从单模态到多模态:大模型架构演进与技术介绍
前言
- 1. ResNet — 残差神经网络
- 背景
- 核心问题与解决方案
- 原理
- 模型架构
- ResNet 系列变体
- 技术创新与影响
- 2. ViT — Vision Transformer
- 背景
- 核心思想
- 发展历程
- Transformer的起源:
- ViT的出现:
- ViT的进一步发展:
- 模型架构
- 技术创新与影响
- 3. Swin Transformer
- 背景
- 核心思想
- 模型架构
- 技术创新与影响
- 4.CLIP — Contrastive Language-Image Pre-training
- 背景
- CLIP 核心思想
- 模型架构
- 训练方法
- 零样本推理(Zero-Shot Prediction)
- 关键实验结果
- 技术创新与影响
- 5. ViLT — Vision-and-Language Transformer
- 背景
- ViLT 的核心特点
- 模型架构
- 技术创新与影响
- 6. ViViT(Video Vision Transformer)
- **1. 背景与核心思想**
- **2. 模型架构**
- **3. 关键技术细节**
- **4. 训练与预训练策略**
- **5. 应用场景**
- **6. 性能与优缺点**
- **8. 后续改进与变体**
- 7. DIT(Diffusion-based Image Transformer)
- **技术发展脉络**
- **扩散模型的崛起**
- **Transformer的视觉革命**
- **DIT的诞生动机**
- **为什么结合扩散模型与Transformer?**
- **1. 核心概念**
- **2. 工作原理**
- **3. 架构设计**
- **4. 关键优势**
- **5. 应用场景**
- **6. 挑战与优化**
- **总结**

人工智能领域的模型架构经历了从单模态(专注于单一数据类型)到多模态(融合多种数据类型)的跨越式发展。这一过程中,残差学习、注意力机制、对比学习等技术的突破推动了模型的性能提升和应用场景扩展。本文将深入解析五个里程碑模型——ResNet、ViT、Swin Transformer、CLIP、ViLT,探讨其核心架构与技术创新,并梳理从单模态到多模态的技术演进路径。
1. ResNet — 残差神经网络
背景
2015年,何恺明团队提出的深度残差网络(ResNet)解决了深度卷积神经网络训练中的梯度消失/爆炸问题,使得构建和训练超深网络成为可能。ResNet在ImageNet竞赛中取得当时最先进的性能,并获得了2015年CVPR最佳论文奖。
核心问题与解决方案
传统CNN模型在层数增加时会遇到退化问题(degradation problem):随着网络深度增加,准确率开始饱和,然后迅速下降。ResNet通过引入残差学习框架解决了这一问题。
原理
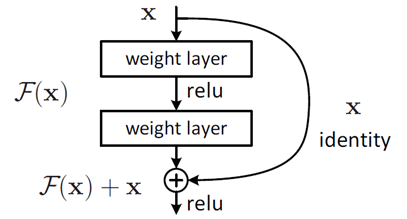
残差学习(Residual Learning):随着网络深度的增加,传统的深层网络面临着梯度消失或梯度爆炸的问题,使得网络难以训练。ResNet通过引入“残差块”(Residual Block),让网络可以轻松地学习恒等映射(Identity Mapping)。这意味着,在深层次网络中,如果某一层没有对特征提取有帮助,则该层可以学为零,从而不会对最终结果造成负面影响。
模型架构
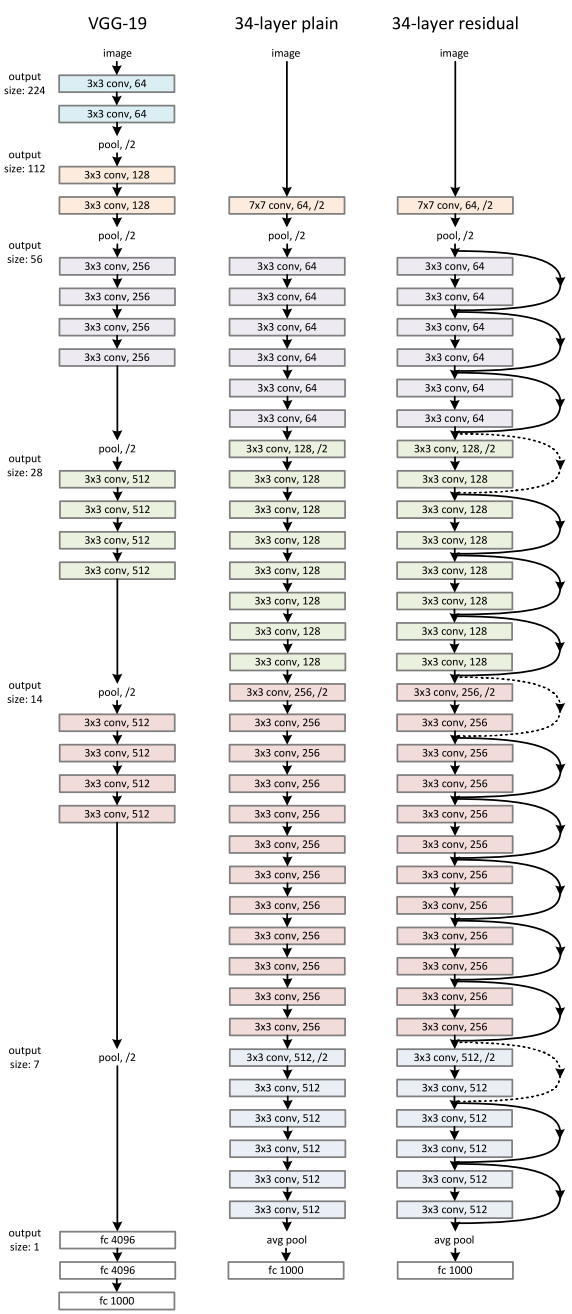
