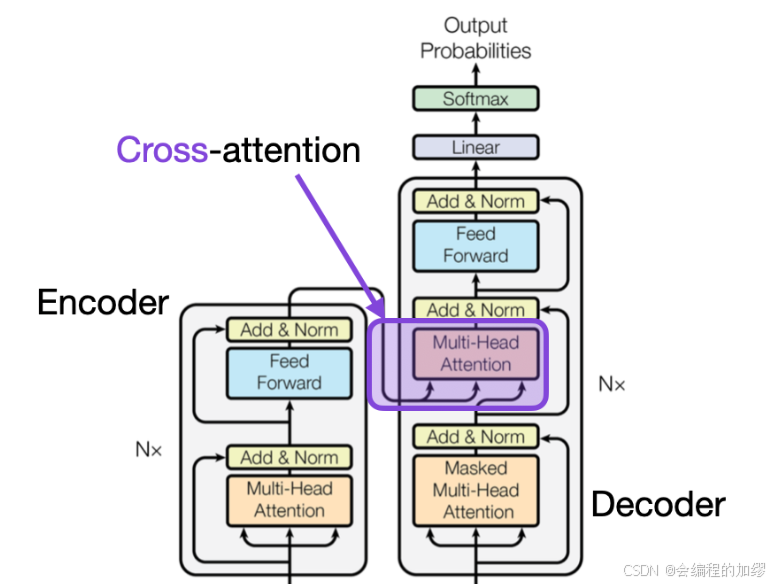
你可能会想,等等,这不就是在我们接触自注意力机制之前注意力机制一直的样子吗?没错,差不多就是这样。所以,如果 h 1 : n ( x ) = TransformerEncoder ( w 1 : n ) (12) h_{1: n}^{(x)}= \text{TransformerEncoder} \left(w_{1: n}\right) \tag{12} h1:n(x)=TransformerEncoder(w1:n)(12) 并且我们有序列 y 1 : m y_{1: m} y1:m的一些中间表示 h ( y ) h^{(y)} h(y),那么我们让查询来自解码器(即 h ( y ) h(y) h(y)序列),而键和值来自编码器: q i = Q h i ( y ) i ∈ { 1 , … , m } (13) q_{i}=Q h_{i}^{(y)} \quad i \in\{1, \ldots, m\} \tag{13} qi=Qhi(y)i∈{1,…,m}(13) k j = K h j ( x ) j ∈ { 1 , … , n } (14) k_{j}=K h_{j}^{(x)} \quad j \in\{1, \ldots, n\} \tag{14} kj=Khj(x)j∈{1,…,n}(14)
v j = V h j ( x ) j ∈ { 1 , … , n } (15) v_{j}=V h_{j}^{(x)} \quad j \in\{1, \ldots, n\} \tag{15} vj=Vhj(x)j∈{1,…,n}(15)
然后像我们为自注意力机制所定义的那样,对 q q q、 k k k、 v v v计算注意力。注意,在图6中,在Transformer编码器-解码器中,交叉注意力机制总是应用于Transformer编码器的输出。
编码器-解码器的用途。当我们希望在某些内容(比如一篇待总结的文章)上利用双向上下文信息来构建强大的表示(也就是说,每个标记都能够关注到所有其他标记),然后又能像使用解码器那样,根据自回归分解的方式生成输出时,就会用到编码器-解码器。尽管已经发现,在中等规模下,这种架构比仅使用解码器的模型能够提供更好的性能(Raffel等人,2020年),但它涉及到在编码器和解码器之间分配参数,而且大多数规模最大的Transformer模型都是仅使用解码器的。