基础学习:(6)nanoGPT
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 1 nanoGPT 浅尝
- 1.1 基础环境
- 1.2 prepare.py
- 1.2 train.py
- 1.3 sample.py
- 2 再探gpt
- 2.1 layer_norm
- 2.2 KQV 和 self attention
- 2.3 masked self-attention
- 2.4 调用构架
- 2.5 Pre-Ln
- 2.6 Encoder & Decoder
前言
看到一个很火的学习开源项目 nano gpt,换换思维,学习下nano gpt
这是我个人仓库,里面很多内容已经build 好,如果有不对的也欢迎大家指正.
我个人非常喜欢<斗破苍穹>, 因此用了土豆老师的斗破苍穹的小说作为训练样本(非商业用途),如有不敬书迷给你磕一个.

1 nanoGPT 浅尝
1.1 基础环境
(1) 仓库地址:https://github.com/MexWayne/mexwayne_nanoGPT
(2) 仓库环境: 见 transformer_env.txt
(3) 训练: python train.py config/train_doupocangqiong_char.py
(4) 推理: python sample.py --init_from=resume --start=“介绍小医仙” --num_samples=5 --max_new_tokens=200
(5) onnx 模型: 用 pt2onnx.py 生成
1.2 prepare.py
prepare.py 是为了将小说数据拆为训练数据和验证数据
(1) 将小说放到input.txt 中.
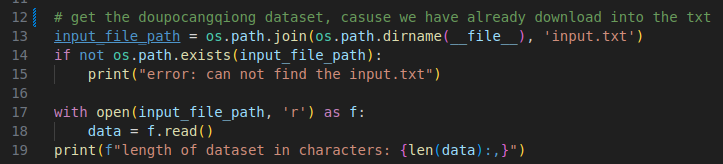
(2) 运行: python data/doupocangqiong_char/prepare.py
prepare过程会将文字进行编码

这里用了set 将重复的char 去掉, 得到字符集合
 真正的小说肯定没有乱字符,我这里因为是我网上爬的,所以先将就.这个字典信息会保留到 meta.pkl(pickle) 中.
真正的小说肯定没有乱字符,我这里因为是我网上爬的,所以先将就.这个字典信息会保留到 meta.pkl(pickle) 中.
(3) 将小说的0%-90% 将小说的90%-100%部分作为验证数据
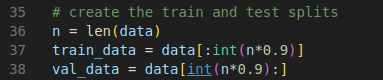
接着将小说的中欧给你的字符串根据set 进行编码.
 于是有
于是有
(3) encode 和 decode 函数
比较简陋

将训练集和测试集用encode转为网络认识的bin文件
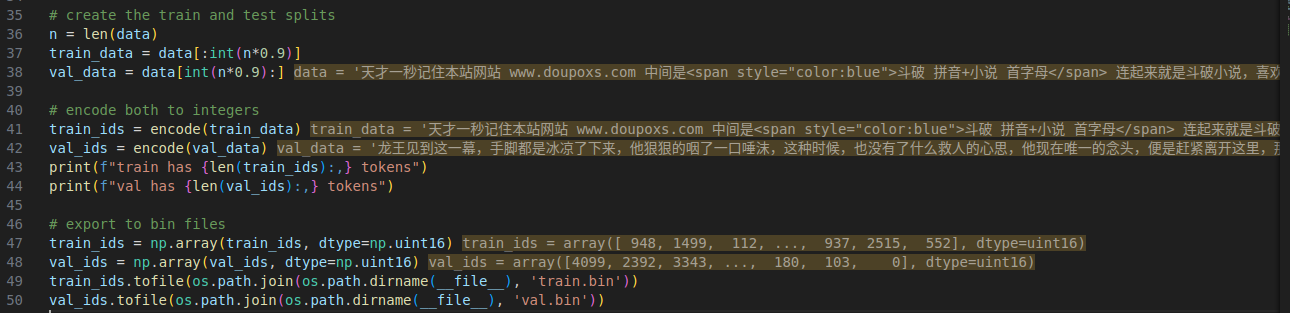
最终将其保存在 meta.pkl 中
1.2 train.py
(1) 这里有个默认的训练设置,scractch 是 从头, resume 是 继续上一次训练, gpt2 是基于gpt2