ResNet的架构 : ResNet34 使用的受 VGG-19 启发的 34 层普通网络架构,随后添加了快捷连接。随后通过这些快捷连接将该架构转变为残差网络,如下图所示:
ResNet的核心是残差块(Residual Block),其结构如下:
- 残差连接(Skip Connection):将输入信号直接添加到层的输出
- 残差学习:网络不直接学习原始映射H(x),而是学习残差
F ( x ) = H ( x ) − x F(x) = H(x) - x F(x)=H(x)−x
一个基本的残差块可以表示为:
y = F ( x , W i ) + x y = F(x, {Wi}) + x y=F(x,Wi)+x
其中F(x, {Wi})表示残差映射,可以是多层堆叠的卷积操作。
ResNet的完整架构包括:
- 初始卷积层(7×7卷积,步长2)
- 最大池化层(3×3,步长2)
- 4组残差块堆叠(每组有不同数量的残差块)
- 全局平均池化
- 全连接层+Softmax
ResNet有多种变体,包括ResNet-18、ResNet-34、ResNet-50、ResNet-101和ResNet-152,数字表示网络深度。
ResNet 系列变体
| 模型 | 层数 | 参数量 | 结构说明 |
|---|---|---|---|
| ResNet-18 | 18 | 11M | 基础残差块 |
| ResNet-34 | 34 | 21M | 基础残差块 |
| ResNet-50 | 50 | 25M | Bottleneck 残差块 |
| ResNet-101 | 101 | 44M | Bottleneck 残差块 |
| ResNet-152 | 152 | 60M | Bottleneck 残差块 |
技术创新与影响
- 解决深度网络训练问题:残差连接使得信息可以直接从浅层传递到深层
- 梯度流动改善:短路连接有助于梯度在反向传播中更好地流动
- 表示能力增强:更深的网络具有更强的特征提取能力
- 训练稳定性:残差学习框架使训练更加稳定
2. ViT — Vision Transformer
背景
2020年10月,谷歌研究团队发布了论文"An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale",首次将自然语言处理领域的Transformer架构直接应用于计算机视觉任务,但是因为其模型“简单”且效果好,可扩展性强(scalable,模型越大效果越好),成为了transformer在CV领域应用的里程碑著作,也引爆了后续相关研究。
核心思想
ViT的核心思想是将图像视为"单词序列",摒弃了CNN中的归纳偏置(如平移不变性、局部连接等),完全依赖自注意力机制处理视觉信息。
发展历程
Transformer的起源:
- 2017年,Google提出了Transformer模型,这是一种基于Seq2Seq结构的语言模型,它首次引入了Self-Attention机制,取代了基于RNN的模型结构。
- Transformer的架构包括Encoder和Decoder两部分,通过Self-Attention机制实现了对全局信息的建模,从而能够解决RNN中的长距离依赖问题。
ViT的出现:
- ViT采用了Transformer模型中的自注意力机制来建模图像的特征,这与CNN通过卷积层和池化层来提取图像的局部特征的方式有所不同。
- ViT模型主体的Block结构基于Transformer的Encoder结构,包含Multi-head Attention结构。
ViT的进一步发展:
- 随着研究的深入,ViT的架构和训练策略得到了进一步的优化和改进,使其在多个计算机视觉任务中都取得了与CNN相当甚至更好的性能。
