【ARM64】【cache/MMU】学习总结
学习Wiki:
ARMV8-aarch64的虚拟内存(mmu/tlb/cache)介绍-概念扫盲
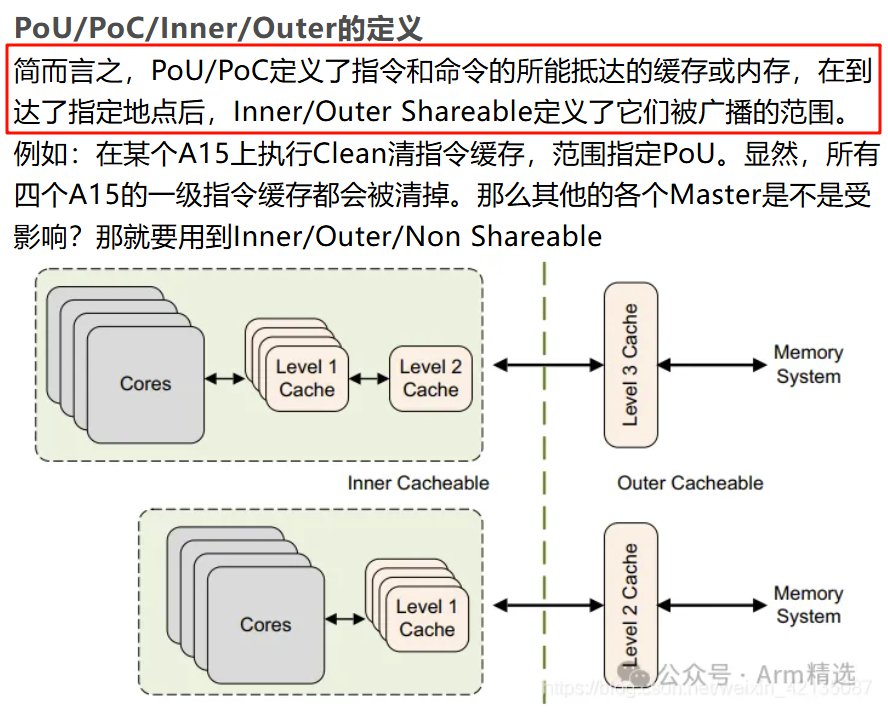
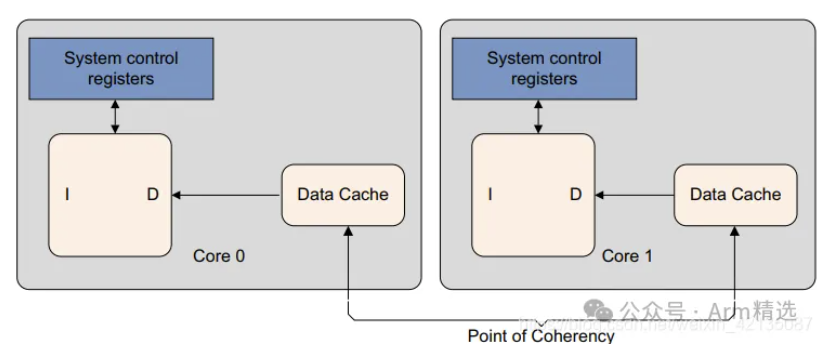
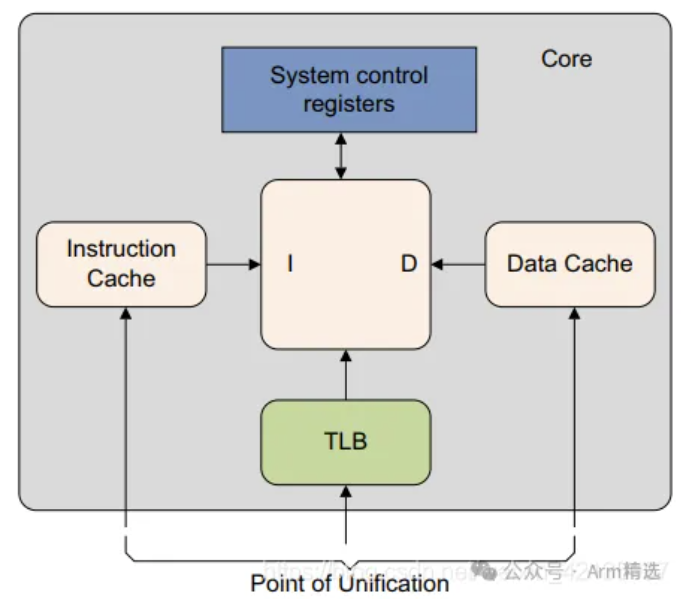
疑问1:
PoU/PoC 概念怎么理解?
(以下解释来自deepseek)
在ARM64架构中,PoU(Point of Unification)和PoC(Point of Coherency)是与缓存一致性(Cache Coherency)和缓存维护操作(Cache Maintenance Operations)密切相关的关键概念。它们的核心区别在于作用范围和一致性层级,理解这些概念对系统级编程(如操作系统、驱动开发)至关重要。
一、基本定义
-
PoC(Point of Coherency)
- 一致性最终点:PoC是系统中所有观察者(CPU核心、DMA设备等)对某一内存地址的数据视图达成一致的最终层级。
- 层级位置:通常是主存(DRAM)。任何缓存维护操作作用于PoC时,会确保所有层级缓存(L1、L2、L3等)和主存之间的数据完全一致。
-
PoU(Point of Unification)
- 统一层级点:PoU是当前CPU核的**指令缓存(I-Cache)和数据缓存(D-Cache)**首次共享同一物理地址空间的层级。
- 层级位置:通常指L2缓存(具体取决于微架构设计)。操作作用于PoU时,会确保该层级及以上的指令和数据缓存的一致性。
二、核心区别与用途
| 特性 | PoC | PoU |
|---|---|---|
| 一致性范围 | 全局一致性(所有缓存+主存) | 局部一致性(指令/数据缓存统一层级) |
| 典型操作 | DMA传输、多核共享内存 | 自修改代码、动态加载代码 |
| 维护指令 | DC CIVAC(清理并无效化到PoC) | IC IALLU(无效化指令缓存到PoU) |
三、应用场景示例
1. PoC的典型场景
- DMA数据传输:
当外设(如GPU、网卡)通过DMA直接访问内存时,需确保CPU缓存中的数据已写回主存(PoC)。
操作步骤:// 清理数据缓存到PoC,确保数据写入内存 DC CIVAC, Xn // Xn为目标地址 DSB SY // 确保操作完成 - 多核共享数据:
多个CPU核访问同一内存时,需通过PoC操作确保全局一致性。
2. PoU的典型场景
- 自修改代码(Self-Modifying Code):
当程序动态生成或修改代码后,需确保指令缓存与数据缓存一致(到PoU)。