(2) wandb 很常见就是做可视化的,我这里用的默认

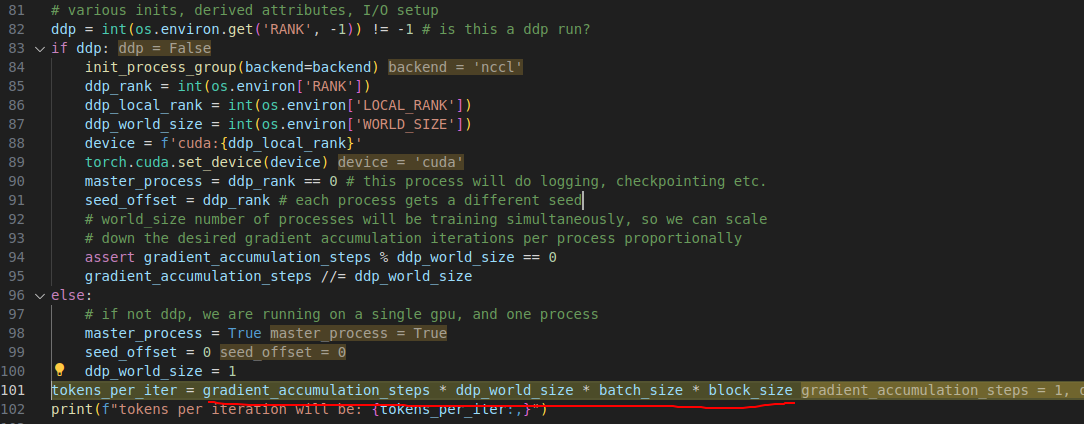
(3) nanogpt 这里很细节, 我们batch大小越大越好,我的实践经验是这样loss 下降的比较快,且训练的结果要强于batch 小的情况,但是我的 4070ti 就12g 显存, 一次读不下太大的batch 所以只能算一点一点算,然后积累到一个 batch 后,更新一次optimizer,这样看起来就像是用个大batch.
配置1个gradient_accumulation_steps 为40, batch size 为 12. block_size = 1024
相当于gradient_accumulation_steps * batch_size * block_size 大小的数据(也就是40 * 12 = 480 个样本)才更新一次

(4) 这里到了 配置 gpt 的模型

但是我这里将生成的模型保存后转为onnx 发现只有6层
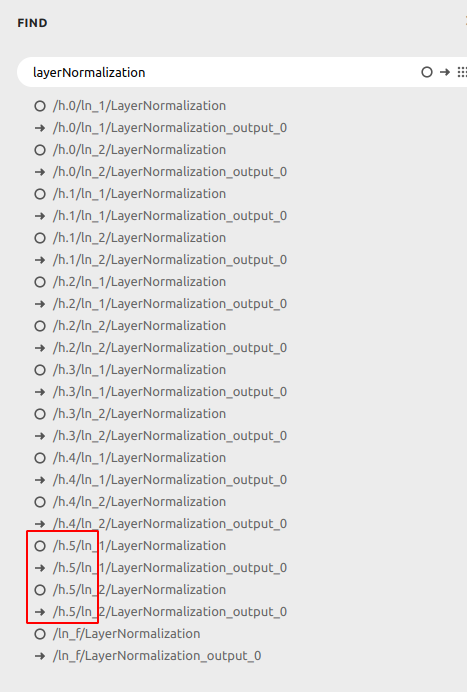
通过如下方式进行打印,也是只有6层,少了一半