- 目前,ViT已经成为计算机视觉领域的一个重要研究方向,并有望在未来进一步替代CNN成为主流方法。
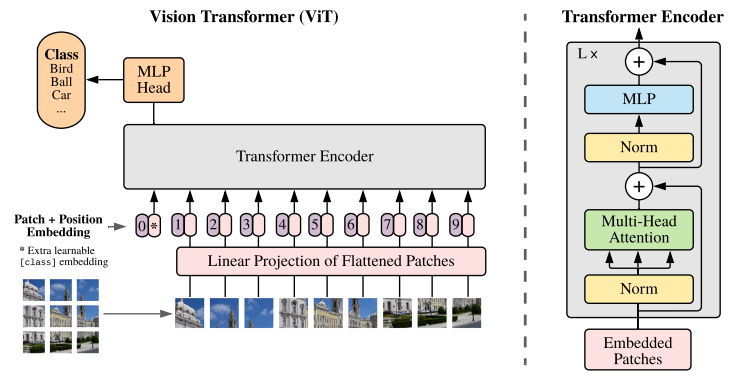
模型架构
ViT将输入图片分为多个patch(16x16),再将每个patch投影为固定长度的向量送入Transformer,后续encoder的操作和原始Transformer中完全相同。但是因为对图片分类,因此在输入序列中加入一个特殊的token,该token对应的输出即为最后的类别预测
ViT的处理流程如下:
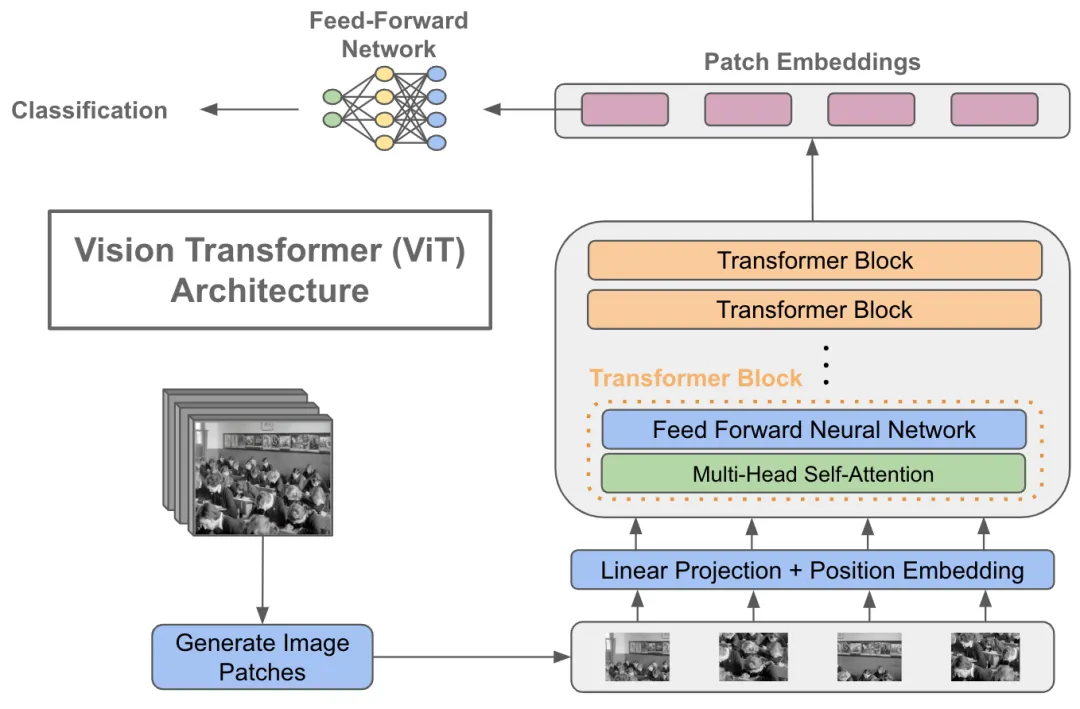
-
图像分块与线性投影
- 将输入图像划分为固定尺寸的方形区域(如16×16像素),生成二维网格序列。每个图像块经全连接层进行线性投影,转化为768维特征向量。此时视觉数据完成形态转换,形成类序列结构。
-
类别标记注入
- 在序列首部插入可学习的分类标识向量,该特殊标记贯穿整个网络运算,最终作为图像表征的聚合载体。此操作使序列长度由N增至N+1,同时保持特征维度一致性。
-
位置编码融合
- 通过可训练的位置嵌入表为每个序列元素注入空间信息。采用向量相加方式而非拼接,在保留原始特征维度的前提下,使模型感知元素的相对位置关系。
-
Transformer编码架构
-
由多层相同结构模块堆叠组成,每个模块包含:
-
层归一化处理的多头注意力机制:将特征拆分为多个子空间(如12个64维头部),并行捕获异构关联模式,输出重聚合后维持768维
-
多层感知机扩展层:先进行4倍维度扩展(768→3072)增强表征能力,再投影回原维度保证结构统一性
-
-
特征演化与输出
- 所有编码模块保持输入输出同维度(197×768),实现深度堆叠。最终提取首位的类别标记向量作为全局图像描述符,或采用全序列均值池化策略,接入分类器完成视觉任务。这种架构通过序列化处理实现了视觉与语言模型的范式统一。
ViT的公式表示:
z 0 = [ x c l a s s ; x 1 E ; x 2 E ; . . . ; x N E ] + E p o s z_0 = [x_class; x_1^E; x_2^E; ...; x_N^E] + E_pos z0=[xclass;x1E;x2E;...;xNE]+Epos
z l = M S A ( L N ( z l − 1 ) ) + z l − 1 z_l = MSA(LN(z_{l-1})) + z_{l-1} zl=MSA(LN(zl−1))+zl−1
z l = M L P ( L N ( z l ) ) + z l z_l = MLP(LN(z_l)) + z_l zl=MLP(LN(zl))+zl
y = L N ( z L 0 ) y = LN(z_L^0) y=LN(zL0)
技术创新与影响
- 打破CNN垄断:ViT证明了纯Transformer架构在视觉任务上的可行性
- 缩小模态差距:为视觉和语言任务提供了统一的架构基础
- 全局感受野:自注意力机制天然具有全局视野,不同于CNN的局部感受野
- 数据效率权衡:需要大量数据预训练才能超越CNN模型
ViT的出现标志着计算机视觉领域的范式转变,开启了"Transformer时代",大大推动了视觉-语言多模态模型的发展。
3. Swin Transformer
背景
微软研究院于2021年3月发表Swin Transformer,试图解决ViT在计算效率和细粒度特征提取方面的局限性,尤其是针对密集预测任务(如目标检测、分割)。
核心思想
Swin Transformer的核心思想在于利用窗口内的自注意力机制,同时通过层级结构实现跨窗口的信息交互,从而实现了高效的视觉特征提取和表达。具体来说:
