运筹学之遗传算法
目录
- 一、历史
- 二、精髓思想
- 三、案例与代码
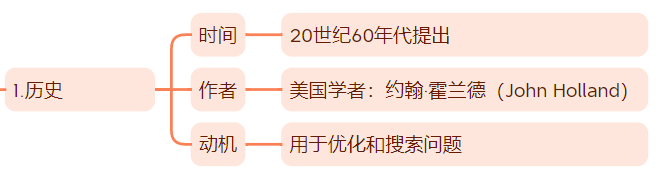
一、历史
- 问:谁在什么时候提出遗传算法?
- 答:遗传算法(Genetic Algorithm,简称 GA)最早是由美国学者 约翰·霍兰德(John Holland) 在 20世纪60年代 提出的,并在 1975年 通过其著作《Adaptation in Natural and Artificial Systems》中系统地加以阐述和推广。
二、精髓思想
一言以蔽之:模拟“优胜劣汰,适者生存”的自然进化机制,利用群体搜索和随机性,在解空间中寻找最优解。

总结下来就是4个step:
- 选择:随机初始化种群
- 淘汰:取其精华(精英)
- 交叉:顺序交叉,繁衍后代
- 变异:基因突变,跳出局部最优
三、案例与代码
-
题干:
6艘船靠3个港口,已知达到时间arrival和卸货时长handling,求最优停靠方案,即等待时长最短。 -
数据:
ships = {'S1': {'arrival': 0.1, 'handling': 4},'S2': {'arrival': 2.1, 'handling': 3},'S3': {'arrival': 4.2, 'handling': 2},'S4': {'arrival': 6.3, 'handling': 3},'S5': {'arrival': 5.5, 'handling': 2},'S6': {'arrival': 3.9, 'handling': 4},'S7': {'arrival': 3.7, 'handling': 4},'S8': {'arrival': 3.4, 'handling': 4},
}
- 实现:
step1:选择,初始化种群
针对此问题,个体代表一种所有船舶靠港顺序方案,初始化种群就是随机初始化这些个体(方案),换个说法也可称为染色体编码。
POP_SIZE = 20 # 种群数(方案数)
SHIP_IDS = list(ships.keys()) # 船名
population = [random.sample(SHIP_IDS, len(SHIP_IDS)) for _ in range(POP_SIZE)]
print(population)
# [['S4', 'S2', 'S6', 'S8', 'S5', 'S3', 'S7', 'S1'], ['S7', 'S8', 'S4', 'S5', 'S1', 'S2', 'S6', 'S3'], ...]
step2:淘汰,取其精华(精英)
什么叫做精华(精英)?
针对个体(所有船舶靠港顺序方案),能够使得等待时间最小的才是精华!称之为评估函数或者适应度函数,如下:
NUM_BERTHS = 3 # 泊位数
# 评估或者自适应函数
# individual(个体) ['S4', 'S2', 'S6', 'S8', 'S5', 'S3', 'S7', 'S1']
def evaluate(individual):berth_times = [0] * NUM_BERTHS # 港口可用时间total_wait = 0 # 总等待时间for ship_id in individual:arrival = ships[ship_id]['arrival']handling = ships[ship_id]['handling']# 找一个最早可用泊位:遍历所有泊位索引,计算i泊位的可用时间 = max(到达时间,泊位可用时间),然后对所有泊位取最小那个berth_index = min(range(NUM_BERTHS), key=lambda i: max(arrival, berth_times[i])) # 泊位# start_time = 开始卸货时间 = max(到达时间, 泊位可用时间)。# 解释:要卸货的话,船先到达了没有泊位可用也得等,反之,有空泊位了船还没到也得等。start_time = max(arrival, berth_times[berth_index])wait_time = start_time - arrival # 等待时间 = 开始卸货时间 - 船到达时间total_wait += wait_timeberth_times[berth_index] = start_time + handling # 泊位占用时间 = 开始卸货时间 + 卸货时长return -total_wait # 越大越好(负等待时间)
接下来就选择前4名精英!如下:
population.sort(key=lambda x: evaluate(x), reverse=True)
next_gen = population[:4] # 精英保留
以上就选出来这一世代的前四强了!
step3:交叉,顺序交叉,繁衍后代
既然大家都是精英,能不能优秀部分互相换一换,例如有人颜值很高但身高不那么高,有人身材很棒但是不是特别漂亮,换一换说不定就有完美人类。对,就是杂交!
def crossover(parent1, parent2):size = len(parent1) # parent1的长度a, b = sorted(random.sample(range(size), 2)) # 随机截取的索引范围,升序排列child = [None] * size # 初始化新的childchild[a:b] = parent1[a:b] # 片段复制过去# 然后其他部分用parent2部分填充fill = [item for item in parent2 if item not in child]idx = 0for i in range(size):if child[i] is None:child[i] = fill[idx]idx += 1return child
step4:变异,基因突变,跳出局部最优
杂交还不够,还需要变异!变着变着或者就出现超级赛亚人了呢!
怎么个变异法?随机交换两个基因位置!
def mutate(individual):a, b = random.sample(range(len(individual)), 2)individual[a], individual[b] = individual[b], individual[a]
这就是遗传算法的全部了!
想要进化多少代,完全由你决定。
变异多不多,完全由你决定。
MAX_GEN = 50 # 最大世代
MUT_RATE = 0.2 # 变异率# 进化
def evolution():for generation in range(MAX_GEN):population.sort(key=lambda x: evaluate(x), reverse=True)next_gen = population[:4] # 精英保留while len(next_gen) < POP_SIZE:parents = random.choices(population[:10], k=2)child = crossover(parents[0], parents[1])if random.random() < MUT_RATE:mutate(child)next_gen.append(child)population = next_gen# 遗传算法结果:
# 最优调度顺序: ['S8', 'S1', 'S2', 'S3', 'S5', 'S6', 'S7', 'S4']
# 最小总等待时间: 7.2 小时 结果每次不一定一样哦