【redis进阶三】分布式系统之主从复制结构(1)
目录
一 为什么要有分布式系统?
二 分布式系统涉及到的非常关键的问题:单点问题
三 学习部署主从结构的redis
(1)创建一个目录
(2)进入目录拷贝两份原有redis
(3)使用vim修改几个选项
(4)启动两个从节点服务器
(5)建立复制,要想配置成主从结构就要用到slaveof
(6)观察结果
(7)试试从节点能不能 执行写操作
(8)可以通过 info replication 命令查看复制相关状态。
1)主节点6379复制状态信息
2)从节点6380复制状态信息
3)每个字段代表的意思在官网直接查就行
(9)通过slaveof命令断开连接
四 额外提醒
一 为什么要有分布式系统?
1)要想弄清楚这个问题,首先要明确我们平时使用的软件大部分是客户端软件,那么谁为我们提供服务呢?那肯定是服务器,你看他名字就是为了服务我们,比如我们学习redis的时候在redis-cli上敲命令就是通过网络通信把我们敲的命令发送给服务器帮我们做相关操作。那么到这里就明确了一点:服务器用来给我们提供良好的服务!!!
2)那么想象一下这个场景:同时10个人同时打开一款你刚写好的部署在云服务器上的web项目,尚可功能正常运行,但是逐渐加大并发量呢?100个人开始吃力了,1000个人可能就崩溃了,但是你看下抖音,同时在线百万,千万人刷视频 玩游戏 购物还能流畅运行,那是为什么???是的没错他一定是使用了分布式系统来提高 可用性和高并发!!!
3)像我们上边说的服务器就是用来给我们提供服务的,而且一定是要高可用,能够抗住高并发的服务器,那为什么你的服务器不行?人家大公司抖音就可以呢?说白了就是 钱的力量,你的就一个2g2核的,人家可是成千上百台多核多内存的形成一个庞大的集群。
4)跑偏了,总结上述所讲原因就是:服务器接收请求,每个请求都会消耗你的服务器一些资源才能处理(cpu,内存,磁盘,网络带宽等)你就一个服务器资源肯定有限啊,同时大量的请求打过来,直接给你的内存打满都不够这样的情况,那你的服务器肯定崩溃,所以 分布式系统通过引入更多服务器来引入更多的物理实体资源提高 高并发功能!!!并且你的一个服务部署在好几个服务器上比如3个,第一个挂掉了另外两个还能提供服务,不至于整个系统都挂掉,这只是分布式系统提高并发量 可用性的一个原因,更多原因请查看本专栏开始讲解的 架构演进。
二 分布式系统涉及到的非常关键的问题:单点问题

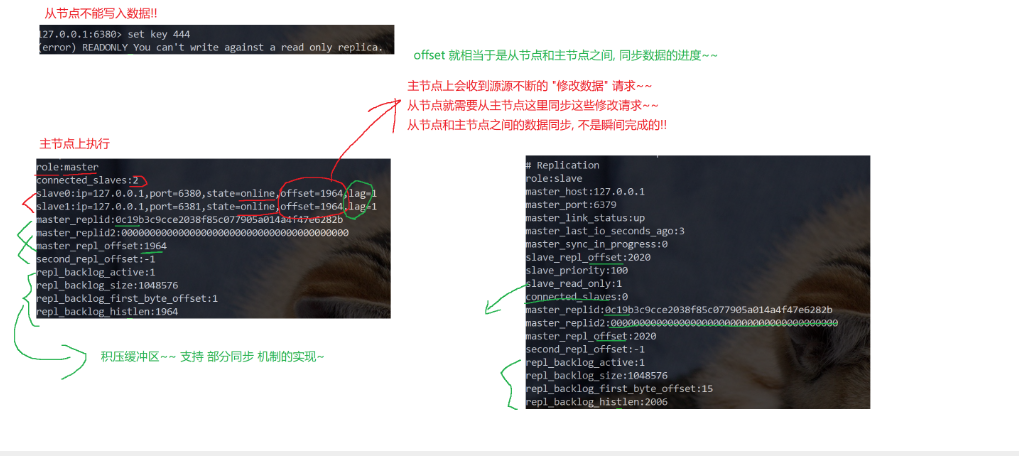
ps:在分布式系统中为了解决单点问题,通常会把数据复制多个副本部署到其他服务器,满⾜故障恢复和负载均衡等需求。Redis 也是如此,它为我们提供了复制的功能,实现了相同数据的多个 Redis 副 本。复制功能是⾼可⽤ Redis 的基础,哨兵和集群都是在复制的基础上构建的。
总结:只有主节点能进行写操作,从节点只能进行读操作
进阶二内容如下:
(1)介绍复制的使⽤⽅式:如何建⽴或断开复制、安全性、只读等。
(2) 说明复制可⽀持的拓扑结构,以及每个拓扑结构的适⽤场景。
(3)分析复制的原理,包括:建⽴复制、全量复制、部分复制、⼼跳检测等。
三 学习部署主从结构的redis
(1)创建一个目录
mkdir redis-conf![]()
(2)进入目录拷贝两份原有redis
cp /etc/redis/redis.conf ./slave1.conf
cp /etc/redis/redis.conf ./slave2.conf(3)使用vim修改几个选项
我们现在是配置从节点,学习网络的时候有一个很重要的知识点就是一个进程可以绑定多个端口号,但是一个端口号只能给一个节点使用,我们使用默认的redis-server(port:6379)作为主节点,所以另外两个节点就是用不同的端口号,第一个从节点用6380,第二个从节点用6381
![]()
因为我们现在就一个云服务器,所以绑定本机就行
![]()
daemonize 改为yes表示一后台进程方式运行

(4)启动两个从节点服务器
先查看当前是否就一个redis-server服务
ps -axj | head -1 && ps -axj | grep redis-server
然后我们使用命令行启动两个从节点
redis-server ./slave1.conf
redis-server ./slave1.conf ps:

查看两个从节点redis-server服务进程是否启动

ok,正确启动,到这里就启动了三个redis-server,port为6379的默认redis-server服务后边我们把它作为主节点,6380和6381作为从节点
ps:
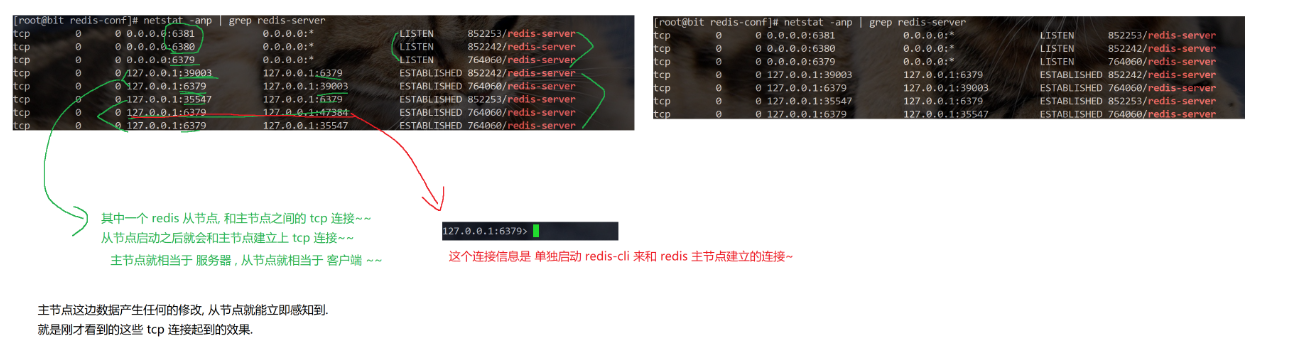
(5)建立复制,要想配置成主从结构就要用到slaveof
参与复制的 Redis 实例划分为主节点(master)和从节点(slave)。每个从结点只能有⼀个主节点, ⽽⼀个主节点可以同时具有多个从结点。复制的数据流是单向的,只能由主节点到从节点。配置复制 的⽅式有以下三种:
1. 在配置⽂件中加⼊ slaveof {masterHost} {masterPort} 随 Redis 启动⽣效。
2. 在 redis-server 启动命令时加⼊ --slaveof {masterHost} {masterPort} ⽣效。
3. 直接使⽤ redis 命令:slaveof {masterHost} {masterPort} ⽣效。
我们选择第一种方式修改配置文件,修改以后一直生效
port为6379的默认redis-server服务我们把它作为主节点,6380和6381作为从节点
步骤一:还是使用vim打开以下两个文件
![]()
在最后一行配置上这一句