- 窗口化自注意力(Window-based Self-Attention, W-MSA):将图像划分为不重叠的窗口,仅在每个窗口内进行自注意力计算。
- 移位窗口(Shifted Windows, SW-MSA):通过在相邻层之间移动窗口位置,实现窗口间的交互,弥补W-MSA缺乏跨窗口连接的不足。
- 层次化结构:借鉴CNN的多尺度设计,Swin Transformer通过逐步合并patch降低分辨率,扩大感受野,形成类似金字塔的特征提取过程
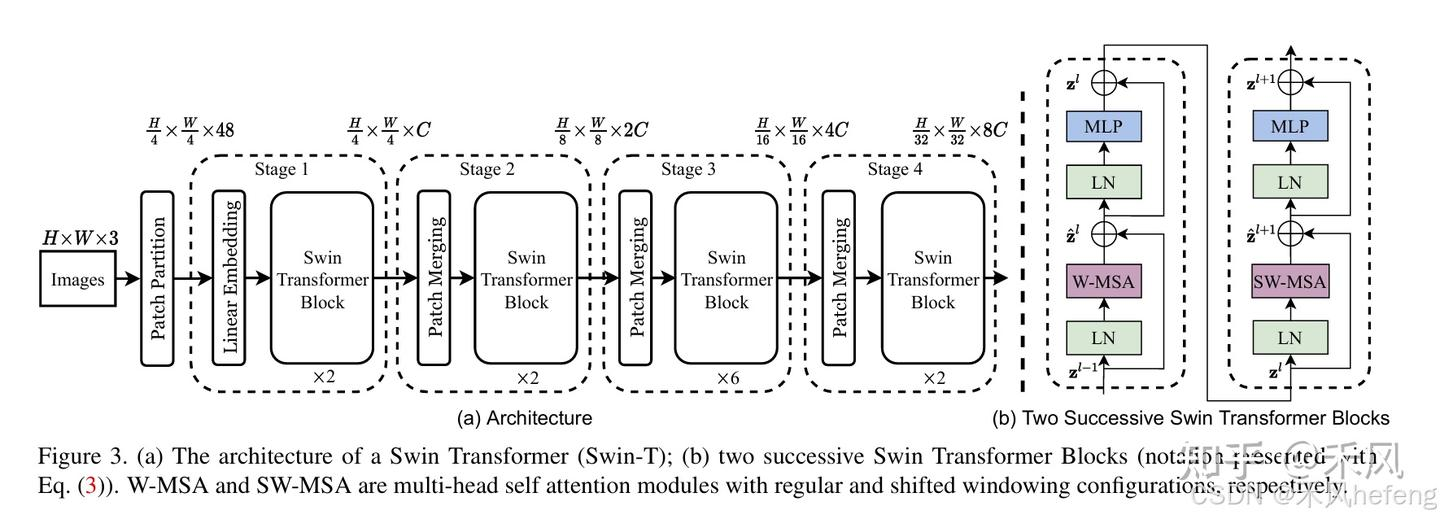
模型架构
Swin Transformer的关键设计包括:
- 层级结构:类似CNN的层级特征图,分辨率逐层下降
- 窗口自注意力:将自注意力计算限制在局部窗口内(如7×7大小)
- 窗口移位操作:在连续层之间交替使用常规窗口和移位窗口,使得不同窗口之间可以交换信息
- 相对位置编码:在窗口内使用相对位置偏置而非绝对位置编码
Swin Transformer包含4个阶段:
Swin Transformer的整体架构包括Patch Embedding、多个Swin Transformer Block以及分类头。下面逐步介绍其主要组成部分:
- Patch Partition:这是模型对输入图像进行预处理的一种重要操作。该操作的主要目的是将原始的连续像素图像分割成一系列固定大小的图像块(patches),以便进一步转化为Transformer可以处理的序列数据 2。
- Swin Transformer Block:是模型的核心单元,每个block包含以下步骤:
- Layer Normalization
- W-MSA或SW-MSA
- 残差连接
- 再次Layer Normalization
- 前馈网络(FFN)
- 残差连接
- Patch Merging:为了实现层次化特征提取,Swin Transformer在每个stage结束后通过Patch Merging合并相邻patch。这一步骤类似于卷积神经网络中的池化操作,但采用的是线性变换而不是简单的最大值或平均值操作 5。
- 输出模块:包括一个LayerNorm层、一个AdaptiveAvgPool1d层和一个全连接层,用于最终的分类或其他任务 4
技术创新与影响
- 线性计算复杂度:窗口注意力使得计算复杂度与图像大小成线性关系,而非ViT的二次关系
- 层级表示:生成多尺度特征,适合各种视觉任务
- 跨窗口连接:移位窗口机制允许信息在不同窗口间流动
- 通用视觉骨干网:成为视觉领域的通用主干网络,用于分类、检测和分割等多种任务
Swin Transformer成功地将Transformer的优势与CNN的层级结构相结合,为后续多模态模型提供了更高效的视觉特征提取器。
4.CLIP — Contrastive Language-Image Pre-training
背景
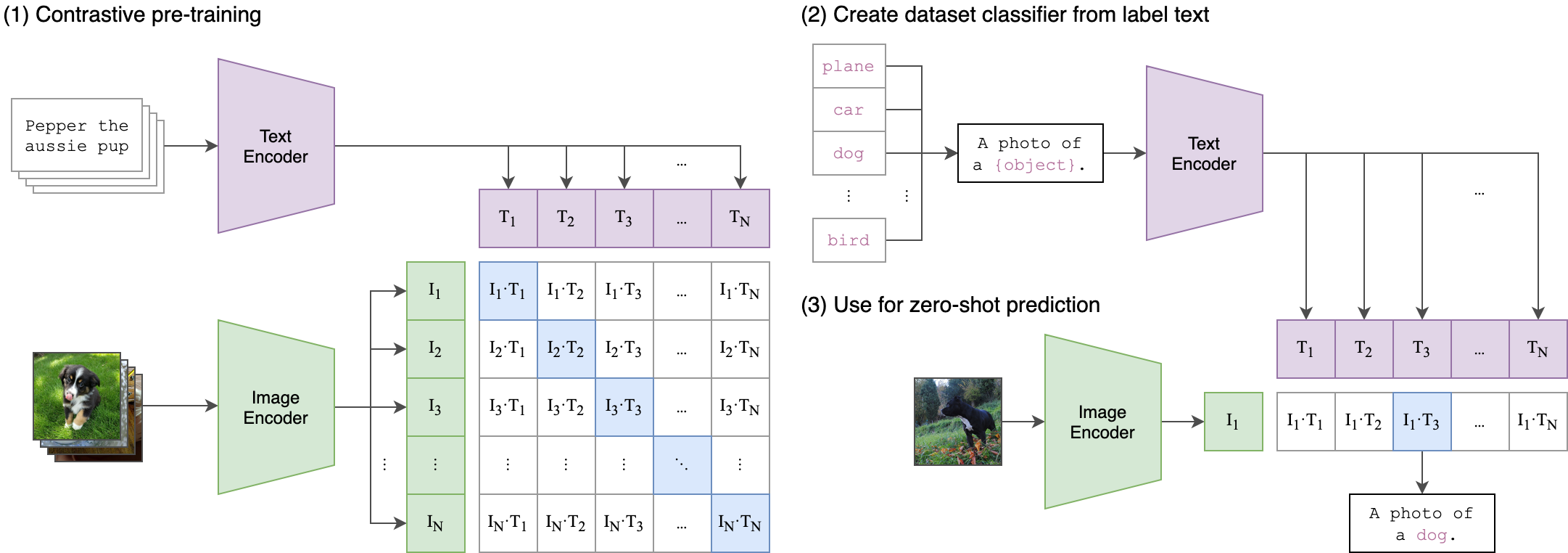
CLIP(Contrastive Language-Image Pretraining)是 OpenAI 在 2021 年提出的 多模态预训练模型,通过对比学习将图像和文本映射到同一语义空间,实现 零样本(Zero-Shot)分类、跨模态检索等任务。它彻底改变了传统视觉模型的训练方式,成为多模态领域的里程碑工作。
CLIP 核心思想
(1) 核心目标
-
学习图像和文本的联合表示,使匹配的图文对在特征空间中靠近,不匹配的远离。
-
无需人工标注的类别标签,直接利用自然语言描述(如“一只猫在沙发上”)作为监督信号。
(2) 关键创新
-