看了下代码,发现这里会重写
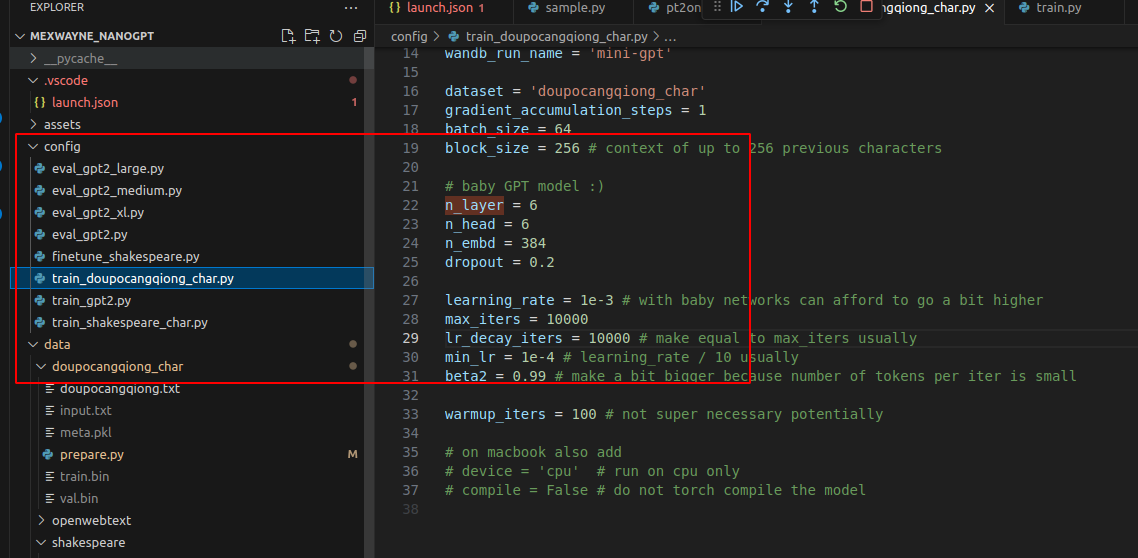
修改后键入: python train.py config/train_doupocangqiong_char.py
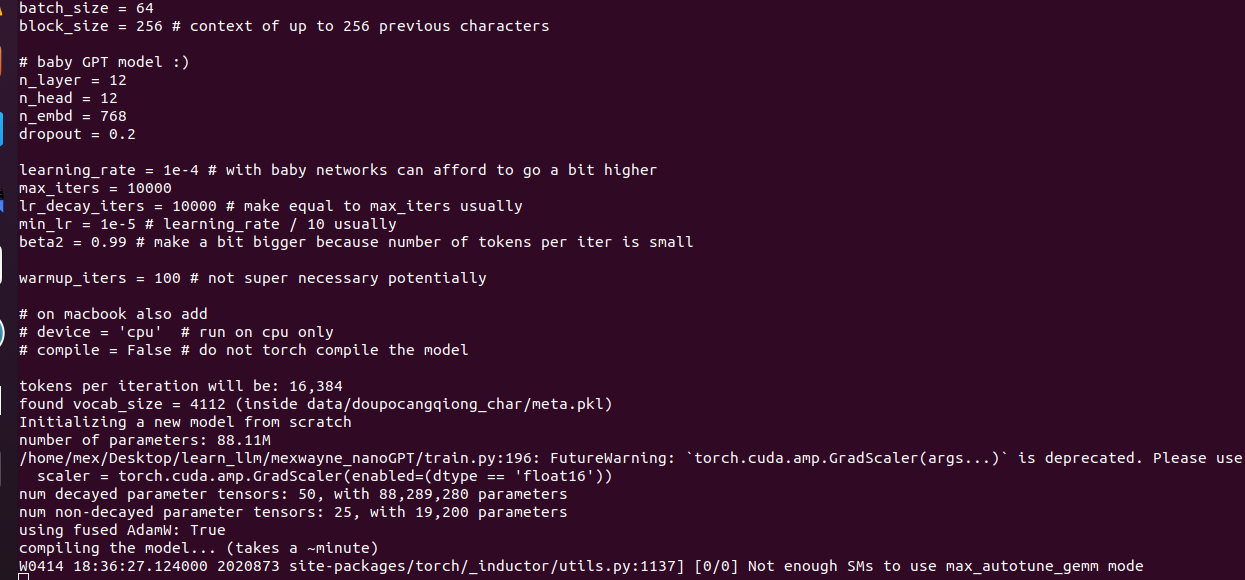
改了后就对了
(4) DistributedDataParallel(DDP)
多卡多机训练为false因为我就一张卡.
这里的一个iter 训练大小也符合之前本文前面的公式
(5) build gpt 模型
这里也很制式化,就是设计好layernorm 等结构的参数,传入后训练即可
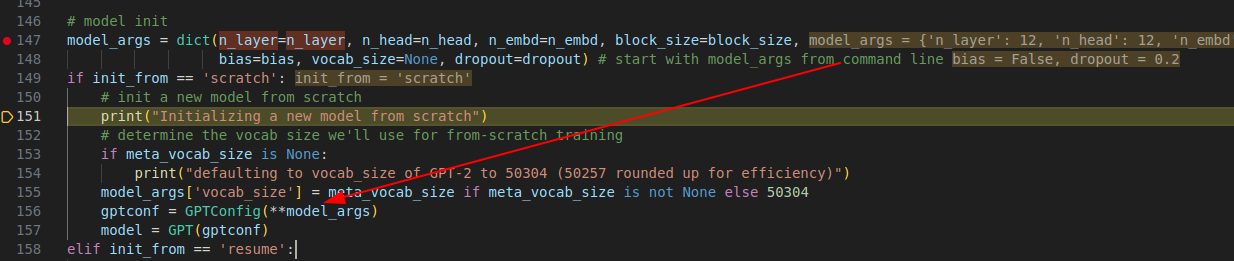
(6)model的size 大于模型的size 需要剪裁,最大就是1024,是我们配置好的

(7)混合精度训练—满满的细节

(8) 优化器

weight_decay L2 正则项系数(防止过拟合)
learning_rate 学习率,我一直理解为步长
(beta1, beta2) AdamW 的动量超参数 详见 adamw,我就不多说
device_type 设备类型, 这里是 cuda就是gpu
(9)开启图编译优化

这里不得不说下, 因为编译好的算子都是一个节点,进而将一个网络通过图论思想建立为一个有向或者无向图
根据当前任务,部分算子可以融合或者并行优化或者直接利用硬件加速,满满的细节.
(9) eval_loss
有之前配置,每250步算一次loss,每次计算loss 需要200个batch
这里也是满满的细节,我之前训练降噪,顶多是用指数下降,这里是先
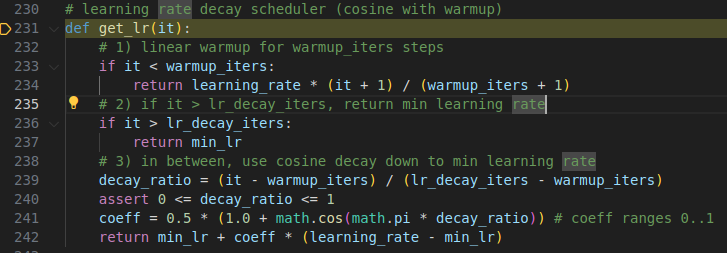
这里是分三段,地一段热身: 学习率线性上升. 第二阶段:中间cos 阶段,用 0~1来控制,最后一个阶段 decay,这个阶段就是最小学习率等步长走. 全是细节.看了下,先线性升高(warmup),再使用余弦函数平滑下降(cosine decay),最后保持最低值,Transformer 训练的标准做法。如下示意图
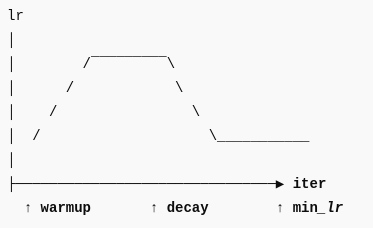
(10) train主体
注意这里有个细节
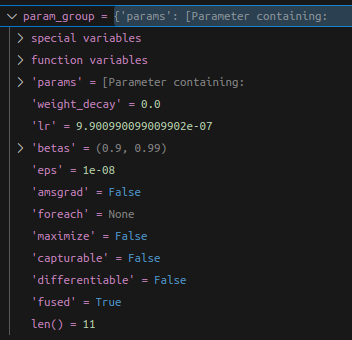
optimizer = torch.optim.AdamW([{'params': model.backbone.parameters(), 'lr': 1e-4},{'params': model.head.parameters(), 'lr': 5e-4},
])
每次计算完不同阶段的 loss rate 后喂给 backbone和head 的都是 相同 lr,其实不是,查了下网上,这里可以用相同的学习率 且不是 backbone 和 head 而是一组加 weight decay,另一组不加.
optimizer = AdamW([{"params": decay_params, "weight_decay": 0.1},{"params": no_decay_params, "weight_decay": 0.0}
], lr=6e-4)
哪些情况下要用不一样的 lr?
- 使用预训练 + 微调(fine-tuning):
预训练层(backbone)设低 lr
微调新加的输出层(head)设高 lr - 做 multi-stage training / layer-wise lr decay
- 训练 GAN、diffusion 等复杂结构
(11) 40个小batch+前向传播 + 反向传播 + 梯度累积 + 梯度裁剪 + 参数更新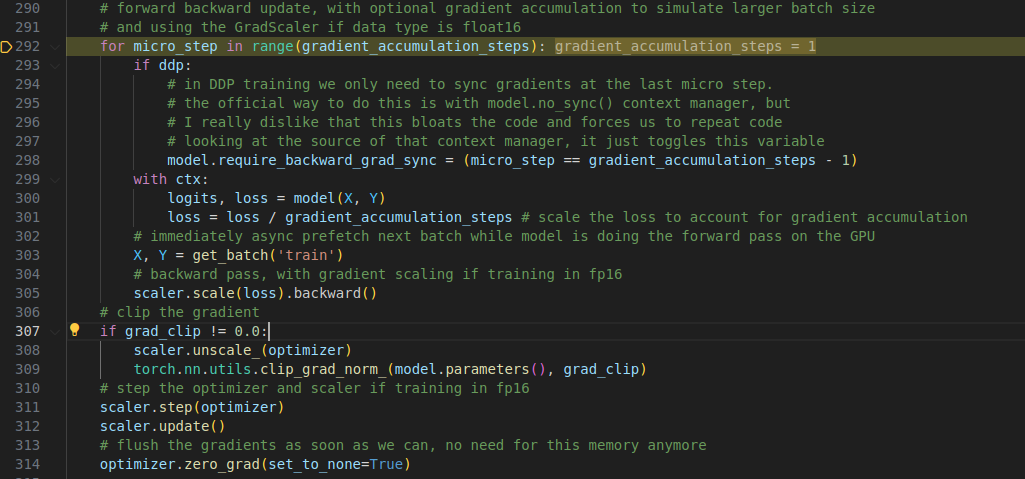
40个小batch
range(gradient_accumulation_steps): 这里gradient_accumulation_steps=40
用于 模拟大 batch(显存不够)
将多个小 batch 梯度累积后再更新参数
比如:你设置了 gradient_accumulation_steps = 40,那么每次训练就会累积 40 个 小batch后,再更新一次参数相当于更新了一次大batch.
ddp的训练按照 最后一次通信的计算— 这个是制式的,我每次照抄.
前向传播
前向传播是通过过了 model 得到的 loss 是40个小batch 中的一个,所以要除以gradient_accumulation_steps 才是正确的 loss
with ctx 是采用了混合精度.
预取
get_batch 是预取下一次batch, 类似优化常用的ping-pong 操作
反向传播
使用 AMP 训练(float16)时:
scaler.scale() 会把 loss 放大,避免梯度 underflow(过小变 0)然后 backward() 会传播放大后的梯度
40次循环结束后
梯度剪裁:
必须先 unscale_(),因为上一步的梯度是放大过的, 然后 执行 torch.nn.utils.clip_grad_norm_(model.parameters(), grad_clip) 进行梯度剪裁防止梯度爆炸大模型训练经常需要
梯度更新
略
(12)都是logging 略
1.3 sample.py
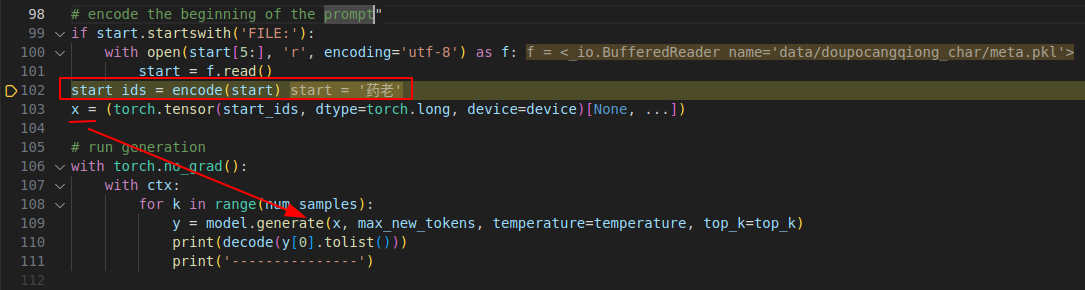
sample 其实就是 inference
这里的 start 就是 q k v 的 query , 但需要 将其 encode 再经过embedding.