操作步骤:// 清理数据缓存到PoU,确保代码写入内存 DC CVAU, Xn // 清理数据缓存到PoU DSB SY // 无效化指令缓存到PoU,使新代码生效 IC IALLU // 无效化所有指令缓存 DSB SY ISB // 确保流水线刷新 - 动态加载代码(如JIT编译器):
新生成的代码需从内存加载到指令缓存,需通过PoU操作同步。
四、技术细节与挑战
-
层级依赖性与微架构差异
- PoU和PoC的具体层级由CPU设计决定(如ARM Cortex-A77的PoU可能是L2,而Cortex-A55可能是L1)。
- 需查阅具体处理器的技术参考手册(TRM)确认。
-
性能影响
- PoC操作(如
DC CIVAC)涉及全局缓存一致性,可能触发总线监听(Snooping),延迟较高。 - PoU操作(如
IC IALLU)仅影响局部缓存层级,开销较小。
- PoC操作(如
-
内存屏障(Barrier)的必要性
- 在缓存维护操作后需插入
DSB/ISB指令,确保指令顺序性和流水线刷新。
- 在缓存维护操作后需插入
五、总结
- PoC:保证全局一致性,适用于多核、外设共享内存的场景。
- PoU:保证指令与数据缓存的局部一致性,适用于代码动态修改的场景。
- 关键原则:根据场景选择最小作用范围的维护操作(优先使用PoU,避免不必要的PoC开销)。
理解PoU/PoC的差异是优化ARM64系统性能和正确性的基础,尤其在涉及缓存管理的底层开发中需格外谨慎。

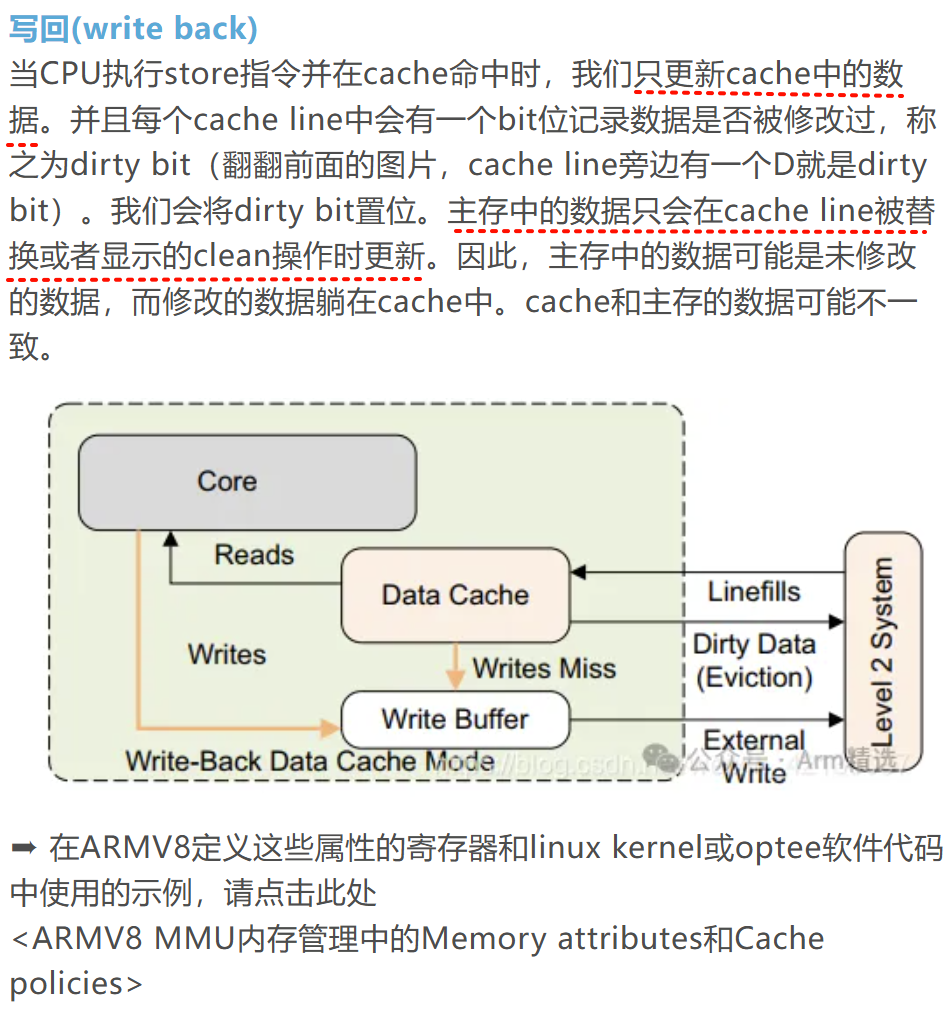
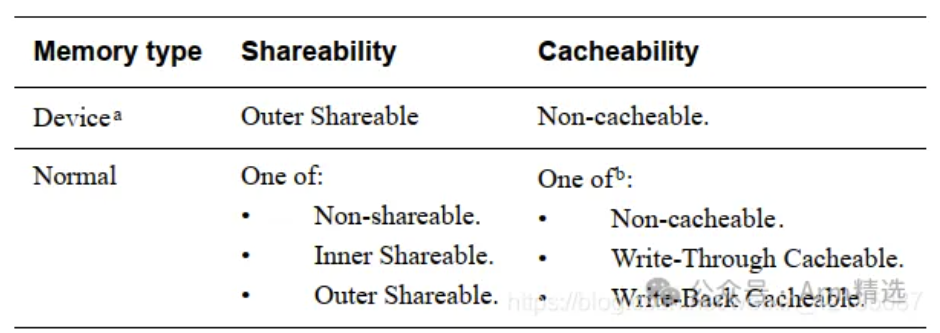


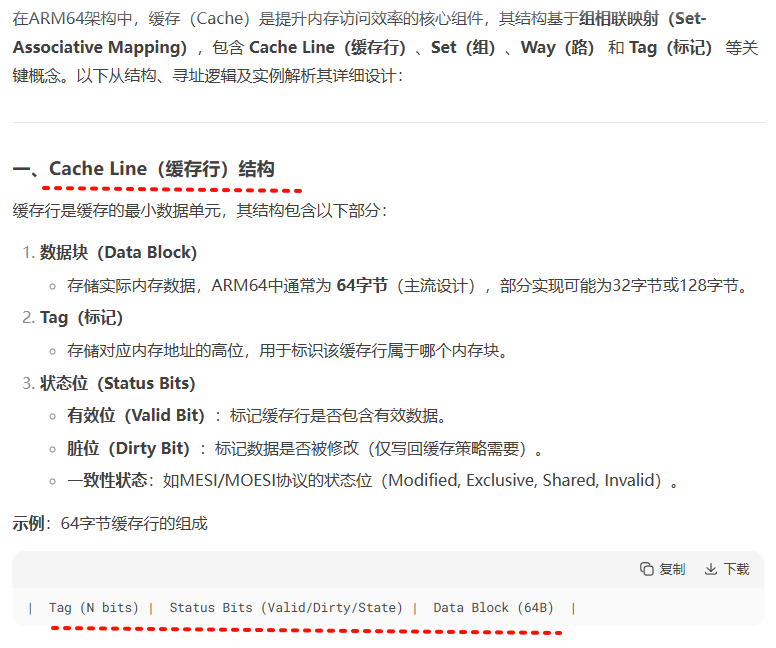
在ARM64架构中,缓存(Cache)是提升内存访问效率的核心组件,其结构基于组相联映射(Set-Associative Mapping),包含 Cache Line(缓存行)、Set(组)、Way(路) 和 Tag(标记) 等关键概念。以下从结构、寻址逻辑及实例解析其详细设计:
一、Cache Line(缓存行)结构
缓存行是缓存的最小数据单元,其结构包含以下部分:
- 数据块(Data Block)
- 存储实际内存数据,ARM64中通常为 64字节(主流设计),部分实现可能为32字节或128字节。
- Tag(标记)
- 存储对应内存地址的高位,用于标识该缓存行属于哪个内存块。
- 状态位(Status Bits)
- 有效位(Valid Bit):标记缓存行是否包含有效数据。
- 脏位(Dirty Bit):标记数据是否被修改(仅写回缓存策略需要)。
- 一致性状态:如MESI/MOESI协议的状态位(Modified, Exclusive, Shared, Invalid)。
示例:64字节缓存行的组成
| Tag (N bits) | Status Bits (Valid/Dirty/State) | Data Block (64B) |
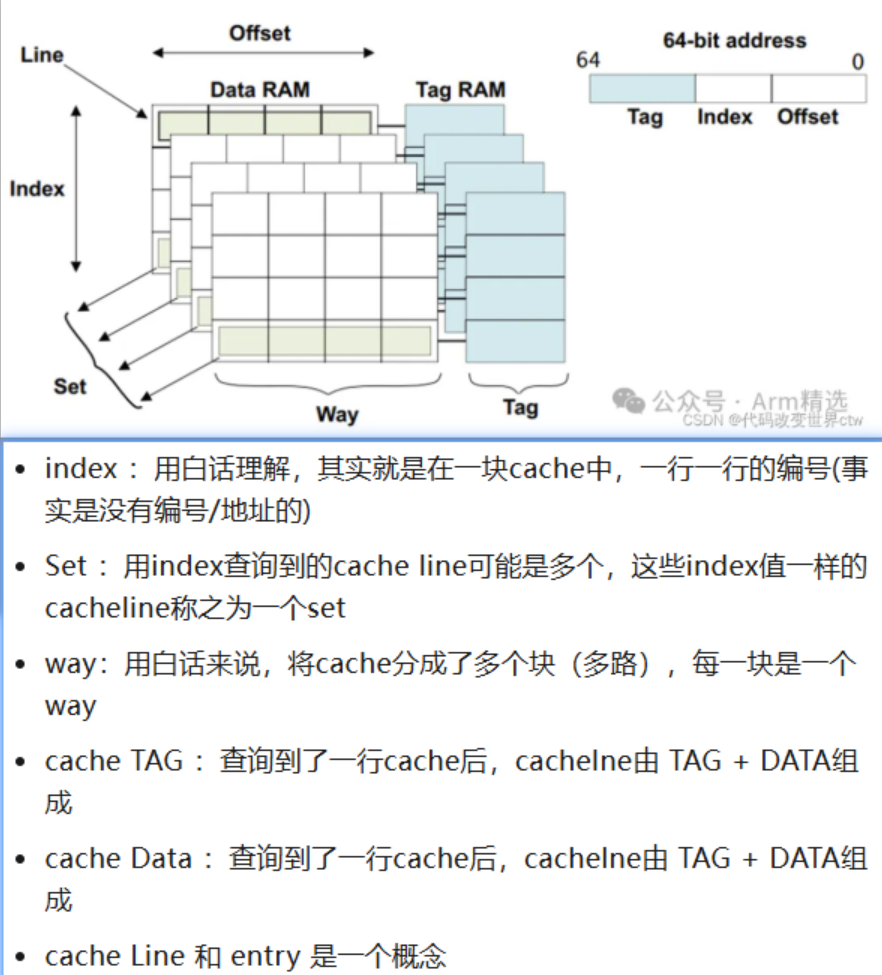
二、Set(组)与 Way(路)的映射逻辑
ARM64缓存采用 N路组相联(N-Way Set-Associative) 结构,其设计如下:
-
缓存总容量:
[
\text{总容量} = \text{Set数} \times \text{Way数} \times \text{Cache Line大小}
] -
地址划分:
内存地址被划分为三部分:| Tag (高位) | Index(组号) | Block Offset(块内偏移) |- Block Offset:由缓存行大小决定(64B → 6位)。
- Index:确定所属的Set,位数由Set数量决定(如128组 → 7位)。
- Tag:剩余高位用于匹配缓存行。
-
寻址流程:
- 通过 Index 定位到特定Set。
- 在Set内遍历所有Way的Tag,匹配访问地址的Tag。
- 匹配成功后,结合 Block Offset 读取数据。
三、实例计算(以L1缓存为例)
假设一个 4路组相联(4-Way) 的L1数据缓存(D-Cache),总容量为 32KB,缓存行大小 64B:
- Set数量计算:
[
\text{Set数} = \frac{\text{总容量}}{\text{Way数} \times \text{Cache Line大小}} = \frac{32\text{KB}}{4 \times 64\text{B}} = 128
]- Index位数:128 → ( \log_2(128) = 7 )位。
- 地址划分(48位物理地址):
| Tag (35 bits) | Index (7 bits) | Block Offset (6 bits) |- Block Offset:64B → 6位((2^6 = 64))。
- Index:128组 → 7位。
- Tag:48 - 7 - 6 = 35位。
四、不同缓存层级的差异
| 特性 | L1缓存 | L2/L3缓存 |
|---|---|---|
| 延迟 | 1~3周期 | 10~20周期 |
| 容量 | 32KB~64KB(每核) | 256KB~8MB(共享) |
| 相联度 | 4~8路组相联 | 16~32路组相联 |
| 替换策略 | LRU或伪LRU | 近似LRU或随机替换 |
五、地址索引方式的影响
ARM64缓存通常采用以下两种索引模式:
-
PIPT(Physical Index Physical Tag)
- 物理地址索引+物理地址标记,需MMU完成虚拟到物理地址转换后才能访问缓存。
- 优点:无别名(Alias)问题,一致性易维护。
- 缺点:访问延迟较高(需先转换地址)。
-
VIPT(Virtual Index Physical Tag)
- 虚拟地址索引+物理地址标记,可并行执行地址转换与缓存访问。
- 优点:降低访问延迟。
- 挑战:需解决不同虚拟地址映射同一物理地址导致的别名问题(通过缓存对齐或着色技术解决)。
六、缓存维护操作与Set/Way的关系
ARM64提供缓存维护指令(如DC CIVAC、IC IALLU),可通过指定Set/Way直接操作缓存:
// 清理并无效化指定Set/Way的缓存行
DC CISW, Xn // Xn寄存器包含Set/Way编码
- Set/Way编码:将Set和Way编号按位组合(如Set占低7位,Way占后续位)。
七、总结
- Cache Line 是缓存的基本单位,包含数据、Tag及状态位。
- Set/Way 实现组相联映射,通过Index定位Set,Tag匹配Way。