对比学习(Contrastive Learning):通过大规模图文对训练,拉近正样本对(匹配图文),推开负样本对(不匹配图文)。
-
自然语言作为监督信号:摆脱固定类别标签的限制,支持开放词汇(Open-Vocabulary)任务。
-
零样本迁移能力:预训练后可直接用于下游任务(如分类、检索),无需微调。
模型架构
CLIP 包含两个独立的编码器:
-
图像编码器(Image Encoder):
-
可选架构:ViT(Vision Transformer) 或 ResNet(如 ResNet-50)。
-
输入:图像 → 输出:图像特征向量(如 512 维)。
-
-
文本编码器(Text Encoder):
-
基于 Transformer(类似 GPT-2)。
-
输入:文本描述 → 输出:文本特征向量(与图像特征同维度)。
-
训练方法
1. 对比损失(Contrastive Loss)
- 对一个 batch 中的 N 个图文对:
- 计算图像特征 Ii 和文本特征 Tj的余弦相似度矩阵
S i , j = I i ⋅ T j S i , j = I i ⋅ T j Si,j=Ii⋅TjS i,j =I i ⋅T j Si,j=Ii⋅TjSi,j=Ii⋅Tj
损失函数(对称交叉熵损失):
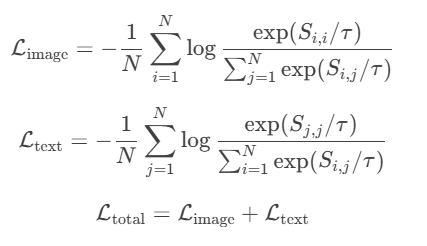
其中τ 是温度系数(可学习参数)。
(2) 训练数据
-
数据集:4 亿个互联网公开图文对(WebImageText)。
-
数据增强:随机裁剪、颜色抖动等。
零样本推理(Zero-Shot Prediction)
(1) 分类任务流程
-
构建文本模板:
- 将类别名称(如“dog”)填入提示模板(Prompt Template),例如:
“a photo of a {dog}”
- 生成所有类别的文本描述,并编码为文本特征 T1,T2,…,T K 。
- 将类别名称(如“dog”)填入提示模板(Prompt Template),例如:
- 编码待分类图像:得到图像特征 I
- 计算相似度:
-
图像特征与所有文本特征计算余弦相似度。
-
选择相似度最高的文本对应的类别作为预测结果。
-
(2) 优势
-
无需微调:直接利用预训练模型。
-
支持开放词汇:新增类别只需修改文本描述,无需重新训练。
关键实验结果
(1) 零样本分类性能
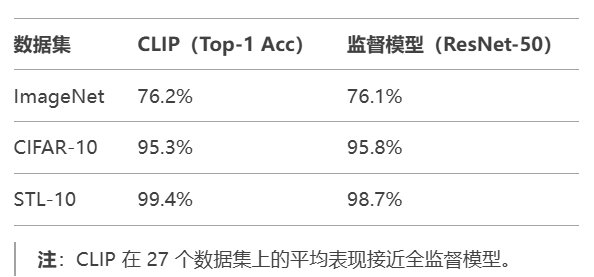
技术创新与影响
- 零样本迁移学习:无需针对特定任务微调即可应用于新类别
- 大规模预训练:在4亿图像-文本对上训练
- 多模态理解:构建图像和文本的联合表示空间
- 灵活性:可用于图像分类、图像检索、文本检索等多种任务
- 减少标注依赖:利用互联网上自然存在的图像-文本对训练
CLIP开创了视觉-语言预训练的新范式,证明了通过自然语言监督可以学习到强大且通用的视觉表示,奠定了多模态AI系统的基础。
5. ViLT — Vision-and-Language Transformer
背景
ViLT(Vision-and-Language Transformer)是 2021 年提出的一种 纯 Transformer 架构的视觉-语言多模态模型,其核心思想是 用统一的 Transformer 同时处理图像和文本,无需卷积网络(CNN)或区域特征提取(如 Faster R-CNN),极大简化了多模态模型的复杂度。
ViLT 的核心特点
(1) 极简架构设计
- 完全基于 Transformer:
-
传统多模态模型(如 LXMERT、UNITER)依赖 CNN 提取图像特征 或 Faster R-CNN 提取区域特征,计算成本高。
