KTransformers安装笔记 利用docker安装KTransformers
KTransformers安装笔记
- 0、前提条件
- 1、安装相关依赖
- 2、创建虚拟环境并操作
- 3、安装pytorch==2.6版本
- 4、下载项目源代码:
- 针对于cpu and 1T RAM硬件条件:
- 5、相关权重文件以及配置文件下载
- 6、利用docker安装KTransformers
0、前提条件
CUDA12.4
建议升级到较新版本的CMake,安装git,g++,gcc
执行以下命令,把 CUDA_HOME 指向你 CUDA 的安装目录(比如 /usr/local/cuda-12.4)
export CUDA_HOME=/usr/local/cuda-12.4
export PATH=$CUDA_HOME/bin:$PATH
export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH
source ~/.bashrc
查看是否成功:
which nvcc
输出:表示配置成功
/usr/local/cuda-12.4/bin/nvcc
创建本地容器
docker run -it -d --gpus all --privileged -p 8083:8080 -p 8084:8084 -p 8055:22 --name KT_ubuntu2204_cuda124_cudnn8700 -v /home/data_c/KT_data/:/home/data_c/KT_data/ -v /home/data_a/gqr/:/home/data_a afa4f07f5e5e /bin/bash
默认cuda与cudnn已经安装完毕,conda也安装完毕
1、安装相关依赖
sudo apt-get update
sudo apt-get install build-essential cmake ninja-build patchelf
2、创建虚拟环境并操作
conda create --name ktransformers python=3.11
conda activate ktransformers # 激活环境
conda install -c conda-forge libstdcxx-ng # Anaconda provides a package called `libstdcxx-ng` that includes a newer version of `libstdc++`, which can be installed via `conda-forge`.# 查看指令
strings ~/anaconda3/envs/ktransformers/lib/libstdc++.so.6 | grep GLIBCXX3、安装pytorch==2.6版本

pip install torch torchvision torchaudio
国内:
pip3 install torch torchvision torchaudio --default-timeout=100 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install packaging ninja cpufeature numpy --default-timeout=100 -i https://pypi.tuna.tsinghua.edu.cn/simple
安装flash-attention
pip install flash_attn
最好执行上述语句安装,因为这中安装方式成功后,表明相关的nvcc安装成功,对接下来的安装更优把握
也可以直接下载对应cuda与torch版本的.whl包(官网说可以,没亲自尝试过)
https://github.com/Dao-AILab/flash-attention/releases
或者:
pip install flash-attn --find-links https://github.com/Dao-AILab/flash-attn/releases判断flash-attn是否安装成功执行如下:
import flash_attn
print(flash_attn.__version__)
# 有时 flash_attn 会安装成功但 CUDA 编译失败,你可以进一步测试核心 CUDA 扩展:
from flash_attn.layers.rotary import RotaryEmbedding
from flash_attn.bert_padding import pad_input, unpad_input
正常运行,则表示成功!!!