- 地址划分 取决于缓存容量和相联度,直接影响Tag/Index位数。
- 替换策略(如LRU)和索引模式(如VIPT)是性能优化的关键。
理解这些概念对优化ARM64系统性能(如减少缓存冲突、提升数据局部性)至关重要。具体实现细节需参考处理器手册(如Cortex-A系列TRM)。
set/way结构图

多路组相连:
自己理解:
多路组相连,结合下图,通过地址中的index可以找出一组(set)cacheline,通过比较tag确定是哪一路(way),最终找到地址对应的cacheline,offset是cacheline内的字节偏移。



MESI/MOESI协议的状态位解释;
MESI/MOESI 协议状态位详解
一、MESI 协议状态定义
MESI 是缓存一致性协议的核心模型,包含 4 种状态,通过状态位标记缓存行的数据状态和权限:
| 状态 | 全称 | 含义 | 触发条件 |
|---|---|---|---|
| M | Modified (修改) | 数据仅存在于当前缓存,且已被修改(与主存不一致)。 | 本地处理器写入缓存行,且未同步到其他缓存或主存。 |
| E | Exclusive (独占) | 数据仅存在于当前缓存,与主存一致,当前处理器拥有独占访问权。 | 从主存加载数据时,其他缓存中无该数据副本。 |
| S | Shared (共享) | 数据存在于多个缓存中,所有副本与主存一致。 | 其他处理器已加载相同数据,或本地处理器读取已被共享的缓存行。 |
| I | Invalid (无效) | 缓存行数据已失效,不可直接使用。 | 其他处理器修改了该数据(触发总线监听),或本地缓存行被替换。 |
状态转换示例(以本地操作为核心):
- 本地读命中:
- M/E/S → 保持原状态(数据有效,无需同步)。
- 本地写命中:
- M → 保持 M(直接修改)。
- E/S → 升级为 M(需通过总线广播使其他缓存行失效)。
- 远程读监听命中:
- M → 降级为 S(将修改数据写回主存,供其他处理器共享)。
- 远程写监听命中:
- M/E/S → 降级为 I(其他处理器修改数据,本地副本失效)。
二、MOESI 协议扩展(新增 O 状态)