-
ViLT 直接对原始图像像素进行 Patch Embedding(类似 ViT),文本则通过 Token Embedding 输入,两者共享同一 Transformer 编码器。
-
(2) 模态交互方式
-
单流架构(Single-Stream):
-
图像和文本的嵌入向量拼接后输入同一 Transformer,通过自注意力机制直接交互。
-
对比双流架构(如 CLIP),计算更高效,模态融合更彻底。
-
(3) 轻量高效
-
参数量仅为传统模型的 1/10:
-
ViLT-Base 参数量约 110M,而类似功能的 UNITER 需 1B+ 参数。
-
训练速度提升 2-10 倍,适合低资源场景。
-
模型架构
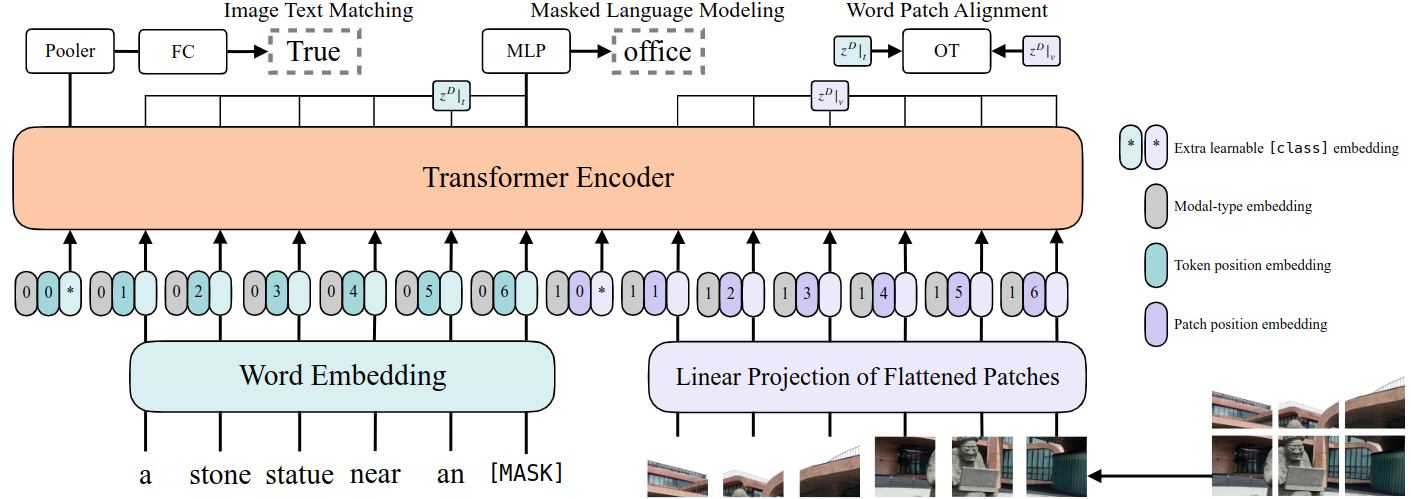
- 文本经过pre-trained BERT tokenizer得到word embedding(前面有CLS token,图中*表示)
- 图片经过ViT patch projection层得到patch embedding(也是用*表示CLS token);
- 文本特征+文本位置编码+模态嵌入得到最终的text embedding,图像这边也是类似的操作得到image embedding;二者concat拼接之后,一起输入transformer layer,然后做MSA交互(多头自注意力)
(1) 输入表示
-
图像输入:
-
将图像分割为 N×N 的 Patches(如 32×32)。
-
线性投影为 Patch Embeddings,并添加位置编码(Position Embedding)。
-
-
文本输入:
-
使用 WordPiece 分词,生成 Token Embeddings。
-
添加位置编码和模态类型编码(Modality-Type Embedding)。
-
(2) 共享 Transformer 编码器
-
图像和文本的 Embeddings 拼接后输入 Transformer:
I n p u t = [ I m a g e E m b ; T e x t E m b ] + P o s i t i o n E m b + M o d a l i t y E m b Input=[Image_Emb;Text_Emb]+Position_Emb+Modality_Emb Input=[ImageEmb;TextEmb]+PositionEmb+ModalityEmb -
通过多层 Transformer Blocks 进行跨模态交互:
-
自注意力机制:图像 Patch 和文本 Token 互相计算注意力权重。
-
模态无关性:不预设图像/文本的优先级,完全依赖数据驱动学习。
-
(3) 预训练任务
-
图像-文本匹配(ITM):
- 二分类任务,判断图像和文本是否匹配。
-
掩码语言建模(MLM):
- 随机掩盖文本 Token,预测被掩盖的词(类似 BERT)。
-
掩码图像建模(MIM):
- 随机掩盖图像 Patches,预测被掩盖的像素(类似 MAE)。
技术创新与影响
- 简化流程:移除了预提取的视觉特征,大大简化了处理流程
- 计算效率:比之前的视觉-语言模型快10-100倍
- 端到端训练:整个模型可以从头到尾联合优化
- 性能与效率平衡:虽然性能可能略低于最先进模型,但效率大幅提升
资源友好:降低了计算和存储需求,使多模态模型更易于部署
ViLT代表了多模态模型架构简化的重要趋势,表明有效的模态融合不一定需要复杂的特征提取步骤,为后续更高效的多模态系统铺平了道路。
6. ViViT(Video Vision Transformer)
1. 背景与核心思想
