PyTorch - Tensor 学习笔记
上层链接:PyTorch 学习笔记-CSDN博客
Tensor
初始化Tensor
import torch
import numpy as np# 1、直接从数据创建张量。数据类型是自动推断的
data = [[1, 2],[3, 4]]
x_data = torch.tensor(data)torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
''' 输出:
tensor([[2, 1, 4, 3],[1, 2, 3, 4],[4, 3, 2, 1]])
'''# 2、从 NumPy 数组创建张量(反之亦然)
np_array = np.array(data)
x_np = torch.from_numpy(np_array)3、从另一个张量创建:
# 从另一个张量创建张量,新张量保留参数张量的属性(形状、数据类型),除非显式覆盖
x_ones = torch.ones_like(x_data) # retains the properties of x_data 保留原有属性
print(f"Ones Tensor: \n {x_ones} \n")x_rand = torch.rand_like(x_data, dtype=torch.float) # overrides the datatype of x_data 覆盖原有类型
print(f"Random Tensor: \n {x_rand} \n") 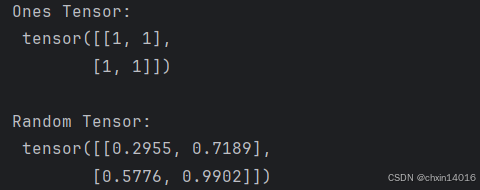
4、使用随机值或常量值:(三个皆是数据类型默认为浮点型(torch.float32))
# 使用随机值或常量值创建张量:
shape = (2,3,) # shape是张量维度的元组,确定输出张量的维数
rand_tensor = torch.rand(shape) # 元素为 [0, 1) 中的随机浮点型,
ones_tensor = torch.ones(shape) # 元素为全 1
zeros_tensor = torch.zeros(shape) # 元素为全 0print(f"Random Tensor: \n {rand_tensor} \n")
print(f"Ones Tensor: \n {ones_tensor} \n")
print(f"Zeros Tensor: \n {zeros_tensor}")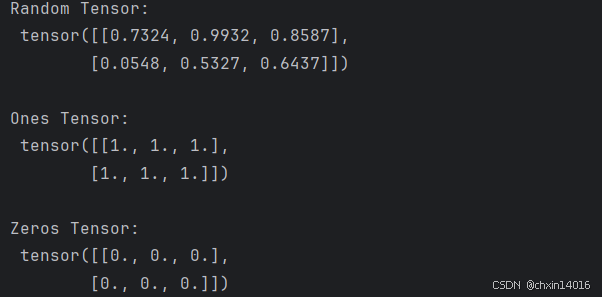
torch.zeros((2, 3, 4))
''' 输出:
tensor([[[0., 0., 0., 0.],[0., 0., 0., 0.],[0., 0., 0., 0.]],[[0., 0., 0., 0.],[0., 0., 0., 0.],[0., 0., 0., 0.]]])
'''torch.ones((2, 3, 4))
''' 输出:
tensor([[[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.]],[[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.]]])
'''若想指定生成其他数据类型的张量,可以通过
dtype参数显式指定。例如:# 整数类型 rand_tensor_int = torch.rand((2, 3), dtype=torch.int32) print(rand_tensor_int.dtype) # 输出: torch.int32# 双精度浮点型 ones_tensor_double = torch.ones((2, 3), dtype=torch.float64) print(ones_tensor_double.dtype) # 输出: torch.float64
动手学深度学习的内容
x = torch.arange(12) # 创建行向量 x,其包含以0开始的前12个整数,默认创建为整数
# 除非额外指定,新的张量将存储在内存中,并采用基于CPU的计算。
# 输出:tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])x.shape # 访问张量(沿每个轴的长度)的形状
# 输出:torch.Size([12])x.numel() # 张量中元素的总数,即形状的所有元素乘积,可以检查它的大小(size)。因为这里在处理的是一个向量,所以它的shape与它的size相同
# 输出:12X = x.reshape(3, 4) # 改变张量的形状,而不改变其元素数量和元素值。
'''
把张量x从形状为(12,)的行向量转换为形状为(3,4)的矩阵。
这个新的张量包含与转换前相同的值,但是它被看成一个3行4列的矩阵。
重点说明:虽然张量的形状发生了改变,但其元素值并没有变。
注意,通过改变张量的形状,张量的大小不会改变。
输出:
tensor([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
'''属性
Tensor 属性描述其形状、数据类型和存储它们的设备
tensor = torch.rand(3,4)
print(f"Shape of tensor: {tensor.shape}") # 形状
print(f"Datatype of tensor: {tensor.dtype}") # 数据类型
print(f"Device tensor is stored on: {tensor.device}") # 存储其的设备
操作(形状相同的两个矩阵)
索引和切片:(类似 numpy )
tensor = torch.ones(4, 4)
# tensor = torch.tensor([[1, 2, 3, 4],
# [5, 6, 7, 8],
# [9, 10, 11, 12],
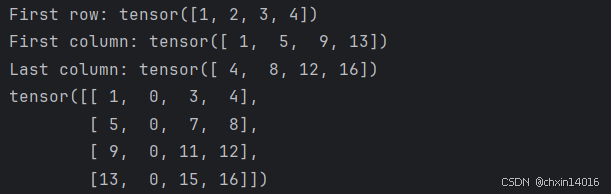
# [13, 14, 15, 16]])print(f"First row: {tensor[0]}")
print(f"First column: {tensor[:, 0]}")
print(f"Last column: {tensor[..., -1]}")
tensor[:,1] = 0
print(tensor)
与任何Python数组一样:第一个元素的索引是0,最后一个元素索引是-1; 可以指定范围以包含第一个元素和最后一个之前的元素,即。
x = torch.arange(12) # 创建行向量 x,其包含以0开始的前12个整数,默认创建为整数
# 除非额外指定,新的张量将存储在内存中,并采用基于CPU的计算。
# 输出:tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])X = x.reshape(3, 4) # 改变张量的形状,而不改变其元素数量和元素值。
'''
把张量x从形状为(12,)的行向量转换为形状为(3,4)的矩阵。
这个新的张量包含与转换前相同的值,但是它被看成一个3行4列的矩阵。
重点说明:虽然张量的形状发生了改变,但其元素值并没有变。
注意,通过改变张量的形状,张量的大小不会改变。
输出:
tensor([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
'''X[-1], X[1:3] # [-1]选择最后一个元素,[1:3]选择第二个和第三个元素
'''
(tensor([ 8., 9., 10., 11.]),tensor([[ 4., 5., 6., 7.],[ 8., 9., 10., 11.]]))
'''X[1, 2] = 9 # 指定索引第二行第三列,将元素9写入矩阵
'''
array([[ 0., 1., 2., 3.],[ 4., 5., 9., 7.],[ 8., 9., 10., 11.]])
'''# 多个元素赋值相同的值
X[0:2, :] = 12 # [0:2, :]访问第1行和第2行,其中“:”代表沿轴1(列)的所有元素
'''
array([[12., 12., 12., 12.],[12., 12., 12., 12.],[ 8., 9., 10., 11.]])
'''torch.cat() 拼接张量 (沿给定维度连接一系列张量)。
另请参见 torch.stack, 另一个与 . 略有不同的 Tensor Joining 运算符。torch.cattorch.cat
'''
dim=1 :沿着第 1 维(通常是列)进行拼接
如果 tensor 的形状是 (a, b),
则沿着第 1 维拼接三次后,结果张量 t1 的形状将是 (a, b * 3)。
'''
t1 = torch.cat([tensor, tensor, tensor], dim=1) # 沿着第 1 维拼接三次
print(t1)

- 沿行连结(轴-0,形状的第一个元素)
- 按列连结(轴-1,形状的第二个元素)
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
torch.cat((X, Y), dim=0), torch.cat((X, Y), dim=1)
''' 输出:
(tensor([[ 0., 1., 2., 3.],[ 4., 5., 6., 7.],[ 8., 9., 10., 11.],[ 2., 1., 4., 3.],[ 1., 2., 3., 4.],[ 4., 3., 2., 1.]]),tensor([[ 0., 1., 2., 3., 2., 1., 4., 3.],[ 4., 5., 6., 7., 1., 2., 3., 4.],[ 8., 9., 10., 11., 4., 3., 2., 1.]]))
'''单个张量 (tensor.sum()求和 & 转int/float)
.sum() 聚合所有 值转换为一个值;.item() 将其转换为 Python 数值使用。
agg = tensor.sum() # 所有元素求和,返回新的张量(标量张量)
agg_item = agg.item() # 将标量张量agg转成Python的基本数据类型(如float或int,具体取决于张量中数据的类型)
print(agg_item, type(agg_item))# 输出 agg的值为 tensor(12.)![]()
In-place 操作
add_是一个 in-place 操作,会直接修改原张量tensor的值,而不会创建新的张量。- 若不想修改原张量,可使用非 in-place 操作
tensor + 5,这样会返回一个新的张量,而原张量保持不变。
# 使用 in-place 操作对张量中的每个元素加 5
print(f"{tensor} \n")
tensor.add_(5) # add_ 是 in-place 操作,会直接修改原张量
print(tensor)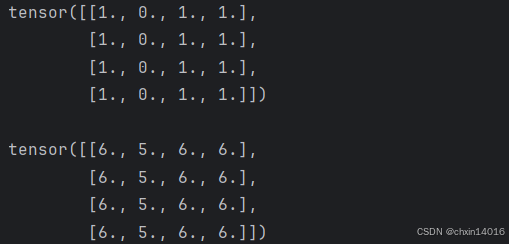
in-place 的优缺点
优点:节省内存。(直接在原张量上操作,避免额外分配内存)
缺点:因为是直接修改原数据,会丢失历史记录,因此不鼓励使用。
算术运算
矩阵乘法 和 元素积(逐元素乘积)
计算两张量间的 矩阵乘法 和 元素积(逐元素乘积)
# 计算两个张量间的矩阵乘法
# This computes the matrix multiplication between two tensors. y1, y2, y3 will have the same value
# ``tensor.T`` 返回张量的转置 returns the transpose of a tensor
y1 = tensor @ tensor.T # “@”是矩阵乘法的简写,用于张量之间的矩阵乘法; tensor.T 返回 tensor 的转置
y2 = tensor.matmul(tensor.T) # matmul用于矩阵乘法,与 @ 功能等价y3 = torch.rand_like(y1) # 创建与 y1 形状相同的新张量,元素为随机值
torch.matmul(tensor, tensor.T, out=y3) # 进行矩阵乘法,并将结果存储在 y3 中print("Matrix Multiplication Results:") # y1, y2, y3 三者相等
print("y1:\n", y1)
print("y2:\n", y2)
print("y3:\n", y3)# 计算元素积
# This computes the element-wise product. z1, z2, z3 will have the same value
z1 = tensor * tensor # 对 tensor 进行逐元素相乘
z2 = tensor.mul(tensor) # 与 * 相同的逐元素相乘z3 = torch.rand_like(tensor)
torch.mul(tensor, tensor, out=z3) # 使用 torch.mul 函数对 tensor 进行逐元素相乘,并将结果存储在 z3 中print("\nElement-wise Product Results:") # z1, z2, z3 三者相等
print("z1:\n", z1)
print("z2:\n", z2)
print("z3:\n", z3)
按元素操作 (加减乘除 **幂 等)
对于任意具有相同形状的张量, 常见的标准算术运算符(+、-、*、/和**)都可以被升级为按元素运算。 我们可以在同一形状的任意两个张量上调用按元素操作。
在下面的例子中,使用逗号来表示一个具有5个元素的元组,其中每个元素都是按元素操作的结果。
x = torch.tensor([1.0, 2, 4, 8])
y = torch.tensor([2, 2, 2, 2])
x + y, x - y, x * y, x / y, x ** y # **运算符是求幂运算
''' 输出:
(tensor([ 3., 4., 6., 10.]),tensor([-1., 0., 2., 6.]),tensor([ 2., 4., 8., 16.]),tensor([0.5000, 1.0000, 2.0000, 4.0000]),tensor([ 1., 4., 16., 64.]))
'''逻辑运算符构建二元张量
以X == Y为例: 对于每个位置,如果X和Y在该位置相等,则新张量中相应项的值为1。 这意味着逻辑语句X == Y在该位置处为真,否则该位置为0。
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
X == Y
''' 输出:
tensor([[False, True, False, True],[False, False, False, False],[False, False, False, False]])
'''torch.exp() 对张量中每个元素计算自然指数
“按元素”方式可以应用更多的计算,包括像求幂这样的一元运算符:
用于对张量中每个元素计算自然指数函数 的函数,常用于 实现 softmax、log-normalization、指数增长建模 等场景:
对输入张量中的每个元素 执行:
其中
import torch
x = torch.tensor([1.0, 2, 4, 8])
torch.exp(x)
''' 输出:
tensor([2.7183e+00, 7.3891e+00, 5.4598e+01, 2.9810e+03])
'''x = torch.tensor([0.0, 1.0, 2.0])
y = torch.exp(x)
print(y) # 输出:tensor([1.0000, 2.7183, 7.3891])x = torch.tensor([[0.0, -1.0], [1.0, -2.0]])
print(torch.exp(x))
''' 输出:
tensor([[1.0000, 0.3679],[2.7183, 0.1353]])
'''常见应用:Softmax 的实现
x = torch.tensor([1.0, 2.0, 3.0]) softmax = torch.exp(x) / torch.sum(torch.exp(x)) print(softmax)常见应用:概率建模中的对数概率反变换
log_probs = torch.tensor([-1.0, -2.0]) probs = torch.exp(log_probs)常见应用:正态化、注意力机制等。
注意:
- 输入为负数时,输出仍为正数(因为
对任意实数
成立)。
- 大数值可能导致数值溢出(输出为
inf),因此常配合数值稳定性处理(如在 softmax 前减去最大值)使用。
使用NumPy桥接
- 共享内存:Tensor 和 NumPy 数组在
.numpy()和torch.from_numpy()转换时,会 共享底层内存(共享底层数据存储),因此对一方的修改会直接影响另一方。 - 潜在风险:如果对共享内存的张量或数组进行了非原地安全的操作(如直接赋值),可能导致数据竞争或意外覆盖。
以下例子中 t 和 n 的值始终同步,因为它们共享相同的内存。这种特性在需要高效数据传递时非常有用,但需要谨慎操作以避免数据竞争。
Tensor 转 NumPy 数组
t = torch.ones(5) # 创建一个包含 5 个 1.0 的张量
print(f"t: {t}")# 将张量 t 转换为 NumPy 数组
n = t.numpy() # .numpy() 方法将 PyTorch 张量转换为 NumPy 数组
print(f"n: {n}")![]()
张量的变化反映在 NumPy 数组中:
t.add_(1) # 使用 add_ 进行原地加法
print(f"t: {t}")
print(f"n: {n}") # n 的值也会改变,因为 t 和 n 共享内存![]()
NumPy 数组 转 Tensor
n = np.ones(5) # 创建一个包含 5 个 1.0 的 NumPy 数组
t = torch.from_numpy(n) # 将 NumPy 数组转换为 PyTorch 张量NumPy 数组中的更改反映在张量中:
np.add(n, 5, out=n) # 对 NumPy 数组,使用 out 参数 进行原地加法操作
print(f"t: {t}") # 由于 t 和 n 底层共享内存,t 的值也会随之改变
print(f"n: {n}")
广播机制(形状不同的两个矩阵)
在上面的部分中,我们看到了如何在相同形状的两个张量上执行按元素操作。 在某些情况下,即使形状不同,我们仍然可以通过调用 广播机制(broadcasting mechanism)来执行按元素操作。 这种机制的工作方式如下:
-
通过适当复制元素来扩展一个或两个数组,以便在转换之后,两个张量具有相同的形状;
-
对生成的数组执行按元素操作。
在大多数情况下,我们将沿着数组中长度为1的轴进行广播,如下例子:
a = torch.arange(3).reshape((3, 1))
b = torch.arange(2).reshape((1, 2))
a, b
''' 输出
(tensor([[0],[1],[2]]),tensor([[0, 1]]))
'''由于a和b分别是形状不同的 3*3 和 1*2 矩阵,若让它们相加,它们的形状不匹配。 我们将两个矩阵广播为一个更大的3*2 矩阵,如下所示:
# 矩阵a将复制列, 矩阵b将复制行,然后再按元素相加。
a + b
''' 输出
tensor([[0, 1],[1, 2],[2, 3]])
'''节省内存
运行一些操作可能会导致为新结果分配内存。
例如,执行 Y = X + Y,我们将取消引用Y指向的张量,而是指向新分配的内存处的张量。
id() 返回内存中引用对象的确切地址
before = id(Y)
Y = Y + X
id(Y) == before # 输出:False如上,运行Y = Y + X后,id(Y) 指向了另一个位置。 这是因为Python首先计算Y + X,为结果分配新的内存,然后使Y指向内存中的这个新位置。
这可能是不可取的,原因有两个:
-
在机器学习中,可能会有数百兆的参数,且在一秒内多次更新所有参数。因此,为避免不必要地分配内存,我们希望原地执行这些参数更新;
-
若不原地更新,其他引用仍然会指向旧的内存位置,这样某些代码可能会无意中引用旧的参数。
执行原地操作 (避免不必要地分配内存)
使用切片表示法将操作的结果分配给先前分配的数组,例如Y[:] = <expression>。
Z = torch.zeros_like(Y) # 创建 形状与Y相同的新矩阵Z,zeros_like将元素设全0
print('id(Z):', id(Z))
Z[:] = X + Y
print('id(Z):', id(Z))
'''
id(Z): 140327634811696
id(Z): 140327634811696
'''若后续计算中没有重复使用X,也可以使用 X[:]=X+Y 或 X+=Y 来减少操作的内存开销:
before = id(X)
X += Y
id(X) == before # 输出:True