下图可以看到 送给 gpt 的 foward
2 再探gpt
上面第一章,摸清了基本运行代码,下面我们深入探究
2.1 layer_norm
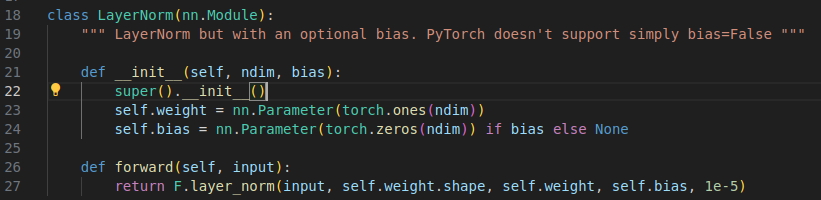
代码比较制式, 讲layer norm详细内容见:https://blog.csdn.net/mikhailbran/article/details/147249369?spm=1001.2014.3001.5501
2.2 KQV 和 self attention
这个 self attention是 gpt 的核心之一,网上讲解巨多无比,我这里列下公式,方便讲解.
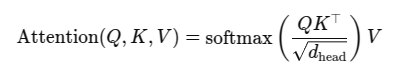
nanogpt也给出了标准过程
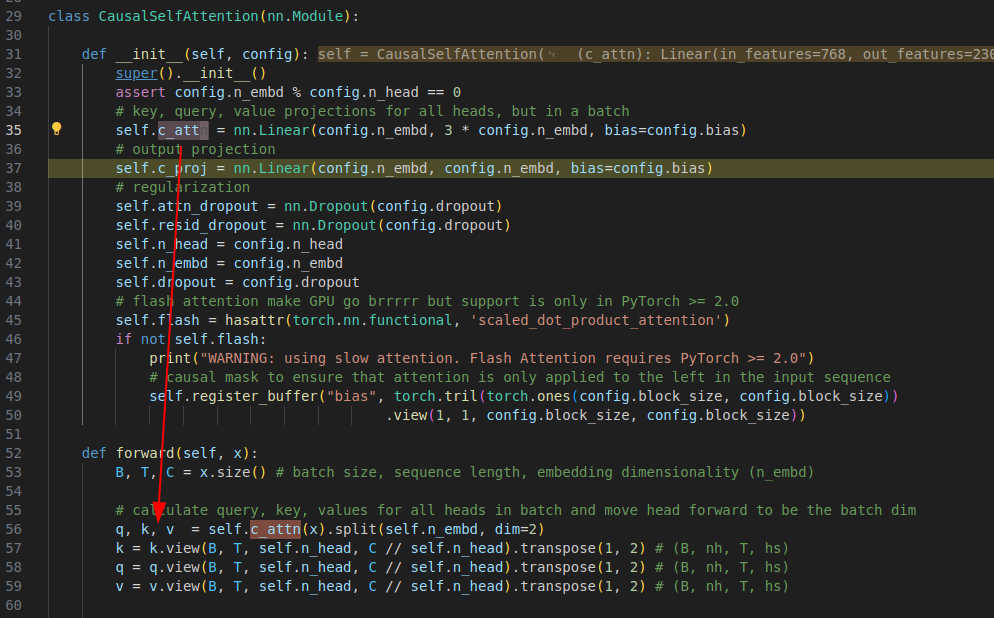
37行一次生成了 3 * n_embd 数据即 qkv 数据. 是为下图过程做准备,因为nn.Linear 就是计算 xw + b, b 是偏移,这里没有.所以就是 xw. 所以我们就的到 QKV.
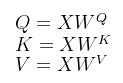
45行是判断是否开启了 flash attention,详细见链接:https://blog.csdn.net/mikhailbran/article/details/140446863?spm=1001.2014.3001.5501
nanogpt 是开启的.
2.3 masked self-attention
这里有个 很细节的地方,因为我们默认开了 flash attention, 虽然没有 attn_mask, 但是有了casual_mask, 网上查了下这个是下三角mask
y = torch.nn.functional.scaled_dot_product_attention(q, k, v, attn_mask=None, dropout_p=self.dropout if self.training else 0, is_causal=True)
代码中的 is_causal 就是 mask
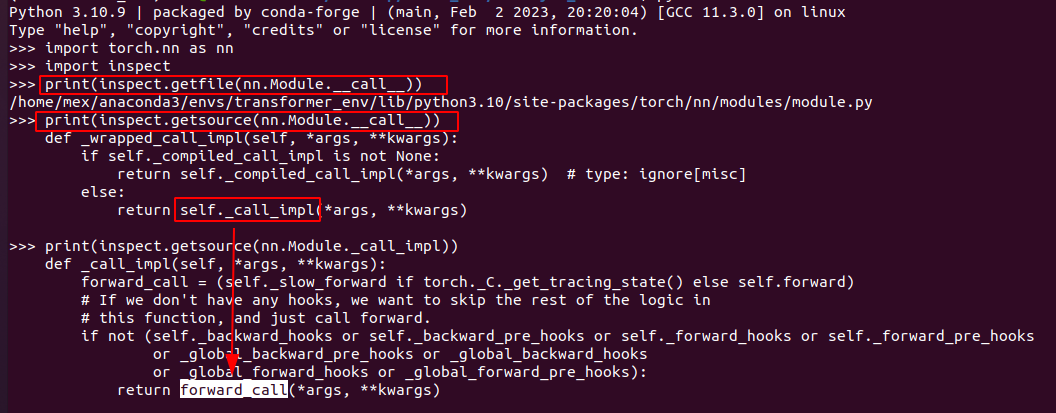
2.4 调用构架
这里代码非常清晰,结构关系如下图