apt install libtbb-dev libssl-dev libcurl4-openssl-dev libaio1 libaio-dev libgflags-dev zlib1g-dev libfmt-devapt install libtbb-dev libssl-dev libcurl4-openssl-dev libaio1 libaio-dev libfmt-dev libgflags-dev zlib1g-dev patchelfapt install libnuma-dev
pip install packaging ninja cpufeature numpy openai4、下载项目源代码:
git clone https://github.com/kvcache-ai/ktransformers.git
cd ktransformers
git submodule update --init --recursive
针对与不同情况的安装方式:
针对于cpu and 1T RAM硬件条件:
# For Multi-concurrency with two cpu and 1T RAM:
apt install libnuma-dev
export USE_NUMA=1
USE_BALANCE_SERVE=1 USE_NUMA=1 bash ./install.sh
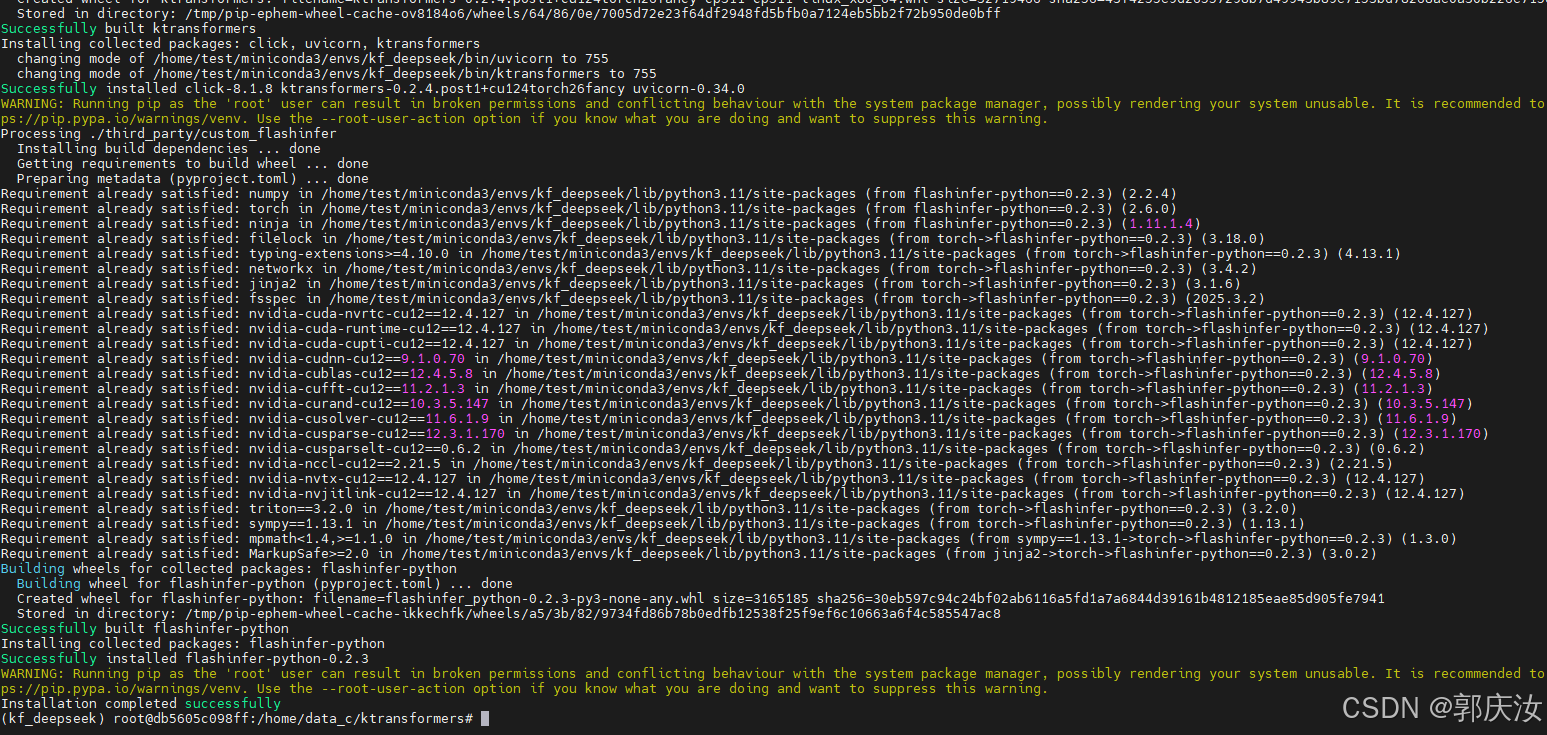
经过漫长的时间等待后,编译成功,如下所示:
5、相关权重文件以及配置文件下载
下载Deepseek-R1-Q4模型权重
# 安装魔搭社区
pip install modelscope
# 模型权重文件下载
modelscope download --model lmstudio-community/DeepSeek-R1-GGUF --include DeepSeek-R1-Q4_K_M* --local_dir ./dir

下载Deepseek-R1-Q4 config配置文件
modelscope download --model deepseek-ai/DeepSeek-R1 --exclude *.safetensors --local_dir ./config

报错类型:
报错一:
编译阶段报错如下:
ERROR: Failed to build installable wheels for some pyproject.toml based projects (ktransformers)

官网解决方案:
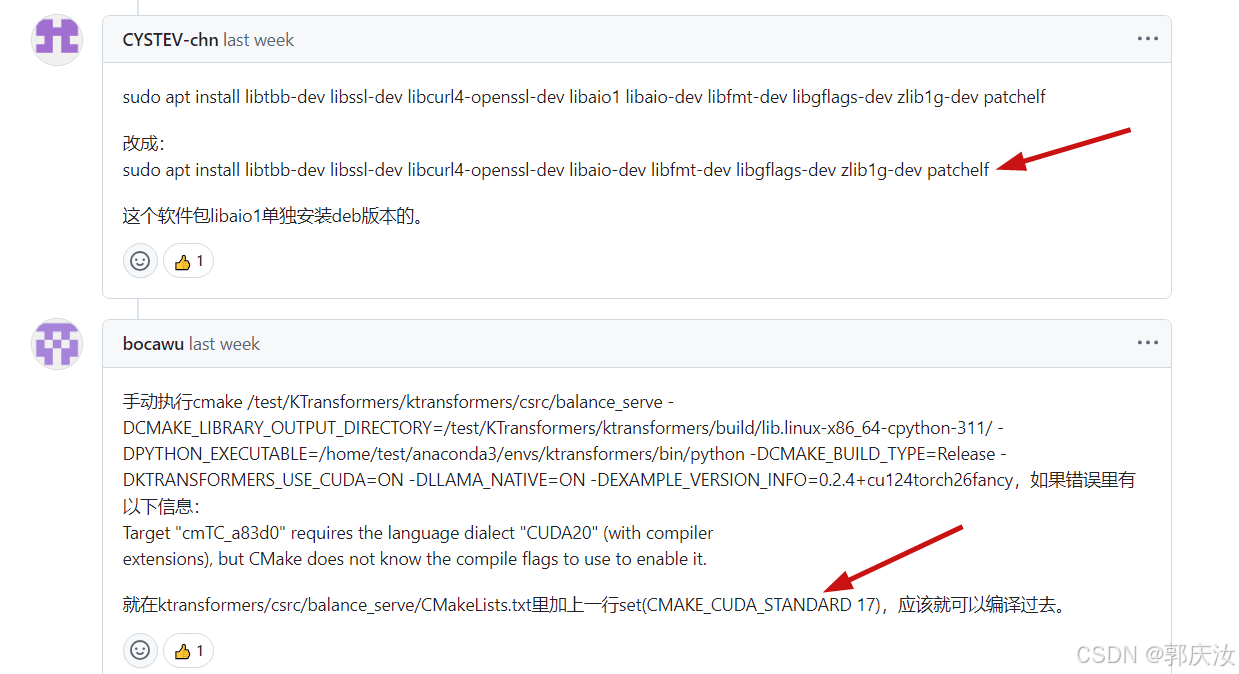
语句:
sudo apt install libtbb-dev libssl-dev libcurl4-openssl-dev libaio-dev libfmt-dev libgflags-dev zlib1g-dev patchelf
###############################################################################
就在ktransformers/csrc/balance_serve/CMakeLists.txt里加上一行set(CMAKE_CUDA_STANDARD 17),应该就可以编译过去。
重新编译后:
报错二:
问题描述:
执行语句如下
python ktransformers/server/main.py \--port 10002 \--model_path /home/data_c/KT_data/config \--gguf_path /home/data_c/KT_data/dir \--optimize_config_path ktransformers/optimize/optimize_rules/DeepSeek-V3-Chat-serve.yaml \--max_new_tokens 1024 \--cache_lens 32768 \--chunk_size 256 \--max_batch_size 4 \--backend_type balance_serve \--force_think # useful for R1报错显示如下:
File "/kiwi/helly/ktransformers/ktransformers/ktransformers/local_chat.py", line 110, in local_chat
optimize_and_load_gguf(model, optimize_rule_path, gguf_path, config)
File "/kiwi/helly/ktransformers/ktransformers/ktransformers/optimize/optimize.py", line 128, in optimize_and_load_gguf
inject(module, optimize_config, model_config, gguf_loader)
File "/kiwi/helly/ktransformers/ktransformers/ktransformers/optimize/optimize.py", line 31, in inject
module_cls=getattr(import(import_module_name, fromlist=[""]), import_class_name)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/kiwi/helly/ktransformers/ktransformers/ktransformers/operators/models.py", line 22, in
from ktransformers.operators.dynamic_attention import DynamicScaledDotProductAttention
File "/kiwi/helly/ktransformers/ktransformers/ktransformers/operators/dynamic_attention.py", line 19, in
from ktransformers.operators.cpuinfer import CPUInfer, CPUInferKVCache
File "/kiwi/helly/ktransformers/ktransformers/ktransformers/operators/cpuinfer.py", line 25, in
import cpuinfer_ext
ImportError: /root/miniconda3/envs/ktransformers/bin/../lib/libstdc++.so.6: version `GLIBCXX_3.4.30' not found (required by /kiwi/helly/ktransformers/ktransformers/cpuinfer_ext.cpython-311-x86_64-linux-gnu.so)解决方案:
先执行如下语句,在拉起项目服务:
# 先执行如下
export LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libstdc++.so.6# 在执行如下
python ktransformers/server/main.py \--port 10002 \--model_path /home/data_c/KT_data/config \--gguf_path /home/data_c/KT_data/dir \--optimize_config_path ktransformers/optimize/optimize_rules/DeepSeek-V3-Chat-serve.yaml \--max_new_tokens 1024 \--cache_lens 32768 \--chunk_size 256 \--max_batch_size 4 \--backend_type balance_serve \--force_think # useful for R1
其他安装指令
conda create --name ktransformers python=3.11
conda activate ktransformers
conda install -c conda-forge libstdcxx-ng
sudo apt install libtbb-dev libssl-dev libcurl4-openssl-dev libaio1 libaio-dev libfmt-dev libgflags-dev zlib1g-dev patchelf
git clone https://github.com/kvcache-ai/ktransformers.git
cd ktransformers
git submodule update --init --recursive
sudo env USE_BALANCE_SERVE=1 PYTHONPATH="$(which python)" PATH="$(dirname $(which python)):$PATH" bash ./install.sh报错三:
项目启动后,加载模型参数阶段,出现如下报错:
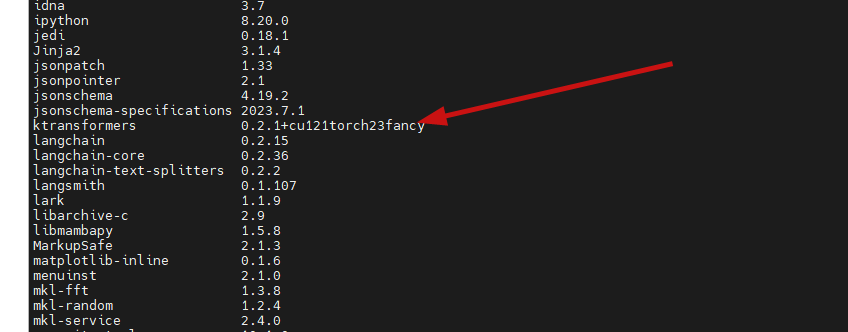
Use docker and upgrade to 0.2.3 version
ktransformers 0.2.3.post1+cu121torch23fancyktransformers --gguf_path /models/GGUF --model_path /models --cpu_infer 190 --optimize_config_path /models/DeepSeek-V3-Chat-multi-gpu.yaml --port 10002 --max_new_tokens 8192 --host 0.0.0.0 --cache_lens 32768 --total_context 32768 --force_think --no-use_cuda_graph --model_name DeepSeek-R1Get warnings below but still can work.
No idea what's wrong.loading blk.3.attn_q_a_norm.weight to cuda:6
loading blk.3.attn_kv_a_norm.weight to cuda:6
loading blk.3.attn_kv_b.weight to cuda:6
mbind: Operation not permitted
mbind: Operation not permitted
mbind: Operation not permitted
mbind: Operation not permitted
mbind: Operation not permitted
mbind: Operation not permitted
set_mempolicy: Operation not permitted
set_mempolicy: Operation not permitted报错原因:这是使用docker部署时,容器没有相应的权限,需要在创建容器是加上参数
--privileged
即:
docker run -it -d --gpus all --privileged -p 8083:8080 -p 8084:8084 -p 8055:22 --name KT_ubuntu2204_cuda124_cudnn8700 -v /home/data_c/KT_data/:/home/data_c/KT_data/ -v /home/data_a/gqr/:/home/data_a afa4f07f5e5e /bin/bash其他安装指令:
conda create --name ktransformers python=3.11
conda activate ktransformers
conda install -c conda-forge libstdcxx-ng
sudo apt install libtbb-dev libssl-dev libcurl4-openssl-dev libaio1 libaio-dev libfmt-dev libgflags-dev zlib1g-dev patchelf
git clone https://github.com/kvcache-ai/ktransformers.git
cd ktransformers
git submodule update --init --recursive
sudo env USE_BALANCE_SERVE=1 PYTHONPATH="$(which python)" PATH="$(dirname $(which python)):$PATH" bash ./install.sh
apt install libnuma-dev
export USE_NUMA=1
env USE_BALANCE_SERVE=1 PYTHONPATH="$(which python)" PATH="$(dirname $(which python)):$PATH" bash ./install.sh
6、利用docker安装KTransformers
本文安装的版本是0.2.1版本
拉取官方镜像指令:
docker pull approachingai/ktransformers:0.2.1
创建对应容器指令:
docker run --gpus all -p 8077:8082 --privileged -v /home/data_c/KT_data/:/models --name ktransformers -itd approachingai/ktransformers:0.2.1
进入容器内部:
docker exec -it ktransformers /bin/bash
启动模型对话:
python -m ktransformers.local_chat --gguf_path /models/DeepSeek-V3 --model_path /models/deepseek-ai/DeepSeek-V3 --cpu_infer 33
如果运行上述语句报错,提示如下:
Illegal instruction (core dumped)
解决的方案是:
在该容器环境内,重新编译KTransformers,执行
bash install.sh
启动后,出现如下:
官方也提供OpenAI接口的形式:
运行如下指令:
python ktransformers/server/main.py --port 8082 --model_path /models/deepseek-ai/DeepSeek-V3 --gguf_path /models/DeepSeek-V3 --optimize_config_path ktransformers/optimize/optimize_rules/DeepSeek-V3-Chat.yaml --max_new_tokens 1024 --cache_lens 32768 --max_batch_size 4 --force_think True --model_name DeepSeek-R1

运行后:

访问方式:
curl -X POST http://localhost:8082/v1/chat/completions \-H "accept: application/json" \-H "Content-Type: application/json" \-d '{"messages": [{"role": "user", "content": "hello"}],"model": "DeepSeek-R1","temperature": 0.3,"top_p": 1.0,"stream": true}'参数:
usage: kvcache.ai [-h] [--host HOST] [--port PORT] [--ssl_keyfile SSL_KEYFILE] [--ssl_certfile SSL_CERTFILE] [--web WEB] [--model_name MODEL_NAME] [--model_dir MODEL_DIR] [--model_path MODEL_PATH] [--device DEVICE][--gguf_path GGUF_PATH] [--optimize_config_path OPTIMIZE_CONFIG_PATH] [--cpu_infer CPU_INFER] [--type TYPE] [--paged PAGED] [--total_context TOTAL_CONTEXT] [--max_batch_size MAX_BATCH_SIZE][--max_chunk_size MAX_CHUNK_SIZE] [--max_new_tokens MAX_NEW_TOKENS] [--json_mode JSON_MODE] [--healing HEALING] [--ban_strings BAN_STRINGS] [--gpu_split GPU_SPLIT] [--length LENGTH] [--rope_scale ROPE_SCALE][--rope_alpha ROPE_ALPHA] [--no_flash_attn NO_FLASH_ATTN] [--low_mem LOW_MEM] [--experts_per_token EXPERTS_PER_TOKEN] [--load_q4 LOAD_Q4] [--fast_safetensors FAST_SAFETENSORS] [--draft_model_dir DRAFT_MODEL_DIR][--no_draft_scale NO_DRAFT_SCALE] [--modes MODES] [--mode MODE] [--username USERNAME] [--botname BOTNAME] [--system_prompt SYSTEM_PROMPT] [--temperature TEMPERATURE] [--smoothing_factor SMOOTHING_FACTOR][--dynamic_temperature DYNAMIC_TEMPERATURE] [--top_k TOP_K] [--top_p TOP_P] [--top_a TOP_A] [--skew SKEW] [--typical TYPICAL] [--repetition_penalty REPETITION_PENALTY] [--frequency_penalty FREQUENCY_PENALTY][--presence_penalty PRESENCE_PENALTY] [--max_response_tokens MAX_RESPONSE_TOKENS] [--response_chunk RESPONSE_CHUNK] [--no_code_formatting NO_CODE_FORMATTING] [--cache_8bit CACHE_8BIT] [--cache_q4 CACHE_Q4][--ngram_decoding NGRAM_DECODING] [--print_timings PRINT_TIMINGS] [--amnesia AMNESIA] [--batch_size BATCH_SIZE] [--cache_lens CACHE_LENS] [--log_dir LOG_DIR] [--log_file LOG_FILE] [--log_level LOG_LEVEL][--backup_count BACKUP_COUNT] [--db_type DB_TYPE] [--db_host DB_HOST] [--db_port DB_PORT] [--db_name DB_NAME] [--db_pool_size DB_POOL_SIZE] [--db_database DB_DATABASE] [--user_secret_key USER_SECRET_KEY][--user_algorithm USER_ALGORITHM] [--force_think FORCE_THINK] [--web_cross_domain WEB_CROSS_DOMAIN] [--file_upload_dir FILE_UPLOAD_DIR] [--assistant_store_dir ASSISTANT_STORE_DIR] [--prompt_file PROMPT_FILE]报错:
在docker容器内运行0.2.1版本的API时,会出现以下报错,解决方案是拉取0.2.0版本的docker容器,构建项目
During handling of the above exception, another exception occurred:Exception Group Traceback (most recent call last):
| File "/usr/python310/lib/python3.10/site-packages/uvicorn/protocols/http/httptools_impl.py", line 409, in run_asgi
| result = await app( # type: ignore[func-returns-value]
| File "/usr/python310/lib/python3.10/site-packages/uvicorn/middleware/proxy_headers.py", line 60, in call
| return await self.app(scope, receive, send)
| File "/usr/python310/lib/python3.10/site-packages/fastapi/applications.py", line 1054, in call
| await super().call(scope, receive, send)
| File "/usr/python310/lib/python3.10/site-packages/starlette/applications.py", line 112, in call
| await self.middleware_stack(scope, receive, send)
| File "/usr/python310/lib/python3.10/site-packages/starlette/middleware/errors.py", line 187, in call
| raise exc
| File "/usr/python310/lib/python3.10/site-packages/starlette/middleware/errors.py", line 165, in call
| await self.app(scope, receive, _send)
| File "/usr/python310/lib/python3.10/site-packages/starlette/middleware/cors.py", line 85, in call
| await self.app(scope, receive, send)
| File "/usr/python310/lib/python3.10/site-packages/starlette/middleware/exceptions.py", line 62, in call
| await wrap_app_handling_exceptions(self.app, conn)(scope, receive, send)
| File "/usr/python310/lib/python3.10/site-packages/starlette/_exception_handler.py", line 53, in wrapped_app
| raise exc
| File "/usr/python310/lib/python3.10/site-packages/starlette/_exception_handler.py", line 42, in wrapped_app
| await app(scope, receive, sender)
| File "/usr/python310/lib/python3.10/site-packages/starlette/routing.py", line 715, in call
| await self.middleware_stack(scope, receive, send)
| File "/usr/python310/lib/python3.10/site-packages/starlette/routing.py", line 735, in app
| await route.handle(scope, receive, send)
| File "/usr/python310/lib/python3.10/site-packages/starlette/routing.py", line 288, in handle
| await self.app(scope, receive, send)
| File "/usr/python310/lib/python3.10/site-packages/starlette/routing.py", line 76, in app
| await wrap_app_handling_exceptions(app, request)(scope, receive, send)
| File "/usr/python310/lib/python3.10/site-packages/starlette/_exception_handler.py", line 53, in wrapped_app
| raise exc
| File "/usr/python310/lib/python3.10/site-packages/starlette/_exception_handler.py", line 42, in wrapped_app
| await app(scope, receive, sender)
| File "/usr/python310/lib/python3.10/site-packages/starlette/routing.py", line 74, in app
| await response(scope, receive, send)
| File "/usr/python310/lib/python3.10/site-packages/starlette/responses.py", line 261, in call
| async with anyio.create_task_group() as task_group:
| File "/usr/python310/lib/python3.10/site-packages/anyio/_backends/asyncio.py", line 767, in aexit
| raise BaseExceptionGroup(
| exceptiongroup.ExceptionGroup: unhandled errors in a TaskGroup (1 sub-exception)
+-+---------------- 1 ----------------
| Traceback (most recent call last):
| File "/usr/python310/lib/python3.10/site-packages/starlette/responses.py", line 264, in wrap
| await func()
| File "/usr/python310/lib/python3.10/site-packages/starlette/responses.py", line 245, in stream_response
| async for chunk in self.body_iterator:
| File "/mnt/data/ktransformers-0.2.1/ktransformers/server/schemas/assistants/streaming.py", line 80, in check_client_link
| async for event in async_events:
| File "/mnt/data/ktransformers-0.2.1/ktransformers/server/schemas/assistants/streaming.py", line 93, in to_stream_reply
| async for event in async_events:
| File "/mnt/data/ktransformers-0.2.1/ktransformers/server/schemas/assistants/streaming.py", line 87, in add_done
| async for event in async_events:
| File "/mnt/data/ktransformers-0.2.1/ktransformers/server/schemas/assistants/streaming.py", line 107, in filter_chat_chunk
| async for event in async_events:
| File "/mnt/data/ktransformers-0.2.1/ktransformers/server/api/openai/endpoints/chat.py", line 34, in inner
| async for token in interface.inference(input_message,id):
| File "/mnt/data/ktransformers-0.2.1/ktransformers/server/backend/interfaces/ktransformers.py", line 181, in inference
| async for v in super().inference(local_messages, thread_id):
| File "/mnt/data/ktransformers-0.2.1/ktransformers/server/backend/interfaces/transformers.py", line 340, in inference
| for t in self.prefill(input_ids, self.check_is_new(thread_id)):
| File "/usr/python310/lib/python3.10/site-packages/torch/utils/contextlib.py", line 36, in generator_context
| response = gen.send(None)
| File "/mnt/data/ktransformers-0.2.1/ktransformers/server/backend/interfaces/ktransformers.py", line 130, in prefill
| self.cache.reset()
| File "/mnt/data/ktransformers-0.2.1/ktransformers/models/custom_cache.py", line 175, in reset
| self.value_cache[layer_idx].zero()
| AttributeError: 'NoneType' object has no attribute 'zero'
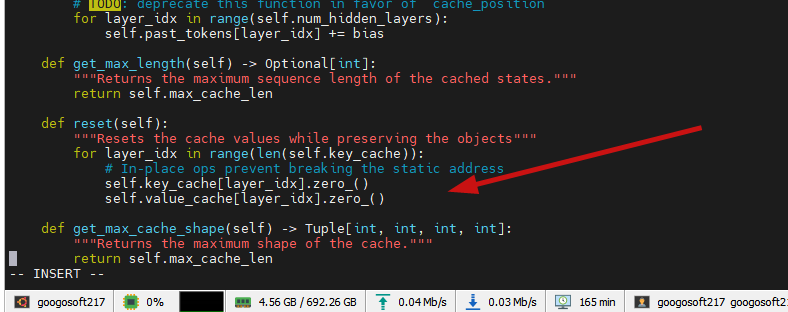
修改后:
def reset(self):"""Resets the cache values while preserving the objects"""for layer_idx in range(len(self.key_cache)):# In-place ops prevent breaking the static addressif self.key_cache[layer_idx] is not None:self.key_cache[layer_idx].zero_()if self.value_cache[layer_idx] is not None:self.value_cache[layer_idx].zero_()或者:
Should be fixed by latest release0.2.1.post1