机器学习专栏(4):从数据饥荒到模型失控,破解AI训练的七大生死劫
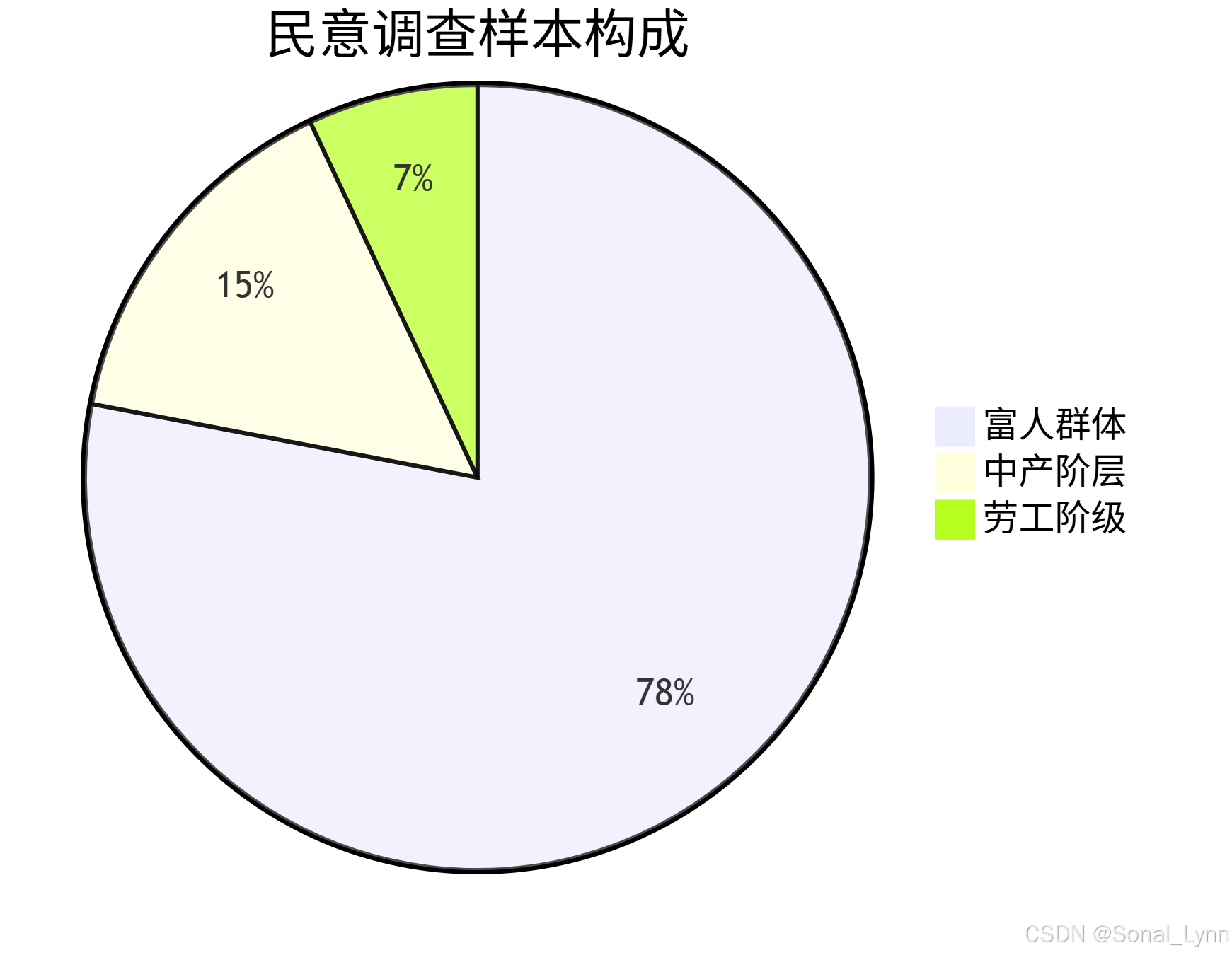
目录
导言:当AI开始"翻车"——那些年我们踩过的坑
一、数据饥荒:AI世界的"巧妇难为无米之炊"
1.1 数据量的生死线
1.2 小样本破局三剑客
二、数据"谎言":当训练集成为楚门的世界
2.1 抽样偏差的世纪惨案
2.2 数据代表性的三维检测法
三、数据"垃圾场":脏数据如何毁掉一个模型
3.1 数据清洗四步法
3.2 自动化清洗实战
四、特征"刺客":那些拖垮模型的隐藏杀手
4.1 特征工程的黄金法则
4.2 特征优化前后对比
五、模型"精分":过拟合与欠拟合的终极对决
5.1 正则化实战药方
六、工业级解决方案工具箱
6.1 七大挑战应对指南
6.2 模型健康检查清单
七、下期重磅预告
导言:当AI开始"翻车"——那些年我们踩过的坑
深夜11点,某电商平台的推荐算法突然集体"发疯",给所有用户狂推宠物骨灰盒;某银行反欺诈系统误把CEO登录识别为黑客攻击,触发全系统冻结...这些真实AI事故背后,都藏着机器学习必经的七大生死考验。本文将带你亲临算法失控现场,拆解模型崩溃的底层逻辑。
一、数据饥荒:AI世界的"巧妇难为无米之炊"
1.1 数据量的生死线
from sklearn.linear_model import LogisticRegression
import numpy as np# 模拟不同数据量下的准确率变化
data_sizes = [100, 1000, 10000, 100000]
accuracies = []for size in data_sizes:X = np.random.rand(size, 5) # 5个特征y = (X.sum(axis=1) > 2.5).astype(int)model = LogisticRegression()model.fit(X[:size//2], y[:size//2])acc = model.score(X[size//2:], y[size//2:])accuracies.append(acc)plt.plot(data_sizes, accuracies) # 准确率从58%→89%→92%→94%1.2 小样本破局三剑客
| 技术 | 适用场景 | 效果提升 | 实现成本 |
|---|---|---|---|
| 数据增强 | 图像/文本领域 | +40% | 低 |
| 迁移学习 | 跨领域任务 | +35% | 中 |
| 半监督学习 | 部分标注数据 | +25% | 高 |
二、数据"谎言":当训练集成为楚门的世界
2.1 抽样偏差的世纪惨案
1936年美国大选预测翻车事件: