一种基于学习的多尺度方法及其在非弹性碰撞问题中的应用
A learning-based multiscale method and its application to inelastic impact problems
摘要:
我们在工程应用中观察和利用的材料宏观特性,源于电子、原子、缺陷、域等多尺度物理机制间复杂的相互作用。多尺度建模旨在通过利用固有的层次化结构来理解这些相互作用——在更粗尺度上的行为会调控并平均化更细尺度的行为。这需要反复求解计算代价高昂的细尺度模型,且通常需预先知晓那些影响粗尺度的细尺度行为特征(如序参数、状态变量、描述符等)。我们在双尺度框架下应对这一挑战:首先通过离线计算学习细尺度行为,然后将学习到的行为直接应用于粗尺度计算。该方法借鉴了深度神经网络的最新成果,并结合了模型降阶的思想,通过深度神经网络在高维空间中的逼近能力与模型降阶技术相结合,构建出高保真、低计算成本、无需先验知识约束的神经网络近似模型,可直接嵌入粗尺度计算中。我们以镁材料(一种极具潜力的轻质结构和防护材料)的冲击响应问题为例,验证了该方法的有效性。
重要性:新材料的开发和优化具有挑战性,因为材料的宏观行为是在广泛的长度和时间尺度上运行的机制的结果。传统的经验模型计算成本低,但无法描述这种行为的复杂性。另一方面,高保真的并发多尺度方法用第一性原理建模取代了对经验信息的需求,但往往成本过高。我们提出了一种方法,通过将机器学习与模型降阶相结合来近似细尺度模型的解算器,以经验模型几倍的计算成本提供了并发多尺度建模及更高的保真度。
材料的宏观行为是跨越广泛时空尺度的多种机制共同作用的结果,其中较大尺度的机制既对较小尺度机制进行筛选(平均化),又对其施加调控(设定边界条件)。新材料的开发与优化需要理解不同尺度下的机制及其相互作用。传统研究通过在单一尺度构建模型来分析特定机制,例如:电子尺度、原子尺度、纳米尺度、亚晶粒尺度、工程尺度。近年来,多尺度建模成为研究热点,其核心思想是:
尺度层级划分:将材料行为分解为多个尺度层级;跨尺度信息传递:通过理论工具(如数学均匀化理论)在不同尺度间传递关键参数(如边界条件、本构关系);机制协同分析:整合各尺度模型以揭示宏观行为的形成机理。
多尺度建模方法主要分为两类:顺序多尺度(参数传递法)与并发多尺度法,两者在精度与计算成本间存在显著权衡。
1. 顺序多尺度方法(参数传递法)通过下层模型(如原子尺度)计算参数,传递给上层模型(如宏观尺度)以优化经验模型参数。优势是计算成本较低,可部分替代实验参数标定。缺点是粗尺度模型需先验假设(如本构方程形式),难以适应复杂非线性行为。参数传递可能导致跨尺度信息丢失(如瞬态过程的动态耦合效应)。
2. 并发多尺度方法是多尺度模型并行计算,实时交互数据(如边界条件、状态变量)。优势高保真度,可捕捉跨尺度动态耦合效应。局限是计算成本极高:需同时求解多尺度方程,难以处理工程实际问题。描述符依赖:需预先定义跨尺度通信的描述符(如状态变量、序参数),但其存在性与辨识方法尚不明确,尤其在瞬态现象中(如冲击载荷下的相变演化)。
多尺度材料建模面临两大关键挑战:其一,建模过程需依赖跨尺度交互的先验经验知识(如本构方程形式假设);其二,并发多尺度方法需反复求解计算昂贵的细尺度模型,却仅利用其极小部分信息(如边界条件),导致资源浪费。这引出了核心问题:如何利用细尺度模型的海量计算数据构建高效代理模型,使其解算器能直接嵌入粗尺度计算而无须额外建模?机器学习为此提供了新思路——深度神经网络已在图像识别与自然语言处理中展现出强大的特征提取与高维映射能力,并在材料科学中逐步应用:1)结合理论计算与高通量实验,加速材料性能预测与优化(如高通量筛选高强镁合金);2)实现跨尺度参数传递(如分子动力学到连续介质模型的弹性参数映射)与实验数据反演(如通过力学响应识别微观结构参数);3)构建材料本构行为代理模型(如神经网络替代晶体塑性计算)及均质化建模(如基于微观结构图像预测宏观弹性模量)。这些进展为多尺度建模的"保真度-效率"平衡提供了创新解决方案。
本研究提出了一种双尺度建模框架,旨在解决多尺度材料建模中“高保真与低计算成本难以兼顾”的核心挑战。以多晶非弹性固体冲击响应问题为例,该框架通过结合模型降阶技术与深度神经网络,实现了宏观力学问题的高保真求解(保真度达到甚至超越传统并发多尺度方法),其计算成本仅比经验模型高数倍。创新点在于:1)突破传统方法对先验状态变量的依赖(如无需预设本构方程中的内变量);2)利用神经网络直接学习函数空间映射关系(如平均应变历史→应力响应的偏微分方程解算子),而非传统离散化子空间,从而避免求解过程受网格分辨率制约;3)采用基于Bhattacharya等人发展的**“模型降阶+神经网络”混合方法**,实现跨尺度映射的高效近似,适用于非均匀材料动态响应等复杂场景。该框架为工程材料冲击损伤、防护结构设计等实际问题提供了兼具精度与效率的计算工具。
