某益网络面经总结
一、线程池相关
1.当主线程执行结束后,子线程还会继续执行下去吗?
取决于子线程的类型:
- 用户线程:若子线程为用户线程,主线程结束后,用户线程会继续执行,直到全部用户线程执行完毕,JVM 才会退出。
- 守护线程:若子线程是守护线程,主线程结束后,守护线程会随着 JVM 退出而结束执行。
2. 线程池核心参数
- corePoolSize:核心线程数,线程池会一直保留这些线程。
- maximumPoolSize:最大线程数,线程池允许创建的最大线程数量。
- keepAliveTime:线程空闲时的存活时间。
- unit:存活时间的时间单位。
- workQueue:任务队列,用于存储待执行的任务。
- threadFactory:线程工厂,用于创建线程。
- handler:拒绝策略,当任务队列满且线程数达到最大时的处理方式。
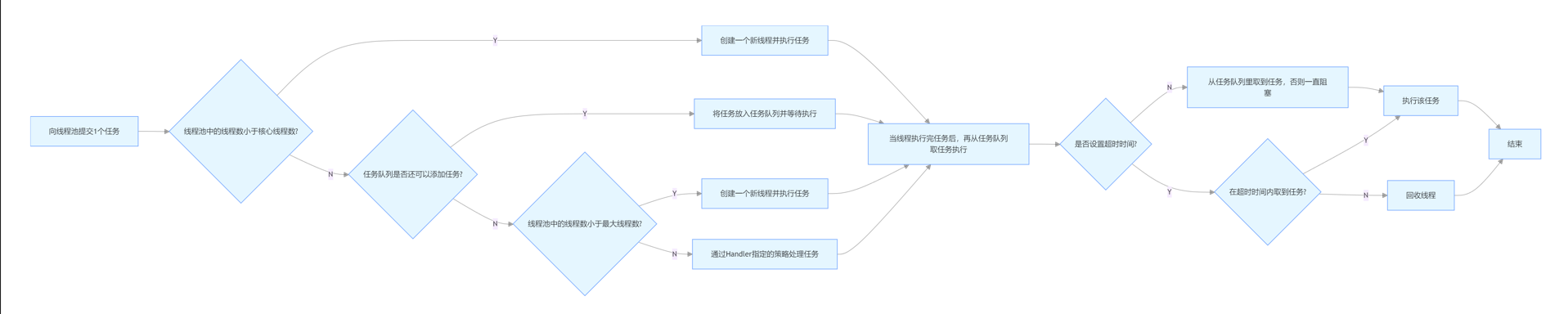
3.线程池原理:
线程池启动后,当有任务提交:
- 若核心线程未达corePoolSize,创建新线程执行任务。
- 若核心线程已满,将任务放入workQueue等待。
- 若任务队列已满,且线程数未达maximumPoolSize,创建新线程执行任务。
- 若线程数达到maximumPoolSize,任务队列也满,执行handler拒绝策略。
- 空闲线程超过keepAliveTime会被销毁,但核心线程默认不销毁。
4. 拒绝策略
当线程池的线程数达到最大线程数时,需要执行拒绝策略。
- AbortPolicy(默认):直接丢弃新提交的任务,并且抛出 RejectedExecutionException 异常来表明任务无法被处理。
- CallerRunsPolicy:当触发拒绝策略时,将任务交还给调用线程,由调用线程来负责执行该任务。
- DiscardPolicy:直接丢弃新任务,不会抛出任何异常。开发者可以基于此策略,自定义额外的处理逻辑。
- DiscardOldestPolicy:丢弃任务队列中最早进入且尚未处理的任务,之后重新尝试执行新提交的任务。
5.线程池类型
| 类型 | 池内线程类型 | 池内线程数量 | 处理特点 | 应用场景 |
|---|---|---|---|---|
| 定长线程池(FixedThreadPool) | 核心线程 | 固定 | 核心线程空闲时不回收(除非关闭线程);所有线程活动时,新任务等待至有线程空闲;任务队列无大小限制(超出线程的任务在队列中等待) | 控制线程最大并发数 |
| 定时线程池(ScheduledThreadPool) | 核心 & 非核心线程 | 核心固定,非核心无限制 | 非核心线程空闲时立即回收 | 执行定时 / 周期性任务 |
| 可缓存线程池(CachedThreadPool) | 非核心线程 | 不固定(可无限大) | 优先复用闲置线程处理新任务;无线程可用时新建线程(任务立即执行,无需等待);空闲线程超 60s 回收(回收后几乎不占系统资源) | 执行数量多、耗时少的线程任务 |
| 单线程化线程池(SingleThreadExecutor) | 核心线程 | 1 个 | 保证任务按指定顺序在一个线程中执行(顺序执行任务);无需处理线程同步问题 | 单线程场景(不适合并发,如可能引起 IO 阻塞或影响 UI 线程响应的操作,如数据库操作等) |
6.线程池工作原理
二、HBase rowkey的设计原则(三大原则)
HBase 是三维有序存储的,通过 rowkey(行键),column key(column family 和 qualifier)和 TimeStamp(时间戳)这个三个维度可以对 HBase 中的数据进行快速定位。RowKey 是 HBase 中用来唯一标识一行数据的主键。以下是 HBase 的 RowKey 三大设计原则:
- 唯一性原则:RowKey 在整个表中必须是唯一的,这是最基本的要求。因为 HBase 通过 RowKey 来定位和区分每一行数据,如果 RowKey 不唯一,就无法准确地获取到想要的数据,会导致数据的混淆和错误。例如,在一个存储用户信息的 HBase 表中,以用户 ID 作为 RowKey,每个用户的 ID 是唯一的,这样就能确保通过 RowKey 可以准确地查询到每个用户的相关信息。
- 长度原则:RowKey 的长度应该尽可能短。因为 RowKey 会被频繁地读取和比较,过长的 RowKey 会占用更多的存储空间和网络带宽,影响查询性能。一般来说,RowKey 的长度最好控制在 10 到 100 字节之间。例如,如果存储的是一些时间序列数据,可以将时间戳转换为合适的短格式作为 RowKey 的一部分,而不是直接使用完整的长整型时间戳。
- 散列原则:RowKey 的设计应该尽量保证数据在 HBase 表中均匀分布,避免数据热点问题。可以通过对 RowKey 进行散列处理,使得不同的 RowKey 能够均匀地分布在不同的 Region 上。例如,在设计 RowKey 时,可以在一些有规律的字段前加上随机的前缀,或者使用一些散列算法对原始的 Key 进行处理,让数据能够更均匀地存储在 HBase 集群中,提高系统的并发处理能力和整体性能。
三、HBase热点问题
- 热点定义:HBase 中行按 rowkey 字典序排序,糟糕的 rowkey 设计是热点源头。热点指大量 client 集中访问集群的一个或极少数节点,会致节点性能下降、region 不可用,还影响同 RegionServer 上其他 region。
- 避免热点方法及优缺点
- 加盐:在 rowkey 前加随机数,依随机前缀分散到各 region 避热点,前缀数与分散 region 数一致。
- 哈希:用确定哈希给同一行加固定前缀,可分散负载,且读可预测,客户端能重构 rowkey 精准获取数据。
- 反转:反转固定长度或数字格式 rowkey,能随机 rowkey 但牺牲有序性,如手机号反转作 rowkey。
- 时间戳反转:用 Long.Max_Value - timestamp 追加到 key 末尾,如 [key][reverse_timestamp],利于快速获取 [key] 最新值,scan [key] 的首条记录即最新录入数据。
- 其他建议:减少行键和列族大小,因 value 传输时 key、列名、时间戳会一同传输;列族越短越好,最好一个字符;短属性名比冗长属性名更适合存储在 HBase 中。
四、hashmap的底层原理,为什么hashtable可以保证线程安全
HashMap 的底层原理
- 数据结构:HashMap 底层是基于数组和链表(或红黑树)实现的。数组的每个元素是一个链表的头节点,链表用于解决哈希冲突。当链表长度超过一定阈值(默认为 8)且数组大小大于等于 64 时,链表会转换为红黑树,以提高查找效率。
- 哈希函数:通过对键对象的哈希码进行计算,得到在数组中的存储位置。通常使用
key.hashCode()方法获取键的哈希码,然后对数组长度取模,得到数组索引。 - 存储过程:当向 HashMap 中添加键值对时,先计算键的哈希值,根据哈希值确定在数组中的位置。如果该位置为空,则直接将键值对存储在该位置;如果该位置已有元素,说明发生了哈希冲突,会将新的键值对添加到链表的末尾(或根据红黑树的规则插入到红黑树中)。
- 扩容机制:当 HashMap 中的元素数量达到负载因子(默认为 0.75)与数组长度的乘积时,会触发扩容操作。扩容会创建一个新的更大的数组,并将原数组中的元素重新哈希分配到新数组中。
Hashtable 保证线程安全的原因
- 同步方法:Hashtable 中的几乎所有操作方法(如
put、get、remove等)都被synchronized关键字修饰,同一时刻仅一个线程可访问,其他线程需等待当前线程执行完并释放锁,从而保障线程安全。 - 锁机制:Hashtable 利用对象锁对整体进行同步,所有操作均需获取该锁,确保任一时刻仅有一个线程能修改或访问,避免多线程下数据不一致 。
五、Hive内部表和外部表的区别
- 未被external修饰的是内部表,被external修饰的为外部表。
- 内部表数据由Hive自身管理,外部表数据由HDFS管理;
- 内部表数据存储的位置是
hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己制定(如果没有LOCATION,Hive将在HDFS上的/user/hive/warehouse文件夹下以外部表的表名创建一个文件夹,并将属于这个表的数据存放在这里); - 删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除。
六、数据倾斜,怎么解决
在 Hive 处理千亿级数据时,数据倾斜问题需重点关注,其本质原因是大量相同 key 数据处理或读取不可分割大文件,常见于 reduce 阶段,map 阶段在特定情况下也会发生。以下是不同场景下的数据倾斜及解决方案:
- 空值引发:大量 null 值参与 join 时,因 shuffle 阶段 hash 相同进入同一 reduce 导致倾斜。解决方法包括将 null 值过滤后再 union ,或给 null 值随机赋值,使其 hash 结果不同,分散到不同 reduce。
- 不同数据类型:表连接字段类型不同,如 int 和 string 混合,默认按 int 型 hash 会使 string 类型集中到一个 reduce。可将 int 类型转为 string,统一 hash 分配规则。
- 不可拆分大文件:使用 GZIP 等不支持分割的压缩方式,使大文件只能被一个 map 读取引发倾斜。应采用 bzip2、Zip 等支持分割的压缩算法。
- 数据膨胀:多维聚合计算中分组字段多,数据膨胀易致内存溢出和数据倾斜。可拆分 SQL 语句,或通过参数
hive.new.job.grouping.set.cardinality自动控制作业拆解,倾斜严重时调小该值。 - 表连接:普通 repartition join 键倾斜会引发数据倾斜。可利用 MapJoin,将小表存到分布式缓存,在 Map 阶段完成 join,避免 Shuffle;Hive 0.11 后默认开启优化,可通过参数设置触发时机,必要时手动标记。
- 无法减少数据量:如使用
collect_list等函数且分组字段存在倾斜时,会导致内存溢出,hive.groupby.skewindata参数对此类场景无效。可直接调整mapreduce.reduce.memory.mb来增大 reduce 执行内存 。
七、算法手撕:有n级楼梯,你一次可以爬一级或两级,问爬上n级楼梯有多少种爬法?
public class ClimbStairsRecursive {public static int climbStairs(int n) {if (n == 1) {return 1;}if (n == 2) {return 2;}return climbStairs(n - 1) + climbStairs(n - 2);}public static void main(String[] args) {int n = 5;System.out.println("爬上 " + n + " 级楼梯的方法数为: " + climbStairs(n));}
}
原文地址:https://blog.csdn.net/m0_62410190/article/details/147156028
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mrgr.cn/news/98294.html 如若内容造成侵权/违法违规/事实不符,请联系邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mrgr.cn/news/98294.html 如若内容造成侵权/违法违规/事实不符,请联系邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!