MOESI 在 MESI 基础上增加 Owned (拥有) 状态,解决多缓存共享脏数据的问题,典型应用于 AMD 处理器:
| 新增状态 | 全称 | 含义 | 与 MESI 的区别 |
|---|---|---|---|
| O | Owned (拥有) | 缓存行数据为“脏数据”(与主存不一致),但允许其他缓存共享该副本。 | - 数据由 O 状态缓存负责回写主存,避免多缓存重复回写。 - 其他缓存可持有 S 状态副本。 |
关键场景:
当缓存行处于 M 状态时,若其他处理器请求读取:
- MESI:需将数据写回主存,本地状态降为 S,其他缓存从主存加载 S 状态副本。
- MOESI:本地状态降为 O,直接提供数据给请求方(无需写回主存),请求方缓存行标记为 S。
三、状态转换对比(MESI vs. MOESI)
| 操作 | MESI 转换 | MOESI 转换 |
|---|---|---|
| 本地写命中(原状态 S) | S → M,其他缓存行失效 | S → M 或 O(视是否允许共享脏数据) |
| 远程读监听命中(原状态 M) | M → S,数据写回主存 | M → O,直接提供数据 |
| 缓存替换(原状态 M) | 必须写回主存 | 若处于 O 状态,可延迟写回 |
四、设计意义与性能影响
- MESI:
- 优点:协议简单,总线通信量较低。
- 缺点:共享脏数据需频繁写回主存,增加延迟。
- MOESI:
- 优点:减少主存写入次数(O 状态缓存统一负责回写),提升多核性能。
- 缺点:协议复杂度更高,需额外状态管理。
五、实际应用
- MESI:Intel x86、ARM 多核处理器(如 Cortex-A 系列)。
- MOESI:AMD 处理器(如 Ryzen 系列)。
相关问题
- 为什么 MOESI 协议能减少主存写入次数?
- MESI 协议在总线争用场景下有何瓶颈?
- 如何通过代码优化减少缓存一致性协议的开销?
- : MOESI 协议在 AMD 处理器中的应用及其对共享脏数据的优化。
- MESI 与 MOESI 状态转换规则的对比分析。
- MESI 协议的状态迁移规则与总线监听机制。
- 总线监听协议的演进与 MESI 协议的设计取舍。
遗留问题:
物理地址和虚拟地址划分是一样的吗?