实验方法
(1)实验数据驱动替代方案
原则上可直接从实验数据学习宏观本构映射Ψ(无需依赖单元胞模型的细尺度计算),但需充足实验数据支持(如高时空分辨率的动态力学测试)。此外,可通过简化单元胞模型(如泰勒模型假设单元胞内速度场为零)降低计算复杂度,但会牺牲微观物理保真度。
(2)模型降阶与架构灵活性
降维方法:采用主成分分析(PCA)压缩输入(应变历史)与输出(应力历史)空间维度,但可替换为自动编码器等非线性降维技术。
学习架构:当前使用全连接深度神经网络,但可扩展为卷积网络(适用于空间局部特征提取)或随机特征模型(加速训练)。
(3)时间依赖性与状态建模限制
全局时间约束:需在预设的模拟总时长T内训练模型,而实际工程问题中T可能未知或动态变化。
状态信息缺失:当前模型仅关联平均变形梯度与应力历史,未显式建模材料内部状态(如位错密度、损伤变量)。
记忆效应未假设:未引入记忆衰退假设(如Boltzmann叠加原理),需未来从单元胞数据中学习时序依赖性。
(4)成本分析
离线成本(一次性生成数据与训练),与训练时间步长 T 呈线性关系,与训练数据集规模(模拟次数)及训练轮次(epochs)正相关
效率对比:离线成本与传统并发多尺度方法单次模拟成本相当(因所需训练样本数≈典型样本积分点数)
潜在优化:训练轮次与数据集规模可能受时间步长影响,需进一步研究
在线成本(模拟中神经网络评估)
计算量级:低于宏观时间积分成本,但随模拟时长 T 呈平方增长(需评估完整历史轨迹)
优势:在线计算成本仅比经验本构模型高数倍(如经验模型为1单位,本文方法为3~5单位)
因已知完整轨迹,可大幅增加宏观积分时间步长(如从 Δt=1μs 提升至 10μs),显著提升整体效率。
算法1 基于机器学习的多尺度建模方法

该算法通过结合离线训练与在线预测,利用神经网络替代传统并发多尺度计算中的细尺度求解,显著提升材料力学模拟效率。以下是分步解析:
第一阶段:离线训练(材料特性建模)
离线阶段旨在通过细尺度模拟构建材料的本构响应数据库,并训练机器学习模型替代传统经验方程。具体步骤如下:
(1)单元胞问题求解:选取代表材料微结构的单元胞(如多晶体的晶粒集合),施加多种宏观变形历史 U(t)(如阶梯加载、循环应变),通过有限元或分子动力学计算其响应,记录平均Cauchy应力 ⟨σ⟩(t) 和变形梯度 F(t)。例如,模拟镁合金在冲击下位错运动导致的应力演化。
(2)数据预处理与降维:对变形梯度历史 F(t) 进行极分解 F=QU,提取右拉伸张量 U(t) 以消除旋转效应;利用主成分分析(PCA)将高维应变-应力数据压缩至低维特征空间,减少神经网络输入维度。
(3)神经网络训练:构建深度神经网络(如全连接网络或LSTM),输入为降维后的变形历史特征,输出预测应力历史。训练时采用均方误差损失函数,优化器选择Adam,通过反向传播调整权重。最终得到映射 Ψ:U(t)→⟨σ⟩(t),隐式编码材料微观物理机制。
第二阶段:在线模拟(宏观动力学计算)
在线阶段利用训练好的模型实时预测材料响应,嵌入宏观有限元框架,实现高效多尺度计算:
问题离散化:将宏观结构(如骨植入物)离散为有限元网格,每个积分点关联一个材料响应模型;时间域采用显式中心差分法离散,步长 Δt 满足Courant条件。
时间步进循环:
步骤1:在时间步 tn,积分点接收变形梯度历史 {Fm}m≤n。
步骤2:极分解 Fm=QmUm 分离旋转 Qm 与纯变形 Um,消除刚体运动对应力的影响。
步骤3:插值生成连续变形轨迹 U(t)(如三次样条拟合 {Um}),输入训练好的神经网络预测应力 ⟨σ⟩(t)。
步骤4:根据当前旋转 Qn 修正应力方向:σn=Qn⟨σ⟩(tn)QnT,确保客观性。
步骤5:将 σn 传递至显式积分器,更新节点位移和速度,推进至 tn+1。
终止条件:当时刻 tn 达到预设总时长 T,输出位移、应力场及损伤演化结果。
实验结果
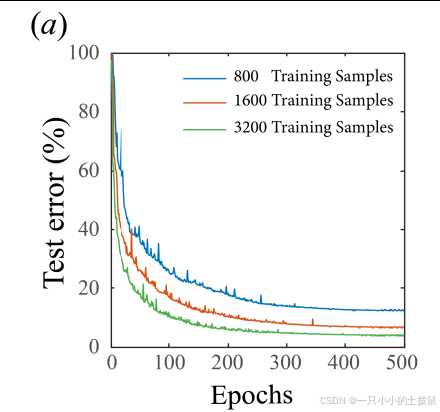
结果如图1所示。图1(a)显示,随着训练数据量和训练轮次的增加,测试误差(所有测试样本的平均值)逐渐减小,在3200个样本、400轮次的训练中,平均测试误差降至5%。图1(b,c)展示了使用3200个样本和500轮次训练的神经网络对典型测试样本和训练样本的输入和输出(包括真实值和近似值)。我们得出结论,我们的模型简化方法能够学习到地图Ψ的非常精确的近似。