注意这里有个小trick, 之前见过, 这里顺带看了下 gpt 也是一样的.
2.5 Pre-Ln
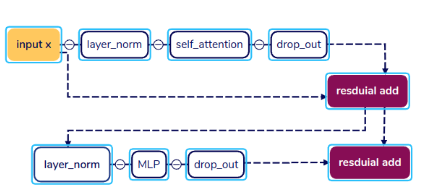
看到这里我还有点懵: nanogpt 是 input -> layerNorm-> atten->layer_norm->mlp->output. 论文里是:
input -> atten->layer_norm->mlp->layerNorm-> output. 后来查了下,nanogpt 是 Pre-LN 架构而 论文中是Post-LN.
Pre-LN 构架有如下优点:
(1)更稳定 在训练深层模型时,Pre-LN 不容易梯度爆炸或消失
(2) 更容易收敛 特别是在长序列或超大模型下(GPT-3、GPT-4 都用)
(3) 实现更优雅 结构更统一,不需要太多调参技巧
在《On Layer Normalization in the Transformer Architecture》(2020)以及 GPT-3 论文《Language Models are Few-Shot Learners》附录 B 以及《A Primer in BERTology: What we know about how BERT works》三个文章中 都 强调了 LayerNorm 的位置影响很大. 下图左侧是论文示意图,右边是nanogpt 示意图.
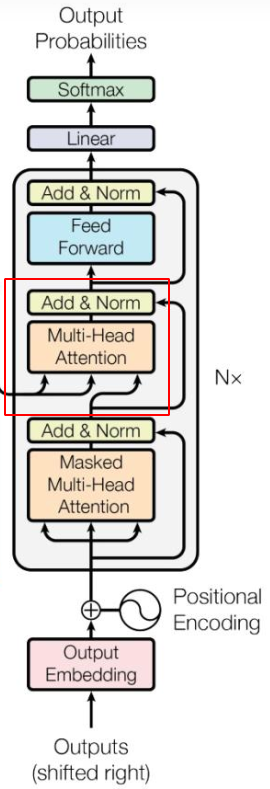
注意这里,原论文中decoder 是有三个 layer norm, 而nano gpt 只有两个,原因是因为没有encoder ,所以接受来自encoder 的 layernorm就去掉了.可以看到nanogpt 是下图逻辑.
2.6 Encoder & Decoder
看论文的时候我们发现, 结构是 encoder 和 decoder. 但是nanogpt 中只有decoder.而且我在第一章的实践中,你不难发现 nanogpt 给一个输出,并给一段可能的后面链接的输出.你可看到我输入的问题, 其实我想要的是nanogpt读懂小说并回答我的问题, 说白了就是预测token 也就是一个 自回归语言模型(CLM)
| 模块 | 作用 | 用于什么任务? |
|---|---|---|
| Encoder | 编码输入信息(如一整段文字) | 翻译、问答、分类等 |
| Decoder | 一边看前文,一边逐步生成目标语言输出 | 生成任务,如翻译输出句子、对话、生成文本 |
结合之前我使用过的 bert, 再进行比较
| 模型类型 | Attention 类型 | Encoder 结构 | Decoder 结构 |
|---|---|---|---|
| 原始 Transformer | Self + Cross Attention | 有 | 有 |
| BERT | Self Attention | 有 | 没有 |
| GPT / GPT-2 / NanoGPT | Masked Self Attention | 没有 | 部分 |
至此, nanogpt 工程基本过了一遍