-
背景:
ViViT(Video Vision Transformer)是一种基于Transformer架构的视频理解模型,扩展自Vision Transformer(ViT),专门用于处理视频数据。通过将视频分解为时空块并利用自注意力机制,ViViT能够有效捕捉视频中的时空特征,在多项视频任务中表现优异。 -
核心思想:
将视频划分为时空块序列,每个块作为Token输入Transformer,通过自注意力机制学习时空特征。关键挑战在于高效处理高维视频数据并降低计算复杂度。
2. 模型架构
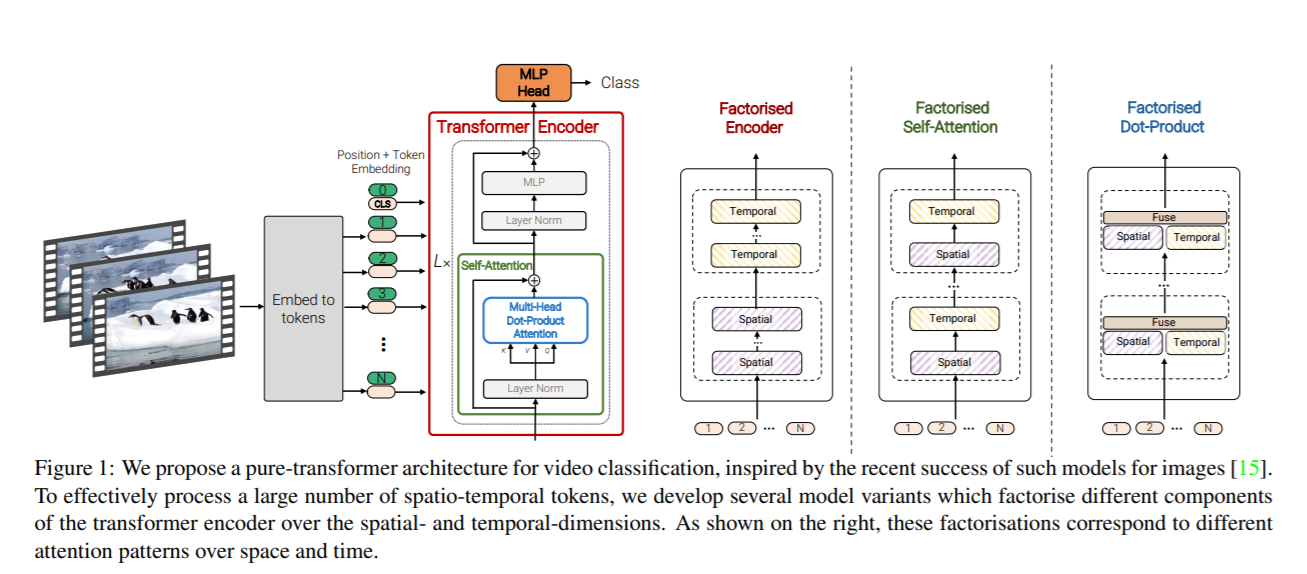
ViViT的设计围绕如何分解或联合建模时空信息,常见变体包括:
-
时空联合编码(Joint Space-Time Model)
- 将视频划分为时空立方体(如
T×H×W),展平为Token序列。 - 添加时空位置编码,输入Transformer编码器。
- 自注意力同时作用于时间和空间维度。
- 将视频划分为时空立方体(如
-
分解式编码(Factorized Encoder)
- 空间编码层:独立处理每帧图像,提取空间特征(类似ViT)。
- 时间编码层:在时间维度聚合各帧特征,捕捉时序关系。
- 优势:降低计算量,适合长视频。
-
分层时空注意力(Hierarchical Attention)
- 交替使用空间注意力和时间注意力层。
- 例如:先进行空间局部注意力,再在时间维度全局聚合。
3. 关键技术细节
-
输入处理:
- 视频分割为
T个片段,每片段采样N帧。 - 每帧切割为
P×P图像块,展平为向量,形成T×N×P²的Token序列。 - 位置编码:结合空间(x, y)和时间(t)坐标,通常使用可学习编码。
- 视频分割为
-
计算优化:
- 局部注意力:限制注意力范围(如局部时间窗口),减少计算量。
- 模型蒸馏:用预训练ViT初始化空间层,加速训练。
4. 训练与预训练策略
- 数据集:
- 常用Kinetics-400/600、Something-Something V2、HMDB-51等。
- 预训练:
- 图像预训练:空间层继承ViT权重(如ImageNet预训练)。
- 视频微调:在目标视频数据集上微调时空层。
- 训练技巧:
- 混合精度训练、梯度检查点降低显存占用。
- 数据增强:时间裁剪、帧随机采样、空间翻转等。
5. 应用场景
- 视频分类:识别动作类别(如“跑步”、“开门”)。
- 时序动作定位:检测视频中动作的起止时间。
- 视频分割:逐帧像素级预测(需解码器配合)。
- 多模态任务:结合音频、文本进行跨模态学习。
6. 性能与优缺点
-
优势:
- 长距离依赖建模能力强,适合复杂时序关系。
- 参数量低于3D CNN(如I3D),部分场景更高效。
- 在Kinetics-400等基准上达到SOTA(如ViViT-L/16x2精度达84.9%)。
-
局限性:
- 计算复杂度高(序列长度随帧数增长呈平方级增加)。
- 需要大规模数据,小数据集易过拟合。
8. 后续改进与变体
- TimeSformer:提出“分治”注意力(Divided Space-Time Attention),时空注意力分离,显著降低计算量。
- MViT(Multiscale Vision Transformer):引入多尺度特征金字塔,提升细粒度理解。
- X-ViT:结合可变形注意力,动态聚焦关键时空区域。
ViViT通过将Transformer引入视频领域,为视频理解任务提供了新范式。其核心在于时空Token化与自注意力机制的灵活结合,尽管面临计算复杂度挑战,但通过结构优化(如分解注意力、分层处理)和预训练策略,已在多个任务中证明有效性。未来方向可能包括轻量化设计、多模态融合及高效注意力机制的进一步探索。
7. DIT(Diffusion-based Image Transformer)
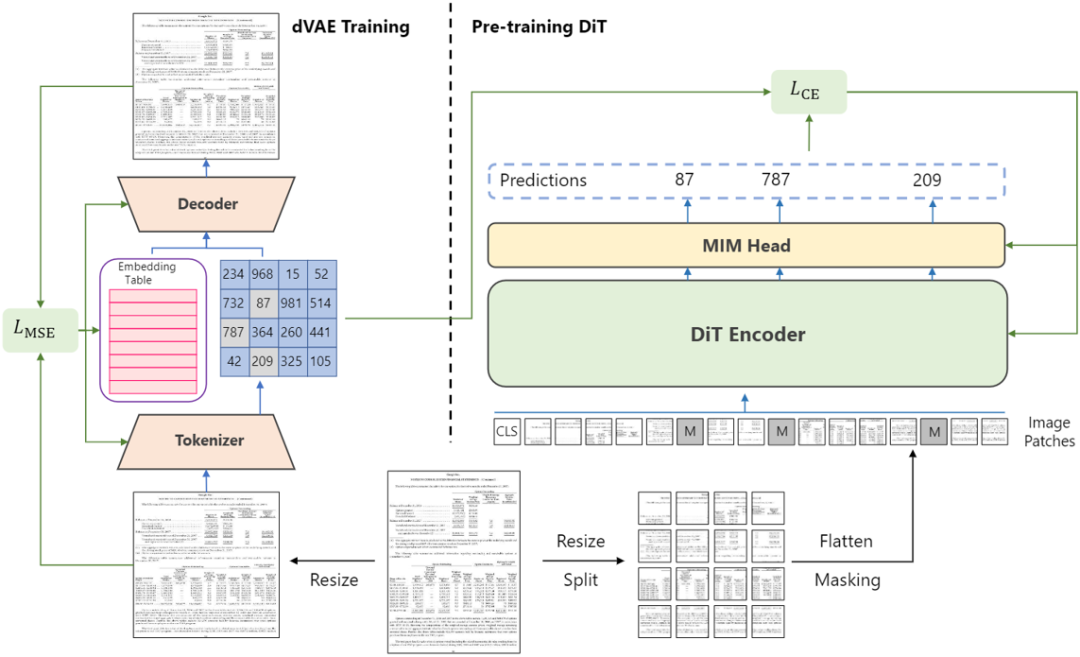
技术发展脉络
扩散模型的崛起
- 2015年:扩散模型(Diffusion Models)首次提出,但早期受限于训练效率和生成质量。
- 2020年:DDPM(Denoising Diffusion Probabilistic Models)通过改进训练目标,显著提升生成效果,成为主流框架。
- 2021年:OpenAI的GLIDE和DALL·E 2、Google的Imagen等模型将扩散模型与大规模预训练结合,实现高质量文本到图像生成。
- 核心架构:早期扩散模型多基于U-Net(卷积神经网络),擅长局部特征提取,但全局建模能力有限。
Transformer的视觉革命
- 2017年:Transformer在NLP领域(如BERT、GPT)大获成功。
- 2020年:Vision Transformer(ViT)证明Transformer可直接处理图像分块,替代CNN。
- 优势:自注意力机制捕捉全局依赖,模型扩展性强(参数量越大性能越好)。
DIT的诞生动机
为什么结合扩散模型与Transformer?
-
U-Net的局限性
- 依赖局部卷积操作,难以建模图像全局结构(如对称性、长距离关系)。
- 参数量扩展性差,难以通过单纯增加深度提升效果。
-
Transformer的潜力
- 自注意力机制天然适合处理图像分块间的全局关系。
- 模型规模与生成质量正相关(如Meta的DiT证明:参数量越大,FID指标越好)。
-
扩散模型的精细化需求
- 扩散过程需要逐步细化图像细节,而Transformer的并行处理能力可加速去噪过程。
- 在多模态任务(如文本+图像生成)中,Transformer更易融合跨模态信息。
1. 核心概念
- 扩散模型:通过逐步添加噪声破坏数据,再学习逆向去噪过程生成数据。
- Transformer架构:利用自注意力机制捕捉全局依赖关系,擅长处理长序列数据(如图像分块)。
- 结合优势:扩散模型生成细节丰富,Transformer增强全局结构一致性。
2. 工作原理
- 前向扩散
逐步向图像添加噪声,直至变为纯高斯噪声。 - 逆向去噪
- 输入:噪声图像 + 时间步嵌入
- 处理:Transformer预测当前噪声
- 输出:逐步去噪生成清晰图像
- 训练目标
最小化预测噪声与真实噪声的均方误差(MSE)。
3. 架构设计
- 图像分块
将图像分割为固定大小块(如16×16像素)。 - 位置编码
保留空间位置信息,嵌入至分块向量。 - Transformer Encoder
多层自注意力机制 + 前馈网络。 - 时间步融合
将扩散过程的时间步信息嵌入到注意力层。
4. 关键优势
✅ 高质量生成:扩散过程细化细节,Transformer保证全局结构
✅ 灵活扩展:支持动态调整模型深度与宽度
✅ 多任务适配:可用于生成、修复、超分辨率等任务
5. 应用场景
- 文本到图像生成(结合CLIP等模型)
- 图像修复与编辑(局部/全局修改)
- 视频生成(扩展至时序数据)
6. 挑战与优化
| 挑战 | 解决方案 |
|---|---|
| 高计算复杂度 | 稀疏注意力、分块并行计算 |
| 长序列训练不稳定 | 渐进式训练、梯度裁剪 |
| 生成速度慢(多步迭代) | 蒸馏技术、确定性采样加速 |
总结
DIT通过扩散模型与Transformer的深度融合,在生成质量与灵活性上取得突破,未来可能成为多模态生成任务的通用架构范式。