# 加上主从结构的配置
slaveof 127.0.0.1 6379
(6)观察结果
我们在主节点插入 key:111 的键值对
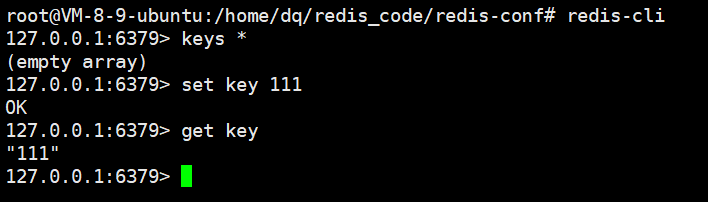
紧接着去第一个从节点查看数据是否同步上去

ok,同步上去
紧接着去第一个从节点查看数据是否同步上去

ok,同步上去了
(7)试试从节点能不能 执行写操作
 符合预期,只能读不能写
符合预期,只能读不能写
(8)可以通过 info replication 命令查看复制相关状态。
1)主节点6379复制状态信息
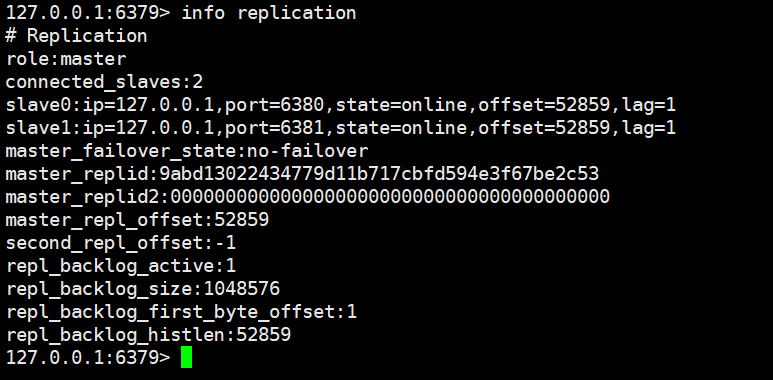
2)从节点6380复制状态信息
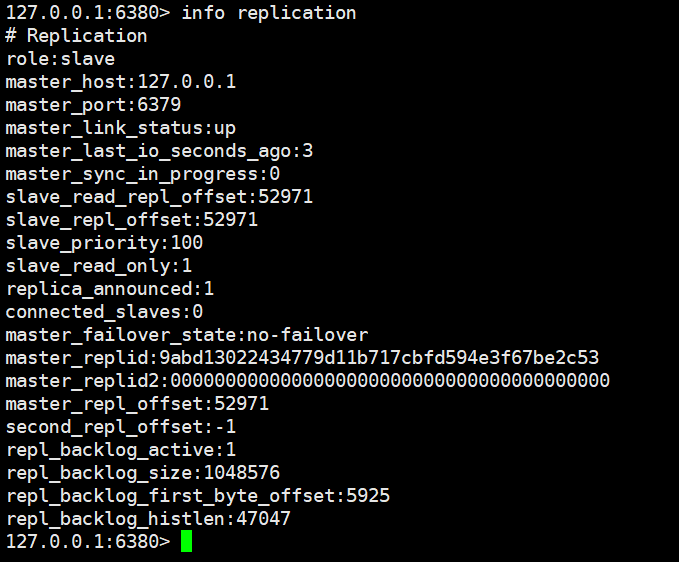
3)每个字段代表的意思在官网直接查就行
(9)通过slaveof命令断开连接
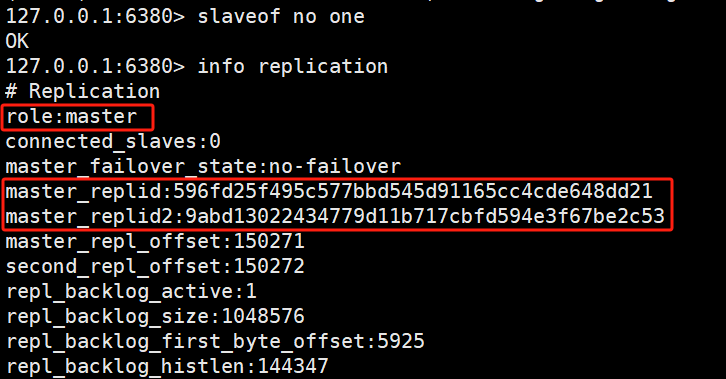
断开复制:
slaveof 命令不但可以建⽴复制,还可以在从节点执⾏slaveof no one来断开与主节点复制关系。 例如在6380节点上执⾏slaveofnoone来断开复制。
断开复制主要流程: 1)断开与主节点复制关系。 2)从节点晋升为主节点。
从节点断开复制后并不会抛弃原有数据,只是⽆法再获取主节点上的数据变化。
通过slaveof命令还可以实现切主操作,将当前从节点的数据源切换到另⼀个主节点。执⾏ slaveof {newMasterIp} {newMasterPort} 命令即可。
切主操作主要流程:
1)断开与旧主节点复制关系。
2)与新主节点建⽴复制关系。
3)删除从节点当前所有数据。
4)从新主节点进⾏复制操作。
未断开连接的6380:
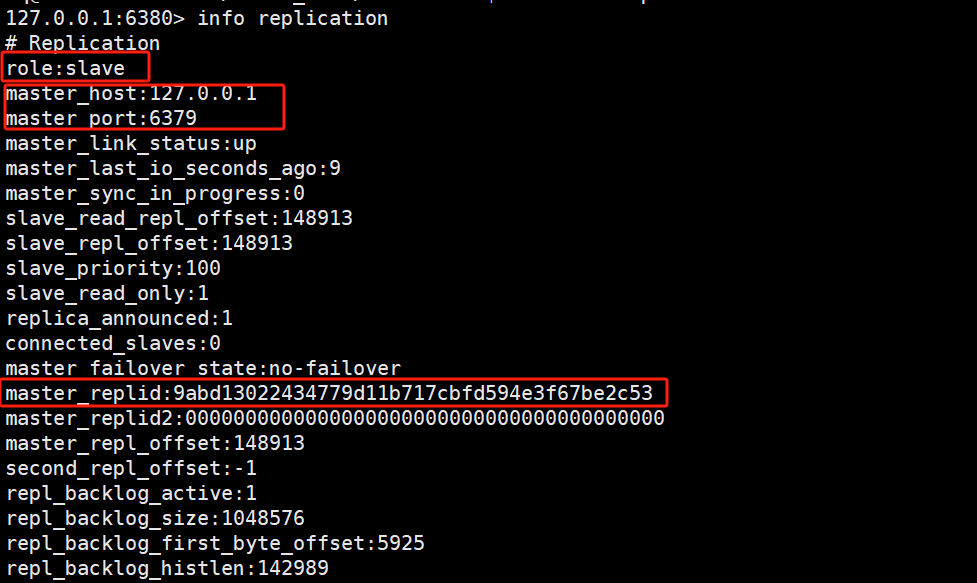
断开连接的6380
四 额外提醒