ARM 64位架构物理地址与虚拟地址格式解析及区别
一、虚拟地址格式解析
ARMv8的虚拟地址设计以48位为主(默认配置),但可通过ARMv8.2 LVA(Larger Virtual Addressing)扩展至52位(支持 4 PiB 4\,\text{PiB} 4PiB虚拟地址空间)。虚拟地址格式与页表映射粒度和地址空间划分策略密切相关:
-
典型48位虚拟地址划分(以4KB页为例):
V A = 页表索引(L0-L3) ⏟ 36 bits ∣ 页内偏移 ⏟ 12 bits VA = \underbrace{\text{页表索引(L0-L3)}}_{36\,\text{bits}} \mid \underbrace{\text{页内偏移}}_{12\,\text{bits}} VA=36bits 页表索引(L0-L3)∣12bits 页内偏移- 页表索引:分为4级(L0-L3),每级9位,共 9 × 4 = 36 9 \times 4 = 36 9×4=36位。
- 页内偏移:12位(对应 2 12 = 4 KB 2^{12}=4\,\text{KB} 212=4KB页大小)。
-
用户态与内核态划分:
- 用户空间:
TTBR0_EL1管理,范围 [ 0 , 0 x 0000 ffffffffffff ] [0, 0x0000\text{ffffffffffff}] [0,0x0000ffffffffffff]。 - 内核空间:
TTBR1_EL1管理,范围 [ 0 x f f f f 000000000000 , 0 x f f f f ffffffffffff ] [0xffff000000000000, 0xffff\text{ffffffffffff}] [0xffff000000000000,0xffffffffffffffff]。 - 示例:若
VA_BITS=48,内核空间起始地址为0xffff000000000000,通过TCR_EL1.T1SZ调节偏移量。
- 用户空间:
二、物理地址格式解析
物理地址宽度由ID_AA64MMFR0_EL1.IPS定义(默认48位,可通过ARMv8.2 LPA扩展至52位),其结构与缓存层次和内存控制器设计强相关:
-
典型48位物理地址划分(假设64B缓存行):
P A = Tag ⏟ 35 bits ∣ Index ⏟ 7 bits ∣ Block Offset ⏟ 6 bits PA = \underbrace{\text{Tag}}_{35\,\text{bits}} \mid \underbrace{\text{Index}}_{7\,\text{bits}} \mid \underbrace{\text{Block Offset}}_{6\,\text{bits}} PA=35bits Tag∣7bits Index∣6bits Block Offset- Tag:唯一标识缓存行,用于匹配物理地址(避免缓存别名问题)。
- Index:选择缓存组(Set),直接关联缓存容量(如512组需9位)。
- Block Offset:缓存行内偏移(64B需6位)。
-
扩展至52位物理地址(ARMv8.2 LPA):
- Tag和Index字段可动态调整,例如增加Tag位数以支持更大物理内存。
三、物理地址与虚拟地址的核心差异
| 特征 | 虚拟地址 (VA) | 物理地址 (PA) |
|---|---|---|
| 位数 | 默认48位,可扩展至52位(LVA) | 默认48位,可扩展至52位(LPA) |
| 组成结构 | 页表索引 + 页内偏移 | Tag + Index + Block Offset |
| 配置方式 | 通过TCR_EL1.T0SZ/T1SZ调节地址空间范围 | 由SoC内存控制器和缓存架构固定定义 |
| 用途 | 进程隔离、内存保护、地址随机化 | 实际访问DRAM、缓存、外设的硬件寻址 |
| 别名问题 | 多个VA可映射同一PA(需缓存/TLB一致性) | 唯一标识物理存储位置 |
四、关键设计权衡
- 地址位数限制:
- 默认48位(而非64位)减少了页表级数和TLB压力,平衡性能与扩展性。
- 52位扩展(LVA/LPA)面向高性能计算和大内存需求场景。
- 内核空间布局:
- 内核固定使用高地址区域(如
0xffff000000000000),简化地址检查逻辑。
- 内核固定使用高地址区域(如
- 缓存与物理地址关系:
- 物理地址的Tag设计直接关联缓存一致性协议(如MESI),避免重名(Homonym)和别名(Synonym)问题。
五、示例分析
场景:4KB页 + 48位VA + 48位PA
- 虚拟地址
0xffff800011223344:- 高位
0xffff8表示内核空间(TTBR1_EL1管理)。 - 页表索引:
0x000112233(36位,分4级查询页表)。 - 页内偏移:
0x44(12位)。
- 高位
- 物理地址
0x1a2b3c4d5e6f:- Tag:
0x1a2b3c(35位,标识缓存行)。 - Index:
0x4d(7位,选择缓存组)。 - Block Offset:
0x5e6f(6位,缓存行内偏移)。
- Tag:
待学习Wiki:
【ARM中文手册】ARM Cortex-A的Programmer Guide目录合集–搜藏篇
Armv8/armv9架构入门指南
cache的58问,您能回答上来几个?
深度学习arm cache系列–一篇就够了